Les questions suivantes vous aideront à consolider votre compréhension des concepts de base du ML.
Pouvoir prédictif
Les modèles de ML supervisé sont entraînés à l'aide d'ensembles de données contenant des exemples étiquetés. Le modèle
apprend à prédire l'étiquette à partir des caractéristiques. Toutefois, toutes les caractéristiques d'un ensemble de données n'ont pas de pouvoir prédictif. Dans certains cas, seules quelques caractéristiques agissent comme
des prédicteurs de l'étiquette. Dans l'ensemble de données ci-dessous, utilisez le prix comme étiquette
et les colonnes restantes comme caractéristiques.

Selon vous, quelles sont les trois caractéristiques les plus susceptibles de prédire le prix d'une voiture
?
Marque_modèle, année, kilomètres
La marque/le modèle, l'année et le kilométrage d'une voiture sont probablement parmi les
meilleurs prédicteurs de son prix.
Couleur, hauteur, marque_modèle
La hauteur et la couleur d'une voiture ne sont pas de bons prédicteurs de son
prix.
Kilomètres, boîte_de_vitesse, marque_modèle
La boîte de vitesses n'est pas un prédicteur principal du prix.
Taille_des_pneus, empattement, année
La taille des pneus et l'empattement ne sont pas de bons prédicteurs du prix d'une voiture.
Apprentissage supervisé et non supervisé
En fonction du problème, vous utiliserez une approche supervisée ou non supervisée.
Par exemple, si vous connaissez à l'avance la valeur ou la catégorie que vous souhaitez prédire,
vous utiliserez l'apprentissage supervisé. Toutefois, si vous souhaitez savoir si votre ensemble de données
contient des segmentations ou des regroupements d'exemples associés, vous utiliserez
l'apprentissage non supervisé.
Supposons que vous disposiez d'un ensemble de données d'utilisateurs pour un site Web de vente en ligne, et qu'il
contienne les colonnes suivantes :

Si vous souhaitez comprendre les types d'utilisateurs qui visitent le site,
utiliserez-vous l'apprentissage supervisé ou non supervisé ?
Apprentissage non supervisé
Comme nous voulons que le modèle regroupe des clients associés,
nous utiliserons l'apprentissage non supervisé. Une fois que le modèle aura regroupé les utilisateurs,
nous créerons nos propres noms pour chaque groupe, par exemple
« chercheurs de réductions », « chasseurs de bonnes affaires », « surfeurs », « fidèles »
et « promeneurs ».
Apprentissage supervisé, car j'essaie de prédire la classe
à laquelle appartient un utilisateur.
Dans l'apprentissage supervisé, l'ensemble de données doit contenir l'étiquette que vous essayez de prédire. Dans l'ensemble de données, aucune étiquette ne fait référence à une
catégorie d'utilisateur.
Supposons que vous disposiez d'un ensemble de données sur la consommation d'énergie pour les maisons avec les colonnes suivantes :
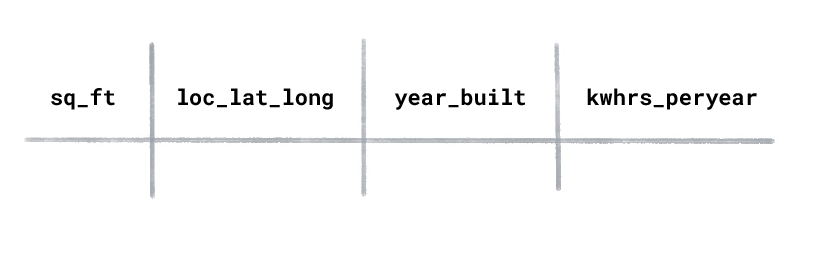
Quel type de ML utiliseriez-vous pour prédire le nombre de kilowattheures utilisés par
an pour une maison nouvellement construite ?
Apprentissage supervisé
L'apprentissage supervisé s'entraîne sur des exemples étiquetés. Dans cet ensemble de données
« kilowattheures utilisés par an » serait l’étiquette, car il s’agit de la
valeur que vous souhaitez que le modèle prédise. Les caractéristiques seraient
"superficie", "emplacement" et "année de construction".
Apprentissage non supervisé
L'apprentissage non supervisé utilise des exemples non étiquetés. Dans cet exemple,
"kilowattheures utilisés par an" serait l'étiquette, car il s'agit de la
valeur que vous souhaitez que le modèle prédise.
Supposons que vous disposiez d'un ensemble de données sur les vols avec les colonnes suivantes :

Si vous souhaitez prédire le coût d'un billet d'avion, utiliserez-vous
la régression ou la classification ?
Régression
La sortie d'un modèle de régression est une valeur numérique.
Classification
La sortie d'un modèle de classification est une valeur discrète,
généralement un mot. Dans ce cas, le coût d'un billet d'avion est
une valeur numérique.
En fonction de l'ensemble de données, pourriez-vous entraîner un modèle de classification
pour classer le coût d'un billet d'avion comme
"élevé," "moyen," ou "faible" ?
Oui, mais nous devons d'abord convertir les valeurs numériques de la colonne
airplane_ticket_cost en valeurs catégorielles.
Il est possible de créer un modèle de classification à partir de l'ensemble de données.
Vous pouvez procéder comme suit :
- Recherchez le coût moyen d'un billet de l'aéroport de départ à
l'aéroport de destination.
- Déterminez les seuils qui constitueraient les valeurs "élevée", "moyenne"
et "faible".
- Comparez le coût prédit aux seuils et générez la
catégorie dans laquelle la valeur se situe.
Non, il n'est pas possible de créer un modèle de classification. Les valeurs
airplane_ticket_cost sont numériques et non catégorielles.
Avec un peu de travail, vous pouvez créer un modèle de classification
model.
Non. Les modèles de classification ne prédisent que deux catégories, comme
spam ou not_spam. Ce modèle devrait prédire
trois catégories.
Les modèles de classification peuvent prédire plusieurs catégories. On les appelle des modèles de classification multiclasse.
Entraînement et évaluation
Une fois que nous avons entraîné un modèle, nous l'évaluons à l'aide d'un ensemble de données contenant des exemples étiquetés
et comparons la valeur prédite du modèle à la valeur réelle de l'étiquette.
Sélectionnez les deux meilleures réponses à la question.
Si les prédictions du modèle sont très éloignées, que pouvez-vous faire pour les améliorer
?
Réentraînez le modèle, mais n'utilisez que les caractéristiques qui, selon vous, ont le
plus fort pouvoir prédictif pour l'étiquette.
Le réentraînement du modèle avec moins de caractéristiques, mais avec un pouvoir prédictif plus élevé
peut produire un modèle qui fait de meilleures prédictions
Vous ne pouvez pas corriger un modèle dont les prédictions sont très éloignées.
Il est possible de corriger un modèle dont les prédictions sont erronées. La plupart des modèles
nécessitent plusieurs cycles d'entraînement avant de faire
des prédictions utiles.
Réentraînez le modèle à l'aide d'un ensemble de données plus volumineux et plus diversifié.
Les modèles entraînés sur des ensembles de données comportant plus d'exemples et un plus large éventail de
valeurs peuvent produire de meilleures prédictions, car le modèle dispose d'une meilleure
solution généralisée pour la relation entre les caractéristiques et
l'étiquette.
Essayez une autre approche d'entraînement. Par exemple, si vous avez utilisé une
approche supervisée, essayez une approche non supervisée.
Une approche d'entraînement différente ne produirait pas de meilleures
prédictions.
Vous êtes maintenant prêt à passer à l'étape suivante de votre parcours ML :
Machine Learning Crash Course Si vous êtes
prêt à adopter une approche pratique et approfondie pour en savoir plus sur le ML.
Cadrage du problème. Si vous recherchez
une approche éprouvée pour créer des modèles de ML et éviter les pièges courants.
People + AI Guidebook Si vous recherchez
des conseils pratiques pour concevoir des produits d'IA centrés sur l'humain.