DSPL মানে ডেটাসেট পাবলিশিং ল্যাঙ্গুয়েজ। DSPL-এ বর্ণিত ডেটাসেটগুলি Google পাবলিক ডেটা এক্সপ্লোরার- এ আমদানি করা যেতে পারে, একটি টুল যা ডেটার সমৃদ্ধ, ভিজ্যুয়াল অনুসন্ধানের অনুমতি দেয়।
দ্রষ্টব্য: পাবলিক ডেটা আপলোড টুল ব্যবহার করে Google পাবলিক ডেটাতে ডেটা আপলোড করতে, আপনার একটি Google অ্যাকাউন্ট থাকতে হবে।
এই টিউটোরিয়ালটি কীভাবে একটি মৌলিক DSPL ডেটাসেট প্রস্তুত করতে হয় তার একটি ধাপে ধাপে উদাহরণ প্রদান করে।
একটি DSPL ডেটাসেট হল একটি বান্ডিল যাতে একটি XML ফাইল এবং CSV ফাইলের একটি সেট থাকে। CSV ফাইলগুলি হল সাধারণ সারণী যাতে ডেটাসেটের ডেটা থাকে৷ এক্সএমএল ফাইল ডেটাসেটের মেটাডেটা বর্ণনা করে, যার মধ্যে তথ্যগত মেটাডেটা যেমন পরিমাপের বর্ণনা, সেইসাথে টেবিলের মধ্যে রেফারেন্সের মতো কাঠামোগত মেটাডেটা। মেটাডেটা অ-বিশেষজ্ঞ ব্যবহারকারীদের আপনার ডেটা অন্বেষণ এবং কল্পনা করতে দেয়।
এই টিউটোরিয়ালটি বোঝার একমাত্র পূর্বশর্ত হল এক্সএমএল বোঝার একটি ভাল স্তর। সাধারণ ডাটাবেস ধারণাগুলির কিছু বোঝা (যেমন, টেবিল, প্রাথমিক কী) সাহায্য করতে পারে, তবে এটির প্রয়োজন নেই। রেফারেন্সের জন্য, এই টিউটোরিয়ালের সাথে যুক্ত সম্পূর্ণ XML ফাইল এবং সম্পূর্ণ ডেটাসেট বান্ডেল পর্যালোচনার জন্য উপলব্ধ।
ওভারভিউ
আমাদের ডেটাসেট তৈরি করা শুরু করার আগে, এখানে একটি DSPL ডেটাসেটে কী রয়েছে তার একটি উচ্চ-স্তরের ওভারভিউ দেওয়া হল:
- সাধারণ তথ্য: ডেটাসেট সম্পর্কে
- ধারণা: ডেটাসেটে প্রদর্শিত "জিনিস" এর সংজ্ঞা (যেমন, দেশ, বেকারত্বের হার, লিঙ্গ, ইত্যাদি)
- স্লাইস: ধারণার সমন্বয় যার জন্য ডেটা আছে
- টেবিল: ধারণা এবং স্লাইস জন্য ডেটা। কনসেপ্ট টেবিল গণনা ধারণ করে এবং স্লাইস টেবিলে পরিসংখ্যানগত তথ্য থাকে
- বিষয়: লেবেলিংয়ের মাধ্যমে ডেটাসেটের ধারণাগুলিকে একটি অর্থপূর্ণ শ্রেণিবিন্যাসে সংগঠিত করতে ব্যবহৃত হয়
এই বরং বিমূর্ত ধারণাগুলিকে ব্যাখ্যা করার জন্য, এই টিউটোরিয়াল জুড়ে ব্যবহৃত ডেটাসেট (ডামি ডেটা সহ) বিবেচনা করুন: জনসংখ্যা এবং বেকারত্বের জন্য পরিসংখ্যানগত সময় সিরিজ, দেশ, মার্কিন রাজ্য এবং লিঙ্গের বিভিন্ন সংমিশ্রণ দ্বারা একত্রিত।
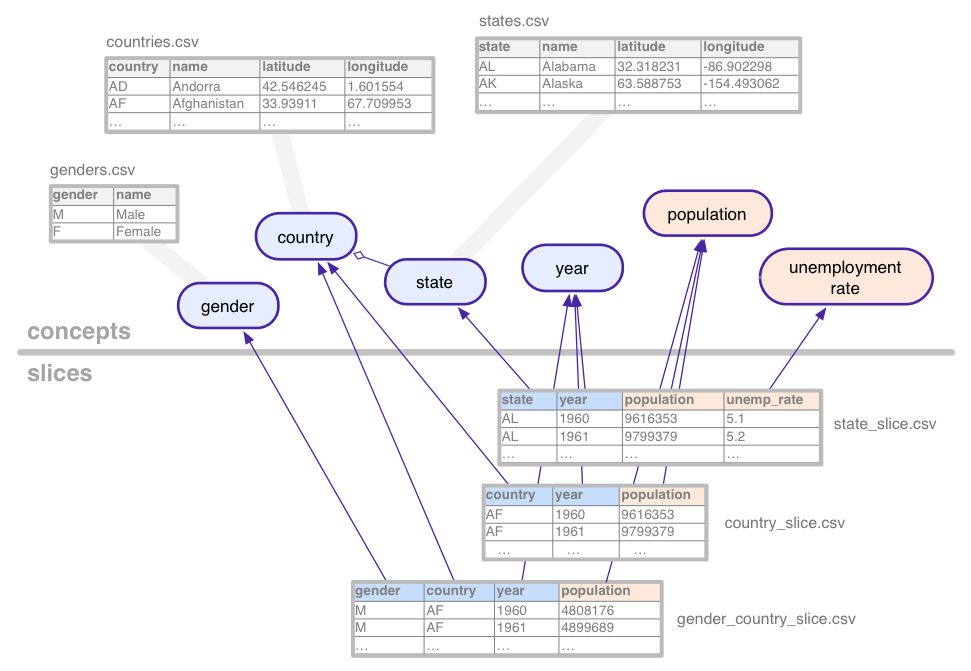
এই উদাহরণ ডেটাসেট নিম্নলিখিত ধারণাগুলি সংজ্ঞায়িত করে:
- দেশ
- লিঙ্গ
- জনসংখ্যা
- রাষ্ট্র
- বেকারত্বের হার
- বছর
যে ধারণাগুলি শ্রেণীবদ্ধ, যেমন রাষ্ট্র, ধারণা টেবিলের সাথে যুক্ত, যা তাদের সমস্ত সম্ভাব্য মান গণনা করে (ক্যালিফোর্নিয়া, অ্যারিজোনা, ইত্যাদি)। ধারণাগুলির বৈশিষ্ট্যগুলির জন্য অতিরিক্ত কলাম থাকতে পারে যেমন নাম বা একটি রাষ্ট্রের দেশ।
স্লাইসগুলি ধারণাগুলির প্রতিটি সংমিশ্রণকে সংজ্ঞায়িত করে যার জন্য ডেটাসেটে পরিসংখ্যানগত ডেটা রয়েছে৷ একটি স্লাইসে মাত্রা এবং মেট্রিক্স থাকে। উপরের ছবিতে, মাত্রাগুলি নীল এবং মেট্রিকগুলি কমলা৷ এই উদাহরণে, gender_country_slice এ মেট্রিক population এবং country , year এবং gender মাত্রার ডেটা রয়েছে। country_slice নামক আরেকটি স্লাইস দেশগুলির জন্য মোট বার্ষিক জনসংখ্যার সংখ্যা (মেট্রিক) দেয়।
মাত্রা এবং মেট্রিক্স ছাড়াও, স্লাইসগুলি সারণীগুলিকেও উল্লেখ করে, যা প্রকৃত ডেটা ধারণ করে।
আসুন এখন DSPL-এ এমন একটি ডেটাসেট তৈরির মাধ্যমে ধাপে ধাপে চলুন।
ডেটাসেট তথ্য
শুরু করার জন্য, আমাদের ডেটাসেটের জন্য একটি XML ফাইল তৈরি করতে হবে। আমাদের উদাহরণ ডেটাসেটের জন্য এখানে একটি DSPL বর্ণনার শুরু:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
ডেটাসেটের বিবরণ একটি শীর্ষ-স্তরের <dspl> উপাদান দিয়ে শুরু হয়। targetNamespace অ্যাট্রিবিউটে একটি URI রয়েছে যা এই ডেটাসেটটিকে অনন্যভাবে সনাক্ত করে। ডেটাসেট প্রকাশ করার সময় ডেটাসেটের নামস্থান বিশেষভাবে গুরুত্বপূর্ণ, কারণ এটি আপনার ডেটাসেটের বিশ্বব্যাপী শনাক্তকারী এবং অন্যদের এটি উল্লেখ করার উপায় হবে।
লক্ষ্য করুন যে targetNamespace বৈশিষ্ট্যটি বাদ দেওয়া হতে পারে। এই ক্ষেত্রে একটি অনন্য নামস্থান স্বয়ংক্রিয়ভাবে তৈরি হয় যখন ডেটাসেট আমদানি করা হয়।
অন্যান্য ডেটাসেট থেকে তথ্য ব্যবহার করা
ডেটাসেটগুলি সেই ডেটাসেটগুলি আমদানি করে অন্যান্য ডেটাসেট থেকে সংজ্ঞা এবং ডেটা পুনরায় ব্যবহার করতে পারে। প্রতিটি <import> উপাদান অন্য ডেটাসেটের নামস্থান নির্দিষ্ট করে যা এই ডেটাসেটটি উল্লেখ করবে।
আমাদের উদাহরণ ডেটাসেটে, আমাদের http://www.google.com/publicdata/dataset/google/quantity থেকে কিছু সংজ্ঞা প্রয়োজন হবে (Google দ্বারা তৈরি একটি ডেটাসেট যাতে সাংখ্যিক পরিমাণ সংজ্ঞায়িত করার জন্য উপযোগী ধারণা রয়েছে), এবং সময় থেকে , সত্তা , এবং জিও ডেটাসেট, যা যথাক্রমে সময়, সত্তা এবং ভূগোল সম্পর্কিত সংজ্ঞা প্রদান করে।
উপরের <dspl> উপাদানটি প্রতিটি আমদানি করা ডেটাসেটের জন্য একটি নামস্থান উপসর্গ ঘোষণা প্রদান করে (যেমন, xmlns:time="http://..." )। সংক্ষিপ্ত উপায়ে অন্যান্য ডেটাসেট থেকে উপাদানগুলিকে উল্লেখ করার জন্য উপসর্গ ঘোষণার প্রয়োজন। উদাহরণস্বরূপ, time:year আমদানি করা ডেটাসেটে year সংজ্ঞা উল্লেখ করে যার নামস্থান উপসর্গ time সাথে যুক্ত।
ডেটাসেট এবং প্রদানকারীর তথ্য
<info> উপাদানটিতে ডেটাসেট সম্পর্কে সাধারণ তথ্য রয়েছে: নাম, বিবরণ এবং একটি URL যেখানে আরও তথ্য পাওয়া যেতে পারে।
<provider> উপাদানটিতে ডেটাসেটের প্রদানকারী সম্পর্কে তথ্য রয়েছে: এর নাম এবং একটি URL যেখানে আরও তথ্য পাওয়া যেতে পারে (সাধারণত ডেটা প্রদানকারীর হোম পেজ)।
ধারণা সংজ্ঞায়িত
এখন যেহেতু আমরা ডেটাসেট সম্পর্কে কিছু সাধারণ তথ্য প্রদান করেছি, আমরা এর বিষয়বস্তু সংজ্ঞায়িত করতে প্রস্তুত। আমাদের পরবর্তী লক্ষ্য হল বিগত 50 বছর ধরে দেশগুলির জনসংখ্যার পরিসংখ্যান যোগ করা।
আমাদের যা করতে হবে তা হল জনসংখ্যা, দেশ এবং বছরের ধারণার জন্য কিছু সংজ্ঞা প্রদান করা। DSPL-এ, এই সংজ্ঞাগুলিকে বলা হয় ধারণা ।
একটি ধারণা হল এক ধরণের ডেটার সংজ্ঞা যা একটি ডেটাসেটে প্রদর্শিত হয়। একটি প্রদত্ত ধারণার সাথে সম্পর্কিত ডেটা মানগুলিকে সেই ধারণার দৃষ্টান্ত বলা হয়।
জনসংখ্যা
এর জনসংখ্যা ধারণা সংজ্ঞায়িত সঙ্গে শুরু করা যাক. একটি DSPL নথিতে, ধারণাগুলিকে একটি <concepts> উপাদানে সংজ্ঞায়িত করা হয় যা ডেটাসেট এবং প্রদানকারীর তথ্যের ঠিক পরে আসে।
এখানে একটি জনসংখ্যার ধারণা রয়েছে যেকোন ধারণার জন্য প্রয়োজনীয় ন্যূনতম তথ্য সহ: id (একটি অনন্য শনাক্তকারী), name এবং type ।
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
এই নমুনা কিভাবে কাজ করে তা এখানে:
- প্রতিটি ধারণাকে অবশ্যই একটি
idপ্রদান করতে হবে যা ডেটাসেটের মধ্যে ধারণাটিকে অনন্যভাবে সনাক্ত করে। এর মানে হল যে একই ডেটাসেটে সংজ্ঞায়িত কোন দুটি ধারণা একই আইডি থাকতে পারে না। - ঠিক যেমন ডেটাসেট এবং এর প্রদানকারীর জন্য,
<info>উপাদানগুলি ধারণা সম্পর্কে পাঠ্য তথ্য প্রদান করে, যেমন এর নাম এবং বিবরণ। -
<type>উপাদানটি ধারণার উদাহরণের জন্য ডেটা টাইপ নির্দিষ্ট করে (অন্য কথায়, এর "মান")। এই উদাহরণে,populationধরনটিinteger। DSPL নিম্নলিখিত ডেটা প্রকারগুলিকে সমর্থন করে:-
string -
integer -
float -
boolean -
date
-
দেশ
এখন দেশের ধারণার সংজ্ঞা লিখি:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
দেশের ধারণার সংজ্ঞা পূর্ববর্তীটির মতো শুরু হয়, একটি id , info এবং একটি type দিয়ে।
ধারণার মান
দেশগুলির মতো শ্রেণীবদ্ধ ধারণাগুলির সমস্ত সম্ভাব্য উদাহরণের একটি গণনা রয়েছে। অন্য কথায়, আপনি রেফারেন্স করা যেতে পারে এমন সমস্ত সম্ভাব্য দেশের তালিকা করতে পারেন। কিন্তু এটি করার জন্য, প্রতিটি দেশের একটি অনন্য শনাক্তকারী প্রয়োজন। এই উদাহরণটি দেশগুলিকে চিহ্নিত করতে ISO দেশের কোড ব্যবহার করে; এই কোড টাইপ string হয়.
এই উদাহরণে, আপনাকে ISO কোড ব্যবহার করতে হবে না; আপনি শুধু দেশের নাম ব্যবহার করতে পারেন. নামগুলি, তবে, ভাষা অনুসারে আলাদা, সময়ের সাথে সাথে পরিবর্তিত হতে পারে এবং সবসময় ডেটাসেট জুড়ে ধারাবাহিকভাবে ব্যবহৃত হয় না। দেশগুলির জন্য এবং সাধারণভাবে শ্রেণীবদ্ধ ধারণাগুলির জন্য, সংক্ষিপ্ত, স্থিতিশীল, সাধারণত ব্যবহৃত এবং ভাষা-স্বাধীন শনাক্তকারী (যদি তারা বিদ্যমান থাকে) বাছাই করা একটি ভাল অভ্যাস।
ধারণা বৈশিষ্ট্য
এর id ছাড়াও, দেশের ধারণাটিতে একটি <property> উপাদান রয়েছে যা দেশের নাম নির্দিষ্ট করে। অন্য কথায়, দেশের নাম ("আয়ারল্যান্ড") id আইডি সহ দেশের একটি সম্পত্তি । বৈশিষ্ট্যগুলি হল কীভাবে DSPL একটি ধারণার উদাহরণ সম্পর্কে অতিরিক্ত কাঠামোগত তথ্য সরবরাহ করে।
ধারণার মতোই, বৈশিষ্ট্যগুলির একটি id , info এবং type রয়েছে।
ধারণা তথ্য
অবশেষে, দেশের ধারণার একটি <table> উপাদান আছে। এই উপাদানটি একটি টেবিল উল্লেখ করে যা সমস্ত দেশের তালিকা গণনা করে।
টেবিল ব্যবহার করা কিছু ধারণার জন্য অর্থপূর্ণ, কিন্তু অন্যদের জন্য নয়। উদাহরণস্বরূপ, ধারণা জনসংখ্যার জন্য সমস্ত সম্ভাব্য মান গণনা করার অর্থ নেই। যাইহোক, যদি আপনি একটি ধারণার জন্য একটি সারণী উল্লেখ করেন, তাহলে সেই সারণীতে অবশ্যই ধারণার সমস্ত দৃষ্টান্ত থাকতে হবে-উদাহরণস্বরূপ, এটি প্রতিটি দেশকে তালিকাভুক্ত করতে হবে, শুধুমাত্র কয়েকটি নমুনা নয়।
ডেটাসেটটি নিম্নরূপ countries_table সারণীকে সংজ্ঞায়িত করে:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
দেশ টেবিলটি টেবিলের কলাম এবং তাদের প্রকারগুলি নির্দিষ্ট করে এবং একটি CSV ফাইল উল্লেখ করে যাতে ডেটা রয়েছে৷ এই CSV হয় ডেটাসেট XML এর সাথে বান্ডেল এবং আপলোড করা যেতে পারে বা HTTP, HTTPS বা FTP এর মাধ্যমে দূরবর্তীভাবে অ্যাক্সেস করা যেতে পারে। পরবর্তী ক্ষেত্রে, আপনি countries.csv একটি URL দিয়ে প্রতিস্থাপন করবেন, উদাহরণস্বরূপ http://www.myserver.com/mydata/countries.csv ।
যেখানেই এটি সংরক্ষণ করা হোক না কেন, CSV ফাইলটি দেখতে এরকম দেখাচ্ছে:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
টেবিলের প্রথম সারিটি কলাম আইডিগুলিকে তালিকাভুক্ত করে, যেমনটি DSPL table সংজ্ঞায় উল্লেখ করা হয়েছে। নিম্নলিখিত সারিগুলির প্রতিটি দেশের ধারণার একটি উদাহরণের সাথে মিলে যায়৷ যদি ধারণাটির একটি টেবিল থাকে, তাহলে টেবিলটিতে অবশ্যই ধারণার সমস্ত দৃষ্টান্ত থাকতে হবে- এই ক্ষেত্রে, এটি অবশ্যই সমস্ত দেশকে তালিকাভুক্ত করতে হবে।
কলামগুলি তাদের আইডির উপর ভিত্তি করে দেশের ধারণা এবং এর বৈশিষ্ট্যগুলির সাথে ম্যাপ করা হয়৷ প্রথম কলামের আইডি, country , ধারণা আইডির সাথে মেলে। এর মানে হল এই কলামে দেশের ধারণা দ্বারা সংজ্ঞায়িত অনন্য দেশ শনাক্তকারী রয়েছে৷ পরবর্তী কলামটি দেশের ধারণার name সম্পত্তির সাথে মিলে যায়। এই কলামের মানগুলি name সম্পত্তির মানগুলির সাথে মেলে৷
ধারণা টেবিলের জন্য CSV ডেটার জন্য কয়েকটি প্রয়োজনীয়তা রয়েছে:
- ডেটা ফাইলের প্রথম লাইনের কলামের শিরোনামগুলি অবশ্যই ধারণা
idএবং ধারণার সম্পত্তিidসাথে হুবহু মিলে যাবে যার সাথে ডেটা যুক্ত (যদিও ক্রম পরিবর্তিত হতে পারে)৷ - প্রতিটি সারিতে অবশ্যই ধারণার বৈশিষ্ট্যের সংখ্যার সমান সংখ্যক উপাদান থাকতে হবে (মান খালি থাকলেও)।
- ধারণার
idক্ষেত্রের প্রতিটি মান (এখানে, দেশের কোড) অবশ্যই অনন্য এবং খালি নয় (একটি খালি ক্ষেত্র শূন্য বা শুধুমাত্র সাদা স্থানের অক্ষর সহ একটি)। - বৈশিষ্ট্যের মানগুলি যেগুলি অন্যান্য ধারণার উল্লেখ করে সেগুলি অবশ্যই খালি হতে হবে বা উল্লেখিত ধারণার একটি বৈধ মান হতে হবে৷
- যে মানগুলিতে কমা, ডবল কোট বা নিউলাইন অক্ষর রয়েছে সেগুলি অবশ্যই ডবল কোটগুলিতে সম্পূর্ণরূপে আবদ্ধ হতে হবে।
- একটি মানের ভিতরে যেকোনো আক্ষরিক দ্বিগুণ উদ্ধৃতি অক্ষর অবিলম্বে অন্য একটি দ্বিগুণ উদ্ধৃতির আগে থাকতে হবে।
বছর
আমাদের দেশের জনসংখ্যার তথ্যের জন্য আমাদের সর্বশেষ ধারণাটি বছরের প্রতিনিধিত্ব করার একটি ধারণা। একটি নতুন ধারণা সংজ্ঞায়িত করার পরিবর্তে, আমরা আমদানি করা ডেটাসেটের একটি থেকে বছরের ধারণা ব্যবহার করব: "http://www.google.com/publicdata/dataset/google/time"। এটি করার জন্য, আমাদের এটিকে time:year হিসাবে উল্লেখ করতে হবে, যেখানে time উল্লেখ করা ডেটাসেটকে উপস্থাপন করে এবং year ধারণাটিকে চিহ্নিত করে।
ক্যানোনিকাল ধারণা
time:year হল Google দ্বারা সংজ্ঞায়িত ক্যানোনিকাল ধারণাগুলির একটি ছোট সেটের অংশ। ক্যানোনিকাল ধারণাগুলি সময়, ভূগোল, সংখ্যাগত পরিমাণ, একক ইত্যাদির জন্য মৌলিক সংজ্ঞা প্রদান করে।
প্রকৃতপক্ষে, উপরে সংজ্ঞায়িত দেশের ধারণাটি একটি আদর্শ ধারণা হিসাবে বিদ্যমান। আমরা এখানে শুধুমাত্র দৃষ্টান্তের উদ্দেশ্যে এটি তৈরি করেছি। যখনই সম্ভব, আপনার ডেটাসেটে ক্যানোনিকাল ধারণাগুলি ব্যবহার করা উচিত, হয় সরাসরি বা সেগুলি প্রসারিত করে (নীচে এক্সটেনশনে আরও বেশি)। ক্যানোনিকাল ধারণাগুলি আপনার ডেটাকে অন্যান্য ডেটাসেটের সাথে তুলনীয় করে তোলে এবং পাবলিক ডেটা এক্সপ্লোরারে আপনার ডেটাসেটের জন্য বৈশিষ্ট্যগুলি সক্ষম করে৷ উদাহরণস্বরূপ, সময়ের সাথে সাথে ডেটা অ্যানিমেটিং করা বা মানচিত্রে ভৌগলিক ডেটা দেখানো যথাক্রমে time এবং geo প্রাকৃতিক ধারণাগুলি ব্যবহার করার উপর নির্ভর করে।
প্রথম স্লাইস
এখন যেহেতু আমাদের কাছে জনসংখ্যা, দেশ এবং বছরের জন্য ধারণা আছে, এখন সেগুলিকে একত্রিত করার সময়!
এর জন্য, আমাদের একটি স্লাইস তৈরি করতে হবে যা তাদের একত্রিত করে। DSPL-এ, একটি স্লাইস হল ধারণাগুলির একটি সমন্বয় যার জন্য ডেটা বিদ্যমান।
কেন শুধু ডান কলাম দিয়ে একটি টেবিল তৈরি করবেন না? কারণ স্লাইসগুলি ডেটাসেটের ধারণার পরিপ্রেক্ষিতে তথ্য ক্যাপচার করে। আমরা আমাদের ডেটাসেটের আরও টুকরো তৈরি করার সাথে সাথে এটি আরও পরিষ্কার হয়ে যাবে।
DSPL ফাইলে একটি <slices> উপাদানের অধীনে স্লাইস প্রদর্শিত হয়, যা concepts বিভাগের ঠিক পরে উপস্থিত হওয়া আবশ্যক।
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices> ধারণার মতো, প্রতিটি স্লাইসের একটি id ( countries_slice ) থাকে যা ডেটাসেটের মধ্যে স্লাইসটিকে অনন্যভাবে সনাক্ত করে।
একটি স্লাইসে দুটি ধরণের ধারণার রেফারেন্স রয়েছে: মাত্রা এবং মেট্রিক্স । মেট্রিক্সের মানগুলি মাত্রার মানের সাথে পরিবর্তিত হয়। এখানে, population মান (মেট্রিক) country এবং year মাত্রা অনুসারে পরিবর্তিত হয়।
ধারণার মতো, স্লাইসগুলি একটি টেবিলের একটি রেফারেন্স অন্তর্ভুক্ত করে যাতে স্লাইসের ডেটা থাকে। উল্লেখিত সারণীতে স্লাইসের প্রতিটি মাত্রা এবং মেট্রিকের জন্য একটি কলাম থাকতে হবে। ঠিক যেমন ধারণার জন্য, স্লাইসের মাত্রা এবং মেট্রিক্স একই আইডি দিয়ে টেবিলের কলামে ম্যাপ করা হয়।
স্লাইস টেবিল
আমাদের জনসংখ্যা স্লাইসের জন্য টেবিলটি DSPL ফাইলের tables বিভাগে প্রদর্শিত হয়:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
নোট করুন যে year কলামটি একটি format বৈশিষ্ট্যের সাথে আসে যা বছরগুলি কীভাবে বিন্যাস করা হয় তা নির্দিষ্ট করে। সমর্থিত তারিখ বিন্যাসগুলি জোডা ডেটটাইম বিন্যাস দ্বারা সংজ্ঞায়িত করা হয়।
countries_slice টেবিলটি টেবিলের কলাম এবং তাদের প্রকারগুলি নির্দিষ্ট করে এবং একটি CSV ফাইলের দিকে নির্দেশ করে যাতে ডেটা রয়েছে৷ CSV ফাইলটি দেখতে এইরকম:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
ডেটা টেবিলের প্রতিটি সারিতে population মেট্রিকের সংশ্লিষ্ট মান সহ country এবং year মাত্রার একটি অনন্য সমন্বয় রয়েছে (উদাহরণস্বরূপ, 1960 সালে আফগানিস্তানের জনসংখ্যা - মেট্রিক - মাত্রা )।
মনে রাখবেন যে country কলামের মানগুলি country ধারণার মান/শনাক্তকারীর সাথে মেলে, যা দেশের ISO 3166 2-অক্ষরের কোড।
একটি স্লাইসের জন্য CSV ডেটা অবশ্যই নিম্নলিখিত সীমাবদ্ধতাগুলি পূরণ করবে:
- একটি মাত্রা ক্ষেত্রের প্রতিটি মান (যেমন
countryএবংyear) অবশ্যই খালি নয়৷ মেট্রিক ক্ষেত্রের মান (যেমনpopulation) খালি হতে পারে। একটি খালি মান কোন অক্ষর দ্বারা প্রতিনিধিত্ব করা হয়. - একটি ধারণার উল্লেখ করে এমন একটি মাত্রা ক্ষেত্রের প্রতিটি মান অবশ্যই সেই ধারণার ডেটাতে উপস্থিত থাকতে হবে। উদাহরণস্বরূপ, মান
AFঅবশ্যইcountryধারণা ডেটা টেবিলে উপস্থিত থাকতে হবে। - মাত্রা মানের প্রতিটি অনন্য সমন্বয়, যেমন
AF, 2000, শুধুমাত্র একবার ঘটতে পারে। - ডেটা অ-টাইম ডাইমেনশন কলাম দ্বারা বাছাই করা উচিত (যেকোন ক্রমে), এবং তারপরে, ঐচ্ছিকভাবে, অন্য যে কোনও কলাম দ্বারা। সুতরাং, উদাহরণস্বরূপ, কলাম
[date, dimension1, dimension2, metric1, metric2]সহ একটি সারণীতে, আপনিdimension1, তারপরেdimension2, তারপরdate, তবেdateএবং তারপরে মাত্রা অনুসারে সাজাতে পারেন৷
সারাংশ
এই মুহুর্তে, দেশের জনসংখ্যার তথ্য বর্ণনা করার জন্য আমাদের DSPL-এ যথেষ্ট আছে। সংক্ষেপে, আমাদের যা করতে হয়েছিল তা হল:
- DSPL হেডার এবং ডেটাসেট এবং এর প্রদানকারীর বিবরণ তৈরি করুন
- জনসংখ্যার জন্য একটি এবং দেশের জন্য আরেকটি ধারণা তৈরি করুন, একটি csv ফাইলের সাথে সমস্ত দেশ এবং তাদের নাম গণনা করুন৷
- Google থেকে আমদানি করা সময়-ডেটাসেটে ইতিমধ্যে-সংজ্ঞায়িত বছরের ধারণাটি উল্লেখ করে সময়ের সাথে সাথে দেশগুলির জন্য আমাদের জনসংখ্যার সংখ্যা সহ একটি স্লাইস তৈরি করুন।
এই টিউটোরিয়ালের বাকি অংশে, আমরা আমাদের ডেটাসেটকে আরও সমৃদ্ধ করে তুলব আরও স্লাইসে আরও মাত্রা যোগ করে, সেইসাথে বিষয় অনুসারে গোষ্ঠীবদ্ধ আরও মেট্রিক্স।
একটি মাত্রা যোগ করা: মার্কিন যুক্তরাষ্ট্র
এখন মার্কিন যুক্তরাষ্ট্রের রাজ্যগুলির জন্য জনসংখ্যার ডেটা যোগ করে আমাদের ডেটাসেটকে সমৃদ্ধ করা যাক৷ আমাদের প্রথমে রাজ্যগুলির জন্য একটি ধারণা সংজ্ঞায়িত করতে হবে। এটি দেখতে অনেকটা দেশের ধারণার মতো যা আমরা আগে সংজ্ঞায়িত করেছি।
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>ধারণা এক্সটেনশন এবং সম্পত্তি রেফারেন্স
রাষ্ট্রীয় ধারণা ডিএসপিএল-এর বেশ কয়েকটি নতুন বৈশিষ্ট্য প্রবর্তন করে।
প্রথমত, রাজ্য আরেকটি ধারণাকে প্রসারিত করে , geo:location (আমরা আমাদের ডেটাসেটের শুরুতে আমদানি করেছি বহিরাগত জিও ডেটাসেটে সংজ্ঞায়িত)। শব্দার্থগতভাবে, এর অর্থ হল state হল এক ধরনের geo:location । একটি ফলাফল হল যে এটি geo:location এর সমস্ত বৈশিষ্ট্য এবং বৈশিষ্ট্য উত্তরাধিকার সূত্রে প্রাপ্ত হয়। বিশেষ করে, অবস্থান latitude এবং longitude বৈশিষ্ট্য নির্ধারণ করে; পূর্বের ধারণাটি প্রসারিত করে, এই বৈশিষ্ট্যগুলি রাষ্ট্রেও প্রয়োগ করা হয়। অধিকন্তু, যেহেতু অবস্থান entity:entity থেকে উত্তরাধিকারসূত্রে পাওয়া যায়, তাই রাজ্যও name , description এবং info_url সহ পরবর্তী সমস্ত বৈশিষ্ট্য পায়।
দ্রষ্টব্য: পূর্বে সংজ্ঞায়িত দেশের ধারণাটি প্রযুক্তিগতভাবে, geo:location থেকেও প্রসারিত হওয়া উচিত। সরলতার জন্য এই পয়েন্টটি আগে বাদ দেওয়া হয়েছিল; আমরা দেশের উত্তরাধিকারে অবস্থান অন্তর্ভুক্ত করেছি, তবে, চূড়ান্ত XML ফাইলে ।
দ্রষ্টব্য: আপনি অন্যান্য ডেটাসেট দ্বারা সংজ্ঞায়িত তথ্য পুনঃব্যবহার করতে আপনার নিজস্ব ডেটাসেটে extends নির্মাণ ব্যবহার করতে পারেন। extends ব্যবহার করার জন্য প্রয়োজন যে আপনার ধারণার সমস্ত দৃষ্টান্তগুলি আপনি যে ধারণাটি প্রসারিত করছেন তার বৈধ উদাহরণ। এক্সটেনশনগুলি আপনাকে অতিরিক্ত বৈশিষ্ট্য এবং গুণাবলী যোগ করতে দেয় এবং দৃষ্টান্তের সেটটিকে বর্ধিত ধারণার উদাহরণগুলির একটি উপসেটে সীমাবদ্ধ করতে দেয়।
উত্তরাধিকারের পাশাপাশি, রাষ্ট্রীয় সম্পত্তি ধারণার রেফারেন্সের ধারণাও প্রবর্তন করে। বিশেষ করে, রাষ্ট্রীয় ধারণার country নামক একটি সম্পত্তি রয়েছে, যা আমরা উপরে তৈরি করা দেশের ধারণাকে উল্লেখ করে। এটি একটি concept বৈশিষ্ট্য ব্যবহার করে করা হয়। মনে রাখবেন যে এই সম্পত্তি একটি আইডি প্রদান করে না, শুধুমাত্র একটি ধারণা রেফারেন্স। এটি উল্লেখিত ধারণার আইডি (অর্থাৎ, এই উদাহরণে country ) হিসাবে একই মান সহ একটি আইডি তৈরি করার সমতুল্য। রেফারেন্সে isParent="true" অ্যাট্রিবিউট দিয়ে রাজ্য এবং কাউন্টির মধ্যে শ্রেণীবদ্ধ সম্পর্ক ধরা হয়। সাধারণভাবে, অনুক্রমিক সম্পর্কের সাথে মাত্রাগুলি, যেমন ভৌগোলিক, এইভাবে উপস্থাপন করা উচিত, চাইল্ড কনসেপ্টের এমন একটি সম্পত্তি রয়েছে যা isParent অ্যাট্রিবিউট ব্যবহার করে পিতামাতার ধারণাকে উল্লেখ করে।
রাজ্যের জন্য টেবিল সংজ্ঞা এই মত দেখায়:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
দেশের কলাম সব রাজ্যের জন্য একটি ধ্রুবক মান আছে. ডিএসপিএল-এ এটি নির্দিষ্ট করা ডেটাতে প্রতিটি রাজ্যের জন্য সেই মানটি পুনরাবৃত্তি করা এড়িয়ে যায়। এছাড়াও মনে রাখবেন যে আমরা name , latitude এবং longitude জন্য কলামগুলি অন্তর্ভুক্ত করেছি যেহেতু রাজ্য এই বৈশিষ্ট্যগুলি geo:location থেকে উত্তরাধিকারসূত্রে পেয়েছে৷ অন্যদিকে, কিছু উত্তরাধিকারসূত্রে প্রাপ্ত বৈশিষ্ট্যের (যেমন, description ) কলাম নেই; এটি ঠিক আছে- যদি একটি ধারণার সংজ্ঞা টেবিল থেকে একটি সম্পত্তি বাদ দেওয়া হয়, তাহলে ধারণার প্রতিটি উদাহরণের জন্য এর মানটি অনির্ধারিত বলে ধরে নেওয়া হয়।
CSV ফাইলটি দেখতে এইরকম:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
যেহেতু আমাদের কাছে ইতিমধ্যেই জনসংখ্যা এবং বছরের ধারণা রয়েছে, তাই আমরা রাজ্যের জনসংখ্যার জন্য একটি নতুন স্লাইস সংজ্ঞায়িত করতে সেগুলি পুনরায় ব্যবহার করতে পারি।
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>ডেটা টেবিল সংজ্ঞা এই মত দেখায়:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
এবং CSV ফাইলটি দেখতে এইরকম:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
অপেক্ষা করুন, কেন আমরা আগেরটির সাথে আরেকটি মাত্রা যোগ করার পরিবর্তে একটি নতুন স্লাইস তৈরি করেছি?
রাষ্ট্র এবং দেশ উভয়ের জন্য মাত্রা সহ একটি স্লাইস সঠিক হবে না, কারণ কিছু সারি দেশের ডেটার জন্য এবং কিছু সারি রাজ্য ডেটার জন্য হবে৷ টেবিলে কিছু মাত্রার জন্য "গর্ত" থাকবে, যা অনুমোদিত নয় (মনে রাখবেন যে অনুপস্থিত মানগুলি শুধুমাত্র মেট্রিক্সের জন্য অনুমোদিত এবং মাত্রা নয়)।
মাত্রা স্লাইসের জন্য একটি "প্রাথমিক কী" হিসাবে কাজ করে। এর মানে হল যে প্রতিটি ডেটা সারিতে সমস্ত মাত্রার মান থাকতে হবে এবং কোনও দুটি ডেটা সারিতে সমস্ত মাত্রার জন্য একই মান থাকতে পারে না।
একটি মেট্রিক যোগ করা: বেকারত্বের হার
এখন আমাদের ডেটাসেটে আরেকটি মেট্রিক যোগ করা যাক:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
এই মেট্রিকের info বিভাগে একটি নাম, বিবরণ এবং একটি URL রয়েছে (ইউএস ব্যুরো অফ লেবার স্ট্যাটিস্টিক্সের সাথে লিঙ্ক করা)।
এই ধারণাটি quantity:rate ক্যানোনিকাল ধারণাকেও প্রসারিত করে। পরিমাণ ডেটাসেট সংখ্যাসূচক পরিমাণের প্রতিনিধিত্ব করার জন্য মূল ধারণাগুলিকে সংজ্ঞায়িত করে। আপনার ডেটাসেটে, আপনার উপযুক্ত পরিমাণের ধারণা প্রসারিত করে আপনার সংখ্যাসূচক ধারণা তৈরি করা উচিত। সুতরাং, উপরে সংজ্ঞায়িত population ধারণাটি, প্রযুক্তিগতভাবে, quantity:amount থেকে প্রসারিত হওয়া উচিত।
ধারণা বৈশিষ্ট্য
এই ধারণাটি একটি বৈশিষ্ট্যের গঠনও প্রবর্তন করে। এই উদাহরণে, একটি বৈশিষ্ট্য বলতে ব্যবহৃত হয় যে unemployment_rate একটি শতাংশ। is_percentage বৈশিষ্ট্যটি quantity:rate ধারণা থেকে উত্তরাধিকারসূত্রে প্রাপ্ত হয় যা এই ধারণাটি প্রসারিত করে। এই তথ্যটি পাবলিক ডেটা এক্সপ্লোরার দ্বারা ডেটা ভিজ্যুয়ালাইজ করার সময় শতাংশ চিহ্ন দেখানোর জন্য ব্যবহার করা হয়।
বৈশিষ্ট্যগুলি একটি ধারণার সাথে কী/মান জোড়া সংযুক্ত করার জন্য একটি সাধারণ প্রক্রিয়া প্রদান করে (বৈশিষ্ট্যের সাথে বিপরীতে, যা একটি ধারণার উদাহরণের সাথে অতিরিক্ত মান যুক্ত করে)। ধারণা এবং বৈশিষ্ট্যের মতো, বৈশিষ্ট্যগুলির একটি id , info এবং একটি type রয়েছে। বৈশিষ্ট্যের মতো, তারা অন্যান্য ধারণার উল্লেখ করতে পারে।
গুণাবলী শুধুমাত্র পূর্বনির্ধারিত সাধারণ জিনিসের জন্য নয়, যেমন সংখ্যাগত বৈশিষ্ট্য। আপনি আপনার ধারণার জন্য আপনার নিজস্ব গুণাবলী সংজ্ঞায়িত করতে পারেন।
মার্কিন যুক্তরাষ্ট্রের জন্য বেকারত্বের হার ডেটা যোগ করা হচ্ছে
আমরা এখন মার্কিন রাজ্যগুলির জন্য বেকারত্বের হার ডেটা যোগ করতে প্রস্তুত৷ যেহেতু বেকারত্বের হার একটি মেট্রিক এবং আমাদের কাছে ইতিমধ্যেই রাজ্যগুলির জনসংখ্যার ডেটা রয়েছে, আমরা এটিকে রাজ্য এবং বছরের মাত্রার জন্য ইতিমধ্যে তৈরি করা স্লাইসে যোগ করতে পারি:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... এবং টেবিল সংজ্ঞায় অন্য কলাম যোগ করুন:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... এবং CSV ফাইলে:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
আমরা আগে বলেছি যে প্রতিটি স্লাইসের জন্য, মাত্রাগুলি স্লাইসের জন্য একটি প্রাথমিক কী গঠন করে। উপরন্তু, প্রতিটি ডেটাসেটে মাত্রার একটি প্রদত্ত সংমিশ্রণের জন্য শুধুমাত্র একটি স্লাইস থাকতে পারে। এই মাত্রাগুলির জন্য উপলব্ধ সমস্ত মেট্রিকগুলি অবশ্যই একই স্লাইসের অন্তর্গত।
আরও মাত্রা: লিঙ্গ অনুসারে জনসংখ্যা ভাঙ্গন
আসুন দেশগুলির জন্য লিঙ্গ অনুসারে জনসংখ্যার ভাঙ্গন সহ আমাদের ডেটাসেটকে সমৃদ্ধ করি। এখন পর্যন্ত, আপনি ড্রিলটি জানতে শুরু করেছেন... আমাদের প্রথমে লিঙ্গের জন্য একটি ধারণা যোগ করতে হবে:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
লিঙ্গ ধারণা info বিভাগে একটি pluralName রয়েছে, যা লিঙ্গ ধারণার একাধিক উদাহরণ উল্লেখ করতে ব্যবহৃত পাঠ্য সরবরাহ করে। info বিভাগে একটি totalName অন্তর্ভুক্ত রয়েছে, যা সম্পূর্ণরূপে লিঙ্গ ধারণার সমস্ত উদাহরণ উল্লেখ করতে ব্যবহৃত পাঠ্য সরবরাহ করে। এই দুটিই লিঙ্গ ধারণা সম্পর্কিত তথ্য প্রদর্শন করতে পাবলিক ডেটা এক্সপ্লোরার দ্বারা ব্যবহৃত হয়। সাধারণভাবে, আপনি তাদের ধারণার জন্য প্রদান করা উচিত যা মাত্রা হিসাবে ব্যবহার করা যেতে পারে।
উল্লেখ্য যে লিঙ্গ ধারণাটি entity:entity থেকেও প্রসারিত। মাত্রা হিসাবে ব্যবহৃত ধারণাগুলির জন্য এটি একটি ভাল অনুশীলন, কারণ এটি আপনাকে বিভিন্ন ধারণার উদাহরণের জন্য কাস্টম নাম, URL এবং রঙ যোগ করতে দেয়।
লিঙ্গ ধারণাটি genders_table টেবিলকে বোঝায়, যেখানে লিঙ্গ এবং তাদের প্রদর্শনের নামগুলির সম্ভাব্য মান রয়েছে (এখানে বাদ দেওয়া হয়েছে)।
আমাদের ডেটাসেটে লিঙ্গ অনুসারে জনসংখ্যা যোগ করতে, আমাদের একটি নতুন স্লাইস তৈরি করতে হবে (মনে রাখবেন: প্রতিটি উপলভ্য মাত্রার সংমিশ্রণ ডেটাসেটের একটি স্লাইসের সাথে মিলে যায়)।
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
স্লাইস জন্য টেবিল সংজ্ঞা এই মত দেখায়:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
টেবিলের জন্য CSV ফাইল এই মত দেখায়:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
পূর্ববর্তী দেশ, জনসংখ্যা এবং বেকারত্বের অংশের তুলনায়, এটির একটি অতিরিক্ত মাত্রা রয়েছে; জনসংখ্যার মেট্রিকের প্রতিটি মান শুধুমাত্র একটি নির্দিষ্ট দেশ এবং বছরের সাথেই নয়, একটি নির্দিষ্ট লিঙ্গের সাথেও মিলে যায়।
মনে রাখবেন আমরা একটি "স্পার্স" ডেটাসেট তৈরি করেছি। সমস্ত মাত্রার জন্য সমস্ত মেট্রিক্স উপলব্ধ নয়: জনসংখ্যা দেশ এবং মার্কিন রাজ্যগুলির জন্য বার্ষিক ভিত্তিতে উপলব্ধ, যখন বেকারত্বের হার শুধুমাত্র দেশগুলির জন্য উপলব্ধ৷ লিঙ্গ দ্বারা ভাঙ্গন শুধুমাত্র দেশ অনুসারে জনসংখ্যার জন্য উপলব্ধ; এটি বেকারত্বের হার মেট্রিকের জন্য উপলব্ধ নয়, এবং রাষ্ট্রীয় মাত্রার জন্য নয়। স্পারসিটি ডেটা স্তরেও থাকতে পারে, নির্দিষ্ট মেট্রিক্সে নির্দিষ্ট মাত্রার মানগুলির জন্য মান থাকে না, তবে এটি ডিএসপিএল-এ উপস্থাপন করা হয় না।
বিষয়
DSPL এর শেষ বৈশিষ্ট্যটি আমরা আমাদের ডেটাসেটে ব্যবহার করব তা হল বিষয় । বিষয়গুলি শ্রেণীবদ্ধভাবে ধারণাগুলিকে শ্রেণিবদ্ধ করতে ব্যবহৃত হয় এবং ব্যবহারকারীদের আপনার ডেটাতে নেভিগেট করতে সহায়তা করার জন্য অ্যাপ্লিকেশনগুলি ব্যবহার করে৷
DSPL ফাইলে, বিষয়গুলি ধারণার ঠিক আগে উপস্থিত হয়। এখানে একটি নমুনা বিষয় অনুক্রম আছে:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>আপনি প্রয়োজনীয় বিষয়গুলিকে গভীরভাবে নেস্ট করতে পারেন।
বিষয়গুলি ব্যবহার করার জন্য, আপনাকে কেবল ধারণার সংজ্ঞা থেকে সেগুলি উল্লেখ করতে হবে, নিম্নরূপ:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
একটি ধারণা একাধিক বিষয় উল্লেখ করতে পারে।
আপনার ডেটাসেট জমা দেওয়া হচ্ছে
এখন আপনি আপনার ডেটাসেট তৈরি করেছেন, পরবর্তী পদক্ষেপটি হল জিপ করা এবং জিপ ফাইলটি Google পাবলিক ডেটা এক্সপ্লোরার টুলে আপলোড করা ৷ আপনি যদি কোনো সমস্যার সম্মুখীন হন, তাহলে প্রায়শই জিজ্ঞাসিত প্রশ্নাবলী দেখুন, যার মধ্যে সবচেয়ে সাধারণ আপলোডিং সমস্যাগুলির আলোচনা রয়েছে৷
রেফারেন্সের জন্য, আপনি এই টিউটোরিয়ালের সাথে যুক্ত সম্পূর্ণ XML ফাইল এবং সম্পূর্ণ ডেটাসেট বান্ডেল ডাউনলোড করতে পারেন।
এখান থেকে কোথায় যেতে হবে
আপনার প্রথম DSPL ডেটাসেট তৈরি করার জন্য অভিনন্দন! এখন যেহেতু আপনি বেসিকগুলি বুঝতে পেরেছেন, আমরা ডেভেলপার গাইডের মাধ্যমে পড়ার পরামর্শ দিই, যা অন্যান্য জিনিসগুলির মধ্যে, বহু-ভাষা সমর্থন এবং ম্যাপযোগ্য ধারণাগুলির মতো "উন্নত" DSPL বৈশিষ্ট্যগুলি নথিভুক্ত করে৷
আপনি আরও কিছু উদাহরণ ডেটাসেট দেখতে চাইতে পারেন।