اختبار الفهم
تنظيم صفحاتك في مجموعات
يمكنك حفظ المحتوى وتصنيفه حسب إعداداتك المفضّلة.
تساعدك الأسئلة التالية في تعزيز فهمك لمفاهيم تعلُّم الآلة الأساسية.
القدرة التنبؤية
يتم تدريب نماذج تعلُّم الآلة المراقَب باستخدام مجموعات بيانات تتضمّن أمثلة مصنَّفة. يتعلّم النموذج كيفية توقّع التصنيف من الميزات. ومع ذلك، لا تتمتّع كل ميزة في مجموعة البيانات بقدرة توقّعية. في بعض الحالات، لا تعمل سوى بضع ميزات كعوامل تنبؤية للتصنيف. في مجموعة البيانات أدناه، استخدِم السعر كتصنيف
والأعمدة المتبقية كميزات.
ما هي الميزات الثلاث التي تعتقد أنّها من أهم المؤشرات التي تحدّد سعر السيارة؟
Make_model, year, miles.
من المرجّح أن تكون العلامة التجارية والطراز والسنة والمسافة المقطوعة من أقوى المؤشرات على سعر السيارة.
اللون والارتفاع والطراز
لا تشكّل كلّ من ارتفاع السيارة ولونها مؤشّرًا قويًا على سعرها.
الأميال وناقل الحركة والعلامة التجارية والطراز
لا يُعدّ ناقل الحركة عاملاً رئيسيًا في تحديد السعر.
Tire_size وwheel_base وyear
لا يشكّل حجم الإطارات وقاعدة العجلات مؤشرات قوية لتوقّع سعر السيارة.
التعلّم الموجّه وغير الموجّه
استنادًا إلى المشكلة، ستستخدم إما أسلوبًا خاضعًا للإشراف أو غير خاضع للإشراف.
على سبيل المثال، إذا كنت تعرف مسبقًا القيمة أو الفئة التي تريد توقّعها، ستستخدم التعلّم الخاضع للإشراف. ومع ذلك، إذا أردت معرفة ما إذا كانت مجموعة البيانات تتضمّن أي تقسيمات أو مجموعات من الأمثلة ذات الصلة، يمكنك استخدام التعلّم غير الموجّه.
لنفترض أنّ لديك مجموعة بيانات مستخدمين لموقع إلكتروني للتسوّق، وأنّها تحتوي على الأعمدة التالية:
إذا أردت فهم أنواع المستخدمين الذين يزورون الموقع الإلكتروني، هل ستستخدم التعلّم الخاضع للإشراف أو غير الخاضع للإشراف؟
التعلّم غير الموجَّه
بما أنّنا نريد أن يجمع النموذج مجموعات من العملاء ذوي الصلة،
سنستخدم التعلّم غير الموجَّه. بعد أن يصنّف النموذج المستخدمين في مجموعات، ننشئ أسماء خاصة لكل مجموعة، مثل "الباحثون عن الخصومات" و"الباحثون عن الصفقات" و"المتصفّحون" و"المستخدمون الأوفياء" و"المستخدمون العشوائيون".
التعلم الخاضع للإشراف لأنّني أحاول التنبؤ بالفئة التي ينتمي إليها المستخدم.
في التعلّم الموجّه، يجب أن تحتوي مجموعة البيانات على التصنيف الذي تحاول توقّعه. لا يتضمّن مجموعة البيانات تصنيفًا يشير إلى فئة من المستخدمين.
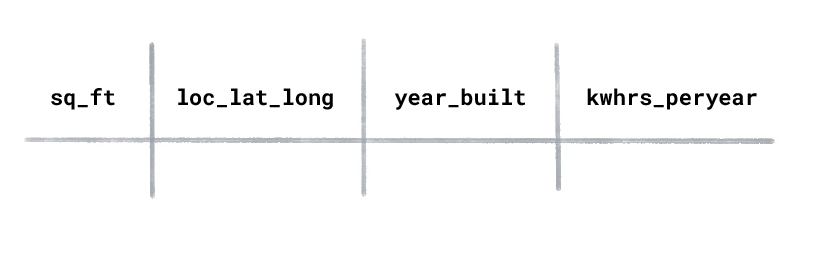
لنفترض أنّ لديك مجموعة بيانات عن استهلاك الطاقة في المنازل تتضمّن الأعمدة التالية:
ما هو نوع تعلُّم الآلة الذي ستستخدمه لتوقّع عدد كيلوواط الساعات المستخدَمة سنويًا في منزل تم إنشاؤه حديثًا؟
التعلّم الخاضع للإشراف
يتم تدريب التعلّم الموجَّه على أمثلة مصنَّفة. في مجموعة البيانات هذه، سيكون "عدد كيلوواط ساعة المستخدَمة في السنة" هو التصنيف لأنّ هذه هي القيمة التي تريد أن يتوقّعها النموذج. ستكون الميزات "المساحة المربعة" و"الموقع الجغرافي" و"عام الإنشاء".
التعلّم غير الموجَّه
يستخدم التعلّم غير الموجَّه أمثلة غير مصنَّفة. في هذا المثال، ستكون التسمية هي "كيلوواط ساعة مستخدَمة في السنة" لأنّ هذه هي القيمة التي تريد أن يتوقّعها النموذج.
لنفترض أنّ لديك مجموعة بيانات رحلات جوية تتضمّن الأعمدة التالية:
إذا أردت توقّع تكلفة تذكرة طائرة، هل ستستخدم الانحدار أو التصنيف؟
الانحدار
الناتج الذي يصدره نموذج الانحدار هو قيمة رقمية.
التصنيف
يكون الناتج الذي يصدره نموذج التصنيف قيمة منفصلة،
عادةً ما تكون كلمة. في هذه الحالة، تكون تكلفة تذكرة الطائرة قيمة رقمية.
استنادًا إلى مجموعة البيانات، هل يمكنك تدريب نموذج تصنيف لتصنيف تكلفة تذكرة طائرة على أنّها "مرتفعة" أو "متوسطة" أو "منخفضة"؟
نعم، ولكن علينا أولاً تحويل القيم الرقمية في العمود airplane_ticket_cost إلى قيم فئوية.
من الممكن إنشاء نموذج تصنيف من مجموعة البيانات.
يمكنك اتّخاذ إجراء مشابه لما يلي:
تعرض هذه السمة متوسط تكلفة تذكرة من مطار المغادرة إلى مطار الوصول.
حدِّد الحدود الدنيا التي تشكّل "مرتفع" و"متوسط" و "منخفض".
قارِن التكلفة المتوقّعة بالحدود الدنيا والعليا، ثم اعرض الفئة التي تندرج ضمنها القيمة.
لا، لا يمكن إنشاء نموذج تصنيف. قيم airplane_ticket_cost رقمية وليست فئوية.
وببعض الجهد، يمكنك إنشاء نموذج تصنيف.
لا، فنماذج التصنيف تتنبأ بفئتين فقط، مثل spam أو not_spam. سيحتاج هذا النموذج إلى توقّع ثلاث فئات.
يمكن لنماذج التصنيف التنبؤ بفئات متعددة. ويُطلق عليها اسم نماذج التصنيف المتعدد الفئات.
التدريب والتقييم
بعد تدريب النموذج، نقيّمه باستخدام مجموعة بيانات تتضمّن أمثلة مصنّفة ونقارن القيمة المتوقّعة للنموذج بالقيمة الفعلية للتصنيف.
اختَر أفضل إجابتَين للسؤال.
إذا كانت توقّعات النموذج بعيدة عن الواقع، ما الذي يمكنك فعله لتحسينها؟
أعِد تدريب النموذج، ولكن استخدِم فقط الميزات التي تعتقد أنّها تتمتّع بأقوى قدرة على التنبؤ بالتصنيف.
يمكن أن يؤدي إعادة تدريب النموذج باستخدام عدد أقل من الميزات، ولكن مع ميزات ذات قدرة تنبؤية أكبر، إلى إنشاء نموذج يقدم توقعات أفضل.
لا يمكنك إصلاح نموذج تكون توقّعاته بعيدة عن الواقع.
من الممكن إصلاح نموذج تكون توقّعاته غير دقيقة، إذ تتطلّب معظم النماذج عدة جولات من التدريب إلى أن تقدّم توقّعات مفيدة.
أعِد تدريب النموذج باستخدام مجموعة بيانات أكبر وأكثر تنوّعًا.
يمكن للنماذج المدرَّبة على مجموعات بيانات تتضمّن المزيد من الأمثلة ونطاقًا أوسع من القيم أن تقدّم توقّعات أفضل لأنّ النموذج يتضمّن حلاً عامًا أفضل للعلاقة بين الميزات والتصنيف.
جرِّب أسلوب تدريب مختلفًا. على سبيل المثال، إذا كنت تستخدم أسلوبًا خاضعًا للإشراف، جرِّب أسلوبًا غير خاضع للإشراف.
ولن يؤدي اتّباع نهج تدريب مختلف إلى تقديم تنبؤات أفضل.
أنت الآن جاهز لاتخاذ الخطوة التالية في رحلة تعلُّم الآلة:
تاريخ التعديل الأخير: 2026-01-05 (حسب التوقيت العالمي المتفَّق عليه)
[[["يسهُل فهم المحتوى.","easyToUnderstand","thumb-up"],["ساعَدني المحتوى في حلّ مشكلتي.","solvedMyProblem","thumb-up"],["غير ذلك","otherUp","thumb-up"]],[["لا يحتوي على المعلومات التي أحتاج إليها.","missingTheInformationINeed","thumb-down"],["الخطوات معقدة للغاية / كثيرة جدًا.","tooComplicatedTooManySteps","thumb-down"],["المحتوى قديم.","outOfDate","thumb-down"],["ثمة مشكلة في الترجمة.","translationIssue","thumb-down"],["مشكلة في العيّنات / التعليمات البرمجية","samplesCodeIssue","thumb-down"],["غير ذلك","otherDown","thumb-down"]],["تاريخ التعديل الأخير: 2026-01-05 (حسب التوقيت العالمي المتفَّق عليه)"],[],[]]