Nell'ML di produzione, l'obiettivo non è creare un singolo modello ed eseguirne il deployment. L'obiettivo è creare pipeline automatizzate per sviluppare, testare e implementare modelli nel tempo. Perché? Con il cambiamento del mondo, le tendenze nei dati cambiano, causando l'obsolescenza dei modelli in produzione. In genere, i modelli devono essere riaddestrati con dati aggiornati per continuare a fornire previsioni di alta qualità nel lungo periodo. In altre parole, ti servirà un modo per sostituire i modelli obsoleti con quelli nuovi.
Senza le pipeline, la sostituzione di un modello obsoleto è un processo soggetto a errori. Ad esempio, una volta che un modello inizia a fornire previsioni errate, qualcuno dovrà raccogliere ed elaborare manualmente nuovi dati, addestrare un nuovo modello, convalidarne la qualità e infine implementarlo. Le pipeline ML automatizzano molti di questi processi ripetitivi, rendendo la gestione e la manutenzione dei modelli più efficienti e affidabili.
Creazione di pipeline
Le pipeline ML organizzano i passaggi per la creazione e il deployment dei modelli in attività ben definite. Le pipeline hanno una di due funzioni: fornire previsioni o aggiornare il modello.
Fornire previsioni
La pipeline di pubblicazione fornisce le previsioni. Espone il modello al mondo reale, rendendolo accessibile ai tuoi utenti. Ad esempio, quando un utente vuole una previsione, come il meteo di domani, i minuti necessari per raggiungere l'aeroporto o un elenco di video consigliati, la pipeline di pubblicazione riceve ed elabora i dati dell'utente, fa una previsione e poi la invia all'utente.
Aggiornamento del modello
I modelli tendono a diventare obsoleti quasi immediatamente dopo l'avvio della produzione. In sostanza, fanno previsioni utilizzando informazioni obsolete. I loro set di dati di addestramento hanno acquisito lo stato del mondo un giorno fa o, in alcuni casi, un'ora fa. Inevitabilmente il mondo è cambiato: un utente ha guardato più video e ha bisogno di un nuovo elenco di consigli; la pioggia ha rallentato il traffico e gli utenti hanno bisogno di stime aggiornate per i loro orari di arrivo; una tendenza popolare spinge i rivenditori a richiedere previsioni aggiornate dell'inventario per determinati articoli.
In genere, i team addestrano nuovi modelli molto prima che il modello di produzione diventi obsoleto. In alcuni casi, i team addestrano e implementano nuovi modelli ogni giorno in un ciclo continuo di addestramento e implementazione. Idealmente, l'addestramento di un nuovo modello dovrebbe avvenire molto prima che il modello di produzione diventi obsoleto.
Le seguenti pipeline funzionano insieme per addestrare un nuovo modello:
- Pipeline di dati. La pipeline di dati elabora i dati utente per creare set di dati di addestramento e test.
- Pipeline di addestramento. La pipeline di addestramento addestra i modelli utilizzando i nuovi set di dati di addestramento della pipeline di dati.
- Pipeline di convalida. La pipeline di convalida convalida il modello addestrato confrontandolo con il modello di produzione utilizzando set di dati di test generati dalla pipeline di dati.
La Figura 4 illustra gli input e gli output di ogni pipeline ML.
Pipeline di ML

Figura 4. Le pipeline ML automatizzano molti processi per lo sviluppo e la manutenzione dei modelli. Ogni pipeline mostra i relativi input e output.
A livello molto generale, ecco come le pipeline mantengono un modello aggiornato in produzione:
Innanzitutto, un modello viene messo in produzione e la pipeline di pubblicazione inizia a fornire previsioni.
La pipeline di dati inizia immediatamente a raccogliere dati per generare nuovi set di dati di addestramento e test.
In base a una pianificazione o a un trigger, le pipeline di addestramento e convalida addestrano e convalidano un nuovo modello utilizzando i set di dati generati dalla pipeline di dati.
Quando la pipeline di convalida conferma che il nuovo modello non è peggiore del modello di produzione, viene eseguito il deployment del nuovo modello.
Questo processo si ripete continuamente.
Obsolecenza del modello e frequenza di addestramento
Quasi tutti i modelli diventano obsoleti. Alcuni modelli diventano obsoleti più rapidamente di altri. Ad esempio, i modelli che consigliano abiti in genere diventano rapidamente obsoleti perché le preferenze dei consumatori cambiano di frequente. D'altra parte, i modelli che identificano i fiori potrebbero non diventare mai obsoleti. Le caratteristiche identificative di un fiore rimangono stabili.
La maggior parte dei modelli inizia a diventare obsoleta immediatamente dopo l'inserimento in produzione. Ti consigliamo di stabilire una frequenza di addestramento che rifletta la natura dei tuoi dati. Se i dati sono dinamici, esegui l'addestramento spesso. Se è meno dinamico, potresti non aver bisogno di allenarti così spesso.
Addestra i modelli prima che diventino obsoleti. L'addestramento anticipato fornisce un buffer per risolvere potenziali problemi, ad esempio se i dati o la pipeline di addestramento non funzionano o la qualità del modello è scarsa.
Una best practice consigliata è addestrare ed eseguire il deployment di nuovi modelli ogni giorno. Proprio come i normali progetti software che prevedono un processo di compilazione e rilascio giornaliero, le pipeline ML per l'addestramento e la convalida spesso funzionano meglio se eseguite quotidianamente.
Verifica di aver compreso tutto
Pipeline di pubblicazione
La pipeline di distribuzione genera e fornisce le previsioni in due modi: online o offline.
Previsioni online. Le previsioni online vengono eseguite in tempo reale, in genere inviando una richiesta a un server online e restituendo una previsione. Ad esempio, quando un utente vuole una previsione, i dati dell'utente vengono inviati al modello e il modello restituisce la previsione.
Previsioni offline. Le previsioni offline vengono precalcolate e memorizzate nella cache. Per pubblicare una previsione, l'app trova la previsione memorizzata nella cache nel database e la restituisce. Ad esempio, un servizio basato su abbonamento potrebbe prevedere il tasso di abbandono dei suoi abbonati. Il modello prevede la probabilità di abbandono per ogni abbonato e la memorizza nella cache. Quando l'app ha bisogno della previsione, ad esempio per incentivare gli utenti che potrebbero abbandonare l'app, cerca la previsione precalcolata.
La Figura 5 mostra come vengono generate e pubblicate le previsioni online e offline.
Previsioni online e offline
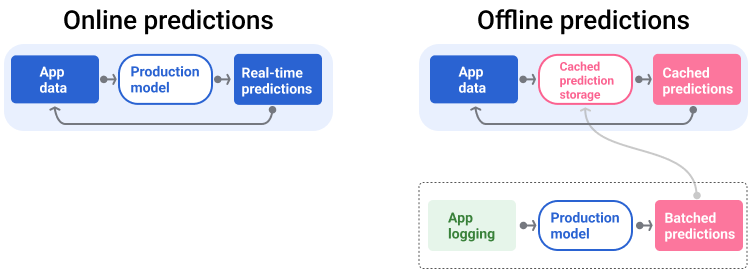
Figura 5. Le previsioni online forniscono previsioni in tempo reale. Le previsioni offline vengono memorizzate nella cache e consultate al momento della pubblicazione.
Post-elaborazione delle previsioni
In genere, le previsioni vengono post-elaborate prima di essere pubblicate. Ad esempio, le previsioni potrebbero essere post-elaborate per rimuovere contenuti tossici o distorti. I risultati della classificazione potrebbero sottoporsi a un processo per riordinare i risultati anziché mostrare l'output non elaborato del modello, ad esempio, per dare risalto ai contenuti più autorevoli, presentare una diversità di risultati, declassare risultati particolari (come i clickbait) o rimuovere risultati per motivi legali.
La Figura 6 mostra una pipeline di pubblicazione e le attività tipiche coinvolte nella pubblicazione delle previsioni.
Previsioni di post-elaborazione

Figura 6. Pipeline di pubblicazione che illustra le attività tipiche coinvolte per fornire previsioni.
Tieni presente che il passaggio di feature engineering viene in genere creato all'interno del modello e non è un processo separato e autonomo. Il codice di elaborazione dei dati nella pipeline di gestione è spesso quasi identico al codice di elaborazione dei dati utilizzato dalla pipeline di dati per creare set di dati di addestramento e di test.
Archiviazione di asset e metadati
La pipeline di pubblicazione deve incorporare un repository per registrare le previsioni del modello e, se possibile, i dati empirici reali.
La registrazione delle previsioni del modello consente di monitorare la qualità del modello. Aggregando le previsioni, puoi monitorare la qualità generale del modello e determinare se sta iniziando a perdere qualità. In generale, le previsioni del modello di produzione devono avere la stessa media delle etichette del set di dati di addestramento. Per ulteriori informazioni, consulta la sezione Bias di previsione.
Acquisizione dei dati di fatto
In alcuni casi, la verità di riferimento diventa disponibile molto più tardi. Ad esempio, se un'app meteo prevede il tempo sei settimane nel futuro, la verità di riferimento (il tempo reale) non sarà disponibile per sei settimane.
Se possibile, chiedi agli utenti di segnalare la verità di base aggiungendo meccanismi di feedback all'app. Un'app di posta può acquisire implicitamente il feedback degli utenti quando spostano la posta dalla posta in arrivo alla cartella Spam. Tuttavia, questo funziona solo quando l'utente classifica correttamente la posta. Quando gli utenti lasciano lo spam nella posta in arrivo (perché sanno che è spam e non lo aprono mai), i dati di addestramento diventano imprecisi. Il messaggio in questione verrà etichettato "Non spam" quando dovrebbe essere "Spam". In altre parole, cerca sempre di trovare modi per acquisire e registrare i dati di riferimento, ma tieni presente le carenze che potrebbero esistere nei meccanismi di feedback.
La figura 7 mostra le previsioni che vengono inviate a un utente e registrate in un repository.
Registrazione delle previsioni

Figura 7. Registra le previsioni per monitorare la qualità del modello.
Pipeline di dati
Le pipeline di dati generano set di dati di addestramento e test dai dati delle applicazioni. Le pipeline di addestramento e convalida utilizzano quindi i set di dati per addestrare e convalidare nuovi modelli.
La pipeline di dati crea set di dati di addestramento e test con le stesse funzionalità ed etichetta utilizzate originariamente per addestrare il modello, ma con informazioni più recenti. Ad esempio, un'app di mappe genererebbe set di dati di addestramento e test a partire dai recenti tempi di percorrenza tra punti per milioni di utenti, insieme ad altri dati pertinenti, come il meteo.
Un'app di consigli sui video genererebbe set di dati di addestramento e test che includono i video su cui un utente ha fatto clic nell'elenco dei consigli (insieme a quelli su cui non ha fatto clic), nonché altri dati pertinenti, come la cronologia delle visualizzazioni.
La Figura 8 illustra la pipeline di dati che utilizza i dati dell'applicazione per generare set di dati di addestramento e test.
Pipeline di dati

Figura 8. La pipeline di dati elabora i dati dell'applicazione per creare set di dati per le pipeline di addestramento e convalida.
Raccolta ed elaborazione dei dati
Le attività di raccolta ed elaborazione dei dati nelle pipeline di dati probabilmente differiranno dalla fase di sperimentazione (in cui hai stabilito che la tua soluzione era fattibile):
Raccolta dei dati. Durante la sperimentazione, la raccolta dei dati in genere richiede l'accesso ai dati salvati. Per le pipeline di dati, la raccolta dei dati potrebbe richiedere l'individuazione e l'approvazione per accedere ai dati dei log di streaming.
Se hai bisogno di dati etichettati da persone (come immagini mediche), dovrai anche un processo per raccoglierli e aggiornarli.
Trattamento dei dati. Durante la sperimentazione, le funzionalità giuste sono state ottenute tramite scraping, unione e campionamento dei set di dati di sperimentazione. Per le pipeline di dati, la generazione delle stesse funzionalità potrebbe richiedere processi completamente diversi. Tuttavia, assicurati di duplicare le trasformazioni dei dati della fase di sperimentazione applicando le stesse operazioni matematiche alle funzionalità e alle etichette.
Archiviazione di asset e metadati
Avrai bisogno di una procedura per archiviare, controllare le versioni e gestire i set di dati di addestramento e test. I repository con controllo delle versioni offrono i seguenti vantaggi:
Riproducibilità. Ricrea e standardizza gli ambienti di addestramento dei modelli e confronta la qualità delle previsioni tra modelli diversi.
Conformità. Rispettare i requisiti di conformità normativa per l'auditabilità e la trasparenza.
Fidelizzazione. Imposta i valori di conservazione dei dati per determinare la durata della conservazione dei dati.
Gestione dell'accesso. Gestisci chi può accedere ai tuoi dati tramite autorizzazioni granulari.
Integrità dei dati. Monitora e comprendi le modifiche ai set di dati nel tempo, in modo da diagnosticare più facilmente i problemi relativi ai dati o al modello.
Rilevabilità. Facilita la ricerca dei tuoi set di dati e delle tue funzionalità. Gli altri team possono quindi determinare se sono utili per i loro scopi.
Documentare i dati
Una buona documentazione aiuta gli altri a comprendere le informazioni chiave sui tuoi dati, come tipo, origine, dimensioni e altri metadati essenziali. Nella maggior parte dei casi, è sufficiente documentare i dati in un documento di progettazione . Se prevedi di condividere o pubblicare i tuoi dati, utilizza schede con i dati per strutturare le informazioni. Le schede dei dati consentono ad altri utenti di scoprire e comprendere più facilmente i tuoi set di dati.
Pipeline di addestramento e convalida
Le pipeline di addestramento e convalida producono nuovi modelli per sostituire i modelli di produzione prima che diventino obsoleti. L'addestramento e la convalida continui di nuovi modelli garantiscono che il modello migliore sia sempre in produzione.
La pipeline di addestramento genera un nuovo modello dai set di dati di addestramento e la pipeline di convalida confronta la qualità del nuovo modello con quello in produzione utilizzando set di dati di test.
La figura 9 illustra la pipeline di addestramento che utilizza un set di dati di addestramento per addestrare un nuovo modello.
Pipeline di addestramento

Figura 9. La pipeline di addestramento addestra nuovi modelli utilizzando il set di dati di addestramento più recente.
Una volta addestrato il modello, la pipeline di convalida utilizza set di dati di test per confrontare la qualità del modello di produzione con quella del modello addestrato.
In generale, se il modello addestrato non è significativamente peggiore del modello di produzione, viene messo in produzione. Se il modello addestrato è peggiore, l'infrastruttura di monitoraggio deve creare un avviso. I modelli addestrati con una qualità di previsione peggiore potrebbero indicare potenziali problemi con le pipeline di dati o di convalida. Questo approccio garantisce che in produzione sia sempre presente il modello migliore, addestrato con i dati più recenti.
Archiviazione di asset e metadati
I modelli e i relativi metadati devono essere archiviati in repository con controllo delle versioni per organizzare e monitorare le implementazioni dei modelli. I repository di modelli offrono i seguenti vantaggi:
Monitoraggio e valutazione. Monitora i modelli in produzione e comprendi le metriche di qualità di valutazione e previsione.
Procedura di rilascio del modello. Rivedi, approva, rilascia o esegui facilmente il rollback dei modelli.
Riproducibilità e debug. Riproduci i risultati del modello e esegui il debug dei problemi in modo più efficace tracciando i set di dati e le dipendenze di un modello nelle implementazioni.
Rilevabilità. Facilita la ricerca del tuo modello da parte di altri. Gli altri team possono quindi determinare se il tuo modello (o parti di esso) può essere utilizzato per i loro scopi.
La figura 10 mostra un modello convalidato archiviato in un repository di modelli.
Archiviazione del modello

Figura 10. I modelli convalidati vengono archiviati in un repository di modelli per il monitoraggio e la rilevabilità.
Utilizza schede dei modelli per documentare e condividere le informazioni chiave sul tuo modello, come lo scopo, l'architettura, i requisiti hardware, le metriche di valutazione e così via.
Verifica di aver compreso tutto
Sfide nella creazione di pipeline
Quando crei pipeline, potresti riscontrare le seguenti difficoltà:
Ottenere l'accesso ai dati che ti servono. L'accesso ai dati potrebbe richiedere una giustificazione del motivo per cui ti servono. Ad esempio, potresti dover spiegare come verranno utilizzati i dati e chiarire come verranno risolti i problemi relativi alle informazioni che consentono l'identificazione personale (PII). Preparati a mostrare una prova di fattibilità che dimostri come il tuo modello fa previsioni migliori con l'accesso a determinati tipi di dati.
Ottenere le funzionalità giuste. In alcuni casi, le funzionalità utilizzate nella fase di sperimentazione non saranno disponibili dai dati in tempo reale. Pertanto, quando esegui esperimenti, cerca di confermare che potrai ottenere le stesse funzionalità in produzione.
Comprendere come vengono raccolti e rappresentati i dati. Comprendere come sono stati raccolti i dati, chi li ha raccolti e in che modo (insieme ad altri problemi) può richiedere tempo e impegno. È importante comprendere a fondo i dati. Non utilizzare dati di cui non ti fidi per addestrare un modello che potrebbe essere messo in produzione.
Comprendere i compromessi tra impegno, costi e qualità del modello. L'integrazione di una nuova funzionalità in una pipeline di dati può richiedere molto impegno. Tuttavia, la funzionalità aggiuntiva potrebbe migliorare solo leggermente la qualità del modello. In altri casi, l'aggiunta di una nuova funzionalità potrebbe essere semplice. Tuttavia, le risorse per ottenere e archiviare la funzionalità potrebbero essere eccessivamente costose.
Ottenere risorse di calcolo. Se hai bisogno di TPU per il riaddestramento, potrebbe essere difficile ottenere la quota richiesta. Inoltre, la gestione delle TPU è complicata. Ad esempio, alcune parti del modello o dei dati potrebbero dover essere progettate specificamente per le TPU suddividendo le parti su più chip TPU.
Trovare il set di dati di riferimento giusto. Se i dati cambiano di frequente, ottenere dataset di riferimento con etichette coerenti e accurate può essere difficile.
Rilevare questi tipi di problemi durante la sperimentazione consente di risparmiare tempo. Ad esempio, non vuoi sviluppare le migliori funzionalità e il miglior modello solo per scoprire che non sono fattibili in produzione. Pertanto, cerca di confermare il prima possibile che la tua soluzione funzionerà entro i limiti di un ambiente di produzione. È meglio dedicare del tempo a verificare che una soluzione funzioni piuttosto che dover tornare alla fase di sperimentazione perché la fase della pipeline ha rivelato problemi insormontabili.