На этой странице представлены термины глоссария генеративного искусственного интеллекта. Для просмотра всех терминов глоссария нажмите здесь .
А
приспособление
Синоним к слову «настройка» или «тонкая настройка» .
агент
Программное обеспечение, способное анализировать вводимые пользователем данные для планирования и выполнения действий от его имени.
В обучении с подкреплением агент — это сущность, которая использует стратегию для максимизации ожидаемой отдачи от перехода между состояниями окружающей среды .
агентный
Прилагательная форма слова «агент» . «Агентный» относится к качествам, которыми обладают агенты (например, автономия).
агентский рабочий процесс
Динамический процесс, в котором агент автономно планирует и выполняет действия для достижения цели. Этот процесс может включать рассуждения, использование внешних инструментов и самокоррекцию плана.
AI slop
Результат работы генеративной системы искусственного интеллекта , которая отдает предпочтение количеству, а не качеству. Например, веб-страница, созданная с помощью ИИ, заполнена дешевым, сгенерированным ИИ, низкокачественным контентом.
автоматическая оценка
Использование программного обеспечения для оценки качества результатов работы модели.
Когда выходные данные модели относительно просты, скрипт или программа могут сравнить выходные данные модели с эталонным ответом . Этот тип автоматической оценки иногда называют программной оценкой . Для программной оценки часто полезны такие метрики, как ROUGE или BLEU .
Когда результаты работы модели сложны или не имеют единственно правильного ответа , иногда автоматическую оценку выполняет отдельная программа машинного обучения, называемая авторизатором .
Сравните с человеческой оценкой .
авторская оценка
Гибридный механизм оценки качества результатов работы генеративной модели ИИ , сочетающий в себе оценку человеком и автоматическую оценку . Авторефер — это модель машинного обучения, обученная на данных, созданных в результате оценки человеком . В идеале авторефер учится имитировать действия человека-оценщика.В продаже имеются готовые автоматизированные системы оценки, но лучшие из них специально оптимизированы для решения конкретной задачи.
авторегрессионная модель
Модель , которая делает вывод на основе собственных предыдущих прогнозов. Например, авторегрессивные языковые модели прогнозируют следующий токен на основе ранее предсказанных токенов. Все большие языковые модели на основе Transformer являются авторегрессивными.
В отличие от них, модели обработки изображений на основе GAN обычно не являются авторегрессивными, поскольку они генерируют изображение за один прямой проход, а не итеративно пошагово. Однако некоторые модели генерации изображений являются авторегрессивными, поскольку они генерируют изображение пошагово.
Б
базовая модель
Предварительно обученная модель , которая может служить отправной точкой для тонкой настройки с целью решения конкретных задач или приложений.
См. также предварительно обученную модель и базовую модель .
С
цепочка мыслей подсказка
Метод разработки подсказок , который побуждает большую языковую модель (БЯМ) пошагово объяснять свои рассуждения. Например, рассмотрим следующую подсказку, обратив особое внимание на второе предложение:
Какую перегрузку (g) будет испытывать водитель в автомобиле, разгоняющемся от 0 до 60 миль в час за 7 секунд? В ответе покажите все необходимые расчеты.
Ответ магистра права, скорее всего, будет следующим:
- Представьте последовательность физических формул, подставив значения 0, 60 и 7 в соответствующие места.
- Объясните, почему были выбраны именно эти формулы и что означают различные переменные.
Метод подсказок, основанный на логической цепочке рассуждений, заставляет логическую модель выполнять все вычисления, что может привести к более правильному ответу. Кроме того, этот метод позволяет пользователю изучить шаги логической модели, чтобы определить, имеет ли ответ смысл.
чат
Содержимое диалога с системой машинного обучения, как правило, с большой языковой моделью . Предыдущее взаимодействие в чате (то, что вы напечатали, и ответ большой языковой модели) становится контекстом для последующих частей чата.
Чат-бот — это приложение, использующее большую языковую модель.
контекстуализированное встраивание языка
Встраивание языка, которое приближается к «пониманию» слов и фраз так же, как это могут делать свободно говорящие на языке люди. Контекстуализированные языковые встраивания способны понимать сложный синтаксис, семантику и контекст.
Например, рассмотрим векторные представления английского слова cow . Более старые векторные представления, такие как word2vec, могут представлять английские слова таким образом, что расстояние в пространстве векторных представлений от cow до bull аналогично расстоянию от ewe (самка овцы) до ram (самец овцы) или от female до male . Контекстуализированные векторные представления языка могут пойти еще дальше, учитывая, что носители английского языка иногда в разговорной речи используют слово cow как в значении «корова», так и «бык».
контекстное окно
Количество токенов , которые модель может обработать в заданном запросе . Чем больше контекстное окно, тем больше информации модель может использовать для предоставления связных и согласованных ответов на запрос.
разговорное программирование
Итеративный диалог между вами и моделью генеративного ИИ с целью создания программного обеспечения. Вы отправляете запрос, описывающий некое программное обеспечение. Затем модель использует это описание для генерации кода. После этого вы отправляете новый запрос, чтобы исправить недостатки в предыдущем запросе или в сгенерированном коде, и модель генерирует обновленный код. Вы продолжаете обмен данными до тех пор, пока сгенерированное программное обеспечение не станет достаточно хорошим.
Кодирование разговора по сути является первоначальным смыслом кодирования атмосферы .
В отличие от специфического кодирования .
Д
прямое подсказывание
Синоним для «подсказки без предварительного обучения» .
дистилляция
Процесс уменьшения размера одной модели (известной как « учитель ») до меньшей модели (известной как « ученик» ), которая максимально точно имитирует предсказания исходной модели. Дистилляция полезна, потому что меньшая модель имеет два ключевых преимущества перед большей моделью (учителем):
- Более быстрое время вывода
- Сниженное потребление памяти и энергии.
Однако прогнозы ученика, как правило, не так точны, как прогнозы учителя.
Метод дистилляции обучает модель-ученика минимизировать функцию потерь , основанную на разнице между результатами прогнозов модели-ученика и модели-учителя.
Сравните и сопоставьте процесс дистилляции со следующими терминами:
Дополнительную информацию см. в разделе LLMs: Тонкая настройка, дистилляция и разработка алгоритмов быстрого реагирования в книге Machine Learning Crash Course.
Е
оценки
В основном используется как аббревиатура для обозначения оценок в рамках магистерских программ . В более широком смысле, «оценки» — это аббревиатура для любой формы оценки .
оценка
Процесс оценки качества модели или сравнения различных моделей друг с другом.
Для оценки модели машинного обучения с учителем обычно проводят сравнение с проверочным и тестовым наборами данных . Оценка модели машинного обучения с учителем, как правило, включает в себя более широкие оценки качества и безопасности.
Ф
фактичность
В мире машинного обучения фактичность — это свойство, описывающее модель, выходные данные которой основаны на реальности. Фактичность — это скорее концепция, чем метрика. Например, предположим, вы отправляете следующий запрос большой языковой модели :
Какова химическая формула поваренной соли?
Модель, оптимизирующая достоверность фактов, дала бы следующий ответ:
NaCl
Заманчиво предположить, что все модели должны основываться на фактах. Однако некоторые подсказки, например, следующие, должны побудить генеративную модель ИИ оптимизировать креативность, а не факты .
Расскажите мне лимерик об астронавте и гусенице.
Маловероятно, что получившийся лимерик будет основан на реальных событиях.
В отличие от устойчивости .
быстрый распад
Метод обучения , позволяющий улучшить производительность LLM . Быстрое затухание предполагает быстрое снижение скорости обучения во время тренировки. Эта стратегия помогает предотвратить переобучение модели на обучающих данных и улучшает обобщающую способность .
подсказка с небольшим количеством попыток
Запрос , содержащий более одного («несколько») примеров, демонстрирующих, как должна отвечать большая языковая модель . Например, следующий длинный запрос содержит два примера, показывающих, как большая языковая модель должна отвечать на запрос.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| Франция: EUR | Один пример. |
| Соединенное Королевство: фунты стерлингов | Ещё один пример. |
| Индия: | Сам запрос. |
Как правило, подсказки, полученные за несколько попыток, дают более желаемые результаты, чем подсказки, полученные за одну попытку , или подсказки, полученные за одну попытку . Однако подсказки, полученные за несколько попыток, требуют более длинной подсказки.
Метод обучения с малым количеством примеров — это форма обучения с малым количеством примеров, применяемая к обучению на основе подсказок .
Для получения дополнительной информации см. раздел «Оперативная разработка в рамках курса «Машинное обучение»».
тонкая настройка
Второй, специализированный этап обучения выполняется на предварительно обученной модели для уточнения ее параметров под конкретный сценарий использования. Например, полная последовательность обучения для некоторых крупных языковых моделей выглядит следующим образом:
- Предварительное обучение: обучите большую языковую модель на обширном общем наборе данных, например, на всех страницах Википедии на английском языке.
- Тонкая настройка: Обучение предварительно обученной модели для выполнения конкретной задачи, например, ответа на медицинские запросы. Тонкая настройка обычно включает сотни или тысячи примеров, ориентированных на конкретную задачу.
В качестве еще одного примера, полная последовательность обучения для модели обработки больших изображений выглядит следующим образом:
- Предварительное обучение: обучите модель обработки больших изображений на обширном общем наборе данных изображений, например, на всех изображениях из Wikimedia Commons.
- Тонкая настройка: Обучение предварительно обученной модели выполнению конкретной задачи, например, генерации изображений косаток.
Тонкая настройка может включать в себя любую комбинацию следующих стратегий:
- Изменение всех существующих параметров предварительно обученной модели. Иногда это называют полной тонкой настройкой .
- Изменение только некоторых существующих параметров предварительно обученной модели (как правило, слоев, ближайших к выходному слою ), при сохранении остальных существующих параметров без изменений (как правило, слоев, ближайших к входному слою ). См. параметроэффективную настройку .
- Добавление дополнительных слоев, как правило, поверх существующих слоев, расположенных ближе всего к выходному слою.
Тонкая настройка — это форма трансферного обучения . В связи с этим, при тонкой настройке может использоваться другая функция потерь или другой тип модели, отличный от тех, которые использовались для обучения предварительно обученной модели. Например, можно выполнить тонкую настройку предварительно обученной модели для больших изображений, чтобы получить модель регрессии, которая возвращает количество птиц на входном изображении.
Сравните и сопоставьте термин «тонкая настройка» со следующими понятиями:
Более подробную информацию можно найти в разделе «Тонкая настройка в экспресс- курсе по машинному обучению».
Флэш-модель
Семейство относительно небольших моделей Gemini , оптимизированных для скорости и низкой задержки . Флэш-модели разработаны для широкого спектра применений, где важны быстрая реакция и высокая пропускная способность.
фундаментальная модель
Очень большая предварительно обученная модель, обученная на огромном и разнообразном обучающем наборе данных . Базовая модель может выполнять обе следующие функции:
- Умеет оперативно реагировать на широкий круг запросов.
- Служит базовой моделью для дальнейшей тонкой настройки или других модификаций.
Иными словами, базовая модель уже в общем смысле очень функциональна, но её можно дополнительно адаптировать, чтобы сделать ещё более полезной для решения конкретной задачи.
доля успехов
Метрика для оценки текста, сгенерированного моделью машинного обучения. Доля успешных результатов — это количество «успешных» сгенерированных текстовых результатов, деленное на общее количество сгенерированных текстовых результатов. Например, если большая языковая модель сгенерировала 10 блоков кода, пять из которых были успешными, то доля успешных результатов составит 50%.
Хотя показатель доли успешных результатов широко используется в статистике, в машинном обучении он в первую очередь полезен для оценки проверяемых задач, таких как генерация кода или решение математических задач.
Г
Близнецы
Экосистема, включающая в себя самые передовые разработки Google в области искусственного интеллекта. Элементы этой экосистемы включают в себя:
- Различные модели Gemini .
- Интерактивный диалоговый интерфейс для модели Gemini. Пользователи вводят подсказки, а Gemini отвечает на них.
- Различные API Gemini.
- Различные бизнес-продукты, основанные на моделях Gemini; например, Gemini для Google Cloud .
модели Близнецов
Передовые многомодальные модели Google на основе Transformer . Модели Gemini специально разработаны для интеграции с агентами .
Пользователи могут взаимодействовать с моделями Gemini различными способами, в том числе через интерактивный диалоговый интерфейс и с помощью SDK.
Джемма
Семейство облегченных открытых моделей, созданных на основе тех же исследований и технологий, что и модели Gemini . Доступно несколько различных моделей Gemma, каждая из которых предлагает различные функции, такие как машинное зрение, программирование и следование инструкциям. Подробнее см. Gemma .
GenAI или genAI
Сокращение от генеративного искусственного интеллекта .
сгенерированный текст
В общем, это текст, который выдает модель машинного обучения. При оценке больших языковых моделей некоторые метрики сравнивают сгенерированный текст с эталонным текстом . Например, предположим, вы пытаетесь определить, насколько эффективно модель машинного обучения переводит с французского на голландский. В этом случае:
- Сгенерированный текст представляет собой голландский перевод, который выдает модель машинного обучения.
- В качестве эталонного текста используется голландский перевод, выполненный человеком-переводчиком (или с помощью программного обеспечения).
Следует отметить, что некоторые стратегии оценки не предполагают использования справочного текста.
генеративный ИИ
Это развивающаяся, преобразующая область, не имеющая формального определения. Тем не менее, большинство экспертов сходятся во мнении, что генеративные модели ИИ могут создавать («генерировать») контент, который соответствует всем перечисленным ниже критериям:
- сложный
- согласованный
- оригинал
Примерами генеративного искусственного интеллекта являются:
- Крупные языковые модели , способные генерировать сложный оригинальный текст и отвечать на вопросы.
- Модель генерации изображений, способная создавать уникальные изображения.
- Модели генерации аудио и музыки, способные создавать оригинальную музыку или генерировать реалистичную речь.
- Модели генерации видео, способные создавать оригинальные видеоролики.
Некоторые более ранние технологии, включая LSTM и RNN , также способны генерировать оригинальный и связный контент. Некоторые эксперты рассматривают эти более ранние технологии как генеративный искусственный интеллект, в то время как другие считают, что для истинного генеративного ИИ требуется более сложный результат, чем тот, который могут обеспечить эти более ранние технологии.
Сравните с прогностическим машинным обучением .
золотой ответ
Ответ, заведомо считающийся правильным. Например, при следующей подсказке :
2 + 2
Наилучший ответ, будем надеяться, будет таким:
4
GPT (Generative Pre-trained Transformer)
Семейство больших языковых моделей на основе трансформеров , разработанных компанией OpenAI .
Варианты GPT могут применяться к различным методам диагностики , включая:
- генерация изображений (например, ImageGPT)
- генерация текста в изображение (например, DALL-E ).
ЧАС
галлюцинация
Генеративная модель искусственного интеллекта выдает на первый взгляд правдоподобные, но фактически неверные утверждения, которые якобы отражают реальный мир. Например, генеративная модель ИИ, утверждающая, что Барак Обама умер в 1865 году, — это галлюцинация .
оценка человеком
Процесс, в котором люди оценивают качество выходных данных модели машинного обучения; например, оценка качества модели машинного перевода двуязычными людьми. Человеческая оценка особенно полезна для оценки моделей, у которых нет единственно правильного ответа .
Сравните с автоматической оценкой и оценкой автором .
Человек в замкнутом цикле (HITL)
Нечетко определенное идиоматическое выражение, которое может означать одно из следующих:
- Политика критического или скептического отношения к результатам работы генеративного искусственного интеллекта .
- Стратегия или система, обеспечивающая участие людей в формировании, оценке и совершенствовании поведения модели. Привлечение человека позволяет ИИ извлекать выгоду как из машинного, так и из человеческого интеллекта. Например, система, в которой ИИ генерирует код, который затем проверяют инженеры-программисты, является системой с участием человека.
я
обучение в контексте
Синоним для "подсказки в нескольких попытках" .
вывод
В традиционном машинном обучении процесс прогнозирования осуществляется путем применения обученной модели к неразмеченным примерам . Подробнее об этом можно узнать в курсе «Введение в машинное обучение» в разделе «Обучение с учителем».
В больших языковых моделях вывод — это процесс использования обученной модели для генерации ответа на входной запрос .
В статистике понятие «вывод» имеет несколько иное значение. Подробнее об этом можно прочитать в статье Википедии о статистическом выводе .
настройка инструкций
Тонкая настройка , улучшающая способность генеративной модели ИИ следовать инструкциям. Настройка инструкций включает в себя обучение модели на серии подсказок, как правило, охватывающих широкий спектр задач. В результате настроенная на инструкции модель, как правило, генерирует полезные ответы на подсказки без предварительного обучения в различных задачах.
Сравните и сопоставьте с:
Л
большая языковая модель
Как минимум, это языковая модель с очень большим количеством параметров . В более неформальном смысле, это любая языковая модель на основе трансформеров , например, Gemini или GPT .
Более подробную информацию см. в разделе «Краткий курс по машинному обучению» в книге «Большие языковые модели (LLM)» .
задержка
Время, необходимое модели для обработки входных данных и генерации ответа. Генерация ответа с высокой задержкой занимает больше времени, чем генерация ответа с низкой задержкой.
К факторам, влияющим на задержку больших языковых моделей, относятся:
- Длина входных и выходных токенов
- Сложность модели
- Инфраструктура, на которой работает модель
Оптимизация задержки имеет решающее значение для создания отзывчивых и удобных для пользователя приложений.
магистр права
Сокращение от large language model (большая языковая модель) .
Оценка программ магистратуры в области права (LLM)
Набор метрик и критериев для оценки производительности больших языковых моделей (БЛМ). В общих чертах, оценка БЛМ включает в себя:
- Помогите исследователям выявить области, в которых программы обучения лингвистическим навыкам нуждаются в улучшении.
- Они полезны для сравнения различных моделей обучения и определения наилучшей модели обучения для конкретной задачи.
- Помогите обеспечить безопасность и этичность использования LLM-ов.
Более подробную информацию см. в разделе «Краткий курс по машинному обучению» в книге «Большие языковые модели (LLM)» .
ЛоРА
Сокращение от Low-Rank Adaptability (адаптивность низкого ранга) .
Адаптивность низкого ранга (LoRA)
Эффективный с точки зрения параметров метод тонкой настройки , который «замораживает» предварительно обученные веса модели (так что их больше нельзя изменять), а затем вставляет в модель небольшой набор обучаемых весов. Этот набор обучаемых весов (также известный как «матрицы обновления») значительно меньше базовой модели и, следовательно, обучается гораздо быстрее.
LoRA предоставляет следующие преимущества:
- Улучшает качество прогнозов модели в той области, где применяется тонкая настройка.
- Этот метод позволяет быстрее выполнять тонкую настройку параметров модели, чем методы, требующие точной настройки всех параметров модели.
- Снижает вычислительные затраты на вывод результатов , позволяя одновременно запускать несколько специализированных моделей, использующих одну и ту же базовую модель.
М
машинный перевод
Использование программного обеспечения (как правило, модели машинного обучения) для преобразования текста с одного человеческого языка на другой человеческий язык, например, с английского на японский.
средняя точность при k (mAP@k)
Среднестатистическое значение всех показателей средней точности при k значениях по всему набору данных для валидации. Одним из применений средней точности при k является оценка качества рекомендаций, генерируемых рекомендательной системой .
Хотя фраза «среднее арифметическое» звучит избыточно, название метрики вполне уместно. В конце концов, эта метрика вычисляет среднее значение точности множественных усреднений для k значений.
смесь экспертов
Схема повышения эффективности нейронной сети путем использования только подмножества ее параметров (известного как эксперт ) для обработки заданного входного токена или примера . Сеть-управляющий направляет каждый входной токен или пример к соответствующему эксперту (экспертам).
Более подробную информацию можно найти в одной из следующих статей:
- Невероятно большие нейронные сети: слой разреженно управляемой смеси экспертов.
- Маршрутизация с использованием комбинации экспертов и выбора эксперта
ММИТ
Сокращение от multimodal instruction-tuned (мультимодальная настройка инструкций) .
каскадирование моделей
Система, которая выбирает идеальную модель для конкретного запроса на вывод.
Представьте себе группу моделей, от очень больших (много параметров ) до гораздо меньших (значительно меньше параметров). Очень большие модели потребляют больше вычислительных ресурсов во время вывода , чем меньшие модели. Однако очень большие модели, как правило, могут выполнять более сложные запросы, чем меньшие. Каскадирование моделей определяет сложность запроса на вывод, а затем выбирает подходящую модель для выполнения вывода. Основная цель каскадирования моделей — снижение затрат на вывод за счет, как правило, выбора меньших моделей и выбора более крупной модели только для более сложных запросов.
Представьте, что небольшая модель работает на телефоне, а более крупная версия этой модели — на удалённом сервере. Эффективное каскадирование моделей снижает затраты и задержку, позволяя меньшей модели обрабатывать простые запросы и вызывая удалённую модель только для обработки сложных запросов.
См. также модель маршрутизатора .
модель маршрутизатора
Алгоритм, определяющий идеальную модель для вывода в каскадном построении моделей . Маршрутизатор моделей сам по себе обычно представляет собой модель машинного обучения, которая постепенно учится выбирать наилучшую модель для заданных входных данных. Однако иногда маршрутизатор моделей может быть более простым алгоритмом, не относящимся к машинному обучению.
МОЭ
Сокращение от "смешанная группа экспертов" .
МТ
Сокращение для машинного перевода .
Н
Нано
Относительно компактная модель Gemini , предназначенная для использования непосредственно на устройстве. Подробнее см. Gemini Nano .
Нет единственно верного ответа (NORA)
Задание , имеющее несколько правильных ответов . Например, следующее задание не имеет единственно правильного ответа:
Расскажите мне смешной анекдот про слонов.
Оценка ответов на вопросы, не имеющие единственно правильного ответа, обычно гораздо более субъективна, чем оценка вопросов с одним правильным ответом . Например, для оценки шутки про слона необходим систематический способ определения того, насколько смешна эта шутка.
НОРА
Сокращение от "нет единственно правильного ответа" .
Блокнот LM
Инструмент на основе Gemini, позволяющий пользователям загружать документы, а затем использовать подсказки для того, чтобы задавать вопросы, резюмировать или систематизировать эти документы. Например, автор может загрузить несколько коротких рассказов и попросить Notebook LM найти их общие темы или определить, какой из них лучше всего подойдет для экранизации.
О
один правильный ответ (ORA)
Вопрос , имеющий только один правильный ответ . Например, рассмотрим следующий вопрос:
Правда или ложь: Сатурн больше Марса.
Единственный правильный ответ — «истина» .
В отличие от ситуации, когда нет единственно правильного ответа .
одноразовая подсказка
Запрос , содержащий один пример, демонстрирующий, как должна отвечать большая языковая модель . Например, следующий запрос содержит один пример, показывающий, как большая языковая модель должна отвечать на запрос.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| Франция: EUR | Один пример. |
| Индия: | Сам запрос. |
Сравните и сопоставьте однократное подсказывание со следующими терминами:
ОРА
Сокращенное обозначение одного правильного ответа .
П
параметрически эффективная настройка
Набор методов для более эффективной тонкой настройки большой предварительно обученной языковой модели (PLM) , чем полная тонкая настройка . Параметроэффективная настройка обычно позволяет настроить гораздо меньше параметров , чем полная тонкая настройка, но, как правило, создает большую языковую модель , которая работает так же хорошо (или почти так же хорошо), как большая языковая модель, построенная на основе полной тонкой настройки.
Сравните и сопоставьте параметрически эффективную настройку с помощью:
Параметроэффективная настройка также известна как параметроэффективная тонкая настройка .
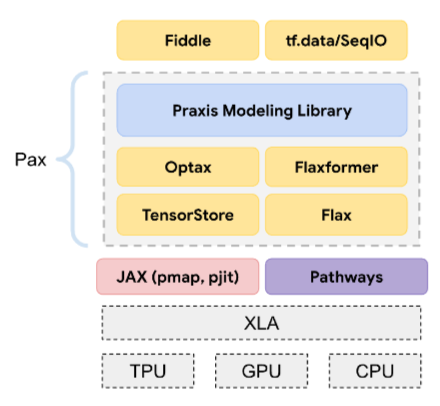
Пакс
Программная среда, предназначенная для обучения крупномасштабных моделей нейронных сетей , настолько больших, что они занимают несколько сегментов или блоков чипов ускорителей TPU .
Pax построен на Flax , который, в свою очередь, построен на JAX .
ПЛМ
Сокращение от pre-trained language model (предварительно обученная языковая модель).
постобученная модель
Термин с расплывчатым определением, обычно обозначающий предварительно обученную модель , прошедшую некоторую постобработку, например, одну или несколько из следующих:
предварительно обученная модель
Хотя этот термин может относиться к любой обученной модели или обученному вектору встраивания , в настоящее время под предварительно обученной моделью обычно подразумевается обученная большая языковая модель или другая форма обученной модели генеративного искусственного интеллекта .
См. также базовую модель и модель фундамента .
предварительная подготовка
Первоначальное обучение модели на большом наборе данных . Некоторые предварительно обученные модели представляют собой неуклюжие гиганты и, как правило, требуют доработки посредством дополнительного обучения. Например, эксперты по машинному обучению могут предварительно обучить большую языковую модель на огромном текстовом наборе данных, таком как все англоязычные страницы Википедии. После предварительного обучения полученная модель может быть дополнительно доработана с помощью любого из следующих методов:
- дистилляция
- тонкая настройка
- настройка инструкций
- параметрически эффективная настройка
- настройка подсказок
Про
Модель Gemini с меньшим количеством параметров , чем Ultra , но большим количеством параметров, чем Nano . Подробнее см. Gemini Pro .
быстрый
Any text entered as input to a large language model to condition the model to behave in a certain way. Prompts can be as short as a phrase or arbitrarily long (for example, the entire text of a novel). Prompts fall into multiple categories, including those shown in the following table:
| Категория подсказки | Пример | Примечания |
|---|---|---|
| Вопрос | How fast can a pigeon fly? | |
| Инструкция | Write a funny poem about arbitrage. | A prompt that asks the large language model to do something. |
| Пример | Translate Markdown code to HTML. For example: Markdown: * list item HTML: <ul> <li>list item</li> </ul> | The first sentence in this example prompt is an instruction. The remainder of the prompt is the example. |
| Роль | Explain why gradient descent is used in machine learning training to a PhD in Physics. | The first part of the sentence is an instruction; the phrase "to a PhD in Physics" is the role portion. |
| Partial input for the model to complete | The Prime Minister of the United Kingdom lives at | A partial input prompt can either end abruptly (as this example does) or end with an underscore. |
A generative AI model can respond to a prompt with text, code, images, embeddings , videos…almost anything.
prompt-based learning
A capability of certain models that enables them to adapt their behavior in response to arbitrary text input ( prompts ). In a typical prompt-based learning paradigm, a large language model responds to a prompt by generating text. For example, suppose a user enters the following prompt:
Summarize Newton's Third Law of Motion.
A model capable of prompt-based learning isn't specifically trained to answer the previous prompt. Rather, the model "knows" a lot of facts about physics, a lot about general language rules, and a lot about what constitutes generally useful answers. That knowledge is sufficient to provide a (hopefully) useful answer. Additional human feedback ("That answer was too complicated." or "What's a reaction?") enables some prompt-based learning systems to gradually improve the usefulness of their answers.
prompt design
Synonym for prompt engineering .
prompt engineering
The art of creating prompts that elicit the desired responses from a large language model . Humans perform prompt engineering. Writing well-structured prompts is an essential part of ensuring useful responses from a large language model. Prompt engineering depends on many factors, including:
- The dataset used to pre-train and possibly fine-tune the large language model.
- The temperature and other decoding parameters that the model uses to generate responses.
Prompt design is a synonym for prompt engineering.
See Introduction to prompt design for more details on writing helpful prompts.
prompt set
A group of prompts for evaluating a large language model . For example, the following illustration shows a prompt set consisting of three prompts:
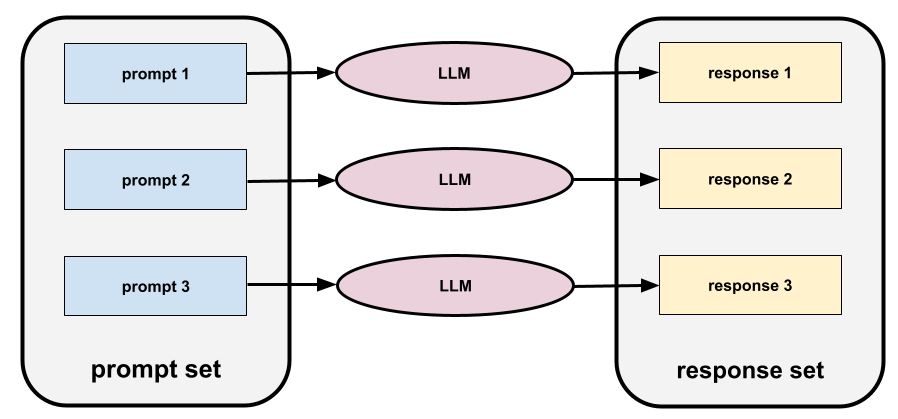
Good prompt sets consist of a sufficiently "wide" collection of prompts to thoroughly evaluate the safety and helpfulness of a large language model.
See also response set .
prompt tuning
A parameter efficient tuning mechanism that learns a "prefix" that the system prepends to the actual prompt .
One variation of prompt tuning—sometimes called prefix tuning —is to prepend the prefix at every layer . In contrast, most prompt tuning only adds a prefix to the input layer .
Р
reference text
An expert's response to a prompt . For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE ) measure the degree to which the reference text matches an ML model's generated text .
отражение
A strategy for improving the quality of an agentic workflow by examining (reflecting on) a step's output before passing that output to the next step.
The examiner is often the same LLM that generated the response (though it could be a different LLM). How could the same LLM that generated a response be a fair judge of its own response? The "trick" is to put the LLM in a critical (reflective) mindset. This process is analogous to a writer who uses a creative mindset to write a first draft and then switches to a critical mindset to edit it.
For example, imagine an agentic workflow whose first step is to create text for coffee mugs. The prompt for this step might be:
You are a creative. Generate humorous, original text of less than 50 characters suitable for a coffee mug.
Now imagine the following reflective prompt:
You are a coffee drinker. Would you find the preceding response humorous?
The workflow might then only pass text that receives a high reflection score to the next stage.
Reinforcement Learning from Human Feedback (RLHF)
Using feedback from human raters to improve the quality of a model's responses . For example, an RLHF mechanism can ask users to rate the quality of a model's response with a 👍 or 👎 emoji. The system can then adjust its future responses based on that feedback.
ответ
The text, images, audio, or video that a generative AI model infers . In other words, a prompt is the input to a generative AI model and the response is the output .
response set
The collection of responses a large language model returns to an input prompt set .
role prompting
A prompt , typically beginning with the pronoun you , that tells a generative AI model to pretend to be a certain person or a certain role when generating the response . Role prompting can help a generative AI model get into the right "mindset" in order to generate a more useful response. For example, any of the following role prompts might be appropriate depending on the kind of response you are seeking:
You have a PhD in computer science.
You are a software engineer who enjoys giving patient explanations about Python to new programming students.
You are an action hero with a very particular set of programming skills. Assure me that you will find a particular item in a Python list.
С
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning . Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
specificational coding
The process of writing and maintaining a file in a human language (for example, English) that describes software. You can then tell a generative AI model or another software engineer to create the software that fulfills that description.
Automatically-generated code generally requires iteration. In specificational coding, you iterate on the description file. By contrast, in conversational coding , you iterate within the prompt box. In practice, automatic code generation sometimes involves a combination of both specificational coding and conversational coding.
Т
температура
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and or string values.
У
Ультра
The Gemini model with the most parameters . See Gemini Ultra for details.
V
Вершина
Google Cloud's platform for AI and machine learning. Vertex provides tools and infrastructure for building, deploying, and managing AI applications, including access to Gemini models.кодирование вибрации
Prompting a generative AI model to create software. That is, your prompts describe the software's purpose and features, which a generative AI model translates into source code. The generated code doesn't always match your intentions, so vibe coding usually requires iteration.
Andrej Karpathy coined the term vibe coding in this X post . In the X post, Karpathy describes it as "a new kind of coding...where you fully give in to the vibes..." So, the term originally implied an intentionally loose approach to creating software in which you might not even examine the generated code. However, the term has rapidly evolved in many circles to now mean any form of AI-generated coding.
For a more detailed description of vibe coding, seeWhat is vibe coding? .
In addition, compare and contrast vibe coding with:
З
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. For example:
| Parts of one prompt | Примечания |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| Индия: | The actual query. |
The large language model might respond with any of the following:
- Рупия
- мРНК
- ₹
- индийская рупия
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: