يشير الاختصار DSPL إلى لغة نشر مجموعة البيانات. مجموعات البيانات الموضحة في DSPL إلى بيانات Google العامة Explorer، وهي أداة تتيح استكشافًا غنيًا بصريًا البيانات.
ملاحظة: لتحميل البيانات إلى Google Public Data باستخدام أداة تحميل البيانات العامة، يجب أن يكون لديك حساب على Google.
يقدم هذا البرنامج التعليمي مثالاً خطوة بخطوة حول كيفية إعداد نموذج مجموعة بيانات DSPL.
مجموعة بيانات DSPL هي حزمة تحتوي على ملف XML ومجموعة من ملفات CSV. ملفات CSV هي جداول بسيطة تحتوي على بيانات مجموعة البيانات. ويصف ملف XML البيانات الوصفية لمجموعة البيانات. بما في ذلك بيانات التعريف المعلوماتية مثل أوصاف التدابير، بالإضافة إلى بيانات التعريف الهيكلية مثل المراجع بين الجداول. تتيح بيانات التعريف المستخدمين غير الخبراء لاستكشاف بياناتك وتصورها.
الشرط الأساسي الوحيد لفهم هذا البرنامج التعليمي هو الحصول على مستوى جيد من فهم XML. فهم بعض مفاهيم قواعد البيانات البسيطة (على سبيل المثال، الجداول والمفاتيح الأساسية)، لكنه ليس مطلوبًا. كمرجع لك، ملفّ XML مكتمل مجموعة البيانات الكاملة تتوفر أيضًا الحزمة المرتبطة بهذا البرنامج التعليمي للمراجعة.
نظرة عامة
قبل البدء في إنشاء مجموعة البيانات الخاصة بنا، إليك نظرة عامة رفيعة المستوى ما تحتوي عليه مجموعة بيانات DSPL:
- معلومات عامة: حول مجموعة البيانات
- المفاهيم: تعريفات "الأشياء" الذي/التي في مجموعة البيانات (على سبيل المثال، البلدان، ومعدل البطالة، والجنس، etc.)
- الشرائح: مجموعات من المفاهيم البيانات
- الجداول: بيانات المفاهيم والشرائح جداول المفاهيم الاحتفاظ بالتعدادات وجداول الشرائح التي تحتوي على بيانات إحصائية
- المواضيع: تُستخدَم لتنظيم مفاهيم مجموعة البيانات. في تسلسل هرمي هادف من خلال تسمية
لتوضيح هذه المفاهيم التجريدية إلى حد ما، ضع في اعتبارك مجموعة البيانات (مع البيانات الوهمية) المستخدمة في هذا البرنامج التعليمي: سلسلة زمنية إحصائية وعدد السكان والبطالة، مجمّعة حسب مجموعات مختلفة من البلدان، الولاية والجنس في الولايات المتحدة.
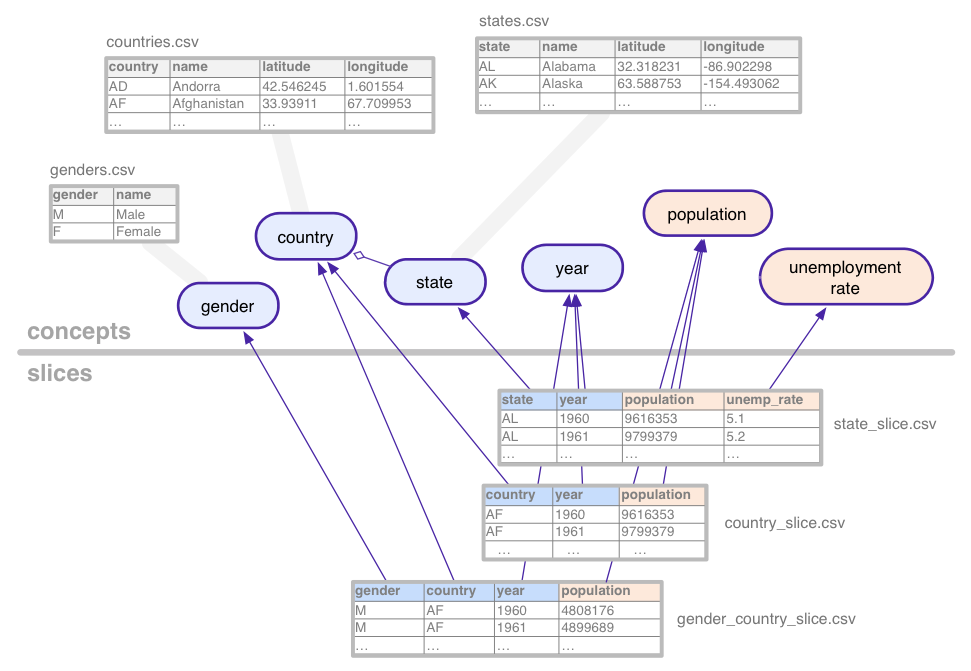
يوضّح نموذج مجموعة البيانات هذا المفاهيم التالية:
- بلد
- الجنس
- عدد السكان
- الولاية
- نسبة البطالة
- سنة
ترتبط المفاهيم الفئوية، مثل الحالة، بالمفهوم tables التي تعدد جميع قيمها الممكنة (كاليفورنيا، أريزونا، إلخ.). قد تحتوي المفاهيم على أعمدة إضافية للخصائص مثل اسم الولاية أو بلدها.
تحدد الشرائح كل مجموعة من المفاهيم التي تتوفر لها
البيانات الإحصائية في مجموعة البيانات. تحتوي الشريحة على أبعاد
المقاييس. في الصورة أعلاه، الأبعاد زرقاء
والمقاييس باللون البرتقالي. في هذا المثال، تشير الشريحة
تتوفّر بيانات عن المقياس في "gender_country_slice"
population والأبعاد country،
"year" و"gender" شريحة أخرى تسمى
country_slice، يقدم إجمالي أعداد السكان سنويًا (المقياس)
البلدان.
بالإضافة إلى الأبعاد والمقاييس، تشير الشرائح أيضًا tables التي تحتوي على البيانات الفعلية.
لننتقل الآن خطوة بخطوة خلال عملية إنشاء مجموعة البيانات هذه في DSPL.
معلومات مجموعة البيانات
للبدء، نحتاج إلى إنشاء ملف XML لمجموعة البيانات الخاصة بنا. إليك بداية وصف DSPL لمجموعة البيانات النموذجية:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
يبدأ وصف مجموعة البيانات بـ <dspl> من المستوى الأعلى.
العنصر. تحتوي السمة targetNamespace على معرّف موارد منتظم (URI)
تحدد مجموعة البيانات هذه بشكل فريد. تُستخدم مساحة اسم مجموعة البيانات بشكل خاص
عند نشر مجموعة البيانات، حيث إنها ستكون المعرف العام
مجموعة البيانات والوسائل الخاصة بالآخرين للإشارة إليها.
يُرجى العِلم أنّه قد يتم حذف السمة targetNamespace. ضِمن
في هذه الحالة، يتم إنشاء مساحة اسم فريدة تلقائيًا عندما تكون مجموعة البيانات
التي تم استيرادها.
استخدام معلومات من مجموعات بيانات أخرى
يمكن لمجموعات البيانات إعادة استخدام التعريفات والبيانات من مجموعات البيانات الأخرى عن طريق استيراد
مجموعات البيانات هذه. يحدد كل عنصر <import> السمة
مساحة الاسم لمجموعة بيانات أخرى ستشير إليها مجموعة البيانات هذه.
في نموذج مجموعة البيانات، سنحتاج إلى بعض التعريفات من http://www.google.com/publicdata/dataset/google/quantity (مجموعة بيانات تم إنشاؤها بواسطة Google تحتوي على مفاهيم مفيدة لتحديد بكميات رقمية) ومن مجموعات بيانات الوقت والكيان والموقع الجغرافي، والتي توفر التعريفات المتعلقة بالوقت والكيانات والموقع الجغرافي على التوالي.
يوفّر العنصر <dspl> العلوي بادئة مساحة الاسم
(على سبيل المثال، xmlns:time="http://...") لكل
لمجموعات البيانات المستوردة. يجب الإشارة إلى إعلانات البادئة
والعناصر من مجموعات البيانات الأخرى بطريقة موجزة. على سبيل المثال:
تشير السمة time:year إلى تعريف year في
مجموعة البيانات المستوردة التي ترتبط مساحة الاسم بالبادئة
time
معلومات الموفّر ومجموعة البيانات
يحتوي العنصر <info> على معلومات عامة عن
مجموعة البيانات: الاسم والوصف وعنوان URL حيث يمكن
التي تم العثور عليها.
يحتوي العنصر <provider> على معلومات حول
أي موفِّر مجموعة بيانات: اسمه وعنوان URL حيث يمكن الحصول على مزيد من المعلومات
(الصفحة الرئيسية لمزود البيانات بشكل عام).
تعريف المفاهيم
والآن بعد أن قدمنا بعض المعلومات العامة حول مجموعة البيانات، نحن جاهزون لبدء تحديد محتوياته. هدفنا التالي هو إضافة الإحصاءات السكانية للبلدان على مدار الخمسين عامًا الماضية.
أول شيء يتعين علينا القيام به هو تقديم بعض التعريفات للمفاهيم للسكان والبلد والسنة. في DSPL، تسمى هذه التعريفات المفاهيم.
المفهوم هو تعريف لنوع البيانات الذي يظهر في مجموعة البيانات الأصلية. تُسمى قيم البيانات التي تتوافق مع مفهوم معين المثيلات لهذا المفهوم.
السكان
لنبدأ بتعريف مفهوم المجموعة بالكامل. في
مستند DSPL، تم تحديد المفاهيم في <concepts>
العنصر الذي يأتي بعد مجموعة البيانات ومعلومات المزود مباشرةً.
إليك مفهوم السكان مع توفير الحد الأدنى من المعلومات المطلوبة
لأي مفهوم: id (معرّف فريد)، name و
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
في ما يلي طريقة عمل هذا النموذج:
- يجب أن يوفّر كل مفهوم سمة
idتُعرّف بشكلٍ فريد المفهوم داخل مجموعة البيانات. هذا يعني أنه لا يوجد مفهومان محددان في نفس مجموعة البيانات أن يكون لها نفس المعرف. - وتمامًا كما هو الحال مع مجموعة البيانات ومزودها،
عناصر
<info>توفر معلومات نصية حول المفهوم، مثل الاسم والوصف. - يحدّد العنصر
<type>نوع البيانات ممثيلات المفهوم (بعبارة أخرى، "القيم"). في هذا المثال، نوعpopulationهوintegerيتيح DSPL أنواع البيانات التالية:stringintegerfloatbooleandate
البلد
لنكتب الآن تعريف مفهوم البلد:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
يبدأ تعريف مفهوم البلد مثل التعريف السابق،
مع id وinfo وtype.
قيم المفاهيم
فإن المفاهيم الفئوية مثل البلدان لها تعداد لكل ما هو ممكن
الحالات. أو بعبارةٍ أخرى، يمكنك إدراج جميع البلدان المحتملة التي
المشار إليها. ولكن من أجل إجراء ذلك، يحتاج كل بلد إلى معرّف فريد.
يستخدم هذا المثال
رموز البلدان وفقًا لمعايير ISO لتحديد البلدان هذه الرموز
من النوع string.
في هذا المثال، لن تحتاج إلى استخدام رمز ISO، CANNOT TRANSLATE يمكنهم أيضًا استخدام اسم البلد. ومع ذلك، تختلف الأسماء حسب اللغة، يمكن أن تتغير بمرور الوقت، ولا يتم استخدامها دائمًا بشكل متسق عبر مجموعات البيانات. بالنسبة للبلدان، وبالنسبة للمفاهيم الفئوية بشكل عام، من الجيد التدرب على الاختيار، والقصير، والثابت، والشائع، والمستقل عن اللغة (إن وجدت).
خصائص المفهوم
بالإضافة إلى id، يشمل مفهوم البلد
عنصر <property> يحدّد اسم البلد
بعبارة أخرى، اسم البلد ("أيرلندا") هو موقع إلكتروني.
البلد التي لديها id IE. الخصائص هي الطريقة التي يوفرها DSPL
معلومات منظمة إضافية حول حالات أحد المفهوم.
وتمامًا مثل المفهوم نفسه، تتضمّن الخصائص id،
info وtype
بيانات المفهوم
وأخيرًا، يتضمّن مفهوم البلد عنصر <table>.
يشير هذا العنصر إلى جدول يذكر قائمة بجميع
البلدان.
يعد استخدام الجداول منطقيًا لبعض المفاهيم، وليس للمفاهيم الأخرى. بالنسبة على سبيل المثال، ليس من المنطقي تعداد جميع القيم المحتملة مفهوم المجموعة بالكامل. ومع ذلك، إذا قمت بالإشارة إلى جدول مفهومًا ما، يجب أن يحتوي هذا الجدول على جميع مثيلات المفهوم - على سبيل المثال، يجب أن يسرد جميع البلدان، وليس فقط عينة من هذه البلدان.
تحدِّد مجموعة البيانات جدول countries_table على النحو التالي:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
يحدد جدول البلدان أعمدة الجدول وأنواعها،
ويشير إلى ملف CSV يحتوي على البيانات. يمكن استخدام ملف CSV هذا
مجمعة وتحميلها مع XML لمجموعة البيانات أو الوصول إليها عن بُعد عبر HTTP وHTTPS،
أو بروتوكول FTP. في الحالات الثانية، يمكنك استبدال countries.csv بـ
عنوان URL، مثل http://www.myserver.com/mydata/countries.csv.
أينما تم تخزينه، سيظهر ملف CSV على النحو التالي:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
يسرد الصف الأول من الجدول معرّفات الأعمدة، كما هو محدّد في DSPL
تعريف "table" يتجاوب كل صف من الصفوف التالية مع صف
مثال على مفهوم البلد. إذا كان المفهوم يحتوي على جدول،
أن يحتوي الجدول على جميع مثيلات المفهوم، في هذه
حالة، يجب أن يسرد جميع البلدان.
يتم ربط الأعمدة بمفهوم البلد وخصائصه استنادًا إلى
رقم تعريفه. يتطابق رقم تعريف العمود الأول، country، مع المفهوم
المعرّف. وهذا يعني أنّ هذا العمود يحتوي على معرّف البلد الفريد.
محدد من خلال مفهوم البلد. يتجاوب العمود التالي مع
السمة name لمفهوم البلد. القيم
في هذا العمود تتطابق مع قيم السمة name.
هناك بعض المتطلبات لبيانات CSV في جدول المفاهيم:
- عناوين الأعمدة في السطر الأول من ملف البيانات يجب
تتطابق تمامًا مع المفهوم
idوالسمةidللمفهوم الذي ترتبط به البيانات (على الرغم من قد يختلف الطلب). - يجب أن يحتوي كل صف على نفس عدد العناصر مثل عدد الخصائص حول المفهوم (حتى إذا كانت القيمة فارغة).
- كل قيمة لحقل
idللمفهوم (هنا، رمز البلد) يجب أن يكون فريدًا وغير فارغ (الحقل الفارغ يساوي صفر) أو أحرف المسافات البيضاء فقط). - يجب أن تكون قيم الخصائص التي تشير إلى مفاهيم أخرى إما فارغة أو أن تكون قيمة صالحة للمفهوم المُشار إليه.
- يجب أن تكون القيم التي تحتوي على فواصل أو علامات اقتباس مزدوجة أو أحرف سطر جديد مغلقة بالكامل بين علامتي اقتباس.
- يجب إدراج أي علامة اقتباس حرفية مزدوجة داخل إحدى القيم على الفور مسبوقة باقتباس مزدوج آخر.
سنة
المفهوم الأخير الذي نحتاجه لبيانات السكان في بلدنا هو مفهوم
تمثل سنوات. وبدلاً من تحديد مفهوم جديد، سنستخدم
مفهوم السنة من إحدى مجموعات البيانات التي استوردناها:
"http://www.google.com/publicdata/dataset/google/time". للقيام بذلك،
نحتاج إلى الإشارة إليه على أنه time:year، حيث time
يمثل مجموعة البيانات المشار إليها، وتحدد year
المفهوم.
المفاهيم الأساسية
time:year هي جزء من مجموعة صغيرة من المفاهيم الأساسية.
محددة من قبل Google. توفر المفاهيم الأساسية تعريفات أساسية للوقت
الجغرافيا والكميات العددية والوحدات وغيرها
في الواقع، هناك مفهوم البلد المحدد أعلاه باعتباره
المفهوم الأساسي. وقد أنشأناها هنا لأغراض التوضيح فقط.
يجب عليك، كلما أمكن، استخدام المفاهيم الأساسية في مجموعات البيانات، إما
مباشرةً أو من خلال تمديدها (يمكنك الاطّلاع على مزيد من المعلومات حول الإضافة أدناه). المفاهيم الأساسية
وجعل بياناتك قابلة للمقارنة بمجموعات البيانات الأخرى، وتمكين ميزات
مجموعات البيانات في
مستكشف البيانات العامة. على سبيل المثال، يؤدي تحريك البيانات بمرور الوقت
أو عرض البيانات الجغرافية على خريطة تعتمد على استخدام السمتَين time
مفهومان (geo) أساسيان، على التوالي.
الشريحة الأولى
الآن بعد أن أصبح لدينا مفاهيم للسكان والبلد والسنة، حان الوقت لتجميعها معًا!
لهذا السبب، يجب إنشاء شريحة تجمع بينهما. في DSPL، الشريحة هي مزيج من المفاهيم التي توجد لها بيانات.
لماذا لا تنشئ جدولاً بالأعمدة الصحيحة فقط؟ لأنّ الشرائح تلتقط معلومات مجموعة البيانات من حيث مفاهيمها. سيصبح هذا بشكل أفضل حيث ننشئ المزيد من أجزاء مجموعة البيانات.
تظهر الشرائح في ملف DSPL ضمن <slices>.
الذي يجب أن يظهر بعد القسم concepts مباشرةً.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>تمامًا مثل المفاهيم، تحتوي كل شريحة على id
(countries_slice) التي تُعرف بشكل فريد الشريحة داخل
مجموعة البيانات الأصلية.
تحتوي الشريحة على نوعين من مراجع المفاهيم: السمات
المقاييس. تختلف قيم المقاييس باختلاف قيم
الأبعاد. هنا، تختلف قيمة population (المقياس) حسب
السمتين country وyear.
تمامًا مثل المفاهيم، تتضمن الشرائح إشارة إلى جدول تحتوي على بيانات الشريحة. يجب أن يحتوي الجدول المشار إليه على عمود واحد كل بُعد ومقياس في الشريحة. وتمامًا كما هو الحال مع المفاهيم، فإن شريحة يتم ربط السمات والمقاييس بأعمدة الجدول باستخدام أرقام التعريف نفسها.
جدول التقطيع
يظهر جدول شريحة السكان في tables.
قسم ملف DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
يُرجى العلم أنّ عمود "year" يأتي بـ format.
التي تحدد كيفية تنسيق السنوات. تنسيقات التاريخ المتوافقة هي
التي تحددها تنسيق Juda DateTime.
يحدد الجدول countries_slice أعمدة الجدول
وأنواعها، ويشير إلى ملف CSV يحتوي على البيانات. ملف CSV
يبدو كما يلي:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
يحتوي كل صف من صفوف جدول البيانات على مجموعة فريدة من السمات.
country وyear، مع القيمة المقابلة
للمقياس population (مثلاً، عدد السكان -
المقياس - لأفغانستان في عام 1960 - السمات).
يُرجى العلم أنّ القيم في عمود "country" تتطابق مع
القيمة/المعرّف لمفهوم country، وهو ISO 3166
رمز البلد المكوّن من حرفين.
يجب أن تستوفي بيانات ملف CSV لإحدى الشرائح القيود التالية:
- كل قيمة لحقل سمة (مثل
countryyear) يجب ألا يكون فارغًا. قيم حقول المقاييس (مثلpopulation) يمكن أن يكون فارغًا. يتم تمثيل القيمة الفارغة بـ "لا" الأحرف. - يجب أن تكون كل قيمة لحقل بُعد تشير إلى مفهوم ما
موجودة في بيانات هذا المفهوم. على سبيل المثال، القيمة
AFيجب أن تكون متوفّرة في جدول بيانات مفهومcountry. - كل مجموعة فريدة من قيم السمات، مثل
AF, 2000, قد تحدث مرة واحدة فقط. - يجب ترتيب البيانات حسب أعمدة السمات التي لا تخصّ الوقت (بأي ترتيب).
ثم اختياريًا حسب أي عمود من الأعمدة الأخرى. لذا، على سبيل المثال،
في جدول يحتوي على العمودين
[date, dimension1, dimension2, metric1, metric2]، يمكنك الترتيب حسبdimension1، ثمdimension2، ثمdate، ولكن ليس بحلولdateثم السمات.
ملخّص
في هذه المرحلة، لدينا ما يكفي في DSPL لوصف البلد بيانات السكان. باختصار، ما كان علينا القيام به هو:
- إنشاء عنوان DSPL ووصف مجموعة البيانات مزوِّد الخدمة
- أنشئ مفهومًا للسكان ومفهومًا آخر للبلد csv. جميع البلدان وأسمائها.
- إنشاء شريحة بأعداد السكان في البلدان بمرور الوقت مع الإشارة إلى مفهوم السنة المحدد مسبقًا في مجموعة البيانات الزمنية المستوردة من Google.
في بقية هذا البرنامج التعليمي، سنجعل مجموعة البيانات الخاصة بنا أكثر ثراءً عن طريق إضافة المزيد من الأبعاد في المزيد من الشرائح، وكذلك المزيد من المقاييس المجمَّعة حسب الموضوع.
إضافة بُعد: الولايات الأمريكية
لنثري مجموعة البيانات الآن بإضافة بيانات سكانية للولايات في الولايات المتحدة. نحتاج أولاً إلى تعريف مفهوم الحالات. يبدو هذا كثيرًا مثل مفهوم الدولة الذي حددناه من قبل.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>المواقع والإضافات الخاصة بالمفاهيم المراجع
يقدم مفهوم الولاية العديد من الميزات الجديدة لـ DSPL.
أولاً، تمد الدولة مفهومًا آخر،
geo:location (كما هو موضح في مجموعة البيانات الجغرافية الخارجية الذي
استيراده في بداية مجموعة البيانات). دلاليًا، يعني ذلك أن
state هو نوع من geo:location. النتيجة هي
وأنها ترث جميع سمات وخصائص
geo:location على وجه الخصوص، يحدد الموقع خصائص
latitude وlongitude؛ من خلال تمديد الطريقة
مفهوم، يتم تطبيق هذه الخصائص على الحالة أيضًا. علاوة على ذلك، نظرًا
يرث الموقع الجغرافي من entity:entity، وتحصل الولاية أيضًا على
وجميع خصائص الأخير، بما في ذلك name،
description، وinfo_url.
ملاحظة: مفهوم البلد المحدّد سابقًا
من الناحية الفنية، يشمل ذلك أيضًا فترة geo:location.
لقد تم حذف هذه النقطة من قبل للتبسيط؛ قمنا بتضمين
من موقع إلى آخر بلد، ومع ذلك، في
ملف XML النهائي.
ملاحظة: يمكنك استخدام extends
ويمكنك إنشاؤها في مجموعات البيانات الخاصة بك لإعادة استخدام المعلومات المحددة في مجموعات البيانات الأخرى.
يتطلب استخدام extends أن تكون جميع مثيلات مفهومك
المثيلات الصالحة للمفهوم الذي تقوم بتوسيعه. تتيح لك الإضافات إضافة
الخصائص والسمات الإضافية، وحصر مجموعة المثيلات
مجموعة فرعية من حالات المفهوم الموسع.
بالإضافة إلى الاكتساب، تقدم خاصية الولاية أيضًا
بفكرة المراجع المتعلقة بالمفهوم.
وبالتحديد، لمفهوم الولاية خاصية تسمى country،
الذي يشير إلى مفهوم البلد الذي أنشأناه أعلاه. يتم ذلك بواسطة
باستخدام السمة concept. يُرجى العِلم أنّ هذا الموقع
توفير معرف، بل مرجع مفهوم فقط. يعادل ذلك إنشاء معرّف
لها القيمة نفسها كمعرّف المفهوم المُشار إليه (أي
country في هذا المثال). العلاقة الهرمية بين
يتم تسجيل الولاية والمقاطعة من خلال وجود تصنيف
isParent="true" في المرجع بشكل عام،
ذات العلاقات الهرمية، مثل المناطق الجغرافية،
ممثلة بهذه الطريقة، مع وجود خاصية للمفهوم الفرعي
إلى المفهوم الأصلي باستخدام السمة isParent.
يبدو تعريف الجدول للحالات على النحو التالي:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
يحتوي عمود country على قيمة ثابتة لجميع الولايات. التحديد في
يتجنب DSPL تكرار هذه القيمة لكل حالة في البيانات. ملاحظة أيضًا
أننا قمنا بتضمين أعمدة لـ name، وlatitude،
longitude منذ اكتساب الولاية هذه الخصائص من
geo:location ومن ناحية أخرى، فإن بعض الخصائص الموروثة
(مثال: description) لا تحتوي على أعمدة. لا بأس بذلك -
في حال إسقاط خاصية من جدول تعريف المفهوم، فإن قيمته
يُفترض أنها غير محددة لكل مثيل من المفهوم.
يبدو ملف CSV على النحو التالي:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
نظرًا لأن لدينا مفاهيم بالفعل للسكان والسنة، يمكننا إعادة استخدامها لتحديد شريحة جديدة لمجتمع الحالات.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>يبدو تعريف جدول البيانات على النحو التالي:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
ويبدو ملف CSV على النحو التالي:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
لمَ أنشأنا شريحة جديدة بدلاً من إضافة شريحة أخرى بالسمة السابقة؟
لن تكون الشريحة ذات الأبعاد لكل من الولاية والبلد صحيحة، لأن بعض الصفوف ستكون لبيانات البلد وبعض الصفوف ستكون لولاية البيانات. سيكون للطاولة "ثقوب" بالنسبة إلى بعض السمات، والتي تمثّل غير مسموح به (تذكر أن القيم المفقودة مسموح بها فقط للمقاييس وليس الأبعاد).
تعمل السمات كـ "مفتاح أساسي" للشريحة. هذا يعني أنّ يجب أن يحتوي كل صف بيانات على قيم لجميع السمات وليس صفي بيانات يمكن أن يتطابق مع القيم نفسها لجميع السمات.
إضافة مقياس: البطالة تقييم
لنضيف الآن مقياسًا آخر إلى مجموعة البيانات:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
يتضمّن القسم "info" من هذا المقياس اسمًا ووصفًا
URL (مرتبط بمكتب إحصاءات العمل بالولايات المتحدة).
ويوضّح هذا المفهوم أيضًا مفهوم quantity:rate الأساسي.
الكمية
مجموعة البيانات المفاهيم الأساسية لتمثيل الكميات الرقمية. ضِمن
مجموعة البيانات، فيجب عليك إنشاء مفاهيمك العددية من خلال تمديد
مفهوم الكمية المناسب. ومن ثم، فإن مفهوم population
المحدد أعلاه، من الناحية الفنية، من
quantity:amount
سمات المفهوم
يقدِّم هذا المفهوم أيضًا إنشاء السمة. ضِمن
في هذا المثال، يتم استخدام إحدى السمات للدلالة على أن unemployment_rate
هي نسبة مئوية. السمة is_percentage مكتسَبة من
مفهوم quantity:rate الذي يتسع له هذا المفهوم. هذا النمط
يتم استخدام المعلومات من قبل Public Data Explorer لعرض علامات النسبة المئوية عند
لتصور البيانات.
توفر السمات آلية عامة لإرفاق أزواج المفتاح/القيمة
مفهوم (على عكس الخصائص، التي تربط القيم الإضافية
المثيلات لمفهوم). تمامًا مثل المفاهيم والخصائص،
تحتوي السمات على id وinfo و
type وكما هي الحال في الخصائص، يمكنها الإشارة إلى مفاهيم أخرى.
لا تقتصر السمات على الأشياء العامة المحددة مسبقًا فقط، مثل المواقع. ويمكنك تحديد السمات الخاصة بالمفاهيم.
إضافة بيانات معدل البطالة في الولايات المتحدة الحالات
نحن جاهزون الآن لإضافة بيانات معدل البطالة في الولايات الأمريكية. لأنّ يُعد معدل البطالة مقياسًا ولدينا بالفعل بيانات سكانية للولايات، يمكننا فقط إضافتها إلى الشريحة التي أنشأناها بالفعل للولاية والسنة الأبعاد:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... وإضافة عمود آخر إلى تعريف الجدول:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... وإلى ملف CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
قلنا سابقًا أنه لكل شريحة، تشكل الأبعاد مفتاحًا أساسيًا للشريحة. بالإضافة إلى ذلك، يمكن أن تحتوي كل مجموعة بيانات على شريحة واحدة فقط مجموعة معيّنة من الأبعاد. جميع المقاييس المتاحة لهذه يجب أن تنتمي الأبعاد إلى الشريحة نفسها.
المزيد من السمات: تقسيم السكان حسب الجنس
دعونا نثري مجموعة البيانات بتقسيم السكان حسب الجنس البلدان. والآن، بدأت الآن في معرفة التمرين... نحتاج أولاً إلى لإضافة مفهوم للجنس:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
يحتوي قسم مفهوم الجنس info على
pluralName، لتوفير النص الذي سيتم استخدامه للإشارة إليه
أمثلة متعددة لمفهوم الجنس. يتضمّن القسم "info" أيضًا
يتضمن totalName، والذي يوفر النص الذي سيتم استخدامه
يشيرون إلى جميع الأمثلة على مفهوم الجنس ككل. كلاهما
يستخدمها "مستكشف البيانات العامة" لعرض المعلومات المتعلقة بالجنس
المفهوم. بشكل عام، يجب عليك تقديمها للمفاهيم التي يمكن استخدامها ك
الأبعاد.
لاحظ أن مفهوم الجنس يمتد أيضًا من
entity:entity هذه ممارسة جيدة للمفاهيم
تُستخدم كأبعاد، حيث تسمح لك بإضافة أسماء مخصصة
وعناوين URL وألوان لمثيلات المفاهيم المختلفة.
يشير مفهوم الجنس إلى جدول genders_table، الذي
يحتوي على القيم المحتملة للجنس والأسماء المعروضة
(محذوف هنا).
لإضافة عدد السكان حسب الجنس إلى مجموعة البيانات، نحتاج إلى إنشاء شريحة جديدة (تذكر: تتوافق كل مجموعة متاحة من الأبعاد مع شريحة في مجموعة البيانات).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
يبدو تعريف الجدول للشريحة كما يلي:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
يبدو ملف CSV للجدول كما يلي:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
مقارنةً بالبلدان السابقة وعدد السكان وشريحة البطالة، لهذه القناة بُعد إضافي؛ كل قيمة للمقياس السكاني لا تتوافق فقط مع بلد وعام معينين، ولكن أيضًا مع جنس معين.
لاحظ أننا أنشأنا قيمًا "متفرقة" مجموعة البيانات الأصلية. قد لا يتلقّى تتوفّر المقاييس لجميع الأبعاد: يبلغ عدد السكان متاحة في البلدان والولايات الأمريكية على أساس سنوي، بينما يتوفّر السعر في البلدان فقط. التقسيم حسب الجنس متوفر للسكان حسب البلد فقط لا تتوفّر لمعدل البطالة أو مقياس الحالة، وليس لسمة الحالة. يمكن أن توجد الندرة أيضًا في البيانات المستوى، مع عدم وجود قيم لقيم سمات معينة في مقاييس معينة، ولكن لم يتم تمثيل ذلك في DSPL.
المواضيع
الميزة الأخيرة في DSPL التي سنستخدمها في مجموعة البيانات هي المواضيع. فتُستخدم الموضوعات لتصنيف المفاهيم بالتسلسل الهرمي، وتُستخدم التطبيقات لمساعدة المستخدمين على الانتقال إلى بياناتك.
في ملف DSPL، تظهر المواضيع مباشرةً قبل المفاهيم. إليك عيّنة التسلسل الهرمي للمواضيع:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>يمكنك تضمين المواضيع بشكل تفصيلي حسب الضرورة.
لاستخدام المواضيع، ما عليك سوى الإشارة إليها من المفهوم على النحو التالي:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
قد يشير المفهوم إلى أكثر من موضوع.
تقديم مجموعة البيانات
الآن بعد أن قمت بإنشاء مجموعة البيانات الخاصة بك، فإن الخطوة التالية هي ضغطها حمِّل ملف ZIP إلى أداة Google Public Data Explorer. إذا واجهت أي مشكلات، فتحقق من الأسئلة الشائعة، التي تتضمّن مناقشة من أكثر المشاكل شيوعًا في تحميل المحتوى
يمكنك أيضًا تنزيل ملف XML الكامل وحزمة مجموعة البيانات الكاملة كمرجع لك. المرتبط بهذا البرنامج التعليمي.
الخطوات التالية
تهانينا على إنشاء أول مجموعة بيانات DSPL! الآن بعد أن فهم الأساسيات، ننصحك بقراءة دليل المطوِّر الذي إلى جانب أشياء أخرى، المستندات "متقدمة" يمكن استخدام ميزات DSPL مثل دعم اللغات المتعددة والمفاهيم التي يمكن ربطها.
ننصحك أيضًا بالاطّلاع على المزيد من الأمثلة على مجموعات البيانات.