Scopri in che modo Google ha sviluppato il modello di classificazione delle immagini all'avanguardia per la ricerca in Google Foto. Ottieni un corso accelerato sulle reti neurali convoluzionali, quindi crea il tuo classificatore di immagini per distinguere le foto dei gatti dalle foto dei cani.
Prerequisiti
Corso di arresto anomalo di machine learning o esperienza equivalente con i concetti di base del machine learning
Conoscenza delle nozioni di base della programmazione e una certa familiarità con la programmazione in Python
Introduzione
A maggio 2013, Google ha rilasciato la ricerca delle foto personali, offrendo agli utenti la possibilità di recuperare le foto nelle loro raccolte in base agli oggetti presenti nelle immagini.
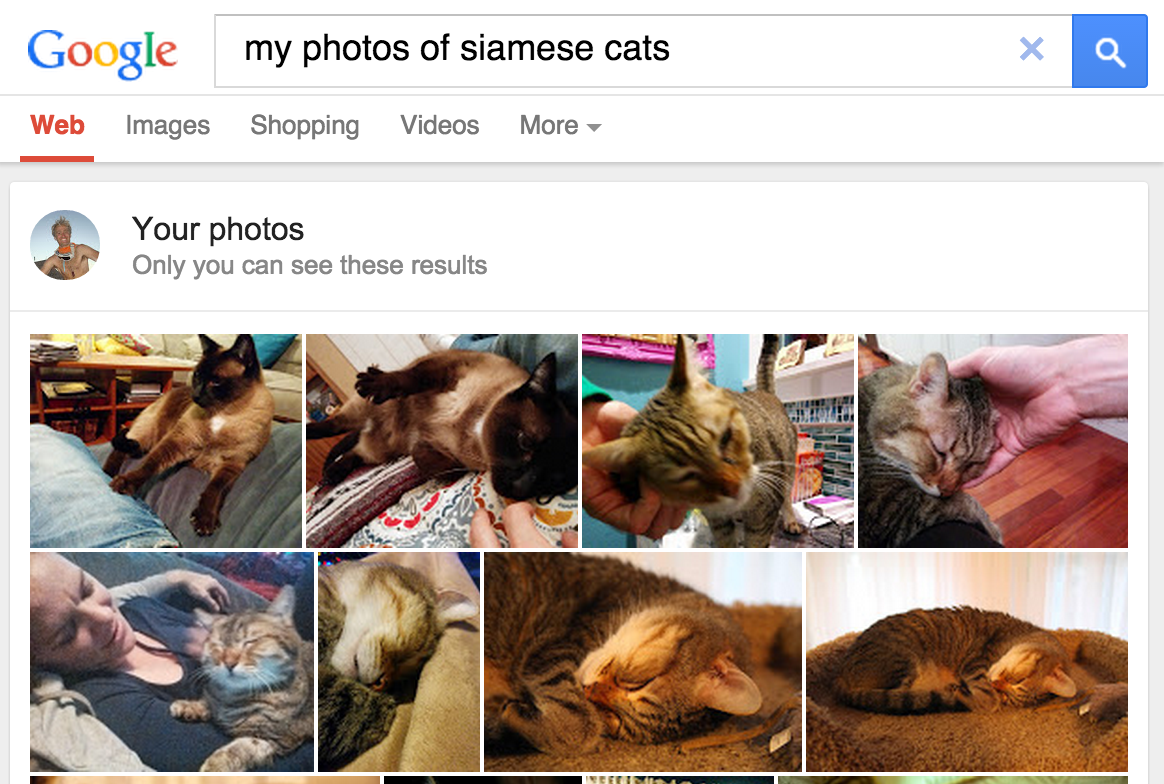 Figura 1. Alla ricerca di Google Foto di
gatti siamese consegnano i loro prodotti.
Figura 1. Alla ricerca di Google Foto di
gatti siamese consegnano i loro prodotti.
La funzionalità, integrata in Google Foto nel 2015, è stata ampiamente percepita come un punto di svolta, una proof of concept che il software di visione artificiale poteva classificare le immagini in base agli standard umani, aggiungendo valore in diversi modi:
- Gli utenti non avevano più bisogno di taggare foto con etichette come "spiaggia" per classificare i contenuti delle immagini, eliminando un'attività manuale che potrebbe risultare piuttosto noiosa durante la gestione di insiemi di centinaia o migliaia di immagini.
- Gli utenti potevano esplorare la loro raccolta di foto in nuovi modi, utilizzando i termini di ricerca per individuare foto con oggetti che non avrebbero mai taggato. Ad esempio, potrebbero cercare "palma" per mettere in risalto tutte le foto delle vacanze che avevano delle palme sullo sfondo.
- Il software potrebbe "vedere" le distinzioni tassonomiche che gli utenti stessi potrebbero non essere in grado di percepire (ad esempio, distinguere i gatti siamesi e quelli abissini), aumentando in modo efficace le conoscenze del dominio.
Come funziona la classificazione delle immagini
La classificazione delle immagini è un problema di apprendimento supervisionato: definisci un insieme di classi target (oggetti da identificare nelle immagini) e addestra un modello in modo che li riconosca utilizzando foto di esempio etichettate. I primi modelli di visione artificiale facevano affidamento sui dati pixel non elaborati come input per il modello. Tuttavia, come mostrato nella Figura 2, i dati di pixel non elaborati da soli non forniscono una rappresentazione sufficientemente stabile per includere le innumerevoli varianti di un oggetto acquisite in un'immagine. La posizione dell'oggetto, lo sfondo dietro l'oggetto, l'illuminazione ambientale, l'angolazione della fotocamera e la messa a fuoco della videocamera possono tutti variare i dati in pixel non elaborati; queste differenze sono abbastanza significative da non poter essere corrette utilizzando medie ponderate dei valori dei pixel RGB.
 Figura 2. Sinistra: i gatti possono essere acquisiti in una foto in una varietà di posizioni, con sfondi e condizioni di illuminazione diversi. Giusto: la media dei dati dei pixel per tenere conto di questa varietà non produce informazioni significative.
Figura 2. Sinistra: i gatti possono essere acquisiti in una foto in una varietà di posizioni, con sfondi e condizioni di illuminazione diversi. Giusto: la media dei dati dei pixel per tenere conto di questa varietà non produce informazioni significative.
Per modellare gli oggetti in modo più flessibile, i modelli classici di visione artificiale hanno aggiunto nuove funzionalità derivate dai dati di pixel, come gli istogrammi di colore, le texture e le forme. Lo svantaggio di questo approccio è stato che l'ingegneria delle funzionalità è diventata un carico di lavoro enorme, poiché gli input erano tanti. Per un classificatore di gatti, quali colori erano più pertinenti? Quanto devono essere flessibili le definizioni delle forme? Le funzionalità dovevano essere ottimizzate in modo molto preciso, pertanto la creazione di modelli solidi era piuttosto impegnativa e l'accuratezza ne risentiva.