דף זה מכיל מונחי מילון מונחים בנושא הערכת שפה. לכל המונחים במילון המונחים, לחצו כאן.
A
תשומת הלב,
מנגנון ברשת נוירונים שמציין את החשיבות של מילה מסוימת או חלק ממילה מסוימת. כשמפעילים את תשומת הלב, המערכת דוחסת את כמות המידע שנדרשת למודל כדי לחזות את האסימון/המילה הבאה. מנגנון תשומת לב אופייני עשוי לכלול סכום משוקלל על קבוצת קלטים, כאשר המשקל של כל קלט מחושב על ידי חלק אחר ברשת הנוירונים.
אפשר לקרוא גם על קשב עצמי ועל קשב עצמי רב-ראשי, שהם אבני הבניין של טרנספורמרים.
מקודד אוטומטי
מערכת שלומדת לחלץ את המידע החשוב ביותר מהקלט. מקודדים אוטומטיים הם שילוב של מקודד ומפענח. מקודדים אוטומטיים מסתמכים על התהליך הדו-שלבי הבא:
- המקודד ממפה את הקלט לפורמט (בדרך כלל) עם אבד-ממדים נמוך יותר (בינוני).
- המפענח בונה גרסה עם אבדן של הקלט המקורי על ידי מיפוי של הפורמט עם הממדים הנמוכים יותר לפורמט הקלט הממדי הגבוה יותר.
המקודדים האוטומטיים מאומנים מקצה לקצה, כך שהמפענח מנסה לשחזר את הקלט המקורי מפורמט הביניים של המקודד ככל האפשר. מכיוון שפורמט הביניים קטן יותר (בממדים קטנים יותר) מהפורמט המקורי, המקודד האוטומטי נאלץ ללמוד איזה מידע בקלט הוא חיוני, והפלט לא יהיה זהה לחלוטין לקלט.
למשל:
- אם נתוני הקלט הם גרפיים, העותק הלא מדויק יהיה דומה לגרפיקה המקורית, אבל השתנה מעט. אולי העותק הלא מדויק מסיר רעש מהגרפיקה המקורית או ממלא פיקסלים חסרים.
- במקרה שנתוני הקלט הם טקסט, מקודד אוטומטי ייצור טקסט חדש שמחקה (אבל לא זהה) לטקסט המקורי.
ראו גם מקודדים אוטומטיים משתנים.
מודל רגרסיבי אוטומטי
model שמסיק חיזוי על סמך החיזויים הקודמים שלו. לדוגמה, מודלים של שפה רגרסיביים אוטומטיים חוזים את האסימון הבא על סמך האסימונים הצפויים בעבר. כל מודלים גדולים של שפה (LLM) שמבוססים על טרנספורמרים הם רגרסיביים אוטומטיים.
לעומת זאת, מודלים של תמונות שמבוססים על GAN הם בדרך כלל לא רגרסיביים אוטומטיים, כי הם יוצרים תמונה במעבר אחד, ולא באופן איטרטיבי בשלבים. עם זאת, בחלק מהמודלים ליצירת תמונות הם רגרסיביים באופן אוטומטי כי הם יוצרים תמונה בשלבים.
B
שק של מילים
ייצוג של המילים בביטוי או בפסקה, ללא קשר לסדר. לדוגמה, 'תיק מילים' מייצג את שלושת הביטויים הבאים באופן זהה:
- הכלב קופץ
- קופץ על הכלב
- כלב קופץ
כל מילה ממופה לאינדקס בוקטור sparse, שבו לווקטור יש אינדקס לכל מילה באוצר המילים. לדוגמה, הביטוי הכלב קופץ ממופה לווקטור של מאפיין עם ערכים שאינם אפס בשלושת האינדקסים שתואמים למילים the, dog ו-jumps. הערך שאינו אפס יכול להיות כל אחד מהערכים הבאים:
- 1 לציון קיומה של מילה.
- מספר הפעמים שמילה מופיעה בתיק. לדוגמה, אם הביטוי היה כלב חום ערמוני הוא כלב עם פרווה חום ערמוני, גם חום ערמוני וגם כלב מיוצגים כ-2 והמילים האחרות מיוצגות כ-1.
- ערך אחר, כמו הלוגריתם של מספר הפעמים שמילה מופיעה בתיק.
BERT (ייצוגים דו-כיווניים של מקודד מטרנספורמרים)
ארכיטקטורת מודל לייצוג טקסט. מודל BERT מאומן יכול לשמש כחלק ממודל גדול יותר לסיווג טקסט או למשימות למידת מכונה אחרות.
ל-BERT יש את המאפיינים הבאים:
- נעשה שימוש בארכיטקטורה של טרנספורמר, ולכן הוא מסתמך על קשב עצמי.
- משתמש בחלק המקודד של הטרנספורמר. התפקיד של המקודד הוא ליצור ייצוגים טובים של טקסט, במקום לבצע משימה ספציפית, כמו סיווג.
- הוא דו-כיווני.
- נעשה שימוש באנונימיזציה לצורך אימון ללא פיקוח.
הווריאנטים של BERT כוללים:
סקירה כללית על BERT מופיעה במאמר Open Ssourcecing BERT: אימון מקדים של עיבוד שפה טבעית (NLP).
דו-כיווני
מונח המשמש לתיאור מערכת שמעריכה את הטקסט שקודם וגם עוקב אחרי קטע יעד של טקסט. לעומת זאת, מערכת חד-כיוונית מעריכה רק את הטקסט שקודם קטע יעד בטקסט.
לדוגמה, צריך להשתמש במודל אנונימיזציה של שפה שחייב לקבוע את ההסתברויות למילה או למילים שמייצגות את הקו התחתון בשאלה הבאה:
מה _____ איתך?
מודל שפה חד-כיווני יצטרך לבסס את ההסתברויות שלו רק על ההקשר של המילים "מה", "הוא" ו "ה". לעומת זאת, מודל שפה דו-כיווני יכול לקבל הקשר גם מ'עם' ומ'את', מה שיכול לעזור למודל ליצור חיזויים טובים יותר.
מודל שפה דו-כיווני
מודל שפה שקובע את ההסתברות לכך שאסימון נתון נמצא במיקום נתון בקטע טקסט על סמך הטקסט הקודם והבא.
Bigram
N-gram שבו N=2.
BLEU (לימודי הערכה דו-לשוניים)
ציון בין 0.0 ל-1.0, כולל, שמציין את איכות התרגום בין שתי שפות אנושיות (לדוגמה, בין אנגלית לרוסית). ציון 1.0 ב-BLEU מציין תרגום מושלם. ציון 0.0 ב-BLEU מציין תרגום גרוע.
C
מודל שפה סיבתי
מילה נרדפת למודל שפה חד-כיווני.
ראו מודל שפה דו-כיווני כדי להשוות גישות כיווניות שונות בבניית מודלים של שפות.
הנחיות בטכניקת שרשרת מחשבה
שיטה של הנדסת פרומפטים שמעודדת מודל שפה גדול (LLM) להסביר את הסיבה שלו שלב אחרי שלב. לדוגמה, כדאי לחשוב על ההנחיה הבאה, ולהקדיש תשומת לב ספציפית למשפט השני:
כמה כוחות g היה נהג במכונית שנסעת מ-0 ל-96 ק"מ לשעה ב-7 שניות? בתשובה, הצג את כל החישובים הרלוונטיים.
סביר להניח שהתגובה של ה-LLM תהיה:
- מציגים רצף של נוסחאות בפיזיקה, מחברים את הערכים 0, 60 ו-7 במקומות המתאימים.
- הסבירו מדוע הם בחרו בנוסחאות האלה ומה המשמעות של המשתנים השונים.
הנחיה של שרשרת מחשבה מאלצת את ה-LLM לבצע את כל החישובים, מה שיכול להוביל לתשובה נכונה יותר. בנוסף, בקשה משרשרת מחשבה מאפשרת למשתמשים לבחון את השלבים של ה-LLM כדי להחליט אם התשובה הגיונית או לא.
צ'אט, צ'ט, צאט, צט
התוכן של דיאלוג הלוך ושוב עם מערכת למידת מכונה, בדרך כלל מודל שפה גדול (LLM). האינטראקציה הקודמת בצ'אט (מה הקלדתם והאופן שבו מודל השפה הגדול הגיב) הופכת להקשר של החלקים הבאים בצ'אט.
צ'אט בוט הוא אפליקציה של מודל שפה גדול (LLM).
שיחה
מילה נרדפת להזיה.
קונפליקציה היא כנראה מונח מדויק יותר מבחינה טכנית מאשר המונח 'הזיה'. עם זאת, ההזיה הפכה לפופולרית בהתחלה.
ניתוח קהל בוחרים
פיצול משפט למבנים דקדוקיים קטנים יותר ("מרכיבים"). חלק מאוחר יותר במערכת למידת המכונה, כמו מודל הבנת שפה טבעית (NLP), יכול לנתח את המרכיבים בקלות רבה יותר מאשר המשפט המקורי. לדוגמה, שימו לב למשפט הבא:
חבר שלי אימץ שני חתולים.
מנתח בוחרים יכול לחלק את המשפט הזה לשני המרכיבים הבאים:
- חבר שלי הוא ביטוי שם.
- אמץ שני חתולים הוא ביטוי פועל.
אפשר לחלק את המרכיבים האלה לקבוצות משנה קטנות יותר. לדוגמה, ביטוי פועל
אימצו שני חתולים
ניתן לחלק אותה לחלוקות משנה נוספות:
- adopted הוא פועל.
- שני חתולים הוא ביטוי נוסף של שם עצם.
הטמעת שפה לפי הקשר
הטמעה שקרובה ל "הבנה" של מילים וביטויים באופן שדוברים ילידיים יכולים. הטמעות של שפות לפי הקשר יכולות להבין תחביר, סמנטיקה והקשר מורכבים.
לדוגמה, כדאי לשקול הטמעות של המילה באנגלית cow (פרה). הטמעות ישנות יותר, כמו word2vec, יכולות לייצג מילים באנגלית, כך שהמרחק בשטח ההטמעה מפרה לשור דומה למרחק בין ewe (כבש) ל-Ram (כבש זכר) או מנקבה לזכר. הטמעות של שפות לפי הקשר יכולות לקחת צעד אחד קדימה, באמצעות ההכרה בכך שדוברי אנגלית לפעמים משתמשים במילה פרה בתור פרה או שור.
חלון הקשר
מספר האסימונים שמודל יכול לעבד בהנחיה נתונה. ככל שחלון ההקשר גדול יותר, כך המודל יכול להשתמש במידע רב יותר כדי לספק תשובות עקביות ועקביות להנחיה.
פריחה
משפט או ביטוי עם משמעות לא ברורה. פריחת הקריסה יוצרת בעיה משמעותית בהבנת שפה טבעית. לדוגמה, הכותרת Red Tape Holds Up Skyscraper היא פריחה מפושטת, מפני שמודל NLU יכול לפרש את הכותרת באופן מילולי או מילולי.
D
מפענח
באופן כללי, כל מערכת למידת מכונה שממירה מייצוג מעובד, צפוף או פנימי לייצוג גולמי, דליל או חיצוני יותר.
מפענחים הם לעיתים קרובות רכיב במודל גדול יותר, שאותו הם מותאמים לעיתים קרובות למקודד.
במשימות רצף לרצף, המפענח מתחיל במצב הפנימי שהמקודד יצר כדי לחזות את הרצף הבא.
במאמר טרנספורמר מוסבר איך להגדיר מפענח בארכיטקטורת הטרנספורמר.
סינון רעשים
גישה נפוצה ללמידה בהשגחה עצמית, שבה:
סינון רעשים מאפשר ללמוד מדוגמאות ללא תוויות. מערך הנתונים המקורי משמש כיעד או label, והנתונים עם הרעש משמשים כקלט.
בחלק מהמודלים של אנונימיזציה של שפה נעשה שימוש בסינון רעשים באופן הבא:
- המערכת מוסיפה רעש באופן מלאכותי למשפט בלי תווית על ידי התממה של חלק מהאסימונים.
- המודל מנסה לחזות את האסימונים המקוריים.
הנחיות ישירות
מילה נרדפת להנחיה ישירה (zero-shot).
ה.
עריכת המרחק
מדידה של הדמיון בין שתי מחרוזות טקסט. בלמידת מכונה, כדאי לערוך את המרחק כי הוא פשוט לחישוב, ודרך יעילה להשוות בין שתי מחרוזות שידוע שהן דומות או כדי למצוא מחרוזות שדומות למחרוזת נתונה.
יש כמה הגדרות של עריכת מרחק, כל אחת משתמשת בפעולות מחרוזת שונות. לדוגמה, הערך של Levenshtein ותמונות [מרחק לונשטיין] מביא בחשבון את המספר הנמוך ביותר של פעולות מחיקה, הוספה והחלפה.
לדוגמה, המרחק בין המילים "לב" ל "חיצים" הוא 3, כי 3 העריכות הבאות הן רק השינויים הקטנים ביותר שמאפשרים להפוך מילה אחת לאחרת:
- לב ← deart (מחליפים h ב-d)
- deart → dart (מחיקה של 'e')
- dart → חצים (יש להכניס 's')
שכבת הטמעה
שכבה נסתרת מיוחדת שמאפשרת אימון על תכונה קטגורית בממדים גבוהים כדי ללמוד בהדרגה וקטור הטמעה של מאפיינים נמוכים יותר. שכבת הטמעה מאפשרת לרשת נוירונים לאמן הרבה יותר ביעילות מאשר אימון רק על התכונה הקטגורית בעלת הממדים הגבוהים.
לדוגמה, כדור הארץ תומך כרגע בכ-73,000 זני עצים. נניח שמיני עצים הם תכונה במודל, ולכן שכבת הקלט של המודל כוללת וקטור אחד חם באורך 73,000 רכיבים.
לדוגמה, אפשר לייצג את baobab בצורה הבאה:

מערך של 73,000 רכיבים הוא ארוך מאוד. אם לא תוסיפו למודל שכבת הטמעה, האימון יהיה ארוך מאוד עקב הכפלה של 72,999 אפסים. אולי תבחרו בשכבת ההטמעה שתהיה כוללת 12 מימדים. כתוצאה מכך, שכבת ההטמעה תלמד בהדרגה וקטור הטמעה חדש לכל סוג של עץ.
במצבים מסוימים, גיבוב הוא חלופה סבירה לשכבת הטמעה.
מרחב הטמעה
ממופים למרחב הווקטור ה-D-ממדי שלו, שמאפיינים ממרחב וקטורי גבוה יותר. באופן אידאלי, מרחב ההטמעה מכיל מבנה שמאפשר תוצאות מתמטיות משמעותיות. לדוגמה, במרחב הטמעה אידיאלי, חיבור וחיסור של הטמעות יכולים לפתור משימות של אנלוגיה מילים.
מכפלת הנקודות של שתי הטמעות היא מדד של הדמיון ביניהן.
וקטור הטמעה
באופן כללי, מערך של מספרים של נקודות צפות שנלקחו מכל שכבה נסתרת שמתארת את הקלט לשכבה המוסתרת. לעיתים קרובות, וקטור הטמעה הוא מערך של מספרי נקודות צפות שמאומנים בשכבת הטמעה. לדוגמה, נניח ששכבת ההטמעה חייבת ללמוד וקטור הטמעה לכל אחד מ-73,000 זני העצים בכדור הארץ. אולי המערך הבא הוא וקטור ההטמעה של עץ באובב:

וקטור הטמעה אינו קבוצה של מספרים אקראיים. שכבת ההטמעה קובעת את הערכים האלה באמצעות אימון, בדומה לאופן שבו רשת נוירונים לומדת משקולות אחרות במהלך האימון. כל רכיב במערך הוא דירוג לאורך מאפיין מסוים של מין עצים. איזה רכיב מייצג את המאפיין של מיני עצים? זה מאוד קשה לבני האדם.
החלק המתמטי של וקטור הטמעה הוא שלפריטים דומים יש קבוצות דומות של מספרים בנקודה צפה (floating-point). לדוגמה, לזנים דומים של עצים יש קבוצה דומה יותר של מספרים בנקודה צפה מאשר לזנים שונים של עצים. עצי סקויה וסקיה הם מיני עצים קשורים, ולכן יש להם קבוצה דומה יותר של מספרים צפים מאשר עצי סקוויה ועצי קוקוס. המספרים בווקטור ההטמעה ישתנו בכל פעם שיאמנו מחדש את המודל, גם אם תאמנו מחדש את המודל עם קלט זהה.
מקודד
באופן כללי, כל מערכת למידת מכונה שממירה מייצוג גולמי, דליל או חיצוני לייצוג פנימי, צפוף יותר או מעובד יותר.
מקודדים הם בדרך כלל רכיב במודל גדול יותר, שאותו הם מותאמים לעיתים קרובות למפענח. חלק מטרנספורמרים מתאימים בין מקודדים למפענחים, אבל טרנספורמרים אחרים משתמשים רק במקודד או רק במפענח.
חלק מהמערכות משתמשות בפלט של המקודד כקלט לרשת סיווג או רגרסיה.
במשימות רצף לרצף, המקודד לוקח רצף קלט ומחזיר מצב פנימי (וקטור). לאחר מכן, המפענח משתמש במצב הפנימי הזה כדי לחזות את הרצף הבא.
במאמר טרנספורמר מוסבר איך מגדירים מקודד בארכיטקטורת טרנספורמר.
נ
יצירת הנחיות בכמה דוגמאות
הודעה שמכילה יותר מדוגמה אחת ('מעט') שממחישה איך צריך להגיב מודל שפה גדול (LLM). לדוגמה, ההנחיה הארוכה הבאה מכילה שתי דוגמאות למודל שפה גדול (LLM) כדי לענות על שאילתה.
| חלקים מהנחיה אחת | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שעליה אתם רוצים שה-LLM יענה. |
| צרפת: EUR | דוגמה אחת. |
| בריטניה: GBP | דוגמה נוספת. |
| הודו: | השאילתה עצמה. |
בדרך כלל, יצירת הנחיות מכמה דוגמאות מניבה תוצאות יותר רצויות מאשר יצירת הנחיות מאפס והנחיות בדוגמה אחת. אבל כדי ליצור הנחיות עם כמה דוגמאות, צריך הנחיה ארוכה יותר.
הנחיות מכמה דוגמאות הן סוג של למידה עם כמה דוגמאות שחלה על למידה מבוססת-הנחיות.
כינור
ספריית הגדרות ב-Python שמגדירה את הערכים של פונקציות ומחלקות ללא קוד או תשתית פולשניים. במקרה של Pax וסביבות קוד אחרות של למידת מכונה, הפונקציות והמחלקות האלה מייצגות מודלים ואימון היפר-פרמטרים.
Fiddle מניחה שבסיסי הקוד של למידת המכונה בדרך כלל מתחלקים ל:
- קוד ספרייה, שמגדיר את השכבות ואת כלי האופטימיזציה.
- קוד 'glue' של מערך הנתונים, שקורא לספריות ולכבלים ביחד.
ב-Fiddle מתבצע תיעוד של מבנה הקריאה של קוד השיוך בצורה שלא מוערכת ושאפשר לשנות אותה.
כוונון עדין
העברת אימון שנייה ספציפית למשימה באמצעות מודל שעבר אימון מראש, כדי לשפר את הפרמטרים שלו בתרחיש ספציפי לדוגמה. לדוגמה, רצף האימון המלא של חלק ממודלים גדולים של שפה הוא:
- אימון מראש: אימון מודל שפה גדול (LLM) במערך נתונים כללי נרחב, כמו כל דפי הוויקיפדיה באנגלית.
- כוונון: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו מענה לשאילתות רפואיות. בדרך כלל הכוונון כולל מאות או אלפי דוגמאות שמתמקדות במשימה הספציפית.
דוגמה נוספת: רצף האימון המלא של מודל תמונה גדול הוא:
- אימון מראש: אימון מודל תמונה גדול על מערך נתונים כללי של תמונות, כמו כל התמונות ב-Wikimedia Common.
- כוונון: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו יצירת תמונות של קטלנים.
כוונון עדין יכול לכלול כל שילוב של האסטרטגיות הבאות:
- שינוי כל הפרמטרים הקיימים של המודל שעבר אימון מראש. פעולה זו נקראת לפעמים כוונון מלא.
- שינוי רק חלק מהפרמטרים הקיימים של המודל שעבר אימון מראש (בדרך כלל, השכבות הקרובות ביותר לשכבת הפלט), תוך השארת פרמטרים קיימים ללא שינוי (בדרך כלל, השכבות הקרובות ביותר לשכבת הקלט). למידע נוסף, ראו כוונון יעיל בפרמטרים.
- הוספת שכבות נוספות, בדרך כלל על גבי השכבות הקיימות הקרובות ביותר לשכבת הפלט.
כוונון הוא סוג של למידה בהעברה. לכן, כוונון עדין עשוי להשתמש בפונקציית אובדן אחרת או בסוג מודל שונה מאלה ששימשו לאימון המודל שעבר אימון מראש. לדוגמה, אפשר לכוונן מודל תמונה גדול שעבר אימון מראש כדי ליצור מודל רגרסיה שמחזיר את מספר הציפורים בתמונת קלט.
השוו והבדילו בין כוונון באמצעות המונחים הבאים:
פשתן
ספריית קוד פתוח בעלת ביצועים גבוהים ללמידה עמוקה, שמבוססת על JAX. Flax מספק פונקציות לאימון רשתות נוירונים, וגם שיטות להערכת הביצועים.
פשתן
ספריית טרנספורמר בקוד פתוח שמבוססת על Flax, שמיועדת בעיקר לעיבוד שפה טבעית (NLP) ולמחקר מרובה מצבים.
G
בינה מלאכותית גנרטיבית
שדה טרנספורמטיבי מתפתח ללא הגדרה רשמית. עם זאת, רוב המומחים מסכימים שמודלים של בינה מלאכותית גנרטיבית יכולים ליצור ('ליצור' תוכן שהוא:
- מורכב
- עקבי
- מקורית
לדוגמה, מודל של בינה מלאכותית גנרטיבית יכול ליצור מאמרים או תמונות מתוחכמים.
גם חלק מהטכנולוגיות הקודמות, כולל LSTM ו-RNN, יכולות ליצור תוכן מקורי ועקבי. חלק מהמומחים מתייחסים לטכנולוגיות הקודמות האלה כבינה מלאכותית גנרטיבית, ואילו אחרים סבורים שבינה מלאכותית גנרטיבית אמיתי דורשת פלט מורכב יותר מאשר הטכנולוגיות הקודמות יכולות להפיק.
בניגוד ללמידת מכונה חזויה.
GPT (טרנספורמר גנרטיבי שעבר אימון מראש)
משפחה של מודלים גדולים של שפה (LLM) שמבוססים על טרנספורמרים, שפותחו על ידי OpenAI.
אפשר להחיל וריאציות של GPT על שיטות מרובות, כולל:
- יצירת תמונות (לדוגמה, ImageGPT)
- ליצירת טקסט לתמונה (לדוגמה, DALL-E).
H
הזיה
ייצור פלט שנראית הגיונית אבל עובדתיתו שגויה על ידי מודל של בינה מלאכותית גנרטיבית שמתיימר להציג טענה לגבי העולם האמיתי. לדוגמה, מודל של בינה מלאכותית גנרטיבית טוען שברק אובמה נפטר ב-1865 גורם להזיה.
I
למידה בהקשר
מילה נרדפת להנחיה עם כמה דוגמאות.
L
LaMDA (מודל שפה לאפליקציות דיאלוג)
Google פיתחה מודל שפה גדול (LLM) שמבוסס על טרנספורמר, שאותו Google אימנה באמצעות מערך נתונים גדול של דיאלוג, שיכול ליצור תשובות מציאותיות לשיחות.
LaMDA: טכנולוגיית השיחות שלנו ופריצת הדרך מספקת סקירה כללית.
מודל שפה
model שמעריך את ההסתברות שmodel או רצף של אסימונים יופיעו ברצף ארוך יותר של אסימונים.
מודל שפה גדול (LLM)
מונח לא רשמי ללא הגדרה מדויקת, שהוא בדרך כלל מודל שפה שיש לו מספר גבוה של פרמטרים. חלק מהמודלים הגדולים של שפה מכילים יותר מ-100 מיליארד פרמטרים.
מרחב נסתר
מילה נרדפת להטמעת מרחב.
מודל שפה גדול (LLM)
LoRA
קיצור של התאמה בדירוג נמוך.
התאמה בדירוג נמוך (LoRA)
אלגוריתם לביצוע כוונון יעיל בפרמטרים שמחדד רק קבוצת משנה של פרמטרים של מודל שפה גדול. אלה היתרונות של LoRA:
- כוונון מהיר יותר מאשר טכניקות שדורשות כוונון עדין של כל הפרמטרים של המודל.
- הפחתת עלות החישוב של הֶקֵּשׁ במודל הכוונון עדין.
מודל שעבר כוונון בעזרת LoRA שומר או משפר את איכות החיזויים שלו.
שיטת LoRA מאפשרת להפעיל מספר גרסאות מיוחדות של מודל.
M
מודל התממת שפה (MLM)
מודל שפה שחוזה את ההסתברות שאסימונים מועמדים ימלאו תאים ריקים ברצף. לדוגמה, מודל התממת שפה יכול לחשב הסתברויות למילים מועמדות שיחליפו את הקו התחתון במשפט הבא:
ה-____ בכובע חזר.
בספרות נעשה בדרך כלל שימוש במחרוזת 'MASK' במקום בקו תחתון. למשל:
המילה "MASK" בכובע חזר.
רוב המודלים המודרניים של אנונימיזציה של שפה הם דו-כיווניים.
מטא-למידה
קבוצת משנה של למידת מכונה שמזהה או משפרת אלגוריתם למידת מכונה. מערכת מטא-למידה יכולה גם לנסות לאמן מודל ללמוד במהירות משימה חדשה מכמות קטנה של נתונים או מהניסיון שצברתם במשימות קודמות. אלגוריתמים של למידה חישובית בדרך כלל מנסים להשיג את הדברים הבאים:
- לשפר או ללמוד תכונות בהנדסה ידנית (כמו מאתחל או אופטימיזציה).
- להיות יעילים יותר בנתונים ולייעל את המחשוב.
- שיפור ההכללה.
מטא-למידת מכונה קשורה ללמידה חלקית.
שיטה
קטגוריה של נתונים ברמה גבוהה. לדוגמה, מספרים, טקסט, תמונות, וידאו ואודיו הם חמש שיטות שונות.
מקביליות של מודלים
דרך להתאים לעומס את האימון או להסקת מסקנות, שמציבה חלקים שונים של model אחד בmodel שונים. במקבילות של מודלים מאפשרת למודלים שגדולים מדי מכדי להתאים למכשיר יחיד.
כדי ליישם מקביליות של מודלים, בדרך כלל המערכת מבצעת את הפעולות הבאות:
- פיצול (מחלק) את המודל לחלקים קטנים יותר.
- מחלק את האימון של החלקים הקטנים יותר בין מספר מעבדים. כל מעבד מתאמן חלק משלו במודל.
- שילוב התוצאות כדי ליצור מודל יחיד.
במקבילות של מודל מאטה את האימון.
אפשר לקרוא גם על מקביליות של נתונים.
קשב עצמי עם ריבוי ראשים
תוסף של קשב עצמי שמפעיל את מנגנון הקשב העצמי כמה פעמים על כל מיקום ברצף הקלט.
טרנספורמרים כוללים את התכונה של קשב עצמי עם ריבוי ראשים.
מודל מרובה מצבים
מודל שהקלט ו/או הפלט שלו כוללים יותר ממודל אחד. לדוגמה, נניח שמודל שמקבל גם תמונה וגם כיתוב של טקסט (שתי שיטות) כתכונות, ומפיק ציון שמציין עד כמה כיתוב הטקסט מתאים לתמונה. כלומר, מקורות הקלט של המודל הזה הם מרובי מצבים, והפלט הוא אחיד.
לא
הבנת שפה טבעית (NLU)
זיהוי כוונות המשתמש על סמך מה שהוא הקליד או אמר. לדוגמה, מנוע חיפוש משתמש בהבנת שפה טבעית (NLP) כדי לקבוע מה המשתמש מחפש על סמך מה שהוא הקליד או אמר.
N-גרם
רצף סדור של N מילים. לדוגמה, הכיתוב באמת מטורף הוא 2 גרם. בגלל שסדר הוא רלוונטי, אז הערך באמת מטורף הוא 2 גרם שונה ממה שבאמת מטורף.
| לא | שמות לסוג N-gram | דוגמאות |
|---|---|---|
| 2 | Bigram או 2 גרם | ללכת, ללכת, לאכול ארוחת צהריים, לאכול ארוחת ערב |
| 3 | טריגרם או 3 גרם | אכלתם יותר מדי, שלושה עכברים עיוורים, פעמוניות |
| 4 | 4 גרם | ללכת בפארק, אבק ברוח, הילד אכל עדשים |
מודלים רבים של הבנת שפה טבעית מסתמכים על N-gram כדי לחזות את המילה הבאה שהמשתמש יקליד או יאמר. לדוגמה, נניח שמשתמש הקליד שלושה עיוורים. סביר להניח שמודל NLU שמבוסס על טריגרים יחזה שהמשתמש יקליד עכברים.
השוו בין גרם N לתיק מילים, שהן קבוצות לא מסודרות של מילים.
NLU
קיצור של הבנת שפה טבעית (NLP).
O
הנחיות בנוסחה אחת
הודעה שמכילה דוגמה אחת שממחישה איך צריך להגיב מודל שפה גדול (LLM). לדוגמה, ההנחיה הבאה מכילה דוגמה אחת למודל שפה גדול (LLM) שבו הוא צריך לענות על שאילתה.
| חלקים מהנחיה אחת | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שעליה אתם רוצים שה-LLM יענה. |
| צרפת: EUR | דוגמה אחת. |
| הודו: | השאילתה עצמה. |
השוו והבדילו בין יצירת הנחיות מדוגמה אחת לבין המונחים הבאים:
P
כוונון יעיל בפרמטרים
קבוצת שיטות לכוונון מודל שפה גדול שעבר אימון מראש (PLM) בצורה יעילה יותר מאשר כוונון מלא. בדרך כלל, כוונון יעיל בפרמטרים מכוונן הרבה פחות פרמטרים מאשר כוונון מלא, אבל בדרך כלל יוצר מודל שפה גדול (LLM) שמניב ביצועים טובים (או כמעט טוב) כמודל שפה גדול שמבוסס על כוונון מלא.
השוו בין כוונון יעיל בפרמטרים עם:
כוונון יעיל בפרמטרים נקרא גם כוונון יעיל בפרמטרים.
צינור עיבוד נתונים
צורה של מקביליות של המודל, שבה העיבוד של המודל מחולק לשלבים עוקבים, וכל שלב מבוצע במכשיר אחר. כאשר השלב מעבד אצווה אחת, השלב הקודם יכול לפעול גם באצווה הבאה.
אפשר לעיין גם בהדרכה מדורגת.
PLM
קיצור של מודל שפה שעבר אימון מראש.
קידוד תלוי מיקום
שיטה להוספת מידע על המיקום של אסימון ברצף להטמעת האסימון. מודלים של טרנספורמרים משתמשים בקידוד תלוי מיקום כדי להבין טוב יותר את הקשר בין חלקים שונים ברצף.
בקידוד תלוי מיקום נעשה שימוש בפונקציה סינוסואידית. (באופן ספציפי, התדירות והמשרעת של הפונקציה הסינוסואידית נקבעות לפי מיקום האסימון ברצף). השיטה הזו מאפשרת למודל טרנספורמר ללמוד לזהות חלקים שונים ברצף על סמך המיקום שלהם.
מודל שעבר אימון מראש
מודלים או רכיבי מודל (למשל וקטור הטמעה) שכבר אומנו. לפעמים מזינים וקטורים של הטמעה שעברו אימון ברשת נוירונים. במקרים אחרים, המודל יאמן את הווקטורים של ההטמעה בעצמו במקום להסתמך על ההטמעות שעברו אימון.
המונח מודל שפה שעבר אימון מראש מתייחס למודל שפה גדול (LLM) שעבר אימון מראש.
אימון מראש
האימון הראשוני של מודל על מערך נתונים גדול. חלק מהמודלים שעברו אימון מראש הם ענקיים מגושמים, ובדרך כלל צריך לשפר אותם באמצעות אימון נוסף. לדוגמה, מומחי למידת מכונה יכולים לאמן מראש מודל שפה גדול על מערך נתונים נרחב של טקסט, כמו כל הדפים באנגלית בוויקיפדיה. אחרי האימון מראש, אפשר לשפר את המודל שמתקבל באמצעות אחת מהשיטות הבאות:
הצעה לפעולה
כל טקסט שהוזן כקלט במודל שפה גדול (LLM) כדי להתנות שהמודל יתנהג בצורה מסוימת. הנחיות יכולות להיות קצרות כמו ביטוי או ארוכות באופן שרירותי (לדוגמה, הטקסט כולו של הספר). ההנחיות מחולקות לכמה קטגוריות, כולל אלו שמוצגות בטבלה הבאה:
| קטגוריית ההצעה לפעולה | דוגמה | הערות |
|---|---|---|
| שאלה | כמה מהר יונה יכול לעוף? | |
| הוראות | כתיבת שיר מצחיק על ארביטראז'. | הודעה שמבקשת ממודל השפה הגדול לבצע פעולה כלשהי. |
| דוגמה | תרגום של קוד Markdown ל-HTML. לדוגמה:
Markdown: * פריט ברשימה HTML: <ul> <li>פריט רשימה</li> </ul> |
המשפט הראשון בהנחיה לדוגמה הזו הוא הוראה. שאר ההנחיה היא הדוגמה. |
| תפקיד | להסביר למה משמשים ירידה הדרגתית באימון למידת מכונה לתואר דוקטור בפיזיקה. | החלק הראשון של המשפט הוא הוראה. הביטוי "אל דוקטורט בפיזיקה" הוא חלק התפקיד. |
| קלט חלקי להשלמת המודל | ראש ממשלת בריטניה גר | הנחיה עם קלט חלקי יכולה להסתיים בפתאומיות (כמו בדוגמה הזו) או להסתיים בקו תחתון. |
מודל של בינה מלאכותית גנרטיבית יכול להשיב להנחיה עם טקסט, קוד, תמונות, הטמעות, סרטונים... כמעט כל דבר.
למידה מבוססת-הנחיה
יכולת של מודלים מסוימים שמאפשרת להם להתאים את ההתנהגות שלהם בתגובה לקלט טקסט שרירותי (הנחיות). בפרדיגמה טיפוסית של למידה מבוססת הנחיות, מודל שפה גדול מגיב להנחיה על ידי יצירת טקסט. לדוגמה, נניח שמשתמש מזין את ההנחיה הבאה:
תסכם את חוק התנועה השלישי של ניוטון.
מודל שאפשר ללמידה מבוססת הנחיות לא עבר אימון ספציפי לענות על ההנחיה הקודמת. במקום זאת, המודל "יודע" הרבה עובדות על פיזיקה, הרבה על כללי שפה כלליים והרבה על מה הן תשובות שימושיות באופן כללי. הידע הזה מספיק כדי לספק תשובה (יש לקוות) מועילה. משוב אנושי נוסף ("התשובה הייתה מורכבת מדי" או "מהי תגובה?") מאפשר למערכות למידה מסוימות לשפר בהדרגה את השימושיות של התשובות שלהן.
עיצוב הנחיות
מילה נרדפת ל-prompt Engineering.
הנדסת הנחיות
יצירת הודעות פתיחה שגורמות לתגובות הרצויות ממודל שפה גדול (LLM). בני אדם מבצעים הנדסת הנחיות. כדי להבטיח תשובות מועילות ממודל שפה גדול, חשוב מאוד לכתוב הנחיות שמובנות היטב. הנדסת פרומפטים תלויה בגורמים רבים, כולל:
- מערך הנתונים שמשמש לאימון מראש ואולי לצמצום מודל השפה הגדול (LLM).
- הטמפרטורה ופרמטרים אחרים של פענוח שהמודל משתמש בהם כדי ליצור תשובות.
תוכלו לקרוא מידע נוסף על כתיבת הנחיות מועילות במאמר מבוא לעיצוב הנחיות.
עיצוב הנחיות הוא מילה נרדפת להנדסת פרומפטים.
כוונון של הנחיות
מנגנון כוונון יעיל בפרמטרים שלומד 'קידומת' שהמערכת מצרפת מראש להודעה בפועל.
אחת מהגרסאות של כוונון של הנחיות – שלפעמים נקראת כוונון קידומת – היא להוסיף את הקידומת לתחילת כל שכבה. לעומת זאת, ברוב המקרים כוונון של הנחיות מוסיף קידומת רק לשכבת הקלט.
R
הנחיות ליצירת תפקידים
חלק אופציונלי בהודעה שמזהה את קהל היעד לתשובה של מודל AI גנרטיבי. ללא בקשה לתפקידים, מודל שפה גדול (LLM) מספק תשובה שעשויה להיות מועילה או לא מועילה לאדם ששואל את השאלות. עם בקשת תפקידים, מודל שפה גדול יכול לענות באופן מתאים ומועיל יותר לקהל יעד ספציפי. לדוגמה, החלק של בקשת התפקיד בהודעות הבאות מופיע בגופן מודגש:
- תסכם את המאמר הזה לתואר דוקטור בכלכלה.
- תארו כיצד פועלים גאות עבור ילד בן עשר.
- הסבר על המשבר הפיננסי ב-2008. דברו כמו במקרה של ילד קטן או גולדן רטריבר.
S
קשב עצמי (נקרא גם שכבת הקשב העצמי)
שכבה של רשת נוירונים שמשנה רצף של הטמעות (למשל, הטמעות של אסימון) לרצף אחר של הטמעות. כל הטמעה ברצף הפלט נוצרת על ידי שילוב מידע מהאלמנטים של רצף הקלט באמצעות מנגנון תשומת לב.
החלק עצמי בקשב עצמי מתייחס לרצף שעוסק בעצמו ולא להקשר אחר. קשב עצמי הוא אחד מאבני הבניין העיקריות של טרנספורמרים, והוא משתמש בטרמינולוגיה של חיפוש מילונים, כמו "query", "key" ו-"value".
שכבת הקשבה עצמית מתחילה ברצף של ייצוגי קלט – אחד לכל מילה. ייצוג הקלט של מילה יכול להיות הטמעה פשוטה. לכל מילה ברצף הקלט, הרשת קובעת את מידת הרלוונטיות שלה לכל רכיב ברצף המילים. ציוני הרלוונטיות קובעים עד כמה הייצוג הסופי של המילה יכלול את הייצוגים של מילים אחרות.
לדוגמה, יש לשים לב למשפט הבא:
החיה לא חצה את הרחוב כי היא הייתה עייפה מדי.
באיור הבא (מ-Transformer: A Novel Neural Network Architecture for LanguageUnderstanding) ניתן לראות את דפוס תשומת הלב של שכבת הקשב העצמי ללשון הפנייה it, כאשר כל שורה מחושת עד כמה כל מילה תורמת לייצוג:
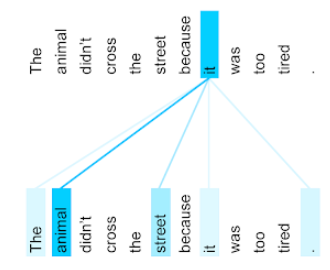
בשכבת הקשב העצמי מדגישה מילים שרלוונטיות למונח 'זה'. במקרה הזה, שכבת תשומת הלב למדה להדגיש מילים שהיא עשויה להתייחס אליהן, ולהקצות את המשקל הגבוה ביותר לבעל חיים.
ברצף של n אסימונים, הקשב עצמי משנה רצף של הטמעות n פעמים נפרדות, פעם אחת בכל מיקום ברצף.
תוכלו להיעזר גם במאמרים בנושא תשומת לב וקשב עצמי עם מספר ראשים.
ניתוח סנטימנט
שימוש באלגוריתמים סטטיסטיים או באלגוריתמים של למידת מכונה כדי לקבוע את הגישה הכוללת של קבוצה – חיובית או שלילית – לשירות, למוצר, לארגון או לנושא. לדוגמה, באמצעות הבנת שפה טבעית, אלגוריתם יכול לבצע ניתוח סנטימנטים במשוב הטקסטי מקורס באוניברסיטה כדי לקבוע את מידת האדיבות הכללית של הקורס באוניברסיטה.
משימת רצף לרצף
משימה שממירה רצף קלט של אסימונים לרצף פלט של אסימונים. לדוגמה, יש שני סוגים פופולריים של משימות רצף לרצף:
- מתרגמים:
- רצף קלט לדוגמה: "אני אוהב אותך".
- רצף פלט לדוגמה: "Je t'aime".
- מענה על שאלות:
- רצף קלט לדוגמה: "Do I need my car in Tel Aviv?"
- רצף פלט לדוגמה: "לא. יש להשאיר את הרכב בבית".
דילוג על gram
n-gram שיכול להשמיט (או "לדלג") מילים מהקשר המקורי, כלומר יכול להיות ש-N המילים לא היו קשורות במקור. באופן מדויק יותר, "k-skip-n-gram" הוא n-gram שעליו דילגתם על עד k מילים.
לדוגמה, ל"שועל החום המהיר" יש 2 גרם אפשריות:
- "המהיר"
- "חום מהיר"
- "חום שועל"
הביטוי "1-skip-2-gram" הוא זוג מילים שיש ביניהן מילה אחת לכל היותר. לכן, ל"שועל החום המהיר" יש 2 גרם של דילוג אחד:
- "חום"
- "שועל מהיר"
בנוסף, כל שני הגרם הם גם 1-skip-2-gram, כי אפשר לדלג על פחות ממילה אחת.
השימוש בגרם דילוגים עוזר להבין טוב יותר את ההקשר של המילה. בדוגמה, המילה "fox" שויך ישירות ל "מהיר" בקבוצה של 1-skip-2 גרם, אבל לא בקבוצה של 2 גרם.
דילוג על גרם עוזר לאמן מודלים של הטמעת מילים.
כוונון של הנחיות עם יכולת שחזור
שיטה לכוונון מודל שפה גדול (LLM) למשימה מסוימת, ללא כוונון עדין עתיר משאבים. במקום לאמן מחדש את כל המשקלים במודל, כוונון של הנחיות עם יכולת שחזור מתאים באופן אוטומטי הודעה כדי להשיג את אותה המטרה.
בהינתן הנחיה טקסטואלית, בדרך כלל, כוונון של הנחיות רכה מצרף להנחיה עוד הטמעות של אסימונים, ומשתמש בהפצה לאחור כדי לבצע אופטימיזציה של הקלט.
הנחיה 'קשה' מכילה אסימונים בפועל במקום הטמעות אסימונים.
ישות מועטה
תכונה שהערכים שלה הם בעיקר אפס או ריקים. לדוגמה, מאפיין שמכיל ערך בודד של 1 ומיליון ערכים הוא 0 הוא חלקי. לעומת זאת, לתכונה צפופה יש ערכים שהם בעיקר לא אפס או ריקים.
בלמידת מכונה יש מעט תכונות שהן מעטות. תכונות קטגוריות הן בדרך כלל ישויות מועטות. לדוגמה, מתוך 300 זני העצים האפשריים ביער, דוגמה אחת יכולה לזהות רק עץ מייפל. או, מתוך מיליוני הסרטונים האפשריים בספריית סרטונים, רק דוגמה אחת יכולה לזהות את קזבלנקה.
במודל, אתם בדרך כלל מייצגים תכונות מיעוט באמצעות קידוד one-hot. אם הקידוד החד-פעמי גדול, אפשר להוסיף שכבת הטמעה על גבי הקידוד החד-פעמי כדי לשפר את היעילות.
ייצוג דל
אחסון רק את המיקום(או המיקומים) של רכיבים שאינם אפס בתכונה מצומצמת.
לדוגמה, נניח שתכונה קטגורית בשם species מזהה את 36 זני העצים ביער מסוים. בנוסף, נניח שכל דוגמה מזהה רק מין אחד.
בכל דוגמה אפשר להשתמש בווקטור חם אחד כדי לייצג את מין העצים.
וקטור אחד החם יכלול 1 יחיד (שמייצג את סוג העצים הספציפי בדוגמה הזו) ו-35 פריטי 0 (שמייצג את 35 זני העצים לא בדוגמה הזו). אז הייצוג החם ביותר של maple עשוי להיראות כך:

לחלופין, ייצוג דל פשוט יזהה את המיקום של המינים האלה. אם maple נמצא במיקום 24, הייצוג המועט של maple יהיה פשוט:
24
שימו לב שהייצוג הדליל הוא הרבה יותר קומפקטי מהייצוג בחום אחד.
לוחצים על הסמל כדי לראות דוגמה קצת יותר מורכבת.
נניח שכל דוגמה במודל שלך צריכה לייצג את המילים - אבל לא את הסדר של המילים האלה - במשפט באנגלית. באנגלית יש כ-170,000 מילים, כך שאנגלית היא קטגוריה שכוללת כ-170,000 רכיבים. ברוב המשפטים באנגלית משתמשים בחלק זעיר מאוד מתוך 170,000 המילים האלה, כך שקבוצת המילים בדוגמה אחת כמעט ודאית תהיה מועטה.
נשקול את המשפט הבא:
My dog is a great dog
אפשר להשתמש בווריאנט של וקטור חם אחד כדי לייצג את המילים במשפט הזה. בווריאנט הזה, כמה תאים בווקטור יכולים להכיל ערך שהוא לא אפס. בנוסף, בווריאנט הזה, תא יכול להכיל מספר שלם אחר. למרות שהמילים "my", "is", "a" ו-"נהדר" מופיעות רק פעם אחת במשפט, המילה "כלב" מופיעה פעמיים. השימוש בווריאנט הזה של וקטורים חמים אחדות כדי לייצג את המילים במשפט מניב את הווקטור הבא של 170,000 רכיבים:

ייצוג דלי של אותו משפט יהיה פשוט:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
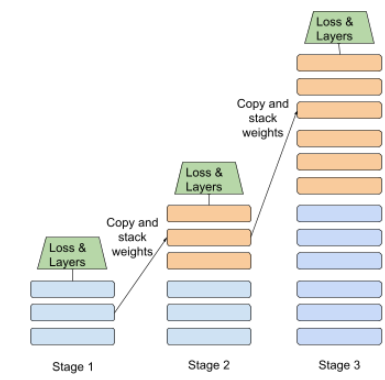
אימון מדורג
טקטיקה של אימון מודל ברצף של שלבים נפרדים. המטרה יכולה להיות לזרז את תהליך האימון או לשפר את איכות המודל.
איור של גישת הערימה הפרוגרמטית:
- שלב 1 מכיל 3 שכבות מוסתרות, שלב 2 מכיל 6 שכבות מוסתרות ושלב 3 מכיל 12 שכבות מוסתרות.
- שלב 2 מתחיל להתאמן עם המשקולות שנלמדו בשלוש השכבות המוסתרות בשלב 1. שלב 3 מתחיל להתאמן עם המשקולות שנלמדו ב-6 השכבות הנסתרות בשלב 2.
ראו גם צינור עיבוד נתונים.
אסימון של מילת משנה
במודלים של שפה, אסימון שהוא מחרוזת משנה של מילה, שיכול להיות המילה כולה.
לדוגמה, יכול להיות שמילה כמו "itemize" תפוצל לחלקים "item" (מילת שורש) ו-"ize" (סיומת), שכל אחת מהן מיוצגת על ידי אסימון משלה. פיצול מילים לא נפוצות לחלקים כאלה, שנקראות מילות משנה, מאפשר למודלים של שפה לפעול על החלקים הנפוצים יותר של המילה, כמו קידומות וסיומות.
לעומת זאת, יכול להיות שמילים נפוצות כמו "פועל" לא יפוצלו, והן עשויות להיות מיוצגות באמצעות אסימון יחיד.
T
T5
מודל העברת למידה של טקסט לטקסט, שהושק על ידי Google AI בשנת 2020. T5 הוא מודל מקודד-מפענח, שמבוסס על ארכיטקטורת Transformer, שאומן על מערך נתונים גדול במיוחד. הוא יעיל במגוון משימות של עיבוד שפה טבעית (NLP) כמו יצירת טקסט, תרגום שפות ומענה על שאלות בשיחות.
T5 מקבל את שמו מחמשת האותיות T ב-"Text-to-Text Transfer Transformer".
T5X
מסגרת של למידת מכונה בקוד פתוח, שנועדה ליצור ולאמן מודלים גדולים של עיבוד שפה טבעית (NLP) בקנה מידה גדול. T5 מוטמע ב-codebase T5X (שמבוסס על JAX ו-Flax).
טמפרטורה
היפר-פרמטר שקובע את מידת הרנדומיזציה של הפלט של המודל. טמפרטורה גבוהה יותר מובילה לפלט אקראי יותר, וטמפרטורות נמוכות יותר מניבות פלט אקראי פחות.
בחירת הטמפרטורה הטובה ביותר תלויה באפליקציה הספציפית ובמאפיינים המועדפים של הפלט של המודל. לדוגמה, סביר להניח שתרצו להעלות את הטמפרטורה כשיוצרים אפליקציה שמייצרת פלט של קריאייטיב. לעומת זאת, כדאי להוריד את הטמפרטורה כשבונים מודל שמסווג תמונות או טקסט כדי לשפר את הדיוק והעקביות של המודל.
לרוב, משתמשים בטמפרטורה כשמשתמשים ב-softmax.
טווח הטקסט
טווח האינדקס של המערך שמשויך לקטע משנה ספציפי של מחרוזת טקסט.
לדוגמה, המילה good במחרוזת Python s="Be good now" מכילה את טווח הטקסט מ-3 עד 6.
token
במודל שפה, היחידה האטומית שעליה המודל מתאמן ומבצעת תחזיות. בדרך כלל אסימון הוא אחד מהבאים:
- מילה מסוימת – לדוגמה, הביטוי "כלבים כמו חתולים" מורכב משלושה אסימוני מילים: "כלבים", "לייק" ו "חתולים".
- דמות כלשהי – לדוגמה, הביטוי 'דגי אופניים' כולל אסימונים עם תשעה תווים. (שימו לב שהרווח הריק נחשב לאחד מהאסימונים).
- מילות משנה – שבהן מילה יחידה יכולה להיות אסימון יחיד או כמה אסימונים. מילת משנה מורכבת ממילת שורש, מקידומת או מסיומת. לדוגמה, מודל שפה שמשתמש במילות משנה בתור אסימונים עשוי לראות את המילה 'כלבים' כשני אסימונים (מילה השורש 'כלב' וסיומת הרבים 's'). אותו מודל שפה עשוי להתייחס למילה הבודדת "taller" כשתי מילות משנה (מילת הבסיס "tall" והסיומת "er").
בדומיינים מחוץ למודלים של שפה, אסימונים יכולים לייצג סוגים אחרים של יחידות אטומיות. לדוגמה, בראייה ממוחשבת, אסימון יכול להיות קבוצת משנה של תמונה.
רובוטריק
ארכיטקטורה של רשתות נוירונים שפותחה ב-Google ומסתמכת על מנגנוני קשב עצמי כדי לשנות רצף של הטמעות קלט לרצף של הטמעות פלט בלי להסתמך על קובולציות או על רשתות נוירונים חוזרות. אפשר להציג את הטרנספורמר בתור מקבץ של שכבות של תשומת לב עצמית.
טרנספורמר יכול לכלול כל אחת מהאפשרויות הבאות:
מקודד ממיר רצף של הטמעות לרצף חדש באותו אורך. המקודד כולל N שכבות זהות, וכל אחת מהן מכילה שתי שכבות משנה. שתי שכבות המשנה האלה מוחלות בכל מיקום ברצף של הטמעת הקלט, וכל רכיב ברצף הופך להטמעה חדשה. שכבת המשנה הראשונה של המקודד צוברת מידע מכל רצף הקלט. שכבת המשנה השנייה של המקודד הופכת את המידע הנצבר להטמעת פלט.
מפענח ממיר רצף של הטמעות קלט לרצף של הטמעות פלט, אולי באורך שונה. המפענח כולל גם N שכבות זהות עם שלוש שכבות משנה, ששתיים מהן דומות לשכבות המשנה של המקודד. שכבת המשנה השלישית של המפענח מקבלת את פלט המקודד ומחילה את מנגנון ההקשבה העצמית כדי לאסוף ממנו מידע.
בפוסט בבלוג Transformer: A Novel Neural Network Architecture for LanguageUnderstanding ניתן למצוא מבוא טוב לטרנספורמרים.
טריגרם
N-gram שבו N=3.
U
חד-כיווני
מערכת שבודקת רק את הטקסט שקודם לקטע יעד בטקסט. לעומת זאת, מערכת דו-כיוונית מעריכה גם את הטקסט שקודם וגם עוקב אחרי קטע יעד של טקסט. לפרטים נוספים, אפשר לעיין בקטע דו-כיווני.
מודל שפה חד-כיווני
מודל שפה שמבסס את ההסתברויות שלו רק על האסימונים שמופיעים לפני, ולא אחרי אסימוני היעד. ליצור ניגוד למודל שפה דו-כיווני.
V
מקודד אוטומטי וריאציה (VAE)
סוג של מקודד אוטומטי שממנף את אי ההתאמה בין מקורות הקלט לפלט כדי ליצור גרסאות מותאמות של הקלט. מקודדים אוטומטיים וריאציוניים (VAE) שימושיים ל-בינה מלאכותית גנרטיבית.
משתני VAE מבוססים על מסקנות משתנים: שיטה להערכת הפרמטרים של מודל הסתברות.
W
הטמעת מילים
ייצוג של כל מילה בקבוצת מילים בתוך וקטור הטמעה. כלומר, ייצוג של כל מילה כווקטור של ערכים של נקודה צפה בין 0.0 ל-1.0. למילים עם משמעויות דומות יש ייצוגים דומים יותר למילים עם משמעויות שונות. לדוגמה, לגזרים, לסלרי ולמלפפון יהיו ייצוגים דומים יחסית, שיהיו שונים מאוד מהייצוגים של מטוסים, משקפי שמש ומשחת שיניים.
Z
יצירת הנחיות מאפס
הודעה שלא מספקת דוגמה לאופן שבו אתם רוצים שמודל השפה הגדול יגיב. למשל:
| חלקים מהנחיה אחת | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שעליה אתם רוצים שה-LLM יענה. |
| הודו: | השאילתה עצמה. |
מודל השפה הגדול יכול להגיב עם אחת מהאפשרויות הבאות:
- רופיות
- INR
- ₹
- רופי הודי
- הרופי
- רופי הודי
כל התשובות נכונות, אבל ייתכן שתעדיפו פורמט מסוים.
השוו והבדילו בין יצירת הנחיות מאפס לבין המונחים הבאים: