Halaman ini berisi istilah glosarium Evaluasi Bahasa. Untuk semua istilah glosarium, klik di sini.
J
Attention,
Mekanisme yang digunakan dalam jaringan neural yang menunjukkan pentingnya kata atau bagian tertentu dari sebuah kata. Attention mengompresi jumlah informasi yang diperlukan model untuk memprediksi token/kata berikutnya. Mekanisme atensi umum mungkin terdiri dari jumlah berbobot pada sekumpulan input dengan bobot untuk setiap input dihitung oleh bagian lain dari jaringan neural.
Lihat juga self-attention dan multi-head self-attention, yang merupakan elemen penyusun Transformer.
autoencoder
Sistem yang mempelajari cara mengekstrak informasi yang paling penting dari input. Autoencoder adalah kombinasi dari encoder dan decoder. Autoencoder mengandalkan proses dua langkah berikut:
- Encoder memetakan input ke format dimensi rendah (biasanya) lossy (biasanya) lossy (sedang).
- Decoder membuat versi lossy dari input asli dengan memetakan format dimensi rendah ke format input asli yang berdimensi lebih tinggi.
Autoencoder dilatih secara menyeluruh dengan meminta decoder mencoba merekonstruksi input asli dari format perantara encoder sedekat mungkin. Karena format perantara lebih kecil (dimensi lebih rendah) daripada format aslinya, autoencoder terpaksa mempelajari informasi apa yang penting dalam input, dan output tidak akan sama persis dengan input.
Contoh:
- Jika data input berupa grafis, salinan yang tidak tepat akan serupa dengan grafik asli, tetapi sedikit dimodifikasi. Mungkin teks yang tidak tepat menghilangkan derau dari grafis asli atau mengisi beberapa piksel yang hilang.
- Jika data input berupa teks, autoencoder akan membuat teks baru yang meniru (tetapi tidak identik) dengan teks asli.
Lihat juga autoencoder bervariasi.
model auto-regresif
model yang menyimpulkan prediksi berdasarkan prediksinya sendiri sebelumnya. Misalnya, model bahasa auto-regresif memprediksi token berikutnya berdasarkan token yang diprediksi sebelumnya. Semua model bahasa besar berbasis Transformer bersifat auto-regresif.
Sebaliknya, model gambar berbasis GAN biasanya tidak regresi otomatis karena menghasilkan gambar dalam satu penerusan maju dan tidak secara berulang dalam langkah. Namun, model pembuatan gambar tertentu bersifat autoregresif karena model tersebut menghasilkan gambar secara bertahap.
B
kantong data
Representasi kata-kata dalam frasa atau teks, terlepas dari urutannya. Misalnya, kumpulan kata-kata mewakili tiga frasa berikut secara identik:
- anjingnya melompat
- anjingnya melompat
- {i>dog jumping<i}
Setiap kata dipetakan ke indeks dalam vektor renggang, dengan vektor memiliki indeks untuk setiap kata dalam kosakata. Misalnya, frasa the dog jumps dipetakan ke dalam vektor fitur dengan nilai bukan nol pada tiga indeks yang sesuai dengan kata the, dog, dan jumps. Nilai bukan nol dapat berupa salah satu dari hal berikut:
- A 1 untuk menunjukkan adanya sebuah kata.
- Hitungan berapa kali kata muncul dalam tas. Misalnya, jika frasanya adalah merah marun adalah berbulu merah marun, maka marun dan akan direpresentasikan sebagai 2, sementara kata lainnya akan direpresentasikan sebagai 1.
- Beberapa nilai lainnya, seperti logaritma jumlah berapa kali kata muncul dalam tas.
BERT (Representasi Encoder Dua Arah dari Transformer)
Arsitektur model untuk representasi teks. Model BERT terlatih dapat bertindak sebagai bagian dari model yang lebih besar untuk klasifikasi teks atau tugas ML lainnya.
BERT memiliki karakteristik berikut:
- Menggunakan arsitektur Transformer, sehingga mengandalkan self-attention.
- Menggunakan bagian encoder dari Transformer. Tugas encoder adalah menghasilkan representasi teks yang baik, bukan melakukan tugas tertentu seperti klasifikasi.
- Bersifat dua arah.
- Menggunakan masking untuk pelatihan unsupervised.
Varian BERT meliputi:
Lihat Open Sourcing BERT: Pra-pelatihan Tercanggih untuk Natural Language Processing untuk mengetahui ringkasan BERT.
dua arah
Istilah yang digunakan untuk mendeskripsikan sistem yang mengevaluasi teks yang mendahului dan mengikuti bagian target teks. Sebaliknya, sistem searah hanya mengevaluasi teks yang mendahului bagian teks target.
Misalnya, pertimbangkan model bahasa yang disamarkan yang harus menentukan probabilitas kata atau kata-kata yang mewakili garis bawah dalam pertanyaan berikut:
Apa _____ dengan Anda?
Model bahasa searah harus mendasarkan probabilitasnya hanya pada konteks yang disediakan oleh kata "Apa", "adalah", dan "the". Sebaliknya, model bahasa dua arah juga bisa mendapatkan konteks dari "dengan" dan "Anda", yang mungkin membantu model tersebut menghasilkan prediksi yang lebih baik.
model bahasa dua arah
Model bahasa yang menentukan probabilitas bahwa token tertentu ada di lokasi tertentu dalam kutipan teks berdasarkan teks sebelumnya dan berikut.
Bigram
N-gram yang mana N=2.
BLEU (Studi Evaluasi Bilingual)
Skor antara 0,0 dan 1,0, inklusif, yang menunjukkan kualitas terjemahan antara dua bahasa manusia (misalnya, antara Inggris dan Rusia). Skor BLEU 1,0 menunjukkan terjemahan yang sempurna; skor BLEU 0,0 menunjukkan terjemahan yang buruk.
C
model bahasa kausal
Sinonim dari model bahasa searah.
Lihat model bahasa dua arah untuk mengontraskan pendekatan terarah yang berbeda dalam pemodelan bahasa.
prompting chain-of-thought
Teknik rekayasa perintah yang mendorong model bahasa besar (LLM) untuk menjelaskan alasannya, langkah demi langkah. Misalnya, perhatikan perintah berikut, dengan memberi perhatian khusus pada kalimat kedua:
Berapa banyak gaya g yang dialami pengemudi dalam mobil yang melaju dari 0 hingga 60 mil per jam dalam 7 detik? Pada jawaban, tampilkan semua penghitungan yang relevan.
Respons LLM kemungkinan akan:
- Tampilkan urutan rumus fisika, dengan memasukkan nilai 0, 60, dan 7 di tempat yang sesuai.
- Jelaskan mengapa ia memilih formula-formula tersebut dan apa arti berbagai variabel tersebut.
Permintaan rantai pemikiran memaksa LLM untuk melakukan semua penghitungan, yang dapat menghasilkan jawaban yang lebih benar. Selain itu, prompting chain-of-pemikiran memungkinkan pengguna memeriksa langkah-langkah LLM untuk menentukan apakah jawabannya masuk akal atau tidak.
chat
Isi dialog dua arah dengan sistem ML, biasanya model bahasa besar. Interaksi sebelumnya dalam chat (apa yang Anda ketik dan respons model bahasa besar) menjadi konteks untuk bagian chat berikutnya.
chatbot adalah penerapan model bahasa besar.
konfabulasi
Sinonim dari halusinasi.
Konfabulasi mungkin merupakan istilah yang lebih akurat secara teknis daripada halusinasi. Namun, halusinasi menjadi populer terlebih dahulu.
penguraian konstituen
Membagi kalimat menjadi struktur gramatikal yang lebih kecil ("konstituen"). Bagian selanjutnya dari sistem ML, seperti model natural language understanding, dapat mengurai konstituen dengan lebih mudah daripada kalimat aslinya. Misalnya, perhatikan kalimat berikut:
Teman saya mengadopsi dua kucing.
Parser konstituensi dapat membagi kalimat ini menjadi dua konstituen berikut:
- Teman saya adalah frasa kata benda.
- adopted two cats adalah frasa kata kerja.
Konstituen ini dapat dibagi lagi menjadi konstituen yang lebih kecil. Misalnya, frasa kata kerja
mengadopsi dua kucing
dapat dibagi lagi menjadi:
- adopted adalah kata kerja.
- two cats (dua kucing) adalah frasa kata benda lainnya.
embedding bahasa yang kontekstual
Penyematan yang mendekati cara "memahami" kata-kata dan frasa dengan cara yang dapat dilakukan oleh penutur asli manusia. Penyematan bahasa yang kontekstual dapat memahami sintaksis, semantik, dan konteks yang kompleks.
Misalnya, pertimbangkan embedding dari kata bahasa Inggris cow. Embedding lama seperti word2vec dapat merepresentasikan kata bahasa Inggris sehingga jarak dalam ruang penyematan dari sapi ke bull mirip dengan jarak dari sapi betina (domba betina) ke ram (domba jantan) atau dari perempuan ke jantan. Penyematan bahasa yang kontekstual dapat berkembang lebih jauh dengan mengenali bahwa penutur bahasa Inggris terkadang menggunakan kata cow untuk berarti sapi atau banteng.
jendela konteks
Jumlah token yang dapat diproses oleh model pada perintah tertentu. Makin besar jendela konteks, makin banyak informasi yang dapat digunakan model untuk memberikan respons yang koheren dan konsisten terhadap prompt.
frasa ambigu
Kalimat atau frasa dengan makna ambigu. Frasa ambigu menghadirkan masalah yang signifikan dalam natural language understanding. Misalnya, judul Red Tape Holds Up Skyscraper adalah frasa ambigu karena model NLU dapat menafsirkan judul secara harfiah atau figuratif.
D
decoder
Secara umum, semua sistem ML yang melakukan konversi dari representasi yang diproses, padat, atau internal menjadi representasi yang lebih mentah, renggang, atau eksternal.
Decoder sering kali merupakan komponen dari model yang lebih besar, yang sering dipasangkan dengan encoder.
Pada tugas urutan ke urutan, decoder dimulai dengan status internal yang dihasilkan oleh encoder untuk memprediksi urutan berikutnya.
Lihat Transformer untuk mengetahui definisi decoder dalam arsitektur Transformer.
mengurangi derau
Pendekatan umum untuk pembelajaran mandiri yang:
Pengurangan noise memungkinkan pembelajaran dari contoh tak berlabel. Set data asli berfungsi sebagai target atau label dan data derau sebagai input.
Beberapa model bahasa yang disamarkan menggunakan peredam bising sebagai berikut:
- Derau ditambahkan secara artifisial ke kalimat tanpa label dengan menyamarkan beberapa token.
- Model ini mencoba memprediksi token awal.
prompting langsung
Sinonim untuk zero-shot prompting.
E
edit jarak
Pengukuran tentang kemiripan dua {i>string<i} teks satu sama lain. Dalam machine learning, edit jarak berguna karena mudah untuk dihitung, serta cara yang efektif untuk membandingkan dua string yang diketahui mirip atau untuk menemukan string yang mirip dengan string tertentu.
Ada beberapa definisi untuk jarak edit, masing-masing menggunakan operasi string yang berbeda. Misalnya, Jarak Levenshtein mempertimbangkan operasi hapus, penyisipan, dan pengganti yang paling sedikit.
Misalnya, jarak Levenshtein antara kata "hati" dan "anak panah" adalah 3 karena 3 pengeditan berikut adalah perubahan paling sedikit untuk mengubah satu kata menjadi kata lainnya:
- hati → deart (ganti "h" dengan "d")
- deart → dart (hapus "e")
- dart → dart (insert "s")
lapisan embedding
lapisan tersembunyi khusus yang melatih fitur kategoris berdimensi tinggi untuk mempelajari vektor embedding dengan dimensi yang lebih rendah secara bertahap. Lapisan embedding memungkinkan jaringan neural untuk berlatih jauh lebih efisien daripada melatih fitur kategoris berdimensi tinggi saja.
Misalnya, Bumi saat ini mendukung sekitar 73.000 spesies pohon. Misalkan spesies pohon adalah fitur dalam model Anda, jadi lapisan input model Anda mencakup vektor one-hot dengan panjang 73.000 elemen.
Misalnya, mungkin baobab akan direpresentasikan seperti ini:

Array berisi 73.000 elemen sangat panjang. Jika lapisan embedding tidak ditambahkan ke model, pelatihan akan sangat memakan waktu karena mengalikan 72.999 angka nol. Mungkin Anda memilih lapisan embedding terdiri dari 12 dimensi. Akibatnya, lapisan embedding secara bertahap akan mempelajari vektor embedding baru untuk setiap spesies pohon.
Dalam situasi tertentu, hashing adalah alternatif yang wajar untuk lapisan embedding.
ruang sematan
Ruang vektor d dimensi yang ditampilkan dari ruang vektor berdimensi lebih tinggi akan dipetakan. Idealnya, ruang embedding berisi struktur yang menghasilkan hasil matematika yang bermakna; misalnya, dalam ruang embedding yang ideal, penjumlahan dan pengurangan embedding dapat menyelesaikan tugas analogi kata.
Produk titik dari dua embeddings adalah ukuran kesamaan dari embedding tersebut.
vektor embedding
Secara umum, array bilangan floating point yang diambil dari setiap lapisan tersembunyi yang menjelaskan input ke lapisan tersembunyi tersebut. Sering kali, vektor embedding adalah array bilangan floating point yang dilatih dalam lapisan embedding. Misalnya, lapisan embedding harus mempelajari vektor embedding untuk masing-masing dari 73.000 spesies pohon di Bumi. Mungkin array berikut adalah vektor embedding untuk pohon baobab:

Vektor embedding bukanlah sekelompok angka acak. Lapisan embedding menentukan nilai ini melalui pelatihan, mirip dengan cara jaringan neural mempelajari bobot lain selama pelatihan. Setiap elemen array merupakan rating bersama beberapa karakteristik spesies pohon. Elemen mana yang mewakili karakteristik spesies pohon mana? Sangat sulit bagi manusia untuk menentukannya.
Bagian yang luar biasa secara matematis dari vektor embedding adalah item serupa memiliki kumpulan bilangan floating point yang serupa. Misalnya, spesies pohon yang serupa memiliki kumpulan bilangan floating point yang lebih mirip daripada spesies pohon yang berbeda. Redwood dan sequoia adalah spesies pohon yang terkait, sehingga mereka akan memiliki kumpulan bilangan floating yang lebih mirip daripada kayu redwood dan pohon kelapa. Angka dalam vektor embedding akan berubah setiap kali Anda melatih ulang model, meskipun Anda melatih ulang model dengan input yang identik.
pembuat enkode
Secara umum, semua sistem ML yang melakukan konversi dari representasi mentah, renggang, atau eksternal menjadi representasi internal yang lebih terproses, padat, atau lebih.
Encoder sering kali merupakan komponen dari model yang lebih besar dan sering disambungkan dengan decoder. Beberapa Transformer memasangkan encoder dengan decoder, meskipun Transformer lain hanya menggunakan encoder atau hanya decoder.
Beberapa sistem menggunakan output encoder sebagai input untuk jaringan klasifikasi atau regresi.
Dalam tugas urutan ke urutan, encoder mengambil urutan input dan menampilkan status internal (vektor). Kemudian, decoder menggunakan status internal tersebut untuk memprediksi urutan berikutnya.
Lihat Transformer untuk mengetahui definisi encoder dalam arsitektur Transformer.
F
few-shot prompting
Prompt yang berisi lebih dari satu ("beberapa") contoh yang menunjukkan cara model bahasa besar merespons. Misalnya, perintah panjang berikut berisi dua contoh yang menunjukkan model bahasa besar cara menjawab kueri.
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang Anda inginkan untuk dijawab oleh LLM. |
| Prancis: EUR | Salah satu contohnya. |
| Inggris Raya: GBP | Contoh lainnya. |
| India: | Kueri yang sebenarnya. |
Few-shot prompting umumnya memberikan hasil yang lebih diinginkan daripada zero-shot prompting dan one-shot prompting. Namun, few-shot prompting memerlukan prompt yang lebih panjang.
Few-shot prompting adalah bentuk pembelajaran few-shot yang diterapkan pada pembelajaran berbasis prompt.
Biola
Library konfigurasi yang mengutamakan Python yang menetapkan nilai fungsi dan class tanpa kode atau infrastruktur invasif. Dalam kasus Pax—dan codebase ML lainnya—fungsi dan class ini mewakili model dan pelatihan hyperparameter.
Fiddle mengasumsikan bahwa codebase machine learning biasanya dibagi menjadi:
- Kode library, yang menentukan lapisan dan pengoptimal.
- Kode "glue" set data, yang memanggil library dan menggabungkan semuanya.
Fiddle merekam struktur panggilan kode glue dalam bentuk yang tidak dievaluasi dan dapat diubah.
fine tuning
Penerusan pelatihan khusus tugas kedua yang dilakukan pada model yang telah dilatih sebelumnya guna meningkatkan kualitas parameternya untuk kasus penggunaan tertentu. Misalnya, urutan pelatihan lengkap untuk beberapa model bahasa besar adalah sebagai berikut:
- Pra-pelatihan: Latih model bahasa besar pada set data umum yang luas, seperti semua halaman Wikipedia berbahasa Inggris.
- Fine-tuning: Latih model yang telah dilatih sebelumnya untuk melakukan tugas tertentu, seperti merespons kueri medis. Fine-tuning biasanya melibatkan ratusan atau ribuan contoh yang berfokus pada tugas tertentu.
Sebagai contoh lainnya, urutan pelatihan lengkap untuk model gambar besar adalah sebagai berikut:
- Pra-pelatihan: Latih model gambar besar pada set data gambar umum yang luas, seperti semua gambar di Wikimedia commons.
- Fine-tuning: Latih model yang telah dilatih sebelumnya untuk melakukan tugas tertentu, seperti membuat gambar orca.
Fine-tuning dapat memerlukan kombinasi apa pun dari strategi berikut:
- Memodifikasi semua parameter model terlatih yang ada. Hal ini terkadang disebut penyempurnaan penuh.
- Hanya memodifikasi beberapa parameter terlatih yang ada dari model terlatih (biasanya, lapisan yang paling dekat dengan lapisan output), sekaligus mempertahankan parameter lain yang sudah ada (biasanya, lapisan yang paling dekat dengan lapisan input). Lihat parameter-efficient tuning.
- Menambahkan lebih banyak lapisan, biasanya di atas lapisan yang ada yang terdekat dengan lapisan output.
Penyesuaian adalah salah satu bentuk pembelajaran transfer. Dengan demikian, fine-tuning mungkin menggunakan fungsi kerugian yang berbeda atau jenis model yang berbeda dengan yang digunakan untuk melatih model terlatih. Misalnya, Anda dapat menyesuaikan model gambar besar yang dilatih sebelumnya untuk menghasilkan model regresi yang menampilkan jumlah burung dalam gambar input.
Bandingkan dan kontraskan fine-tuning dengan istilah berikut:
Flax
Library open source berperforma tinggi untuk deep learning yang dibangun di atas JAX. Flax menyediakan fungsi untuk melatih jaringan neural, serta metode untuk mengevaluasi performanya.
Flaxformer
Library Transformer open source, yang dibangun di Flax, dirancang khusus untuk natural language processing dan riset multimodal.
G
AI generatif
Sebuah bidang transformatif yang sedang berkembang tanpa definisi formal. Meskipun demikian, sebagian besar pakar sependapat bahwa model AI generatif dapat membuat konten ("membuat") yang berupa hal-hal berikut:
- kompleks
- koheren
- asli
Misalnya, model AI generatif dapat membuat esai atau gambar yang canggih.
Beberapa teknologi sebelumnya, termasuk LSTM dan RNN, juga dapat menghasilkan konten asli dan koheren. Beberapa pakar menganggap teknologi lama ini sebagai AI generatif, sementara pakar lain merasa bahwa AI generatif yang sesungguhnya memerlukan output yang lebih kompleks daripada yang dapat dihasilkan oleh teknologi sebelumnya.
Berbeda dengan ML prediktif.
GPT (Transformer terlatih Generatif)
Keluarga Transformer model bahasa besar berbasis OpenAI.
Varian GPT dapat diterapkan ke beberapa modalitas, termasuk:
- pembuatan gambar (misalnya, ImageGPT)
- pembuatan teks ke gambar (misalnya DALL-E).
H
halusinasi
Produksi output yang tampak masuk akal tetapi tidak benar secara faktual oleh model AI generatif yang dimaksudkan untuk membuat pernyataan tentang dunia nyata. Misalnya, model AI generatif yang mengklaim bahwa Barack Obama meninggal pada tahun 1865 adalah halusinasi.
I
pembelajaran dalam konteks
Sinonim dari few-shot prompting.
L
LaMDA (Language Model for Dialogue Applications/Model Bahasa untuk Aplikasi Dialog)
Model bahasa besar berbasis Transformer yang dikembangkan oleh Google dilatih menggunakan set data dialog berukuran besar yang dapat menghasilkan respons percakapan yang realistis.
LaMDA: terobosan teknologi percakapan kami memberikan ringkasan.
model bahasa
model yang memperkirakan probabilitas model atau urutan token yang terjadi dalam urutan token yang lebih panjang.
model bahasa besar
Istilah informal tanpa definisi ketat yang biasanya berarti model bahasa yang memiliki banyak parameter. Beberapa model bahasa besar berisi lebih dari 100 miliar parameter.
ruang laten
Sinonim untuk menyematkan ruang.
LLM
Singkatan dari model bahasa besar.
LoRA
Singkatan dari Low-Rank Adaptability.
Kemampuan Adaptasi Tingkat Rendah (LoRA)
Algoritma untuk melakukan penyesuaian parameter yang menyesuaikan hanya subset parameter model bahasa besar. LoRA memberikan manfaat berikut:
- Menyesuaikan lebih cepat daripada teknik yang memerlukan penyempurnaan semua parameter model.
- Mengurangi biaya komputasi inferensi dalam model yang disesuaikan.
Model yang disesuaikan dengan LoRA mempertahankan atau meningkatkan kualitas prediksinya.
LoRA memungkinkan beberapa versi khusus dari sebuah model.
S
model bahasa yang disamarkan
Model bahasa yang memprediksi probabilitas token kandidat untuk mengisi bagian yang kosong secara berurutan. Misalnya, model bahasa yang disamarkan dapat menghitung probabilitas kata kandidat untuk mengganti garis bawah dalam kalimat berikut:
____ di dalam topi kembali muncul.
Literatur biasanya menggunakan string "MASK" bukan garis bawah. Contoh:
"MASK" di topi kembali muncul.
Sebagian besar model bahasa modern yang disamarkan bersifat dua arah.
pembelajaran meta
Bagian dari machine learning yang menemukan atau meningkatkan algoritma pembelajaran. Sistem pembelajaran meta juga dapat bertujuan untuk melatih model agar dapat dengan cepat mempelajari tugas baru dari sejumlah kecil data atau dari pengalaman yang diperoleh pada tugas sebelumnya. Algoritma pembelajaran meta umumnya mencoba mencapai hal berikut:
- Meningkatkan atau mempelajari fitur buatan tangan (seperti penginisialisasi atau pengoptimal).
- Lebih hemat data dan hemat komputasi.
- Meningkatkan generalisasi.
Meta-learning berkaitan dengan pembelajaran beberapa tahap.
modalitas
Kategori data tingkat tinggi. Misalnya, angka, teks, gambar, video, dan audio adalah lima modalitas yang berbeda.
paralelisme model
Cara penskalaan pelatihan atau inferensi yang menempatkan berbagai bagian dari satu model di berbagai perangkat. Paralelisme model memungkinkan model yang terlalu besar untuk dimuat di satu perangkat.
Untuk menerapkan paralelisme model, sistem biasanya melakukan hal berikut:
- Membagi (membagi) model menjadi bagian-bagian yang lebih kecil.
- Mendistribusikan pelatihan bagian yang lebih kecil ke beberapa prosesor. Setiap prosesor melatih bagian modelnya sendiri.
- Menggabungkan hasilnya untuk membuat satu model.
Paralelisme model memperlambat pelatihan.
Lihat juga paralelisme data.
atensi mandiri multi-head
Perluasan self-attention yang menerapkan mekanisme self-attention beberapa kali untuk setiap posisi dalam urutan input.
Transformer memperkenalkan atensi mandiri multi-head.
model multimodal
Model yang input dan/atau outputnya menyertakan lebih dari satu modalitas. Misalnya, pertimbangkan model yang menggunakan gambar dan teks teks (dua modalitas) sebagai fitur, dan menghasilkan skor yang menunjukkan seberapa sesuai teks tersebut untuk gambar. Jadi, {i>input<i} model ini adalah multimodal dan {i>outputnya<i} adalah unimodal.
N
natural language understanding
Menentukan niat pengguna berdasarkan apa yang diketik atau dikatakan pengguna. Misalnya, mesin telusur menggunakan natural language understanding untuk menentukan apa yang ditelusuri pengguna berdasarkan apa yang diketik atau dikatakan pengguna.
N-gram
Rangkaian N kata yang berurutan. Misalnya, truly madly bernilai 2 gram. Karena urutan bersifat relevan, nilai 2 gram pada madly true berbeda dengan truly madly.
| N | Nama untuk jenis N-gram ini | Contoh |
|---|---|---|
| 2 | bigram atau 2 gram | pergi, pergi, makan siang, makan malam |
| 3 | trigram atau 3 gram | terlalu banyak makan, tiga tikus buta, suara lonceng |
| 4 | 4 gram | berjalan di taman, berdebu tertiup angin, anak laki-laki itu makan lentil |
Banyak model natural language understanding mengandalkan N-gram untuk memprediksi kata berikutnya yang akan diketik atau diucapkan pengguna. Misalnya, anggaplah pengguna mengetik three buta. Model NLU berdasarkan trigram kemungkinan akan memprediksi bahwa pengguna selanjutnya akan mengetik mice.
Bedakan N-gram dengan kantong data, yang merupakan kumpulan kata yang tidak berurutan.
NLU
Singkatan dari natural language understanding.
O
metode one-shot prompting
Perintah yang berisi satu contoh yang menunjukkan cara model bahasa besar akan merespons. Misalnya, perintah berikut berisi satu contoh yang menunjukkan model bahasa besar cara menjawab kueri.
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang Anda inginkan untuk dijawab oleh LLM. |
| Prancis: EUR | Salah satu contohnya. |
| India: | Kueri yang sebenarnya. |
Bandingkan dan bedakan one-shot prompting dengan istilah berikut:
P
parameter-efficient tuning
Serangkaian teknik untuk menyesuaikan model bahasa terlatih (PLM) besar yang lebih efisien daripada penyesuaian sepenuhnya. Penyesuaian yang hemat parameter biasanya meningkatkan parameter yang jauh lebih sedikit daripada penyempurnaan penuh, tetapi umumnya menghasilkan model bahasa besar yang berperforma juga (atau hampir sama)nya dengan model bahasa besar yang dibuat dari penyempurnaan penuh.
Membandingkan dan membedakan parameter-efficient tuning dengan:
Parameter-efficient tuning juga dikenal sebagai parameter-efficient fine-tuning.
pipeline
Bentuk paralelisme model di mana pemrosesan model dibagi menjadi beberapa tahap yang berurutan dan setiap tahap dijalankan di perangkat yang berbeda. Saat suatu tahap memproses satu batch, tahap sebelumnya dapat diterapkan pada batch berikutnya.
Lihat juga pelatihan bertahap.
PLM
Singkatan dari model bahasa terlatih.
encoding posisi
Teknik untuk menambahkan informasi tentang posisi token dalam suatu urutan ke embedding token. Model transformer menggunakan encoding posisi untuk lebih memahami hubungan antara berbagai bagian urutan.
Implementasi umum dari encoding posisi menggunakan fungsi sinusoidal. (Secara khusus, frekuensi dan amplitudo fungsi sinusoidal ditentukan oleh posisi token dalam urutan.) Teknik ini memungkinkan model Transformer belajar menghadiri berbagai bagian urutan berdasarkan posisinya.
model terlatih
Model atau komponen model (seperti vektor embedding) yang telah dilatih. Terkadang, Anda akan memasukkan vektor embedding yang telah dilatih sebelumnya ke dalam jaringan neural. Di lain waktu, model Anda akan melatih vektor embedding itu sendiri, bukan mengandalkan embedding yang telah dilatih sebelumnya.
Istilah model bahasa terlatih mengacu pada model bahasa besar yang telah melalui pra-pelatihan.
latihan awal
Pelatihan awal model pada set data besar. Beberapa model yang dilatih sebelumnya adalah model yang ceroboh dan biasanya harus ditingkatkan melalui pelatihan tambahan. Misalnya, pakar ML dapat melatih terlebih dahulu model bahasa besar dengan set data teks yang luas, seperti semua halaman berbahasa Inggris di Wikipedia. Setelah melakukan pra-pelatihan, model yang dihasilkan dapat disempurnakan lebih lanjut melalui salah satu teknik berikut:
perintah
Semua teks yang dimasukkan sebagai input untuk model bahasa besar untuk mengondisikan model agar berperilaku dengan cara tertentu. Perintah dapat sesingkat frasa atau panjangnya bebas (misalnya, seluruh teks novel). Perintah terbagi dalam beberapa kategori, termasuk yang ditampilkan dalam tabel berikut:
| Kategori perintah | Contoh | Catatan |
|---|---|---|
| Pertanyaan | Seberapa cepat burung dara bisa terbang? | |
| Petunjuk | Tulis puisi lucu tentang arbitrase. | Perintah yang meminta model bahasa besar untuk melakukan sesuatu. |
| Contoh | Terjemahkan kode Markdown ke HTML. Misalnya:
Markdown: * item daftar HTML: <ul> <li>daftar item</li> </ul> |
Kalimat pertama dalam contoh prompt ini adalah sebuah instruksi. Contohnya adalah bagian selanjutnya dari prompt tersebut. |
| Peran | Jelaskan mengapa penurunan gradien digunakan dalam pelatihan machine learning untuk meraih gelar PhD bidang Fisika. | Bagian pertama kalimat adalah petunjuk; frasa "mendapatkan gelar PhD dalam bidang Fisika" adalah bagian peran. |
| Input parsial untuk diselesaikan model | Perdana Menteri Inggris Raya tinggal di | Permintaan input parsial dapat diakhiri secara tiba-tiba (seperti dalam contoh ini) atau diakhiri dengan garis bawah. |
Model AI generatif dapat merespons prompt dengan teks, kode, gambar, penyematan, video...hampir semua hal.
pembelajaran berbasis prompt
Kemampuan model tertentu yang memungkinkan mereka menyesuaikan perilakunya sebagai respons terhadap input teks arbitrer (perintah). Dalam paradigma pembelajaran berbasis perintah yang umum, model bahasa besar akan merespons perintah dengan membuat teks. Misalnya, anggaplah pengguna memasukkan perintah berikut:
Rangkum Hukum Ketiga Newton tentang Gerak.
Model yang mampu melakukan pembelajaran berbasis perintah tidak dilatih secara khusus untuk menjawab prompt sebelumnya. Sebaliknya, model "mengetahui" banyak fakta tentang fisika, tentang aturan bahasa umum, dan banyak hal tentang jawaban yang umumnya berguna. Pengetahuan tersebut sudah cukup untuk memberikan jawaban yang (semoga) bermanfaat. Masukan manusia tambahan ("Jawaban itu terlalu rumit" atau "Apa itu reaksi?") memungkinkan beberapa sistem pembelajaran berbasis perintah untuk secara bertahap meningkatkan kegunaan jawaban mereka.
desain prompt
Sinonim dari engineering prompt.
rekayasa perintah
Seni membuat prompt yang memunculkan respons yang diinginkan dari model bahasa besar. Manusia melakukan rekayasa perintah. Menulis perintah yang terstruktur dengan baik merupakan bagian penting untuk memastikan respons yang bermanfaat dari model bahasa besar. Prompt Engineering bergantung pada banyak faktor, termasuk:
- Set data digunakan untuk melatih terlebih dahulu dan mungkin menyempurnakan model bahasa besar.
- suhu dan parameter decoding lainnya yang digunakan model untuk menghasilkan respons.
Lihat Pengantar desain perintah untuk mengetahui detail selengkapnya tentang cara menulis perintah yang bermanfaat.
Prompt design adalah sinonim dari prompt engineering.
prompt tuning
Mekanisme tuning parameter yang efisien yang mempelajari "awalan" yang ditambahkan oleh sistem ke prompt sebenarnya.
Salah satu variasi prompt tuning—terkadang disebut tuning awalan—adalah dengan menambahkan awalan di setiap lapisan. Sebaliknya, sebagian besar prompt tuning hanya menambahkan awalan ke lapisan input.
R
perintah peran
Bagian opsional dari perintah yang mengidentifikasi target audiens untuk respons model AI generatif. Tanpa dialog peran, model bahasa besar memberikan jawaban yang mungkin berguna atau tidak berguna bagi orang yang mengajukan pertanyaan. Dengan perintah peran, model bahasa besar dapat menjawab dengan cara yang lebih tepat dan lebih membantu untuk target audiens tertentu. Misalnya, bagian perintah peran dari dialog berikut dicetak tebal:
- Rangkum artikel ini untuk mendapatkan gelar PhD di bidang ekonomi.
- Menjelaskan cara kerja pasang surut untuk anak berusia sepuluh tahun.
- Menjelaskan krisis keuangan 2008. Bicaralah seperti yang biasa Anda lakukan pada anak kecil, atau golden retriever.
S
self-attention (juga disebut lapisan self-attention)
Lapisan jaringan neural yang mengubah urutan embeddings (misalnya, embedding token) menjadi urutan embeddings lain. Setiap embedding dalam urutan output dibuat dengan mengintegrasikan informasi dari elemen urutan input melalui mekanisme attention.
Bagian self dari self-attention mengacu pada urutan yang memperhatikan diri itu sendiri, bukan pada beberapa konteks lain. Self-attention adalah salah satu elemen penyusun utama Transformer dan menggunakan terminologi pencarian kamus, seperti "query", "key", dan "value".
Lapisan self-attention dimulai dengan urutan representasi input, satu untuk setiap kata. Representasi input untuk sebuah kata dapat berupa embedding sederhana. Untuk setiap kata dalam urutan input, jaringan akan menilai relevansi kata ke setiap elemen dalam seluruh urutan kata. Skor relevansi menentukan seberapa besar representasi akhir kata menggabungkan representasi kata lain.
Misalnya, pertimbangkan kalimat berikut:
Hewan itu tidak menyeberang jalan karena terlalu lelah.
Ilustrasi berikut (dari Transformer: Arsitektur Jaringan Neural Baru untuk Pemahaman Bahasa) menunjukkan pola atensi lapisan self-attention untuk sebutan it, dengan kegelapan setiap baris menunjukkan seberapa banyak kontribusi setiap kata terhadap representasi:
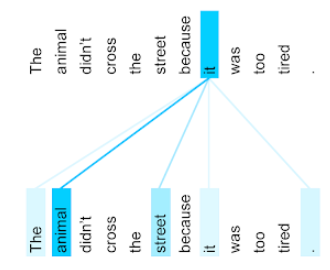
Lapisan self-attention menyoroti kata-kata yang relevan dengan "hal itu". Dalam hal ini, lapisan atensi telah belajar untuk menandai kata-kata yang mungkin merujuk, sehingga menetapkan bobot tertinggi untuk animal.
Untuk urutan n token, self-attention mengubah urutan embedding n waktu yang berbeda, sekali pada setiap posisi dalam urutan tersebut.
Lihat juga attention dan multi-head self-attention.
analisis sentimen
Menggunakan algoritma statistik atau machine learning untuk menentukan sikap keseluruhan kelompok—positif atau negatif—terhadap layanan, produk, organisasi, atau topik. Misalnya, dengan menggunakan natural language understanding, algoritme dapat melakukan analisis sentimen terhadap masukan tekstual dari mata kuliah untuk menentukan sejauh mana mahasiswa umumnya menyukai atau tidak menyukai mata kuliah tersebut.
tugas urutan-ke-urutan
Tugas yang mengonversi urutan input token menjadi urutan output token. Misalnya, dua jenis tugas urutan ke urutan yang populer adalah:
- Penerjemah:
- Contoh urutan input: "Aku cinta kamu".
- Contoh urutan output: "Je t'aime".
- Menjawab pertanyaan:
- Contoh urutan input: "Apakah saya perlu mobil di New York City?"
- Contoh urutan output: "Tidak. Simpan mobil Anda di rumah".
lewati-gram
n-gram yang dapat menghilangkan (atau "melewati") kata-kata dari konteks aslinya, yang berarti bahwa kata-kata N mungkin awalnya tidak berdekatan. Tepatnya, "k-skip-n-gram" adalah n-gram yang mungkin telah dilewati hingga k kata.
Misalnya, "rubah cokelat cepat" memiliki kemungkinan 2 gram berikut:
- "yang cepat"
- "cokelat cepat"
- "rubah cokelat"
"1-lewat-2-gram" adalah sepasang kata yang memiliki paling banyak 1 kata di antara mereka. Oleh karena itu, "si rubah cokelat cepat" memiliki 1 gram 2 gram berikut:
- "cokelat"
- "rubah cepat"
Selain itu, semua 2 gram juga merupakan 1-lewat-2-gram, karena kurang dari satu kata dapat dilewati.
Lewati-gram berguna untuk lebih memahami konteks di sekitar sebuah kata. Dalam contoh, "fox" secara langsung dikaitkan dengan "cepat" dalam kumpulan 1-lewat-2-gram, tetapi tidak dalam kumpulan 2-gram.
Lewati-gram membantu melatih model penyematan kata.
soft prompt tuning
Teknik untuk menyesuaikan model bahasa besar untuk tugas tertentu, tanpa penyesuaian resource yang intensif. Alih-alih melatih ulang semua bobot dalam model, penyesuaian soft prompt akan otomatis menyesuaikan perintah untuk mencapai sasaran yang sama.
Mengingat perintah tekstual, soft prompt tuning biasanya menambahkan embedding token tambahan ke prompt dan menggunakan propagasi mundur untuk mengoptimalkan input.
Prompt "hard" berisi token sebenarnya, bukan embedding token.
fitur renggang
Fitur yang sebagian besar nilainya nol atau kosong. Misalnya, fitur yang berisi satu nilai 1 dan satu juta nilai 0 bersifat jarang. Sebaliknya, fitur padat memiliki nilai yang utamanya bukan nol atau kosong.
Dalam machine learning, fitur yang jumlahnya mengejutkan adalah fitur yang jarang. Fitur kategoris biasanya merupakan fitur renggang. Misalnya, dari 300 kemungkinan spesies pohon di hutan, satu contoh mungkin hanya mengidentifikasi pohon maple. Atau, dari jutaan kemungkinan video dalam pustaka video, satu contoh mungkin hanya mengidentifikasi "Casablanca".
Dalam model, Anda biasanya merepresentasikan fitur renggang dengan encoding one-hot. Jika encoding one-hot berukuran besar, Anda dapat menempatkan lapisan embedding di atas enkode one-hot untuk efisiensi yang lebih besar.
representasi renggang
Hanya menyimpan posisi elemen bukan nol dalam fitur renggang.
Misalnya, fitur kategoris bernama species mengidentifikasi 36
spesies pohon di hutan tertentu. Asumsikan lebih lanjut bahwa setiap
contoh hanya mengidentifikasi satu spesies.
Anda dapat menggunakan vektor one-hot untuk mewakili spesies pohon pada setiap contoh.
Vektor one-hot akan berisi satu 1 (untuk mewakili
spesies pohon tertentu dalam contoh tersebut) dan 35 0 (untuk mewakili
35 spesies pohon yang tidak dalam contoh tersebut). Jadi, representasi one-hot
maple mungkin terlihat seperti berikut:

Atau, representasi renggang hanya akan mengidentifikasi posisi
spesies tertentu. Jika maple berada pada posisi 24, representasi renggang maple akan menjadi:
24
Perhatikan bahwa representasi renggang jauh lebih ringkas daripada representasi one-hot.
Klik ikon untuk contoh yang sedikit lebih kompleks.
Misalkan setiap contoh dalam model Anda harus mewakili kata-kata, tetapi bukan urutan kata-kata tersebut, dalam kalimat bahasa Inggris. Bahasa Inggris terdiri dari sekitar 170.000 kata, jadi bahasa Inggris adalah fitur kategoris dengan sekitar 170.000 elemen. Sebagian besar kalimat bahasa Inggris menggunakan bagian yang sangat kecil dari 170.000 kata tersebut, sehingga kumpulan kata dalam satu contoh hampir bisa dipastikan akan menjadi data yang sedikit.
Pertimbangkan kalimat berikut:
My dog is a great dog
Anda dapat menggunakan varian vektor one-hot untuk mewakili kata-kata dalam kalimat ini. Pada varian ini, beberapa sel dalam vektor dapat berisi nilai bukan nol. Selain itu, dalam varian ini, sel dapat berisi bilangan bulat selain satu. Meskipun kata "my", "is", "a", dan "great" hanya muncul sekali dalam kalimat, kata "dog" muncul dua kali. Penggunaan varian vektor one-hot ini untuk mewakili kata-kata dalam kalimat ini menghasilkan vektor 170.000 elemen berikut:

Representasi renggang dari kalimat yang sama akan berupa:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
pelatihan bertahap
Taktik pelatihan model dalam urutan tahapan terpisah. Tujuannya bisa untuk mempercepat proses pelatihan, atau untuk mencapai kualitas model yang lebih baik.
Ilustrasi tentang pendekatan {i>progressive stacking<i} (susunan progresif) ditampilkan di bawah ini:
- Tahap 1 berisi 3 lapisan tersembunyi, tahap 2 berisi 6 lapisan tersembunyi, dan tahap 3 berisi 12 lapisan tersembunyi.
- Tahap 2 memulai pelatihan dengan bobot yang dipelajari di 3 lapisan tersembunyi pada Tahap 1. Tahap 3 memulai pelatihan dengan bobot yang dipelajari dalam 6 lapisan tersembunyi pada Tahap 2.
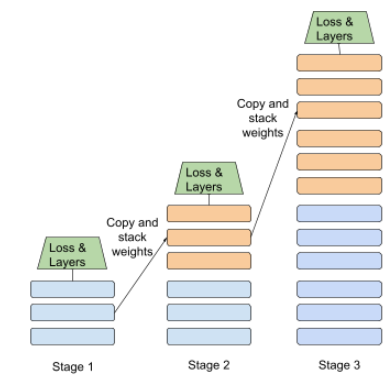
Lihat juga pipeline.
token subkata
Dalam model bahasa, token yang merupakan substring kata, yang dapat berupa seluruh kata.
Misalnya, kata seperti "itemize" dapat dipecah menjadi bagian-bagian "item" (kata root) dan "ize" (akhiran), yang masing-masing diwakili oleh tokennya sendiri. Memisahkan kata-kata yang tidak umum menjadi beberapa bagian yang disebut subkata memungkinkan model bahasa beroperasi pada bagian konstituen yang lebih umum dari kata tersebut, seperti awalan dan akhiran.
Sebaliknya, kata-kata umum seperti "pergi" mungkin tidak dipisah dan mungkin diwakili oleh satu token.
T
T5
Model pembelajaran teks ke teks yang diperkenalkan oleh Google AI pada tahun 2020. T5 adalah model encoder-decoder, yang didasarkan pada arsitektur Transformer, yang dilatih pada set data yang sangat besar. API ini efektif pada berbagai tugas natural language processing, seperti membuat teks, menerjemahkan bahasa, dan menjawab pertanyaan seperti percakapan.
T5 mendapatkan namanya dari lima T dalam "{i>Text-to-Text Transfer Transformer<i}."
T5X
Framework machine learning open source yang dirancang untuk membangun dan melatih model natural language processing (NLP) skala besar. T5 diterapkan pada codebase T5X (yang di-build pada JAX dan Flax).
suhu
hyperparameter yang mengontrol tingkat keacakan output model. Suhu yang lebih tinggi menghasilkan output yang lebih acak, sedangkan suhu yang lebih rendah menghasilkan output yang lebih sedikit acak.
Pemilihan suhu terbaik bergantung pada aplikasi tertentu dan properti pilihan dari output model. Misalnya, Anda mungkin akan menaikkan suhu saat membuat aplikasi yang menghasilkan output materi iklan. Sebaliknya, Anda mungkin akan menurunkan suhu saat membangun model yang mengklasifikasikan gambar atau teks untuk meningkatkan akurasi dan konsistensi model.
Suhu sering digunakan dengan softmax.
rentang teks
Rentang indeks array yang terkait dengan subbagian tertentu dari string teks.
Misalnya, kata good dalam string Python s="Be good now" akan menempati
rentang teks dari 3 hingga 6.
token
Dalam model bahasa, satuan atom tempat model dilatih dan digunakan untuk membuat prediksi. Token biasanya berupa salah satu dari berikut:
- sebuah kata—misalnya, frasa "dogs like cats" terdiri dari tiga token kata: "dogs", "like", dan "cats".
- sebuah karakter—misalnya, frasa "bike fish" terdiri dari token sembilan karakter. (Perhatikan bahwa ruang kosong dihitung sebagai salah satu token.)
- di mana satu kata bisa menjadi satu token atau beberapa token. Subkata terdiri dari kata dasar, awalan, atau akhiran. Misalnya, model bahasa yang menggunakan subkata sebagai token dapat melihat kata "dogs" sebagai dua token (kata root "dog" dan akhiran jamak "s"). Model bahasa yang sama mungkin menganggap satu kata "taller" sebagai dua subkata (kata root "tall" dan akhiran "er").
Dalam domain di luar model bahasa, token dapat mewakili jenis unit atom lainnya. Misalnya, dalam computer vision, token mungkin merupakan subset dari sebuah gambar.
Transformator
Arsitektur jaringan neural yang dikembangkan di Google yang mengandalkan mekanisme self-attention untuk mengubah urutan embedding input menjadi urutan embedding output tanpa bergantung pada konvolusi atau jaringan neural berulang. Transformer dapat dilihat sebagai tumpukan lapisan self-attention.
Transformer dapat mencakup salah satu dari hal berikut:
Encoder mengubah urutan embedding menjadi urutan baru dengan panjang yang sama. Encoder mencakup N lapisan identik, yang masing-masing berisi dua sub-lapisan. Kedua sub-lapisan ini diterapkan pada setiap posisi urutan penyematan input, sehingga mengubah setiap elemen urutan menjadi embedding baru. Sub-lapisan encoder pertama mengagregasi informasi dari seluruh urutan input. Sub-lapisan encoder kedua mengubah informasi gabungan menjadi embedding output.
Decoder mengubah urutan embedding input menjadi urutan embedding output, yang kemungkinan memiliki panjang yang berbeda. Decoder juga mencakup N lapisan identik dengan tiga sub-lapisan, dua di antaranya mirip dengan sub-lapisan encoder. Sub-lapisan decoder ketiga mengambil output encoder dan menerapkan mekanisme self-attention untuk mengumpulkan informasi darinya.
Postingan blog Transformer: Arsitektur Jaringan Neural Baru untuk Pemahaman Bahasa memberikan pengantar yang bagus tentang Transformer.
trigram
N-gram yang mana N=3.
U
searah
Sistem yang hanya mengevaluasi teks yang mendahului bagian target teks. Sebaliknya, sistem dua arah mengevaluasi teks yang mendahului dan mengikuti bagian teks target. Lihat dua arah untuk detail selengkapnya.
model bahasa searah
Model bahasa yang mendasarkan probabilitasnya hanya pada token yang muncul sebelum, bukan setelah, token target. Berbeda dengan model bahasa dua arah.
V
{i> variational autoencoder<i} (VAE)
Jenis autoencoder yang memanfaatkan perbedaan antara input dan output untuk menghasilkan versi input yang dimodifikasi. Autoencoder variasional berguna untuk AI generatif.
VAE didasarkan pada inferensi variasi: teknik untuk memperkirakan parameter model probabilitas.
W
penyematan kata
Merepresentasikan setiap kata dalam kumpulan kata dalam vektor embedding; yaitu, merepresentasikan setiap kata sebagai vektor nilai floating point antara 0,0 dan 1,0. Kata dengan makna serupa memiliki representasi yang lebih mirip daripada kata dengan arti yang berbeda. Misalnya, wortel, seledri, dan mentimun akan memiliki representasi yang relatif mirip, yang akan sangat berbeda dari representasi pesawat, kacamata hitam, dan pasta gigi.
Z
metode zero-shot prompting
Perintah yang tidak memberikan contoh cara Anda ingin model bahasa besar merespons. Contoh:
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang Anda inginkan untuk dijawab oleh LLM. |
| India: | Kueri yang sebenarnya. |
Model bahasa besar dapat merespons dengan salah satu hal berikut:
- Rupee
- INR
- ₹
- Rupee India
- Rupee
- Rupee India
Semua jawaban benar, meskipun Anda mungkin memilih format tertentu.
Bandingkan dan bedakan zero-shot prompting dengan istilah berikut: