Halaman ini berisi istilah glosarium Model Gambar. Untuk semua istilah glosarium, klik di sini.
J
augmented reality
Teknologi yang menempatkan gambar buatan komputer pada pandangan pengguna tentang dunia nyata, sehingga memberikan tampilan gabungan.
autoencoder
Sistem yang mempelajari cara mengekstrak informasi yang paling penting dari input. Autoencoder adalah kombinasi dari encoder dan decoder. Autoencoder mengandalkan proses dua langkah berikut:
- Encoder memetakan input ke format dimensi rendah (biasanya) lossy (biasanya) lossy (sedang).
- Decoder membuat versi lossy dari input asli dengan memetakan format dimensi rendah ke format input asli yang berdimensi lebih tinggi.
Autoencoder dilatih secara menyeluruh dengan meminta decoder mencoba merekonstruksi input asli dari format perantara encoder sedekat mungkin. Karena format perantara lebih kecil (dimensi lebih rendah) daripada format aslinya, autoencoder terpaksa mempelajari informasi apa yang penting dalam input, dan output tidak akan sama persis dengan input.
Contoh:
- Jika data input berupa grafis, salinan yang tidak tepat akan serupa dengan grafik asli, tetapi sedikit dimodifikasi. Mungkin teks yang tidak tepat menghilangkan derau dari grafis asli atau mengisi beberapa piksel yang hilang.
- Jika data input berupa teks, autoencoder akan membuat teks baru yang meniru (tetapi tidak identik) dengan teks asli.
Lihat juga autoencoder bervariasi.
model auto-regresif
model yang menyimpulkan prediksi berdasarkan prediksinya sendiri sebelumnya. Misalnya, model bahasa auto-regresif memprediksi token berikutnya berdasarkan token yang diprediksi sebelumnya. Semua model bahasa besar berbasis Transformer bersifat auto-regresif.
Sebaliknya, model gambar berbasis GAN biasanya tidak regresi otomatis karena menghasilkan gambar dalam satu penerusan maju dan tidak secara berulang dalam langkah. Namun, model pembuatan gambar tertentu bersifat autoregresif karena model tersebut menghasilkan gambar secara bertahap.
B
kotak pembatas
Dalam gambar, koordinat (x, y) persegi panjang di sekitar area menarik, seperti pada gambar di bawah.

C
konvolusi
Dalam matematika, berbicara santai adalah campuran dua fungsi. Dalam machine learning, konvolusi menggabungkan filter konvolusional dan matriks input untuk melatih bobot.
Istilah "konvolusi" dalam machine learning sering kali merupakan cara singkat untuk merujuk ke operasi konvolusional atau lapisan konvolusional.
Tanpa konvolusi, algoritma machine learning harus mempelajari bobot terpisah untuk setiap sel dalam tensor besar. Misalnya, pelatihan algoritma machine learning pada gambar 2K x 2K akan dipaksa untuk menemukan 4 juta bobot terpisah. Berkat konvolusi, algoritma machine learning hanya perlu menemukan bobot untuk setiap sel dalam saringan konvolusional, yang secara drastis mengurangi memori yang diperlukan untuk melatih model. Saat diterapkan, filter konvolusional hanya direplikasi ke seluruh sel sehingga setiap sel dikalikan dengan filter.
filter konvolusional
Salah satu dari dua aktor dalam operasi konvolusional. (Aktor lainnya adalah potongan dari matriks input.) Saringan konvolusional adalah matriks yang memiliki peringkat yang sama dengan matriks input, tetapi bentuknya lebih kecil. Misalnya, dengan matriks input 28x28, filter dapat berupa matriks 2D yang lebih kecil dari 28x28.
Dalam manipulasi fotografi, semua sel dalam filter konvolusional biasanya ditetapkan ke pola konstan satu dan nol. Dalam machine learning, filter konvolusional biasanya diisi dengan angka acak, lalu jaringan melatih nilai yang ideal.
lapisan konvolusional
Lapisan jaringan neural dalam tempat filter konvolusional meneruskan matriks input. Misalnya, pertimbangkan saringan konvolusional 3x3 berikut:
![Matriks 3x3 dengan nilai berikut: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=1&hl=id)
Animasi berikut menunjukkan lapisan konvolusional yang terdiri dari 9 operasi konvolusional yang melibatkan matriks input 5x5. Perhatikan bahwa setiap operasi konvolusional bekerja pada potongan matriks input 3x3 yang berbeda. Matriks 3x3 yang dihasilkan (di sebelah kanan) terdiri dari hasil 9 operasi konvolusional:
![Animasi yang menunjukkan dua matriks. Matriks pertama adalah matriks 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,4]
Matriks kedua adalah matriks 3x3: [[181,303,618], [115,338,605], [169,351,560]].
Matriks kedua dihitung dengan menerapkan filter konvolusional [[0, 1, 0], [1, 0, 1], [0, 1, 0]] di berbagai subset 3x3 dari matriks 5x5.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=1&hl=id)
jaringan neural konvolusional
Jaringan neural yang setidaknya satu lapisannya adalah lapisan konvolusional. Jaringan neural konvolusional umum terdiri dari beberapa kombinasi lapisan berikut:
Jaringan neural konvolusional telah meraih sukses besar dalam jenis masalah tertentu, seperti pengenalan gambar.
operasi konvolusional
Operasi matematika dua langkah berikut:
- Perkalian berbasis elemen dari filter konvolusional dan potongan dari matriks input. (Potongan matriks input memiliki peringkat dan ukuran yang sama dengan filter konvolusional.)
- Penjumlahan semua nilai dalam matriks produk yang dihasilkan.
Misalnya, pertimbangkan matriks input 5x5 berikut:
![Matriks 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100], [31,40,100]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=1&hl=id)
Sekarang bayangkan filter konvolusional 2x2 berikut:
![Matriks 2x2: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=1&hl=id)
Setiap operasi konvolusional melibatkan potongan 2x2 tunggal dari matriks input. Misalnya, kita menggunakan potongan 2x2 di kiri atas matriks input. Jadi, operasi konvolusi pada potongan ini akan terlihat seperti berikut:
![Menerapkan filter konvolusional [[1, 0], [0, 1]] ke bagian kiri atas
2x2 dari matriks input, yaitu [[128,97], [35,22]].
Saringan konvolusional membiarkan 128 dan 22 tetap utuh, tetapi 97 dan 35 menjadi nol. Akibatnya, operasi konvolusi menghasilkan nilai 150 (128+22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=1&hl=id)
Lapisan konvolusional terdiri dari serangkaian operasi konvolusional, masing-masing bekerja pada potongan matriks input yang berbeda.
D
pengayaan data
Secara artifisial, meningkatkan rentang dan jumlah contoh pelatihan dengan mengubah contoh yang sudah ada untuk membuat contoh tambahan. Misalnya, anggaplah gambar adalah salah satu fitur Anda, tetapi set data tidak berisi contoh gambar yang memadai bagi model untuk mempelajari keterkaitan yang berguna. Idealnya, tambahkan cukup gambar berlabel ke set data agar model Anda dapat dilatih dengan benar. Jika hal itu tidak memungkinkan, pengayaan data dapat merotasi, melebarkan, dan merefleksikan setiap gambar untuk menghasilkan banyak varian dari gambar asli, yang mungkin menghasilkan data berlabel yang cukup untuk memungkinkan pelatihan yang sangat baik.
jaringan neural konvolusional yang dapat dipisahkan secara mendalam (sepCNN)
Arsitektur jaringan neural konvolusional berdasarkan Inception, tetapi di mana modul Inception diganti dengan konvolusi yang dapat dipisahkan secara mendalam. Juga dikenal sebagai Xception.
Konvolusi yang dapat dipisahkan secara mendalam (juga disingkat sebagai konvolusi yang dapat dipisahkan) memfaktorkan konvolusi 3D standar menjadi dua operasi konvolusi terpisah yang lebih efisien secara komputasi: pertama, konvolusi yang dalam kedalaman, dengan kedalaman 1 (n ✕ n ✕ 1), lalu 1, 1, dengan panjang kolom
Untuk mempelajari lebih lanjut, lihat Xception: Deep Learning dengan Depthwise Separable Convolution.
pengurangan sampel
Istilah yang kelebihan beban yang dapat berarti salah satu dari hal berikut:
- Mengurangi jumlah informasi dalam suatu fitur untuk melatih model dengan lebih efisien. Misalnya, sebelum melatih model pengenalan citra, lakukan downsampling pada gambar beresolusi tinggi ke format resolusi yang lebih rendah.
- Melatih contoh kelas dengan persentase rendah yang tidak proporsional untuk meningkatkan pelatihan model pada kelas yang kurang terwakili. Misalnya, dalam set data kelas tidak seimbang, model cenderung belajar banyak tentang kelas mayoritas dan tidak cukup tentang kelas minoritas. Penurunan/pengurangan sampel membantu menyeimbangkan jumlah pelatihan pada kelas mayoritas dan minoritas.
F
fine tuning
Penerusan pelatihan khusus tugas kedua yang dilakukan pada model yang telah dilatih sebelumnya guna meningkatkan kualitas parameternya untuk kasus penggunaan tertentu. Misalnya, urutan pelatihan lengkap untuk beberapa model bahasa besar adalah sebagai berikut:
- Pra-pelatihan: Latih model bahasa besar pada set data umum yang luas, seperti semua halaman Wikipedia berbahasa Inggris.
- Fine-tuning: Latih model yang telah dilatih sebelumnya untuk melakukan tugas tertentu, seperti merespons kueri medis. Fine-tuning biasanya melibatkan ratusan atau ribuan contoh yang berfokus pada tugas tertentu.
Sebagai contoh lainnya, urutan pelatihan lengkap untuk model gambar besar adalah sebagai berikut:
- Pra-pelatihan: Latih model gambar besar pada set data gambar umum yang luas, seperti semua gambar di Wikimedia commons.
- Fine-tuning: Latih model yang telah dilatih sebelumnya untuk melakukan tugas tertentu, seperti membuat gambar orca.
Fine-tuning dapat memerlukan kombinasi apa pun dari strategi berikut:
- Memodifikasi semua parameter model terlatih yang ada. Hal ini terkadang disebut penyempurnaan penuh.
- Hanya memodifikasi beberapa parameter terlatih yang ada dari model terlatih (biasanya, lapisan yang paling dekat dengan lapisan output), sekaligus mempertahankan parameter lain yang sudah ada (biasanya, lapisan yang paling dekat dengan lapisan input). Lihat parameter-efficient tuning.
- Menambahkan lebih banyak lapisan, biasanya di atas lapisan yang ada yang terdekat dengan lapisan output.
Penyesuaian adalah salah satu bentuk pembelajaran transfer. Dengan demikian, fine-tuning mungkin menggunakan fungsi kerugian yang berbeda atau jenis model yang berbeda dengan yang digunakan untuk melatih model terlatih. Misalnya, Anda dapat menyesuaikan model gambar besar yang dilatih sebelumnya untuk menghasilkan model regresi yang menampilkan jumlah burung dalam gambar input.
Bandingkan dan kontraskan fine-tuning dengan istilah berikut:
G
AI generatif
Sebuah bidang transformatif yang sedang berkembang tanpa definisi formal. Meskipun demikian, sebagian besar pakar sependapat bahwa model AI generatif dapat membuat konten ("membuat") yang berupa hal-hal berikut:
- kompleks
- koheren
- asli
Misalnya, model AI generatif dapat membuat esai atau gambar yang canggih.
Beberapa teknologi sebelumnya, termasuk LSTM dan RNN, juga dapat menghasilkan konten asli dan koheren. Beberapa pakar menganggap teknologi lama ini sebagai AI generatif, sementara pakar lain merasa bahwa AI generatif yang sesungguhnya memerlukan output yang lebih kompleks daripada yang dapat dihasilkan oleh teknologi sebelumnya.
Berbeda dengan ML prediktif.
I
pengenalan gambar
Sebuah proses yang mengklasifikasikan objek, pola, atau konsep dalam sebuah gambar. Pengenalan citra juga dikenal sebagai klasifikasi gambar.
Untuk mengetahui informasi selengkapnya, lihat Praktik ML: Klasifikasi Gambar.
persimpangan akibat union (IoU)
Perpotongan dua himpunan yang dibagi berdasarkan gabungannya. Dalam tugas deteksi gambar machine learning, IoU digunakan untuk mengukur akurasi kotak pembatas prediksi model sehubungan dengan kotak pembatas ground-truth. Dalam hal ini, IoU untuk dua kotak adalah rasio antara area tumpang-tindih dan luas total, dan nilainya berkisar dari 0 (tidak ada tumpang-tindih yang diprediksi kotak pembatas dan kotak pembatas kebenaran ground) hingga 1 (kotak pembatas yang diprediksi dan kotak pembatas kebenaran ground memiliki koordinat yang sama persis).
Misalnya, pada gambar di bawah ini:
- Prediksi kotak pembatas (koordinat yang membatasi tempat model memprediksi meja malam dalam lukisan berada) digarisbawahi dengan warna ungu.
- Kotak pembatas kebenaran nyata (koordinat yang membatasi lokasi tabel malam dalam lukisan sebenarnya) ditandai dengan warna hijau.
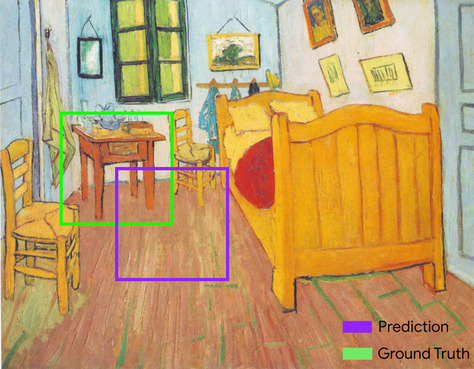
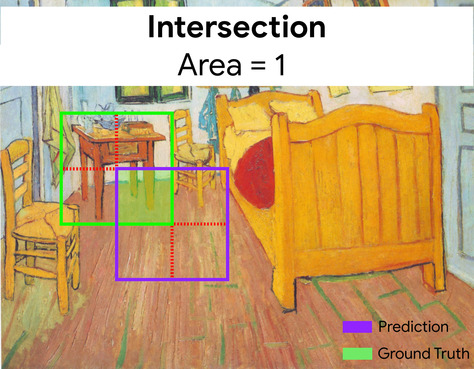
Di sini, perpotongan kotak pembatas untuk prediksi dan kebenaran dasar (di bawah kiri) adalah 1, dan gabungan kotak pembatas untuk prediksi dan kebenaran dasar (di bawah kanan) adalah 7, sehingga IoU adalah \(\frac{1}{7}\).

K
keypoint
Koordinat fitur tertentu pada gambar. Misalnya, untuk model pengenalan gambar yang membedakan spesies bunga, keypoint dapat menjadi pusat setiap kelopak, batang, benang sari, dan seterusnya.
L
tempat terkenal
Sinonim dari keypoint.
S
MNIST
Set data domain publik yang dikompilasi oleh LeCun, Cortes, dan Burges yang berisi 60.000 gambar, setiap gambar menunjukkan cara manusia menulis digit tertentu dari 0–9 secara manual. Setiap gambar disimpan sebagai array bilangan bulat berukuran 28x28, dengan setiap bilangan bulat adalah nilai hitam putih antara 0 dan 255, inklusif.
MNIST adalah set data kanonis untuk machine learning, yang sering digunakan untuk menguji pendekatan machine learning baru. Untuk mengetahui detailnya, lihat Database MNIST untuk Digit Tulis Tangan.
P
penggabungan
Mengurangi matriks (atau matriks) yang dibuat oleh lapisan konvolusional sebelumnya ke matriks yang lebih kecil. Penggabungan biasanya melibatkan penggunaan nilai maksimum atau rata-rata di seluruh area gabungan. Misalnya, kita memiliki matriks 3x3 berikut:
![Matriks 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?authuser=1&hl=id)
Operasi penggabungan, seperti operasi konvolusional, membagi matriks tersebut menjadi beberapa bagian, lalu menggeser operasi konvolusional tersebut dengan jangka. Misalnya, operasi penggabungan membagi matriks konvolusional menjadi irisan 2x2 dengan jangka 1x1. Seperti yang digambarkan oleh diagram berikut, terjadi empat operasi penggabungan. Bayangkan bahwa setiap operasi penggabungan memilih nilai maksimum dari empat operasi tersebut dalam potongan tersebut:
![Matriks input adalah 3x3 dengan nilai-nilai: [[5,3,1], [8,2,5], [9,4,3]].
Submatriks 2x2 kiri atas dari matriks input adalah [[5,3], [8,2]], sehingga operasi penggabungan di kiri atas menghasilkan nilai 8 (yang merupakan maksimum 5, 3, 8, dan 2). Submatriks 2x2 kanan atas dari matriks input adalah [[3,1], [2,5]], sehingga operasi penggabungan kanan atas menghasilkan nilai 5. Submatriks 2x2 kiri bawah dari matriks input adalah
[[8,2], [9,4]], sehingga operasi penggabungan kiri bawah menghasilkan nilai
9. Submatriks 2x2 kanan bawah dari matriks input adalah [[2,5], [4,3]], sehingga operasi penggabungan kanan bawah menghasilkan nilai 5. Singkatnya, operasi penggabungan menghasilkan matriks 2x2 [[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=1&hl=id)
Penggabungan membantu menerapkan invariansi translasi dalam matriks input.
Penggabungan untuk aplikasi visi dikenal lebih formal sebagai penggabungan spasial. Penerapan deret waktu biasanya mengacu pada penggabungan sebagai penggabungan sementara. Secara kurang formal, penggabungan sering disebut subsampling atau downsampling.
model terlatih
Model atau komponen model (seperti vektor embedding) yang telah dilatih. Terkadang, Anda akan memasukkan vektor embedding yang telah dilatih sebelumnya ke dalam jaringan neural. Di lain waktu, model Anda akan melatih vektor embedding itu sendiri, bukan mengandalkan embedding yang telah dilatih sebelumnya.
Istilah model bahasa terlatih mengacu pada model bahasa besar yang telah melalui pra-pelatihan.
latihan awal
Pelatihan awal model pada set data besar. Beberapa model yang dilatih sebelumnya adalah model yang ceroboh dan biasanya harus ditingkatkan melalui pelatihan tambahan. Misalnya, pakar ML dapat melatih terlebih dahulu model bahasa besar dengan set data teks yang luas, seperti semua halaman berbahasa Inggris di Wikipedia. Setelah melakukan pra-pelatihan, model yang dihasilkan dapat disempurnakan lebih lanjut melalui salah satu teknik berikut:
R
invariansi rotasi
Dalam masalah klasifikasi gambar, kemampuan algoritma agar berhasil mengklasifikasikan gambar meskipun orientasi gambar berubah. Misalnya, algoritme masih dapat mengidentifikasi raket tenis apakah mengarah ke atas, ke samping, atau ke bawah. Perhatikan bahwa invariansi rotasional tidak selalu diinginkan; misalnya, 9 terbalik tidak boleh diklasifikasikan sebagai 9.
Lihat juga invariansi translasi dan invariansi ukuran.
S
invariansi ukuran
Dalam masalah klasifikasi gambar, kemampuan algoritme agar berhasil mengklasifikasikan gambar meskipun ukuran gambar berubah. Misalnya, algoritma masih dapat mengidentifikasi kucing apakah itu menggunakan 2 juta piksel atau 200 ribu piksel. Perhatikan bahwa algoritma klasifikasi gambar terbaik sekalipun masih memiliki batas praktis terkait invariansi ukuran. Misalnya, algoritma (atau manusia) tidak mungkin mengklasifikasikan dengan benar gambar kucing yang hanya menggunakan 20 piksel.
Lihat juga invariansi translasi dan invariansi rotasional.
penggabungan spasial
Lihat penggabungan.
langkah
Dalam operasi konvolusional atau penggabungan, delta di setiap dimensi dari rangkaian irisan input berikutnya. Misalnya, animasi berikut menunjukkan jangka (1,1) selama operasi konvolusional. Oleh karena itu, irisan input berikutnya memulai satu posisi di sebelah kanan irisan input sebelumnya. Saat operasi mencapai tepi kanan, irisan berikutnya sepenuhnya ke kiri tetapi satu posisi di bawah.
Contoh sebelumnya menunjukkan jangka dua dimensi. Jika matriks masukan memiliki tiga dimensi, jangkanya juga akan memiliki tiga dimensi.
subsampling
Lihat penggabungan.
T
suhu
hyperparameter yang mengontrol tingkat keacakan output model. Suhu yang lebih tinggi menghasilkan output yang lebih acak, sedangkan suhu yang lebih rendah menghasilkan output yang lebih sedikit acak.
Pemilihan suhu terbaik bergantung pada aplikasi tertentu dan properti pilihan dari output model. Misalnya, Anda mungkin akan menaikkan suhu saat membuat aplikasi yang menghasilkan output materi iklan. Sebaliknya, Anda mungkin akan menurunkan suhu saat membangun model yang mengklasifikasikan gambar atau teks untuk meningkatkan akurasi dan konsistensi model.
Suhu sering digunakan dengan softmax.
invariansi translasi
Dalam masalah klasifikasi gambar, kemampuan algoritme agar berhasil mengklasifikasikan gambar meskipun posisi objek dalam gambar berubah. Misalnya, algoritma masih dapat mengidentifikasi seekor, baik yang berada di tengah frame atau di ujung kiri frame.
Lihat juga invariansi ukuran dan invariansi rotasional.