
Pakiet SDK oprogramowania sprzęgającego i interfejs Cloud Search API obsługują tworzenie kolejek indeksowania Cloud Search. Używaj tych kolejek, aby:
- Utrzymuj stan poszczególnych dokumentów (stan, hasze itp.), aby zachować synchronizację indeksu.
- Utrzymuje listę elementów do zindeksowania, które zostały wykryte podczas przechodzenia.
- Ustal priorytety elementów na podstawie ich stanu.
- przechowywania informacji o stanie, takich jak punkty kontrolne i tokeny zmian;
Kolejka to etykieta przypisana do indeksowanego elementu (np. „default”).
Stan i priorytet
Priorytet dokumentu zależy od jego kodu:ItemStatus Możliwe kody w kolejności priorytetu (od najwyższego do najniższego):
ERROR: produkt napotkał błąd asynchroniczny i wymaga ponownego zindeksowania.MODIFIED: produkt został wcześniej zindeksowany, ale uległ zmianie w repozytorium.NEW_ITEM: produkt nie został jeszcze zindeksowany.ACCEPTED: element został wcześniej zindeksowany i nie uległ zmianie.
W przypadku elementów o tym samym stanie wyższy priorytet mają te, które najdłużej znajdują się w kolejce.
Indeksowanie nowego lub zmienionego elementu
Ilustracja 1 przedstawia kroki indeksowania nowego lub zmienionego elementu za pomocą kolejki indeksowania. Te czynności odzwierciedlają wywołania interfejsu API REST. Odpowiedniki w pakiecie SDK znajdziesz w sekcji Operacje na kolejkach (pakiet SDK oprogramowania sprzęgającego).
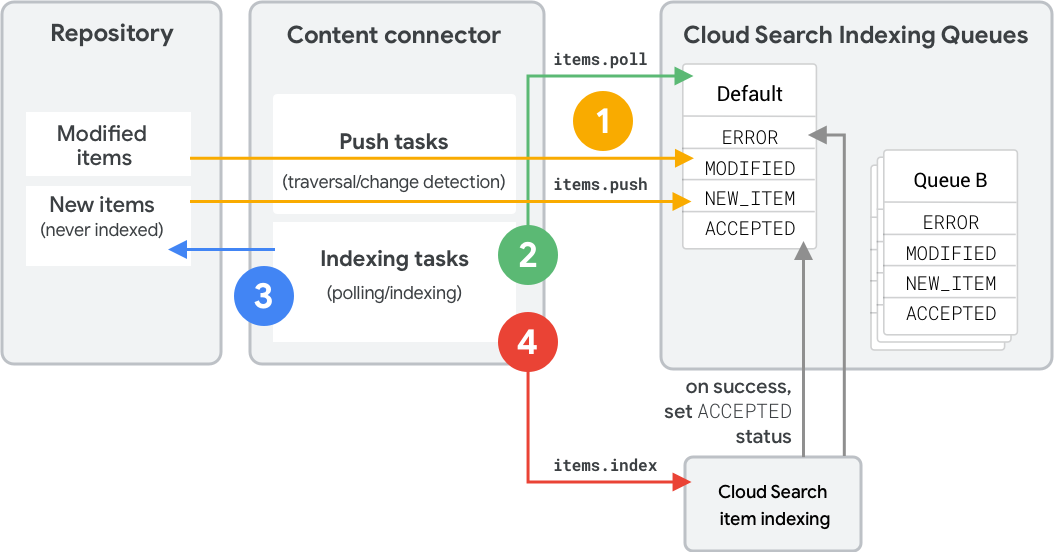
- Łącznik treści używa
items.pushdo umieszczania metadanych i haszy w kolejce.- Jeśli program sprzęgający zawiera push
typelubcontentHash, Cloud Search określa stan. - Nieznane produkty otrzymują stan
NEW_ITEM. - Istniejące elementy z pasującymi haszami pozostaną
ACCEPTED. - Istniejące produkty z różnymi skrótami stają się
MODIFIED.
- Jeśli program sprzęgający zawiera push
- Oprogramowanie sprzęgające używa parametru
items.polldo określania, które elementy mają być indeksowane. Cloud Search zwraca elementy w kolejności priorytetu. - Oprogramowanie sprzęgające pobiera elementy z repozytorium i tworzy żądania interfejsu API indeksu.
- Oprogramowanie sprzęgające używa
items.indexdo indeksowania elementów. Po pomyślnym przetworzeniu produkt przechodzi w stanACCEPTED.
Usuwanie elementu
Strategia pełnego przechodzenia korzysta z 2 kolejek do indeksowania elementów i wykrywania usunięć. Na rysunku 2 widać drugie przejście w ramach tej strategii.
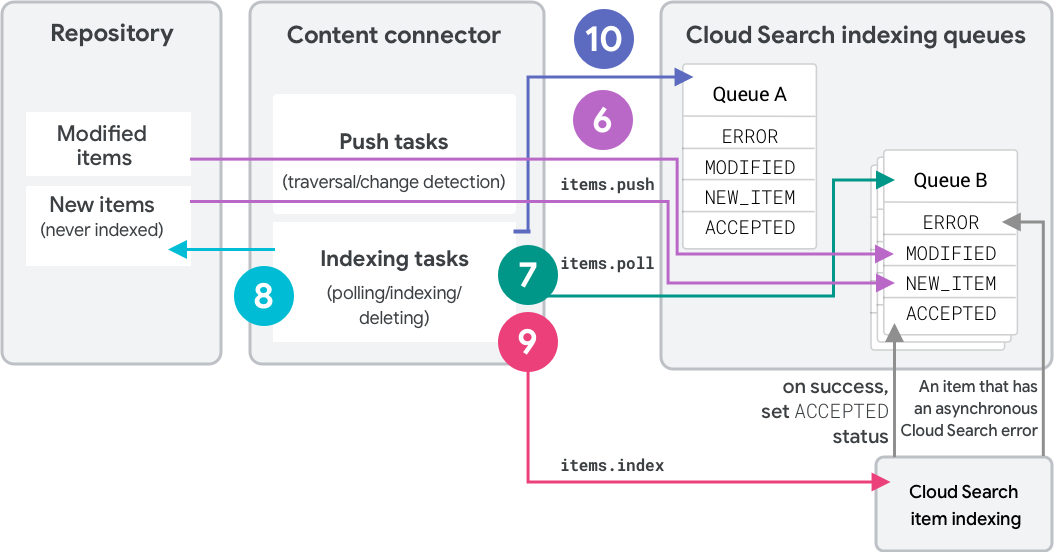
- Podczas pierwszego przejścia oprogramowanie sprzęgające umieszcza elementy w „kolejce A” jako
NEW_ITEM. Każdy element otrzymuje etykietę „A”. - Oprogramowanie sprzęgające odpytuje kolejkę A i indeksuje elementy.
- Podczas drugiego pełnego przejścia łącznik przesyła elementy do „kolejki B”.
- Nieznane produkty otrzymują etykietę „B” i stan
NEW_ITEM. - Istniejące elementy o pasujących skrótach zmieniają etykietę na „B” i pozostają w
ACCEPTED. - Istniejące produkty z różnymi haszami zmieniają etykietę na „B” i stają się
MODIFIED.
- Nieznane produkty otrzymują etykietę „B” i stan
- Oprogramowanie sprzęgające odpytuje kolejkę B i indeksuje elementy.
- Na koniec oprogramowanie sprzęgające wywołuje
deleteQueueItemsw kolejce A. Spowoduje to usunięcie wszystkich wcześniej zindeksowanych elementów, które nadal mają etykietę „A”. - Kolejne przejścia zamieniają role obu kolejek.
Operacje na kolejce (pakiet SDK łącznika)
Użyj narzędzia do tworzenia pushItems, aby wypychać elementy. Pakiet SDK automatycznie pobiera elementy z kolejki w kolejności priorytetów za pomocą metody getDoc klasy Repository.
Operacje na kolejkach (API REST)
- Aby przesunąć: użyj
Items.push. - Aby wysłać ankietę, użyj
Items.poll.
Możesz też użyć
Items.index
do wypychania elementów podczas indeksowania. Te elementy automatycznie otrzymują stan ACCEPTED.
Items.push
Ta metoda dodaje identyfikatory do kolejki. Wartość
type
określa wynik. Wysłanie nowego identyfikatora powoduje dodanie wpisu ze stanem NEW_ITEM.
Opcjonalny ładunek jest zwracany podczas odpytywania.
Elementy objęte sondowaniem są zarezerwowane i nie mogą być zwracane przez inne wywołania sondowania. Użycie elementu Items.push z atrybutem type ustawionym na NOT_MODIFIED, REPOSITORY_ERROR lub REQUEUE cofnie rezerwację wpisów.
Items.push z hashami
W żądaniu push określ metadane lub hasze treści.
Cloud Search porównuje je z zapisanymi wartościami. Jeśli się nie zgadzają, wpis staje się MODIFIED. Niedopasowane identyfikatory, które nie istnieją, stają się NEW_ITEM.
Items.poll
Ta metoda pobiera wpisy o wysokim priorytecie. Każdy zwrócony wpis jest zarezerwowany, dopóki nie upłynie czas jego ważności, nie zostanie ponownie zindeksowany lub nie zostanie odwołana jego rezerwacja za pomocą Items.push.