Dowiedz się, jak Google opracował najnowocześniejszy model klasyfikacji obrazów, na którym działa wyszukiwarka Google. Przygotuj się na wypadek sieci neuronowych neuronowych, a potem utwórz własny klasyfikator obrazów, aby odróżnić zdjęcia kotów od zdjęć psów.
Wymagania wstępne
Kolejne szkolenie z systemów uczących się lub równoważne doświadczenie w zakresie systemów uczących się
Znajomość podstaw programowania i doświadczenie w programowaniu w języku Python
Wstęp
W maju 2013 roku udostępniliśmy funkcję wyszukiwania zdjęć prywatnych, która daje użytkownikom możliwość pobierania zdjęć z bibliotek na podstawie obiektów znajdujących się na obrazach.
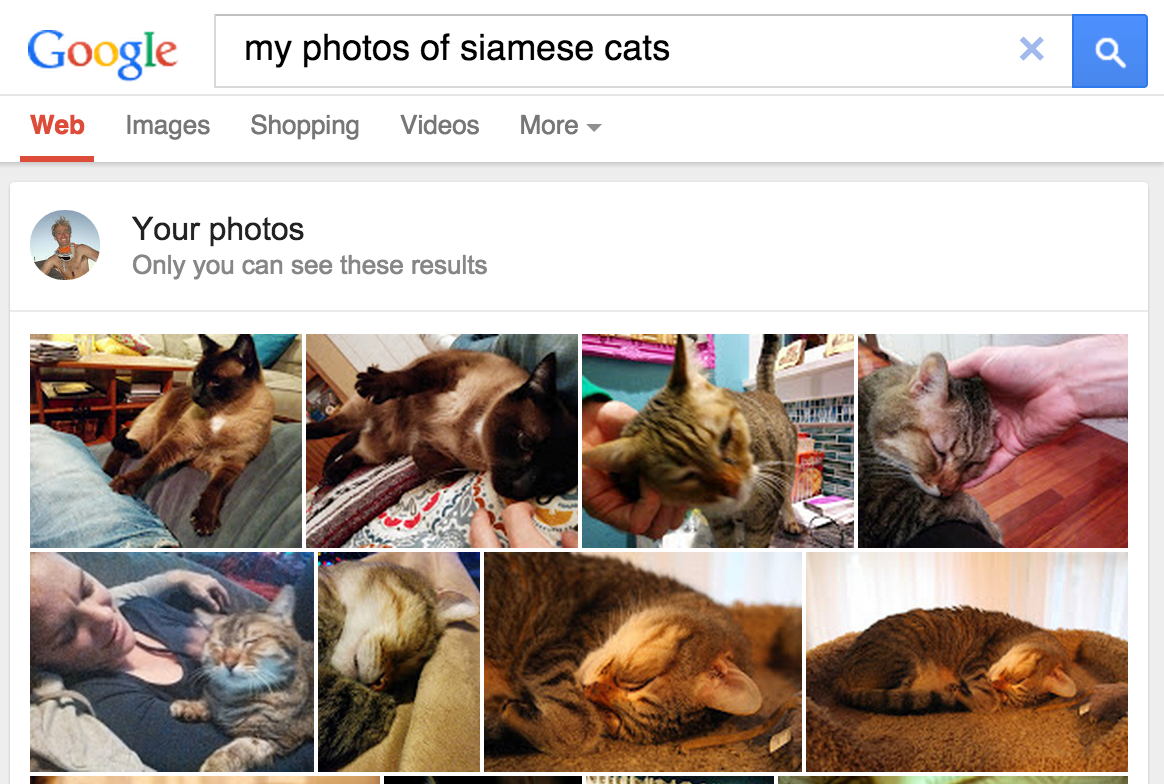 Rysunek 1. Zdjęcia Google szukają
Kotów synaskich!
Rysunek 1. Zdjęcia Google szukają
Kotów synaskich!
Ta funkcja została później dodana do Zdjęć Google w 2015 roku i została powszechnie uznana za rewolucyjne rozwiązanie, które pokazuje, że oprogramowanie do rozpoznawania obrazów umożliwia klasyfikację obrazów zgodnie ze standardami ludzkimi na wiele sposobów:
- Użytkownicy nie muszą już oznaczać tagów etykietami, takimi jak &plac;
- Użytkownicy mogą przeglądać kolekcję zdjęć na nowe sposoby, używając wyszukiwanych haseł, aby znaleźć zdjęcia z obiektami, z których nigdy wcześniej nie zostali oznaczeni tagami. Mogą na przykład wyszukać hasło „palm drzewo”, aby zobaczyć w tle wszystkie zdjęcia z wakacji, w których rosną palmy.
- Oprogramowanie może sprawiać, że użytkownicy mogą nie być w stanie zrozumieć swoich taksonomii (np. rozróżnić koty syamskie i ossynowe), aby w ten sposób zwiększyć ich wiedzę o domenie.
Jak działa klasyfikacja obrazów
Klasyfikacja obrazów to nadzorowany problem z uczeniem się: zdefiniuj zestaw klas docelowych (obiekty do zidentyfikowania na obrazach) i wytrenuj model do rozpoznawania ich na podstawie przykładowych zdjęć. Wczesne modele rozpoznawania obrazów polegały na nieprzetworzonych danych pikseli jako danych wejściowych w modelu. Jak pokazujemy na rysunku 2, nieprzetworzone dane piksela nie są wystarczająco stabilne do odzwierciedlenia najróżniejszych odmian obiektu, które są widoczne na zdjęciu. Położenie obiektu, tło za obiektem, oświetlenie otoczenia, kąt kąta oraz ostrość kamery mogą powodować wahania nieprzetworzonych danych pikseli. Te różnice są na tyle istotne, że nie można ich skorygować przez stosowanie średnich wartości ważonych pikseli RGB.
 Rysunek 2. Po lewej: koty można uchwycić na zdjęciach w różnych pozach, które można ustawić na dowolnym tle i w różnych warunkach oświetleniowych. Po prawej: uśrednianie danych piksela pod kątem tej różnorodności nie dostarcza żadnych istotnych informacji.
Rysunek 2. Po lewej: koty można uchwycić na zdjęciach w różnych pozach, które można ustawić na dowolnym tle i w różnych warunkach oświetleniowych. Po prawej: uśrednianie danych piksela pod kątem tej różnorodności nie dostarcza żadnych istotnych informacji.
Aby modelować obiekty bardziej elastycznie, klasyczne modele rozpoznawania obrazów dodały nowe funkcje uzyskane z danych pikseli, takie jak histogramy kolorów, tekstury i kształty. Wadą tego rozwiązania było to, że inżynieria cech była wyjątkowo trudna, ponieważ trzeba było wprowadzić wiele zmian. Który z tych kolorów był dla Ciebie najtrafniejszy? Jak elastyczne powinny być definicje kształtów? Ponieważ funkcje te wymagały pewnej precyzji, tworzenie niezwykłych modeli było dość trudne i związane z dokładnością.