หน้านี้มีคำศัพท์ในอภิธานศัพท์เกี่ยวกับเมตริก ดูคำศัพท์ทั้งหมดได้โดยคลิกที่นี่
A
ความแม่นยำ
จำนวนการคาดการณ์การจัดประเภทที่ถูกต้องหารด้วยจำนวนการคาดการณ์ทั้งหมด โดยการ
เช่น โมเดลที่คาดการณ์ถูกต้อง 40 รายการและคาดการณ์ไม่ถูกต้อง 10 รายการ จะมีความแม่นยำดังนี้
การจัดประเภทแบบไบนารีจะระบุชื่อที่เฉพาะเจาะจง สำหรับหมวดหมู่ต่างๆ ของการคาดการณ์ที่ถูกต้องและ การคาดการณ์ที่ไม่ถูกต้อง ดังนั้น สูตรความแม่นยำสำหรับการจัดประเภทแบบไบนารี จึงเป็นดังนี้
where:
- TP คือจำนวนผลบวกจริง (การคาดการณ์ที่ถูกต้อง)
- TN คือจำนวนผลลบจริง (การคาดการณ์ที่ถูกต้อง)
- FP คือจำนวนผลบวกลวง (การคาดการณ์ที่ไม่ถูกต้อง)
- FN คือจำนวนผลลบลวง (การคาดการณ์ที่ไม่ถูกต้อง)
เปรียบเทียบความแม่นยำกับความเที่ยงตรงและความอ่อนไหว
ดูข้อมูลเพิ่มเติมได้ที่การจัดประเภท: ความแม่นยำ, การเรียกคืน, ความแม่นยำ และเมตริกที่เกี่ยวข้อง ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
พื้นที่ใต้กราฟ PR
พื้นที่ใต้กราฟ ROC
AUC (พื้นที่ใต้กราฟ ROC)
ตัวเลขระหว่าง 0.0 ถึง 1.0 ซึ่งแสดงถึงความสามารถของโมเดลการจัดประเภทแบบไบนารี ในการแยกคลาสที่เป็นบวกออกจากคลาสที่เป็นลบ ยิ่ง AUC ใกล้ 1.0 มากเท่าใด ความสามารถของโมเดลในการแยก คลาสออกจากกันก็จะยิ่งดีขึ้นเท่านั้น
ตัวอย่างเช่น ภาพต่อไปนี้แสดงโมเดลการจัดประเภทที่แยกคลาสเชิงบวก (วงรีสีเขียว) ออกจากคลาสเชิงลบ (สี่เหลี่ยมผืนผ้าสีม่วง) ได้อย่างสมบูรณ์ โมเดลที่สมบูรณ์แบบอย่างไม่สมจริงนี้มี AUC เท่ากับ 1.0

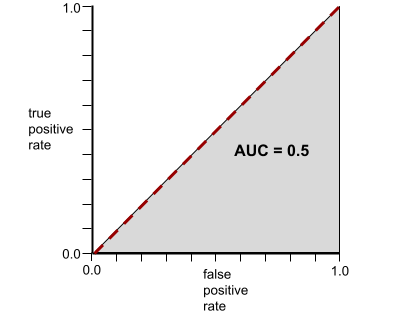
ในทางกลับกัน ภาพต่อไปนี้แสดงผลลัพธ์ของโมเดลการจัดประเภทที่สร้างผลลัพธ์แบบสุ่ม โมเดลนี้มี AUC เท่ากับ 0.5

ใช่ โมเดลก่อนหน้ามี AUC เท่ากับ 0.5 ไม่ใช่ 0.0
โมเดลส่วนใหญ่อยู่ระหว่าง 2 สุดขั้วนี้ ตัวอย่างเช่น โมเดลต่อไปนี้จะแยกผลลัพธ์เชิงบวกออกจากเชิงลบได้ในระดับหนึ่ง ดังนั้นจึงมี AUC อยู่ระหว่าง 0.5 ถึง 1.0

AUC จะไม่สนใจค่าที่คุณตั้งไว้สำหรับ เกณฑ์การจัดประเภท แต่ AUC จะพิจารณาเกณฑ์การแยกประเภทที่เป็นไปได้ทั้งหมด
คลิกไอคอนเพื่อดูข้อมูลเกี่ยวกับความสัมพันธ์ระหว่าง AUC กับเส้นโค้ง ROC
AUC แสดงถึงพื้นที่ใต้ กราฟ ROC ตัวอย่างเช่น กราฟ ROC สำหรับโมเดลที่แยกผลบวกออกจากผลลบได้อย่างสมบูรณ์จะมีลักษณะดังนี้
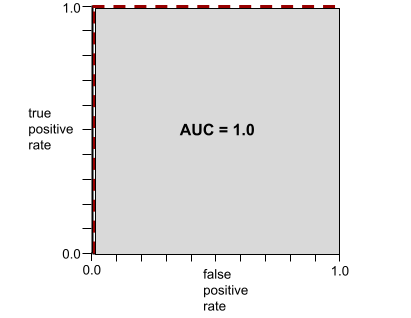
AUC คือพื้นที่ของบริเวณสีเทาในภาพประกอบก่อนหน้า ในกรณีที่ผิดปกติเช่นนี้ พื้นที่ก็คือความยาวของพื้นที่สีเทา (1.0) คูณด้วยความกว้างของพื้นที่สีเทา (1.0) ดังนั้น ผลคูณของ 1.0 และ 1.0 จึงให้ค่า AUC เท่ากับ 1.0 ซึ่งเป็นคะแนน AUC ที่สูงที่สุด ที่เป็นไปได้
ในทางกลับกัน เส้นโค้ง ROC สำหรับโมเดลการแยกประเภทที่ไม่สามารถ แยกคลาสได้เลยจะเป็นดังนี้ พื้นที่ของบริเวณสีเทานี้คือ 0.5
กราฟ ROC โดยทั่วไปจะมีลักษณะดังต่อไปนี้
การคำนวณพื้นที่ใต้กราฟนี้ด้วยตนเองเป็นเรื่องที่ยากมาก โปรแกรมจึงมักคำนวณค่า AUC ส่วนใหญ่
ดูข้อมูลเพิ่มเติมได้ที่การแยกประเภท: ROC และ AUC ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ความแม่นยำเฉลี่ยที่ k
เมตริกสำหรับสรุปประสิทธิภาพของโมเดลในพรอมต์เดียวที่สร้างผลลัพธ์ที่จัดอันดับ เช่น รายการที่เรียงลำดับเลขของคำแนะนำหนังสือ ความแม่นยำเฉลี่ยที่ k คือค่าเฉลี่ยของค่า ความแม่นยำที่ k สำหรับผลลัพธ์ที่เกี่ยวข้องแต่ละรายการ ดังนั้น สูตรสำหรับความแม่นยำเฉลี่ยที่ k คือ
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- \(n\) คือจำนวนรายการที่เกี่ยวข้องในรายการ
เปรียบเทียบกับฟีเจอร์ความทรงจำที่ k
B
พื้นฐาน
โมเดลที่ใช้เป็นจุดอ้างอิงในการเปรียบเทียบประสิทธิภาพของโมเดลอื่น (โดยปกติจะเป็นโมเดลที่ซับซ้อนกว่า) ตัวอย่างเช่น โมเดลการถดถอยแบบโลจิสติกอาจเป็นโมเดลเชิงลึกที่ดี
สำหรับปัญหาหนึ่งๆ เกณฑ์พื้นฐานจะช่วยให้นักพัฒนาโมเดลระบุปริมาณ ประสิทธิภาพขั้นต่ำที่คาดหวังซึ่งโมเดลใหม่ต้องทำให้ได้เพื่อให้โมเดลใหม่ มีประโยชน์
คำถามบูลีน (BoolQ)
ชุดข้อมูลสำหรับประเมินความสามารถของ LLM ในการตอบคำถามแบบใช่หรือไม่ ความท้าทายแต่ละอย่างในชุดข้อมูลมีองค์ประกอบ 3 อย่าง ดังนี้
- การค้นหา
- ข้อความที่สื่อถึงคำตอบของคำค้นหา
- คำตอบที่ถูกต้อง ซึ่งอาจเป็นใช่หรือไม่ใช่
เช่น
- คำค้นหา: รัฐมิชิแกนมีโรงไฟฟ้านิวเคลียร์ไหม
- ข้อความ: ...โรงไฟฟ้านิวเคลียร์ 3 แห่งจ่ายไฟฟ้าให้มิชิแกน ประมาณ 30%
- คำตอบที่ถูกต้อง: ใช่
นักวิจัยรวบรวมคำถามจากคำค้นหาใน Google Search ที่รวบรวมและลบข้อมูลระบุตัวบุคคลแล้ว จากนั้นใช้หน้า Wikipedia เพื่ออ้างอิงข้อมูล
ดูข้อมูลเพิ่มเติมได้ที่ BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
BoolQ เป็นองค์ประกอบของกลุ่ม SuperGLUE
BoolQ
ตัวย่อของคำถามบูลีน
C
CB
ตัวย่อของ CommitmentBank
คะแนน F ของ N-gram อักขระ (ChrF)
เมตริกสำหรับประเมินโมเดลการแปลด้วยคอมพิวเตอร์ คะแนน F ของ N-gram อักขระจะกำหนดระดับที่ N-gram ในข้อความอ้างอิงซ้อนทับกับ N-gram ในข้อความที่สร้างขึ้นของโมเดล ML
คะแนน F ของ N-gram อักขระคล้ายกับเมตริกในกลุ่ม ROUGE และ BLEU ยกเว้นว่า
- คะแนน F ของ N-gram อักขระจะทำงานกับ N-gram อักขระ
- ROUGE และ BLEU ทำงานกับ N-gram ของคำหรือโทเค็น
ทางเลือกของทางเลือกที่เป็นไปได้ (COPA)
ชุดข้อมูลสำหรับประเมินว่า LLM สามารถระบุคำตอบที่ดีกว่าใน 2 คำตอบที่เป็น ทางเลือกสำหรับสมมติฐานได้ดีเพียงใด ความท้าทายแต่ละอย่างในชุดข้อมูล ประกอบด้วย 3 องค์ประกอบ ดังนี้
- สมมติฐาน ซึ่งโดยปกติจะเป็นคำกล่าวตามด้วยคำถาม
- คำตอบที่เป็นไปได้ 2 คำตอบสำหรับคำถามที่ระบุไว้ในสมมติฐาน โดยคำตอบหนึ่ง ถูกต้องและอีกคำตอบไม่ถูกต้อง
- คำตอบที่ถูกต้อง
เช่น
- สมมติฐาน: ชายคนนี้ทำนิ้วเท้าหัก สาเหตุของปัญหานี้คืออะไร
- คำตอบที่เป็นไปได้
- ถุงเท้าของเขามีรู
- เขาทำค้อนหล่นใส่เท้า
- คำตอบที่ถูกต้อง: 2
COPA เป็นส่วนประกอบของกลุ่ม SuperGLUE
CommitmentBank (CB)
ชุดข้อมูลสําหรับประเมินความเชี่ยวชาญของ LLM ในการพิจารณาว่าผู้เขียนข้อความเชื่อในอนุประโยคเป้าหมายภายในข้อความนั้นหรือไม่ แต่ละรายการในชุดข้อมูลประกอบด้วยข้อมูลต่อไปนี้
- ข้อความ
- อนุประโยคเป้าหมายภายในข้อความนั้น
- ค่าบูลีนที่ระบุว่าผู้เขียนข้อความเชื่อว่ามาตราเป้าหมาย
เช่น
- ข้อความ: ฟังอาร์เทมิสหัวเราะช่างสนุกเสียนี่กระไร เธอเป็นเด็กที่จริงจังมาก ฉันไม่รู้ว่าเธอมีอารมณ์ขัน
- อนุประโยคเป้าหมาย: เธอมีอารมณ์ขัน
- บูลีน: จริง ซึ่งหมายความว่าผู้เขียนเชื่อว่าข้อความเป้าหมาย
CommitmentBank เป็นส่วนประกอบของกลุ่ม SuperGLUE
COPA
ตัวย่อของ Choice of Plausible Alternatives
ต้นทุน
คำพ้องความหมายของการสูญเสีย
ความเป็นธรรมแบบข้อเท็จจริง
เมตริกความเป็นธรรมที่ตรวจสอบว่าโมเดลการจัดประเภทให้ผลลัพธ์เดียวกันสำหรับบุคคลหนึ่งกับอีกบุคคลหนึ่งซึ่งเหมือนกับบุคคลแรกหรือไม่ ยกเว้นในส่วนของแอตทริบิวต์ที่ละเอียดอ่อนอย่างน้อย 1 รายการ การประเมินโมเดลการจัดประเภทเพื่อความเป็นธรรมแบบข้อเท็จจริง เป็นวิธีหนึ่งในการระบุแหล่งที่มาของความเอนเอียงที่อาจเกิดขึ้นในโมเดล
โปรดดูข้อมูลเพิ่มเติมในแหล่งข้อมูลต่อไปนี้
- ความเป็นธรรม: ความเป็นธรรมแบบข้อเท็จจริงที่ขัดแย้ง ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
- เมื่อโลกมาบรรจบกัน: การผสานรวมสมมติฐานแบบ Counterfactual ที่แตกต่างกัน ในความเท่าเทียม
ครอสเอนโทรปี
การสรุปการสูญเสียบันทึกเป็น ปัญหาการจัดประเภทแบบหลายคลาส Cross-entropy วัดความแตกต่างระหว่างการแจกแจงความน่าจะเป็น 2 แบบ ดูเพิ่มเติม perplexity
ฟังก์ชันการกระจายสะสม (CDF)
ฟังก์ชันที่กำหนดความถี่ของตัวอย่างที่น้อยกว่าหรือเท่ากับค่าเป้าหมาย เช่น พิจารณาการแจกแจงปกติของค่าต่อเนื่อง CDF บอกคุณว่าตัวอย่างประมาณ 50% ควรน้อยกว่าหรือเท่ากับค่าเฉลี่ย และตัวอย่างประมาณ 84% ควรน้อยกว่าหรือเท่ากับค่าเบี่ยงเบนมาตรฐาน 1 ค่าเหนือค่าเฉลี่ย
D
ความเท่าเทียมทางประชากร
เมตริกความเป็นธรรมที่ตรงตามเงื่อนไขในกรณีที่ผลลัพธ์ของการจัดประเภทของโมเดลไม่ได้ขึ้นอยู่กับแอตทริบิวต์ที่มีความละเอียดอ่อนที่กำหนด
ตัวอย่างเช่น หากทั้งชาวลิลิพุตและชาวโบรบดิงแนกสมัครเข้าเรียนที่ มหาวิทยาลัยกลับบ์ดรับดริบ ความเท่าเทียมทางประชากรจะเกิดขึ้นหากเปอร์เซ็นต์ ของชาวลิลิพุตที่ได้รับการตอบรับเท่ากับเปอร์เซ็นต์ของชาวโบรบดิงแนก ที่ได้รับการตอบรับ ไม่ว่ากลุ่มใดกลุ่มหนึ่งจะมีคุณสมบัติมากกว่าอีกกลุ่มโดยเฉลี่ยหรือไม่ก็ตาม
แตกต่างจากอัตราต่อรองที่เท่ากันและความเท่าเทียมกันของโอกาส ซึ่งอนุญาตให้ผลการจัดประเภทโดยรวมขึ้นอยู่กับแอตทริบิวต์ที่ละเอียดอ่อน แต่ไม่อนุญาตให้ผลการจัดประเภทสำหรับป้ายกำกับความจริงพื้นฐานที่ระบุบางอย่างขึ้นอยู่กับแอตทริบิวต์ที่ละเอียดอ่อน ดูภาพ "การต่อสู้กับการเลือกปฏิบัติด้วยแมชชีนเลิร์นนิงที่ชาญฉลาดยิ่งขึ้น" เพื่อสำรวจการแลกเปลี่ยนเมื่อเพิ่มประสิทธิภาพเพื่อความเท่าเทียมกันทางประชากร
ดูข้อมูลเพิ่มเติมได้ที่ความเป็นธรรม: ความเท่าเทียมกันทางประชากร ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
E
ระยะทางของเครื่องเคลื่อนย้ายดิน (EMD)
การวัดความคล้ายคลึงกันของการกระจาย 2 รายการ ยิ่งระยะทางของ Earth Mover ต่ำเท่าใด การกระจายก็จะยิ่งคล้ายกันมากขึ้นเท่านั้น
ระยะทางแก้ไข
การวัดว่าสตริงข้อความ 2 รายการมีความคล้ายกันมากน้อยเพียงใด ในแมชชีนเลิร์นนิง ระยะทางในการแก้ไขมีประโยชน์ด้วยเหตุผลต่อไปนี้
- การคำนวณระยะทางในการแก้ไขทำได้ง่าย
- ระยะทางในการแก้ไขสามารถเปรียบเทียบสตริง 2 รายการที่ทราบว่าคล้ายกัน
- ระยะทางในการแก้ไขจะกำหนดระดับที่สตริงต่างๆ คล้ายกับสตริงที่กำหนด
มีคำจำกัดความหลายอย่างสำหรับระยะทางในการแก้ไข โดยแต่ละคำจำกัดความจะใช้การดำเนินการกับสตริงที่แตกต่างกัน ดูตัวอย่างได้ที่ระยะทางเลเวนชไตน์
ฟังก์ชันการกระจายสะสมเชิงประจักษ์ (eCDF หรือ EDF)
ฟังก์ชันการกระจายสะสม โดยอิงตามการวัดเชิงประจักษ์จากชุดข้อมูลจริง ค่าของฟังก์ชันที่จุดใดก็ตามตามแกน x คือเศษส่วนของการสังเกตในชุดข้อมูลที่น้อยกว่าหรือเท่ากับค่าที่ระบุ
เอนโทรปี
ใน ทฤษฎีสารสนเทศ คำอธิบายว่าการกระจายความน่าจะเป็นคาดเดาไม่ได้เพียงใด หรืออาจกล่าวได้ว่าเอนโทรปีคือปริมาณข้อมูลที่ตัวอย่างแต่ละรายการมี การกระจายจะมี เอนโทรปีสูงสุดที่เป็นไปได้เมื่อค่าทั้งหมดของตัวแปรสุ่มมี โอกาสเท่ากัน
เอนโทรปีของชุดที่มีค่าที่เป็นไปได้ 2 ค่าคือ "0" และ "1" (เช่น ป้ายกำกับในปัญหาการแยกประเภทแบบไบนารี) มีสูตรดังนี้
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
where:
- H คือเอนโทรปี
- p คือเศษส่วนของตัวอย่าง "1"
- q คือเศษส่วนของตัวอย่าง "0" โปรดทราบว่า q = (1 - p)
- log โดยทั่วไปคือ log2 ในกรณีนี้ หน่วยเอนโทรปี คือบิต
ตัวอย่างเช่น สมมติว่า
- ตัวอย่าง 100 รายการมีค่า "1"
- ตัวอย่าง 300 รายการมีค่า "0"
ดังนั้นค่าเอนโทรปีจึงเป็นดังนี้
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 บิตต่อตัวอย่าง
ชุดข้อมูลที่สมดุลอย่างสมบูรณ์ (เช่น "0" 200 รายการและ "1" 200 รายการ) จะมีเอนโทรปี 1.0 บิตต่อตัวอย่าง เมื่อชุดข้อมูลไม่สมดุลมากขึ้น เอนโทรปีของชุดข้อมูลจะเข้าใกล้ 0.0
ในแผนผังการตัดสินใจ เอนโทรปีช่วยสร้างการได้ข้อมูลเพื่อช่วยให้ตัวแยกเลือกเงื่อนไข ในระหว่างการเติบโตของแผนผังการตัดสินใจแบบการจัดประเภท
เปรียบเทียบเอนโทรปีกับ
- ความไม่บริสุทธิ์ของ Gini
- ฟังก์ชันการสูญเสียเอนโทรปีครอส
โดยมักเรียกเอนโทรปีว่าเอนโทรปีของแชนนอน
ดูข้อมูลเพิ่มเติมได้ที่ตัวแยกที่แน่นอนสำหรับการแยกประเภทแบบไบนารีที่มีฟีเจอร์เชิงตัวเลข ในหลักสูตร Decision Forests
ความเท่าเทียมกันในโอกาส
เมตริกความเป็นธรรมเพื่อประเมินว่าโมเดล คาดการณ์ผลลัพธ์ที่ต้องการได้ดีเท่าๆ กันสำหรับค่าทั้งหมดของแอตทริบิวต์ที่ละเอียดอ่อนหรือไม่ กล่าวอีกนัยหนึ่งคือ หากคลาสที่เป็นบวกคือผลลัพธ์ที่ต้องการสำหรับโมเดล เป้าหมายคือการทำให้อัตราผลบวกจริงเหมือนกันทั้งหมดสำหรับทุกกลุ่ม
ความเท่าเทียมกันของโอกาสเกี่ยวข้องกับโอกาสที่เท่าเทียมกัน ซึ่งกำหนดให้ทั้งอัตราผลบวกจริงและ อัตราผลบวกลวงต้องเหมือนกันทั้งหมดสำหรับทุกกลุ่ม
สมมติว่ามหาวิทยาลัยกลับดับดริบรับทั้งชาวลิลิปุตและชาวบร็อบดิงแนก เข้าโปรแกรมคณิตศาสตร์ที่เข้มงวด โรงเรียนมัธยมศึกษาของชาวลิลิพุตมี หลักสูตรที่แข็งแกร่งสำหรับชั้นเรียนคณิตศาสตร์ และนักเรียนส่วนใหญ่ มีคุณสมบัติเหมาะสมสำหรับโปรแกรมมหาวิทยาลัย โรงเรียนมัธยมของชาวบร็อบดิงแนกไม่มี ชั้นเรียนคณิตศาสตร์เลย และด้วยเหตุนี้ นักเรียนที่ มีคุณสมบัติจึงมีจำนวนน้อยกว่ามาก โอกาสที่เท่าเทียมกันจะเกิดขึ้นสำหรับป้ายกำกับที่ต้องการ "รับเข้า" ในส่วนที่เกี่ยวข้องกับสัญชาติ (ลิลิพุตหรือบร็อบดิงแนก) หากนักเรียน/นักศึกษาที่มีคุณสมบัติเหมาะสมมีโอกาสได้รับการรับเข้าเท่ากัน ไม่ว่าจะเป็นชาวลิลิพุตหรือชาวบร็อบดิงแนก
ตัวอย่างเช่น สมมติว่ามีชาวลิลิพุต 100 คนและชาวโบรบดิงแนก 100 คนสมัครเข้าเรียนที่ มหาวิทยาลัยกลับบ์ดับดริบ และการตัดสินใจรับเข้าเรียนมีดังนี้
ตารางที่ 1 ผู้สมัครจากลิลิพุต (90% มีคุณสมบัติ)
| เข้าเกณฑ์ | คุณสมบัติไม่ครบ | |
|---|---|---|
| ยอมรับ | 45 | 3 |
| ถูกปฏิเสธ | 45 | 7 |
| รวม | 90 | 10 |
|
เปอร์เซ็นต์ของนักเรียนที่มีคุณสมบัติเหมาะสมที่ได้รับการตอบรับ: 45/90 = 50% เปอร์เซ็นต์ของนักเรียนที่ไม่มีคุณสมบัติเหมาะสมที่ถูกปฏิเสธ: 7/10 = 70% เปอร์เซ็นต์รวมของนักเรียนชาวลิลิพุตที่ได้รับการตอบรับ: (45+3)/100 = 48% |
||
ตารางที่ 2 ผู้สมัครจาก Brobdingnag (10% มีคุณสมบัติ):
| เข้าเกณฑ์ | คุณสมบัติไม่ครบ | |
|---|---|---|
| ยอมรับ | 5 | 9 |
| ถูกปฏิเสธ | 5 | 81 |
| รวม | 10 | 90 |
|
เปอร์เซ็นต์ของนักเรียนที่มีคุณสมบัติเหมาะสมที่ได้รับการตอบรับ: 5/10 = 50% เปอร์เซ็นต์ของนักเรียนที่ไม่มีคุณสมบัติเหมาะสมที่ถูกปฏิเสธ: 81/90 = 90% เปอร์เซ็นต์รวมของนักเรียน Brobdingnagian ที่ได้รับการตอบรับ: (5+9)/100 = 14% |
||
ตัวอย่างก่อนหน้านี้เป็นไปตามความเท่าเทียมกันในโอกาสที่จะได้รับการยอมรับ สำหรับนักเรียน/นักศึกษาที่มีคุณสมบัติเหมาะสม เนื่องจากทั้งชาวลิลิปุตและชาวบร็อบดิงแนก มีโอกาส 50% ที่จะได้รับการตอบรับ
แม้ว่าโอกาสที่เท่าเทียมจะได้รับการตอบสนอง แต่เมตริกความเป็นธรรม 2 รายการต่อไปนี้ ยังไม่ได้รับการตอบสนอง
- ความเท่าเทียมกันทางประชากรศาสตร์: ชาวลิลิพุตและชาวบร็อบดิงแนกได้รับการตอบรับเข้ามหาวิทยาลัยในอัตราที่แตกต่างกัน โดยมีนักเรียนชาวลิลิพุต 48% ที่ได้รับการตอบรับ แต่มีนักเรียนชาวบร็อบดิงแนกเพียง 14% เท่านั้นที่ได้รับการตอบรับ
- โอกาสที่เท่าเทียมกัน: แม้ว่านักเรียน/นักศึกษาชาวลิลิพุตและชาวบร็อบดิงแนกที่มีคุณสมบัติเหมาะสมจะมีโอกาสได้รับการตอบรับเท่ากัน แต่ข้อจำกัดเพิ่มเติมที่ว่านักเรียน/นักศึกษาชาวลิลิพุตและชาวบร็อบดิงแนกที่ไม่มีคุณสมบัติเหมาะสมจะมีโอกาสถูกปฏิเสธเท่ากันนั้นไม่เป็นจริง ชาวลิลิปุตที่ไม่ผ่านเกณฑ์มีอัตราการปฏิเสธ 70% ส่วนชาวบร็อบดิงแน็กที่ไม่ผ่านเกณฑ์มีอัตราการปฏิเสธ 90%
ดูข้อมูลเพิ่มเติมได้ที่ความเป็นธรรม: ความเท่าเทียมกันของโอกาส ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
โอกาสที่เท่ากัน
เมตริกความเป็นธรรมเพื่อประเมินว่าโมเดลคาดการณ์ผลลัพธ์ได้ดีเท่ากันสำหรับค่าทั้งหมดของแอตทริบิวต์ที่ละเอียดอ่อนหรือไม่ โดยคำนึงถึงทั้งคลาสบวกและคลาสลบ ไม่ใช่แค่คลาสใดคลาสหนึ่งเท่านั้น กล่าวคือ อัตราผลบวกจริง และอัตราผลลบลวงควรเท่ากันสำหรับ ทุกกลุ่ม
โอกาสที่เท่าเทียมกันเกี่ยวข้องกับความเท่าเทียมกันของโอกาส ซึ่งมุ่งเน้นเฉพาะ อัตราข้อผิดพลาดสำหรับคลาสเดียว (บวกหรือลบ)
ตัวอย่างเช่น สมมติว่ามหาวิทยาลัยกลับดับดริบรับทั้งชาวลิลิปุตและชาวบร็อบดิงแนกเข้าเรียนในโปรแกรมคณิตศาสตร์ที่เข้มงวด โรงเรียนมัธยมของชาวลิลิพุต มีหลักสูตรที่แข็งแกร่งสำหรับชั้นเรียนคณิตศาสตร์ และนักเรียนส่วนใหญ่ มีคุณสมบัติเหมาะสมสำหรับโปรแกรมมหาวิทยาลัย โรงเรียนมัธยมของชาวบร็อบดิงแนกไม่มีชั้นเรียนคณิตศาสตร์เลย และด้วยเหตุนี้ นักเรียนจำนวนน้อยมากจึงมีคุณสมบัติเหมาะสม โอกาสที่เท่าเทียมกันจะเกิดขึ้นได้ก็ต่อเมื่อไม่ว่าผู้สมัครจะเป็นชาวลิลิปุตหรือชาวบร็อบดิงแน็ก หากมีคุณสมบัติครบถ้วน ก็มีโอกาสเท่ากันที่จะได้รับการยอมรับให้เข้าร่วมโปรแกรม และหากไม่มีคุณสมบัติครบถ้วน ก็มีโอกาสเท่ากันที่จะถูกปฏิเสธ
สมมติว่าชาวลิลิปุต 100 คนและชาวโบรบดิงแนก 100 คนสมัครเข้าเรียนที่มหาวิทยาลัยกลับบดรับ และมีการตัดสินใจรับเข้าเรียนดังนี้
ตารางที่ 3 ผู้สมัครจากลิลิพุต (90% มีคุณสมบัติ)
| เข้าเกณฑ์ | คุณสมบัติไม่ครบ | |
|---|---|---|
| ยอมรับ | 45 | 2 |
| ถูกปฏิเสธ | 45 | 8 |
| รวม | 90 | 10 |
|
เปอร์เซ็นต์ของนักเรียนที่มีคุณสมบัติผ่านที่ได้รับการตอบรับ: 45/90 = 50% เปอร์เซ็นต์ของนักเรียนที่ไม่มีคุณสมบัติผ่านที่ถูกปฏิเสธ: 8/10 = 80% เปอร์เซ็นต์รวมของนักเรียนชาวลิลิพุตที่ได้รับการตอบรับ: (45+2)/100 = 47% |
||
ตารางที่ 4 ผู้สมัครจาก Brobdingnag (10% มีคุณสมบัติ):
| เข้าเกณฑ์ | คุณสมบัติไม่ครบ | |
|---|---|---|
| ยอมรับ | 5 | 18 |
| ถูกปฏิเสธ | 5 | 72 |
| รวม | 10 | 90 |
|
เปอร์เซ็นต์ของนักเรียนที่มีคุณสมบัติเหมาะสมที่ได้รับการตอบรับ: 5/10 = 50% เปอร์เซ็นต์ของนักเรียนที่ไม่มีคุณสมบัติเหมาะสมที่ถูกปฏิเสธ: 72/90 = 80% เปอร์เซ็นต์รวมของนักเรียนจาก Brobdingnag ที่ได้รับการตอบรับ: (5+18)/100 = 23% |
||
โอกาสที่เท่าเทียมกันเป็นไปตามเงื่อนไขเนื่องจากนักเรียนที่มีคุณสมบัติเหมาะสมทั้งชาวลิลิพุตและชาวบร็อบดิงแนก มีโอกาส 50% ที่จะได้รับการตอบรับ และนักเรียนที่ไม่มีคุณสมบัติเหมาะสมทั้งชาวลิลิพุต และชาวบร็อบดิงแนกมีโอกาส 80% ที่จะถูกปฏิเสธ
ความน่าจะเป็นที่เท่ากันมีการกำหนดอย่างเป็นทางการใน "ความเท่าเทียมของ โอกาสในการเรียนรู้ภายใต้การกำกับดูแล" ดังนี้ "ตัวทำนาย Ŷ มีความน่าจะเป็นที่เท่ากันเมื่อเทียบกับ แอตทริบิวต์ที่ได้รับการคุ้มครอง A และผลลัพธ์ Y หาก Ŷ และ A เป็นอิสระ โดยมีเงื่อนไขเป็น Y"
evals
ใช้เป็นคำย่อสำหรับการประเมิน LLM เป็นหลัก ในวงกว้าง evals เป็นคำย่อของการประเมินในรูปแบบใดก็ได้
การประเมิน
กระบวนการวัดคุณภาพของโมเดลหรือการเปรียบเทียบโมเดลต่างๆ กับโมเดลอื่นๆ
โดยปกติแล้ว คุณจะประเมินโมเดลแมชชีนเลิร์นนิงที่มีการควบคุมดูแลโดยเปรียบเทียบกับชุดข้อมูลสำหรับตรวจสอบความถูกต้องและชุดทดสอบ การประเมิน LLM โดยทั่วไปจะเกี่ยวข้องกับการประเมินคุณภาพและความปลอดภัยในวงกว้าง
การทำงานแบบตรง
เมตริกแบบทั้งหมดหรือไม่มีเลยซึ่งเอาต์พุตของโมเดลจะตรงกับข้อมูลจากการสังเกตการณ์โดยตรงหรือข้อความอ้างอิง อย่างใดอย่างหนึ่ง เช่น หากข้อมูลที่เป็นความจริงคือ orange เอาต์พุตโมเดลเดียวที่ตรงกับการทำงานแบบตรงทั้งหมดคือ orange
การทำงานแบบตรงทั้งหมดสามารถประเมินโมเดลที่มีเอาต์พุตเป็นลำดับได้ด้วย (รายการที่จัดอันดับแล้ว) โดยทั่วไป การทำงานแบบตรงทั้งหมดกำหนดให้รายการที่จัดอันดับซึ่งสร้างขึ้นต้องตรงกับข้อมูลที่เป็นความจริงทุกประการ กล่าวคือ รายการแต่ละรายการในทั้ง 2 รายการต้องอยู่ในลำดับเดียวกัน อย่างไรก็ตาม หากข้อมูลที่เป็นความจริงประกอบด้วยลำดับที่ถูกต้องหลายลำดับ การทำงานแบบตรงทั้งหมดจะกำหนดให้เอาต์พุตของโมเดลตรงกับลำดับที่ถูกต้องลำดับใดลำดับหนึ่งเท่านั้น
การสรุปแบบสุดขั้ว (xsum)
ชุดข้อมูลสำหรับการประเมินความสามารถของ LLM ในการสรุปเอกสารเดียว แต่ละรายการในชุดข้อมูลประกอบด้วย
- เอกสารที่เขียนโดย British Broadcasting Corporation (BBC)
- สรุปเอกสารนั้นใน 1 ประโยค
ดูรายละเอียดได้ที่ ไม่ต้องบอกรายละเอียด แค่สรุปให้หน่อย Topic-Aware Convolutional Neural Networks for Extreme Summarization
F
F1
เมตริกการจัดประเภทแบบไบนารีแบบ "ภาพรวม" ที่ อิงตามทั้งความแม่นยำและความอ่อนไหว สูตรมีดังนี้
เมตริกความเป็นธรรม
คำจำกัดความทางคณิตศาสตร์ของ "ความเป็นธรรม" ที่วัดได้ เมตริกความเป็นธรรมที่ใช้กันโดยทั่วไปมีดังนี้
- โอกาสที่เท่าเทียม
- ความเท่าเทียมในการคาดการณ์
- ความยุติธรรมแบบข้อเท็จจริง
- ความเท่าเทียมกันของข้อมูลประชากร
เมตริกความเป็นธรรมหลายรายการไม่สามารถใช้ร่วมกันได้ โปรดดูความไม่เข้ากันของเมตริกความเป็นธรรม
ผลลบลวง (FN)
ตัวอย่างที่โมเดลคาดการณ์คลาสเชิงลบผิดพลาด เช่น โมเดล คาดการณ์ว่าข้อความอีเมลหนึ่งๆ ไม่ใช่จดหมายขยะ (คลาสเชิงลบ) แต่ข้อความอีเมลนั้นเป็นจดหมายขยะจริง
อัตราผลลบลวง
สัดส่วนของตัวอย่างที่เป็นบวกจริงซึ่งโมเดลคาดการณ์คลาสเชิงลบผิดพลาด สูตรต่อไปนี้ใช้ในการคำนวณอัตราผลลบลวง
ดูข้อมูลเพิ่มเติมได้ที่เกณฑ์และเมทริกซ์ความสับสน ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ผลบวกลวง (FP)
ตัวอย่างที่โมเดลคาดการณ์คลาสที่เป็นบวกอย่างไม่ถูกต้อง เช่น โมเดลคาดการณ์ว่าข้อความอีเมลหนึ่งๆ เป็นจดหมายขยะ (คลาสบวก) แต่ข้อความอีเมลนั้นไม่ใช่จดหมายขยะ
ดูข้อมูลเพิ่มเติมได้ที่เกณฑ์และเมทริกซ์ความสับสน ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
อัตราผลบวกลวง (FPR)
สัดส่วนของตัวอย่างเชิงลบจริงที่โมเดลคาดการณ์คลาสเชิงบวกผิดพลาด สูตรต่อไปนี้ใช้ในการคำนวณอัตราผลบวกลวง
อัตราผลบวกลวงคือแกน x ในกราฟ ROC
ดูข้อมูลเพิ่มเติมได้ที่การแยกประเภท: ROC และ AUC ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ความสำคัญของฟีเจอร์
คำพ้องความหมายสำหรับความสำคัญของตัวแปร
โมเดลพื้นฐาน
โมเดลที่ได้รับการฝึกเบื้องต้นขนาดใหญ่มาก ซึ่งได้รับการฝึกจากชุดฝึกที่หลากหลายและมีขนาดใหญ่ โมเดลพื้นฐานสามารถทำทั้ง 2 อย่างต่อไปนี้ได้
- ตอบสนองต่อคำขอที่หลากหลายได้ดี
- ใช้เป็นโมเดลพื้นฐานสำหรับการปรับแต่งเพิ่มเติมหรือการปรับแต่งอื่นๆ
กล่าวคือ โมเดลพื้นฐานมีความสามารถสูงอยู่แล้วในแง่ทั่วไป แต่สามารถปรับแต่งเพิ่มเติมให้มีประโยชน์มากยิ่งขึ้นสำหรับงานที่เฉพาะเจาะจงได้
เศษส่วนของความสำเร็จ
เมตริกสําหรับประเมินข้อความที่โมเดล ML สร้างขึ้น เศษส่วนของความสำเร็จคือจำนวนเอาต์พุตข้อความที่สร้างขึ้นซึ่ง "สำเร็จ" หารด้วยจำนวนเอาต์พุตข้อความที่สร้างขึ้นทั้งหมด ตัวอย่างเช่น หากโมเดลภาษาขนาดใหญ่สร้างโค้ด 10 บล็อก และมี 5 บล็อกที่สำเร็จ เศษส่วนของความสำเร็จ จะเป็น 50%
แม้ว่าเศษส่วนของความสำเร็จจะมีประโยชน์อย่างกว้างขวางในสถิติ แต่ใน ML เมตริกนี้มีประโยชน์หลักๆ ในการวัดงานที่ตรวจสอบได้ เช่น การสร้างโค้ดหรือปัญหาทางคณิตศาสตร์
G
ความไม่บริสุทธิ์ของจีนี
เมตริกที่คล้ายกับเอนโทรปี ตัวแยก ใช้ค่าที่ได้จากความไม่บริสุทธิ์ของ Gini หรือเอนโทรปีเพื่อสร้าง เงื่อนไขสำหรับการจัดประเภท ต้นไม้ตัดสินใจ การได้ข้อมูลได้มาจากเอนโทรปี ไม่มีคำที่เทียบเท่าซึ่งเป็นที่ยอมรับกันโดยทั่วไปสำหรับเมตริกที่ได้จากความไม่บริสุทธิ์ของ Gini อย่างไรก็ตาม เมตริกที่ไม่มีชื่อนี้มีความสำคัญไม่แพ้การได้ข้อมูล
ความไม่บริสุทธิ์ของจีนียังเรียกว่าดัชนีจีนี หรือเรียกสั้นๆ ว่าจีนี
H
การสูญเสียบานพับ
ตระกูลฟังก์ชันการสูญเสียสำหรับการจัดประเภทที่ออกแบบมาเพื่อค้นหาขอบเขตการตัดสินใจให้ไกลที่สุดจากตัวอย่างการฝึกแต่ละรายการ จึงเป็นการเพิ่มระยะขอบระหว่างตัวอย่างกับขอบเขตให้ได้มากที่สุด KSVM ใช้การสูญเสียแบบบานพับ (หรือฟังก์ชันที่เกี่ยวข้อง เช่น การสูญเสียแบบบานพับยกกำลังสอง) สําหรับการจัดประเภทแบบไบนารี ฟังก์ชันการสูญเสียแบบบานพับ จะกําหนดดังนี้
โดย y คือป้ายกำกับที่แท้จริง ซึ่งอาจเป็น -1 หรือ +1 และ y' คือเอาต์พุตดิบ ของโมเดลการแยกประเภท:
ดังนั้น พล็อตของฟังก์ชันการสูญเสียแบบบานพับเทียบกับ (y * y') จะมีลักษณะดังนี้

I
ความไม่เข้ากันของเมตริกความเป็นธรรม
แนวคิดที่ว่าแนวคิดเรื่องความยุติธรรมบางอย่างใช้ร่วมกันไม่ได้และ ไม่สามารถตอบสนองพร้อมกันได้ ด้วยเหตุนี้ จึงไม่มีเมตริกเดียวที่ใช้กันทั่วไป ในการวัดความเป็นธรรม ซึ่งนำไปใช้กับปัญหา ML ทั้งหมดได้
แม้ว่าอาจดูเหมือนว่าเมตริกความเป็นธรรมไม่เข้ากัน แต่ก็ไม่ได้หมายความว่าความพยายามด้านความเป็นธรรมจะไร้ผล แต่กลับแนะนำว่า ต้องกำหนดความเป็นธรรมตามบริบทสำหรับปัญหา ML ที่กำหนด โดยมี เป้าหมายเพื่อป้องกันอันตรายที่เฉพาะเจาะจงกับ Use Case ของปัญหา
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการไม่สามารถใช้เมตริกความเป็นธรรมร่วมกันได้ที่ "On the (im)possibility of fairness"
ความเป็นธรรมต่อบุคคล
เมตริกความเป็นธรรมที่ตรวจสอบว่าบุคคลที่คล้ายกันได้รับการจัดประเภท ในลักษณะเดียวกันหรือไม่ ตัวอย่างเช่น Brobdingnagian Academy อาจต้องการสร้างความเป็นธรรมในระดับบุคคลโดยการรับประกันว่านักเรียน 2 คนที่มีคะแนนเหมือนกันและคะแนนสอบมาตรฐานมีโอกาสเท่ากันที่จะได้รับการตอบรับ
โปรดทราบว่าความเป็นธรรมในระดับบุคคลขึ้นอยู่กับวิธีที่คุณกำหนด "ความคล้ายคลึง" (ในกรณีนี้คือเกรดและคะแนนสอบ) และคุณอาจเสี่ยงต่อการ ทำให้เกิดปัญหาด้านความเป็นธรรมใหม่ๆ หากเมตริกความคล้ายคลึงพลาดข้อมูลสำคัญ (เช่น ความเข้มงวดของหลักสูตรของนักเรียน)
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการพิจารณาความเป็นธรรมในแต่ละบุคคลได้ที่ "ความเป็นธรรมผ่านการรับรู้"
การได้ข้อมูล
ในป่าการตัดสินใจ ความแตกต่างระหว่างเอนโทรปีของโหนดกับผลรวมของเอนโทรปีของโหนดลูกที่ถ่วงน้ำหนัก (ตามจำนวนตัวอย่าง) เอนโทรปีของโหนดคือเอนโทรปี ของตัวอย่างในโหนดนั้น
ตัวอย่างเช่น ลองพิจารณาค่าเอนโทรปีต่อไปนี้
- เอนโทรปีของโหนดหลัก = 0.6
- เอนโทรปีของโหนดลูกที่มีตัวอย่างที่เกี่ยวข้อง 16 รายการ = 0.2
- เอนโทรปีของโหนดย่อยอีกโหนดหนึ่งที่มีตัวอย่างที่เกี่ยวข้อง 24 รายการ = 0.1
ดังนั้น ตัวอย่าง 40% จึงอยู่ในโหนดลูกโหนดหนึ่ง และอีก 60% อยู่ในโหนดลูกอีกโหนดหนึ่ง ดังนั้น
- ผลรวมของเอนโทรปีแบบถ่วงน้ำหนักของโหนดย่อย = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
ดังนั้น การได้ข้อมูลจึงเป็นดังนี้
- การได้ข้อมูล = เอนโทรปีของโหนดแม่ - ผลรวมของเอนโทรปีแบบถ่วงน้ำหนักของโหนดลูก
- การได้ข้อมูล = 0.6 - 0.14 = 0.46
ตัวแยกส่วนใหญ่พยายามสร้างเงื่อนไข ที่เพิ่มการรับข้อมูลให้ได้มากที่สุด
ความสอดคล้องระหว่างผู้ประเมิน
การวัดความถี่ที่ผู้ให้คะแนนที่เป็นมนุษย์เห็นด้วยเมื่อทำภารกิจ หากผู้ให้คะแนนไม่เห็นด้วย คุณอาจต้องปรับปรุงวิธีการทำงาน บางครั้งเรียกว่าความสอดคล้องระหว่างผู้ใส่คำอธิบายประกอบหรือ ความน่าเชื่อถือระหว่างผู้ให้คะแนน ดูค่าแคปปาของโคเฮนด้วย ซึ่งเป็นหนึ่งในการวัดข้อตกลงระหว่างผู้ประเมินที่ได้รับความนิยมมากที่สุด
ดูข้อมูลเพิ่มเติมได้ที่ข้อมูลเชิงหมวดหมู่: ปัญหาที่พบบ่อย ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
L
แพ้ 1 นัด
ฟังก์ชันการสูญเสียที่คำนวณค่าสัมบูรณ์ของความแตกต่างระหว่างค่าป้ายกำกับจริงกับค่าที่โมเดลคาดการณ์ ตัวอย่างเช่น ต่อไปนี้คือการคำนวณการสูญเสีย L1 สำหรับกลุ่มของตัวอย่าง 5 รายการ
| มูลค่าที่แท้จริงของตัวอย่าง | ค่าที่โมเดลคาดการณ์ | ค่าสัมบูรณ์ของเดลต้า |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = การสูญเสีย L1 | ||
การสูญเสีย L1 มีความไวต่อค่าผิดปกติน้อยกว่าการสูญเสีย L2
ค่าเฉลี่ยความผิดพลาดสัมบูรณ์คือการสูญเสีย L1 โดยเฉลี่ยต่อตัวอย่าง
ดูข้อมูลเพิ่มเติมได้ที่ การถดถอยเชิงเส้น: การสูญเสีย ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การสูญเสีย L2
ฟังก์ชันการสูญเสียที่คำนวณกำลังสองของความแตกต่างระหว่างค่าป้ายกำกับจริงกับค่าที่โมเดลคาดการณ์ ตัวอย่างเช่น ต่อไปนี้คือการคำนวณการสูญเสีย L2 สำหรับกลุ่มของตัวอย่าง 5 รายการ
| มูลค่าที่แท้จริงของตัวอย่าง | ค่าที่โมเดลคาดการณ์ | สี่เหลี่ยมของเดลต้า |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 loss | ||
เนื่องจากการยกกำลังสอง การสูญเสีย L2 จึงขยายอิทธิพลของค่าผิดปกติ กล่าวคือ การสูญเสีย L2 จะตอบสนองต่อการคาดการณ์ที่ไม่ดีมากกว่าการสูญเสีย L1 เช่น การสูญเสีย L1 สำหรับกลุ่มก่อนหน้าจะเป็น 8 แทนที่จะเป็น 16 โปรดสังเกตว่าข้อมูลผิดปกติทางสถิติเพียงรายการเดียวคิดเป็น 9 จาก 16 รายการ
โมเดลการถดถอยมักใช้ Loss L2 เป็น Loss Function
ความคลาดเคลื่อนเฉลี่ยกำลังสองคือการสูญเสีย L2 โดยเฉลี่ยต่อตัวอย่าง Squared loss เป็นอีกชื่อหนึ่งของ L2 loss
ดูข้อมูลเพิ่มเติมได้ที่การถดถอยแบบโลจิสติก: การสูญเสียและ Regularization ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การประเมิน LLM (Evals)
ชุดเมตริกและการเปรียบเทียบสำหรับประเมินประสิทธิภาพของ โมเดลภาษาขนาดใหญ่ (LLM) การประเมิน LLM ในระดับสูงมีดังนี้
- ช่วยนักวิจัยระบุจุดที่ LLM จำเป็นต้องได้รับการปรับปรุง
- มีประโยชน์ในการเปรียบเทียบ LLM ต่างๆ และระบุ LLM ที่ดีที่สุดสำหรับงานหนึ่งๆ
- ช่วยให้มั่นใจว่า LLM จะปลอดภัยและมีจริยธรรมในการใช้งาน
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ (LLM) ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
แพ้
ในระหว่างการฝึกโมเดลภายใต้การควบคุม จะมีการวัดว่าการคาดการณ์ของโมเดลอยู่ห่างจากป้ายกำกับของโมเดลมากน้อยเพียงใด
ฟังก์ชันการสูญเสียจะคำนวณการสูญเสีย
ดูข้อมูลเพิ่มเติมได้ที่ Linear regression: Loss ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ฟังก์ชันการสูญเสีย
ในระหว่างการฝึกหรือการทดสอบ ฟังก์ชันทางคณิตศาสตร์ที่คำนวณ การสูญเสียในกลุ่มของตัวอย่าง ฟังก์ชันการสูญเสียจะส่งคืนการสูญเสียที่ต่ำกว่า สำหรับโมเดลที่ทำการคาดการณ์ได้ดีกว่าโมเดลที่ทำการคาดการณ์ ได้ไม่ดี
โดยปกติแล้วเป้าหมายของการฝึกคือการลดการสูญเสียที่ฟังก์ชันการสูญเสีย ส่งคืน
ฟังก์ชันการสูญเสียมีหลายประเภท เลือกฟังก์ชันการสูญเสียที่เหมาะสม สำหรับโมเดลประเภทที่คุณสร้าง เช่น
- การสูญเสีย L2 (หรือข้อผิดพลาดกำลังสองเฉลี่ย) คือฟังก์ชันการสูญเสียสำหรับการถดถอยเชิงเส้น
- Log Loss คือฟังก์ชันการสูญเสียสำหรับ การถดถอยแบบโลจิสติก
M
MBPP
ตัวย่อของ Mostly Basic Python Problems
ค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์ (MAE)
การสูญเสียเฉลี่ยต่อตัวอย่างเมื่อใช้การสูญเสีย L1 คำนวณค่าเฉลี่ยความผิดพลาดสัมบูรณ์ดังนี้
- คำนวณการสูญเสีย L1 สำหรับกลุ่ม
- หารการสูญเสีย L1 ด้วยจำนวนตัวอย่างในกลุ่ม
ตัวอย่างเช่น ลองพิจารณาการคำนวณการสูญเสีย L1 ในชุดตัวอย่าง 5 รายการต่อไปนี้
| มูลค่าที่แท้จริงของตัวอย่าง | ค่าที่โมเดลคาดการณ์ | การสูญเสีย (ความแตกต่างระหว่างค่าจริงกับค่าที่คาดการณ์) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = การสูญเสีย L1 | ||
ดังนั้นการสูญเสีย L1 คือ 8 และจำนวนตัวอย่างคือ 5 ดังนั้นค่าเฉลี่ยความผิดพลาดสัมบูรณ์จึงเป็นดังนี้
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
เปรียบเทียบค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์กับความคลาดเคลื่อนเฉลี่ยกำลังสองและสแควรูทของความคลาดเคลื่อนกำลังสองเฉลี่ย
ความแม่นยำของค่าเฉลี่ยที่ k (mAP@k)
ค่าเฉลี่ยทางสถิติของคะแนนความแม่นยำเฉลี่ยที่ k ทั้งหมดในชุดข้อมูลการตรวจสอบ การใช้ความแม่นยำเฉลี่ยที่ตำแหน่ง k อย่างหนึ่งคือการประเมิน คุณภาพของคำแนะนำที่สร้างโดยระบบแนะนำ
แม้ว่าวลี "ค่าเฉลี่ย" จะฟังดูซ้ำซ้อน แต่ชื่อของเมตริกก็เหมาะสม เนื่องจากเมตริกนี้จะหาค่าเฉลี่ยของค่าความแม่นยำเฉลี่ยที่ k หลายค่า
ความคลาดเคลื่อนเฉลี่ยกำลังสอง (MSE)
การสูญเสียเฉลี่ยต่อตัวอย่างเมื่อใช้L2 loss คำนวณความคลาดเคลื่อนเฉลี่ยกำลังสองดังนี้
- คำนวณการสูญเสีย L2 สำหรับกลุ่ม
- หารการสูญเสีย L2 ด้วยจำนวนตัวอย่างในกลุ่ม
ตัวอย่างเช่น ลองพิจารณาการสูญเสียในกลุ่มตัวอย่าง 5 รายการต่อไปนี้
| มูลค่าที่แท้จริง | การคาดการณ์ของโมเดล | แพ้ | การสูญเสียกำลังสอง |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 loss | |||
ดังนั้น ความคลาดเคลื่อนเฉลี่ยกำลังสองจึงเป็น
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
ความคลาดเคลื่อนเฉลี่ยกำลังสองเป็นเครื่องมือเพิ่มประสิทธิภาพการฝึกยอดนิยม โดยเฉพาะอย่างยิ่งสำหรับการถดถอยเชิงเส้น
เปรียบเทียบความคลาดเคลื่อนกำลังสองเฉลี่ยกับค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์และสแควรูทของความคลาดเคลื่อนกำลังสองเฉลี่ย
TensorFlow Playground ใช้ข้อผิดพลาดกำลังสองเฉลี่ย เพื่อคำนวณค่าการสูญเสีย
เมตริก
สถิติที่คุณสนใจ
วัตถุประสงค์คือเมตริกที่ระบบแมชชีนเลิร์นนิง พยายามเพิ่มประสิทธิภาพ
Metrics API (tf.metrics)
API ของ TensorFlow สำหรับการประเมินโมเดล เช่น tf.metrics.accuracy
จะกำหนดความถี่ที่การคาดการณ์ของโมเดลตรงกับป้ายกำกับ
การสูญเสียแบบมินิแม็กซ์
ฟังก์ชันการสูญเสียสำหรับGenerative Adversarial Networks โดยอิงตามCross-Entropy ระหว่างการกระจาย ของข้อมูลที่สร้างขึ้นและข้อมูลจริง
การสูญเสียแบบมินิแม็กซ์ใช้ในเอกสารฉบับแรกเพื่ออธิบาย Generative Adversarial Network
ดูข้อมูลเพิ่มเติมได้ที่ฟังก์ชันการสูญเสียใน หลักสูตร Generative Adversarial Networks
ความจุของโมเดล
ความซับซ้อนของปัญหาที่โมเดลสามารถเรียนรู้ได้ ยิ่งโมเดลเรียนรู้ปัญหาที่ซับซ้อนได้มากเท่าใด ความสามารถของโมเดลก็จะยิ่งสูงขึ้นเท่านั้น โดยปกติแล้ว ความจุของโมเดลจะเพิ่มขึ้นตามจำนวนพารามิเตอร์ของโมเดล ดูคำจำกัดความอย่างเป็นทางการของความจุโมเดลการจัดประเภทได้ที่มิติข้อมูล VC
โจทย์ปัญหา Python พื้นฐานส่วนใหญ่ (MBPP)
ชุดข้อมูลสำหรับประเมินความสามารถของ LLM ในการสร้างโค้ด Python Mostly Basic Python Problems มีปัญหาการเขียนโปรแกรมที่รวบรวมจากมวลชนประมาณ 1,000 รายการ ปัญหาแต่ละข้อในชุดข้อมูลประกอบด้วยข้อมูลต่อไปนี้
- คำอธิบายงาน
- รหัสโซลูชัน
- กรณีทดสอบอัตโนมัติ 3 กรณี
N
คลาสที่เป็นลบ
ในการจัดประเภทแบบไบนารี คลาสหนึ่งจะเรียกว่าบวกและอีกคลาสหนึ่งจะเรียกว่าลบ คลาสที่เป็นบวกคือ สิ่งหรือเหตุการณ์ที่โมเดลกำลังทดสอบ และคลาสที่เป็นลบคือ ความเป็นไปได้อื่นๆ เช่น
- คลาสเชิงลบในการตรวจทางการแพทย์อาจเป็น "ไม่ใช่มะเร็ง"
- คลาสเชิงลบในโมเดลการจัดประเภทอีเมลอาจเป็น "ไม่ใช่จดหมายขยะ"
เปรียบเทียบกับคลาสที่เป็นบวก
O
วัตถุประสงค์
เมตริกที่อัลกอริทึมพยายามเพิ่มประสิทธิภาพ
ฟังก์ชันเป้าหมาย
สูตรทางคณิตศาสตร์หรือเมตริกที่โมเดลต้องการเพิ่มประสิทธิภาพ เช่น ฟังก์ชันเป้าหมายสำหรับการถดถอยเชิงเส้นมักจะเป็นการสูญเสียกำลังสองเฉลี่ย ดังนั้น เมื่อฝึกโมเดลการถดถอยเชิงเส้น การฝึกจึงมุ่งเน้นที่การลดการสูญเสียค่าเฉลี่ยกำลังสอง
ในบางกรณี เป้าหมายคือการเพิ่มฟังก์ชันออบเจ็กทีฟให้ได้สูงสุด เช่น หากฟังก์ชันออบเจ็กทีฟคือความแม่นยำ เป้าหมายคือ การเพิ่มความแม่นยำสูงสุด
ดูการสูญเสียด้วย
P
pass at k (pass@k)
เมตริกที่ใช้กำหนดคุณภาพของโค้ด (เช่น Python) ที่โมเดลภาษาขนาดใหญ่สร้างขึ้น กล่าวโดยละเอียดคือ Pass@k จะบอกความน่าจะเป็นที่โค้ดอย่างน้อย 1 บล็อกจากโค้ด k บล็อกที่สร้างขึ้นจะผ่านการทดสอบหน่วยทั้งหมด
โมเดลภาษาขนาดใหญ่มักประสบปัญหาในการสร้างโค้ดที่ดีสำหรับปัญหาการเขียนโปรแกรมที่ซับซ้อน วิศวกรซอฟต์แวร์ปรับตัวให้เข้ากับปัญหานี้โดย การแจ้งโมเดลภาษาขนาดใหญ่ให้สร้างโซลูชันหลายรายการ (k) สำหรับปัญหาเดียวกัน จากนั้นวิศวกรซอฟต์แวร์จะทดสอบโซลูชันแต่ละรายการ กับการทดสอบหน่วย การคำนวณการผ่านที่ k จะขึ้นอยู่กับผลลัพธ์ ของการทดสอบหน่วย
- หากโซลูชันอย่างน้อย 1 รายการผ่านการทดสอบหน่วย แสดงว่า LLM ผ่านความท้าทายในการสร้างโค้ดนั้น
- หากไม่มีโซลูชันใดผ่านการทดสอบหน่วย LLM จะไม่ผ่านความท้าทายในการสร้างโค้ดนั้น
สูตรสำหรับผ่านที่ k มีดังนี้
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
โดยทั่วไป ค่า k ที่สูงขึ้นจะทำให้คะแนนที่ผ่านที่ k สูงขึ้น อย่างไรก็ตาม ค่า k ที่สูงขึ้นต้องใช้โมเดลภาษาขนาดใหญ่และการทำ Unit Test มากขึ้น
การแสดง
คำที่มีความหมายหลายอย่างต่อไปนี้
- ความหมายมาตรฐานในวิศวกรรมซอฟต์แวร์ กล่าวคือ ซอฟต์แวร์นี้ทำงานได้เร็ว (หรือมีประสิทธิภาพ) เพียงใด
- ความหมายในแมชชีนเลิร์นนิง ในที่นี้ ประสิทธิภาพจะตอบคำถามต่อไปนี้ โมเดลนี้ถูกต้องเพียงใด กล่าวคือ การคาดการณ์ของโมเดลดีเพียงใด
ความสําคัญของตัวแปรการเรียงสับเปลี่ยน
ประเภทของความสําคัญของตัวแปรที่ประเมิน การเพิ่มขึ้นของข้อผิดพลาดในการคาดการณ์ของโมเดลหลังจากสลับค่าของฟีเจอร์ ความสําคัญของตัวแปรการสับเปลี่ยนเป็นเมตริกที่ไม่ขึ้นอยู่กับโมเดล
Perplexity
มาตรวัดหนึ่งที่ใช้ประเมินว่าโมเดลทํางานได้ดีเพียงใด เช่น สมมติว่างานของคุณคือการอ่านตัวอักษร 2-3 ตัวแรกของคำ ที่ผู้ใช้พิมพ์บนแป้นพิมพ์โทรศัพท์ และแสดงรายการคำที่เป็นไปได้ เพื่อเติมคำให้สมบูรณ์ ค่าความซับซ้อน P สำหรับงานนี้คือจำนวนคำที่คุณต้องเสนอเพื่อให้รายการของคุณมีคำจริงที่ผู้ใช้พยายามพิมพ์
Perplexity เกี่ยวข้องกับCross-Entropy ดังนี้
คลาสที่เป็นบวก
ชั้นเรียนที่คุณกำลังทดสอบ
เช่น คลาสที่เป็นบวกในโมเดลมะเร็งอาจเป็น "เนื้องอก" คลาสที่เป็นบวกในโมเดลการจัดประเภทอีเมล อาจเป็น "จดหมายขยะ"
เปรียบเทียบกับคลาสที่เป็นลบ
PR AUC (พื้นที่ใต้กราฟ PR)
พื้นที่ใต้กราฟ Precision-Recall ที่ประมาณค่าระหว่างจุด (ความอ่อนไหว ความแม่นยำ) สำหรับค่าต่างๆ ของเกณฑ์การจัดประเภท
ความแม่นยำ
เมตริกสําหรับโมเดลการจัดประเภทที่ตอบคําถามต่อไปนี้
เมื่อโมเดลคาดการณ์คลาสเชิงบวก การคาดการณ์กี่เปอร์เซ็นต์ที่ถูกต้อง
สูตรมีดังนี้
where:
- ผลบวกจริงหมายความว่าโมเดลคาดการณ์คลาสที่เป็นบวกได้ถูกต้อง
- ผลบวกลวงหมายความว่าโมเดลคาดการณ์คลาสที่เป็นบวกอย่างไม่ถูกต้อง
เช่น สมมติว่าโมเดลทำการคาดการณ์เชิงบวก 200 รายการ จากการคาดการณ์ที่เป็นบวก 200 รายการ
- 150 รายการเป็นผลบวกจริง
- 50 รายการเป็นการตรวจจับที่ผิดพลาด
ในกรณีนี้
เปรียบเทียบกับความแม่นยำและความอ่อนไหว
ดูข้อมูลเพิ่มเติมได้ที่การจัดประเภท: ความแม่นยำ, การเรียกคืน, ความแม่นยำ และเมตริกที่เกี่ยวข้อง ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ความแม่นยำที่ k (precision@k)
เมตริกสําหรับการประเมินรายการที่จัดอันดับ (เรียงลําดับ) ความแม่นยำที่ k ระบุเศษส่วนของรายการแรก k ในรายการนั้น ซึ่ง "เกี่ยวข้อง" โดยการ
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
ค่าของ k ต้องน้อยกว่าหรือเท่ากับความยาวของรายการที่แสดง โปรดทราบว่าความยาวของรายการที่แสดงจะไม่รวมอยู่ในการคำนวณ
ความเกี่ยวข้องมักเป็นเรื่องส่วนบุคคล แม้แต่ผู้ประเมินที่เป็นมนุษย์ซึ่งเป็นผู้เชี่ยวชาญก็มักไม่เห็นด้วยว่ารายการใดเกี่ยวข้อง
เปรียบเทียบกับ:
เส้นโค้ง Precision-Recall
กราฟของความแม่นยำเทียบกับความอ่อนไหวที่เกณฑ์การจัดประเภทต่างๆ
อคติในการคาดการณ์
ค่าที่บ่งบอกว่าค่าเฉลี่ยของการคาดการณ์อยู่ห่างจากค่าเฉลี่ยของป้ายกำกับ ในชุดข้อมูลมากน้อยเพียงใด
อย่าสับสนกับคำว่าอคติในโมเดลแมชชีนเลิร์นนิง หรืออคติในด้านจริยธรรมและความยุติธรรม
ความเท่าเทียมในการคาดการณ์
เมตริกความเป็นธรรมที่ตรวจสอบว่าสำหรับโมเดลการแยกประเภทที่กำหนด อัตราความแม่นยำเทียบเท่ากับกลุ่มย่อยที่พิจารณาหรือไม่
ตัวอย่างเช่น โมเดลที่คาดการณ์การตอบรับเข้าวิทยาลัยจะตรงตาม ความเท่าเทียมเชิงคาดการณ์สำหรับสัญชาติ หากอัตราความแม่นยำเท่ากัน สำหรับชาวลิลิปุตและชาวโบรบดิงแนก
บางครั้งเราเรียกความเท่าเทียมในการคาดการณ์ว่าความเท่าเทียมของอัตราการคาดการณ์
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการเท่าเทียมกันในการคาดการณ์ได้ที่ "คำอธิบายคำจำกัดความของความเป็นธรรม" (ส่วนที่ 3.2.1)
ความเท่าเทียมของราคาเชิงคาดการณ์
อีกชื่อหนึ่งของความเท่าเทียมเชิงคาดการณ์
ฟังก์ชันความหนาแน่นของความน่าจะเป็น
ฟังก์ชันที่ระบุความถี่ของตัวอย่างข้อมูลที่มีค่าใดค่าหนึ่งตรงกัน เมื่อค่าของชุดข้อมูลเป็นตัวเลขจุดลอยตัวแบบต่อเนื่อง การจับคู่ที่ตรงกันทุกประการจะเกิดขึ้นได้ยาก อย่างไรก็ตาม การหาปริพันธ์ของฟังก์ชันความหนาแน่นของความน่าจะเป็นจากค่า x ถึงค่า y จะให้ความถี่ที่คาดไว้ของตัวอย่างข้อมูลระหว่าง x และ y
ตัวอย่างเช่น พิจารณาการแจกแจงปกติที่มีค่าเฉลี่ย 200 และค่าเบี่ยงเบนมาตรฐาน 30 หากต้องการกำหนดความถี่ที่คาดไว้ของตัวอย่างข้อมูล ที่อยู่ในช่วง 211.4 ถึง 218.7 คุณสามารถรวมความน่าจะเป็น ฟังก์ชันความหนาแน่นสำหรับการแจกแจงแบบปกติจาก 211.4 ถึง 218.7
R
ชุดข้อมูลการอ่านทำความเข้าใจพร้อมการให้เหตุผลแบบสามัญสำนึก (ReCoRD)
ชุดข้อมูลสำหรับประเมินความสามารถของ LLM ในการใช้เหตุผลตามสามัญสำนึก ตัวอย่างแต่ละรายการในชุดข้อมูลประกอบด้วย 3 องค์ประกอบ ได้แก่
- ย่อหน้า 1-2 ย่อหน้าจากบทความข่าว
- คำค้นหาที่มีการมาสก์เอนทิตีอย่างใดอย่างหนึ่งที่ระบุอย่างชัดเจนหรือโดยนัยในข้อความ
- คำตอบ (ชื่อของเอนทิตีที่อยู่ในมาสก์)
ดูตัวอย่างเพิ่มเติมได้ที่ ReCoRD
ReCoRD เป็นส่วนประกอบของกลุ่ม SuperGLUE
RealToxicityPrompts
ชุดข้อมูลที่มีชุดจุดเริ่มต้นของประโยคที่อาจมี เนื้อหาที่เป็นพิษ ใช้ชุดข้อมูลนี้เพื่อประเมินความสามารถของ LLM ในการสร้าง ข้อความที่ไม่เป็นพิษเพื่อเติมประโยคให้สมบูรณ์ โดยปกติแล้ว คุณจะใช้ Perspective API เพื่อพิจารณาว่า LLM ทำงานนี้ได้ดีเพียงใด
ดูรายละเอียดได้ที่ RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
การเรียกคืน
เมตริกสําหรับโมเดลการจัดประเภทที่ตอบคําถามต่อไปนี้
เมื่อข้อมูลที่เป็นความจริงคือคลาสที่เป็นบวก โมเดลระบุการคาดการณ์เป็นคลาสที่เป็นบวกได้อย่างถูกต้องกี่เปอร์เซ็นต์
สูตรมีดังนี้
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
where:
- ผลบวกจริงหมายความว่าโมเดลคาดการณ์คลาสที่เป็นบวกได้ถูกต้อง
- ผลลบลวงหมายความว่าโมเดลคาดการณ์ผิดพลาดว่า คลาสเชิงลบ
เช่น สมมติว่าโมเดลของคุณทำการคาดการณ์ 200 รายการในตัวอย่างที่ความจริงพื้นฐานเป็นคลาสเชิงบวก โดยในการคาดการณ์ 200 รายการนี้
- 180 รายการเป็นผลบวกจริง
- 20 รายการเป็นผลลบลวง
ในกรณีนี้
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
ดูข้อมูลเพิ่มเติมได้ที่การจัดประเภท: ความแม่นยำ การเรียกคืน ความแม่น และเมตริกที่เกี่ยวข้อง
การเรียกคืนที่ k (recall@k)
เมตริกสำหรับประเมินระบบที่แสดงรายการสินค้าที่จัดอันดับ (เรียงลำดับ) การเรียกคืนที่ k จะระบุเศษส่วนของสินค้าที่เกี่ยวข้องในสินค้า k รายการแรก ในรายการนั้นจากจำนวนสินค้าที่เกี่ยวข้องทั้งหมดที่แสดง
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
เปรียบเทียบกับความแม่นยำที่ k
การจดจำความสัมพันธ์โดยนัยของข้อความ (RTE)
ชุดข้อมูลสําหรับประเมินความสามารถของ LLM ในการพิจารณาว่าสมมติฐาน สามารถสรุป (ดึงออกมาอย่างมีเหตุผล) จากข้อความได้หรือไม่ ตัวอย่างแต่ละรายการในการประเมิน RTE ประกอบด้วย 3 ส่วน ดังนี้
- ข้อความ โดยปกติมาจากบทความข่าวหรือบทความใน Wikipedia
- สมมติฐาน
- คำตอบที่ถูกต้องซึ่งเป็นอย่างใดอย่างหนึ่งต่อไปนี้
- จริง หมายความว่าสามารถสรุปสมมติฐานได้จากข้อความ
- เท็จ หมายความว่าสมมติฐานไม่ได้มาจากข้อความ
เช่น
- ข้อความ: ยูโรเป็นสกุลเงินของสหภาพยุโรป
- สมมติฐาน: ฝรั่งเศสใช้สกุลเงินยูโร
- การอนุมาน: จริง เพราะฝรั่งเศสเป็นส่วนหนึ่งของสหภาพยุโรป
RTE เป็นองค์ประกอบของกลุ่ม SuperGLUE
ReCoRD
คำย่อของ ชุดข้อมูลการอ่านทำความเข้าใจด้วยการให้เหตุผลแบบสามัญสำนึก
กราฟ ROC (Receiver Operating Characteristic)
กราฟของอัตราผลบวกจริงเทียบกับ อัตราผลบวกลวงสำหรับเกณฑ์การจัดประเภทต่างๆ ในการจัดประเภทแบบไบนารี
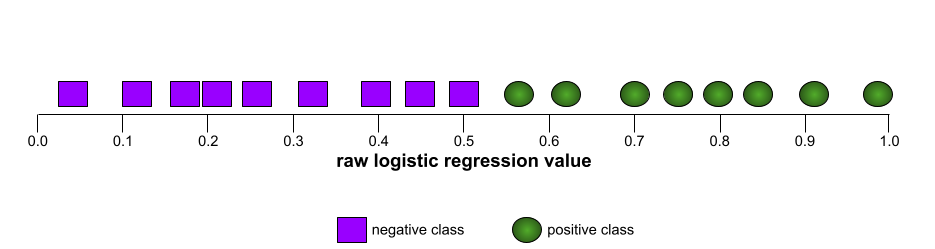
รูปร่างของเส้นโค้ง ROC แสดงให้เห็นความสามารถของโมเดลการจัดประเภทแบบไบนารี ในการแยกคลาสที่เป็นบวกออกจากคลาสที่เป็นลบ สมมติว่าโมเดลการจัดประเภทแบบไบนารีแยกคลาสเชิงลบทั้งหมดออกจากคลาสเชิงบวกทั้งหมดได้อย่างสมบูรณ์ ดังนี้
เส้นโค้ง ROC สำหรับโมเดลก่อนหน้ามีลักษณะดังนี้
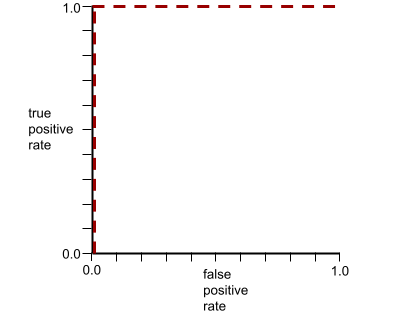
ในทางตรงกันข้าม ภาพประกอบต่อไปนี้แสดงกราฟค่าการถดถอยแบบโลจิสติกแบบดิบ สำหรับโมเดลที่แย่ซึ่งแยกคลาสเชิงลบออกจาก คลาสเชิงบวกไม่ได้เลย
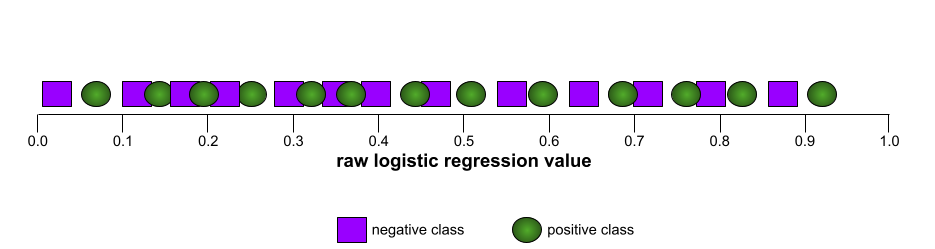
กราฟ ROC สำหรับโมเดลนี้มีลักษณะดังนี้
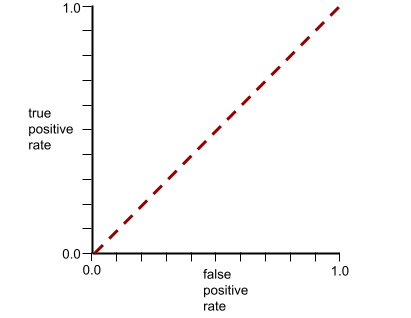
ในขณะเดียวกัน ในโลกแห่งความเป็นจริง โมเดลการจัดประเภทแบบไบนารีส่วนใหญ่จะแยก คลาสที่เป็นบวกและลบในระดับหนึ่ง แต่โดยปกติแล้วจะไม่สมบูรณ์แบบ ดังนั้น กราฟ ROC ทั่วไปจะอยู่ระหว่าง 2 สุดขั้วนี้
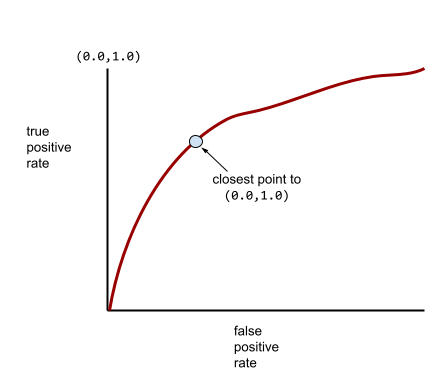
จุดบนเส้นโค้ง ROC ที่ใกล้กับ (0.0,1.0) มากที่สุดจะระบุเกณฑ์การจัดประเภทที่เหมาะสมในทางทฤษฎี อย่างไรก็ตาม ปัญหาอื่นๆ ในโลกแห่งความเป็นจริง มีผลต่อการเลือกเกณฑ์การจัดประเภทที่เหมาะสม ตัวอย่างเช่น ผลลบเท็จอาจสร้างความเจ็บปวดมากกว่าผลบวกเท็จ
เมตริกเชิงตัวเลขที่เรียกว่า AUC จะสรุปเส้นโค้ง ROC เป็นค่าจุดลอยตัวค่าเดียว
สแควรูทของความคลาดเคลื่อนกำลังสองเฉลี่ย (RMSE)
รากที่ 2 ของความคลาดเคลื่อนเฉลี่ยกำลังสอง
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
กลุ่มเมตริกที่ประเมินโมเดลการสรุปอัตโนมัติและการแปลด้วยคอมพิวเตอร์ เมตริก ROUGE จะกำหนดระดับที่ข้อความอ้างอิงซ้อนทับกับข้อความที่สร้างขึ้นของโมเดล ML สมาชิกแต่ละคนในตระกูล ROUGE จะวัดการทับซ้อนกันในวิธีที่แตกต่างกัน คะแนน ROUGE ที่สูงขึ้นบ่งบอกถึง ความคล้ายกันระหว่างข้อความอ้างอิงกับข้อความที่สร้างขึ้นมากกว่าคะแนน ROUGE ที่ต่ำกว่า
โดยปกติแล้ว สมาชิกแต่ละคนในตระกูล ROUGE จะสร้างเมตริกต่อไปนี้
- ความแม่นยำ
- การจดจำ
- F1
ดูรายละเอียดและตัวอย่างได้ที่
ROUGE-L
สมาชิกในตระกูล ROUGE มุ่งเน้นที่ความยาวของลำดับย่อยร่วมกันที่ยาวที่สุด ในข้อความอ้างอิงและข้อความที่สร้างขึ้น สูตรต่อไปนี้ใช้ในการคำนวณการเรียกคืนและความแม่นยำสำหรับ ROUGE-L
จากนั้นคุณจะใช้ F1 เพื่อสรุปการเรียกคืน ROUGE-L และความแม่นยำของ ROUGE-L เป็นเมตริกเดียวได้
ROUGE-L จะไม่สนใจบรรทัดใหม่ในข้อความอ้างอิงและข้อความที่สร้างขึ้น ดังนั้น ลำดับย่อยร่วมที่ยาวที่สุดจึงอาจข้ามหลายประโยคได้ เมื่อข้อความอ้างอิงและข้อความที่สร้างขึ้นมีหลายประโยค โดยทั่วไปแล้ว ROUGE-L รูปแบบหนึ่งที่เรียกว่า ROUGE-Lsum จะเป็นเมตริกที่ดีกว่า ROUGE-Lsum จะกำหนดลำดับย่อยร่วมที่ยาวที่สุดสำหรับประโยค แต่ละประโยคในข้อความ จากนั้นจะคำนวณค่าเฉลี่ยของลำดับย่อยร่วมที่ยาวที่สุดเหล่านั้น
ROUGE-N
ชุดเมตริกภายในตระกูล ROUGE ที่เปรียบเทียบ N-gram ที่แชร์ซึ่งมีขนาดหนึ่งๆ ในข้อความอ้างอิง และข้อความที่สร้างขึ้น เช่น
- ROUGE-1 จะวัดจำนวนโทเค็นที่ใช้ร่วมกันในข้อความอ้างอิงและ ข้อความที่สร้างขึ้น
- ROUGE-2 จะวัดจำนวน bigram (2-gram) ที่ใช้ร่วมกัน ในข้อความอ้างอิงและข้อความที่สร้างขึ้น
- ROUGE-3 จะวัดจำนวน trigram (3-gram) ที่ใช้ร่วมกัน ในข้อความอ้างอิงและข้อความที่สร้างขึ้น
คุณใช้สูตรต่อไปนี้เพื่อคํานวณการเรียกคืน ROUGE-N และความแม่นยําของ ROUGE-N สําหรับสมาชิกใดก็ได้ในตระกูล ROUGE-N
จากนั้นคุณจะใช้ F1 เพื่อสรุปการเรียกคืน ROUGE-N และความแม่นยำ ROUGE-N เป็นเมตริกเดียวได้โดยทำดังนี้
ROUGE-S
รูปแบบที่ยืดหยุ่นของ ROUGE-N ที่ช่วยให้การจับคู่ skip-gram กล่าวคือ ROUGE-N จะนับเฉพาะ N-gram ที่ตรงกันทุกประการ แต่ ROUGE-S จะนับ N-gram ที่คั่นด้วยคำอย่างน้อย 1 คำด้วย เช่น โปรดคำนึงถึงสิ่งต่อไปนี้
- ข้อความอ้างอิง: เมฆสีขาว
- ข้อความที่สร้างขึ้น: เมฆสีขาวที่ลอยเป็นปุย
เมื่อคำนวณ ROUGE-N ไบแกรม White clouds จะไม่ตรงกับ White billowing clouds อย่างไรก็ตาม เมื่อคำนวณ ROUGE-S White clouds จะตรงกับ White billowing clouds
R-squared
เมตริกการถดถอยที่ระบุความผันแปรของป้ายกำกับที่เกิดจากฟีเจอร์แต่ละรายการหรือชุดฟีเจอร์ R-squared คือค่าระหว่าง 0 ถึง 1 ซึ่งคุณสามารถตีความได้ดังนี้
- ค่า R-squared ที่ 0 หมายความว่าความแปรปรวนของค่ายเพลงไม่ได้เกิดจากชุดฟีเจอร์
- ค่า R-squared ที่ 1 หมายความว่าความแปรปรวนทั้งหมดของป้ายกำกับเกิดจาก ชุดฟีเจอร์
- ค่า R-squared ระหว่าง 0 ถึง 1 แสดงให้เห็นถึงขอบเขตที่สามารถคาดการณ์ความแปรปรวนของป้ายกำกับได้จากฟีเจอร์หรือชุดฟีเจอร์หนึ่งๆ เช่น ค่า R ยกกำลังสองที่ 0.10 หมายความว่าความแปรปรวน 10% ในป้ายกำกับเกิดจากชุดฟีเจอร์ ค่า R ยกกำลังสองที่ 0.20 หมายความว่า 20% เกิดจากชุดฟีเจอร์ และอื่นๆ
ค่า R ยกกำลังสองคือค่ากำลังสองของสัมประสิทธิ์สหสัมพันธ์ของ Pearson ระหว่างค่าที่โมเดลคาดการณ์ไว้กับข้อมูลที่เป็นความจริง
RTE
ตัวย่อของ Recognizing Textual Entailment
S
การให้คะแนน
ส่วนของระบบการแนะนำที่ ให้ค่าหรือการจัดอันดับสำหรับแต่ละรายการที่สร้างขึ้นใน ระยะการสร้างแคนดิเดต
การวัดความคล้ายคลึง
ในอัลกอริทึมการจัดกลุ่ม เมตริกที่ใช้ในการพิจารณา ความเหมือน (ความคล้ายคลึง) ของตัวอย่าง 2 รายการ
การขาดแคลนข้อมูล
จำนวนองค์ประกอบที่ตั้งค่าเป็น 0 (หรือ Null) ในเวกเตอร์หรือเมทริกซ์หารด้วยจำนวนรายการทั้งหมดในเวกเตอร์หรือเมทริกซ์นั้น ตัวอย่างเช่น ลองพิจารณาเมทริกซ์ที่มี 100 องค์ประกอบซึ่งมีเซลล์ 98 เซลล์ที่มีค่าเป็น 0 การคำนวณความกระจัดกระจาย มีดังนี้
ความกระจัดกระจายของฟีเจอร์หมายถึงความกระจัดกระจายของเวกเตอร์ฟีเจอร์ ความกระจัดกระจายของโมเดลหมายถึงความกระจัดกระจายของน้ำหนักโมเดล
SQuAD
คำย่อของ Stanford Question Answering Dataset ซึ่งเปิดตัวในเอกสาร SQuAD: 100,000+ Questions for Machine Comprehension of Text คำถามในชุดข้อมูลนี้มาจากผู้ที่ถามคำถามเกี่ยวกับบทความใน วิกิพีเดีย คำถามบางข้อใน SQuAD มีคำตอบ แต่คำถามอื่นๆ ไม่มีคำตอบโดยตั้งใจ ดังนั้น คุณจึงใช้ SQuAD เพื่อประเมินความสามารถของ LLM ในการทำสิ่งต่อไปนี้ได้
- ตอบคำถามที่ตอบได้
- ระบุคำถามที่ตอบไม่ได้
การทำงานแบบตรงทั้งหมดร่วมกับ F1 เป็นเมตริกที่ใช้กันมากที่สุดในการ ประเมิน LLM กับ SQuAD
การสูญเสียบานพับกำลังสอง
กำลังสองของการสูญเสียแบบบานพับ การสูญเสียฮิงก์กำลังสองจะลงโทษ ค่าผิดปกติอย่างรุนแรงกว่าการสูญเสียฮิงก์ปกติ
การสูญเสียกำลังสอง
คำพ้องความหมายของL2 loss
SuperGLUE
ชุดข้อมูลสำหรับการให้คะแนนความสามารถโดยรวมของ LLM ในการทำความเข้าใจ และสร้างข้อความ กลุ่มประกอบด้วยชุดข้อมูลต่อไปนี้
- คำถามแบบบูลีน (BoolQ)
- CommitmentBank (CB)
- ทางเลือกของทางเลือกที่เป็นไปได้ (COPA)
- การอ่านจับใจความแบบหลายประโยค (MultiRC)
- ชุดข้อมูลการอ่านเพื่อความเข้าใจด้วยการใช้สามัญสำนึก (ReCoRD)
- Recognizing Textual Entailment (RTE)
- คำในบริบท (WiC)
- Winograd Schema Challenge (WSC)
ดูรายละเอียดได้ที่ SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
T
การสูญเสียการทดสอบ
เมตริกที่แสดงถึง Loss ของโมเดลเทียบกับ ชุดทดสอบ เมื่อสร้างโมเดล คุณ มักจะพยายามลดการสูญเสียในการทดสอบ เนื่องจากค่าการสูญเสียในการทดสอบที่ต่ำเป็นสัญญาณคุณภาพที่แข็งแกร่งกว่าค่าการสูญเสียในการฝึกที่ต่ำหรือค่าการสูญเสียในการตรวจสอบที่ต่ำ
ช่องว่างขนาดใหญ่ระหว่างการสูญเสียในการทดสอบกับการสูญเสียในการฝึกหรือการสูญเสียในการตรวจสอบบางครั้งบ่งบอกว่าคุณต้องเพิ่มอัตรา Regularization
ความแม่นยำสูงสุด k
เปอร์เซ็นต์ของจำนวนครั้งที่ "ป้ายกำกับเป้าหมาย" ปรากฏภายในk ตำแหน่งแรกของรายการที่สร้างขึ้น รายการอาจเป็นคำแนะนำที่ปรับเปลี่ยนในแบบของคุณ หรือรายการสินค้าที่จัดเรียงตาม softmax
ความแม่นยำสูงสุด k เรียกอีกอย่างว่าความแม่นยำที่ k
ความเชื่อผิดๆ
ระดับของเนื้อหาที่เป็นการละเมิด ข่มขู่ หรือไม่เหมาะสม โมเดลแมชชีนเลิร์นนิงจำนวนมากสามารถระบุ วัดผล และจัดประเภทความเป็นพิษได้ โมเดลส่วนใหญ่เหล่านี้ จะระบุความเป็นพิษตามพารามิเตอร์หลายอย่าง เช่น ระดับของ ภาษาที่ละเมิดและระดับของภาษาที่คุกคาม
การลดลงของการฝึก
เมตริกที่แสดงการสูญเสียของโมเดลระหว่างการฝึก ในรอบการฝึกที่เฉพาะเจาะจง เช่น สมมติว่าฟังก์ชันการสูญเสีย คือความคลาดเคลื่อนกำลังสองเฉลี่ย เช่น การสูญเสียการฝึก (ข้อผิดพลาดกำลังสองเฉลี่ย) สำหรับการทำซ้ำครั้งที่ 10 คือ 2.2 และการสูญเสียการฝึกสำหรับการทำซ้ำครั้งที่ 100 คือ 1.9
เส้นโค้งการสูญเสียจะพล็อตการสูญเสียการฝึกเทียบกับจำนวน การทำซ้ำ เส้นโค้งการสูญเสียจะให้คำแนะนำต่อไปนี้เกี่ยวกับการฝึก
- ความชันลงแสดงว่าโมเดลดีขึ้น
- ความชันที่เพิ่มขึ้นหมายความว่าโมเดลแย่ลง
- ความชันที่แบนราบแสดงว่าโมเดลถึงการบรรจบกันแล้ว
ตัวอย่างเช่น เส้นโค้งการสูญเสียต่อไปนี้ซึ่งค่อนข้างสมบูรณ์ แสดงให้เห็นว่า
- ความชันที่ลดลงอย่างรวดเร็วในระหว่างการทำซ้ำครั้งแรก ซึ่งหมายถึงการปรับปรุงโมเดลอย่างรวดเร็ว
- ความชันที่ค่อยๆ แบนราบ (แต่ยังคงลดลง) จนกระทั่งใกล้สิ้นสุด การฝึก ซึ่งหมายถึงการปรับปรุงโมเดลอย่างต่อเนื่องในอัตราที่ช้าลงเล็กน้อย กว่าในช่วงการทำซ้ำครั้งแรก
- ความชันที่ราบเรียบในช่วงท้ายของการฝึก ซึ่งบ่งบอกถึงการบรรจบกัน
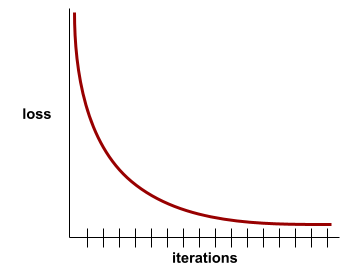
แม้ว่าการสูญเสียจากการฝึกจะมีความสําคัญ แต่โปรดดูการวางนัยทั่วไปด้วย
การตอบคำถามแบบทดสอบความรู้
ชุดข้อมูลเพื่อประเมินความสามารถของ LLM ในการตอบคำถามเรื่องไม่สำคัญ ชุดข้อมูลแต่ละชุดมีคู่คำถาม-คำตอบที่สร้างขึ้นโดยผู้ที่ชื่นชอบเรื่องไม่สำคัญ ชุดข้อมูลต่างๆ อิงตามแหล่งที่มาที่แตกต่างกัน ซึ่งรวมถึงแหล่งที่มาต่อไปนี้
- การค้นหาเว็บ (TriviaQA)
- Wikipedia (TriviaQA_wiki)
ดูข้อมูลเพิ่มเติมได้ที่ TriviaQA: ชุดข้อมูลความท้าทายขนาดใหญ่ที่มีการกำกับดูแลจากระยะไกลสำหรับการอ่านเพื่อความเข้าใจ
ผลลบจริง (TN)
ตัวอย่างที่โมเดลคาดการณ์อย่างถูกต้อง คลาสเชิงลบ ตัวอย่างเช่น โมเดลอนุมานว่า ข้อความอีเมลหนึ่งไม่ใช่จดหมายขยะ และข้อความอีเมลนั้นไม่ใช่จดหมายขยะจริงๆ
ผลบวกจริง (TP)
ตัวอย่างที่โมเดลคาดการณ์อย่างถูกต้องว่า คลาสที่เป็นบวก เช่น โมเดลอนุมานว่า ข้อความอีเมลหนึ่งๆ เป็นจดหมายขยะ และข้อความอีเมลนั้นเป็นจดหมายขยะจริงๆ
อัตราผลบวกจริง (TPR)
คำพ้องความหมายของการเรียกคืน โดยการ
อัตราผลบวกจริงคือแกน y ในกราฟ ROC
การตอบคำถามที่หลากหลายตามประเภท (TyDi QA)
ชุดข้อมูลขนาดใหญ่สำหรับการประเมินความสามารถของ LLM ในการตอบคำถาม ชุดข้อมูลประกอบด้วยคู่คำถามและคำตอบในหลายภาษา
ดูรายละเอียดได้ที่ TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages
U
อัตราการอ้างสิทธิ์ที่ไม่ถูกต้อง (UCR)
เปอร์เซ็นต์ของการกล่าวอ้างในคำตอบที่ไม่ได้อ้างอิง ตัวอย่างเช่น หากคำตอบของ LLM มีการกล่าวอ้าง 10 รายการ แต่มีเพียง 1 รายการที่อิงตามข้อมูล UCR จะเท่ากับ 90%
UCR สูงหมายความว่า LLM หลอนบ่อยเกินไป
ดูเพิ่มเติมที่ความแม่นยำของการอ้างอิงและ การเรียกคืนการอ้างอิง
V
การสูญเสียการตรวจสอบ
เมตริกที่แสดงการสูญเสียของโมเดลในชุดข้อมูลสำหรับตรวจสอบความถูกต้องระหว่างการทำซ้ำของการฝึก
ดูเส้นโค้งการสรุปด้วย
ความสําคัญของตัวแปร
ชุดคะแนนที่บ่งบอกถึงความสำคัญที่สัมพันธ์กันของแต่ละฟีเจอร์ต่อโมเดล
ตัวอย่างเช่น ลองพิจารณาแผนผังการตัดสินใจที่ ประมาณราคาบ้าน สมมติว่าแผนผังการตัดสินใจนี้ใช้ฟีเจอร์ 3 อย่าง ได้แก่ ขนาด อายุ และสไตล์ หากระบบคำนวณชุดความสําคัญของตัวแปร สําหรับฟีเจอร์ทั้ง 3 รายการได้เป็น {size=5.8, age=2.5, style=4.7} แสดงว่าขนาดมีความสําคัญต่อ Decision Tree มากกว่าอายุหรือสไตล์
มีเมตริกความสําคัญของตัวแปรที่แตกต่างกัน ซึ่งจะช่วยให้ผู้เชี่ยวชาญด้าน ML ทราบถึงแง่มุมต่างๆ ของโมเดล
W
การสูญเสีย Wasserstein
ฟังก์ชันการสูญเสียอย่างหนึ่งที่ใช้กันโดยทั่วไปในGenerative Adversarial Network โดยอิงตามระยะทางของ Earth Mover ระหว่างการกระจายข้อมูลที่สร้างขึ้นและข้อมูลจริง
WiC
ตัวย่อของคำในบริบท
WikiLingua (wiki_lingua)
ชุดข้อมูลสำหรับประเมินความสามารถของ LLM ในการสรุปบทความสั้นๆ WikiHow ซึ่งเป็นสารานุกรมบทความที่อธิบาย วิธีทำงานต่างๆ เป็นแหล่งข้อมูลที่มนุษย์เขียนขึ้นสำหรับทั้งบทความ และข้อมูลสรุป แต่ละรายการในชุดข้อมูลประกอบด้วย
- บทความที่สร้างขึ้นโดยการต่อท้ายแต่ละขั้นตอนของเวอร์ชันร้อยแก้ว (ย่อหน้า) ของรายการที่เรียงลำดับเลข โดยลบประโยคเปิดของแต่ละขั้นตอนออก
- สรุปบทความนั้นซึ่งประกอบด้วยประโยคเปิด ของแต่ละขั้นตอนในรายการที่เรียงลำดับเลข
โปรดดูรายละเอียดที่ WikiLingua: ชุดข้อมูลการเปรียบเทียบใหม่สำหรับการสรุปแบบดึงข้อมูลข้ามภาษา
การแข่งขัน Winograd Schema Challenge (WSC)
รูปแบบ (หรือชุดข้อมูลที่เป็นไปตามรูปแบบนั้น) สำหรับประเมินความสามารถของ LLM ในการระบุกลุ่มคำนามที่คำสรรพนาม อ้างถึง
แต่ละรายการใน Winograd Schema Challenge ประกอบด้วย
- บทอ่านสั้นๆ ที่มีคำสรรพนามเป้าหมาย
- คำสรรพนามเป้าหมาย
- กลุ่มคำนามที่เป็นตัวเลือก ตามด้วยคำตอบที่ถูกต้อง (บูลีน) หากคำสรรพนามเป้าหมายอ้างอิงถึงผู้สมัครคนนี้ คำตอบจะเป็น "จริง" หากคำสรรพนามเป้าหมายไม่ได้อ้างอิงถึงผู้สมัครคนนี้ คำตอบจะเป็น False
เช่น
- ข้อความ: มาร์คโกหกพีทหลายเรื่องเกี่ยวกับตัวเขาเอง ซึ่งพีทได้ใส่ไว้ใน หนังสือของเขา เขาควรจะพูดความจริงมากกว่านี้
- คำสรรพนามเป้าหมาย: เขา
- กลุ่มคำนามที่แนะนำ
- มาร์ค: จริง เพราะคำสรรพนามเป้าหมายหมายถึงมาร์ค
- พีท: ไม่จริง เพราะคำสรรพนามเป้าหมายไม่ได้อ้างอิงถึงพีท
การแข่งขัน Winograd Schema เป็นส่วนหนึ่งของกลุ่ม SuperGLUE
คำในบริบท (WiC)
ชุดข้อมูลสำหรับประเมินว่า LLM ใช้บริบทได้ดีเพียงใดในการทำความเข้าใจคำที่มีหลายความหมาย แต่ละรายการในชุดข้อมูลประกอบด้วยข้อมูลต่อไปนี้
- 2 ประโยคที่มีคำเป้าหมาย
- คำเป้าหมาย
- คำตอบที่ถูกต้อง (บูลีน) โดยมีรายละเอียดดังนี้
- True หมายความว่าคำเป้าหมายมีความหมายเหมือนกันใน 2 ประโยค
- False หมายความว่าคำเป้าหมายมีความหมายแตกต่างกันใน 2 ประโยค
เช่น
- 2 ประโยค:
- มีขยะจำนวนมากอยู่ก้นแม่น้ำ
- ฉันวางแก้วน้ำไว้ข้างเตียงตอนนอน
- คำเป้าหมาย: bed
- คำตอบที่ถูกต้อง: เท็จ เนื่องจากคำเป้าหมายมีความหมายต่างกันใน ประโยคทั้ง 2 ประโยค
ดูรายละเอียดได้ที่ WiC: ชุดข้อมูล Word-in-Context สำหรับการประเมินการแสดงความหมายที่คำนึงถึงบริบท
Words in Context เป็นองค์ประกอบของกลุ่ม SuperGLUE
WSC
ตัวย่อของ Winograd Schema Challenge
X
XL-Sum (xlsum)
ชุดข้อมูลสำหรับประเมินความสามารถของ LLM ในการสรุปข้อความ XL-Sum มีรายการในหลายภาษา แต่ละรายการในชุดข้อมูลประกอบด้วยข้อมูลต่อไปนี้
- บทความจาก British Broadcasting Company (BBC)
- สรุปบทความที่เขียนโดยผู้เขียนบทความ โปรดทราบว่า สรุปดังกล่าวอาจมีคำหรือวลีที่ไม่มีในบทความ
ดูรายละเอียดได้ที่ XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages