Mit den folgenden Fragen können Sie Ihr Wissen zu den wichtigsten ML-Konzepten festigen.
Vorhersagekraft
Überwachte ML-Modelle werden mit Datasets mit gelabelten Beispielen trainiert. Das Modell
lernt, das Label anhand der Features vorherzusagen. Allerdings hat nicht jedes Feature in
einem Dataset eine Vorhersagekraft. In einigen Fällen dienen nur wenige Features als
Prädiktoren für das Label. Verwenden Sie im folgenden Dataset den Preis als Label
und die übrigen Spalten als Features.

Welche drei Features sind Ihrer Meinung nach die besten Prädiktoren
für den Preis eines Autos?
Marke_Modell, Jahr, Kilometer
Marke/Modell, Jahr und Kilometer eines Autos sind wahrscheinlich die
stärksten Prädiktoren für seinen Preis.
Farbe, Höhe, Marke_Modell
Höhe und Farbe eines Autos sind keine starken Prädiktoren für den Preis eines Autos.
Kilometer, Getriebe, Marke_Modell
Das Getriebe ist kein Hauptprädiktor für den Preis.
Reifengröße, Radstand, Jahr
Reifengröße und Radstand sind keine starken Prädiktoren für den Preis eines Autos.
Überwachtes und nicht überwachtes Lernen
Je nach Problem verwenden Sie entweder einen überwachten oder einen nicht überwachten Ansatz.
Wenn Sie beispielsweise den Wert oder die Kategorie, die Sie vorhersagen möchten, im Voraus kennen,
verwenden Sie überwachtes Lernen. Wenn Sie jedoch herausfinden möchten, ob Ihr Dataset
Segmentierungen oder Gruppierungen ähnlicher Beispiele enthält, verwenden Sie
nicht überwachtes Lernen.
Angenommen, Sie haben ein Dataset mit Nutzern für eine Onlineshopping-Website, das es
enthält die folgenden Spalten:

Wenn Sie die Arten von Nutzern verstehen möchten, die die Website besuchen,
würden Sie überwachtes oder nicht überwachtes Lernen verwenden?
Nicht überwachtes Lernen
Da wir möchten, dass das Modell Gruppen ähnlicher Kunden zusammenfasst,
verwenden wir nicht überwachtes Lernen. Nachdem das Modell die Nutzer gruppiert hat,
erstellen wir eigene Namen für die einzelnen Cluster, z. B.
„Rabattsuchende“, „Schnäppchenjäger“, „Surfer“, „Treue Kunden“
und „Gelegenheitskäufer“.
Überwachtes Lernen, weil ich vorhersagen möchte, zu welcher Klasse
ein Nutzer gehört.
Beim überwachten Lernen muss das Dataset das Label enthalten, das Sie
vorhersagen möchten. Im Dataset gibt es kein Label, das sich auf eine
Nutzerkategorie bezieht.
Angenommen, Sie haben ein Dataset zum Energieverbrauch von Haushalten mit den folgenden Spalten:
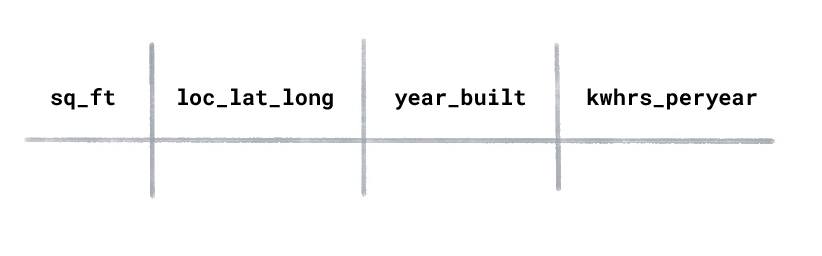
Welche Art von ML würden Sie verwenden, um den jährlichen Kilowattstundenverbrauch für ein neu gebautes Haus vorherzusagen?
Überwachtes Lernen
Beim überwachten Lernen werden gelabelte Beispiele verwendet. In diesem Dataset
„Kilowattstundenverbrauch pro Jahr“ wäre das Label, da dies der
Wert ist, den das Modell vorhersagen soll. Die Features wären
„Quadratmeter“, „Standort“ und „Baujahr“.
Nicht überwachtes Lernen
Beim nicht überwachten Lernen werden nicht gelabelte Beispiele verwendet. In diesem Beispiel wäre „Kilowattstundenverbrauch pro Jahr“ das Label, da dies der Wert ist, den das Modell vorhersagen soll.
Angenommen, Sie haben ein Dataset mit Flügen mit den folgenden Spalten:

Wenn Sie die Kosten eines Flugtickets vorhersagen möchten, würden Sie
Regression oder Klassifizierung verwenden?
Regression
Die Ausgabe eines Regressionsmodells ist ein numerischer Wert.
Klassifizierung
Die Ausgabe eines Klassifizierungsmodells ist ein diskreter Wert,
normalerweise ein Wort. In diesem Fall sind die Kosten eines Flugtickets ein numerischer Wert.
Könnten Sie anhand des Datasets ein Klassifizierungsmodell
trainieren, um die Kosten eines Flugtickets als
„hoch“, „durchschnittlich“ oder „niedrig“ zu klassifizieren?
Ja, aber wir müssten zuerst die numerischen Werte in der
airplane_ticket_cost Spalte in kategoriale Werte umwandeln.
Es ist möglich, ein Klassifizierungsmodell aus dem Dataset zu erstellen.
Sie würden etwa so vorgehen:
- Ermitteln Sie die durchschnittlichen Kosten für ein Ticket vom Abflugort zum
Zielort.
- Bestimmen Sie die Grenzwerte für „hoch“, „durchschnittlich“,
und „niedrig“.
- Vergleichen Sie die vorhergesagten Kosten mit den Grenzwerten und geben Sie die
Kategorie aus, in die der Wert fällt.
Nein, es ist nicht möglich, ein Klassifizierungsmodell zu erstellen. Die
airplane_ticket_cost Werte sind numerisch und nicht kategorial.
Mit etwas Aufwand können Sie ein Klassifizierungs
modell erstellen.
Nein. Klassifizierungsmodelle sagen nur zwei Kategorien voraus, z. B.
spam oder not_spam. Dieses Modell müsste
drei Kategorien vorhersagen.
Klassifizierungsmodelle können mehrere Kategorien vorhersagen. Sie werden als Multiklassen-Klassifizierungsmodelle bezeichnet.
Training und Evaluierung
Nachdem wir ein Modell trainiert haben, evaluieren wir es mit einem Dataset mit
gelabelten Beispielen und vergleichen den vorhergesagten Wert des Modells mit dem tatsächlichen Wert des Labels.
Wählen Sie die beiden besten Antworten auf die Frage aus.
Wenn die Vorhersagen des Modells weit daneben liegen, was können Sie tun, um
sie zu verbessern?
Trainieren Sie das Modell noch einmal, verwenden Sie aber nur die Features, die Ihrer Meinung nach die
stärkste Vorhersagekraft für das Label haben.
Wenn Sie das Modell mit weniger Features trainieren, die aber eine höhere
Vorhersagekraft haben, kann ein Modell mit besseren
Vorhersagen entstehen.
Ein Modell, dessen Vorhersagen weit daneben liegen, kann nicht korrigiert werden.
Es ist möglich, ein Modell zu korrigieren, dessen Vorhersagen nicht stimmen. Die meisten Modelle
müssen mehrmals trainiert werden, bis sie
nützliche Vorhersagen treffen.
Trainieren Sie das Modell noch einmal mit einem größeren und vielfältigeren Dataset.
Modelle, die mit Datasets mit mehr Beispielen und einer größeren Bandbreite an
Werten trainiert wurden, können bessere Vorhersagen treffen, da das Modell eine bessere
verallgemeinerte Lösung für die Beziehung zwischen den Features und
dem Label hat.
Versuchen Sie einen anderen Trainingsansatz. Wenn Sie beispielsweise einen
überwachten Ansatz verwendet haben, versuchen Sie einen nicht überwachten Ansatz.
Ein anderer Trainingsansatz würde keine besseren
Vorhersagen liefern.
Sie sind jetzt bereit für den nächsten Schritt auf Ihrem Weg mit ML:
Crashkurs „Machine Learning“ Wenn Sie
bereit sind für einen umfassenden, praktischen Ansatz, um mehr über ML zu erfahren.
Problem Framing Wenn Sie
einen praxiserprobten Ansatz zum Erstellen von ML-Modellen und Vermeiden häufiger Fehler suchen.
People + AI Guidebook Wenn Sie
praktische Anleitungen zum Entwerfen von nutzerorientierten KI-Produkten suchen.