DSPL adalah singkatan dari {i>Dataset Publishing Language<i}. Set data yang dijelaskan di DSPL dapat diimpor ke Google Public Data Penjelajah, alat yang memungkinkan eksplorasi visual yang lengkap layanan otomatis dan data skalabel.
Catatan: Untuk mengupload data ke Google Public Data menggunakan alat upload Data Publik, Anda harus memiliki Akun Google.
Tutorial ini memberikan contoh langkah demi langkah tentang cara mempersiapkan dasar-dasar set data DSPL.
Set data DSPL adalah paket yang berisi file XML dan serangkaian CSV. File CSV adalah tabel sederhana yang berisi data dari {i>dataset <i}tersebut. File XML menjelaskan metadata set data, termasuk {i>metadata <i}informasi seperti deskripsi tindakan, serta {i>metadata<i} struktural seperti referensi antar tabel. {i>Metadata<i} memungkinkan pengguna non-ahli untuk mengeksplorasi dan memvisualisasikan data Anda.
Satu-satunya prasyarat untuk memahami tutorial ini adalah level yang baik memahami XML. Sedikit pemahaman tentang konsep database sederhana (misalnya, tabel, {i>primary key<i}) mungkin membantu, tetapi hal itu tidak wajib. Sebagai referensi, file XML lengkap dan lengkapi {i>dataset<i} paket yang terkait dengan tutorial ini juga tersedia untuk ditinjau.
Ringkasan
Sebelum mulai membuat {i>dataset<i}, berikut adalah ikhtisar tingkat tinggi dari isi set data DSPL:
- Informasi umum: Tentang set data
- Konsep: Definisi "objek" sehingga muncul dalam {i>dataset <i}(mis., negara, tingkat pengangguran, gender, etc.)
- Slice: Kombinasi konsep yang memiliki data
- Tabel: Data untuk konsep dan slice. Tabel konsep pembekuan enumerasi dan tabel irisan menyimpan data statistik
- Topik: Digunakan untuk mengatur konsep set data dalam hierarki yang bermakna melalui pelabelan
Untuk mengilustrasikan gagasan yang agak abstrak ini, pertimbangkan {i>dataset<i} (dengan data contoh) yang digunakan di seluruh tutorial ini: deret waktu statistik untuk populasi dan pengangguran, digabungkan berdasarkan berbagai kombinasi negara, Negara bagian AS, dan jenis kelamin.
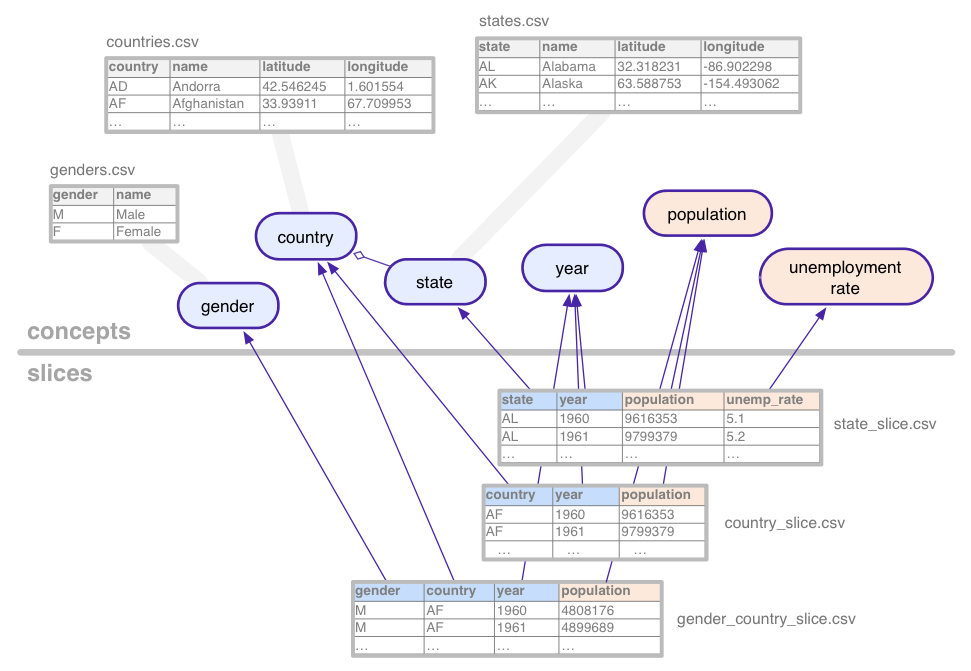
Contoh set data ini menentukan konsep berikut:
- country
- gender
- populasi
- dengan status tersembunyi akhir
- tingkat pengangguran
- tahun
Konsep yang bersifat kategorikal, seperti status, dikaitkan dengan konsep tabel, yang menghitung semua kemungkinan nilainya (California, Arizona, dll.). Konsep dapat memiliki kolom tambahan untuk properti seperti nama atau negara suatu negara bagian.
Slice menentukan setiap kombinasi konsep yang tidak
data statistik yang ada
dalam {i>dataset <i}tersebut. Sebuah irisan berisi dimensi dan
metrik. Pada gambar di atas, dimensinya berwarna biru dan
metrik berwarna oranye. Dalam contoh ini, potongan
gender_country_slice memiliki data untuk metrik
population dan dimensi country,
year dan gender. Bagian lain, yang disebut
country_slice, memberikan total jumlah populasi tahunan (metrik) untuk
negara.
Selain dimensi dan metrik, slice juga merujuk tabel, yang berisi data aktual.
Sekarang, mari kita pelajari langkah demi langkah pembuatan {i>dataset<i} tersebut di {i>DSPL<i}.
Informasi Set Data
Untuk memulai, kita perlu membuat file XML untuk set data kita. Berikut adalah awal deskripsi DSPL untuk contoh {i>dataset<i} kita:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
Deskripsi set data dimulai dengan <dspl> tingkat atas
. Atribut targetNamespace berisi URI yang
secara unik mengidentifikasi
{i>dataset<i} tersebut. Namespace {i>dataset<i} terutama
penting saat mempublikasikan {i>dataset<i}, karena akan menjadi pengenal global
{i>dataset<i} Anda, dan sarana bagi
orang lain untuk menyebutnya.
Perlu diperhatikan bahwa atribut targetNamespace dapat dihilangkan. Di beberapa
dalam hal ini, namespace unik akan
otomatis dibuat saat set data
diimpor.
Menggunakan informasi dari {i>dataset<i} lain
{i>Dataset<i} dapat menggunakan kembali definisi dan data dari {i>dataset<i} lain dengan mengimpor
{i>dataset<i} tersebut. Setiap elemen <import> menentukan
namespace dari set data lain yang akan dirujuk oleh set data ini.
Dalam contoh set data, kita memerlukan beberapa definisi dari http://www.google.com/publicdata/dataset/google/quantity (set data yang dibuat oleh Google yang berisi konsep yang berguna untuk menentukan jumlah numerik), dan dari set data waktu, entitas, dan geo, yang menyediakan berkaitan dengan waktu, entitas, dan geografi.
Elemen <dspl> teratas menyediakan awalan namespace
deklarasi (mis., xmlns:time="http://...") untuk setiap
dari set data yang diimpor. Deklarasi awalan diperlukan untuk mereferensikan
elemen dari {i>dataset<i} lain secara ringkas. Contohnya,
time:year merujuk pada definisi year dalam
set data yang diimpor yang namespace-nya terkait dengan awalan
time.
Info penyedia dan set data
Elemen <info> berisi informasi umum tentang
set data: nama, deskripsi, dan URL tempat informasi lebih lanjut
ditemukan.
Elemen <provider> berisi informasi tentang
penyedia set data: namanya dan URL tempat informasi lebih lanjut dapat
yang ditemukan (umumnya halaman beranda penyedia data).
Mendefinisikan Konsep
Sekarang setelah kami memberikan beberapa informasi umum tentang {i>dataset<i}, kita siap untuk mulai mendefinisikan kontennya. Tujuan kita selanjutnya adalah menambahkan statistik populasi untuk negara selama 50 tahun terakhir.
Hal pertama yang perlu kita lakukan adalah memberikan beberapa definisi untuk gagasan-gagasan tersebut populasi, negara, dan tahun. Dalam DSPL, definisi ini disebut konsep.
Konsep adalah definisi jenis data yang muncul dalam {i>dataset<i} aslinya. Nilai-nilai data yang sesuai dengan konsep tertentu disebut instance dari konsep tersebut.
Populasi
Mari kita mulai dengan mendefinisikan
konsep populasi. Di
Dokumen DSPL, konsep ditentukan dalam <concepts>
elemen yang muncul tepat setelah {i>dataset
<i}dan informasi penyedia.
Berikut ini adalah konsep populasi yang hanya memerlukan sedikit informasi
untuk konsep apa pun: id (ID unik), name, dan
type.
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Berikut adalah cara kerja contoh ini:
- Setiap konsep harus menyediakan
idyang mengidentifikasi secara unik konsep dalam set data tersebut. Ini berarti bahwa tidak ada dua konsep yang didefinisikan dalam {i>dataset<i} yang sama boleh memiliki ID yang sama. - Sama seperti {i>dataset<i} dan penyedianya,
Elemen
<info>memberikan informasi tekstual tentang konsep, seperti nama dan deskripsinya. - Elemen
<type>menentukan jenis data untuk instance dari konsep (dengan kata lain, "nilainya"). Dalam contoh ini, jenispopulationadalahinteger. DSPL mendukung jenis data berikut:stringintegerfloatbooleandate
Negara
Sekarang, mari kita tuliskan definisi konsep negara:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
Definisi konsep negara dimulai
seperti sebelumnya,
dengan id, info, dan type.
Nilai konsep
Konsep kategoris seperti negara memiliki
enumerasi dari semua kemungkinan
instance Compute Engine. Dengan kata lain, Anda dapat membuat
daftar semua kemungkinan negara yang
yang direferensikan. Namun, untuk melakukannya, setiap negara memerlukan ID unik.
Contoh ini menggunakan
Kode negara ISO untuk mengidentifikasi negara; kode-kode ini
dari jenis string.
Dalam contoh ini, Anda tidak perlu menggunakan kode ISO; Anda bisa saja menggunakan nama negara. Namun, nama berbeda-beda di setiap bahasa, dapat berubah dari waktu ke waktu, dan tidak selalu digunakan secara konsisten di seluruh {i>dataset<i}. Untuk negara, dan untuk konsep kategoris secara umum, adalah latihan untuk memilih, singkat, stabil, umum digunakan, dan tidak bergantung pada bahasa pengenal Anda (jika ada).
Properti konsep
Selain id, konsep negara ini memiliki
Elemen <property> yang menentukan nama negara.
Dengan kata lain, nama negara ("Irlandia") adalah properti
negara dengan IE id. Properti adalah cara
DSPL menyediakan
informasi terstruktur tambahan
tentang contoh suatu konsep.
Sama seperti konsep itu sendiri, properti memiliki id,
info, dan type.
Data konsep
Terakhir, konsep negara memiliki elemen <table>.
Elemen ini merujuk ke tabel yang menghitung daftar semua
negara.
Menggunakan tabel masuk akal untuk beberapa konsep, tetapi tidak untuk yang lain. Sebagai tidak masuk akal untuk menghitung semua nilai yang mungkin untuk populasi konsep. Namun, jika Anda mereferensikan tabel untuk sebuah konsep, tabel tersebut harus berisi semua {i>instance<i} konsep tersebut—misalnya, aplikasi harus mencantumkan setiap negara, bukan hanya beberapa contoh.
Set data menentukan tabel countries_table sebagai berikut:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Tabel negara menentukan kolom tabel dan jenisnya,
dan mereferensikan file CSV yang berisi data tersebut. CSV ini dapat berupa
dipaketkan dan diupload dengan XML set data atau diakses dari jarak jauh melalui HTTP, HTTPS,
atau FTP. Dalam kasus yang terakhir, Anda akan mengganti countries.csv dengan
URL, misalnya http://www.myserver.com/mydata/countries.csv.
Di mana pun {i>file<i} disimpan, {i>file<i} CSV akan terlihat seperti ini:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
Baris pertama tabel mencantumkan ID kolom, seperti yang ditentukan dalam DSPL
Definisi table. Setiap baris berikut sesuai dengan satu
dari konsep negara. Jika konsep memiliki tabel, maka
tabel harus berisi semua instance konsep- dalam
maka harus mencantumkan semua negara.
Kolom dipetakan ke konsep negara dan propertinya berdasarkan
ID mereka. ID kolom pertama, country, cocok dengan konsep
ke ID tertentu. Artinya kolom ini berisi pengenal negara unik
didefinisikan oleh konsep negara. Kolom berikutnya sesuai dengan
properti name dari konsep negara. Nilai-nilai
di kolom ini cocok dengan nilai properti name.
Ada beberapa persyaratan data CSV untuk tabel konsep:
- Tajuk kolom di baris pertama {i>file<i} data harus
sama persis dengan konsep
iddan propertiiddari konsep yang terkait dengan data (meskipun urutan dapat bervariasi). - Setiap baris harus memiliki jumlah elemen yang sama persis dengan jumlah elemen properti pada konsep (meskipun nilainya kosong).
- Setiap nilai untuk kolom
idkonsep (di sini, kolom kode negara) harus unik dan tidak kosong (kolom kosong adalah angka nol atau hanya karakter spasi kosong). - Nilai untuk properti yang merujuk konsep lain harus kosong atau merupakan nilai valid dari konsep yang dirujuk.
- Nilai yang berisi koma, tanda kutip ganda, atau karakter baris baru harus diapit oleh tanda kutip ganda.
- Karakter tanda kutip ganda literal di dalam nilai harus segera diawali dengan tanda kutip ganda lainnya.
Tahun
Konsep terakhir yang kita perlukan untuk
data populasi negara adalah konsep untuk
mewakili tahun. Alih-alih mendefinisikan konsep baru, kita akan menggunakan
konsep tahun dari salah satu {i>dataset<i} yang kami impor:
"http://www.google.com/publicdata/dataset/google/time". Untuk melakukannya:
kita perlu mereferensikannya sebagai time:year, dengan time
mewakili set data yang direferensikan, dan year mengidentifikasi
konsepnya.
Konsep kanonis
time:year adalah bagian dari sekumpulan kecil konsep kanonis
yang ditentukan oleh Google. Konsep kanonis memberikan
definisi dasar untuk waktu,
geografi, besaran numerik, satuan, dll.
Bahkan, konsep negara yang didefinisikan di atas ada sebagai sebuah
konsep kanonis. Kami hanya membuatnya di sini untuk tujuan ilustrasi.
Bila memungkinkan, Anda harus menggunakan konsep kanonikal dalam {i>dataset<i} Anda, baik
secara langsung atau dengan memperluasnya (selengkapnya tentang ekstensi ada di bawah). Konsep kanonis
membuat data Anda sebanding dengan {i>dataset<i} lainnya, dan mengaktifkan fitur untuk
{i>dataset<i} di dalam Penjelajah Data Publik. Misalnya, menganimasikan data dari waktu ke waktu
atau menampilkan data geografis pada peta bergantung pada penggunaan time dan
geo masing-masing konsep.
Bagian Pertama
Setelah kita memiliki konsep populasi, negara, dan tahun, untuk menggabungkannya!
Untuk itu, kita perlu membuat slice yang menggabungkannya. Di DSPL, sebuah irisan adalah kombinasi konsep tentang keberadaan data.
Mengapa tidak membuat tabel dengan kolom yang tepat saja? Karena slice menangkap informasi {i>dataset<i} dalam hal konsepnya. Hal ini akan menjadi menjadi lebih jelas saat membuat lebih banyak bagian dari {i>dataset<i}.
Slice muncul dalam file DSPL di bawah <slices>
, yang harus muncul tepat setelah bagian concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Sama seperti konsep, setiap irisan memiliki id
(countries_slice) yang secara unik mengidentifikasi slice dalam
{i>dataset<i} aslinya.
Slice berisi dua jenis referensi konsep: Dimensi dan
metrik. Nilai metrik bervariasi sesuai dengan
dimensi kustom. Di sini, nilai population (metrik) bervariasi menurut
dimensi country dan year.
Sama seperti konsep, slice menyertakan referensi ke tabel yang berisi data slice. Tabel yang dirujuk harus memiliki satu kolom untuk setiap dimensi dan metrik irisan. Sama seperti konsep, lapisan dimensi dan metrik dipetakan ke kolom tabel dengan ID yang sama.
Tabel irisan
Tabel untuk irisan populasi muncul dalam tables
dari file DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Perhatikan bahwa kolom year dilengkapi dengan format
yang menentukan pemformatan tahun. Format tanggal yang didukung adalah
yang ditentukan oleh format Joda DateTime.
Tabel countries_slice menentukan kolom tabel dan
jenisnya, dan menunjuk ke {i>file<i} CSV yang berisi data. File CSV
akan terlihat seperti ini:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Setiap baris tabel data berisi kombinasi dimensi yang unik
country dan year, beserta nilai yang sesuai
dari metrik population (misalnya, populasi -
metrik - Afganistan pada tahun 1960 - dimensi).
Perhatikan bahwa nilai dalam kolom country sesuai dengan
nilai/ID konsep country, yaitu ISO 3166
Kode 2 huruf negara.
Data CSV untuk sebuah slice harus memenuhi batasan berikut:
- Setiap nilai kolom dimensi (seperti
countrydanyear) tidak boleh kosong. Nilai untuk kolom metrik (sepertipopulation) boleh kosong. Nilai kosong ditunjukkan dengan tidak karakter. - Setiap nilai kolom dimensi yang mereferensikan konsep harus
yang ada dalam
data konsep tersebut. Misalnya, nilai
AFharus ada di tabel data konsepcountry. - Setiap kombinasi unik dari nilai dimensi, mis.
AF, 2000, hanya mungkin terjadi sekali. - Data harus diurutkan menurut kolom dimensi non-waktu (dalam urutan apa pun),
dan kemudian, secara opsional, oleh kolom lainnya. Jadi, misalnya,
di tabel dengan kolom
[date, dimension1, dimension2, metric1, metric2], Anda dapat mengurutkan menurutdimension1, laludimension2, laludate, tapi jangan dengandate, lalu dimensinya.
Ringkasan
Saat ini, kami memiliki cukup data di DSPL untuk mendeskripsikan negara data populasi. Sebagai rangkuman, apa yang harus kami lakukan adalah:
- Buat {i>header<i} dan deskripsi DSPL {i>dataset<i} beserta atributnya cloud Anda
- Buat satu konsep untuk populasi dan satu lagi untuk negara, dengan csv yang menghitung semua negara dan namanya.
- Buat potongan dengan jumlah populasi negara dari waktu ke waktu, merujuk ke konsep tahun yang sudah ditentukan dalam {i>dataset<i} waktu yang diimpor dari Google.
Di sisa tutorial ini, kita akan membuat {i>dataset<i} yang lebih kaya dengan menambahkan lebih banyak dimensi dalam lebih banyak bagian, serta lebih banyak metrik yang dikelompokkan menurut topik.
Menambahkan Dimensi: Negara Bagian AS
Sekarang mari kita perkaya {i>dataset<i} dengan menambahkan data populasi untuk Amerika Serikat. Pertama-tama, kita perlu menentukan konsep untuk status. Ini terlihat sangat seperti konsep negara yang kita definisikan sebelumnya.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Ekstensi dan properti konsep referensi
Konsep status memperkenalkan beberapa fitur baru DSPL.
Pertama, status memperluas konsep lain,
geo:location (ditentukan dalam set data geografis eksternal,
diimpor di awal set data). Secara semantik, ini berarti bahwa
state adalah jenis geo:location. Konsekuensinya adalah
bahwa ia mewarisi semua atribut dan properti
geo:location. Secara khusus, lokasi mendefinisikan
properti untuk
latitude dan longitude; dengan memperluas fungsi
, properti ini juga diterapkan ke status. Selain itu, karena
lokasi mewarisi dari entity:entity, status juga mendapat
semua properti yang terakhir, termasuk name,
description, dan info_url.
Catatan: Konsep negara yang ditentukan sebelumnya
harus, secara teknis, juga diperluas dari geo:location.
Poin ini dihilangkan sebelumnya agar lebih praktis; kita menyertakan
lokasi ke pewarisan negara, namun, dalam
file XML final.
Catatan: Anda dapat menggunakan extends
mengkonstruksi di {i>dataset <i}Anda sendiri untuk menggunakan kembali informasi yang ditentukan oleh {i>dataset<i} lain.
Penggunaan extends mengharuskan semua instance konsep Anda
instance yang valid dari konsep yang diperluas. Ekstensi memungkinkan Anda menambahkan
properti dan atribut tambahan, serta membatasi kumpulan instance
dari instance konsep yang diperluas.
Selain pewarisan, properti status juga memperkenalkan
konsep referensi konsep.
Secara khusus, konsep status memiliki properti yang disebut country,
yang merujuk pada konsep negara
yang kita buat di atas. Hal ini dilakukan dengan
menggunakan atribut concept. Perhatikan bahwa properti ini tidak
memberikan id, hanya referensi konsep. Ini sama seperti membuat ID
dengan nilai yang sama dengan ID konsep yang direferensikan (yaitu,
country dalam contoh ini). Hubungan hierarkis antara
negara bagian dan county ditangkap dengan memiliki atribut
isParent="true" pada referensi. Secara umum,
dimensi dengan hubungan hierarkis, seperti geografi, harus
direpresentasikan dengan cara ini, dengan konsep turunan
yang memiliki properti yang
merujuk konsep induk menggunakan atribut isParent.
Definisi tabel untuk status terlihat seperti ini:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
Kolom negara memiliki nilai konstan untuk semua negara bagian. Menentukannya di
DSPL menghindari pengulangan nilai tersebut untuk setiap status dalam data. Perhatikan juga
bahwa kita telah menyertakan kolom untuk name, latitude, dan
longitude karena status telah mewarisi properti ini dari
geo:location. Di sisi lain, beberapa properti turunan
(mis., description) tidak memiliki kolom; ini tidak apa-apa-
jika properti dihilangkan dari tabel definisi konsep, maka nilainya adalah
diasumsikan tidak terdefinisi untuk setiap {i>instance<i} konsep.
File CSV akan terlihat seperti ini:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Karena kita sudah memiliki konsep populasi dan tahun, kita dapat menggunakannya kembali untuk menentukan irisan baru untuk populasi negara bagian.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>Definisi tabel data terlihat seperti ini:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Dan file CSV akan terlihat seperti ini:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Tunggu, mengapa kita membuat slice baru, bukan menambahkan slice lain dengan sebelumnya?
Bagian dengan dimensi untuk negara bagian dan negara tidak akan benar, karena beberapa baris untuk data negara dan beberapa baris untuk negara bagian layanan otomatis dan data skalabel. Tabel itu akan memiliki “lubang” untuk beberapa dimensi, yaitu tidak diizinkan (ingat bahwa nilai yang hilang hanya diizinkan untuk metrik dan bukan dimensi).
Dimensi berfungsi sebagai "kunci utama" untuk slice. Hal ini berarti bahwa setiap baris data harus memiliki nilai untuk semua dimensi dan tidak boleh ada dua baris data dapat memiliki nilai yang sama persis untuk semua dimensi.
Menambahkan Metrik: Pengangguran Beri rating
Sekarang, mari tambahkan metrik lain ke set data:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
Bagian info dari metrik ini memiliki nama, deskripsi, dan
URL (penautan ke Biro Statistik Tenaga Kerja AS).
Konsep ini juga memperluas konsep kanonis quantity:rate.
Jumlah
set data menentukan konsep inti untuk mewakili kuantitas numerik. Di beberapa
{i>dataset<i}, Anda harus membuat konsep numerik Anda dengan memperluas
konsep kuantitas yang sesuai. Dengan demikian, konsep population
yang didefinisikan di atas, secara teknis, telah diperluas dari
quantity:amount.
Atribut konsep
Konsep ini juga memperkenalkan konstruksi atribut. Di beberapa
contoh ini, atribut digunakan untuk menyatakan bahwa unemployment_rate
adalah persentase. Atribut is_percentage diwarisi dari
konsep quantity:rate yang diperluas dari konsep ini. Ini
informasi digunakan oleh Penjelajah Data Publik
untuk menunjukkan tanda persen ketika
memvisualisasikan data.
Atribut menyediakan mekanisme umum untuk melampirkan pasangan kunci/nilai ke
(berlawanan dengan properti, yang mengaitkan nilai tambahan dengan
instance dari konsep). Sama seperti konsep dan properti,
memiliki atribut id, info, dan
type. Seperti properti, mereka dapat merujuk konsep lain.
Atribut tidak hanya untuk hal-hal umum yang telah ditentukan sebelumnya, seperti properti baru. Anda dapat menentukan atribut sendiri untuk konsep Anda.
Menambahkan Data Tingkat Pengangguran untuk Amerika Serikat Negara Bagian
Kami sekarang siap untuk menambahkan data tingkat pengangguran untuk negara bagian AS. Karena tingkat pengangguran adalah metrik dan kita sudah memiliki data populasi untuk negara bagian, kita bisa menambahkannya ke slice yang sudah dibuat untuk status dan tahun dimensi:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... dan menambahkan kolom lain ke definisi tabel:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... dan ke file CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Sebelumnya kita telah menyatakan bahwa untuk setiap irisan, dimensi membentuk kunci utama untuk slice. Selain itu, setiap {i>dataset<i} hanya dapat berisi satu irisan untuk sebuah berdasarkan kombinasi dimensi tertentu. Semua metrik yang tersedia untuk dimensi harus berada dalam irisan yang sama.
Dimensi Lainnya: Perincian Populasi berdasarkan Gender
Mari kita memperkaya {i>dataset<i} dengan perincian populasi berdasarkan gender untuk negara. Sekarang, kamu sudah mulai tahu apa yang harus dilakukan... Pertama-tama, kita harus menambahkan konsep untuk gender:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
Bagian konsep gender info memiliki
pluralName, yang menyediakan teks yang akan digunakan untuk merujuk
beberapa instance dari konsep gender. Bagian info juga
menyertakan totalName, yang menyediakan teks yang akan digunakan untuk
merujuk pada semua contoh
konsep gender secara keseluruhan. Keduanya adalah
digunakan oleh Penjelajah Data Publik untuk menampilkan informasi yang terkait dengan gender
konsep. Secara umum, Anda harus menyediakannya
untuk konsep yang dapat digunakan sebagai
dimensi kustom.
Perhatikan bahwa konsep
gender juga meluas dari
entity:entity. Ini adalah praktik yang baik untuk
yang digunakan sebagai dimensi, karena memungkinkan Anda menambahkan nama,
URL, dan warna untuk berbagai instance konsep.
Konsep gender mengacu pada tabel genders_table, yang
berisi kemungkinan nilai untuk gender dan nama tampilannya
(dihapus di sini).
Untuk menambahkan populasi menurut gender ke set data, kita perlu membuat irisan baru (ingat: setiap kombinasi dimensi yang tersedia sesuai dengan irisan di {i>dataset<i}).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
Definisi tabel untuk slice tersebut akan terlihat seperti ini:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
File CSV untuk tabel akan terlihat seperti ini:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
Dibandingkan dengan tingkat negara, populasi, dan pengangguran sebelumnya, model ini memiliki dimensi tambahan; setiap nilai metrik populasi tidak hanya sesuai dengan negara dan tahun tertentu, tetapi juga dengan jenis kelamin tertentu.
Perhatikan bahwa kita telah membuat "sparse" {i>dataset<i} aslinya. Tidak semua metrik tersedia untuk semua dimensi: populasi adalah tersedia untuk negara dan negara bagian AS, setiap tahun, sementara tingkat pengangguran tarif hanya tersedia untuk negara. Perincian berdasarkan gender tersedia untuk populasi hanya berdasarkan negara; tidak tersedia untuk tingkat pengangguran dan bukan untuk dimensi status. Ketersebaran juga bisa ada pada data metrik tertentu yang tidak memiliki nilai dimensi tertentu, tapi itu tidak diwakili dalam DSPL.
Topik
Fitur terakhir DSPL yang akan kita gunakan dalam set data adalah topik. Topik digunakan untuk mengklasifikasikan konsep secara hierarkis, dan digunakan oleh aplikasi untuk membantu pengguna menavigasi ke data Anda.
Dalam file DSPL, topik muncul tepat sebelum konsep. Berikut contohnya hierarki topik:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Anda dapat menyusun bertingkat topik sedalam yang diperlukan.
Untuk menggunakan topik, Anda hanya perlu merujuk pada topik tersebut dari definisinya, sebagai berikut:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Sebuah konsep dapat merujuk ke lebih dari satu topik.
Mengirimkan Set Data Anda
Sekarang setelah Anda membuat {i>dataset<i}, langkah selanjutnya adalah upload file zip untuk alat Google Public Data Explorer. Jika Anda mengalami masalah, periksa FAQ, yang mencakup diskusi masalah upload yang paling umum.
Sebagai referensi, Anda juga dapat mendownload file XML lengkap dan paket set data lengkap yang terkait dengan tutorial ini.
Langkah Selanjutnya
Selamat atas pembuatan set data DSPL pertama Anda. Sekarang setelah Anda untuk memahami dasar-dasarnya, sebaiknya baca Panduan Developer, yang, antara lain, dokumen "lanjutan" Fitur DSPL seperti dukungan multibahasa dan konsep yang dapat dipetakan.
Anda mungkin juga ingin melihat beberapa contoh set data lainnya.