इस पेज पर, मेट्रिक शब्दावली के शब्द दिए गए हैं. सभी शब्दावली के लिए, यहां क्लिक करें.
A
सटीक
सही क्लासिफ़िकेशन अनुमानों की संख्या को अनुमानों की कुल संख्या से भाग देने पर यह स्कोर मिलता है. यानी:
उदाहरण के लिए, अगर किसी मॉडल ने 40 सही और 10 गलत अनुमान लगाए हैं, तो उसकी सटीकता इस तरह से कैलकुलेट की जाएगी:
बाइनरी क्लासिफ़िकेशन में, सही अनुमानों और गलत अनुमानों की अलग-अलग कैटगरी के लिए खास नाम दिए गए हैं. इसलिए, बाइनरी क्लासिफ़िकेशन के लिए सटीकता का फ़ॉर्मूला इस तरह है:
कहां:
- टीपी, ट्रू पॉज़िटिव (सही अनुमान) की संख्या है.
- TN, ट्रू नेगेटिव (सही अनुमान) की संख्या है.
- FP, फ़ॉल्स पॉज़िटिव (गलत अनुमान) की संख्या है.
- FN, फ़ॉल्स निगेटिव (गलत अनुमान) की संख्या है.
सटीकता की तुलना प्रिसिज़न और रीकॉल से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
पीआर कर्व के नीचे का एरिया
पीआर एयूसी (पीआर कर्व के नीचे का हिस्सा) देखें.
आरओसी कर्व के नीचे का क्षेत्र
एयूसी (आरओसी कर्व के नीचे का हिस्सा) देखें.
AUC (आरओसी कर्व के नीचे का हिस्सा)
यह 0.0 से 1.0 के बीच की एक संख्या होती है. यह बाइनरी क्लासिफ़िकेशन मॉडल की, पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता को दिखाती है. एयूसी की वैल्यू 1.0 के जितनी ज़्यादा करीब होगी, मॉडल की परफ़ॉर्मेंस उतनी ही बेहतर होगी.
उदाहरण के लिए, यहां दी गई इमेज में एक क्लासिफ़िकेशन मॉडल दिखाया गया है. यह पॉज़िटिव क्लास (हरे रंग के ओवल) को नेगेटिव क्लास (बैंगनी रंग के आयत) से पूरी तरह अलग करता है. इस मॉडल का एयूसी 1.0 है, जो कि काफ़ी अच्छा है:

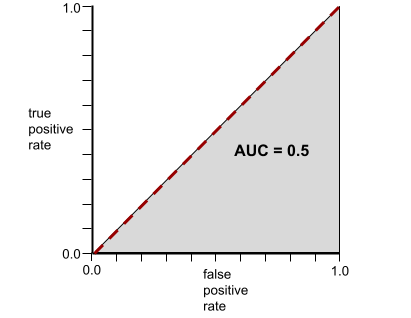
इसके उलट, यहां दिए गए उदाहरण में, क्लासिफ़िकेशन मॉडल के नतीजे दिखाए गए हैं. इस मॉडल ने रैंडम नतीजे जनरेट किए हैं. इस मॉडल का एयूसी 0.5 है:

हां, पिछले मॉडल का एयूसी 0.5 है, न कि 0.0.
ज़्यादातर मॉडल, इन दोनों के बीच में कहीं होते हैं. उदाहरण के लिए, यहां दिया गया मॉडल, पॉज़िटिव और नेगेटिव वैल्यू को कुछ हद तक अलग करता है. इसलिए, इसका एयूसी 0.5 और 1.0 के बीच है:

एयूसी, क्लासिफ़िकेशन थ्रेशोल्ड के लिए सेट की गई किसी भी वैल्यू को अनदेखा करता है. इसके बजाय, एयूसी, क्लासिफ़िकेशन के सभी संभावित थ्रेशोल्ड पर विचार करता है.
एयूसी और आरओसी कर्व के बीच के संबंध के बारे में जानने के लिए, आइकॉन पर क्लिक करें.
AUC, ROC कर्व के नीचे के क्षेत्र को दिखाता है. उदाहरण के लिए, किसी ऐसे मॉडल के लिए आरओसी कर्व यहां दिया गया है जो पॉज़िटिव और नेगेटिव को पूरी तरह से अलग करता है:
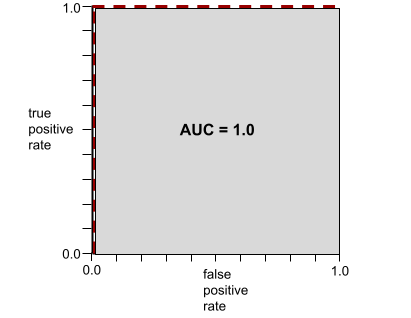
एयूसी, ऊपर दिए गए इलस्ट्रेशन में ग्रे रंग वाला हिस्सा है. इस खास मामले में, क्षेत्रफल निकालने के लिए ग्रे क्षेत्र की लंबाई (1.0) को ग्रे क्षेत्र की चौड़ाई (1.0) से गुणा किया जाता है. इसलिए, 1.0 और 1.0 के प्रॉडक्ट से एयूसी स्कोर 1.0 मिलता है. यह सबसे ज़्यादा एयूसी स्कोर है.
इसके उलट, क्लासिफ़िकेशन मॉडल के लिए आरओसी कर्व, क्लास को अलग नहीं कर सकता. यह इस तरह दिखता है. इस ग्रे रंग के क्षेत्र का क्षेत्रफल 0.5 है.
आम तौर पर, आरओसी कर्व कुछ ऐसा दिखता है:
इस कर्व के नीचे के एरिया का हिसाब मैन्युअल तरीके से लगाना मुश्किल होता है. इसलिए, आम तौर पर कोई प्रोग्राम ज़्यादातर एयूसी वैल्यू का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
k पर औसत प्रीसिज़न
यह एक ऐसी मेट्रिक है जो किसी एक प्रॉम्प्ट के लिए, मॉडल की परफ़ॉर्मेंस की खास जानकारी देती है. यह मेट्रिक, रैंक किए गए नतीजे जनरेट करती है. जैसे, किताबों के सुझावों की नंबर वाली सूची. k पर औसत सटीक नतीजे, हर काम के नतीजे के लिए k पर सटीक नतीजे वैल्यू का औसत होता है. इसलिए, k पर औसत सटीक स्कोर का फ़ॉर्मूला यह है:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
कहां:
- \(n\) सूची में मौजूद काम के आइटम की संख्या है.
k पर वापस बुलाना से तुलना करें.
B
आधारभूत
मॉडल का इस्तेमाल, रेफ़रंस पॉइंट के तौर पर किया जाता है. इससे यह तुलना की जाती है कि कोई दूसरा मॉडल (आम तौर पर, ज़्यादा जटिल मॉडल) कैसा परफ़ॉर्म कर रहा है. उदाहरण के लिए, डीप मॉडल के लिए, लॉजिस्टिक रिग्रेशन मॉडल एक अच्छा बेसलाइन मॉडल हो सकता है.
किसी समस्या के लिए, बेसलाइन से मॉडल डेवलपर को यह तय करने में मदद मिलती है कि नए मॉडल को कम से कम कितनी परफ़ॉर्मेंस देनी चाहिए, ताकि वह उपयोगी हो सके.
बूलियन सवाल (BoolQ)
एलएलएम की इस बात का आकलन करने के लिए डेटासेट कि वह हां या नहीं में जवाब देने वाले सवालों के जवाब देने में कितना माहिर है. डेटासेट में मौजूद हर चुनौती के तीन कॉम्पोनेंट होते हैं:
- क्वेरी
- क्वेरी के जवाब के बारे में जानकारी देने वाला पैसेज.
- सही जवाब, जो हां या नहीं में से कोई एक होता है.
उदाहरण के लिए:
- सवाल: क्या मिशिगन में कोई न्यूक्लियर पावर प्लांट है?
- पैसेज: ...तीन न्यूक्लियर पावर प्लांट, मिशिगन को करीब 30% बिजली की आपूर्ति करते हैं.
- सही जवाब: हां
शोधकर्ताओं ने Google Search पर की गई क्वेरी से सवाल इकट्ठा किए. इन क्वेरी में लोगों की पहचान ज़ाहिर नहीं की गई थी. इसके बाद, उन्होंने Wikipedia पेजों का इस्तेमाल करके जानकारी को सही ठहराया.
ज़्यादा जानकारी के लिए, BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions देखें.
BoolQ, SuperGLUE का एक कॉम्पोनेंट है.
BoolQ
बूलियन सवाल के लिए संक्षिप्त नाम.
C
CB
CommitmentBank का छोटा नाम.
कैरेक्टर एन-ग्राम F-स्कोर (ChrF)
यह मशीन ट्रांसलेशन मॉडल का आकलन करने के लिए इस्तेमाल की जाने वाली मेट्रिक है. वर्ण N-ग्राम F-स्कोर से यह पता चलता है कि रेफ़रंस टेक्स्ट में मौजूद N-ग्राम, एमएल मॉडल के जनरेट किए गए टेक्स्ट में मौजूद N-ग्राम से कितने मिलते-जुलते हैं.
कैरेक्टर एन-ग्राम एफ़-स्कोर, ROUGE और BLEU फ़ैमिली की मेट्रिक के जैसा ही होता है. हालांकि, इसमें ये अंतर होते हैं:
- वर्ण N-ग्राम F-स्कोर, वर्ण N-ग्राम पर काम करता है.
- ROUGE और BLEU, शब्द N-ग्राम या टोकन पर काम करते हैं.
COPA (Choice of Plausible Alternatives)
यह डेटासेट, इस बात का आकलन करने के लिए है कि कोई एलएलएम, किसी आधार के लिए दो विकल्पों में से बेहतर जवाब की पहचान कितनी अच्छी तरह से कर सकता है. डेटासेट में मौजूद हर चुनौती में तीन कॉम्पोनेंट होते हैं:
- कोई आधार वाक्य, जो आम तौर पर एक ऐसा वाक्य होता है जिसके बाद कोई सवाल पूछा जाता है
- आधार में दिए गए सवाल के दो संभावित जवाब, जिनमें से एक सही है और दूसरा गलत
- सही जवाब
उदाहरण के लिए:
- आधार: उस आदमी के पैर की उंगली टूट गई. इसकी वजह क्या थी?
- संभावित जवाब:
- उसकी मोज़े में छेद हो गया.
- उसने अपने पैर पर हथौड़ा गिरा लिया.
- सही जवाब: 2
COPA, SuperGLUE ensemble का एक कॉम्पोनेंट है.
कमिटमेंटबैंक (सीबी)
यह एक ऐसा डेटासेट है जिससे यह आकलन किया जाता है कि एलएलएम, किसी पैसेज के लेखक के बारे में यह पता लगाने में कितना माहिर है कि वह पैसेज में मौजूद किसी टारगेट क्लॉज़ पर भरोसा करता है या नहीं. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- एक पैसेज
- उस पैसेज में मौजूद टारगेट क्लॉज़
- बूलियन वैल्यू, जिससे यह पता चलता है कि पैसेज के लेखक का मानना है कि टारगेट क्लॉज़
उदाहरण के लिए:
- पैसेज: अर्टमिस की हंसी सुनकर बहुत अच्छा लगा. वह बहुत गंभीर बच्ची है. मुझे नहीं पता था कि वह इतनी मज़ेदार है.
- टारगेट क्लॉज़: वह मज़ेदार थी
- बूलियन: सही है. इसका मतलब है कि लेखक का मानना है कि टारगेट क्लॉज़
CommitmentBank, SuperGLUE का एक कॉम्पोनेंट है.
COPA
संभावित विकल्पों का चुनाव के लिए संक्षिप्त नाम.
लागत
loss का समानार्थी शब्द.
काउंटरफ़ैक्चुअल फ़ेयरनेस
यह निष्पक्षता मेट्रिक है. इससे यह पता चलता है कि क्या क्लासिफ़िकेशन मॉडल, एक व्यक्ति के लिए वही नतीजा देता है जो वह किसी दूसरे व्यक्ति के लिए देता है. हालांकि, दूसरा व्यक्ति पहले व्यक्ति जैसा ही होता है. इसमें एक या उससे ज़्यादा संवेदनशील एट्रिब्यूट को छोड़कर, बाकी सभी एट्रिब्यूट एक जैसे होते हैं. काउंटरफ़ैक्चुअल फ़ेयरनेस के लिए, क्लासिफ़िकेशन मॉडल का आकलन करना, मॉडल में पक्षपात के संभावित सोर्स का पता लगाने का एक तरीका है.
ज़्यादा जानकारी के लिए, इनमें से कोई एक लेख पढ़ें:
- मशीन लर्निंग क्रैश कोर्स में, निष्पक्षता: काउंटरफ़ैक्चुअल निष्पक्षता के बारे में जानें.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
क्रॉस-एंट्रॉपी
यह लॉग लॉस का सामान्यीकरण है. इसका इस्तेमाल एक से ज़्यादा क्लास वाले क्लासिफ़िकेशन की समस्याओं को हल करने के लिए किया जाता है. क्रॉस-एंट्रॉपी, दो प्रायिकता बंटनों के बीच के अंतर को मेज़र करती है. perplexity भी देखें.
क्यूमुलेटिव डिस्ट्रीब्यूशन फ़ंक्शन (सीडीएफ़)
यह फ़ंक्शन, टारगेट वैल्यू से कम या उसके बराबर सैंपल की फ़्रीक्वेंसी तय करता है. उदाहरण के लिए, लगातार वैल्यू के सामान्य डिस्ट्रिब्यूशन पर विचार करें. सीडीएफ़ से पता चलता है कि लगभग 50% सैंपल, औसत से कम या उसके बराबर होने चाहिए. साथ ही, लगभग 84% सैंपल, औसत से एक स्टैंडर्ड डेविएशन से कम या उसके बराबर होने चाहिए.
D
डेमोग्राफ़िक पैरिटी
यह एक निष्पक्षता मेट्रिक है. अगर किसी मॉडल के क्लासिफ़िकेशन के नतीजे, दिए गए संवेदनशील एट्रिब्यूट पर निर्भर नहीं करते हैं, तो यह मेट्रिक पूरी होती है.
उदाहरण के लिए, अगर ग्लबडबड्रिब यूनिवर्सिटी में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों आवेदन करते हैं, तो डेमोग्राफ़िक समानता तब हासिल होती है, जब यूनिवर्सिटी में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों को बराबर संख्या में दाखिला मिलता है. भले ही, एक ग्रुप दूसरे ग्रुप की तुलना में ज़्यादा योग्य हो.
इसकी तुलना समान अवसर और समान संभावना से करें. ये दोनों सिद्धांत, एग्रीगेट में क्लासिफ़िकेशन के नतीजों को संवेदनशील एट्रिब्यूट पर निर्भर रहने की अनुमति देते हैं. हालांकि, ये ग्राउंड ट्रुथ के कुछ खास लेबल के लिए, क्लासिफ़िकेशन के नतीजों को संवेदनशील एट्रिब्यूट पर निर्भर रहने की अनुमति नहीं देते. डेमोग्राफ़िक समानता के लिए ऑप्टिमाइज़ करते समय, फ़ायदे और नुकसान के बारे में जानने के लिए, "स्मार्ट मशीन लर्निंग की मदद से भेदभाव को खत्म करना" लेख में दिया गया विज़ुअलाइज़ेशन देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: डेमोग्राफ़िक समानता देखें.
E
अर्थ मूवर डिस्टेंस (ईएमडी)
यह दो डिस्ट्रीब्यूशन के बीच की समानता को मेज़र करता है. अर्थ मूवर की दूरी जितनी कम होगी, डिस्ट्रिब्यूशन उतना ही मिलता-जुलता होगा.
एडिट डिस्टेंस
इससे यह पता चलता है कि दो टेक्स्ट स्ट्रिंग एक-दूसरे से कितनी मिलती-जुलती हैं. मशीन लर्निंग में, एडिट डिस्टेंस इन वजहों से काम का होता है:
- एडिट डिस्टेंस का हिसाब लगाना आसान होता है.
- एडिट डिस्टेंस की मदद से, एक-दूसरे से मिलती-जुलती दो स्ट्रिंग की तुलना की जा सकती है.
- एडिट डिस्टेंस से यह पता लगाया जा सकता है कि अलग-अलग स्ट्रिंग, किसी दी गई स्ट्रिंग से कितनी मिलती-जुलती हैं.
एडिट डिस्टेंस की कई परिभाषाएं मौजूद हैं. हर परिभाषा में अलग-अलग स्ट्रिंग ऑपरेशन का इस्तेमाल किया जाता है. उदाहरण के लिए, लेवेंश्टाइन दूरी देखें.
अनुभवजन्य संचयी बंटन फ़ंक्शन (ईसीडीएफ़ या ईडीएफ़)
किसी असली डेटासेट से अनुभवजन्य मेज़रमेंट के आधार पर तैयार किया गया क्यूमुलेटिव डिस्ट्रिब्यूशन फ़ंक्शन. x-ऐक्सिस पर किसी भी पॉइंट पर फ़ंक्शन की वैल्यू, डेटासेट में मौजूद उन ऑब्ज़र्वेशन का फ़्रैक्शन होती है जो तय की गई वैल्यू से कम या उसके बराबर होती हैं.
एन्ट्रॉपी
सूचना सिद्धांत में, यह बताया जाता है कि किसी संभावना के डिस्ट्रिब्यूशन का अनुमान लगाना कितना मुश्किल है. इसके अलावा, एंट्रॉपी को इस तरह भी परिभाषित किया जाता है कि हर उदाहरण में कितनी जानकारी शामिल है. किसी डिस्ट्रिब्यूशन की एंट्रॉपी सबसे ज़्यादा तब होती है, जब रैंडम वैरिएबल की सभी वैल्यू की संभावना बराबर होती है.
दो संभावित वैल्यू "0" और "1" वाले सेट की एंट्रॉपी (उदाहरण के लिए, बाइनरी क्लासिफ़िकेशन की समस्या में लेबल) का फ़ॉर्मूला यह है:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
कहां:
- H एन्ट्रॉपी है.
- p, "1" उदाहरणों का फ़्रैक्शन है.
- q, "0" उदाहरणों का फ़्रैक्शन है. ध्यान दें कि q = (1 - p)
- log आम तौर पर log2 होता है. इस मामले में, एंट्रॉपी यूनिट एक बिट है.
उदाहरण के लिए, मान लें कि:
- 100 उदाहरणों में "1" वैल्यू मौजूद है
- 300 उदाहरणों में वैल्यू "0" मौजूद है
इसलिए, एन्ट्रापी की वैल्यू यह है:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 बिट प्रति उदाहरण
पूरी तरह से संतुलित सेट (उदाहरण के लिए, 200 "0" और 200 "1") में, हर उदाहरण के लिए एंट्रॉपी 1.0 बिट होगी. सेट जितना ज़्यादा इंबैलेंस होता है, उसकी एंट्रॉपी 0.0 की ओर बढ़ती है.
डिसिज़न ट्री में, एंट्रॉपी सूचना लाभ को फ़ॉर्म्युलेट करने में मदद करती है. इससे स्प्लिटर को क्लासिफ़िकेशन डिसिज़न ट्री के बढ़ने के दौरान शर्तें चुनने में मदद मिलती है.
एंट्रॉपी की तुलना इससे करें:
- गिनी अशुद्धता
- क्रॉस-एंट्रॉपी लॉस फ़ंक्शन
एंट्रॉपी को अक्सर शैनन की एंट्रॉपी कहा जाता है.
ज़्यादा जानकारी के लिए, फ़ैसले लेने वाले फ़ॉरेस्ट कोर्स में संख्यात्मक सुविधाओं के साथ बाइनरी क्लासिफ़िकेशन के लिए सटीक स्प्लिटर देखें.
समान अवसर
निष्पक्षता मेट्रिक का इस्तेमाल यह आकलन करने के लिए किया जाता है कि कोई मॉडल, संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए, एक जैसा और सही नतीजा दे रहा है या नहीं. दूसरे शब्दों में कहें, तो अगर किसी मॉडल के लिए, पॉज़िटिव क्लास सबसे अच्छा नतीजा है, तो सभी ग्रुप के लिए ट्रू पॉज़िटिव रेट एक जैसा होना चाहिए.
अवसर की समानता, समान ऑड्स से जुड़ी होती है. इसके लिए, यह ज़रूरी है कि सभी ग्रुप के लिए, सही पॉज़िटिव रेट और फ़ॉल्स पॉज़िटिव रेट एक जैसे हों.
मान लें कि ग्लबडबड्रिब यूनिवर्सिटी, गणित के एक मुश्किल प्रोग्राम में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों को शामिल करती है. लिलिपुट के सेकंडरी स्कूलों में, गणित की क्लास के लिए एक मज़बूत पाठ्यक्रम उपलब्ध कराया जाता है. साथ ही, ज़्यादातर छात्र-छात्राएं यूनिवर्सिटी प्रोग्राम के लिए ज़रूरी शर्तें पूरी करते हैं. ब्रॉबडिंगनैग के सेकंडरी स्कूलों में गणित की क्लास नहीं होती हैं. इसलिए, वहां के बहुत कम छात्र-छात्राएं गणित में पास हो पाते हैं. अगर ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं को, उनकी राष्ट्रीयता (लिलिपुटियन या ब्रॉबडिंगनैगियन) के आधार पर भेदभाव किए बिना बराबर मौके मिलते हैं, तो राष्ट्रीयता के हिसाब से "स्वीकार किया गया" लेबल के लिए, अवसरों की समानता की शर्त पूरी होती है.
उदाहरण के लिए, मान लें कि ग्लबडबड्रिब यूनिवर्सिटी में 100 बौने और 100 विशालकाय लोगों ने आवेदन किया है. इसके बाद, एडमिशन के फ़ैसले इस तरह लिए जाते हैं:
पहली टेबल. छोटे कारोबारों के लिए आवेदन करने वाले लोग या कंपनियां (इनमें से 90% ने ज़रूरी शर्तें पूरी की हैं)
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 45 | 3 |
| नामंजूर | 45 | 7 |
| कुल | 90 | 10 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से चुने गए छात्र-छात्राओं का प्रतिशत: 45/90 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से अस्वीकार किए गए छात्र-छात्राओं का प्रतिशत: 7/10 = 70% लिलिपुटियन स्कूल में चुने गए छात्र-छात्राओं का कुल प्रतिशत: (45+3)/100 = 48% |
||
टेबल 2. बहुत ज़्यादा आवेदन करने वाले लोग (इनमें से 10% लोग ज़रूरी शर्तें पूरी करते हैं):
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 5 | 9 |
| नामंजूर | 5 | 81 |
| कुल | 10 | 90 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से दाखिला पाने वालों का प्रतिशत: 5/10 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से दाखिला न पाने वालों का प्रतिशत: 81/90 = 90% ब्रॉबडिंगनैगियन छात्र-छात्राओं में से दाखिला पाने वालों का कुल प्रतिशत: (5+9)/100 = 14% |
||
ऊपर दिए गए उदाहरणों में, ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं को बराबर का मौका दिया गया है. ऐसा इसलिए, क्योंकि ज़रूरी शर्तें पूरी करने वाले Lilliputians और Brobdingnagians, दोनों को 50% मौका मिला है.
अवसर की समानता की शर्त पूरी होती है, लेकिन निष्पक्षता से जुड़ी ये दो मेट्रिक पूरी नहीं होती हैं:
- जनसांख्यिकी समानता: लिलिपुटियन और ब्रॉबडिंगनैगियन को अलग-अलग दरों पर यूनिवर्सिटी में दाखिला मिलता है; 48% लिलिपुटियन छात्र-छात्राओं को दाखिला मिलता है, लेकिन सिर्फ़ 14% ब्रॉबडिंगनैगियन छात्र-छात्राओं को दाखिला मिलता है.
- समान अवसर: ज़रूरी शर्तें पूरी करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्र-छात्राओं को दाखिला मिलने की संभावना बराबर होती है. हालांकि, ज़रूरी शर्तें पूरी न करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्र-छात्राओं को दाखिला न मिलने की संभावना बराबर होने की अतिरिक्त शर्त पूरी नहीं होती. ज़रूरी शर्तें पूरी न करने वाले Lilliputians के लिए, अस्वीकार किए जाने की दर 70% है. वहीं, ज़रूरी शर्तें पूरी न करने वाले Brobdingnagians के लिए, अस्वीकार किए जाने की दर 90% है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में निष्पक्षता: अवसर की समानता देखें.
ऑड बराबर करना
यह निष्पक्षता से जुड़ी मेट्रिक है. इससे यह आकलन किया जाता है कि कोई मॉडल, संवेदनशील एट्रिब्यूट की सभी वैल्यू के लिए, पॉज़िटिव क्लास और नेगेटिव क्लास, दोनों के लिए एक जैसे नतीजे दे रहा है या नहीं. ऐसा नहीं होना चाहिए कि वह सिर्फ़ एक क्लास के लिए अच्छे नतीजे दे रहा हो. दूसरे शब्दों में कहें, तो सभी ग्रुप के लिए ट्रू पॉज़िटिव रेट और फ़ॉल्स नेगेटिव रेट एक जैसा होना चाहिए.
ऑड को बराबर करने का सिद्धांत, अवसर की समानता से जुड़ा है. यह सिर्फ़ एक क्लास (पॉज़िटिव या नेगेटिव) के लिए गड़बड़ी की दरों पर फ़ोकस करता है.
उदाहरण के लिए, मान लें कि ग्लबडबड्रिब यूनिवर्सिटी, गणित के एक मुश्किल प्रोग्राम में लिलीपुटियन और ब्रॉबडिंगनैगियन, दोनों को दाखिला देती है. लिलिपुटियन के सेकंडरी स्कूलों में, गणित की क्लास के लिए एक मज़बूत पाठ्यक्रम उपलब्ध कराया जाता है. साथ ही, ज़्यादातर छात्र-छात्राएं यूनिवर्सिटी प्रोग्राम के लिए ज़रूरी शर्तें पूरी करते हैं. ब्रोबडिंगनैग के सेकंडरी स्कूलों में गणित की क्लास नहीं होती हैं. इसलिए, वहां के बहुत कम छात्र-छात्राएं इस परीक्षा को पास कर पाते हैं. अगर कोई व्यक्ति छोटा है या बड़ा, इससे कोई फ़र्क़ नहीं पड़ता. अगर वह ज़रूरी शर्तें पूरी करता है, तो उसे प्रोग्राम में शामिल होने का उतना ही मौका मिलेगा जितना किसी और व्यक्ति को. इसी तरह, अगर वह ज़रूरी शर्तें पूरी नहीं करता है, तो उसे प्रोग्राम में शामिल होने का उतना ही मौका मिलेगा जितना किसी और व्यक्ति को.
मान लें कि ग्लबडबड्रिब यूनिवर्सिटी में 100 लिलिपुटियन और 100 ब्रॉबडिंगनैगियन ने आवेदन किया है. इसके बाद, एडमिशन के फ़ैसले इस तरह लिए जाते हैं:
तीसरी टेबल. छोटे कारोबारों के लिए आवेदन करने वाले लोग या कंपनियां (इनमें से 90% ने ज़रूरी शर्तें पूरी की हैं)
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 45 | 2 |
| नामंजूर | 45 | 8 |
| कुल | 90 | 10 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से, दाखिला पाने वाले छात्र-छात्राओं का प्रतिशत: 45/90 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से, दाखिला न पाने वाले छात्र-छात्राओं का प्रतिशत: 8/10 = 80% लिलिपुटियन स्कूल में दाखिला पाने वाले छात्र-छात्राओं का कुल प्रतिशत: (45+2)/100 = 47% |
||
चौथी टेबल. बहुत ज़्यादा आवेदन करने वाले लोग (इनमें से 10% लोग ज़रूरी शर्तें पूरी करते हैं):
| क्वालिफ़ाई हुई | अयोग्य | |
|---|---|---|
| स्वीकार किया गया | 5 | 18 |
| नामंजूर | 5 | 72 |
| कुल | 10 | 90 |
|
ज़रूरी शर्तें पूरी करने वाले छात्र-छात्राओं में से चुने गए छात्र-छात्राओं का प्रतिशत: 5/10 = 50% ज़रूरी शर्तें पूरी न करने वाले छात्र-छात्राओं में से अस्वीकार किए गए छात्र-छात्राओं का प्रतिशत: 72/90 = 80% Brobdingnagian के कुल छात्र-छात्राओं में से चुने गए छात्र-छात्राओं का प्रतिशत: (5+18)/100 = 23% |
||
इस उदाहरण में, 'समान अवसर' सिद्धांत का पालन किया गया है. ऐसा इसलिए, क्योंकि परीक्षा पास करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्रों को 50% संभावना के साथ दाखिला मिल सकता है. वहीं, परीक्षा पास न करने वाले Lilliputian और Brobdingnagian, दोनों तरह के छात्रों को 80% संभावना के साथ दाखिला नहीं मिल सकता.
"Equality of Opportunity in Supervised Learning" में, समान अवसर को इस तरह से औपचारिक तौर पर परिभाषित किया गया है: "अगर Ŷ और A, Y के आधार पर स्वतंत्र हैं, तो अनुमान लगाने वाला Ŷ, सुरक्षित एट्रिब्यूट A और नतीजे Y के हिसाब से समान अवसर की शर्त पूरी करता है."
आकलन
इसका इस्तेमाल मुख्य रूप से, एलएलएम के आकलन के लिए किया जाता है. मोटे तौर पर, इवैल, इवैलुएशन का संक्षिप्त रूप है.
आकलन
किसी मॉडल की क्वालिटी को मेज़र करने या अलग-अलग मॉडल की तुलना करने की प्रोसेस.
सुपरवाइज़्ड मशीन लर्निंग मॉडल का आकलन करने के लिए, आम तौर पर इसकी तुलना मान्य डेटा सेट और टेस्ट डेटा सेट से की जाती है. किसी एलएलएम का आकलन करने में आम तौर पर, क्वालिटी और सुरक्षा से जुड़े बड़े पैमाने पर आकलन शामिल होते हैं.
पूरा मैच
यह एक ऐसी मेट्रिक है जिसमें मॉडल का आउटपुट, ग्राउंड ट्रुथ या रेफ़रंस टेक्स्ट से पूरी तरह मेल खाता है या नहीं खाता. उदाहरण के लिए, अगर ग्राउंड ट्रुथ orange है, तो मॉडल का सिर्फ़ orange आउटपुट, सटीक मिलान की शर्त को पूरा करता है.
सटीक मैच, उन मॉडल का भी आकलन कर सकता है जिनका आउटपुट एक क्रम (आइटम की रैंक की गई सूची) होता है. आम तौर पर, एग्ज़ैक्ट मैच के लिए ज़रूरी है कि रैंक की गई जनरेट की गई सूची, ग्राउंड ट्रुथ से पूरी तरह मेल खाए. इसका मतलब है कि दोनों सूचियों में मौजूद हर आइटम एक ही क्रम में होना चाहिए. हालांकि, अगर ग्राउंड ट्रुथ में एक से ज़्यादा सही क्रम शामिल हैं, तो पूरी तरह मेल खाने वाले जवाब के लिए, यह ज़रूरी है कि मॉडल का आउटपुट, सही क्रम में से किसी एक से मेल खाता हो.
एक्सट्रीम समराइज़ेशन (xsum)
यह एक ऐसा डेटासेट है जिसका इस्तेमाल, किसी एक दस्तावेज़ की खास जानकारी देने की एलएलएम की क्षमता का आकलन करने के लिए किया जाता है. डेटासेट की हर एंट्री में ये शामिल होते हैं:
- ब्रिटिश ब्रॉडकास्टिंग कॉर्पोरेशन (बीबीसी) का लिखा हुआ दस्तावेज़.
- उस दस्तावेज़ की एक वाक्य में खास जानकारी.
ज़्यादा जानकारी के लिए, मुझे ज़्यादा जानकारी नहीं चाहिए, सिर्फ़ खास जानकारी चाहिए! विषय के हिसाब से कॉन्वलूशनल न्यूरल नेटवर्क की मदद से, टेक्स्ट को छोटा करना.
F
F1
यह एक "रोल-अप" बाइनरी क्लासिफ़िकेशन मेट्रिक है. यह प्रिसिज़न और रीकॉल, दोनों पर निर्भर करती है. यहां फ़ॉर्मूला दिया गया है:
निष्पक्षता मेट्रिक
"निष्पक्षता" की गणितीय परिभाषा, जिसे मापा जा सकता है. आम तौर पर इस्तेमाल की जाने वाली निष्पक्षता मेट्रिक में ये शामिल हैं:
निष्पक्षता से जुड़ी कई मेट्रिक एक-दूसरे से अलग होती हैं. निष्पक्षता से जुड़ी मेट्रिक का एक-दूसरे के साथ काम न करना लेख पढ़ें.
फ़ॉल्स नेगेटिव (FN)
इस उदाहरण में, मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम नहीं है (नेगेटिव क्लास), लेकिन वह ईमेल मैसेज असल में स्पैम है.
खतरे को कम आंकने की दर
यह असल पॉज़िटिव उदाहरणों का अनुपात है जिनके लिए मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया. नीचे दिए गए फ़ॉर्मूले से, फ़ॉल्स नेगेटिव रेट का हिसाब लगाया जाता है:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
फ़ॉल्स पॉज़िटिव (FP)
ऐसा उदाहरण जिसमें मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया है. उदाहरण के लिए, मॉडल का अनुमान है कि कोई ईमेल मैसेज स्पैम (पॉज़िटिव क्लास) है, लेकिन वह ईमेल मैसेज असल में स्पैम नहीं है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में थ्रेशोल्ड और कन्फ़्यूज़न मैट्रिक्स देखें.
फ़ॉल्स पॉज़िटिव रेट (एफ़पीआर)
यह असल नेगेटिव उदाहरणों का अनुपात है जिनके लिए मॉडल ने गलती से पॉज़िटिव क्लास का अनुमान लगाया. यहां दिए गए फ़ॉर्मूले से, फ़ॉल्स पॉज़िटिव रेट का हिसाब लगाया जाता है:
फ़ॉल्स पॉज़िटिव रेट, आरओसी कर्व में x-ऐक्सिस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: आरओसी और एयूसी देखें.
सुविधा की अहमियत
यह बदलाव के हिसाब से अहमियत का समानार्थी शब्द है.
फ़ाउंडेशन मॉडल
यह एक बहुत बड़ा पहले से ट्रेन किया गया मॉडल है. इसे अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेन किया गया है. फ़ाउंडेशन मॉडल, यहां दिए गए दोनों काम कर सकता है:
- अलग-अलग तरह के अनुरोधों का सही जवाब दे सकता है.
- यह अन्य फ़ाइन-ट्यूनिंग या पसंद के मुताबिक बनाने के लिए, बेस मॉडल के तौर पर काम करता है.
दूसरे शब्दों में कहें, तो फ़ाउंडेशन मॉडल सामान्य तौर पर पहले से ही बहुत बेहतर होता है. हालांकि, इसे किसी खास काम के लिए और भी ज़्यादा बेहतर बनाया जा सकता है.
सफलताओं का फ़्रैक्शन
यह एमएल मॉडल के जनरेट किए गए टेक्स्ट का आकलन करने के लिए इस्तेमाल की जाने वाली मेट्रिक है. सफलता की दर, जनरेट किए गए "सफल" टेक्स्ट आउटपुट की संख्या को जनरेट किए गए टेक्स्ट आउटपुट की कुल संख्या से भाग देने पर मिलती है. उदाहरण के लिए, अगर किसी लार्ज लैंग्वेज मॉडल ने कोड के 10 ब्लॉक जनरेट किए हैं और उनमें से पांच ब्लॉक सही हैं, तो सही ब्लॉक का फ़्रैक्शन 50% होगा.
हालांकि, आंकड़ों में फ़्रैक्शन ऑफ़ सक्सेस काफ़ी काम आता है, लेकिन एमएल में यह मेट्रिक मुख्य रूप से ऐसे कामों का आकलन करने के लिए काम आती है जिनकी पुष्टि की जा सकती है. जैसे, कोड जनरेट करना या गणित की समस्याएं हल करना.
G
गिनी अशुद्धता
एंट्रॉपी से मिलती-जुलती मेट्रिक. स्प्लिटर, क्लासिफ़िकेशन डिसिज़न ट्री के लिए शर्तें बनाने के लिए, गिनी इंप्योरिटी या एंट्रॉपी से मिली वैल्यू का इस्तेमाल करते हैं. सूचना लाभ, एंट्रॉपी से मिलता है. गिनी अशुद्धता से निकाली गई मेट्रिक के लिए, कोई भी ऐसा शब्द नहीं है जिसे हर जगह इस्तेमाल किया जा सके. हालांकि, यह बिना नाम वाली मेट्रिक, सूचना के फ़ायदे जितनी ही अहम होती है.
Gini अशुद्धता को gini इंडेक्स या सिर्फ़ gini भी कहा जाता है.
H
हिंज लॉस
यह loss फ़ंक्शन का एक फ़ैमिली है. इसे classification के लिए डिज़ाइन किया गया है. इसका मकसद, decision boundary को हर ट्रेनिंग उदाहरण से ज़्यादा से ज़्यादा दूरी पर रखना है. इससे उदाहरणों और बाउंड्री के बीच मार्जिन बढ़ जाता है. KSVM, हिंज लॉस (या इससे जुड़ा कोई फ़ंक्शन, जैसे कि स्क्वेयर्ड हिंज लॉस) का इस्तेमाल करते हैं. बाइनरी क्लासिफ़िकेशन के लिए, हिंज लॉस फ़ंक्शन को इस तरह से परिभाषित किया गया है:
यहां y, सही लेबल है. यह -1 या +1 हो सकता है. साथ ही, y', क्लासिफ़िकेशन मॉडल का रॉ आउटपुट है:
इसलिए, हिंज लॉस बनाम (y * y') का प्लॉट इस तरह दिखता है:

I
निष्पक्षता से जुड़ी मेट्रिक का साथ में काम न करना
इस सिद्धांत के मुताबिक, निष्पक्षता के कुछ सिद्धांत एक-दूसरे के साथ काम नहीं करते और उन्हें एक साथ लागू नहीं किया जा सकता. इस वजह से, निष्पक्षता का आकलन करने के लिए कोई एक मेट्रिक नहीं है, जिसे एमएल से जुड़ी सभी समस्याओं पर लागू किया जा सके.
हालांकि, यह निराशाजनक लग सकता है, लेकिन निष्पक्षता की मेट्रिक के काम न करने का मतलब यह नहीं है कि निष्पक्षता के लिए की गई कोशिशें बेकार हैं. इसके बजाय, इसमें यह सुझाव दिया गया है कि एमएल से जुड़ी किसी समस्या के लिए, निष्पक्षता को कॉन्टेक्स्ट के हिसाब से तय किया जाना चाहिए. साथ ही, इसका मकसद इस्तेमाल के उदाहरणों से होने वाले नुकसान को रोकना होना चाहिए.
निष्पक्षता की मेट्रिक के काम न करने के बारे में ज़्यादा जानकारी के लिए, "On the (im)possibility of fairness" लेख पढ़ें.
व्यक्तिगत निष्पक्षता
यह निष्पक्षता से जुड़ी मेट्रिक है. इससे यह पता चलता है कि एक जैसे लोगों को एक ही कैटगरी में रखा गया है या नहीं. उदाहरण के लिए, Brobdingnagian Academy यह पक्का करके, व्यक्तिगत निष्पक्षता के सिद्धांत का पालन करना चाहेगी कि एक जैसे ग्रेड और स्टैंडर्ड टेस्ट स्कोर वाले दो छात्र-छात्राओं को एडमिशन मिलने की संभावना बराबर हो.
ध्यान दें कि किसी व्यक्ति के साथ निष्पक्षता से व्यवहार करना, पूरी तरह से इस बात पर निर्भर करता है कि आपने "समानता" को कैसे परिभाषित किया है. इस मामले में, ग्रेड और टेस्ट स्कोर. अगर समानता की मेट्रिक में ज़रूरी जानकारी शामिल नहीं है, तो निष्पक्षता से जुड़ी नई समस्याएं पैदा हो सकती हैं. जैसे, छात्र-छात्रा के पाठ्यक्रम की गंभीरता.
व्यक्तिगत निष्पक्षता के बारे में ज़्यादा जानकारी के लिए, "Fairness Through Awareness" देखें.
सूचना का फ़ायदा
डिसिज़न फ़ॉरेस्ट में, किसी नोड की एंट्रॉपी और उसके चाइल्ड नोड की एंट्रॉपी के वज़न (उदाहरणों की संख्या के हिसाब से) के योग के बीच का अंतर. किसी नोड की एंट्रॉपी, उस नोड में मौजूद उदाहरणों की एंट्रॉपी होती है.
उदाहरण के लिए, यहां दी गई एंट्रॉपी वैल्यू देखें:
- पैरंट नोड की एन्ट्रॉपी = 0.6
- काम के 16 उदाहरणों वाले एक चाइल्ड नोड की एंट्रॉपी = 0.2
- काम के 24 उदाहरणों वाले दूसरे चाइल्ड नोड की एंट्रॉपी = 0.1
इसलिए, 40% उदाहरण एक चाइल्ड नोड में हैं और 60% उदाहरण दूसरे चाइल्ड नोड में हैं. इसलिए:
- चाइल्ड नोड के वेटेड एंट्रॉपी का योग = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
इसलिए, जानकारी में हुई बढ़ोतरी यह है:
- सूचना में बढ़ोतरी = पैरंट नोड की एंट्रॉपी - चाइल्ड नोड की वज़न के हिसाब से एंट्रॉपी का योग
- information gain = 0.6 - 0.14 = 0.46
ज़्यादातर स्प्लिटर, शर्तें बनाने की कोशिश करते हैं, ताकि ज़्यादा से ज़्यादा जानकारी मिल सके.
इंटर-रेटर एग्रीमेंट
इससे यह पता चलता है कि किसी टास्क को पूरा करते समय, ह्यूमन रेटर कितनी बार एक-दूसरे से सहमत होते हैं. अगर रेटिंग देने वाले लोग सहमत नहीं हैं, तो टास्क के निर्देशों में सुधार करना पड़ सकता है. इसे कभी-कभी इंटर-एनोटेटर एग्रीमेंट या इंटर-रेटर रिलायबिलिटी भी कहा जाता है. यह भी देखें कोहेन का कप्पा, जो दो लोगों के बीच सहमति का आकलन करने के सबसे लोकप्रिय तरीकों में से एक है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में कैटगोरिकल डेटा: सामान्य समस्याएं देखें.
L
L1 नुकसान
यह एक लॉस फ़ंक्शन है. यह असल लेबल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर की ऐब्सलूट वैल्यू कैलकुलेट करता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L1 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा की ऐब्सलूट वैल्यू |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 लॉस | ||
L1 लॉस, L2 लॉस की तुलना में आउटलायर के लिए कम संवेदनशील होता है.
कुल गड़बड़ी का मध्यमान, हर उदाहरण के लिए औसत L1 लॉस होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लीनियर रिग्रेशन: लॉस देखें.
L2 नुकसान
यह एक लॉस फ़ंक्शन है. यह असल लेबल वैल्यू और मॉडल की अनुमानित वैल्यू के बीच के अंतर का स्क्वेयर कैलकुलेट करता है. उदाहरण के लिए, यहां पांच उदाहरणों के बैच के लिए, L2 लॉस की गणना दी गई है:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | डेल्टा का स्क्वेयर |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 लॉस | ||
स्क्वेयर करने की वजह से, L2 लॉस, आउटलायर के असर को बढ़ा देता है. इसका मतलब है कि खराब अनुमानों पर, L1 लॉस की तुलना में L2 लॉस ज़्यादा असर डालता है. उदाहरण के लिए, पिछले बैच के लिए L1 लॉस, 16 के बजाय 8 होगा. ध्यान दें कि एक आउटलायर, 16 में से 9 के लिए ज़िम्मेदार है.
रिग्रेशन मॉडल, आम तौर पर लॉस फ़ंक्शन के तौर पर L2 लॉस का इस्तेमाल करते हैं.
मीन स्क्वेयर्ड एरर, हर उदाहरण के लिए औसत L2 लॉस होता है. स्क्वेयर्ड लॉस को L2 लॉस भी कहा जाता है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लॉजिस्टिक रिग्रेशन: लॉस और रेगुलराइज़ेशन देखें.
एलएलएम के आकलन (इवैल)
यह लार्ज लैंग्वेज मॉडल (एलएलएम) की परफ़ॉर्मेंस का आकलन करने के लिए, मेट्रिक और बेंचमार्क का एक सेट है. एलएलएम के आकलन के लिए, ये काम किए जाते हैं:
- शोधकर्ताओं को उन क्षेत्रों की पहचान करने में मदद करना जहां एलएलएम को बेहतर बनाने की ज़रूरत है.
- इनसे अलग-अलग एलएलएम की तुलना करने और किसी टास्क के लिए सबसे सही एलएलएम की पहचान करने में मदद मिलती है.
- यह पक्का करने में मदद करना कि एलएलएम का इस्तेमाल सुरक्षित और ज़िम्मेदारी से किया जा रहा है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल (एलएलएम) देखें.
हार की वजह से
निगरानी वाले मॉडल की ट्रेनिंग के दौरान, यह मेज़रमेंट किया जाता है कि मॉडल का अनुमान, उसके लेबल से कितना अलग है.
लॉस फ़ंक्शन, लॉस का हिसाब लगाता है.
ज़्यादा जानकारी के लिए, Machine Learning Crash Course में लीनियर रिग्रेशन: लॉस देखें.
लॉस फ़ंक्शन
ट्रेनिंग या टेस्टिंग के दौरान, यह एक गणितीय फ़ंक्शन होता है. यह उदाहरणों के बैच के नुकसान की गणना करता है. लॉस फ़ंक्शन, अनुमान लगाने वाले मॉडल के लिए कम लॉस दिखाता है. ऐसा उन मॉडल के मुकाबले होता है जो खराब अनुमान लगाते हैं.
ट्रेनिंग का मकसद आम तौर पर, लॉस फ़ंक्शन से मिलने वाले नुकसान को कम करना होता है.
कई तरह के लॉस फ़ंक्शन मौजूद हैं. बनाए जा रहे मॉडल के हिसाब से, सही लॉस फ़ंक्शन चुनें. उदाहरण के लिए:
- L2 लॉस (या मीन स्क्वेयर्ड एरर), लीनियर रिग्रेशन के लिए लॉस फ़ंक्शन होता है.
- लॉग लॉस, लॉजिस्टिक्स रिग्रेशन के लिए लॉस फ़ंक्शन है.
M
MBPP
Mostly Basic Python Problems का संक्षिप्त नाम.
मीन ऐब्सॉल्यूट एरर (MAE)
L1 लॉस का इस्तेमाल करने पर, हर उदाहरण के लिए औसत लॉस. कुल गड़बड़ी का मध्यमान इस तरह कैलकुलेट करें:
- किसी बैच के लिए L1 लॉस कैलकुलेट करें.
- बैच में मौजूद उदाहरणों की संख्या से L1 लॉस को भाग दें.
उदाहरण के लिए, पांच उदाहरणों के इस बैच में L1 नुकसान के कैलकुलेशन पर विचार करें:
| उदाहरण की असल वैल्यू | मॉडल की अनुमानित वैल्यू | नुकसान (असल और अनुमानित वैल्यू के बीच का अंतर) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 लॉस | ||
इसलिए, L1 लॉस 8 है और उदाहरणों की संख्या 5 है. इसलिए, कुल गड़बड़ी का मध्यमान यह है:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
मीन स्क्वेयर्ड एरर और रूट मीन स्क्वेयर्ड एरर के साथ, कॉन्ट्रास्ट मीन ऐब्सलूट एरर की तुलना करें.
k पर औसत सटीक नतीजे (mAP@k)
यह पुष्टि करने वाले डेटासेट में, सभी k पर औसत सटीक स्कोर का सांख्यिकीय माध्य होता है. के पर औसत सटीक दर का इस्तेमाल, सुझाव देने वाले सिस्टम से जनरेट किए गए सुझावों की क्वालिटी का आकलन करने के लिए किया जाता है.
भले ही, "औसत" शब्द का इस्तेमाल दो बार किया गया है, लेकिन मेट्रिक का नाम सही है. आखिरकार, यह मेट्रिक कई k पर औसत सटीक दर वैल्यू का औसत निकालती है.
मीन स्क्वेयर्ड एरर (एमएसई)
L2 लॉस का इस्तेमाल करने पर, हर उदाहरण के लिए औसत लॉस. मीन स्क्वेयर्ड एरर की गणना इस तरह करें:
- किसी बैच के लिए L2 लॉस की गणना करता है.
- L2 लॉस को बैच में मौजूद उदाहरणों की संख्या से भाग दें.
उदाहरण के लिए, पांच उदाहरणों के इस बैच में हुए नुकसान पर विचार करें:
| वास्तविक मान | मॉडल का अनुमान | हार | स्क्वेयर्ड लॉस |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 लॉस | |||
इसलिए, वर्ग में गड़बड़ी का माध्य यह है:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
वर्ग में गड़बड़ी का माध्य, ट्रेनिंग के लिए इस्तेमाल किया जाने वाला एक लोकप्रिय ऑप्टिमाइज़र है. यह खास तौर पर लीनियर रिग्रेशन के लिए इस्तेमाल किया जाता है.
मीन ऐब्सलूट एरर और रूट मीन स्क्वेयर्ड एरर के साथ कॉन्ट्रास्ट मीन स्क्वेयर्ड एरर की तुलना करें.
TensorFlow Playground, लॉस वैल्यू का हिसाब लगाने के लिए, माध्य वर्ग त्रुटि का इस्तेमाल करता है.
मीट्रिक
वह आंकड़ा जो आपके लिए अहम है.
मकसद एक ऐसी मेट्रिक होती है जिसे मशीन लर्निंग सिस्टम ऑप्टिमाइज़ करने की कोशिश करता है.
Metrics API (tf.metrics)
मॉडल का आकलन करने के लिए, TensorFlow API. उदाहरण के लिए, tf.metrics.accuracy
से यह तय होता है कि मॉडल के अनुमान, लेबल से कितनी बार मेल खाते हैं.
minimax loss
यह जनरेटिव ऐडवर्सैरियल नेटवर्क के लिए एक लॉस फ़ंक्शन है. यह जनरेट किए गए डेटा और असली डेटा के डिस्ट्रिब्यूशन के बीच क्रॉस-एंट्रॉपी पर आधारित होता है.
जनरेटिव ऐडवर्सैरियल नेटवर्क के बारे में बताने के लिए, पहले पेपर में मिनिमैक्स लॉस का इस्तेमाल किया गया है.
ज़्यादा जानकारी के लिए, जनरेटिव ऐडवर्सैरियल नेटवर्क कोर्स में लॉस फ़ंक्शन देखें.
मॉडल की क्षमता
समस्याओं की जटिलता, जिसे मॉडल सीख सकता है. कोई मॉडल जितनी मुश्किल समस्याओं को हल करना सीख सकता है, उसकी क्षमता उतनी ही ज़्यादा होती है. मॉडल के पैरामीटर की संख्या बढ़ने पर, आम तौर पर मॉडल की क्षमता बढ़ जाती है. क्लासिफ़िकेशन मॉडल की क्षमता की औपचारिक परिभाषा के लिए, वीसी डाइमेंशन देखें.
Mostly Basic Python Problems (MBPP)
यह एक ऐसा डेटासेट है जिससे यह पता लगाया जा सकता है कि एलएलएम, Python कोड जनरेट करने में कितना माहिर है. Mostly Basic Python Problems में, क्राउडसोर्सिंग से मिली प्रोग्रामिंग की करीब 1,000 समस्याएं दी गई हैं. डेटासेट में मौजूद हर समस्या में यह जानकारी शामिल होती है:
- टास्क के बारे में जानकारी
- सॉल्यूशन कोड
- तीन ऑटोमेटेड टेस्ट केस
नहीं
नेगेटिव क्लास
बाइनरी क्लासिफ़िकेशन में, एक क्लास को पॉज़िटिव और दूसरी क्लास को नेगेटिव कहा जाता है. पॉज़िटिव क्लास, वह चीज़ या इवेंट होता है जिसके लिए मॉडल की टेस्टिंग की जा रही है. वहीं, नेगेटिव क्लास, दूसरी संभावना होती है. उदाहरण के लिए:
- मेडिकल टेस्ट में नेगेटिव क्लास "ट्यूमर नहीं है" हो सकती है.
- ईमेल के क्लासिफ़िकेशन मॉडल में नेगेटिव क्लास "स्पैम नहीं है" हो सकती है.
पॉज़िटिव क्लास से तुलना करें.
O
कैंपेन का मकसद
मेट्रिक, जिसे आपका एल्गोरिदम ऑप्टिमाइज़ करने की कोशिश कर रहा है.
ऑब्जेक्टिव फ़ंक्शन
गणित का फ़ॉर्मूला या मेट्रिक जिसे मॉडल ऑप्टिमाइज़ करने का लक्ष्य रखता है. उदाहरण के लिए, लीनियर रिग्रेशन के लिए ऑब्जेक्टिव फ़ंक्शन, आम तौर पर मीन स्क्वेयर्ड लॉस होता है. इसलिए, लीनियर रिग्रेशन मॉडल को ट्रेन करते समय, ट्रेनिंग का मकसद औसत स्क्वेयर्ड लॉस को कम करना होता है.
कुछ मामलों में, मकसद फ़ंक्शन को बढ़ाने का होता है. उदाहरण के लिए, अगर ऑब्जेक्टिव फ़ंक्शन सटीक होना है, तो लक्ष्य सटीक होने की संभावना को बढ़ाना है.
loss भी देखें.
P
पास ऐट के (pass@k)
यह एक ऐसी मेट्रिक है जिससे लार्ज लैंग्वेज मॉडल से जनरेट किए गए कोड (उदाहरण के लिए, Python) की क्वालिटी का पता चलता है. खास तौर पर, पास ऐट k से पता चलता है कि जनरेट किए गए k कोड ब्लॉक में से कम से कम एक कोड ब्लॉक, यूनिट टेस्ट के सभी चरणों को पास कर लेगा.
लार्ज लैंग्वेज मॉडल को अक्सर जटिल प्रोग्रामिंग समस्याओं के लिए अच्छा कोड जनरेट करने में मुश्किल होती है. सॉफ़्टवेयर इंजीनियर इस समस्या को हल करने के लिए, लार्ज लैंग्वेज मॉडल को एक ही समस्या के कई (k) समाधान जनरेट करने के लिए प्रॉम्प्ट करते हैं. इसके बाद, सॉफ़्टवेयर इंजीनियर हर समाधान की यूनिट टेस्ट करते हैं. k पर पास होने की कैलकुलेशन, यूनिट टेस्ट के नतीजे पर निर्भर करती है:
- अगर उन समाधानों में से एक या उससे ज़्यादा समाधान यूनिट टेस्ट पास कर लेते हैं, तो एलएलएम, कोड जनरेट करने की उस चुनौती को पास कर लेता है.
- अगर कोई भी समाधान यूनिट टेस्ट पास नहीं करता है, तो एलएलएम, कोड जनरेट करने की चुनौती में फ़ेल हो जाता है.
k पर पास होने का फ़ॉर्मूला यहां दिया गया है:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
आम तौर पर, k की वैल्यू जितनी ज़्यादा होगी, पास ऐट k स्कोर उतना ही ज़्यादा होगा. हालांकि, k की वैल्यू जितनी ज़्यादा होगी, बड़े लैंग्वेज मॉडल और यूनिट टेस्टिंग के लिए उतने ही ज़्यादा संसाधनों की ज़रूरत होगी.
प्रदर्शन
इस शब्द के कई मतलब हैं:
- सॉफ़्टवेयर इंजीनियरिंग में इसका सामान्य मतलब. जैसे: यह सॉफ़्टवेयर कितनी तेज़ी से (या बेहतर तरीके से) काम करता है?
- मशीन लर्निंग में इसका मतलब. यहां परफ़ॉर्मेंस से इस सवाल का जवाब मिलता है: यह मॉडल कितना सही है? इसका मतलब है कि मॉडल के अनुमान कितने सटीक हैं?
पर्म्यूटेशन वैरिएबल के महत्व
यह वैरिएबल के महत्व का एक टाइप है. यह किसी मॉडल की अनुमान लगाने से जुड़ी गड़बड़ी में हुई बढ़ोतरी का आकलन करता है. ऐसा, फ़ीचर की वैल्यू को क्रम बदलने के बाद किया जाता है. परम्यूटेशन वैरिएबल इंपोर्टेंस, मॉडल से जुड़ी मेट्रिक नहीं है.
परप्लेक्सिटी
यह इस बात का आकलन करता है कि मॉडल अपने टास्क को कितनी अच्छी तरह से पूरा कर रहा है. उदाहरण के लिए, मान लें कि आपको किसी शब्द के पहले कुछ अक्षरों को पढ़ना है. यह शब्द, कोई उपयोगकर्ता फ़ोन के कीबोर्ड पर टाइप कर रहा है. इसके बाद, आपको उस शब्द को पूरा करने के लिए संभावित शब्दों की सूची दिखानी है. इस टास्क के लिए परप्लेक्सिटी, P, का मतलब है कि आपको अनुमानित तौर पर इतने शब्द बताने होंगे, ताकि आपकी सूची में वह शब्द शामिल हो सके जिसे उपयोगकर्ता टाइप करने की कोशिश कर रहा है.
परप्लेक्सिटी, क्रॉस-एंट्रॉपी से इस तरह जुड़ी होती है:
पॉज़िटिव क्लास
वह क्लास जिसके लिए आपको टेस्ट करना है.
उदाहरण के लिए, कैंसर के मॉडल में पॉज़िटिव क्लास "ट्यूमर" हो सकती है. ईमेल क्लासिफ़िकेशन मॉडल में पॉज़िटिव क्लास "स्पैम" हो सकती है.
नेगेटिव क्लास से तुलना करें.
PR AUC (PR कर्व के नीचे का हिस्सा)
इंटरपोलेट किए गए सटीकता-वापसी वक्र के नीचे का क्षेत्र. इसे वर्गीकरण थ्रेशोल्ड की अलग-अलग वैल्यू के लिए, (वापसी, सटीकता) पॉइंट को प्लॉट करके हासिल किया जाता है.
प्रीसिज़न
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब मॉडल ने पॉज़िटिव क्लास का अनुमान लगाया, तो कितने प्रतिशत अनुमान सही थे?
यहां फ़ॉर्मूला दिया गया है:
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का गलत अनुमान लगाया है.
उदाहरण के लिए, मान लें कि किसी मॉडल ने 200 पॉज़िटिव अनुमान लगाए. इन 200 पॉज़िटिव अनुमानों में से:
- इनमें से 150 सही पॉज़िटिव थे.
- इनमें से 50 फ़ॉल्स पॉज़िटिव थे.
इस मामले में:
इसकी तुलना सटीकता और रीकॉल से करें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में क्लासिफ़िकेशन: सटीकता, रीकॉल, प्रेसिज़न, और इनसे जुड़ी मेट्रिक देखें.
के पर सटीक (precision@k)
यह मेट्रिक, रैंक की गई (क्रम से लगाई गई) आइटम की सूची का आकलन करने के लिए होती है. k पर सटीक होने का मतलब है कि सूची के पहले k आइटम में से कितने आइटम "काम के" हैं. यानी:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k की वैल्यू, दिखाई गई सूची की लंबाई से कम या इसके बराबर होनी चाहिए. ध्यान दें कि जवाब में मिली सूची की लंबाई, कैलकुलेशन का हिस्सा नहीं होती.
कोई आइटम कितना काम का है, यह अक्सर अलग-अलग लोगों के हिसाब से अलग-अलग होता है. यहां तक कि क्वालिटी का आकलन करने वाले विशेषज्ञ भी इस बात पर सहमत नहीं होते कि कौनसे आइटम काम के हैं.
इसके साथ तुलना करें:
प्रीसिज़न-रिकॉल कर्व
यह अलग-अलग क्लासिफ़िकेशन थ्रेशोल्ड पर, सटीकता बनाम रिकॉल का कर्व होता है.
पूर्वानुमान में होने वाला पक्षपात
यह वैल्यू बताती है कि डेटासेट में, अनुमानों का औसत, लेबल के औसत से कितना अलग है.
इसे मशीन लर्निंग मॉडल में पक्षपात की अवधि या नैतिकता और निष्पक्षता में पक्षपात से भ्रमित नहीं होना चाहिए.
अनुमानित समानता
यह निष्पक्षता मेट्रिक है. इससे यह पता चलता है कि दिए गए क्लासिफ़िकेशन मॉडल के लिए, विचाराधीन सबग्रुप के लिए सटीकता की दरें बराबर हैं या नहीं.
उदाहरण के लिए, अगर कॉलेज में दाखिले का अनुमान लगाने वाले मॉडल का सटीक अनुमान लगाने का रेट, लिलिपुटियन और ब्रॉबडिंगनैगियन के लिए एक जैसा है, तो यह राष्ट्रीयता के लिए प्रेडिक्टिव पैरिटी की शर्त पूरी करेगा.
कभी-कभी, अनुमानित किराये की समानता को अनुमानित किराये की समानता भी कहा जाता है.
अनुमान लगाने की क्षमता के बारे में ज़्यादा जानकारी के लिए, "निष्पक्षता की परिभाषाएं समझाई गई हैं" (सेक्शन 3.2.1) देखें.
किराये की समानता के लिए अनुमानित दर
अनुमानित समानता का दूसरा नाम.
प्रोबैबिलिटी डेंसिटी फ़ंक्शन
यह फ़ंक्शन, ठीक किसी वैल्यू वाले डेटा सैंपल की फ़्रीक्वेंसी का पता लगाता है. जब किसी डेटासेट की वैल्यू लगातार फ़्लोटिंग-पॉइंट नंबर होती हैं, तो एग्ज़ैक्ट मैच बहुत कम होते हैं. हालांकि, वैल्यू x से वैल्यू y तक प्रोबैबिलिटी डेंसिटी फ़ंक्शन को इंटिग्रेट करने पर, x और y के बीच डेटा सैंपल की अनुमानित फ़्रीक्वेंसी मिलती है.
उदाहरण के लिए, मान लें कि किसी नॉर्मल डिस्ट्रिब्यूशन का औसत 200 और स्टैंडर्ड डेविएशन 30 है. 211.4 से 218.7 की सीमा में आने वाले डेटा सैंपल की अनुमानित फ़्रीक्वेंसी का पता लगाने के लिए, सामान्य डिस्ट्रिब्यूशन के लिए प्रायिकता घनत्व फ़ंक्शन को 211.4 से 218.7 तक इंटिग्रेट किया जा सकता है.
R
रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट (ReCoRD)
यह एक डेटासेट है. इससे यह आकलन किया जाता है कि एलएलएम, सामान्य समझ के आधार पर तर्क करने की क्षमता रखता है या नहीं. डेटासेट में मौजूद हर उदाहरण में तीन कॉम्पोनेंट होते हैं:
- किसी समाचार लेख से एक या दो पैराग्राफ़
- ऐसी क्वेरी जिसमें पैसेज में साफ़ तौर पर या किसी दूसरे तरीके से बताई गई किसी एंटिटी को मास्क किया गया हो.
- जवाब (मास्क में मौजूद इकाई का नाम)
उदाहरणों की पूरी सूची के लिए, ReCoRD देखें.
ReCoRD, SuperGLUE का एक हिस्सा है.
RealToxicityPrompts
ऐसा डेटासेट जिसमें वाक्यों की शुरुआत के ऐसे सेट शामिल हैं जिनमें आपत्तिजनक कॉन्टेंट हो सकता है. इस डेटासेट का इस्तेमाल करके, यह आकलन करें कि एलएलएम, वाक्य को पूरा करने के लिए आपत्तिजनक कॉन्टेंट से बचा हुआ टेक्स्ट जनरेट कर सकता है या नहीं. आम तौर पर, इस टास्क में एलएलएम ने कैसा परफ़ॉर्म किया, यह पता लगाने के लिए Perspective API का इस्तेमाल किया जाता है.
ज़्यादा जानकारी के लिए, RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models देखें.
रीकॉल
यह वर्गीकरण मॉडल के लिए एक मेट्रिक है. इससे इस सवाल का जवाब मिलता है:
जब ग्राउंड ट्रुथ, पॉज़िटिव क्लास थी, तब मॉडल ने कितने प्रतिशत अनुमानों को पॉज़िटिव क्लास के तौर पर सही तरीके से पहचाना?
यहां फ़ॉर्मूला दिया गया है:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
कहां:
- ट्रू पॉज़िटिव का मतलब है कि मॉडल ने पॉज़िटिव क्लास का सही अनुमान लगाया है.
- फ़ॉल्स नेगेटिव का मतलब है कि मॉडल ने गलती से नेगेटिव क्लास का अनुमान लगाया है.
उदाहरण के लिए, मान लें कि आपके मॉडल ने उन उदाहरणों के लिए 200 अनुमान लगाए जिनके लिए ग्राउंड ट्रुथ पॉज़िटिव क्लास था. इन 200 अनुमानों में से:
- इनमें से 180 ट्रू पॉज़िटिव थे.
- इनमें से 20 फ़ॉल्स नेगेटिव थे.
इस मामले में:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
ज़्यादा जानकारी के लिए, क्लासिफ़िकेशन: सटीकता, रिकॉल, सटीक और इससे जुड़ी मेट्रिक देखें.
k पर रीकॉल (recall@k)
यह मेट्रिक, उन सिस्टम का आकलन करने के लिए इस्तेमाल की जाती है जो आइटम की रैंक की गई (क्रम से लगाई गई) सूची दिखाते हैं. k पर रीकॉल से पता चलता है कि जवाब में मिले कुल काम के आइटम में से, सूची में मौजूद पहले k आइटम में कितने काम के आइटम हैं.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k पर सटीक जानकारी के साथ कंट्रास्ट करें.
टेक्स्ट से जुड़ी जानकारी को समझने की सुविधा (आरटीई)
यह एक डेटासेट है. इसका इस्तेमाल, यह आकलन करने के लिए किया जाता है कि कोई एलएलएम, किसी टेक्स्ट पैसेज से किसी अनुमान को तार्किक तौर पर निकाल सकता है या नहीं. आरटीई के आकलन में दिए गए हर उदाहरण में तीन हिस्से होते हैं:
- कोई पैसेज, आम तौर पर खबरों या Wikipedia के लेखों से लिया गया
- हाइपोथीसिस
- सही जवाब, जो इनमें से कोई एक हो सकता है:
- सही है. इसका मतलब है कि हाइपोथेसिस, पैसेज से मिलता-जुलता है
- गलत. इसका मतलब है कि पैसेज से हाइपोथेसिस का पता नहीं लगाया जा सकता
उदाहरण के लिए:
- पैसेज: यूरो, यूरोपियन यूनियन की मुद्रा है.
- अनुमान: फ़्रांस में मुद्रा के तौर पर यूरो का इस्तेमाल किया जाता है.
- निहितार्थ: सही है, क्योंकि फ़्रांस, यूरोपियन यूनियन का हिस्सा है.
RTE, SuperGLUE ensemble का एक कॉम्पोनेंट है.
ReCoRD
यह रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट का संक्षिप्त नाम है.
आरओसी (रिसीवर ऑपरेटिंग कैरेक्टरिस्टिक) कर्व
यह बाइनरी क्लासिफ़िकेशन में, अलग-अलग क्लासिफ़िकेशन थ्रेशोल्ड के लिए, ट्रू पॉज़िटिव रेट बनाम फ़ॉल्स पॉज़िटिव रेट का ग्राफ़ होता है.
आरओसी कर्व का आकार, बाइनरी क्लासिफ़िकेशन मॉडल की पॉज़िटिव क्लास को नेगेटिव क्लास से अलग करने की क्षमता के बारे में बताता है. मान लें कि बाइनरी क्लासिफ़िकेशन मॉडल, सभी नेगेटिव क्लास को सभी पॉज़िटिव क्लास से अलग करता है:
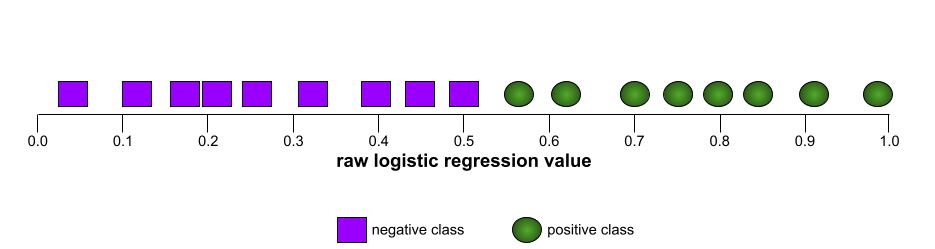
ऊपर दिए गए मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
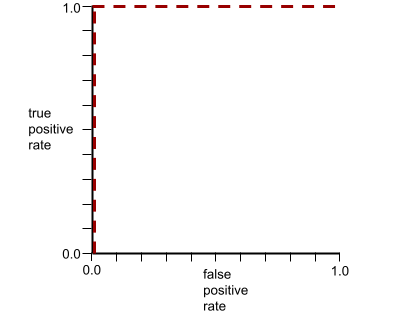
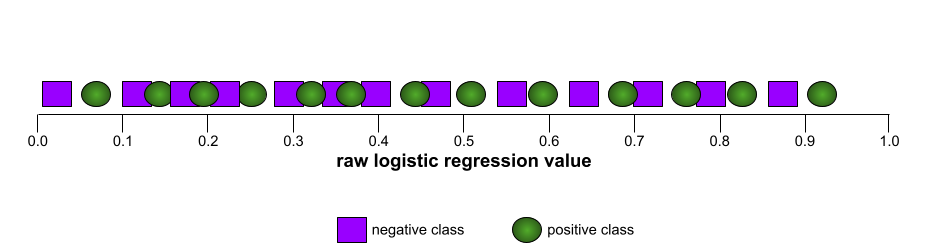
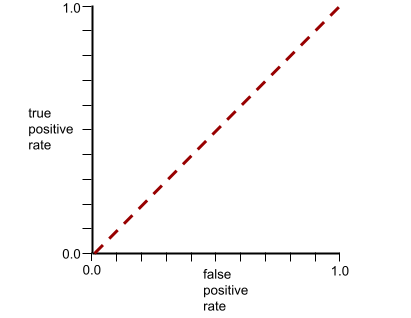
इसके उलट, यहां दिए गए ग्राफ़ में लॉजिस्टिक रिग्रेशन की रॉ वैल्यू दिखाई गई हैं. यह एक खराब मॉडल है, जो नेगेटिव क्लास को पॉज़िटिव क्लास से अलग नहीं कर सकता:
इस मॉडल के लिए आरओसी कर्व ऐसा दिखता है:
इस बीच, असल दुनिया में ज़्यादातर बाइनरी क्लासिफ़िकेशन मॉडल, पॉज़िटिव और नेगेटिव क्लास को कुछ हद तक अलग करते हैं. हालांकि, वे ऐसा पूरी तरह से नहीं कर पाते. इसलिए, सामान्य आरओसी कर्व, इन दोनों एक्सट्रीम के बीच कहीं होता है:
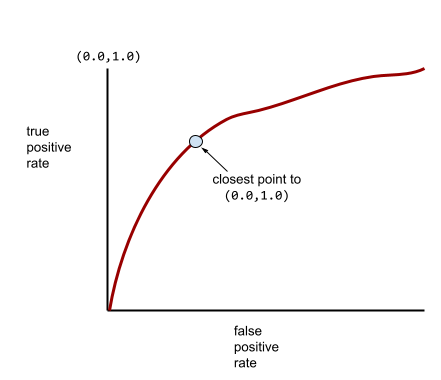
आरओसी कर्व पर (0.0,1.0) के सबसे करीब वाला पॉइंट, सैद्धांतिक तौर पर सबसे सही क्लासिफ़िकेशन थ्रेशोल्ड की पहचान करता है. हालांकि, असल दुनिया की कई अन्य समस्याएं, क्लासिफ़िकेशन के लिए सही थ्रेशोल्ड चुनने पर असर डालती हैं. उदाहरण के लिए, ऐसा हो सकता है कि गलत पहचान किए जाने से ज़्यादा नुकसान, पहचान न किए जाने से होता हो.
AUC नाम की संख्यात्मक मेट्रिक, आरओसी कर्व को एक फ़्लोटिंग-पॉइंट वैल्यू में बदल देती है.
रूट मीन स्क्वेयर्ड एरर (आरएमएसई)
यह मीन स्क्वेयर्ड एरर का स्क्वेयर रूट होता है.
ROUGE (रीकॉल-ओरिएंटेड अंडरस्टडी फ़ॉर गिस्टिंग इवैल्यूएशन)
यह मेट्रिक का एक ग्रुप है. इससे, जवाब की खास जानकारी अपने-आप जनरेट होने और मशीन ट्रांसलेशन मॉडल का आकलन किया जाता है. ROUGE मेट्रिक से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना मिलता-जुलता है. ROUGE फ़ैमिली का हर सदस्य, ओवरलैप को अलग-अलग तरीके से मेज़र करता है. ROUGE स्कोर ज़्यादा होने का मतलब है कि रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट के बीच समानता ज़्यादा है. वहीं, ROUGE स्कोर कम होने का मतलब है कि दोनों के बीच समानता कम है.
ROUGE फ़ैमिली का हर सदस्य आम तौर पर ये मेट्रिक जनरेट करता है:
- स्पष्टता
- रीकॉल
- F1
ज़्यादा जानकारी और उदाहरणों के लिए, इन्हें देखें:
ROUGE-L
यह ROUGE फ़ैमिली का सदस्य है. यह रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में सबसे लंबे कॉमन सबसीक्वेंस की लंबाई पर फ़ोकस करता है. यहां दिए गए फ़ॉर्मूले, ROUGE-L के लिए रीकॉल और सटीक होने का हिसाब लगाते हैं:
इसके बाद, ROUGE-L रीकॉल और ROUGE-L प्रेसिज़न को एक ही मेट्रिक में रोल अप करने के लिए, F1 का इस्तेमाल किया जा सकता है:
ROUGE-L, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में मौजूद नई लाइनों को अनदेखा करता है. इसलिए, सबसे लंबा कॉमन सबसीक्वेंस एक से ज़्यादा वाक्यों में हो सकता है. जब रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में कई वाक्य शामिल होते हैं, तो आम तौर पर ROUGE-Lsum मेट्रिक बेहतर होती है. यह ROUGE-L का एक वैरिएंट है. ROUGE-Lsum, किसी पैसेज के हर वाक्य के लिए सबसे लंबे कॉमन सबसीक्वेंस का पता लगाता है. इसके बाद, उन सबसे लंबे कॉमन सबसीक्वेंस का औसत कैलकुलेट करता है.
ROUGE-N
यह ROUGE फ़ैमिली की मेट्रिक का एक सेट है. यह रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, एक तय साइज़ के शेयर किए गए N-ग्राम की तुलना करता है. उदाहरण के लिए:
- ROUGE-1, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में शेयर किए गए टोकन की संख्या को मेज़र करता है.
- ROUGE-2, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, शेयर किए गए बिगराम (2-ग्राम) की संख्या को मेज़र करता है.
- ROUGE-3, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में मौजूद, एक जैसे ट्रायग्राम (3-ग्राम) की संख्या को मेज़र करता है.
ROUGE-N फ़ैमिली के किसी भी सदस्य के लिए, ROUGE-N रीकॉल और ROUGE-N प्रेसिज़न का हिसाब लगाने के लिए, यहां दिए गए फ़ॉर्मूले इस्तेमाल किए जा सकते हैं:
इसके बाद, ROUGE-N रिकॉल और ROUGE-N प्रेसिज़न को एक ही मेट्रिक में रोल अप करने के लिए, F1 का इस्तेमाल किया जा सकता है:
ROUGE-S
यह ROUGE-N का एक ऐसा फ़ॉर्मूला है जो skip-gram मैचिंग को चालू करता है. इसका मतलब है कि ROUGE-N सिर्फ़ उन N-ग्राम की गिनती करता है जो पूरी तरह मेल खाते हैं. हालांकि, ROUGE-S एक या उससे ज़्यादा शब्दों से अलग किए गए N-ग्राम की भी गिनती करता है. उदाहरण के लिए, आप नीचे दिया गया तरीका अपना सकते हैं:
- रेफ़रंस टेक्स्ट: सफ़ेद बादल
- जनरेट किया गया टेक्स्ट: सफ़ेद रंग के बादल
ROUGE-N का हिसाब लगाते समय, 2-ग्राम, सफ़ेद बादल, सफ़ेद बादल से मेल नहीं खाता. हालांकि, ROUGE-S का हिसाब लगाते समय, सफ़ेद बादल, सफ़ेद बादल से मेल खाते हैं.
R-squared
यह रिग्रेशन मेट्रिक है. इससे पता चलता है कि किसी लेबल में कितना बदलाव, किसी एक सुविधा या सुविधाओं के सेट की वजह से हुआ है. R-स्क्वेयर्ड की वैल्यू 0 से 1 के बीच होती है. इसे इस तरह समझा जा सकता है:
- R-स्क्वेयर्ड की वैल्यू 0 होने का मतलब है कि लेबल में कोई भी बदलाव, फ़ीचर सेट की वजह से नहीं हुआ है.
- R-स्क्वेयर्ड का मान 1 होने का मतलब है कि लेबल के सभी वैरिएशन, फ़ीचर सेट की वजह से हैं.
- R-स्क्वेयर्ड की वैल्यू 0 से 1 के बीच होने का मतलब है कि किसी खास सुविधा या सुविधाओं के सेट से, लेबल के वैरिएशन का अनुमान लगाया जा सकता है. उदाहरण के लिए, R-स्क्वेयर्ड की वैल्यू 0.10 का मतलब है कि लेबल में 10% वैरिएंस, फ़ीचर सेट की वजह से है. R-स्क्वेयर्ड की वैल्यू 0.20 का मतलब है कि 20% वैरिएंस, फ़ीचर सेट की वजह से है. इसी तरह, अन्य वैल्यू का मतलब भी निकाला जा सकता है.
आर-स्क्वेयर्ड, मॉडल की अनुमानित वैल्यू और ग्राउंड ट्रुथ के बीच पियर्सन कोरिलेशन कोएफ़िशिएंट का स्क्वेयर होता है.
RTE
टेक्स्ट से जुड़ी जानकारी को समझना के लिए संक्षिप्त नाम.
S
स्कोरिंग
सुझाव देने वाले सिस्टम का वह हिस्सा जो कैंडिडेट जनरेशन फ़ेज़ में तैयार किए गए हर आइटम के लिए वैल्यू या रैंकिंग देता है.
मिलते-जुलते डिज़ाइन का मेज़रमेंट
क्लस्टरिंग एल्गोरिदम में, इस मेट्रिक का इस्तेमाल यह तय करने के लिए किया जाता है कि कोई दो उदाहरण कितने मिलते-जुलते हैं.
कम जानकारी होना
किसी वेक्टर या मैट्रिक्स में शून्य (या शून्य) पर सेट किए गए एलिमेंट की संख्या को उस वेक्टर या मैट्रिक्स में मौजूद कुल एंट्री की संख्या से भाग दिया जाता है. उदाहरण के लिए, 100 एलिमेंट वाली एक ऐसी मैट्रिक्स पर विचार करें जिसमें 98 सेल में शून्य है. विरलता का हिसाब इस तरह लगाया जाता है:
फ़ीचर स्पार्सिटी का मतलब, फ़ीचर वेक्टर की स्पार्सिटी से है; मॉडल स्पार्सिटी का मतलब, मॉडल के वेट की स्पार्सिटी से है.
SQuAD
यह Stanford Question Answering Dataset का संक्षिप्त नाम है. इसे SQuAD: 100,000+ Questions for Machine Comprehension of Text पेपर में पेश किया गया था. इस डेटासेट में मौजूद सवाल, Wikipedia लेखों के बारे में सवाल पूछने वाले लोगों से मिले हैं. SQuAD में कुछ सवालों के जवाब दिए गए हैं, लेकिन अन्य सवालों के जवाब जान-बूझकर नहीं दिए गए हैं. इसलिए, SQuAD का इस्तेमाल करके, यह आकलन किया जा सकता है कि एलएलएम इन दोनों कामों को कर सकता है या नहीं:
- ऐसे सवालों के जवाब दें जिनके जवाब दिए जा सकते हैं.
- ऐसे सवालों की पहचान करना जिनके जवाब नहीं दिए जा सकते.
पूरी तरह मेल खाने वाले जवाब और F1, SQuAD के हिसाब से एलएलएम का आकलन करने के लिए सबसे आम मेट्रिक हैं.
स्क्वेयर्ड हिंज लॉस
हिंज लॉस का स्क्वेयर. स्क्वेयर्ड हिंज लॉस, आउटलायर को सामान्य हिंज लॉस की तुलना में ज़्यादा नुकसान पहुंचाता है.
स्क्वेयर्ड लॉस
L2 नुकसान के लिए समानार्थी शब्द.
SuperGLUE
एलएलएम की टेक्स्ट को समझने और जनरेट करने की क्षमता का आकलन करने के लिए, डेटासेट का एक ग्रुप. इस मॉडल में ये डेटासेट शामिल हैं:
- बूलियन सवाल (BoolQ)
- CommitmentBank (CB)
- भरोसेमंद विकल्पों का चुनाव (सीओपीए)
- एक से ज़्यादा वाक्यों को पढ़कर जवाब देना (मल्टीआरसी)
- रीडिंग कॉम्प्रिहेंशन विद कॉमनसेंस रीज़निंग डेटासेट (ReCoRD)
- टेक्स्ट से जुड़ी जानकारी को समझना (आरटीई)
- कॉन्टेक्स्ट के हिसाब से शब्दों का इस्तेमाल (डब्ल्यूआईसी)
- विनोग्राड स्कीमा चैलेंज (डब्ल्यूएससी)
ज़्यादा जानकारी के लिए, SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems देखें.
T
टेस्ट लॉस
यह मेट्रिक, टेस्ट सेट के हिसाब से मॉडल के लॉस को दिखाती है. मॉडल बनाते समय, आम तौर पर टेस्ट लॉस को कम करने की कोशिश की जाती है. ऐसा इसलिए है, क्योंकि कम टेस्ट लॉस, कम ट्रेनिंग लॉस या कम पुष्टि करने वाले लॉस की तुलना में ज़्यादा भरोसेमंद क्वालिटी सिग्नल होता है.
कभी-कभी, टेस्ट लॉस और ट्रेनिंग लॉस या पुष्टि करने के लॉस के बीच का बड़ा अंतर यह बताता है कि आपको रेगुलराइज़ेशन रेट को बढ़ाना होगा.
टॉप-k ऐक्युरसी
जनरेट की गई सूचियों की पहली k पोज़िशन में "टारगेट लेबल" के दिखने का प्रतिशत. ये सूचियां, आपकी दिलचस्पी के हिसाब से दिए गए सुझाव हो सकते हैं. इसके अलावा, ये softmax के हिसाब से क्रम में लगाए गए आइटम की सूची भी हो सकती हैं.
टॉप-k ऐक््यूरेसी को k पर ऐक््यूरेसी भी कहा जाता है.
बुरा बर्ताव
कॉन्टेंट कितना आपत्तिजनक, डराने-धमकाने वाला या गाली-गलौज वाला है. मशीन लर्निंग के कई मॉडल, आपत्तिजनक कॉन्टेंट की पहचान कर सकते हैं, उसका आकलन कर सकते हैं, और उसे अलग-अलग कैटगरी में बांट सकते हैं. इनमें से ज़्यादातर मॉडल, कई पैरामीटर के आधार पर बुरे बर्ताव की पहचान करते हैं. जैसे, गाली-गलौज वाली भाषा का लेवल और धमकी देने वाली भाषा का लेवल.
ट्रेनिंग लॉस
यह मेट्रिक, ट्रेनिंग के किसी खास इटरेशन के दौरान मॉडल के लॉस को दिखाती है. उदाहरण के लिए, मान लें कि लॉस फ़ंक्शन Mean Squared Error है. ऐसा हो सकता है कि 10वें इटरेशन के लिए ट्रेनिंग लॉस (मीन स्क्वेयर्ड एरर) 2.2 हो और 100वें इटरेशन के लिए ट्रेनिंग लॉस 1.9 हो.
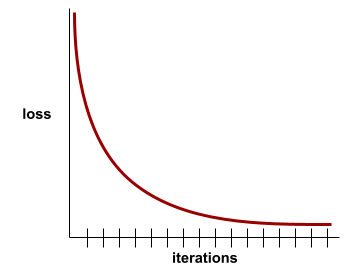
लॉस कर्व, ट्रेनिंग लॉस की तुलना में इटरेशन की संख्या को प्लॉट करता है. लॉस कर्व से, ट्रेनिंग के बारे में ये संकेत मिलते हैं:
- नीचे की ओर झुकी हुई लाइन का मतलब है कि मॉडल बेहतर हो रहा है.
- ऊपर की ओर ढलान का मतलब है कि मॉडल की परफ़ॉर्मेंस खराब हो रही है.
- स्लोप के फ़्लैट होने का मतलब है कि मॉडल कन्वर्जेंस पर पहुंच गया है.
उदाहरण के लिए, यहां दिए गए लॉस कर्व से पता चलता है कि:
- शुरुआती इटरेशन के दौरान, नीचे की ओर ढलान वाली खड़ी लाइन. इसका मतलब है कि मॉडल में तेज़ी से सुधार हो रहा है.
- ट्रेनिंग के आखिर तक, धीरे-धीरे कम होने वाला (लेकिन अब भी नीचे की ओर) स्लोप. इसका मतलब है कि मॉडल में सुधार जारी है, लेकिन शुरुआती इटरेशन की तुलना में कुछ हद तक धीमी गति से.
- ट्रेनिंग के आखिर में, परफ़ॉर्मेंस में मामूली गिरावट दिखती है. इससे पता चलता है कि मॉडल कन्वर्ज हो रहा है.
ट्रेनिंग लॉस अहम होता है. हालांकि, सामान्यीकरण के बारे में भी जानें.
मज़ेदार सवालों के जवाब देना
एलएलएम की सामान्य ज्ञान के सवालों के जवाब देने की क्षमता का आकलन करने के लिए डेटासेट. हर डेटासेट में, सामान्य ज्ञान के शौकीन लोगों ने सवाल-जवाब के जोड़े बनाए हैं. अलग-अलग डेटासेट, अलग-अलग सोर्स से लिए जाते हैं. जैसे:
- वेब पर खोज (TriviaQA)
- Wikipedia (TriviaQA_wiki)
ज़्यादा जानकारी के लिए, TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension देखें.
ट्रू नेगेटिव (टीएन)
ऐसा उदाहरण जिसमें मॉडल, नेगेटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम नहीं है और वह ईमेल मैसेज वाकई स्पैम नहीं है.
ट्रू पॉज़िटिव (टीपी)
ऐसा उदाहरण जिसमें मॉडल, पॉज़िटिव क्लास का सही अनुमान लगाता है. उदाहरण के लिए, मॉडल यह अनुमान लगाता है कि कोई ईमेल मैसेज स्पैम है और वह ईमेल मैसेज वाकई स्पैम है.
ट्रू पॉज़िटिव रेट (टीपीआर)
recall का समानार्थी शब्द. यानी:
ट्रू पॉज़िटिव रेट, आरओसी कर्व में y-ऐक्सिस होता है.
टाइपोलॉजिकल डाइवर्स क्वेश्चन आंसरिंग (TyDi QA)
एलएलएम की, सवालों के जवाब देने की क्षमता का आकलन करने के लिए एक बड़ा डेटासेट. इस डेटासेट में, कई भाषाओं में सवाल और जवाब के जोड़े शामिल हैं.
ज़्यादा जानकारी के लिए, TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages देखें.
U
दावे के सही न होने की दर (यूसीआर)
जवाब में मौजूद उन दावों का प्रतिशत जो भरोसेमंद स्रोतों से मिली जानकारी पर आधारित नहीं हैं. उदाहरण के लिए, अगर किसी एलएलएम के जवाब में 10 दावे किए गए हैं, लेकिन सिर्फ़ 1 दावा भरोसेमंद स्रोत से लिया गया है, तो यूसीआर 90% है.
ज़्यादा यूसीआर का मतलब है कि एलएलएम भ्रम पैदा करने वाली जानकारी बहुत बार दे रहा है.
साइटेशन की सटीक जानकारी और साइटेशन रीकॉल भी देखें.
V
पुष्टि करने के दौरान होने वाला नुकसान
यह एक मेट्रिक है. यह ट्रेनिंग के किसी इटरेशन के दौरान, पुष्टि करने वाले सेट पर मॉडल के लॉस को दिखाती है.
जनरलाइज़ेशन कर्व भी देखें.
वैरिएबल के महत्व
स्कोर का एक ऐसा सेट जो मॉडल के लिए हर फ़ीचर की अहमियत को दिखाता है.
उदाहरण के लिए, डिसिज़न ट्री पर विचार करें, जो घर की कीमतों का अनुमान लगाता है. मान लें कि इस फ़ैसले के ट्री में तीन सुविधाओं का इस्तेमाल किया गया है: साइज़, उम्र, और स्टाइल. अगर तीन सुविधाओं के लिए, वैरिएबल के महत्व का सेट {size=5.8, age=2.5, style=4.7} के तौर पर कैलकुलेट किया जाता है, तो साइज़, उम्र या स्टाइल की तुलना में फ़ैसले के ट्री के लिए ज़्यादा अहम होता है.
वैरिएबल की अहमियत के बारे में बताने वाली अलग-अलग मेट्रिक मौजूद हैं. इनसे एमएल विशेषज्ञों को मॉडल के अलग-अलग पहलुओं के बारे में जानकारी मिल सकती है.
W
Wasserstein loss
यह लॉस फ़ंक्शन, जनरेटिव ऐडवर्सैरियल नेटवर्क में आम तौर पर इस्तेमाल किया जाता है. यह जनरेट किए गए डेटा और असली डेटा के डिस्ट्रिब्यूशन के बीच अर्थ मूवर डिस्टेंस पर आधारित होता है.
WiC
कॉन्टेक्स्ट के हिसाब से शब्द के लिए संक्षिप्ताक्षर.
WikiLingua (wiki_lingua)
यह डेटासेट, छोटे लेखों की खास जानकारी देने की एलएलएम की क्षमता का आकलन करने के लिए बनाया गया है. WikiHow, एक ऐसा एनसाइक्लोपीडिया है जिसमें अलग-अलग कामों को करने का तरीका बताया गया है. यह दोनों लेखों और खास जानकारी के लिए, इंसानों के लिखे हुए सोर्स का इस्तेमाल करता है. डेटासेट की हर एंट्री में ये शामिल होते हैं:
- एक लेख, जिसे नंबर वाली सूची के गद्य (पैराग्राफ़) वर्शन के हर चरण को जोड़कर बनाया जाता है. इसमें हर चरण का शुरुआती वाक्य शामिल नहीं होता.
- उस लेख की खास जानकारी. इसमें नंबर वाली सूची में दिए गए हर चरण का शुरुआती वाक्य शामिल होता है.
ज़्यादा जानकारी के लिए, WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization लेख पढ़ें.
विनोग्राड स्कीमा चैलेंज (डब्ल्यूएससी)
एलएलएम की इस क्षमता का आकलन करने के लिए एक फ़ॉर्मैट (या उस फ़ॉर्मैट के मुताबिक डेटासेट): एलएलएम यह तय कर सकता है कि सर्वनाम किस संज्ञा वाक्यांश के बारे में बताता है.
विनोग्राड स्कीमा चैलेंज में मौजूद हर एंट्री में ये शामिल होते हैं:
- एक छोटा पैसेज, जिसमें टारगेट किया गया सर्वनाम शामिल हो
- टारगेट किया गया सर्वनाम
- संभावित संज्ञा वाक्यांश, जिनके बाद सही जवाब (बूलियन) दिया गया है. अगर टारगेट सर्वनाम इस उम्मीदवार के लिए इस्तेमाल किया गया है, तो जवाब 'सही है' होगा. अगर टारगेट किया गया सर्वनाम, इस उम्मीदवार के बारे में नहीं बताता है, तो जवाब False होता है.
उदाहरण के लिए:
- पैसेज: मार्क ने खुद के बारे में पीट से कई झूठ बोले, जिन्हें पीट ने अपनी किताब में शामिल किया. उसे ज़्यादा ईमानदारी दिखानी चाहिए थी.
- टारगेट किया गया सर्वनाम: वह
- कैंडिडेट के संज्ञा वाक्यांश:
- मार्क: सही है, क्योंकि टारगेट किया गया सर्वनाम मार्क के लिए इस्तेमाल किया गया है
- पीट: गलत, क्योंकि टारगेट किए गए सर्वनाम से पीटर का मतलब नहीं है
Winograd Schema Challenge, SuperGLUE का हिस्सा है.
कॉन्टेक्स्ट के हिसाब से शब्द (डब्ल्यूआईसी)
यह डेटासेट, इस बात का आकलन करने के लिए है कि एलएलएम, कॉन्टेक्स्ट का इस्तेमाल करके उन शब्दों को कितनी अच्छी तरह समझता है जिनके कई मतलब होते हैं. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- दो वाक्य, जिनमें से हर वाक्य में टारगेट किया गया शब्द मौजूद हो
- टारगेट किया गया शब्द
- सही जवाब (बूलियन), जहां:
- True का मतलब है कि टारगेट किए गए शब्द का मतलब दोनों वाक्यों में एक जैसा है
- False का मतलब है कि टारगेट किए गए शब्द का मतलब, दोनों वाक्यों में अलग-अलग है
उदाहरण के लिए:
- दो वाक्य:
- नदी के तल पर बहुत सारा कचरा है.
- सोते समय, मैं अपने बिस्तर के बगल में एक गिलास पानी रखता/रखती हूँ.
- टारगेट किया गया शब्द: बिस्तर
- सही जवाब: गलत, क्योंकि टारगेट किए गए शब्द का मतलब दोनों वाक्यों में अलग-अलग है.
ज़्यादा जानकारी के लिए, WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations देखें.
Words in Context, SuperGLUE ensemble का एक कॉम्पोनेंट है.
WSC
विनोग्राड स्कीमा चैलेंज का संक्षिप्त नाम.
X
XL-Sum (xlsum)
यह एक ऐसा डेटासेट है जिसका इस्तेमाल, टेक्स्ट को खास जानकारी में बदलने के लिए एलएलएम की परफ़ॉर्मेंस का आकलन करने के लिए किया जाता है. XL-Sum, कई भाषाओं में जवाब देता है. डेटासेट की हर एंट्री में यह जानकारी शामिल होती है:
- ब्रिटिश ब्रॉडकास्टिंग कंपनी (बीबीसी) से लिया गया एक लेख.
- लेख के बारे में खास जानकारी, जिसे लेख के लेखक ने लिखा है. ध्यान दें कि जवाब में ऐसे शब्द या वाक्यांश शामिल हो सकते हैं जो लेख में मौजूद नहीं हैं.
ज़्यादा जानकारी के लिए, XL-Sum: 44 भाषाओं में बड़े पैमाने पर टेक्स्ट का सार निकालने की सुविधा लेख पढ़ें.