このページでは、画像モデルの用語集について説明します。用語集のすべての用語については、こちらをクリックしてください。
A
拡張現実
コンピュータによって生成された画像をユーザーの現実世界のビューに重ねて、合成ビューを提供するテクノロジー。
オートエンコーダ
入力から最も重要な情報を抽出することを学習するシステム。オートエンコーダは、エンコーダとデコーダを組み合わせたものです。オートエンコーダは、次の 2 段階のプロセスに依存します。
- エンコーダは、入力を(通常は)非可逆低次元(中間)形式にマッピングします。
- デコーダは、低次元形式を元の高次元入力形式にマッピングすることで、元の入力の非可逆バージョンを作成します。
オートエンコーダは、エンコーダの中間形式から元の入力を可能な限り再現するようにデコーダに試行させることで、エンドツーエンドでトレーニングされます。中間形式は元の形式よりも小さい(低次元)ため、オートエンコーダは入力のどの情報が必須かを学習せざるを得ず、出力が入力と完全に同一になることはありません。
次に例を示します。
- 入力データがグラフィックの場合、完全ではないコピーは元のグラフィックと似ていますが、若干変更されています。元の画像からノイズが取り除かれたり、欠落しているピクセルが埋め込まれていたりすると、元の画像からノイズが取り除かれる場合があります。
- 入力データがテキストの場合、オートエンコーダは元のテキストを模倣した(ただし同一ではない)新しいテキストを生成します。
変分オートエンコーダもご覧ください。
自己回帰モデル
過去の予測に基づいて予測を推測するモデルmodel。たとえば、自己回帰言語モデルは、以前に予測されたトークンに基づいて次のトークンを予測します。Transformer ベースの大規模言語モデルはすべて自己回帰型です。
一方、GAN ベースの画像モデルは通常、ステップで反復的にではなく 1 回のフォワードパスで画像を生成するため、自己回帰的ではありません。ただし、特定の画像生成モデルは、画像を段階的に生成するため、自己回帰的です。
B
境界ボックス
画像における、次の画像の犬など、関心領域を囲む長方形の (x, y) 座標。

C
畳み込み
数学では、気軽に言うと 2 つの関数が混ざり合ったものです。ML では、重みをトレーニングするために、畳み込みによって畳み込みフィルタと入力行列を組み合わせます。
ML における「畳み込み」という用語は、畳み込み演算または畳み込み層の略称でよく使用されます。
畳み込みなしの場合、ML アルゴリズムは大規模なテンソルのセルごとに個別の重みを学習する必要があります。たとえば、2,000 x 2,000 の画像でトレーニングする ML アルゴリズムでは、400 万個の個別の重みを見つける必要があります。畳み込みのおかげで、ML アルゴリズムは畳み込みフィルタ内のすべてのセルの重みを見つけるだけでよく、モデルのトレーニングに必要なメモリを大幅に削減できます。畳み込みフィルタが適用されると、セル間で複製されるだけで、それぞれにフィルタが乗算されます。
畳み込みフィルタ
畳み込み演算における 2 つのアクターのうちの 1 つ。(もう 1 つの行為者は入力行列のスライスです)。畳み込みフィルタは、入力行列と同じ階数を持つが、形状が小さい行列です。たとえば、28x28 の入力行列の場合、フィルタは 28x28 より小さい任意の 2D 行列になります。
写真操作では、通常、畳み込みフィルタ内のすべてのセルが 1 と 0 の一定パターンに設定されます。通常、ML では畳み込みフィルタに乱数がシードされ、ネットワークが理想的な値をトレーニングします。
畳み込み層
ディープ ニューラル ネットワークのレイヤ。このレイヤでは、畳み込みフィルタが入力行列を通過します。たとえば、次の 3x3 畳み込みフィルタについて考えてみましょう。
![次の値を持つ 3x3 行列: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=2&hl=ja)
次のアニメーションは、5x5 入力行列を含む 9 つの畳み込み演算で構成される畳み込みレイヤを示しています。各畳み込み演算は、入力行列の異なる 3x3 スライスで機能します。結果の 3x3 行列(右側)は、次の 9 つの畳み込み演算の結果で構成されます。
![2 つのマトリックスを示すアニメーション。最初の行列は 5x5 の行列です。[[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [10.179], [31,201,198]2 つ目の行列は 3x3 の [[181,303,618], [115,338,605], [169,351,560]] です。2 番目の行列は、5x5 行列の異なる 3x3 サブセットに畳み込みフィルタ [[0, 1, 0], [1, 0, 1], [0, 1, 0]] を適用することで計算されます。](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=2&hl=ja)
畳み込みニューラル ネットワーク
少なくとも 1 つのレイヤが畳み込みレイヤであるニューラル ネットワーク。一般的な畳み込みニューラル ネットワークは、次のレイヤの組み合わせで構成されます。
畳み込みニューラル ネットワークは、画像認識などの特定の種類の問題で大きな成功を収めています。
畳み込み演算
次の 2 段階の算術演算は次のようになります。
- 畳み込みフィルタと入力行列のスライスの要素単位の乗算。(入力行列のスライスのランクとサイズは、畳み込みフィルタと同じです)。
- 結果の商品行列内のすべての値を合計します。
たとえば、次の 5x5 入力行列について考えてみます。
![5x5 行列: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,79]2,100](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=2&hl=ja)
次の 2 × 2 の畳み込みフィルタについて考えてみましょう。
![2x2 行列: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=2&hl=ja)
各畳み込み演算には、入力行列の 1 つの 2x2 スライスが含まれます。たとえば、入力行列の左上の 2x2 スライスを使用するとします。そのため、このスライスの畳み込み演算は次のようになります。
![畳み込みフィルタ [[1, 0], [0, 1]] を入力行列の左上の 2x2 セクション、[[128,97], [35,22]] に適用します。畳み込みフィルタは、128 と 22 をそのまま残し、97 と 35 をゼロにします。その結果、畳み込み演算により値 150(128+22)が生成されます。](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=2&hl=ja)
畳み込みレイヤは一連の畳み込み演算で構成され、各演算は入力行列の異なるスライスに作用します。
D
データの拡張
既存のサンプルを変換して追加のサンプルを作成することで、トレーニングサンプルの範囲と数を人為的に増やす。たとえば、画像が特徴の一つであるものの、モデルが有用な関連付けを学習するのに十分な画像サンプルがデータセットに含まれていないとします。理想的には、モデルが適切にトレーニングできるように、十分な数のラベル付けされた画像をデータセットに追加することが理想的です。それができない場合は、データ拡張によって各画像を回転、引き伸ばし、反射させて、元の画像の多くのバリエーションを生成できます。これにより、優れたトレーニングを可能にする十分なラベル付きデータが得られる可能性があります。
深さ方向分離可能畳み込みニューラル ネットワーク(sepCNN)
Inception に基づく畳み込みニューラル ネットワーク アーキテクチャですが、Inception モジュールが深さ方向に分離可能な畳み込みに置き換えられています。別名 Xception。
深度方向の分離可能な畳み込み(分離可能畳み込みとも呼ばれる)は、標準的な 3 次元畳み込みを、より計算効率の高い 2 つの個別の畳み込み演算に因数分解します。1 つは深度 1(n × n × 1)の深さ方向の畳み込み演算、2 つ目は深さ 1(n × n × 1)の深さ方向の畳み込み演算です。
詳細については、Xception: 深度分離可能な畳み込みを使用したディープ ラーニングをご覧ください。
ダウンサンプリング
次のいずれかを意味する「オーバーロード」の用語:
- モデルをより効率的にトレーニングするために、特徴内の情報量を減らす。たとえば、画像認識モデルをトレーニングする前に、高解像度画像を低解像度形式にダウンサンプリングします。
- 過小評価されているクラスサンプルの割合が不均衡に低いトレーニングを使用して、過小評価されているクラスでのモデル トレーニングを改善します。たとえば、クラス不均衡のデータセットでは、モデルはマジョリティクラスについて多くを学習する傾向がありますが、マイノリティクラスについては十分に学習しません。ダウンサンプリングは、多数派のクラスと少数派のクラスのトレーニング量のバランスを取るのに役立ちます。
F
ファインチューニング
2 つ目のタスク固有のトレーニング パス。事前トレーニング済みモデルに対して行われ、特定のユースケースに合わせてパラメータを調整します。たとえば、一部の大規模言語モデルの完全なトレーニング シーケンスは次のようになります。
- 事前トレーニング: 膨大な一般的なデータセット(すべての英語の Wikipedia ページなど)で大規模言語モデルをトレーニングします。
- ファインチューニング: 医療関連のクエリへの応答など、特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。ファインチューニングには通常、特定のタスクに焦点を当てた数百または数千のサンプルが含まれます。
別の例として、大規模な画像モデルの完全なトレーニング シーケンスは次のようになります。
- 事前トレーニング: Wikimedia Commons にあるすべての画像など、膨大な一般的な画像データセットで大規模画像モデルをトレーニングします。
- ファインチューニング: 事前トレーニング済みモデルをトレーニングして、シャチの画像の生成など、特定のタスクを実行します。
ファインチューニングでは、次の戦略を任意に組み合わせることができます。
- 事前トレーニング済みモデルの既存のパラメータをすべて変更する。これは「フル ファインチューニング」とも呼ばれます。
- 事前トレーニング済みモデルの既存のパラメータの一部(通常は出力レイヤに最も近いレイヤ)のみを変更し、他の既存のパラメータ(通常は入力レイヤに最も近いレイヤ)を変更する。パラメータ効率調整をご覧ください。
- レイヤを追加します。通常は、出力レイヤに最も近い既存のレイヤの上に追加します。
ファインチューニングは転移学習の一形態です。そのため、微調整では、事前トレーニング済みモデルのトレーニングに使用したものとは異なる損失関数や異なるモデルタイプが使用されることがあります。たとえば、事前トレーニング済みの大きな画像モデルをファインチューニングして、入力画像の鳥の数を返す回帰モデルを生成できます。
ファインチューニングを以下の用語と比較対照してください。
1 階
生成 AI
正式な定義のない、新たな変革の分野。とはいえ、生成 AI モデルは、次のすべてを含むコンテンツを作成(「生成」)できるとほとんどの専門家が同意しています。
- 複雑
- 首尾一貫した
- オリジナル
たとえば、生成 AI モデルは洗練されたエッセイや画像を作成できます。
LSTM や RNN などの一部の以前のテクノロジーでも、オリジナルで一貫性のあるコンテンツを生成できます。こうした初期のテクノロジーを生成 AI とみなす専門家もいれば、真の生成 AI には、以前のテクノロジーが生成するよりも複雑な出力が必要であると考える専門家もいます。
予測 ML と対比する。
I
画像認識
画像内のオブジェクト、パターン、コンセプトを分類するプロセス。画像認識は画像分類とも呼ばれます。
詳細については、ML 演習: 画像分類をご覧ください。
IoU(IoU)
2 つの集合の積を和の和で割った部分。ML の画像検出タスクでは、IoU を使用して、モデルの予測された境界ボックスについて、グラウンド トゥルース境界ボックスの精度を測定します。この場合、2 つのボックスの IoU は重なり合う領域と合計領域の比率になり、その値の範囲は 0(予測境界ボックスと正解境界ボックスの重複なし)から 1(予測境界ボックスと正解境界ボックスの座標が完全に同じ)です。
たとえば、下の画像では、次のようになります。
- 予測された境界ボックス(ペイントの夜間テーブルが配置されるとモデルが予測する場所の区切る座標)は紫色で囲まれています。
- グラウンド トゥルースの境界ボックス(ペイントのナイトテーブルが実際に配置されている場所を区切る座標)は緑色の枠で囲まれています。
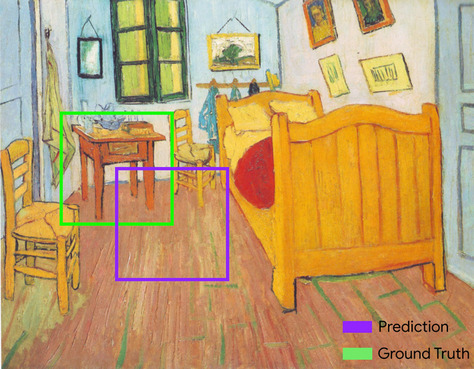
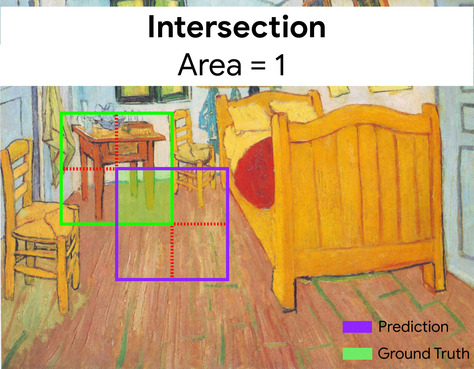
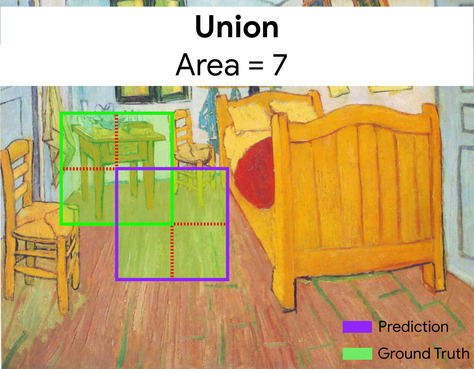
ここで、予測と正解の境界ボックスの交差(左下)は 1、予測と正解の境界ボックス(右下)の和集合は 7 であるため、IoU は \(\frac{1}{7}\)です。
K
キーポイント
画像内の特定の対象物の座標。たとえば、花の種を識別する画像認識モデルの場合、各花びらの中心、茎、おしりなどがキーポイントになります。
L
landmarks
キーポイントと同義です。
M
MNIST
LeCun、Cortes、Burges がコンパイルしたパブリック ドメインのデータセット。60,000 枚の画像が含まれています。各画像は、人間が 0 ~ 9 の特定の数字を手作業で書いた方法を示しています。各画像は 28x28 の整数の配列として保存されます。各整数は 0 ~ 255 のグレースケール値です。
MNIST は ML の正規データセットであり、新しい ML アプローチのテストによく使用されます。詳しくは、 The MNIST Database of Handsigned Digits をご覧ください。
P
プーリング
以前の畳み込み層によって作成された行列をより小さな行列に縮小する。プーリングでは通常、プールされた領域全体の最大値または平均値を取得します。たとえば、次の 3x3 マトリックスがあるとします。
![3x3 行列 [[5,3,1], [8,2,5], [9,4,3]]。](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?authuser=2&hl=ja)
プーリング演算は、畳み込み演算と同様に、その行列をスライスに分割し、その畳み込み演算をストライドでスライドします。たとえば、プーリング演算によって畳み込み行列が 1x1 のストライドで 2x2 のスライスに分割されたとします。次の図に示すように、4 つのプーリング オペレーションが行われます。各プーリング オペレーションで、そのスライス内の 4 つの最大値が選択されるとします。
![入力行列は 3x3 で、値は [[5,3,1], [8,2,5], [9,4,3]] です。入力行列の左上の 2x2 サブ行列は [[5,3], [8,2]] であるため、左上のプーリング演算により値 8(5、3、8、2 の最大値)が生成されます。入力行列の右上の 2x2 サブ行列は [[3,1], [2,5]] であるため、右上のプーリング演算により値 5 が生成されます。入力行列の左下の 2x2 サブ行列は [[8,2], [9,4]] であるため、左下のプーリング演算では値 9 が生成されます。入力行列の右下の 2x2 サブ行列は [[2,5], [4,3]] であるため、右下のプーリング演算により値 5 が生成されます。まとめると、プーリング演算により 2 × 2 の行列 [[8,5], [9,5]] が得られます。](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=2&hl=ja)
プーリングにより、入力行列の翻訳不変性を適用できます。
ビジョン アプリケーション用のプーリングは、より正式には空間プーリングと呼ばれています。通常、時系列アプリケーションでは、プーリングを「時間プーリング」と呼びます。やや形式的には、プーリングは「サブサンプリング」または「ダウンサンプリング」と呼ばれることもあります。
事前トレーニング済みモデル
トレーニング済みのモデルまたはモデル コンポーネント(エンベディング ベクトルなど)。事前トレーニング済みのエンベディング ベクトルをニューラル ネットワークにフィードすることもあります。また、事前にトレーニングされたエンベディングに依存せずに、モデルがエンベディング ベクトル自体をトレーニングする場合もあります。
事前トレーニング済み言語モデルという用語は、事前トレーニングが実施されている大規模言語モデルを指します。
事前トレーニング
大規模なデータセットでのモデルの初期トレーニング。一部の事前トレーニング済みモデルは扱いにくいため、通常は追加のトレーニングによって改良する必要があります。たとえば、ML のエキスパートは、膨大なテキスト データセット(Wikipedia の全英語ページなど)で大規模言語モデルを事前にトレーニングできます。結果として得られるモデルは、事前トレーニングの後、次のいずれかの手法でさらに細かく調整できます。
R
回転不変性
画像分類問題で、画像の向きが変化しても画像を正常に分類するアルゴリズムの能力。たとえば、アルゴリズムはテニスラケットが上、横向き、下を向いているかどうかを識別できます。回転不変性は必ずしも望ましいものではありません。たとえば、逆さまの 9 は 9 に分類すべきではありません。
S
サイズの不変性
画像分類問題で、画像のサイズが変化しても画像を正常に分類するアルゴリズムの能力。たとえば、消費ピクセルが 2M と 200K のどちらでも猫を識別できます。ただし、優れた画像分類アルゴリズムであっても、サイズの不変性には実質的な上限があります。たとえば、アルゴリズム(または人間)が 20 ピクセルしかない猫の画像を正しく分類する可能性は低くなります。
空間プーリング
プーリングをご覧ください。
ストライド
畳み込み演算またはプーリングでは、次の一連の入力スライスの各次元におけるデルタ。たとえば、次のアニメーションは、畳み込み演算中の(1,1)ストライドを示しています。したがって、次の入力スライスは、前の入力スライスの 1 つ右の位置から開始します。演算が右端に到達すると、次のスライスは左端まで達しますが、1 つ下の位置まで来ます。
上記の例は 2 次元のストライドを示しています。入力行列が 3 次元の場合、ストライドも 3 次元になります。
サブサンプリング
プーリングをご覧ください。
T
温度
モデルの出力のランダム性の度合いを制御するハイパーパラメータ。温度が高いほどランダム出力は多くなり、温度を低くするとランダム出力は少なくなります。
最適な温度を選択できるかどうかは、特定のアプリケーションと、モデル出力の望ましいプロパティによって異なります。たとえば、クリエイティブな出力を生成するアプリケーションを作成する際に、おそらく温度を上げます。逆に、画像やテキストを分類するモデルを構築する場合は、モデルの精度と一貫性を向上させるために温度を下げる可能性があります。
温度はソフトマックスでよく使用されます。
並進不変性
画像分類問題で、画像内のオブジェクトの位置が変化しても画像を正常に分類するアルゴリズムの能力。たとえば、フレームの中心かフレームの左端かにかかわらず、アルゴリズムは犬を識別できます。