Машинное обучение (МО) лежит в основе многих важнейших технологий, которые мы используем, от приложений для перевода до беспилотных автомобилей. Этот курс объясняет основные концепции, лежащие в основе МО.
Машинное обучение предлагает новый способ решения проблем, ответа на сложные вопросы и создания нового контента. Машинное обучение может прогнозировать погоду, оценивать время в пути, рекомендовать песни, автоматически дополнять предложения, резюмировать статьи и генерировать невиданные ранее изображения.
В общих чертах, машинное обучение — это процесс обучения программного обеспечения, называемого моделью , для выполнения полезных прогнозов или генерации контента (например, текста, изображений, аудио или видео) на основе данных.
Например, предположим, мы хотим создать приложение для прогнозирования осадков. Мы можем использовать либо традиционный подход, либо подход на основе машинного обучения. При традиционном подходе мы бы создали физически обоснованное представление атмосферы и поверхности Земли, вычисляя огромное количество уравнений гидродинамики. Это невероятно сложно.
Используя подход машинного обучения, мы бы предоставляли модели машинного обучения огромные объемы метеорологических данных до тех пор, пока модель не научилась бы математической зависимости между погодными условиями, которые приводят к различному количеству осадков. Затем мы бы предоставляли модели текущие метеорологические данные, и она бы прогнозировала количество осадков.
Проверьте свои знания
Типы систем машинного обучения
Системы машинного обучения подразделяются на одну или несколько из следующих категорий в зависимости от того, как они учатся делать прогнозы или генерировать контент:
- Обучение под наблюдением
- Обучение без надзора
- Обучение с подкреплением
- Генеративный ИИ
Обучение под наблюдением
Модели контролируемого обучения могут делать прогнозы после анализа большого количества данных с правильными ответами и выявления связей между элементами данных, которые приводят к этим правильным ответам. Это похоже на то, как студент изучает новый материал, используя старые экзаменационные задания, содержащие как вопросы, так и ответы. После того, как студент обучится на достаточном количестве старых экзаменационных заданий, он будет хорошо подготовлен к сдаче нового экзамена. Эти системы машинного обучения являются «контролируемыми» в том смысле, что человек предоставляет системе машинного обучения данные с известными правильными результатами.
Два наиболее распространенных варианта применения обучения с учителем — это регрессия и классификация.
Регрессия
Регрессионная модель предсказывает числовое значение. Например, метеорологическая модель, которая предсказывает количество осадков в дюймах или миллиметрах, является регрессионной моделью.
В таблице ниже приведены дополнительные примеры регрессионных моделей:
| Сценарий | Возможные входные данные | Численное прогнозирование |
|---|---|---|
| Будущая цена дома | Площадь, почтовый индекс, количество спален и ванных комнат, размер участка, процентная ставка по ипотеке, ставка налога на недвижимость, стоимость строительства и количество домов, выставленных на продажу в этом районе. | Цена дома. |
| Будущее время поездки | Исторические данные о дорожной ситуации (полученные со смартфонов, датчиков движения, приложений для заказа такси и других навигационных систем), расстояние до пункта назначения и погодные условия. | Время в минутах и секундах, необходимое для прибытия в пункт назначения. |
Классификация
Классификационные модели предсказывают вероятность принадлежности объекта к определенной категории. В отличие от регрессионных моделей, результатом работы которых является число, классификационные модели выдают значение, указывающее, принадлежит ли объект к определенной категории или нет. Например, классификационные модели используются для прогнозирования того, является ли электронное письмо спамом или содержит ли фотография кошку.
Модели классификации делятся на две группы: бинарная классификация и многоклассовая классификация. Модели бинарной классификации выдают значение из класса, содержащего только два значения, например, модель, которая выдает либо rain , либо no rain . Модели многоклассовой классификации выдают значение из класса, содержащего более двух значений, например, модель, которая может выдавать либо rain , hail , snow » или sleet .
Проверьте свои знания
Обучение без надзора
Целью модели обучения без учителя является выявление значимых закономерностей в наборе данных. Например, многие модели обучения без учителя используют метод кластеризации для организации похожих данных в группы («кластеры»).
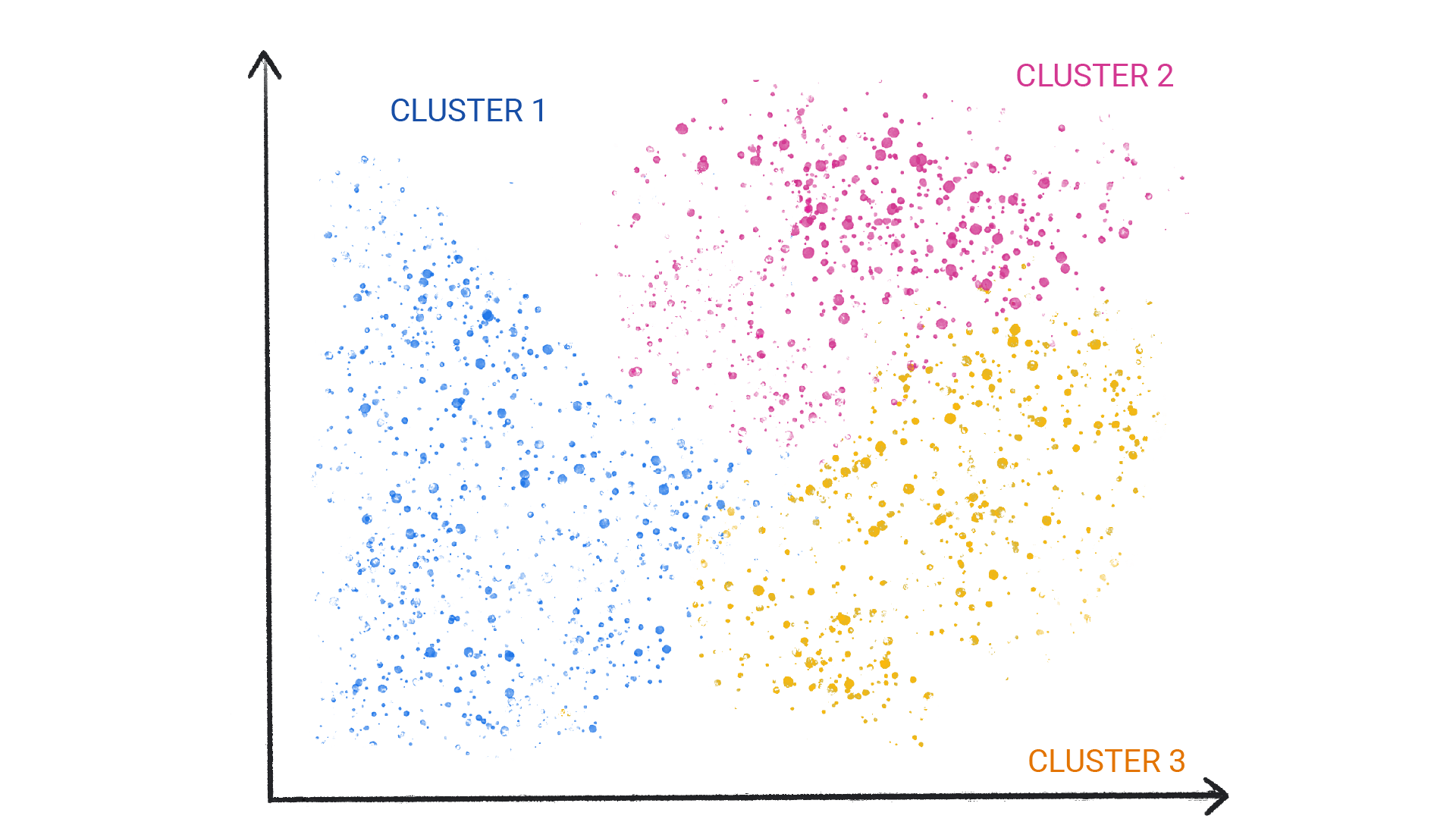
Рисунок 1. Модель машинного обучения, кластеризующая похожие точки данных.
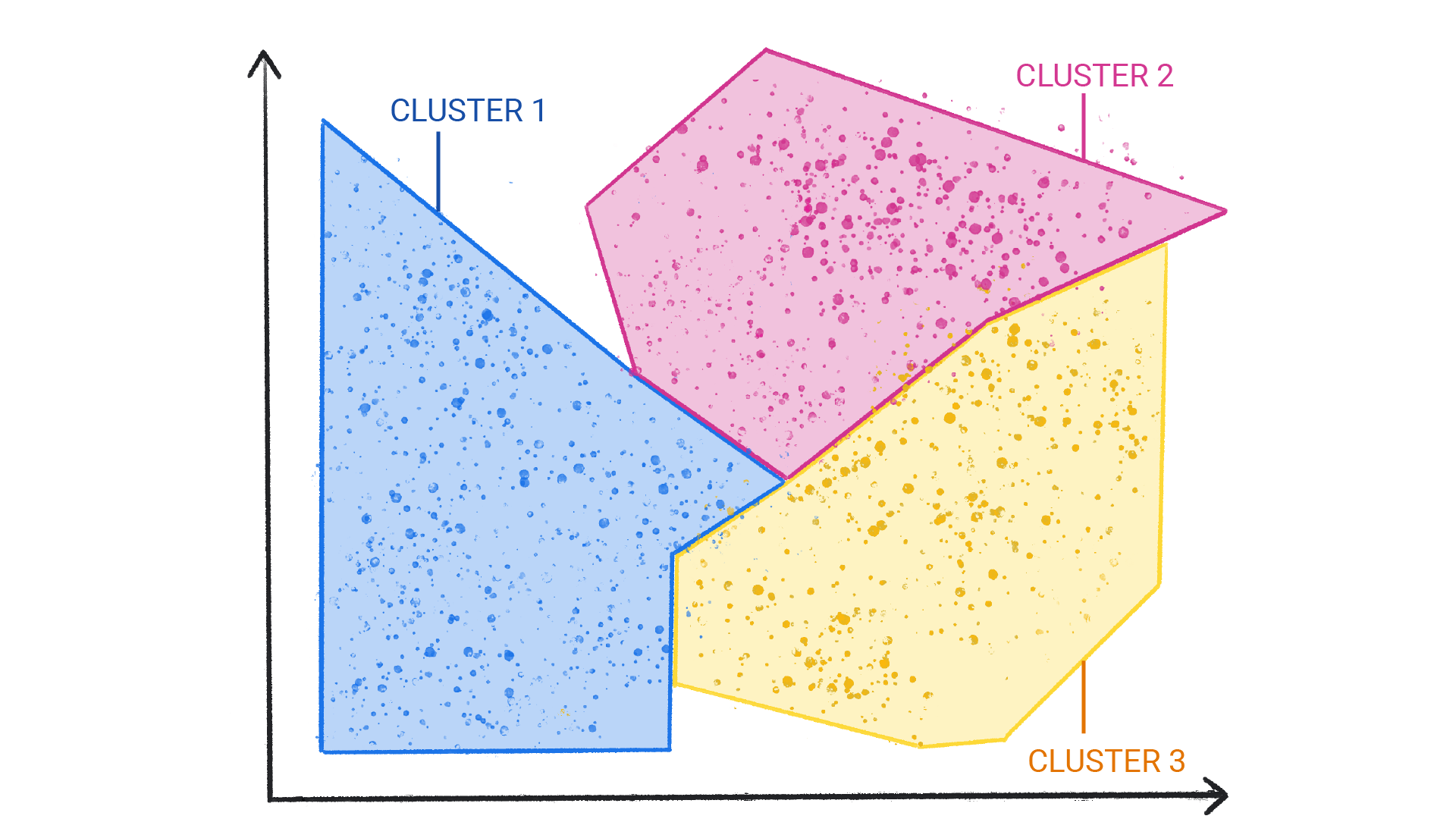
Рисунок 2. Группы кластеров с естественными границами.
Кластеризация отличается от классификации тем, что категории определяются не вами. Например, модель без учителя может кластеризовать набор данных о погоде на основе температуры, выявляя сегментацию, определяющую времена года. Затем вы можете попытаться назвать эти кластеры, основываясь на своем понимании набора данных.
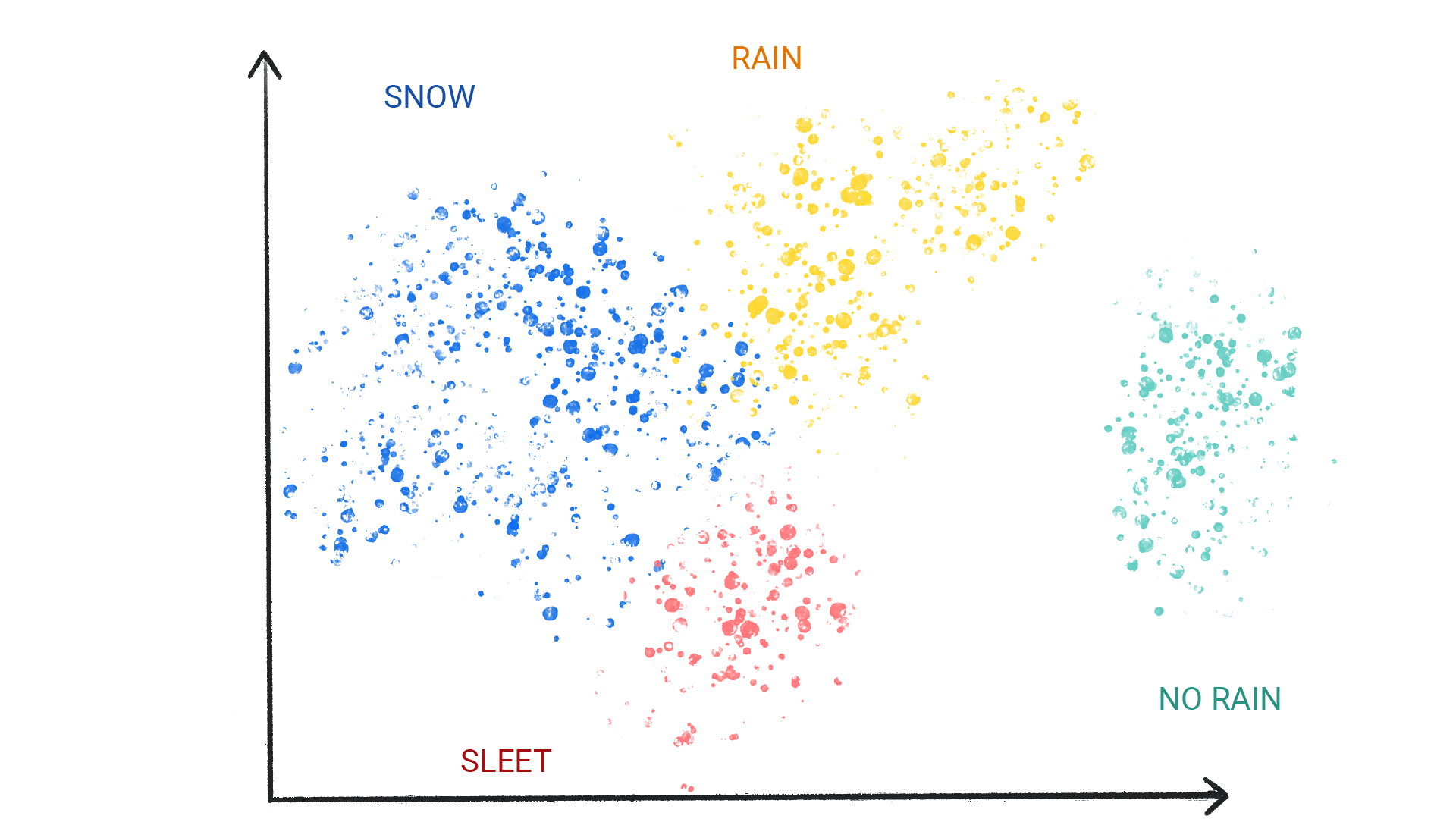
Рисунок 3. Модель машинного обучения, объединяющая схожие погодные условия в кластеры.
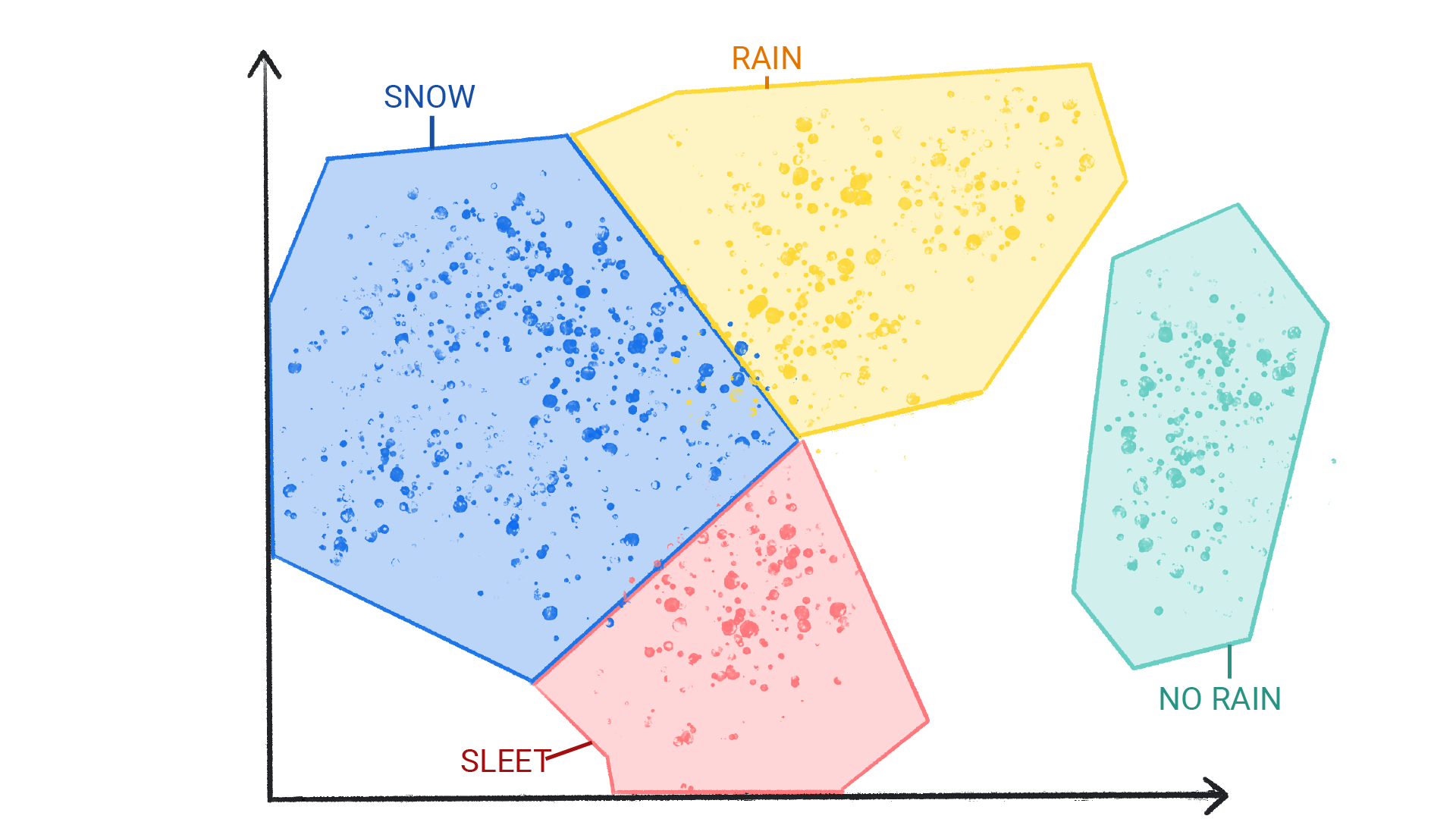
Рисунок 4. Группы погодных явлений, обозначенные как снег, мокрый снег, дождь и отсутствие дождя.
Проверьте свои знания
Обучение с подкреплением
Модели обучения с подкреплением делают прогнозы, получая вознаграждения или штрафы в зависимости от действий, совершаемых в окружающей среде. Система обучения с подкреплением генерирует стратегию , определяющую наилучший способ получения максимального вознаграждения.
Обучение с подкреплением используется для обучения роботов выполнению задач, таких как ходьба по комнате, а также для обучения программных продуктов, таких как AlphaGo игре в го.
Генеративный ИИ
Генеративный ИИ — это класс моделей, которые создают контент на основе пользовательского ввода. Например, генеративный ИИ может создавать уникальные изображения, музыкальные композиции и шутки; он может делать краткие обзоры статей, объяснять, как выполнить задачу, или редактировать фотографии.
Генеративный ИИ может принимать на вход различные данные и создавать на выходе различные результаты, такие как текст, изображения, аудио и видео. Он также может принимать и создавать их комбинации. Например, модель может принять изображение в качестве входных данных и создать изображение и текст в качестве выходных данных, или принять изображение и текст в качестве входных данных и создать видео в качестве выходных данных.
Мы можем обсуждать генеративные модели, рассматривая их входные и выходные данные, обычно обозначаемые как «тип входных данных» — «тип выходных данных». Например, ниже приведён неполный список некоторых входных и выходных данных для генеративных моделей:
- Текст в текст
- Преобразование текста в изображение
- Преобразование текста в видео
- Преобразование текста в код
- Преобразование текста в речь
- Изображение и текст в изображение
В следующей таблице приведены примеры генеративных моделей, их входные данные и возможные выходные данные:
| Модель | Вход | Пример выходных данных |
|---|---|---|
| Текст в текст | Кто придумал гонку Ле-Ман? | Гонка «24 часа Ле-Мана» была основана Автомобильным клубом Западной Франции (ACO), автомобильной организацией, созданной в 1906 году. Первая гонка состоялась 26 и 27 мая 1923 года на трассе Сарта, дорожной трассе длиной 13,426 километра (8,345 мили), расположенной недалеко от города Ле-Ман во Франции. Первоначально гонка задумывалась как способ популяризации ACO и региона Сарта. Источник: Бард |
| Преобразование текста в изображение | Инопланетный осьминог пролетает сквозь портал, читая газету. |  Источник: Imagen |
| Преобразование текста в видео | Фотореалистичный плюшевый мишка плавает в океане у берегов Сан-Франциско. Мишка уходит под воду. Мишка продолжает плыть под водой среди разноцветных рыбок. Под водой плавает панда. |  Источник: Phenaki |
| Преобразование текста в код | Напишите цикл на Python, который перебирает список чисел и выводит простые числа. | for number in numbers: # Check if the number is prime. is_prime = True for i in range(2, number): if number % i == 0: is_prime = False break # If the number is prime, print it. if is_prime: print(number) Источник: Бард |
| Преобразование изображения в текст |  | Это фламинго. Они обитают в Карибском море. Источник: Google DeepMind |
Как работает генеративный ИИ? В общих чертах, генеративные модели изучают закономерности в данных с целью создания новых, но похожих данных. Генеративные модели выглядят следующим образом:
- Комики, которые учатся имитировать других, наблюдая за поведением и манерой речи людей.
- Художники, которые учатся писать в определенном стиле, изучая множество картин, написанных в этом стиле.
- Кавер-группы, которые учатся звучать как определённая музыкальная группа, слушая много музыки этой группы.
Для получения уникальных и креативных результатов генеративные модели первоначально обучаются с использованием подхода без учителя, при котором модель учится имитировать данные, на которых она обучалась. Иногда модель дополнительно обучается с использованием обучения с учителем или обучения с подкреплением на конкретных данных, связанных с задачами, которые могут быть поставлены перед моделью, например, написание краткого изложения статьи или редактирование фотографии.
Генеративный искусственный интеллект — это быстро развивающаяся технология, в которой постоянно открываются новые области применения. Например, генеративные модели помогают компаниям улучшать изображения товаров в электронной коммерции, автоматически удаляя отвлекающий фон или повышая качество изображений с низким разрешением.