इस पेज में इमेज मॉडल के शब्दावली शब्द हैं. शब्दावली के सभी शब्दों के लिए, यहां क्लिक करें.
जवाब
बढ़ी हुई वास्तविकता
ऐसी टेक्नोलॉजी जो कंप्यूटर से जनरेट की गई इमेज को, उपयोगकर्ता के असल दुनिया के नज़रिए पर ले जाती है, जिससे एक कंपोज़िट व्यू मिलता है.
ऑटो-एन्कोडर
ऐसा सिस्टम जो इनपुट से सबसे अहम जानकारी निकालने के बारे में सीखता है. ऑटोएनकोडर, एन्कोडर और डीकोडर के कॉम्बिनेशन होते हैं. ऑटोएन्कोडर, नीचे दी गई दो चरणों वाली प्रोसेस पर निर्भर करते हैं:
- एन्कोडर, इनपुट को (आम तौर पर) नुकसान पहुंचाने वाले लोअर डाइमेंशन (इंटरमीडिएट) फ़ॉर्मैट में मैप करता है.
- डिकोडर, कम डाइमेंशन वाले फ़ॉर्मैट को हाई-डाइमेंशन इनपुट फ़ॉर्मैट से मैप करके, ओरिजनल इनपुट का नुकसानदेह वर्शन बनाता है.
ऑटोकोडर को एंड-टू-एंड ट्रेनिंग दी जाती है. इसके लिए, डिकोडर टूल की मदद से, एन्कोडर के इंटरमीडिएट फ़ॉर्मैट से ओरिजनल इनपुट को हर तरह के रखने की कोशिश की जाती है. इंटरमीडिएट फ़ॉर्मैट, ओरिजनल फ़ॉर्मैट की तुलना में छोटा (लोअर-डाइमेंशन) होता है. इसलिए, ऑटोएनकोडर को यह सीखने के लिए मजबूर किया जाता है कि इनपुट में कौनसी जानकारी ज़रूरी है और आउटपुट इनपुट से पूरी तरह मेल नहीं खाता.
उदाहरण के लिए:
- अगर इनपुट डेटा ग्राफ़िक है, तो बिलकुल सटीक कॉपी मूल ग्राफ़िक की तरह होगी, लेकिन कुछ हद तक उसमें बदलाव किया गया होगा. ऐसा भी हो सकता है कि सटीक कॉपी न होने पर ओरिजनल ग्राफ़िक से शोर को हटा दें या कुछ पिक्सल में जानकारी भर दें.
- अगर इनपुट डेटा टेक्स्ट है, तो ऑटोएन्कोडर ऐसा नया टेक्स्ट जनरेट करेगा जो ओरिजनल टेक्स्ट की नकल करता हो, लेकिन ओरिजनल टेक्स्ट जैसा न हो.
अलग-अलग तरह के ऑटोएन्कोडर भी देखें.
ऑटो-रिग्रेसिव मॉडल
ऐसा model जो अपने पिछले अनुमानों के आधार पर किसी अनुमान का अनुमान लगाता है. उदाहरण के लिए, ऑटो-रिग्रेसिव लैंग्वेज मॉडल, पहले अनुमानित टोकन के आधार पर अगले टोकन का अनुमान लगाते हैं. ट्रांसफ़ॉर्मर पर आधारित सभी बड़े लैंग्वेज मॉडल, ऑटो-रिग्रेसिव होते हैं.
वहीं दूसरी ओर, GAN पर आधारित इमेज मॉडल आम तौर पर ऑटो-रिग्रेसिव नहीं होते, क्योंकि वे एक ही फ़ॉरवर्ड-पास में इमेज जनरेट करते हैं और बार-बार ऐसे ही चरणों में नहीं बनाए जाते. हालांकि, कुछ इमेज जनरेशन मॉडल ऑटो-रिग्रेसिव होते हैं, क्योंकि वे चरणों में इमेज जनरेट करते हैं.
B
बाउंडिंग बॉक्स
एक इमेज में, दिलचस्पी वाली जगह के चारों ओर एक रेक्टैंगल के (x, y) निर्देशांक, जैसे कि नीचे दी गई इमेज में कुत्ते का नाम.

C
कॉन्वलूशन
गणित में, सामान्य तौर पर, दो फलनों का मिश्रण. मशीन लर्निंग में, कॉन्वोलूशन, कंवोलूशनल फ़िल्टर और इनपुट मैट्रिक्स को मिलाता है, ताकि वज़न को ट्रेनिंग दी जा सके.
मशीन लर्निंग में "कॉन्वोल्यूशन" शब्द, अक्सर कॉन्वोलूशनल ऑपरेशन या कॉन्वोलूशनल लेयर के बारे में बताने का आसान तरीका होता है.
कॉन्वलूशन के बिना, मशीन लर्निंग एल्गोरिदम को बड़े टेन्सर में हर सेल के लिए अलग वज़न सीखना होगा. उदाहरण के लिए, 2K x 2K इमेज पर ट्रेनिंग लेने वाले मशीन लर्निंग एल्गोरिदम को 4M अलग-अलग वेट ढूंढने के लिए मजबूर किया जाएगा. कॉन्वलूशन की वजह से, मशीन लर्निंग एल्गोरिदम को कंवोल्यूशनल फ़िल्टर में मौजूद हर सेल के लिए वेट का पता लगाना पड़ता है. इससे मॉडल को ट्रेनिंग देने के लिए ज़रूरी मेमोरी काफ़ी कम हो जाती है. जब कॉन्वलूशनल फ़िल्टर को लागू किया जाता है, तो उसकी कॉपी को सेल पर इस तरह से दोहराया जाता है कि हर सेल को फ़िल्टर से गुणा किया जाए.
कॉन्वलूशनल फ़िल्टर
कॉन्वलेशनल ऑपरेशन में काम कर रहे दो अभिनेताओं में से एक. (दूसरा ऐक्टर इनपुट मैट्रिक्स का एक हिस्सा है.) कॉन्वलूशनल फ़िल्टर, ऐसा मैट्रिक्स होता है जिसका रैंक इनपुट मैट्रिक्स जैसा ही होता है. हालांकि, इसका आकार छोटा होता है. उदाहरण के लिए, अगर 28x28 इनपुट मैट्रिक्स दिया गया है, तो फ़िल्टर 28x28 से छोटा कोई भी 2D मैट्रिक्स हो सकता है.
फ़ोटोग्राफ़िक मैनिप्यूलेशन में, कॉन्वलूशनल फ़िल्टर में मौजूद सभी सेल आम तौर पर एक और शून्य के कॉन्स्टेंट पैटर्न पर सेट होती हैं. मशीन लर्निंग में, कन्वर्ज़न वाले फ़िल्टर आम तौर पर रैंडम नंबर के साथ शामिल किए जाते हैं और फिर नेटवर्क सही वैल्यू को ट्रेन करता है.
कॉन्वलूशनल लेयर
डीप न्यूरल नेटवर्क की एक लेयर, जिसमें कंवोलूशनल फ़िल्टर किसी इनपुट मैट्रिक्स के साथ पास होता है. उदाहरण के लिए, यहां दिए गए 3x3 कॉन्वोलूशनल फ़िल्टर का इस्तेमाल करें:
![इन वैल्यू का 3x3 वाला मैट्रिक्स: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=2&hl=hi)
नीचे दिए गए ऐनिमेशन में एक कन्वलूशनल लेयर दिखाई गई है, जिसमें 5x5 इनपुट मैट्रिक्स वाले नौ कन्वर्ज़न हैं. ध्यान दें कि हर कन्वर्ज़न ऐक्शन, इनपुट मैट्रिक्स के अलग-अलग 3x3 स्लाइस पर काम करता है. बनने वाले 3x3 मैट्रिक्स (दाईं ओर) में, नौ कन्वर्ज़न कार्रवाइयों के नतीजे होते हैं:
![दो मैट्रिक्स दिखाने वाला ऐनिमेशन. पहला मैट्रिक्स 5x5
मैट्रिक्स है: [[1,28,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,174,1.7], [33,97,53,201,198],
दूसरा मैट्रिक्स 3x3 मैट्रिक्स है:
[[1,81,303,618], [1,15,338,605], [16,93,51,560]].
दूसरे मैट्रिक्स का हिसाब, 5x5 के अलग-अलग 3x3 सबसेट में कॉन्वलूशनल
फ़िल्टर [[0, 1, 0], [1, 0, 1], [0, 1, 0]] लगाकर लगाया जाता है.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=2&hl=hi)
कॉन्वलूशनल न्यूरल नेटवर्क
न्यूरल नेटवर्क, जिसमें कम से कम एक लेयर, कंवोल्यूशनल लेयर होती है. किसी सामान्य कॉन्वलूशनल न्यूरल नेटवर्क में नीचे दी गई लेयर के कुछ कॉम्बिनेशन होते हैं:
कॉन्वोलूशनल न्यूरल नेटवर्क को इमेज पहचानने जैसी कुछ समस्याओं में काफ़ी सफलता मिली है.
कॉन्वलूशनल ऑपरेशन
नीचे दिए गए दो चरणों वाले गणितीय तरीके:
- कॉन्वोलूशनल फ़िल्टर और किसी इनपुट मैट्रिक्स के स्लाइस के एलिमेंट के हिसाब से गुणा करना. (इनपुट मैट्रिक्स के स्लाइस की रैंक और साइज़ वही होता है जो कॉन्वलूशनल फ़िल्टर की होती है.)
- प्रॉडक्ट मैट्रिक्स में सभी वैल्यू का योग.
उदाहरण के लिए, नीचे दिए गए 5x5 इनपुट मैट्रिक्स पर विचार करें:
![5x5 मैट्रिक्स: [[1,28,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,719].1,](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=2&hl=hi)
अब नीचे दिए गए 2x2 कॉन्वलूशनल फ़िल्टर की कल्पना करें:
![2x2 मैट्रिक्स: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=2&hl=hi)
हर कन्वलूशनल ऑपरेशन में इनपुट मैट्रिक्स का एक 2x2 स्लाइस होता है. उदाहरण के लिए, मान लें कि हम इनपुट मैट्रिक्स के ऊपर बाईं ओर 2x2 स्लाइस का इस्तेमाल करते हैं. इसलिए, इस स्लाइस पर कन्वर्ज़न ऑपरेशन इस तरह दिखता है:
![इनपुट मैट्रिक्स के सबसे ऊपर बाईं ओर 2x2 सेक्शन में, कॉन्वलूशनल फ़िल्टर [[1, 0], [0, 1]] लागू किया जा रहा है, जो [[1,28,97], [35,22]] है.
कॉन्वलूशनल फ़िल्टर, 128 और 22 को पहले की तरह बना देता है, लेकिन
97 और 35 को शून्य कर देता है. इस वजह से, कन्वर्ज़न की वैल्यू 150 (128+22) मिलती है.](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=2&hl=hi)
कॉन्वोलूशनल लेयर में कॉन्वलूशनल ऑपरेशन की सीरीज़ होती है. हर कार्रवाई, इनपुट मैट्रिक्स के अलग स्लाइस पर काम करती है.
D
डेटा में सुधार
ट्रेनिंग के उदाहरणों की रेंज और उनकी संख्या को आर्टिफ़िशियल तरीके से बढ़ावा देना. इसके लिए, मौजूदा उदाहरणों को बदलकर कोई और उदाहरण बनाया जा सकता है. उदाहरण के लिए, मान लें कि इमेज आपकी सुविधाओं में से एक हैं, लेकिन आपके डेटासेट में मॉडल के लिए, काम के असोसिएशन सीखने के लिए, इमेज के ज़रूरी उदाहरण नहीं हैं. आम तौर पर, आपको अपने डेटासेट में लेबल वाली ज़रूरत के मुताबिक इमेज जोड़नी होंगी, ताकि मॉडल को सही तरीके से ट्रेन किया जा सके. अगर ऐसा नहीं किया जा सकता, तो डेटा को बेहतर बनाने की सुविधा हर इमेज को घुमा सकती है, फैला सकती है, और दिखा सकती है, ताकि मूल तस्वीर के कई वैरिएंट बनाए जा सकें. इससे बेहतरीन ट्रेनिंग चालू करने के लिए, लेबल किया गया डेटा मिल सकता है.
डेप्थवाइज़ सेपरेबल कॉन्वलूशनल न्यूरल नेटवर्क (sepCNN)
कंवोलूशनल न्यूरल नेटवर्क इनसेप्शन पर आधारित एक आर्किटेक्चर है. हालांकि, इसमें इंसेप्शन मॉड्यूल को बेहतर तरीके से अलग किए जा सकने वाले कॉन्वलेशन से बदला जाता है. इसे Xसेप्शन के नाम से भी जाना जाता है.
गहराई से अलग किए जा सकने वाले कन्वलूशन (इसे अलग किए जा सकने वाले कन्वलूशन भी कहा जाता है) से, स्टैंडर्ड 3D कन्वलूशन को दो अलग-अलग कन्वलूशन ऑपरेशंस में शामिल किया जाता है. ये कंप्यूटेशन के हिसाब से ज़्यादा असरदार होते हैं: पहला, ज़्यादा गहराई वाला कॉन्वलूशन, जिसमें एक की डेप्थ (न गु गु गुन 1 1) और फिर दूसरी नंबर 1 पॉइंट की चौड़ाई के साथ.
ज़्यादा जानने के लिए, Xception: Deep Learning के साथ डेप्थवाइज़ सेपरेबल कन्वर्ज़न लेख पढ़ें.
डाउनसैंपलिंग
इन शब्दों में से किसी एक का मतलब ओवरलोड हो सकता है:
- किसी मॉडल को ज़्यादा बेहतर तरीके से ट्रेन करने के लिए, सुविधा में जानकारी की मात्रा कम करना. उदाहरण के लिए, इमेज पहचानने वाले मॉडल को ट्रेनिंग देने से पहले, हाई रिज़ॉल्यूशन वाली इमेज को लो-रिज़ॉल्यूशन वाले फ़ॉर्मैट में डाउनसैंपल करना.
- क्लास में ज़्यादा प्रतिनिधित्व किए गए उदाहरणों के आधार पर ट्रेनिंग करना. इसका मकसद उन क्लास के लिए मॉडल ट्रेनिंग को बेहतर बनाना है जिन्हें ज़्यादा लोग नहीं देते. उदाहरण के लिए, किसी क्लास-असंतुलित डेटासेट में, मॉडल मॉजरिटी क्लास के बारे में काफ़ी जानकारी हासिल करते हैं और अल्पसंख्यक क्लास के बारे में काफ़ी जानकारी नहीं देते. डाउनसैंपलिंग से, बहुसंख्यक और अल्पसंख्यक क्लास के बीच मिलने वाली ट्रेनिंग को संतुलित रखने में मदद मिलती है.
म॰
फ़ाइन ट्यूनिंग
दूसरा, टास्क के हिसाब से दिया जाने वाला ट्रेनिंग पास, जिसे पहले से ट्रेनिंग दिए गए मॉडल पर परफ़ॉर्म किया जाता है, ताकि इस्तेमाल के किसी खास उदाहरण के लिए पैरामीटर बेहतर बनाए जा सकें. उदाहरण के लिए, कुछ बड़े लैंग्वेज मॉडल की ट्रेनिंग का पूरा सीक्वेंस इस तरह है:
- प्री-ट्रेनिंग: एक बड़े सामान्य डेटासेट पर एक बड़े लैंग्वेज मॉडल को ट्रेनिंग दें, जैसे कि अंग्रेज़ी भाषा वाले सभी Wikipedia पेज.
- बेहतर ट्यूनिंग: पहले से ट्रेनिंग वाले मॉडल को कोई खास टास्क करने के लिए ट्रेनिंग दें, जैसे कि चिकित्सा से जुड़ी क्वेरी का जवाब देना. आम तौर पर, फ़ाइन-ट्यूनिंग में किसी खास टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण होते हैं.
एक अन्य उदाहरण में, बड़े इमेज मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- प्री-ट्रेनिंग: एक बड़े सामान्य इमेज डेटासेट का इस्तेमाल करके, एक बड़े इमेज मॉडल को ट्रेनिंग दें, जैसे कि Wikimedia Commons में मौजूद सभी इमेज.
- बेहतर ट्यूनिंग: पहले से ट्रेनिंग वाले मॉडल को कोई खास काम करने के लिए ट्रेनिंग दें, जैसे कि ओरका की इमेज जनरेट करना.
फ़ाइन-ट्यूनिंग के लिए, नीचे दी गई रणनीतियों का कोई भी कॉम्बिनेशन लागू हो सकता है:
- पहले से ट्रेन किए गए मॉडल के सभी मौजूदा पैरामीटर में बदलाव करना. इसे कभी-कभी फ़ुल फ़ाइन-ट्यूनिंग भी कहा जाता है.
- पहले से ट्रेनिंग वाले मॉडल के सिर्फ़ कुछ मौजूदा पैरामीटर में बदलाव किया जाता है (आम तौर पर, आउटपुट लेयर के सबसे करीब की लेयर). आम तौर पर, अन्य मौजूदा पैरामीटर में कोई बदलाव नहीं किया जाता है. आम तौर पर, ये लेयर इनपुट लेयर के आस-पास होती हैं. पैरामीटर की बेहतर ट्यूनिंग देखें.
- ज़्यादा लेयर जोड़ना, आम तौर पर आउटपुट लेयर के सबसे करीब मौजूद लेयर के ऊपर.
फ़ाइन-ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन-ट्यूनिंग किसी अलग तरह के नुकसान फ़ंक्शन या मॉडल टाइप का इस्तेमाल कर सकती है, जो पहले से ट्रेन किए गए मॉडल को ट्रेनिंग देने वाले फ़ंक्शन से अलग होता है. उदाहरण के लिए, पहले से ट्रेनिंग वाले बड़े इमेज मॉडल को ट्यून किया जा सकता है, ताकि ऐसा रिग्रेशन मॉडल बनाया जा सके जो इनपुट इमेज में पक्षियों की संख्या दिखाता हो.
इन शब्दों से फ़ाइन-ट्यूनिंग की तुलना करें और इनके बीच अंतर बताएं:
G
जनरेटिव एआई
शिक्षा से जुड़ा एक उभरता हुआ फ़ील्ड, जिसमें औपचारिक परिभाषा शामिल नहीं है. ज़्यादातर विशेषज्ञों का मानना है कि जनरेटिव एआई मॉडल ऐसा कॉन्टेंट बना सकते हैं ("जनरेट") हो सकता है जो नीचे बताई गई बातों में से कोई भी हो:
- जटिल
- अनुकूल
- मूल
उदाहरण के लिए, जनरेटिव एआई मॉडल, बेहतरीन निबंध या इमेज बना सकता है.
कुछ पुरानी टेक्नोलॉजी भी ओरिजनल और दिलचस्प कॉन्टेंट जनरेट कर सकती हैं. इनमें एलएसटीएम और आरएनएन शामिल हैं. कुछ विशेषज्ञ इन शुरुआती टेक्नोलॉजी को जनरेटिव एआई मानते हैं. हालांकि, कुछ लोगों का मानना है कि जनरेटिव एआई के मुकाबले ज़्यादा मुश्किल आउटपुट की ज़रूरत होती है.
अनुमानित एमएल की सेटिंग के बीच अंतर करें.
I
इमेज पहचानने की सुविधा
किसी इमेज में ऑब्जेक्ट, पैटर्न या कॉन्सेप्ट को कैटगरी में बांटने वाली प्रोसेस. इमेज की पहचान करने की सुविधा को इमेज क्लासिफ़िकेशन भी कहा जाता है.
ज़्यादा जानकारी के लिए, एमएल प्रैक्टिकल: इमेज क्लासिफ़िकेशन लेख पढ़ें.
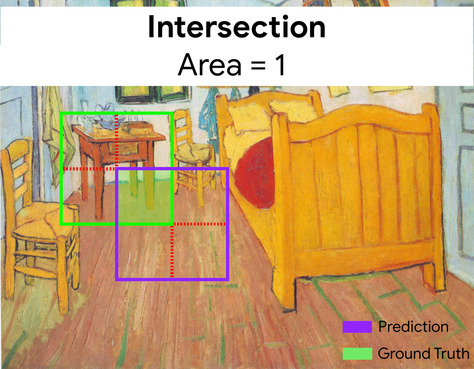
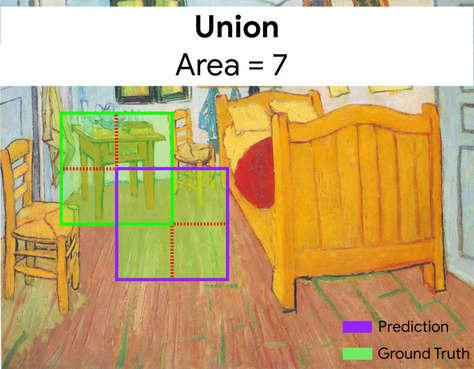
इंटरसेक्शन ओवर यूनियन (IoU)
दो सेट का इंटरसेक्शन, जो उनके यूनियन से भाग दिया गया है. मशीन लर्निंग की मदद से इमेज की पहचान करने वाले टास्क में, ग्राउंड-ट्रुथ बाउंडिंग बॉक्स के हिसाब से, IoU का इस्तेमाल करके मॉडल के अनुमानित बाउंडिंग बॉक्स के सटीक होने का आकलन किया जाता है. इस मामले में, दो बॉक्स के लिए IoU, ओवरलैप होने वाले इलाके और कुल क्षेत्रफल के बीच का अनुपात है और इसकी वैल्यू 0 से है (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रूथ बाउंडिंग बॉक्स का ओवरलैप नहीं) से 1 (अनुमानित बाउंडिंग बॉक्स और ग्राउंड-ट्रुथ बाउंडिंग बॉक्स के निर्देशांक बिलकुल एक जैसे होते हैं).
उदाहरण के लिए, नीचे दी गई इमेज में:
- अनुमानित बाउंडिंग बॉक्स बैंगनी रंग में दिखाया गया है. बाउंडिंग बॉक्स (पेंटिंग में मौजूद रात की टेबल के उस हिस्से को दिखाने वाले निर्देशांक) बैंगनी रंग में दिखाया गया है.
- ज़मीनी सतह को बाउंडिंग बॉक्स (पेंटिंग में मौजूद रात की टेबल को दिखाने वाले निर्देशांक) हरे रंग से आउटलाइन किया गया है.
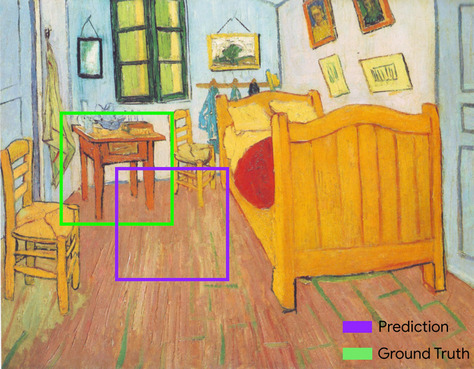
यहां, अनुमान और ज़मीनी जानकारी के लिए बाउंडिंग बॉक्स का इंटरसेक्शन (बाईं ओर नीचे) एक है. अनुमान और तथ्यों की जानकारी के लिए बाउंडिंग बॉक्स का यूनियन 7 है, इसलिए IoU \(\frac{1}{7}\)है.
K
कीपॉइंट
किसी इमेज में मौजूद खास सुविधाओं के निर्देशांक. उदाहरण के लिए, फूलों की प्रजातियों की पहचान करने वाले इमेज की पहचान करने वाले मॉडल के लिए, हर पंखुड़ी, डंठल, और स्टैमन वगैरह के बीच के पॉइंट, मुख्य पॉइंट हो सकते हैं.
L
लैंडमार्क
कीपॉइंट के लिए समानार्थी शब्द.
सोम
एमएनआईएसटी
LeCun, Cortes, और Burges ने एक सार्वजनिक-डोमेन डेटासेट इकट्ठा किया है,जिसमें 60, 000 इमेज हैं. हर इमेज में दिखाया गया है कि किसी व्यक्ति ने 0 से 9 तक के अंकों को मैन्युअल तरीके से कैसे लिखा. हर इमेज को पूर्णांकों की 28x28 कलेक्शन के तौर पर सेव किया जाता है. यहां हर पूर्णांक, 0 से 255 के बीच की ग्रेस्केल वैल्यू होती है.
एमएनआईएसटी, मशीन लर्निंग के लिए एक कैननिकल डेटासेट है. इसका इस्तेमाल अक्सर मशीन लर्निंग के नए तरीकों की जांच करने के लिए किया जाता है. ज़्यादा जानकारी के लिए, हाथ से लिखे हुए अंकों का MNIST डेटाबेस देखें.
P
पूलिंग
किसी पहले वाली कंवोलूशनल लेयर से बनाए गए मैट्रिक्स (या मैट्रिक्स) को छोटा करके. आम तौर पर, पूल करने की जगह में पूल की गई जगह के लिए, ज़्यादा से ज़्यादा या औसत वैल्यू ली जाती है. उदाहरण के लिए, मान लें कि हमारे पास नीचे दिया गया 3x3 मैट्रिक्स है:
![3x3 मैट्रिक्स [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?authuser=2&hl=hi)
किसी पूलिंग ऑपरेशन की तरह ही पूलिंग ऑपरेशन, उस मैट्रिक्स को स्लाइस में बांटता है और फिर उस कॉन्वलूशनल ऑपरेशन को स्ट्रेड के ज़रिए स्लाइड करता है. उदाहरण के लिए, मान लें कि पूलिंग ऑपरेशन कॉन्वलूशनल मैट्रिक्स को 1x1 स्ट्राइड के साथ 2x2 स्लाइस में बांटता है. जैसा कि नीचे दिए गए डायग्राम में दिखाया गया है, पूल करने की चार कार्रवाइयां होती हैं. मान लें कि पूल करने की हर कार्रवाई, उस स्लाइस में चार की ज़्यादा से ज़्यादा वैल्यू चुनता है:
![इनपुट मैट्रिक्स 3x3 है, जिसकी वैल्यू हैं: [[5,3,1], [8,2,5], [9,4,3]].
इनपुट मैट्रिक्स का सबसे ऊपर बाईं ओर मौजूद 2x2 सबमैट्रिक्स [[5,3], [8,2]] होता है. इसलिए,
सबसे ऊपर बाईं ओर मौजूद पूल करने की कार्रवाई से, वैल्यू 8 मिलती है. वैल्यू 5, 3, 8, और 2 हो सकती हैं. इनपुट मैट्रिक्स का सबसे ऊपर दाईं ओर 2x2 सबमैट्रिक्स [[3,1], [2,5]] है, इसलिए सबसे ऊपर दाईं ओर पूल करने की कार्रवाई से
वैल्यू 5 मिलती है. इनपुट मैट्रिक्स का सबसे नीचे बाईं ओर मौजूद 2x2 सबमैट्रिक्स [[8,2], [9,4]] होता है. इसलिए, सबसे नीचे बाईं ओर मौजूद पूलिंग ऑपरेशन की वैल्यू 9 होती है. इनपुट मैट्रिक्स का सबसे नीचे दाईं ओर का 2x2 सबमैट्रिक्स [[2,5], [4,3]] है, इसलिए सबसे नीचे दाईं ओर के पूलिंग ऑपरेशन की वैल्यू
5 मिलती है. संक्षेप में, पूल करने की कार्रवाई से 2x2 मैट्रिक्स मिलता है
[[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=2&hl=hi)
पूल करने की सुविधा से, इनपुट मैट्रिक्स में ट्रांसलेशनल इनवैरियंस लागू करने में मदद मिलती है.
विज़न ऐप्लिकेशन के लिए पूलिंग को औपचारिक तौर पर स्पेशल पूलिंग के नाम से जाना जाता है. टाइम सीरीज़ वाले ऐप्लिकेशन, आम तौर पर पूल करने की सुविधा को टेंपोरल पूलिंग कहते हैं. औपचारिक तौर पर, पूलिंग को सबसैंपलिंग या डाउनसैंपलिंग कहा जाता है.
पहले से ट्रेन किया गया मॉडल
पहले से ट्रेनिंग दिए गए मॉडल या मॉडल कॉम्पोनेंट, जैसे कि एम्बेड करने वाला वेक्टर. कभी-कभी, पहले से ट्रेनिंग वाले एम्बेडिंग वेक्टर को न्यूरल नेटवर्क में फ़ीड किया जाएगा. कभी-कभी, आपका मॉडल पहले से ट्रेन किए गए एम्बेड करने के बजाय, एम्बेड किए गए वेक्टर को खुद ही ट्रेनिंग देगा.
पहले से ट्रेन की गई लैंग्वेज मॉडल शब्द का मतलब बड़े लैंग्वेज मॉडल से है, जिसे प्री-ट्रेनिंग से गुज़रना पड़ा.
प्री-ट्रेनिंग
बड़े डेटासेट पर किसी मॉडल की शुरुआती ट्रेनिंग. कुछ पहले से ट्रेनिंग पा चुके मॉडल पुराने जायंट होते हैं. आम तौर पर, उन्हें अतिरिक्त ट्रेनिंग की मदद से और बेहतर बनाया जाता है. उदाहरण के लिए, मशीन लर्निंग एक्सपर्ट एक बड़े टेक्स्ट डेटासेट, जैसे कि Wikipedia के सभी अंग्रेज़ी पेजों पर बड़े लैंग्वेज मॉडल को प्री-ट्रेन कर सकते हैं. प्री-ट्रेनिंग के बाद, तैयार करने वाले मॉडल को नीचे दी गई किसी भी तकनीक का इस्तेमाल करके और बेहतर बनाया जा सकता है:
R
रोटेशनल इनवैरियंस
इमेज क्लासिफ़िकेशन से जुड़ी समस्या में, इमेज का ओरिएंटेशन बदलने पर भी एल्गोरिदम की इमेज की कैटगरी तय करने की क्षमता होती है. उदाहरण के लिए, एल्गोरिदम अब भी टेनिस रैकेट की पहचान कर सकता है, चाहे वह ऊपर की ओर, बगल में या नीचे की ओर इशारा कर रहा हो. ध्यान दें कि हर बार रोटेशन इनवैरियंस की ज़रूरत नहीं होती; उदाहरण के लिए, अपसाइड-डाउन 9 को 9 के तौर पर नहीं माना जाना चाहिए.
ट्रांसलेशनल इनवैरियंस और साइज़ इनवैरियंस भी देखें.
S
साइज़ इनवैरिएंस
इमेज क्लासिफ़िकेशन से जुड़ी समस्या में, इमेज का साइज़ बदलने पर भी एल्गोरिदम इमेज की कैटगरी तय कर पाता है. उदाहरण के लिए, एल्गोरिदम अब भी बिल्ली की पहचान कर सकता है कि वह 2M पिक्सल का इस्तेमाल करती है या 200K पिक्सल का. ध्यान रखें कि इमेज की कैटगरी तय करने वाले सबसे अच्छे एल्गोरिदम में भी, साइज़ के वैरिएंट की व्यावहारिक सीमाएं होती हैं. उदाहरण के लिए, हो सकता है कि कोई एल्गोरिदम (या इंसान) सिर्फ़ 20 पिक्सल वाली बिल्ली की इमेज को सही तरीके से कैटगरी में बांट दे.
ट्रांसलेशनल इनवैरियंस और रोटेटेशनल इनवैरियंस भी देखें.
स्पेशल पूलिंग
पूलिंग देखें.
स्ट्राइड
कॉन्वलूशनल ऑपरेशन या पूलिंग में, इनपुट स्लाइस की अगली सीरीज़ के हर डाइमेंशन में डेल्टा. उदाहरण के लिए, नीचे दिया गया ऐनिमेशन, कॉन्वलूशनल ऑपरेशन के दौरान एक (1,1) स्ट्रोक दिखाता है. इसलिए, अगले इनपुट स्लाइस, पिछले इनपुट स्लाइस के दाईं ओर एक पोज़िशन शुरू करता है. जब कार्रवाई दाएं किनारे पर पहुंच जाती है, तो अगला स्लाइस बाईं ओर हो जाता है, लेकिन एक जगह नीचे.
पिछला उदाहरण द्वि-आयामी चाल दिखाता है. अगर इनपुट मैट्रिक्स तीन डाइमेंशन वाला है, तो स्ट्रेड भी तीन डाइमेंशन वाला होगा.
सबसैंपलिंग
पूलिंग देखें.
T
तापमान
हाइपर पैरामीटर, जो मॉडल के आउटपुट की रैंडमनेस की डिग्री को कंट्रोल करता है. ज़्यादा तापमान होने से आउटपुट ज़्यादा अनियमित होता है, जबकि कम तापमान से आउटपुट कम मिलता है.
सबसे अच्छा तापमान चुनना, किस ऐप्लिकेशन और मॉडल के आउटपुट के पसंदीदा प्रॉपर्टी पर निर्भर करता है. उदाहरण के लिए, क्रिएटिव आउटपुट जनरेट करने वाला ऐप्लिकेशन बनाते समय शायद आप तापमान बढ़ा दें. इसके ठीक उलट, ऐसा मॉडल बनाते समय तापमान को कम किया जाएगा जो इमेज या टेक्स्ट की कैटगरी तय करने वाला मॉडल बनाता है, ताकि मॉडल को ज़्यादा सटीक और एक जैसा बनाया जा सके.
तापमान की जानकारी अक्सर सॉफ़्टमैक्स के साथ इस्तेमाल की जाती है.
ट्रांसलेशनल इनवैरियंस
इमेज क्लासिफ़िकेशन से जुड़ी समस्या में, इमेज में ऑब्जेक्ट की जगह बदलने पर भी एल्गोरिदम की इमेज को सही कैटगरी में बांटने की काबिलीयत. जैसे, एल्गोरिदम अब भी कुत्ते की पहचान कर सकता है, चाहे वह फ़्रेम के बीच में हो या फ़्रेम के बाईं ओर हो.
साइज़ इनवैरियंस और रोटेशनल इनवैरिएंस भी देखें.