בדף הזה מופיעים מונחים ממילון המונחים בנושא מדדים. כאן אפשר לראות את כל המונחים במילון המונחים.
A
דיוק
מספר התחזיות הנכונות של הסיווג חלקי המספר הכולל של התחזיות. כלומר:
לדוגמה, למודל שביצע 40 חיזויים נכונים ו-10 חיזויים לא נכונים יהיה דיוק של:
סיווג בינארי מספק שמות ספציפיים לקטגוריות השונות של תחזיות נכונות ותחזיות שגויות. לכן, נוסחת הדיוק לסיווג בינארי היא:
where:
- TP הוא מספר החיוביים האמיתיים (תחזיות נכונות).
- TN הוא מספר השליליים האמיתיים (חיזויים נכונים).
- FP הוא מספר החיוביים הכוזבים (תחזיות שגויות).
- FN הוא מספר השליליים הכוזבים (תחזיות שגויות).
השוו בין דיוק לבין דיוק והחזרה.
מידע נוסף זמין במאמר סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים בסדנה ללמידת מכונה.
השטח מתחת לעקומת ה-PR
מידע נוסף על PR AUC (השטח מתחת לעקומת ה-PR)
שטח מתחת לעקומת ROC
מידע נוסף על AUC (השטח מתחת לעקומת ROC)
AUC (השטח מתחת לעקומת ה-ROC)
מספר בין 0.0 ל-1.0 שמייצג את היכולת של מודל סיווג בינארי להפריד בין סיווגים חיוביים לבין סיווגים שליליים. ככל שערך ה-AUC קרוב יותר ל-1.0, כך יכולת המודל להפריד בין המחלקות טובה יותר.
לדוגמה, באיור הבא מוצג מודל סיווג שמפריד בצורה מושלמת בין מחלקות חיוביות (אליפסות ירוקות) לבין מחלקות שליליות (מלבנים סגולים). למודל המושלם הלא-מציאותי הזה יש AUC של 1.0:

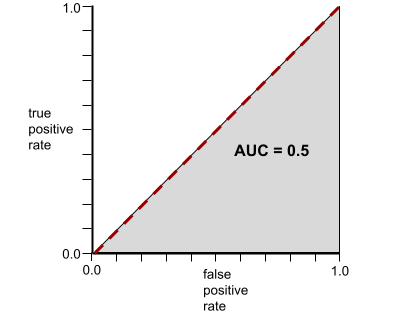
לעומת זאת, באיור הבא מוצגות התוצאות של מודל סיווג שיצר תוצאות אקראיות. המודל הזה כולל AUC של 0.5:

כן, למודל הקודם יש AUC של 0.5, ולא 0.0.
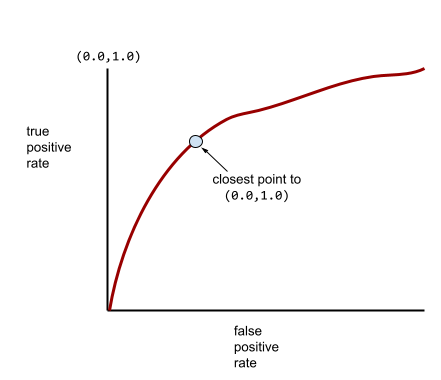
רוב הדגמים נמצאים איפשהו בין שני הקצוות. לדוגמה, המודל הבא מפריד בין ערכים חיוביים לשליליים במידה מסוימת, ולכן ערך ה-AUC שלו הוא בין 0.5 ל-1.0:

הפונקציה AUC מתעלמת מכל ערך שמגדירים עבור classification threshold. במקום זאת, המדד AUC מתחשב בכל ספי הסיווג האפשריים.
כדי לקבל מידע על הקשר בין AUC לבין עקומות ROC, לוחצים על הסמל.
הערך AUC מייצג את השטח מתחת לעקומת ROC. לדוגמה, עקומת ה-ROC של מודל שמפריד בצורה מושלמת בין ערכים חיוביים לערכים שליליים נראית כך:
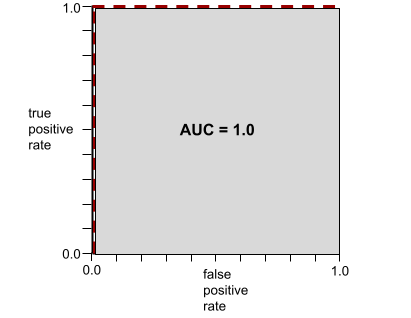
ה-AUC הוא השטח של האזור האפור באיור שלמעלה. במקרה החריג הזה, השטח הוא פשוט האורך של האזור האפור (1.0) כפול הרוחב של האזור האפור (1.0). לכן, המכפלה של 1.0 ו-1.0 היא 1.0 בדיוק, שהוא הציון הכי גבוה שאפשר לקבל ב-AUC.
לעומת זאת, עקומת ה-ROC של מודל סיווג שלא יכול להפריד בין מחלקות בכלל נראית כך. שטח האזור האפור הוא 0.5.
עקומת ROC אופיינית יותר נראית בערך כך:
חישוב השטח מתחת לעקומה הזו באופן ידני הוא תהליך מייגע, ולכן בדרך כלל תוכנה מחשבת את רוב ערכי ה-AUC.
מידע נוסף זמין במאמר בנושא סיווג: ROC ו-AUC בקורס המקוצר בנושא למידת מכונה.
דיוק ממוצע ב-k
מדד לסיכום הביצועים של מודל בהנחיה יחידה שמפיקה תוצאות מדורגות, כמו רשימה ממוספרת של המלצות לספרים. הדיוק הממוצע ב-k הוא, ובכן, הממוצע של ערכי הדיוק ב-k לכל תוצאה רלוונטית. לכן, הנוסחה לחישוב הדיוק הממוצע ב-k היא:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- \(n\) הוא מספר הפריטים הרלוונטיים ברשימה.
השוואה להיזכרות ב-k.
B
baseline
מודל שמשמש כנקודת השוואה כדי לבדוק את הביצועים של מודל אחר (בדרך כלל מורכב יותר). לדוגמה, מודל רגרסיה לוגיסטית יכול לשמש כבסיס טוב למודל עמוק.
בבעיה מסוימת, ה-Baseline עוזר למפתחי מודלים לכמת את הביצועים המינימליים הצפויים שמודל חדש צריך להשיג כדי שהמודל החדש יהיה שימושי.
שאלות בוליאניות (BoolQ)
מערך נתונים להערכת רמת המיומנות של LLM במענה לשאלות שדורשות תשובה של כן או לא. כל אחת מהבעיות בקבוצת הנתונים כוללת שלושה רכיבים:
- שאילתה
- קטע שממנו אפשר להסיק את התשובה לשאילתה.
- התשובה הנכונה, שהיא כן או לא.
לדוגמה:
- שאילתה: האם יש תחנות כוח גרעיניות במישיגן?
- קטע: …three nuclear power plants supply Michigan with about 30% of its electricity.
- תשובה נכונה: כן
החוקרים אספו את השאלות מתוך שאילתות אנונימיות ומצטברות בחיפוש Google, ואז השתמשו בדפי ויקיפדיה כדי לבסס את המידע.
מידע נוסף זמין במאמר BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ הוא רכיב של SuperGLUE ensemble.
BoolQ
קיצור לשאלות בוליאניות.
C
CB
קיצור של CommitmentBank.
ציון F של N-gram של תווים (ChrF)
מדד להערכת מודלים של תרגום אוטומטי. ציון F של N-גרמות של תווים קובע את מידת החפיפה בין N-גרמות בטקסט ההפניה לבין ה-N-גרמות בטקסט שנוצר על ידי מודל ML.
המדד 'ציון F של N-גרם של תווים' דומה למדדים במשפחות ROUGE ו-BLEU, אבל:
- המדד Character N-gram F-score פועל על N-grams של תווים.
- המדדים ROUGE ו-BLEU פועלים על N-gram של מילים או על אסימונים.
בחירת חלופות סבירות (COPA)
מערך נתונים להערכת היכולת של מודל LLM לזהות את התשובה הטובה יותר מבין שתי תשובות חלופיות להנחת יסוד. כל אחת מהבעיות במערך הנתונים מורכבת משלושה רכיבים:
- הנחת יסוד, שהיא בדרך כלל הצהרה שאחריה מופיעה שאלה
- שתי תשובות אפשריות לשאלה שמוצגת בפריט, שאחת מהן נכונה והשנייה לא נכונה
- התשובה הנכונה
לדוגמה:
- הנחת יסוד: האיש שבר את הבוהן. מה הייתה הסיבה לכך?
- תשובות אפשריות:
- יש לו חור בגרב.
- הוא הפיל פטיש על הרגל שלו.
- תשובה נכונה: 2
COPA הוא רכיב של SuperGLUE ensemble.
CommitmentBank (CB)
מערך נתונים להערכת רמת המיומנות של מודל LLM בקביעה אם מחבר הקטע מאמין לסעיף יעד בתוך הקטע. כל רשומה במערך הנתונים מכילה:
- פסקה
- סעיף יעד בקטע הזה
- ערך בוליאני שמציין אם מחבר הקטע מאמין שהסעיף
לדוגמה:
- פסקה: What fun to hear Artemis laugh. היא ילדה כל כך רצינית. לא ידעתי שיש לה חוש הומור.
- סעיף היעד: she had a sense of humor
- Boolean: True, כלומר המחבר מאמין שהסעיף הממוקד
CommitmentBank הוא רכיב של SuperGLUE ensemble.
COPA
קיצור של בחירת חלופות סבירות.
עלות
מילה נרדפת ל-loss.
הוגנות קונטרה-פקטואלית
מדד הוגנות שבודק אם מודל סיווג מפיק את אותה תוצאה עבור אדם מסוים כמו עבור אדם אחר שזהה לו, למעט מאפיינים רגישים מסוימים. הערכה של מודל סיווג מבחינת הוגנות קונטרה-פקטואלית היא שיטה אחת לחשיפת מקורות פוטנציאליים של הטיה במודל.
מידע נוסף זמין במאמרים הבאים:
- הוגנות: הוגנות מנוגדת לעובדות בקורס המקוצר על למידת מכונה.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
אנטרופיה צולבת
הכללה של Log Loss לבעיות סיווג מרובות מחלקות. האנטרופיה הצולבת מכמתת את ההבדל בין שני התפלגויות הסתברות. מידע נוסף זמין במאמר בנושא perplexity.
פונקציית התפלגות מצטברת (CDF)
פונקציה שמגדירה את התדירות של דגימות שקטנות מערך יעד או שוות לו. לדוגמה, נניח שיש התפלגות נורמלית של ערכים רציפים. פונקציית CDF מראה שכ-50% מהדגימות צריכות להיות קטנות מהממוצע או שוות לו, וכ-84% מהדגימות צריכות להיות קטנות מהממוצע או שוות לו בתוספת סטיית תקן אחת.
D
שוויון דמוגרפי
מדד הוגנות שמתקיים אם תוצאות הסיווג של מודל לא תלויות במאפיין רגיש נתון.
לדוגמה, אם גם אנשי ליליפוט וגם אנשי ברובדינגנאג מגישים בקשה להתקבל לאוניברסיטת גלובדובדריב, שוויון דמוגרפי מושג אם אחוז אנשי ליליפוט שהתקבלו זהה לאחוז אנשי ברובדינגנאג שהתקבלו, ללא קשר לשאלה אם קבוצה אחת מוסמכת יותר בממוצע מהקבוצה השנייה.
ההגדרה הזו שונה מסיכויים שווים ומשוויון הזדמנויות, שמאפשרות לתוצאות הסיווג הכוללות להיות תלויות במאפיינים רגישים, אבל לא מאפשרות לתוצאות הסיווג של תוויות אמת בסיסית מסוימות להיות תלויות במאפיינים רגישים. במאמר "Attacking discrimination with smarter machine learning" (התמודדות עם אפליה באמצעות למידת מכונה חכמה יותר) מוצג תרשים שממחיש את היתרונות והחסרונות של אופטימיזציה להשגת שוויון דמוגרפי.
מידע נוסף זמין במאמר בנושא הוגנות: שוויון דמוגרפי בקורס המקוצר על למידת מכונה.
E
מרחק בין תנועות של כלי עפר (EMD)
מדד לדמיון היחסי בין שתי התפלגויות. ככל שהמרחק בין המכונות קטן יותר, כך ההתפלגויות דומות יותר.
מרחק עריכה
מדד של מידת הדמיון בין שתי מחרוזות טקסט. בלמידת מכונה, מרחק העריכה שימושי מהסיבות הבאות:
- קל לחשב את מרחק העריכה.
- מרחק העריכה יכול להשוות בין שתי מחרוזות שידוע שהן דומות זו לזו.
- מרחק עריכה יכול לקבוע את מידת הדמיון בין מחרוזות שונות למחרוזת נתונה.
יש כמה הגדרות של מרחק עריכה, וכל אחת מהן משתמשת בפעולות שונות על מחרוזות. דוגמה מופיעה במאמר בנושא מרחק לבנשטיין.
פונקציית התפלגות מצטברת אמפירית (eCDF או EDF)
פונקציית התפלגות מצטברת שמבוססת על מדידות אמפיריות ממערך נתונים אמיתי. הערך של הפונקציה בכל נקודה לאורך ציר ה-x הוא החלק של התצפיות במערך הנתונים שקטן מהערך שצוין או שווה לו.
אנטרופיה
ב תורת המידע, אנטרופיה היא מדד למידת חוסר הצפיות של התפלגות הסתברויות. לחלופין, אנטרופיה מוגדרת גם ככמות המידע שכל דוגמה מכילה. הפיזור הוא בעל האנטרופיה הגבוהה ביותר האפשרית כשכל הערכים של משתנה אקראי הם בעלי סבירות שווה.
הנוסחה לחישוב האנטרופיה של קבוצה עם שני ערכים אפשריים, 0 ו-1 (לדוגמה, התוויות בבעיית סיווג בינארי), היא:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
where:
- H היא האנטרופיה.
- p הוא החלק היחסי של הדוגמאות מסוג '1'.
- q הוא החלק של הדוגמאות עם הערך '0'. הערה: q = (1 - p)
- הערך של log הוא בדרך כלל log2. במקרה הזה, יחידת האנטרופיה היא ביט.
לדוגמה, נניח את הדברים הבאים:
- 100 דוגמאות מכילות את הערך '1'
- 300 דוגמאות מכילות את הערך '0'
לכן, ערך האנטרופיה הוא:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 bits per example
קבוצה מאוזנת לחלוטין (לדוגמה, 200 ערכים של '0' ו-200 ערכים של '1') תהיה בעלת אנטרופיה של 1.0 ביט לכל דוגמה. ככל שקבוצה הופכת ללא מאוזנת יותר, האנטרופיה שלה מתקרבת ל-0.0.
בעצי החלטה, האנטרופיה עוזרת לגבש רווח מידע כדי לעזור למפצל לבחור את התנאים במהלך הצמיחה של עץ החלטה לסיווג.
השוואה של האנטרופיה עם:
- מדד גיני לאי-טוהר
- פונקציית האובדן cross-entropy
אנטרופיה נקראת לעיתים קרובות האנטרופיה של שאנון.
מידע נוסף זמין במאמר Exact splitter for binary classification with numerical features בקורס Decision Forests.
שוויון הזדמנויות
מדד הוגנות להערכת היכולת של המודל לחזות את התוצאה הרצויה באופן שווה לכל הערכים של מאפיין רגיש. במילים אחרות, אם התוצאה הרצויה של מודל היא הסיווג החיובי, המטרה היא ששיעור החיוביים האמיתיים יהיה זהה לכל הקבוצות.
שוויון הזדמנויות קשור לסיכויים שווים, שמשמעותו שגם שיעורי החיוביים האמיתיים וגם שיעורי החיוביים הכוזבים זהים בכל הקבוצות.
נניח שאוניברסיטת גלאבדאבדריב מקבלת לתוכנית לימודים קפדנית במתמטיקה גם ליליפוטים וגם ברובדינגנאגים. בתי הספר התיכוניים של ליליפוט מציעים תוכנית לימודים מקיפה של שיעורי מתמטיקה, ורוב התלמידים עומדים בדרישות של התוכנית האוניברסיטאית. בבתי הספר התיכוניים של ברובדינגנאג לא מוצעים שיעורי מתמטיקה בכלל, וכתוצאה מכך, הרבה פחות תלמידים עומדים בדרישות. התנאי לשוויון הזדמנויות מתקיים לגבי התווית המועדפת 'התקבל' בהתייחס ללאום (ליליפוטי או ברובדינגנאגי) אם לתלמידים שעומדים בדרישות יש סיכוי שווה להתקבל, בלי קשר להיותם ליליפוטים או ברובדינגנאגים.
לדוגמה, נניח ש-100 אנשים מליליפוט ו-100 אנשים מברובדינגנאג הגישו בקשה להתקבל לאוניברסיטת גלובדאבדריב, וההחלטות לגבי הקבלה מתקבלות באופן הבא:
טבלה 1. מועמדים קטנים (90% מהם כשירים)
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 45 | 3 |
| נדחה | 45 | 7 |
| סה"כ | 90 | 10 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 45/90 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 7/10 = 70% האחוז הכולל של סטודנטים מליליפוט שהתקבלו: (45+3)/100 = 48% |
||
טבלה 2. מועמדים גדולים מאוד (10% כשירים):
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 5 | 9 |
| נדחה | 5 | 81 |
| סה"כ | 10 | 90 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 5/10 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 81/90 = 90% אחוז הסטודנטים הכולל מברובדינגנאג שהתקבלו: (5+9)/100 = 14% |
||
הדוגמאות הקודמות עומדות בדרישה לשוויון הזדמנויות לקבלה של תלמידים שעומדים בדרישות, כי גם לליליפוטים וגם לברובדינגנאגים שעומדים בדרישות יש סיכוי של 50% להתקבל.
למרות שהשוויון בהזדמנויות מתקיים, שני מדדי ההוגנות הבאים לא מתקיימים:
- שוויון דמוגרפי: שיעורי הקבלה של ליליפוטים ושל ברובדינגנאגים לאוניברסיטה שונים; 48% מהסטודנטים הליליפוטים מתקבלים, אבל רק 14% מהסטודנטים הברובדינגנאגים מתקבלים.
- סיכויים שווים: למרות שלתלמידים זכאים מליליפוט ולתלמידים זכאים מברובדינגנאג יש סיכוי שווה להתקבל, המגבלה הנוספת שלפיה לתלמידים לא זכאים מליליפוט ולתלמידים לא זכאים מברובדינגנאג יש סיכוי שווה להידחות לא מתקיימת. שיעור הדחייה של תושבי ליליפוט לא כשירים הוא 70%, לעומת 90% של תושבי ברובדינגנאג לא כשירים.
מידע נוסף זמין במאמר הוגנות: שוויון הזדמנויות בקורס Machine Learning Crash Course.
הסתברות שווה
מדד הוגנות שנועד להעריך אם מודל חוזה תוצאות באותה רמת דיוק לכל הערכים של מאפיין רגיש ביחס לסיווג חיובי ולסיווג שלילי – ולא רק ביחס לסיווג אחד. במילים אחרות, גם שיעור החיוביים האמיתיים וגם שיעור השליליים הכוזבים צריכים להיות זהים בכל הקבוצות.
הסיכויים שווים קשורים לשוויון הזדמנויות, שמתמקד רק בשיעורי השגיאות עבור סיווג יחיד (חיובי או שלילי).
לדוגמה, נניח שאוניברסיטת גלובדובדריב מקבלת לתוכנית לימודים קפדנית במתמטיקה גם ליליפוטים וגם ברובדינגנאגים. בתי הספר התיכוניים של ליליפוט מציעים תוכנית לימודים מקיפה של שיעורי מתמטיקה, ורוב התלמידים עומדים בדרישות של התוכנית האוניברסיטאית. בבתי הספר התיכוניים בברובדינגנאג לא מוצעים שיעורי מתמטיקה בכלל, וכתוצאה מכך, הרבה פחות תלמידים עומדים בדרישות. התנאי של סיכויים שווים מתקיים אם למועמדים יש סיכוי שווה להתקבל לתוכנית אם הם עומדים בדרישות, וסיכוי שווה להידחות אם הם לא עומדים בדרישות, בלי קשר לגודל שלהם.
נניח ש-100 אנשים מליליפוט ו-100 אנשים מברובדינגנאג הגישו בקשה להתקבל לאוניברסיטת גלובדאבדריב, וההחלטות לגבי הקבלה מתקבלות באופן הבא:
טבלה 3. מועמדים קטנים (90% מהם כשירים)
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 45 | 2 |
| נדחה | 45 | 8 |
| סה"כ | 90 | 10 |
|
אחוז התלמידים שעומדים בדרישות והתקבלו: 45/90 = 50% אחוז התלמידים שלא עומדים בדרישות ונדחו: 8/10 = 80% האחוז הכולל של תלמידי ליליפוט שהתקבלו: (45+2)/100 = 47% |
||
טבלה 4. מועמדים גדולים מאוד (10% כשירים):
| כשירים | לא מתאים | |
|---|---|---|
| התקבל | 5 | 18 |
| נדחה | 5 | 72 |
| סה"כ | 10 | 90 |
|
אחוז הסטודנטים שעומדים בדרישות שהתקבלו: 5/10 = 50% אחוז הסטודנטים שלא עומדים בדרישות שנדחו: 72/90 = 80% אחוז הסטודנטים הכולל מברובדינגנאג שהתקבלו: (5+18)/100 = 23% |
||
התנאי של סיכויים שווים מתקיים כי לסטודנטים מליליפוט ומברובדינגנאג שעומדים בדרישות יש סיכוי של 50% להתקבל, ולסטודנטים מליליפוט ומברובדינגנאג שלא עומדים בדרישות יש סיכוי של 80% להידחות.
ההגדרה הפורמלית של סיכויי הצלחה שווים מופיעה במאמר "Equality of Opportunity in Supervised Learning" (שוויון הזדמנויות בלמידה מפוקחת) באופן הבא: "המאפיין המנבא Ŷ עומד בדרישות של סיכויי הצלחה שווים ביחס למאפיין המוגן A ולתוצאה Y אם Ŷ ו-A הם בלתי תלויים, בהינתן Y".
evals
משמש בעיקר כקיצור להערכות של מודלים גדולים של שפה. באופן כללי, evals הוא קיצור לכל סוג של הערכה.
הערכה
התהליך של מדידת האיכות של מודל או השוואה בין מודלים שונים.
כדי להעריך מודל של למידת מכונה מבוקרת, בדרך כלל משווים אותו לקבוצת נתונים לתיקוף ולקבוצת נתונים לבדיקה. הערכה של מודל שפה גדול כוללת בדרך כלל הערכות רחבות יותר של איכות ובטיחות.
התאמה מדויקת
מדד של הכול או כלום, שבו הפלט של המודל תואם לערך האמת או לטקסט ההפניה בדיוק או שלא תואם בכלל. לדוגמה, אם ערך האמת הוא orange, הפלט היחיד של המודל שעומד בדרישות של התאמה מדויקת הוא orange.
התאמה מדויקת יכולה גם להעריך מודלים שהפלט שלהם הוא רצף (רשימה מדורגת של פריטים). באופן כללי, התאמה מדויקת מחייבת שהרשימה המדורגת שנוצרה תהיה זהה לרשימת האמת; כלומר, כל פריט בשתי הרשימות צריך להיות באותו סדר. עם זאת, אם נתוני האמת הבסיסיים כוללים כמה רצפים נכונים, התאמה מדויקת מחייבת רק שהפלט של המודל יתאים לאחד מהרצפים הנכונים.
סיכום קיצוני (xsum)
מערך נתונים להערכת היכולת של LLM לסכם מסמך יחיד. כל רשומה במערך הנתונים כוללת:
- מסמך שנכתב על ידי British Broadcasting Corporation (BBC).
- סיכום של המסמך במשפט אחד.
פרטים נוספים זמינים במאמר Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
מדד סיווג בינארי מסכם שמסתמך על דיוק וגם על היזכרות. זו הנוסחה:
מדד הוגנות
הגדרה מתמטית של 'הוגנות' שאפשר למדוד. דוגמאות למדדי הוגנות נפוצים:
הרבה מדדים של הוגנות הם בלעדיים הדדית. אפשר לקרוא על כך במאמר בנושא אי-תאימות של מדדים של הוגנות.
תוצאה שלילית שגויה (FN)
דוגמה שבה המודל מנבא בטעות את הסיווג השלילי. לדוגמה, המודל מנבא שהודעת אימייל מסוימת אינה ספאם (הסיווג השלילי), אבל הודעת האימייל הזו היא למעשה ספאם.
שיעור השגיאות השליליות
החלק היחסי של דוגמאות חיוביות אמיתיות שהמודל טעה לגביהן וחיזה את הסיווג השלילי. הנוסחה הבאה משמשת לחישוב שיעור התוצאות השליליות השגויות:
מידע נוסף זמין במאמר ערכי סף ומטריצת בלבול בקורס המקוצר על למידת מכונה.
תוצאה חיובית שגויה (FP)
דוגמה שבה המודל חוזה בטעות את הסיווג החיובי. לדוגמה, המודל חוזה שהודעת אימייל מסוימת היא ספאם (הסיווג החיובי), אבל הודעת האימייל הזו לא ספאם בפועל.
מידע נוסף זמין במאמר ערכי סף ומטריצת בלבול בקורס המקוצר על למידת מכונה.
שיעור התוצאות החיוביות השגויות (FPR)
השיעור של הדוגמאות השליליות בפועל שהמודל טעה בהן וחיזה את הסיווג החיובי. הנוסחה הבאה משמשת לחישוב שיעור התוצאות החיוביות השגויות:
שיעור התוצאות החיוביות השגויות הוא ציר ה-x בעקומת ROC.
מידע נוסף זמין במאמר בנושא סיווג: ROC ו-AUC בקורס המקוצר בנושא למידת מכונה.
חשיבות התכונות
מילה נרדפת לחשיבות משתנה.
מודל בסיס
מודל שעבר אימון מראש גדול מאוד שאומן על קבוצת נתונים לאימון עצומה ומגוונת. מודל בסיס יכול לבצע את שתי הפעולות הבאות:
- להגיב בצורה טובה למגוון רחב של בקשות.
- לשמש כמודל בסיסי לכוונון עדין נוסף או להתאמה אישית אחרת.
במילים אחרות, מודל בסיסי כבר מסוגל לבצע משימות רבות באופן כללי, אבל אפשר להתאים אותו עוד יותר כדי שיהיה שימושי יותר למשימה ספציפית.
fraction of successes
מדד להערכת הטקסט שנוצר על ידי מודל ML. המדד 'חלק ההצלחות' הוא מספר הפלט של הטקסט שנוצר בהצלחה חלקי המספר הכולל של פלט הטקסט שנוצר. לדוגמה, אם מודל שפה גדול יצר 10 בלוקים של קוד, וחמישה מהם היו מוצלחים, אז שיעור ההצלחה יהיה 50%.
למרות שהמדד 'שיעור ההצלחות' שימושי ברוב התחומים בסטטיסטיקה, בלמידת מכונה הוא שימושי בעיקר למדידת משימות שניתן לאמת, כמו יצירת קוד או בעיות מתמטיות.
G
gini impurity
מדד שדומה לאנטרופיה. מפצלים משתמשים בערכים שנגזרים מאי-טוהר גיני או מאנטרופיה כדי ליצור תנאים לסיווג עצי החלטה. הרווח במידע נגזר מאנטרופיה. אין מונח מקביל שמקובל באופן אוניברסלי למדד שנגזר מאי-טוהר של גיני. עם זאת, המדד הזה, שאין לו שם, חשוב בדיוק כמו מדד הרווח במידע.
טומאת ג'יני נקראת גם מדד ג'יני או פשוט ג'יני.
H
ציר שבור
משפחה של פונקציות loss לסיווג שנועדו למצוא את גבול ההחלטה במרחק הכי גדול שאפשר מכל דוגמה לאימון, וכך למקסם את השוליים בין הדוגמאות לבין הגבול. KSVMs משתמשים ב-hinge loss (או בפונקציה קשורה, כמו squared hinge loss). בסיווג בינארי, פונקציית ההפסד של הציר מוגדרת כך:
כאשר y הוא התיוג האמיתי, -1 או +1, ו-y' הוא הפלט הגולמי של מודל הסיווג:
לכן, תרשים של הפסד ציר לעומת (y * y') נראה כך:

I
אי התאמה של מדדי הוגנות
הרעיון שלפיו חלק מהמושגים של הוגנות לא תואמים זה לזה ואי אפשר לספק אותם בו-זמנית. לכן, אין מדד אוניברסלי יחיד לכמותיות של הוגנות שאפשר להחיל על כל בעיות ה-ML.
יכול להיות שזה נשמע מייאש, אבל חוסר התאמה של מדדי הוגנות לא אומר שהמאמצים להשגת הוגנות הם חסרי תועלת. במקום זאת, הוא מציע להגדיר הוגנות בהקשר של בעיה נתונה של למידת מכונה, במטרה למנוע נזקים ספציפיים לתרחישי השימוש שלה.
במאמר "On the (im)possibility of fairness" יש דיון מפורט יותר על חוסר התאימות של מדדי הוגנות.
הוגנות אישית
מדד הוגנות שבודק אם סיווג של אנשים דומים הוא דומה. לדוגמה, יכול להיות שבאקדמיה בברובדינגנאג ירצו להבטיח הוגנות כלפי כל אחד מהתלמידים, ולכן יקפידו על כך שלשני תלמידים עם ציונים זהים וציונים זהים במבחנים סטנדרטיים יהיה סיכוי שווה להתקבל ללימודים.
חשוב לזכור שההוגנות האישית תלויה לחלוטין בהגדרה של 'דמיון' (במקרה הזה, ציונים במבחנים וציונים בלימודים), ויש סיכון ליצירת בעיות חדשות שקשורות להוגנות אם מדד הדמיון לא כולל מידע חשוב (כמו רמת הקושי של תוכנית הלימודים של התלמיד).
במאמר "הוגנות באמצעות מודעות" מופיע דיון מפורט יותר בנושא ההוגנות האישית.
הרווח ממידע
ביערות החלטה, ההפרש בין האנטרופיה של צומת לבין הסכום המשוקלל (לפי מספר הדוגמאות) של האנטרופיה של צמתי הצאצאים שלה. האנטרופיה של צומת היא האנטרופיה של הדוגמאות בצומת הזה.
לדוגמה, נבחן את ערכי האנטרופיה הבאים:
- האנטרופיה של צומת ההורה = 0.6
- האנטרופיה של צומת משני אחד עם 16 דוגמאות רלוונטיות = 0.2
- אנטרופיה של צומת משני אחר עם 24 דוגמאות רלוונטיות = 0.1
לכן, 40% מהדוגמאות נמצאות בצומת צאצא אחד ו-60% נמצאות בצומת הצאצא השני. לכן:
- סכום האנטרופיה המשוקללת של צומתי הצאצא = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
לכן, הרווח מהמידע הוא:
- הרווח במידע = האנטרופיה של צומת האב – סכום האנטרופיה המשוקלל של הצמתים המשניים
- הרווח במידע = 0.6 – 0.14 = 0.46
רוב המסַפְּקִים מנסים ליצור תנאים שממקסמים את הרווח במידע.
הסכמה בין מעריכים
מדד לתדירות שבה מעריכים אנושיים מסכימים ביניהם כשהם מבצעים משימה. אם יש חוסר הסכמה בין הבודקים, יכול להיות שצריך לשפר את ההוראות לביצוע המשימה. נקרא גם הסכמה בין מבארים או מהימנות בין מעריכים. ראו גם את קאפה של כהן, שהוא אחד ממדדי ההסכמה הפופולריים ביותר בין מעריכים.
מידע נוסף זמין במאמר נתונים קטגוריים: בעיות נפוצות בסדנה ללימוד מכונת למידה.
L
הפסד של L1
פונקציית הפסד שמחשבת את הערך המוחלט של ההפרש בין ערכי התוויות בפועל לבין הערכים שהמודל חוזה. לדוגמה, החישוב של הפסד L1 עבור קבוצה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | הערך המוחלט של הדלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = הפסד L1 | ||
ההפסד של L1 פחות רגיש לערכים חריגים מאשר ההפסד של L2.
השגיאה הממוצעת המוחלטת היא ממוצע הפסדי L1 לכל דוגמה.
מידע נוסף זמין במאמר Linear regression: Loss (רגרסיה לינארית: הפסד) בסדרת המאמרים Machine Learning Crash Course (מבוא ללמידת מכונה).
הפסד L2
פונקציית הפסד שמחשבת את ריבוע ההפרש בין ערכי התוויות בפועל לבין הערכים שהמודל חוזה. לדוגמה, כך מחשבים את הפסד L2 עבור קבוצה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | ריבוע של דלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 loss | ||
בגלל ההעלאה בריבוע, פונקציית ההפסד L2 מגדילה את ההשפעה של ערכים חריגים. כלומר, פונקציית ההפסד L2 מגיבה בעוצמה רבה יותר לחיזויים לא טובים מאשר פונקציית ההפסד L1. לדוגמה, הפסד L1 עבור האצווה הקודמת יהיה 8 ולא 16. שימו לב שערך חריג אחד מייצג 9 מתוך 16.
מודלים של רגרסיה משתמשים בדרך כלל בהפסד L2 כפונקציית ההפסד.
השגיאה הריבועית הממוצעת היא הפסד L2 הממוצע לכל דוגמה. שגיאה בריבוע הוא שם נוסף לשגיאת L2.
מידע נוסף זמין במאמר Logistic regression: Loss and regularization (רגרסיה לוגיסטית: הפסד ורגולריזציה) בסדנה בנושא למידת מכונה.
הערכות של מודלים גדולים של שפה (LLM)
קבוצה של מדדים ונקודות השוואה להערכת הביצועים של מודלים גדולים של שפה (LLM). ברמת העל, הערכות של מודלים גדולים של שפה (LLM):
- לעזור לחוקרים לזהות תחומים שבהם צריך לשפר את מודלי ה-LLM.
- הם שימושיים להשוואה בין מודלי LLM שונים ולזיהוי מודל ה-LLM הכי טוב למשימה מסוימת.
- עוזרים להבטיח שהשימוש במודלים גדולים של שפה (LLM) יהיה בטוח ואתי.
מידע נוסף זמין במאמר מודלים גדולים של שפה (LLM) בקורס המקוצר על למידת מכונה.
הפסד
במהלך האימון של מודל בפיקוח, נמדד המרחק בין התחזית של המודל לבין התווית שלו.
פונקציית הפסד מחשבת את ההפסד.
מידע נוסף זמין במאמר רגרסיה ליניארית: הפסד בסדנה בנושא למידת מכונה.
פונקציית אובדן
במהלך אימון או בדיקה, פונקציה מתמטית שמחשבת את ההפסד באצווה של דוגמאות. פונקציית הפסד מחזירה ערך הפסד נמוך יותר למודלים שמבצעים חיזויים טובים מאשר למודלים שמבצעים חיזויים לא טובים.
המטרה של האימון היא בדרך כלל למזער את ההפסד שמוחזר על ידי פונקציית הפסד.
קיימים סוגים רבים ושונים של פונקציות אובדן. בוחרים את פונקציית ההפסד המתאימה לסוג המודל שאתם בונים. לדוגמה:
- הפונקציה אובדן L2 (או השגיאה הריבועית הממוצעת) היא הפונקציה אובדן של רגרסיה ליניארית.
- Log Loss היא פונקציית האובדן של רגרסיה לוגיסטית.
M
MBPP
קיצור של בעיות בסיסיות בעיקר ב-Python.
שגיאה ממוצעת מוחלטת (MAE)
ההפסד הממוצע לכל דוגמה כשמשתמשים ב-L1 loss. כדי לחשב את שגיאת הממוצע המוחלט, פועלים לפי השלבים הבאים:
- חישוב הפסד L1 עבור אצווה.
- מחלקים את ההפסד L1 במספר הדוגמאות באצווה.
לדוגמה, נניח שרוצים לחשב את הפסד L1 בקבוצה הבאה של חמש דוגמאות:
| ערך בפועל לדוגמה | הערך שהמודל חזה | הפסד (ההפרש בין הערך בפועל לבין הערך החזוי) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = הפסד L1 | ||
לכן, ערך הפונקציה L1 הוא 8 ומספר הדוגמאות הוא 5. לכן, השגיאה הממוצעת המוחלטת היא:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
השוואה בין שגיאת ממוצע מוחלט לבין שגיאת ממוצע ריבועי ושורש טעות ריבועית ממוצעת.
דיוק ממוצע ממוצע ב-k (mAP@k)
הממוצע הסטטיסטי של כל הציונים של דיוק ממוצע ב-k במערך נתוני אימות. אחד השימושים של מדד הדיוק הממוצע ב-k הוא להעריך את איכות ההמלצות שנוצרות על ידי מערכת המלצות.
למרות שהביטוי 'ממוצע ממוצע' נשמע מיותר, השם של המדד מתאים. בסופו של דבר, המדד הזה מחשב את הממוצע של כמה ערכים של דיוק ממוצע ב-k.
שגיאה ריבועית ממוצעת (MSE)
ההפסד הממוצע לכל דוגמה כשמשתמשים בהפסד L. כך מחשבים את השגיאה הריבועית הממוצעת:
- חישוב הפסד L2 עבור אצווה.
- מחלקים את הפסד L2 במספר הדוגמאות באצווה.
לדוגמה, נניח שאתם רוצים לחשב את הפסד על קבוצה של חמש דוגמאות:
| ערך בפועל | החיזוי של המודל | הפסד | פונקציית הפסד ריבועי |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 loss | |||
לכן, השגיאה הריבועית הממוצעת היא:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
השגיאה הריבועית הממוצעת היא אופטימיזציה פופולרית לאימון, במיוחד עבור רגרסיה לינארית.
השוואה בין שורש טעות ריבועית ממוצעת לבין טעות מוחלטת ממוצעת ושורש טעות ריבועית ממוצעת.
TensorFlow Playground משתמש בטעות ריבועית ממוצעת כדי לחשב את ערכי ההפסד.
ערך
נתון סטטיסטי שחשוב לכם.
יעד הוא מדד שמערכת למידת מכונה מנסה לבצע לו אופטימיזציה.
Metrics API (tf.metrics)
TensorFlow API להערכת מודלים. לדוגמה, tf.metrics.accuracy
קובע את התדירות שבה התחזיות של מודל תואמות לתוויות.
הפסד מינימקס
פונקציית הפסד עבור רשתות יריבות גנרטיביות, שמבוססת על אנטרופיה צולבת בין ההתפלגות של הנתונים שנוצרו לבין הנתונים האמיתיים.
הפסד מינימקס משמש במאמר הראשון לתיאור רשתות גנרטיביות יריבות.
מידע נוסף זמין במאמר בנושא פונקציות הפסד בקורס בנושא רשתות יריבות גנרטיביות.
קיבולת המודל
מורכבות הבעיות שהמודל יכול ללמוד. ככל שהבעיות שמודל יכול ללמוד מורכבות יותר, כך היכולת של המודל גבוהה יותר. הקיבולת של מודל גדלה בדרך כלל עם מספר הפרמטרים של המודל. הגדרה רשמית של הקיבולת של מודל סיווג מופיעה במאמר בנושא ממד VC.
בעיות בסיסיות ב-Python (MBPP)
מערך נתונים להערכת רמת המיומנות של מודל שפה גדולה (LLM) ביצירת קוד Python. Mostly Basic Python Problems כולל כ-1,000 בעיות תכנות שמקורן במיקור המונים. כל בעיה בקבוצת הנתונים מכילה את הפרטים הבאים:
- תיאור המשימה
- קוד הפתרון
- שלושה תרחישי בדיקה אוטומטיים
לא
סיווג שלילי
בסיווג בינארי, מחלקה אחת נקראת חיובית והשנייה נקראת שלילית. הסיווג החיובי הוא הדבר או האירוע שהמודל בודק, והסיווג השלילי הוא האפשרות השנייה. לדוגמה:
- הסיווג השלילי בבדיקה רפואית יכול להיות 'לא גידול'.
- הסיווג השלילי במודל סיווג של אימייל יכול להיות 'לא ספאם'.
ההגדרה הזו שונה מהכיתה החיובית.
O
יעד
מדד שהאלגוריתם מנסה לבצע לו אופטימיזציה.
פונקציית מטרה
הנוסחה המתמטית או המדד שהמודל שואף לבצע אופטימיזציה לגביהם. לדוגמה, פונקציית היעד של רגרסיה לינארית היא בדרך כלל Mean Squared Loss (אובדן ממוצע בריבוע). לכן, כשמאמנים מודל של רגרסיה לינארית, האימון נועד לצמצם את אובדן המידע הממוצע בריבוע.
במקרים מסוימים, המטרה היא למקסם את פונקציית המטרה. לדוגמה, אם פונקציית היעד היא דיוק, המטרה היא למקסם את הדיוק.
מידע נוסף זמין במאמר בנושא הפסד.
P
pass at k (pass@k)
מדד לקביעת איכות הקוד (לדוגמה, Python) שנוצר על ידי מודל שפה גדול. באופן ספציפי יותר, הערך של k מציין את הסבירות שלפחות אחד מתוך k בלוקים של קוד שנוצרו יעבור את כל בדיקות היחידה שלו.
למודלים גדולים של שפה (LLM) יש לעיתים קרובות קושי ליצור קוד טוב לבעיות תכנות מורכבות. מהנדסי תוכנה מתמודדים עם הבעיה הזו על ידי הנחיית מודל שפה גדול (LLM) ליצור כמה (k) פתרונות לאותה בעיה. לאחר מכן, מהנדסי תוכנה בודקים כל אחד מהפתרונות באמצעות בדיקות יחידה. החישוב של pass@k תלוי בתוצאה של בדיקות היחידה:
- אם אחד או יותר מהפתרונות האלה עוברים את בדיקת היחידה, אז ה-LLM עובר את האתגר של יצירת הקוד.
- אם אף אחד מהפתרונות לא עובר את בדיקת היחידה, מודל ה-LLM נכשל באתגר הזה של יצירת קוד.
הנוסחה לחישוב ציון המעבר ב-k היא:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
באופן כללי, ערכים גבוהים יותר של k מניבים ציונים גבוהים יותר של מעבר ב-k, אבל ערכים גבוהים יותר של k דורשים יותר משאבים של מודל שפה גדול (LLM) ובדיקות יחידה (unit testing).
ביצועים
מונח עם כמה משמעויות:
- המשמעות הסטנדרטית בהנדסת תוכנה. כלומר: כמה מהר (או ביעילות) פועל קטע התוכנה הזה?
- המשמעות בהקשר של למידת מכונה. התשובה לשאלה הבאה: עד כמה המודל הזה מדויק? כלומר, עד כמה התחזיות של המודל טובות?
חשיבות משתנים בתמורה
סוג של חשיבות משתנה שמעריך את העלייה בשגיאת החיזוי של מודל אחרי שינוי הערכים של התכונה. חשיבות המשתנה של פרמוטציה היא מדד שלא תלוי במודל.
בלבול
מדד אחד שמשקף את מידת ההצלחה של מודל בהשגת המטרה שלו. לדוגמה, נניח שהמשימה שלכם היא לקרוא את כמה האותיות הראשונות של מילה שמשתמש מקליד במקלדת של טלפון, ולהציע רשימה של מילים אפשריות להשלמה. הערך של מידת ההסתבכות, P, למשימה הזו הוא בערך מספר הניחושים שצריך להציע כדי שהרשימה תכיל את המילה האמיתית שהמשתמש מנסה להקליד.
המדד Perplexity קשור לcross-entropy באופן הבא:
positive class
הכיתה שאתם בודקים.
לדוגמה, המחלקה החיובית במודל לסרטן יכולה להיות 'גידול'. הסיווג החיובי במודל לסיווג אימיילים יכול להיות 'ספאם'.
ההפך מכיתה שלילית.
PR AUC (השטח מתחת לעקומת הדיוק וההחזרה)
השטח מתחת לעקומת הדיוק וההחזרה שחושבה על ידי אינטרפולציה, שהתקבלה משרטוט נקודות (החזרה, דיוק) עבור ערכים שונים של סף הסיווג.
דיוק
מדד למודלים של סיווג שעונה על השאלה הבאה:
כשהמודל חזה את הסיווג החיובי, מה אחוז החיזויים הנכונים?
זו הנוסחה:
where:
- חיובי אמיתי פירושו שהמודל חזה נכון את המחלקה החיובית.
- תוצאה חיובית שגויה פירושה שהמודל טעה וחיזוי את המחלקה החיובית.
לדוגמה, נניח שמודל יצר 200 תחזיות חיוביות. מתוך 200 התחזיות החיוביות האלה:
- 150 היו חיוביים אמיתיים.
- 50 מהן היו תוצאות חיוביות כוזבות.
במקרה זה:
ההגדרה הזו שונה מדיוק ומהחזרה.
מידע נוסף זמין במאמר סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים בסדנה ללמידת מכונה.
דיוק ב-k (precision@k)
מדד להערכת רשימה מדורגת (מסודרת) של פריטים. המדד 'דיוק ב-k' מציין את החלק של k הפריטים הראשונים ברשימה שהם 'רלוונטיים'. כלומר:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
הערך של k צריך להיות קטן מאורך הרשימה שמוחזרת או שווה לו. שימו לב שאורך הרשימה שמוחזרת לא נכלל בחישוב.
רלוונטיות היא לרוב סובייקטיבית. אפילו מעריכים אנושיים מומחים חלוקים בדעתם לגבי הפריטים הרלוונטיים.
השווה ל:
עקומת דיוק-החזרה
עקומת הדיוק לעומת ההחזרה בספי סיווג שונים.
הטיה בתחזית
ערך שמציין את המרחק בין הממוצע של התחזיות לבין הממוצע של התוויות במערך הנתונים.
לא להתבלבל עם מונח ההטיה במודלים של למידת מכונה או עם הטיה באתיקה ובהוגנות.
שוויון חזוי
מדד הוגנות שבודק אם שיעורי הדיוק שווים עבור קבוצות משנה שנבדקות במודל סיווג נתון.
לדוגמה, מודל שמנבא קבלה למכללה יעמוד בדרישות של שוויון חיזוי לפי לאום אם שיעור הדיוק שלו זהה עבור אנשים מליליפוט ואנשים מברובדינגנאג.
לפעמים קוראים לשיטה הזו גם שוויון חזוי בשיעורי ההמרה.
דיון מפורט יותר בנושא שוויון חיזוי זמין במאמר הסבר על הגדרות של הוגנות (סעיף 3.2.1).
השוואת מחירים חזויה
שם נוסף לשוויון חיזוי.
פונקציית צפיפות הסתברות
פונקציה שמזהה את התדירות של דגימות נתונים עם ערך מסוים בדיוק. כשערכים של קבוצת נתונים הם מספרים רציפים עם נקודה צפה (floating-point), התאמות מדויקות הן נדירות. עם זאת, שילוב של פונקציית צפיפות הסתברות מהערך x לערך y מניב את התדירות הצפויה של דגימות נתונים בין x ל-y.
לדוגמה, נניח שיש התפלגות נורמלית עם ממוצע של 200 וסטיית תקן של 30. כדי לקבוע את התדירות הצפויה של דגימות נתונים שנמצאות בטווח 211.4 עד 218.7, אפשר לבצע אינטגרציה של פונקציית צפיפות ההסתברות להתפלגות נורמלית מ-211.4 עד 218.7.
R
הבנת הנקרא עם מערך נתונים של חשיבה הגיונית (ReCoRD)
מערך נתונים להערכת היכולת של מודל LLM לבצע היסק על סמך שכל ישר. כל דוגמה במערך הנתונים מכילה שלושה רכיבים:
- פסקות מתוך כתבה
- שאילתה שבה אחת מהישויות שזוהו במפורש או במרומז בקטע מוסתרת.
- התשובה (שם הישות שצריך להופיע במסכה)
רשימה מקיפה של דוגמאות מופיעה במאמר בנושא ReCoRD.
ReCoRD הוא רכיב של SuperGLUE.
RealToxicityPrompts
מערך נתונים שמכיל קבוצה של התחלות משפטים שעשויות להכיל תוכן רעיל. משתמשים במערך הנתונים הזה כדי להעריך את היכולת של מודל שפה גדול (LLM) ליצור טקסט לא רעיל כדי להשלים את המשפט. בדרך כלל, משתמשים ב-Perspective API כדי לקבוע את רמת הביצוע של ה-LLM במשימה הזו.
פרטים נוספים מופיעים במאמר RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
recall
מדד למודלים של סיווג שעונה על השאלה הבאה:
אם האמת הבסיסית הייתה הסיווג החיובי, מהו אחוז התחזיות שהמודל זיהה בצורה נכונה כסיווג החיובי?
זו הנוסחה:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
where:
- חיובי אמיתי פירושו שהמודל חזה נכון את המחלקה החיובית.
- תוצאה שלילית שגויה פירושה שהמודל טעה בחיזוי הסיווג השלילי.
לדוגמה, נניח שהמודל שלכם ביצע 200 חיזויים על דוגמאות שבהן האמת הבסיסית הייתה הסיווג החיובי. מתוך 200 התחזיות האלה:
- 180 היו תוצאות חיוביות אמיתיות.
- 20 מהן היו תוצאות שליליות מטעות.
במקרה זה:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
מידע נוסף זמין במאמר בנושא סיווג: דיוק, היזכרות, פרסיזיה ומדדים קשורים.
ריקול ב-k (recall@k)
מדד להערכת מערכות שמפיקות רשימה מדורגת (מסודרת) של פריטים. המדד Recall at k מזהה את החלק של הפריטים הרלוונטיים מתוך k הפריטים הראשונים ברשימה, מתוך המספר הכולל של הפריטים הרלוונטיים שהוחזרו.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
הניגודיות עם דיוק ב-k.
זיהוי של הסקה לוגית מטקסט (RTE)
מערך נתונים להערכת היכולת של מודל LLM לקבוע אם אפשר להסיק השערה (לוגית) מקטע טקסט. כל דוגמה בהערכה של RTE מורכבת משלושה חלקים:
- קטע, בדרך כלל מכתבות חדשותיות או ממאמרים בוויקיפדיה
- השערה
- התשובה הנכונה, שהיא אחת מהאפשרויות הבאות:
- True, meaning the hypothesis can be entailed from the passage
- False, כלומר ההשערה לא יכולה להיות מוסקת מהקטע
לדוגמה:
- קטע: האירו הוא המטבע של האיחוד האירופי.
- היפותזה: בצרפת משתמשים באירו כמטבע.
- היסק: True, כי צרפת היא חלק מהאיחוד האירופי.
RTE הוא רכיב של SuperGLUE ensemble.
ReCoRD
קיצור של Reading Comprehension with Commonsense Reasoning Dataset (הבנת הנקרא עם מערך נתונים של חשיבה הגיונית).
עקומת ROC (מאפיין הפעולה של המקלט)
תרשים של שיעור החיוביים האמיתיים לעומת שיעור השליליים הכוזבים עבור סף סיווג שונים בסיווג בינארי.
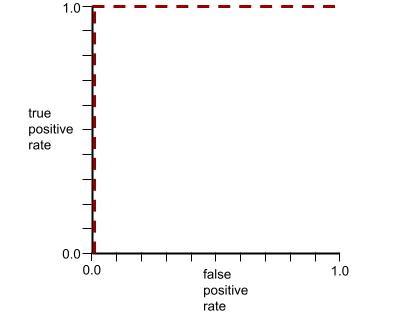
הצורה של עקומת ROC מצביעה על היכולת של מודל סיווג בינארי להפריד בין סיווגים חיוביים לסיווגים שליליים. נניח, לדוגמה, שמודל סיווג בינארי מפריד בצורה מושלמת בין כל המחלקות השליליות לבין כל המחלקות החיוביות:
עקומת ה-ROC של המודל הקודם נראית כך:
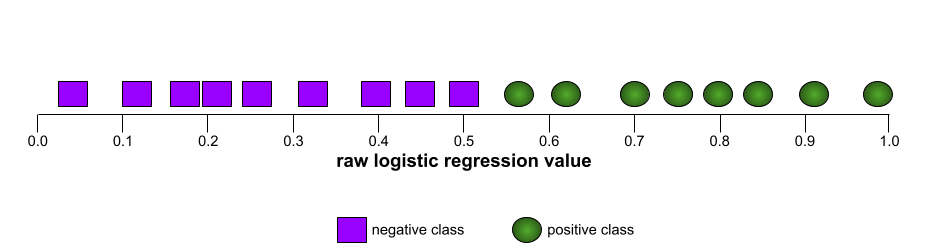
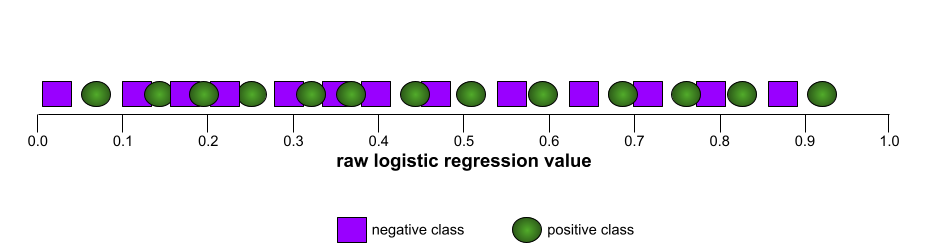
לעומת זאת, באיור הבא מוצגים ערכי הרגרסיה הלוגיסטית הגולמיים של מודל גרוע שלא מצליח להפריד בין מחלקות שליליות למחלקות חיוביות:
עקומת ה-ROC של המודל הזה נראית כך:
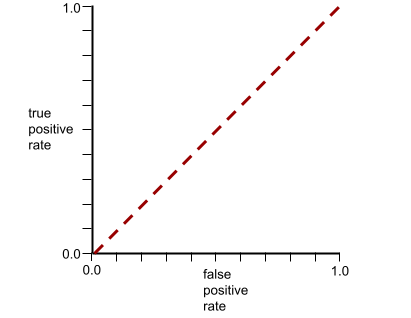
בינתיים, בעולם האמיתי, רוב מודלי הסיווג הבינארי מפרידים בין מחלקות חיוביות ושליליות במידה מסוימת, אבל בדרך כלל לא בצורה מושלמת. לכן, עקומת ROC טיפוסית נמצאת איפשהו בין שני הקצוות:
הנקודה בעקומת ROC שהכי קרובה ל-(0.0,1.0) מזהה באופן תיאורטי את סף הסיווג האידיאלי. עם זאת, יש כמה בעיות אחרות בעולם האמיתי שמשפיעות על הבחירה של סף הסיווג האידיאלי. לדוגמה, יכול להיות שתוצאות שליליות כוזבות גורמות להרבה יותר בעיות מאשר תוצאות חיוביות כוזבות.
מדד מספרי שנקרא AUC מסכם את עקומת ה-ROC לערך יחיד של נקודה צפה.
שורש טעות ריבועית ממוצעת (RMSE)
השורש הריבועי של הטעות הריבועית הממוצעת.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
משפחה של מדדים להערכת מודלים של סיכום אוטומטי ותרגום מכונה. מדדי ROUGE קובעים את מידת החפיפה בין טקסט ייחוס לבין טקסט שנוצר על ידי מודל ML. כל אחד מהמדדים במשפחת ROUGE מודד חפיפה בצורה שונה. ציוני ROUGE גבוהים יותר מצביעים על דמיון רב יותר בין טקסט ההפניה לבין הטקסט שנוצר, בהשוואה לציוני ROUGE נמוכים יותר.
בדרך כלל, כל חבר במשפחת ROUGE יוצר את המדדים הבאים:
- דיוק
- זכירות
- F1
פרטים ודוגמאות מופיעים במאמרים הבאים:
ROUGE-L
חבר במשפחת ROUGE שמתמקד באורך של הרצף המשותף הארוך ביותר בטקסט ההפניה ובטקסט שנוצר. הנוסחאות הבאות משמשות לחישוב ההחזרה והדיוק של ROUGE-L:
אחר כך אפשר להשתמש ב-F1 כדי לסכם את הנתונים של ROUGE-L recall ו-ROUGE-L precision למדד אחד:
המדד ROUGE-L מתעלם ממעברי שורה בטקסט ההשוואה ובטקסט שנוצר, ולכן הרצף המשותף הארוך ביותר יכול לחצות כמה משפטים. אם טקסט ההפניה והטקסט שנוצר כוללים כמה משפטים, מדד טוב יותר בדרך כלל הוא וריאציה של ROUGE-L שנקראת ROUGE-Lsum. המדד ROUGE-Lsum קובע את הרצף המשותף הארוך ביותר לכל משפט בקטע, ואז מחשב את הממוצע של הרצפים המשותפים הארוכים ביותר האלה.
ROUGE-N
קבוצה של מדדים במשפחת ROUGE שמשווה בין ה-N-grams המשותפים בגודל מסוים בטקסט ההפניה לבין הטקסט שנוצר. לדוגמה:
- המדד ROUGE-1 מודד את מספר הטוקנים המשותפים בטקסט ההפניה ובטקסט שנוצר.
- ROUGE-2 מודד את מספר הביגרמות (2-גרמות) המשותפות בטקסט ההפניה ובטקסט שנוצר.
- המדד ROUGE-3 מודד את מספר הטריגרמים (3-גרמים) המשותפים בטקסט ההפניה ובטקסט שנוצר.
אפשר להשתמש בנוסחאות הבאות כדי לחשב את מדד ההחזרה (recall) של ROUGE-N ואת מדד הדיוק (precision) של ROUGE-N לכל חבר במשפחת ROUGE-N:
אחר כך אפשר להשתמש ב-F1 כדי לצמצם את הנתונים של ROUGE-N recall ו-ROUGE-N precision למדד אחד:
ROUGE-S
גרסה סלחנית של ROUGE-N שמאפשרת התאמה של skip-gram. כלומר, ROUGE-N סופר רק N-grams שתואמים בדיוק, אבל ROUGE-S סופר גם N-grams שמפרידה ביניהם מילה אחת או יותר. לדוגמה, שקול את הדברים הבאים:
- טקסט להפניה: עננים לבנים
- טקסט שנוצר: White billowing clouds
כשמחשבים את ROUGE-N, ה-2-gram, White clouds לא תואם ל-White billowing clouds. עם זאת, כשמחשבים את ROUGE-S, White clouds תואם ל-White billowing clouds.
R בריבוע
מדד רגרסיה שמציין כמה מהשונות בתווית נובעת מתכונה יחידה או מקבוצת תכונות. מקדם המתאם R² הוא ערך בין 0 ל-1, שאפשר לפרש אותו באופן הבא:
- ערך של 0 ב-R-squared פירושו שאף אחד מהשינויים בתווית לא נובע מקבוצת התכונות.
- ערך של 1 ב-R בריבוע מציין שכל השונות של תווית מסוימת נובעת מקבוצת התכונות.
- ערך R בריבוע בין 0 ל-1 מציין את המידה שבה אפשר לחזות את השונות של התווית ממאפיין מסוים או מקבוצת המאפיינים. לדוגמה, אם ערך ה-R בריבוע הוא 0.10, המשמעות היא ש-10 אחוזים מהשונות בתווית נובעים מקבוצת התכונות. אם ערך ה-R בריבוע הוא 0.20, המשמעות היא ש-20 אחוזים נובעים מקבוצת התכונות, וכן הלאה.
מקדם המתאם R בריבוע הוא הריבוע של מקדם המתאם של פירסון בין הערכים שהמודל חזה לבין הערכים האמיתיים.
RTE
קיצור של Recognizing Textual Entailment.
S
דירוג
החלק במערכת ההמלצות שמספק ערך או דירוג לכל פריט שנוצר בשלב יצירת המועמדים.
מדד הדמיון
באלגוריתמים של אשכולות, המדד שמשמש לקביעת מידת הדמיון בין שני מקרים.
sparsity
מספר הרכיבים שמוגדרים לאפס (או לערך null) בווקטור או במטריצה, חלקי המספר הכולל של הערכים בווקטור או במטריצה. לדוגמה, נניח שיש מטריצה עם 100 רכיבים, שבה 98 תאים מכילים אפס. החישוב של הדלילות מתבצע כך:
דלילות המאפיינים מתייחסת לדלילות של וקטור מאפיינים, ודלילות המודל מתייחסת לדלילות של משקלי המודל.
SQuAD
ראשי תיבות של Stanford Question Answering Dataset (מערך נתונים של סטנפורד למענה על שאלות), שהוצג במאמר SQuAD: 100,000+ Questions for Machine Comprehension of Text (מערך SQuAD: יותר מ-100,000 שאלות להבנת טקסט על ידי מכונה). השאלות במערך הנתונים הזה מגיעות מאנשים ששואלים שאלות לגבי מאמרים בוויקיפדיה. לחלק מהשאלות ב-SQuAD יש תשובות, אבל לחלק אחר אין תשובות בכוונה. לכן, אפשר להשתמש ב-SQuAD כדי להעריך את היכולת של LLM לבצע את שתי הפעולות הבאות:
- לענות על שאלות שאפשר לענות עליהן.
- לזהות שאלות שאי אפשר לענות עליהן.
התאמה מדויקת בשילוב עם F1 הם המדדים הנפוצים ביותר להערכת מודלים גדולים של שפה (LLM) בהשוואה ל-SQuAD.
squared hinge loss
הריבוע של הפסד הציר. הפסד ציר בריבוע מעניש חריגים בצורה חמורה יותר מאשר הפסד ציר רגיל.
squared loss
מילה נרדפת להפסד L2.
SuperGLUE
קבוצה של מערכי נתונים לדירוג היכולת הכוללת של מודל שפה גדול (LLM) להבין וליצור טקסט. האנסמבל מורכב ממערכי הנתונים הבאים:
- Boolean Questions (BoolQ)
- CommitmentBank (CB)
- בחירת חלופות סבירות (COPA)
- הבנת הנקרא של כמה משפטים (MultiRC)
- מערך נתונים של הבנת הנקרא עם הסקה מבוססת-שכל ישר (ReCoRD)
- Recognizing Textual Entailment (RTE)
- מילים בהקשר (WiC)
- Winograd Schema Challenge (WSC)
פרטים נוספים זמינים במאמר SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
T
הפסד בבדיקה
מדד שמייצג את ההפסד של מודל בהשוואה לקבוצת נתונים לבדיקה. כשבונים מודל, בדרך כלל מנסים למזער את אובדן הבדיקה. הסיבה לכך היא שערך נמוך של הפסד בבדיקה הוא אות איכות חזק יותר מערך נמוך של הפסד באימון או של הפסד באימות.
פער גדול בין הפסד הבדיקה לבין הפסד האימון או הפסד האימות מצביע לפעמים על הצורך להגדיל את שיעור הרגולריזציה.
דיוק top-k
אחוז הפעמים שבהן 'תווית היעד' מופיעה בתוך k המיקומים הראשונים של רשימות שנוצרו. הרשימות יכולות להיות המלצות מותאמות אישית או רשימה של פריטים שמסודרים לפי softmax.
דיוק k המובילים נקרא גם דיוק ב-k.
תוכן רעיל
המידה שבה התוכן פוגעני, מאיים או מעליב. הרבה מודלים של למידת מכונה יכולים לזהות, למדוד ולסווג רעילות. רוב המודלים האלה מזהים רעילות לפי כמה פרמטרים, כמו רמת השפה הפוגעת ורמת השפה המאיימת.
הפסד האימון
מדד שמייצג את ההפסד של מודל במהלך איטרציה מסוימת של אימון. לדוגמה, נניח שפונקציית ההפסד היא Mean Squared Error. יכול להיות שההפסד של האימון (השגיאה הממוצעת בריבוע) באיטרציה העשירית הוא 2.2, וההפסד של האימון באיטרציה ה-100 הוא 1.9.
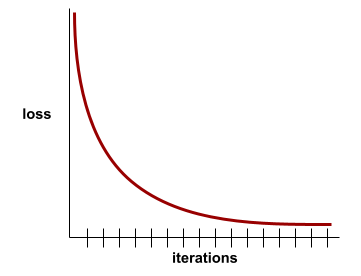
עקומת הפסד מציגה את הפסד האימון לעומת מספר האיטרציות. עקומת הפסד מספקת את הרמזים הבאים לגבי האימון:
- שיפוע כלפי מטה מעיד על שיפור במודל.
- שיפוע כלפי מעלה מרמז שהמודל הולך ונעשה גרוע יותר.
- שיפוע שטוח מרמז שהמודל הגיע להתכנסות.
לדוגמה, עקומת ההפסד הבאה היא אידיאלית במידה מסוימת, והיא מציגה:
- שיפוע חד כלפי מטה במהלך האיטרציות הראשוניות, שמצביע על שיפור מהיר של המודל.
- שיפוע שמשתטח בהדרגה (אבל עדיין יורד) עד לסיום האימון, מה שמצביע על שיפור מתמשך במודל בקצב איטי יותר מאשר במהלך האיטרציות הראשוניות.
- שיפוע שטוח לקראת סוף האימון, שמצביע על התכנסות.
למרות שחשוב להבין את הפסדי האימון, כדאי גם לעיין במושג הכללה.
מענה על שאלות טריוויה
מערכי נתונים להערכת היכולת של מודל שפה גדול לענות על שאלות טריוויה. כל מערך נתונים מכיל זוגות של שאלות ותשובות שנכתבו על ידי חובבי טריוויה. מערכי נתונים שונים מבוססים על מקורות שונים, כולל:
- חיפוש באינטרנט (TriviaQA)
- ויקיפדיה (TriviaQA_wiki)
מידע נוסף זמין במאמר TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
שלילי אמיתי (TN)
דוגמה שבה המודל מנבא בצורה נכונה את הסיווג השלילי. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא לא ספאם, והודעת האימייל הזו באמת לא ספאם.
חיובי אמיתי (TP)
דוגמה שבה המודל מנבא בצורה נכונה את הסיווג החיובי. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא ספאם, והודעת האימייל הזו באמת ספאם.
שיעור חיובי אמיתי (TPR)
מילה נרדפת לrecall. כלומר:
שיעור החיוביים האמיתיים הוא ציר ה-y בעקומת ROC.
מענה לשאלות בשפות מגוונות מבחינה טיפולוגית (TyDi QA)
מערך נתונים גדול להערכת היכולת של מודל LLM לענות על שאלות. מערך הנתונים מכיל זוגות של שאלות ותשובות בשפות רבות.
פרטים נוספים זמינים במאמר TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
שיעור התלונות שלא נתמכות (UCR)
אחוז הטענות בתגובה שלא מבוססות על מידע. לדוגמה, אם תגובה של LLM כוללת 10 טענות אבל רק אחת מהן מבוססת על מקורות, מדד ה-UCR הוא 90%.
שיעור גבוה של תשובות לא נכונות מצביע על כך שמודל שפה גדול מייצר הזיות בתדירות גבוהה מדי.
כדאי לעיין גם בדיוק הציטוט ובהיקף הציטוט.
V
הפסד אימות
מדד שמייצג את הפסד של מודל בקבוצת נתונים לתיקוף במהלך איטרציה מסוימת של אימון.
אפשר לעיין גם בעקומת הכללה.
חשיבות המשתנים
קבוצת ציונים שמציינת את החשיבות היחסית של כל תכונה למודל.
לדוגמה, נניח שיש עץ החלטה שמבצע הערכה של מחירי בתים. נניח שעץ ההחלטה הזה משתמש בשלושה מאפיינים: גודל, גיל וסגנון. אם קבוצת חשיבויות משתנים לשלושת המאפיינים מחושבת כ- {size=5.8, age=2.5, style=4.7}, אז המאפיין size חשוב יותר לעץ ההחלטה מהמאפיינים age או style.
קיימים מדדים שונים לחשיבות משתנים, שיכולים לספק למומחי ML מידע על היבטים שונים של מודלים.
W
פונקציית הפסד Wasserstein
אחת מפונקציות ההפסד שבהן נעשה שימוש בדרך כלל ברשתות יריבות גנרטיביות, על סמך מרחק העברת האדמה בין התפלגות הנתונים שנוצרו לבין הנתונים האמיתיים.
WiC
קיצור של מילים בהקשר.
WikiLingua (wiki_lingua)
מערך נתונים להערכת היכולת של מודל LLM לסכם מאמרים קצרים. WikiHow, אנציקלופדיה של מאמרים שמסבירים איך לבצע משימות שונות, הוא המקור שנכתב על ידי בני אדם גם למאמרים וגם לסיכומים. כל רשומה במערך הנתונים כוללת:
- מאמר שנוצר על ידי הוספה של כל שלב בגרסת הפרוזה (הפסקה) של הרשימה הממוספרת, ללא משפט הפתיחה של כל שלב.
- סיכום של המאמר, שמורכב ממשפט הפתיחה של כל שלב ברשימה הממוספרת.
פרטים נוספים זמינים במאמר WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization.
אתגר סכימת וינוגרד (WSC)
פורמט (או מערך נתונים שתואם לפורמט הזה) להערכת היכולת של מודל שפה גדול (LLM) לקבוע את הצירוף הנומינלי שאליו מתייחסת מילת גוף.
כל רשומה באתגר סכימת וינוגרד כוללת:
- קטע קצר שמכיל כינוי גוף של יעד
- כינוי גוף ליעד
- צירופי שמות עצם אפשריים, ואחריהם התשובה הנכונה (ערך בוליאני). אם כינוי הגוף שאליו מתייחסים מתייחס למועמד הזה, התשובה היא True. אם כינוי הגוף לא מתייחס למועמד הזה, התשובה היא False.
לדוגמה:
- קטע: Mark told Pete many lies about himself, which Pete included in his book. הוא היה צריך להיות יותר כנה.
- כינוי הגוף הממוקד: הוא
- צירופי שם עצם מוצעים:
- סימון: True, כי כינוי המטרה מתייחס למארק
- פיט: False, כי כינוי הגוף לא מתייחס לפיט
אתגר סכמת וינוגרד הוא רכיב של SuperGLUE.
מילים בהקשר (WiC)
מערך נתונים להערכת היכולת של LLM להשתמש בהקשר כדי להבין מילים שיש להן כמה משמעויות. כל רשומה במערך הנתונים מכילה:
- שני משפטים, שכל אחד מהם מכיל את מילת היעד
- מילת היעד
- התשובה הנכונה (ערך בוליאני), כאשר:
- הערך True מציין שלמילת היעד יש את אותה משמעות בשני המשפטים
- הערך False מציין שלמילה המטרה יש משמעות שונה בשני המשפטים
לדוגמה:
- שני משפטים:
- יש הרבה אשפה בקרקעית הנהר.
- אני תמיד מניח מים ליד המיטה כשאני הולך לישון.
- מילת היעד: bed
- תשובה נכונה: False, because the target word has a different meaning in the two sentences.
פרטים נוספים זמינים במאמר WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context הוא רכיב של SuperGLUE ensemble.
WSC
קיצור של Winograd Schema Challenge (אתגר סכימת וינוגרד).
X
XL-Sum (xlsum)
מערך נתונים להערכת רמת המיומנות של מודל שפה גדול (LLM) בסיכום טקסט. XL-Sum מספק רשומות בשפות רבות. כל רשומה במערך הנתונים מכילה:
- מאמר שנלקח מ-British Broadcasting Company (BBC).
- סיכום של המאמר, שנכתב על ידי מחבר המאמר. שימו לב שהסיכום יכול להכיל מילים או ביטויים שלא מופיעים במאמר.
פרטים נוספים זמינים במאמר XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages.