דף זה מכיל מונחי מונחים ביסודות ML. לכל המונחים במילון המונחים, לחצו כאן.
A
דיוק
מספר החיזויים הנכונים לסיווג חלקי מספר החיזויים הכולל. כלומר:
לדוגמה, מודל שביצע 40 חיזויים נכונים ו-10 חיזויים שגויים, יקבל את רמת הדיוק של:
סיווג בינארי מספק שמות ספציפיים לקטגוריות השונות של חיזויים נכונים וחיזויים שגויים. לכן, נוסחת הדיוק לסיווג בינארי היא:
איפה:
- TP הוא מספר התוצאות החיוביות האמיתיות (חיזויים נכונים).
- TN הוא מספר התוצאות השליליות האמיתיות (חיזויים נכונים).
- FP הוא מספר התוצאות החיוביות השגויות (חיזויים שגויים).
- FN הוא מספר התוצאות השליליות השגויות (חיזויים שגויים).
השוו בין הדיוק באמצעות דיוק ואחזור.
פונקציית הפעלה
פונקציה שמאפשרת לרשתות נוירונים ללמוד על קשרים לא ליניאריים (מורכבים) בין תכונות לבין התווית.
פונקציות הפעלה פופולריות כוללות:
הגרפים של פונקציות ההפעלה הן אף פעם לא קווים ישרים בודדים. לדוגמה, התרשים של פונקציית ההפעלה של ReLU מורכב משני קווים ישרים:

תרשים של פונקציית ההפעלה סיגמואיד נראה כך:

אפשר ללחוץ על הסמל כדי לראות דוגמה.
ברשת נוירונים, פונקציות הפעלה מבצעות את הסכום המשוקלל של כל הקלט עבור נוירונים. כדי לחשב סכום משוקלל, הנוירון מסכם את המכפלות של הערכים והמשקולות הרלוונטיים. לדוגמה, נניח שהקלט הרלוונטי לנורון מורכב מהדברים הבאים:
| ערך קלט | משקל הקלט |
| 2 | 1.3- |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0נניח שהמעצב של רשת הנוירונים הזו בוחר בפונקציית הסיגמואיד כפונקציית ההפעלה. במקרה כזה, הנוירון מחשב את הסיגמואיד של 2.0-, שהוא בערך 0.12. לכן, הנוירון מעביר 0.12 (במקום -2.0) לשכבה הבאה ברשת הנוירונים. האיור הבא ממחיש את החלק הרלוונטי בתהליך:
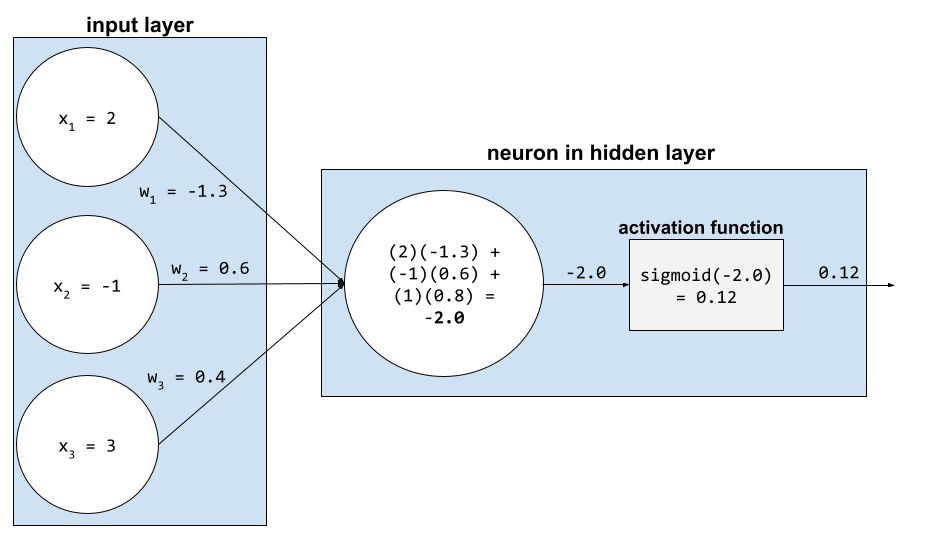
לגבי בינה מלאכותית,
תוכנית או model לא אנושיים שיכולים לפתור משימות מתוחכמות. לדוגמה, גם תוכניות או מודל שמתרגמים טקסט, תוכנית או מודל שמזהים מחלות באמצעות תמונות רדיולוגיות, מציגים בינה מלאכותית.
באופן רשמי, למידת מכונה היא תחום משנה בבינה מלאכותית. עם זאת, בשנים האחרונות, ארגונים מסוימים התחילו להשתמש במונחים בינה מלאכותית ולמידת מכונה לסירוגין.
AUC (אזור מתחת לעקומת ROC)
מספר בין 0.0 ל-1.0 שמייצג את היכולת של מודל סיווג בינארי להפריד בין מחלקות חיוביות ל-מחלקות שליליות. ככל שה-AUC קרוב יותר ל-1.0, כך טובה יותר היכולת של המודל להפריד בין סיווגים.
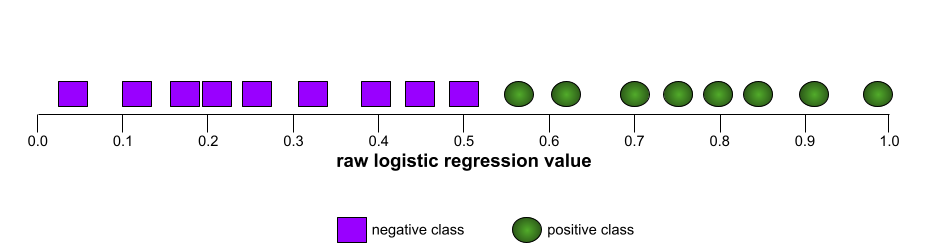
לדוגמה, באיור הבא מוצג מודל מסווג שמפריד באופן מושלם בין סיווגים חיוביים (אליפסות ירוקות) למחלקות שליליות (מלבנים סגולים). למודל הזה, שהוא מושלם באופן לא מציאותי, יש AUC 1.0:

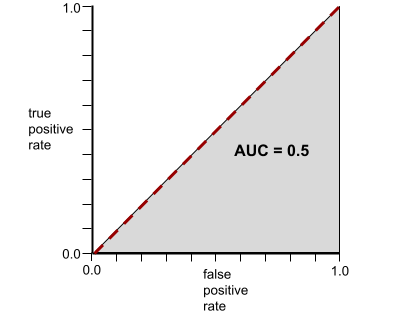
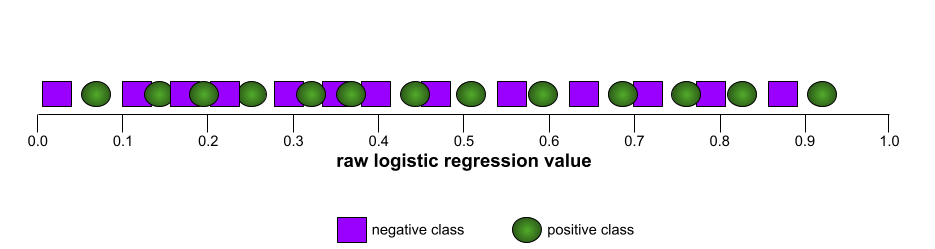
לעומת זאת, באיור הבא מוצגות התוצאות של מודל מסווג שיצר תוצאות אקראיות. במודל הזה יש AUC של 0.5:

כן, למודל הקודם יש AUC של 0.5, לא 0.0.
רוב המודלים נמצאים בין שתי נקודות הקיצון. לדוגמה, המודל הבא יוצר הפרדה מסוימת בין חיובי לשליליים, ולכן יש לו AUC בטווח שבין 0.5 ל-1.0:

AUC מתעלם מכל ערך שמגדירים לסף סיווג. במקום זאת, AUC בודק את כל ערכי הסף האפשריים לסיווג.
לוחצים על הסמל כדי לקבל מידע על הקשר בין עקומות AUC ועקומות ROC.
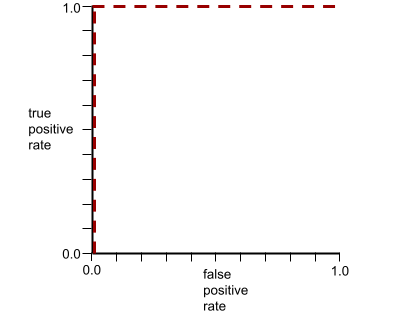
AUC מייצג את האזור מתחת לעקומת ROC. לדוגמה, עקומת ROC של מודל שמפריד באופן מושלם בין חיובי לבין שליליים נראית כך:
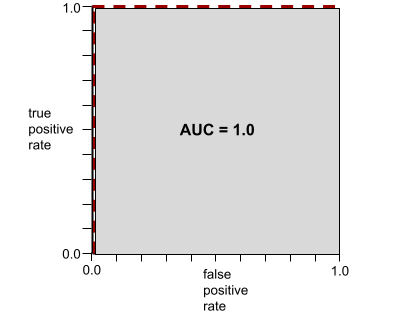
AUC הוא האזור של האזור האפור באיור הקודם. במקרה יוצא הדופן הזה, האזור הוא פשוט אורך האזור האפור (1.0) כפול רוחב האזור האפור (1.0). כלומר, מכפלה של 1.0 ו-1.0 מניבה AUC של 1.0 בדיוק, שהוא דירוג ה-AUC הגבוה ביותר האפשרי.
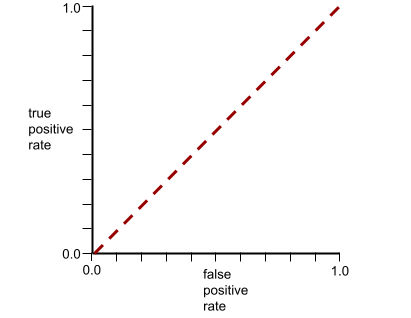
לעומת זאת, כאן מופיעה עקומת ROC של מסווג שלא יכול להפריד בין סיווגים. השטח של האזור האפור הוא 0.5.
עקומת ROC אופיינית יותר נראית בערך כך:
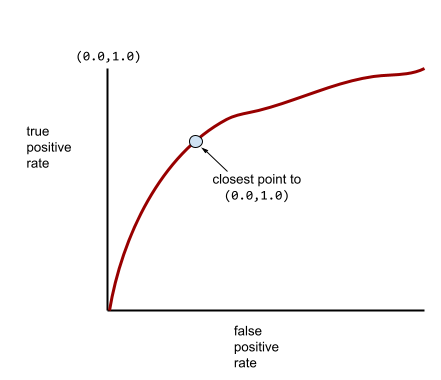
יהיה קשה לחשב את השטח מתחת לעקומה באופן ידני, ולכן התוכנית מחשבת בדרך כלל את רוב ערכי ה-AUC.
B
הפצה לאחור
האלגוריתם שמטמיע ירידה הדרגתית ברשתות נוירונים.
אימון רשת נוירונים כרוך בהרבה איטרציות במחזור הבא של שני שלבים:
- במהלך ההעברה הקדמית, המערכת מעבדת מקבץ של דוגמאות כדי ליצור חיזויים. המערכת משווה כל חיזוי לכל ערך label. ההבדל בין החיזוי לערך התווית הוא loss בדוגמה הזו. המערכת צוברת את ההפסדים עבור כל הדוגמאות כדי לחשב את סך כל ההפסדים באצווה הנוכחית.
- במהלך המעבר לאחור (backfilling), המערכת מצמצמת את האובדן על ידי התאמת המשקולות של כל הנוירונים בכל השכבות המוסתרות.
לרוב, רשתות נוירונים מכילות נוירונים רבים בשכבות נסתרות רבות. כל אחד מהנוירונים תורם לאובדן הכולל בדרכים שונות. הפצה לאחור קובעת אם להגדיל או להקטין את המשקולות שהוחלו על נוירונים מסוימים.
קצב הלמידה הוא מכפיל שקובע את המידה שבה כל העברה לאחור מגדילה או מקטינה כל משקל. קצב למידה גדול יעלה או יקטין כל משקל יותר מקצב למידה קטן.
במונחים בחשבון, הפצה לאחור מיישמת את כלל השרשרת מהחישוב. כלומר, הפצה לאחור מחשבת את הנגזרת החלקית של השגיאה תוך התחשבות בכל פרמטר.
לפני שנים, מומחי למידת מכונה היו צריכים לכתוב קוד כדי להטמיע הפצה לאחור. ממשקי API מודרניים של למידת מכונה, כמו TensorFlow, מטמיעים עכשיו הפצה לאחור. סוף סוף!
אצווה
קבוצת הדוגמאות המשמשות לאיטרציה אחת של אימון. גודל האצווה קובע את מספר הדוגמאות באצווה.
ראו את המאמר תקופה להסבר על האופן שבו אצווה קשורה לתקופה של זמן מערכת.
גודל אצווה
מספר הדוגמאות באצווה. לדוגמה, במקרה שגודל האצווה הוא 100, המודל מעבד 100 דוגמאות לכל איטרציה.
השיטות הבאות הן אסטרטגיות פופולריות לגודל אצווה:
- Stochastic Gradient Descent (SGD), שבו גודל האצווה הוא 1.
- קבוצת האימון המלאה, שבה גודל האצווה הוא מספר הדוגמאות בכל קבוצת האימון. לדוגמה, אם קבוצת האימון מכילה מיליון דוגמאות, גודל האצווה יהיה מיליון דוגמאות. חבילה מלאה היא בדרך כלל אסטרטגיה לא יעילה.
- mini-batch, שבו גודל האצווה הוא בדרך כלל בין 10 ל-1,000. מיני-אצווה היא בדרך כלל האסטרטגיה היעילה ביותר.
הטיה (אתיקה/הוגנות)
1. יצירת סטריאוטיפים, דעה קדומה או העדפה כלפי דברים מסוימים, אנשים או קבוצות על פני דברים אחרים. ההטיות האלה יכולות להשפיע על איסוף נתונים ופרשנות שלהם, על תכנון המערכת ועל האינטראקציה של המשתמשים עם המערכת. דוגמאות לסוג כזה של הטיה:
- הטיה של אוטומציה
- הטיית אישור
- ההטיה של הבודקים
- הטיה של שיוך קבוצתי
- הטיה מרומזת
- הטיה בתוך הקבוצה
- הטיית הומוגניות מחוץ לקבוצה
2. שגיאה שיטתית שמופיעה בהליך של דגימה או דיווח. דוגמאות לסוג כזה של הטיה:
חשוב להבחין במונח ההטיה במודלים של למידת מכונה או בהטיה של חיזוי.
מונח של הטיה (מתמטיקה) או של הטיה
יירוט או היסט ממקור. 'הטיה' היא פרמטר במודלים של למידת מכונה, שמסומן על ידי אחת מהאפשרויות הבאות:
- b
- ש0
לדוגמה, הטייה היא b בנוסחה הבאה:
בקו דו-ממדי פשוט, הטיה פירושה "חיתוך y". לדוגמה, הטיית הקו באיור הבא היא 2.
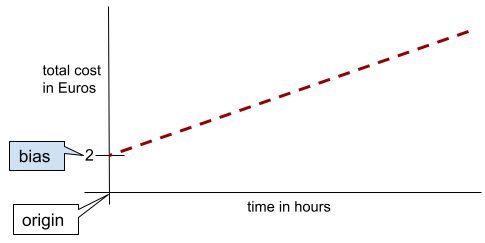
יש הטיה כי לא כל המודלים מתחילים מהמקור (0,0). לדוגמה, נניח שהכניסה לפארק שעשועים היא 2 אירו, ועלות נוספת של 0.5 אירו לכל שעה שבה לקוח שוהה. לכן, במודל שממפה את העלות הכוללת יש הטיה של 2 כי העלות הנמוכה ביותר היא 2 אירו.
חשוב להבדיל בין הטיה לבין הטיה של אתיקה והוגנות או הטיה של חיזוי.
סיווג בינארי
סוג של משימת סיווג שחוזה אחד משני מחלקות בלעדיות הדדיות:
לדוגמה, שני המודלים הבאים של למידת מכונה מבצעים כל אחד סיווג בינארי:
- מודל שקובע אם הודעות אימייל הן ספאם (הכיתה החיובית) או לא ספאם (המחלקה השלילית).
- מודל שמעריך תסמינים רפואיים כדי לקבוע אם לאדם יש מחלה מסוימת (המעמד החיובי) או אם אין לו את המחלה הזו (הסיווג השלילי).
בניגוד לסיווג מרובה מחלקות.
למידע נוסף, ראו רגרסיה לוגיסטית וסף סיווג.
חלוקה לקטגוריות
המרה של תכונה יחידה במספר תכונות בינאריות, שנקראות buckets או bins, בדרך כלל לפי טווח ערכים. המאפיין הקטוע הוא בדרך כלל ישות מתמשכת.
לדוגמה, במקום לייצג את הטמפרטורה כתכונה של נקודה צפה רציפה, אפשר לחתוך טווחי טמפרטורות לקטגוריות נפרדות, כמו:
- <= 10 מעלות צלזיוס תהיה הקטגוריה ה "קרה".
- הקטגוריה ה "מתונה" תהיה 11 עד 24 מעלות צלזיוס.
- >= 25 מעלות צלזיוס תהיה הדלי ה "חם".
המודל יתייחס לכל ערך באותה קטגוריה באופן זהה. לדוגמה, הערכים 13 ו-22 נמצאים בקטגוריה הממוזגת, כך שהמודל מתייחס לשני הערכים באופן זהה.
C
נתונים קטגוריים
תכונות עם קבוצה ספציפית של ערכים אפשריים. לדוגמה, שימו לב לתכונה קטגורית בשם traffic-light-state, שיכולה לכלול רק אחד משלושת הערכים האפשריים הבאים:
redyellowgreen
הצגת traffic-light-state כתכונה קטגורית מאפשרת למודל ללמוד את ההשפעות השונות של red, green ו-yellow על התנהגות הנהגים.
לפעמים תכונות קטגוריה נקראות תכונות שונות.
בניגוד לנתונים מספריים.
מחלקה
קטגוריה שתווית יכולה להשתייך אליה. למשל:
- במודל סיווג בינארי שמזהה ספאם, שתי המחלקות יכולות להיות ספאם ולא ספאם.
- במודל סיווג רב-סיווגי שמזהה גזעים של כלבים, המחלקות יכולות להיות פודל, ביגל, פאג וכן הלאה.
מודל סיווג יוצר תחזית של סיווג. לעומת זאת, מודל רגרסיה חוזה מספר ולא מחלקה.
מודל סיווג,
model שהחיזוי שלו הוא model. לדוגמה, אלה כל המודלים של הסיווג:
- מודל שחוזה את השפה של משפט קלט (צרפתית? ספרדית? איטלקית?).
- מודל שמנבא זני עצים (מייפל? Oak? באובב?).
- מודל שחוזה את הסיווג החיובי או השלילי של בעיה רפואית מסוימת.
לעומת זאת, מודלים של רגרסיה חוזים מספרים ולא מחלקות.
שני סוגים נפוצים של מודלים של סיווג הם:
סף סיווג (classification threshold)
בסיווג בינארי, מספר בין 0 ל-1 שממיר את הפלט הגולמי של מודל רגרסיה לוגיסטית לחיזוי של המחלקה החיובית או הסיווג השלילי. שימו לב שסף הסיווג הוא ערך שבן אדם בוחר, ולא ערך שנבחר באימון המודל.
מודל רגרסיה לוגיסטי יוצר ערך גולמי בין 0 ל-1. לאחר מכן:
- אם הערך הגולמי גדול מסף הסיווג, אז הסיווג החיובי צפוי.
- אם הערך הגולמי נמוך מסף הסיווג, אז צפוי הסיווג השלילי.
לדוגמה, נניח שסף הסיווג הוא 0.8. אם הערך הגולמי הוא 0.9, המודל חוזה את המחלקה החיובית. אם הערך הגולמי הוא 0.7, המודל חוזה את המחלקה השלילית.
סף הסיווג משפיע משמעותית על מספר התוצאות החיוביות השגויות והתוצאות השליליות השגויות.
מערך נתונים לא מאוזן לכיתה
מערך נתונים שמיועד לבעיית סיווג, שבה המספר הכולל של תוויות לכל מחלקה משתנה באופן משמעותי. לדוגמה, נשתמש במערך נתונים של סיווג בינארי ששתי התוויות שלו מחולקות באופן הבא:
- 1,000,000 תוויות שליליות
- 10 תוויות חיוביות
היחס בין התוויות השליליות לתוויות החיוביות הוא 100,000 ל-1, ולכן זהו מערך נתונים לא מאוזן לכיתה.
לעומת זאת, במערך הנתונים הבא אין איזון כיתתי כי היחס בין תוויות שליליות לתוויות חיוביות קרוב יחסית ל-1:
- 517 תוויות שליליות
- 483 תוויות חיוביות
גם מערכי נתונים מרובי מחלקות יכולים להיות לא איזון כיתתי. לדוגמה, מערך הנתונים הבא של סיווג מרובה-סיווגים גם הוא חסר איזון כיתתי כי לתווית אחת יש הרבה יותר דוגמאות מהשתיים האחרות:
- 1,000,000 תוויות עם המחלקה "ירוק"
- 200 תוויות עם המחלקה "סגול"
- 350 תוויות עם המחלקה "כתום"
למידע נוסף, ראו אנטרופיה, סיווג ראשי וסיווג מיעוט.
חיתוך
שיטה לטיפול בגורמים חריגים באמצעות אחת מהפעולות הבאות או שתיהן:
- הקטנת ערכי feature שגדולים מסף מקסימלי עד לסף המקסימלי.
- הגדלת ערכי תכונות שנמוכים מהסף המינימלי עד לסף המינימלי הזה.
לדוגמה, נניח שפחות מ-0.5% מהערכים של תכונה מסוימת נמצאים מחוץ לטווח 40-60. במקרה כזה, ניתן לבצע את הפעולות הבאות:
- צריך לחתוך את כל הערכים שמעל 60 (הסף המקסימלי) כך שיהיו 60 בדיוק.
- צריך לחתוך את כל הערכים מתחת ל-40 (הסף המינימלי) כך שהם יהיו בדיוק 40.
חריגים עלולים לפגוע במודלים, ולגרום לפעמים למשקל להציף במהלך אימון. בנוסף, ערכים חריגים יכולים לשבש בצורה דרמטית מדדים כמו דיוק. חיתוך היא שיטה נפוצה להגבלת הנזק.
חיתוך הדרגתי מאלצת ערכים של הדרגתיות בטווח מוגדר במהלך האימון.
מטריצת בלבול
טבלת NxN שמסכמת את מספר החיזויים הנכונים והשגיאות שנוצרו על ידי מודל סיווג. לדוגמה, אפשר להשתמש במטריצת הבלבול הבאה למודל סיווג בינארי:
| גידול (צפוי) | ללא גידול (חיזוי) | |
|---|---|---|
| גידול (אמת הקרקע) | 18 (TP) | 1 (FN) |
| ללא טמור (ground truth) | 6 (FP) | 452 (TN) |
מטריצת הבלבול הקודמת מציגה את הפרטים הבאים:
- מתוך 19 החיזויים שבהם ground truth היה Tumor, המודל סיווג בצורה נכונה 18 וסווג בצורה שגויה 1.
- מתוך 458 החיזויים שבהם אמת השורש הייתה 'לא טומור', המודל סיווג בצורה נכונה 452 וסווג בצורה שגויה 6.
מטריצת הבלבול לבעיה בסיווג מרובה סיווגים יכולה לעזור לכם לזהות דפוסים של טעויות. לדוגמה, נשתמש במטריצת הבלבול הבאה למודל סיווג רב-סיווגי בן 3 מחלקות, שמסווג שלושה סוגים שונים של קשתית העין (Virginica, Virsicolor ו-Setosa). כשהאמת הבסיסית הייתה וירג'יניה, מטריצת הבלבול מראה שיש סיכוי גדול בהרבה שהמודל יחזות בטעות את ורזיקולור מאשר סטוסה:
| Setosa (חיזוי) | Versicolor (חיזוי) | וירג'יניה (חזוי) | |
|---|---|---|---|
| סטוסה (ground truth) | 88 | 12 | 0 |
| Versicolor (אמת קרקע) | 6 | 141 | 7 |
| Virginica (ground truth) | 2 | 27 | 109 |
דוגמה נוספת: מטריצה מבלבלת יכולה לחשוף שמודל שאומן לזהות ספרות בכתב יד נוטה לחזות בטעות את המספר 9 במקום את המספר 4, או לחזות בטעות את המספר 1 במקום את 7.
מטריצות בלבול מכילות מספיק מידע כדי לחשב מגוון של מדדי ביצועים, כולל דיוק ואחזור.
פיצ'ר מתמשך
תכונה עם נקודה צפה (floating-point) עם טווח אינסופי של ערכים אפשריים, כמו טמפרטורה או משקל.
ליצור ניגוד עם תכונה שונה.
מתכנס
מצב שמתקבל כאשר ערכי loss משתנים מעט מאוד או לא משתנים כלל בכל איטרציה. לדוגמה, עקומת ההפסד הבאה מרמזת על התכנסות בערך ב-700 איטרציות:
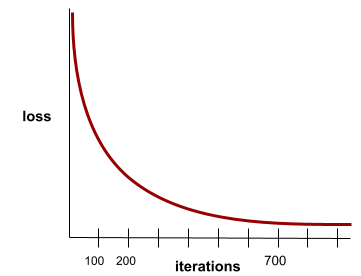
מודל מתכנס כשאימון נוסף לא משפר את המודל.
בלמידה עמוקה (Deep Learning), ערכי האובדן נשארים לפעמים קבועים או כמעט קבועים באיטרציות רבות עד בסופו של דבר. במהלך תקופה ארוכה של ערכי אובדן קבוע, יכול להיות באופן זמני לקבל תחושה שגויה של התכנסות.
כדאי גם לקרוא על עצירה מוקדמת.
D
DataFrame
סוג פופולרי של נתונים מסוג פנדות לייצוג מערכי נתונים בזיכרון.
A DataFrame דומה לטבלה או לגיליון אלקטרוני. לכל עמודה של DataFrame יש שם (כותרת), וכל שורה מזוהה באמצעות מספר ייחודי.
כל עמודה ב-DataFrame בנויה כמו מערך דו-ממדי, אבל ניתן להקצות לכל עמודה סוג נתונים משלה.
אפשר גם לעיין בדף העזר הרשמי של pandas.DataFrame.
קבוצת נתונים או מערך נתונים
אוסף של נתונים גולמיים, שמאורגנים בדרך כלל (אבל לא באופן בלעדי) באחד מהפורמטים הבאים:
- גיליון אלקטרוני
- קובץ בפורמט CSV (ערכים מופרדים בפסיקים)
מודל עמוק
רשת נוירונים שמכילה יותר משכבה נסתרת אחת.
מודל עמוק נקרא גם רשת נוירונים עמוקה.
הניגוד למודל רחב.
ישות צפופה
תכונה שבה רוב הערכים או כל הערכים הם שונים מאפס, בדרך כלל חיישן של ערכים של נקודה צפה (floating-point). לדוגמה, Tensor עם 10 רכיבים צפוף כי 9 מהערכים שלו שונים מאפס:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
הניגוד לתכונה מצומצמת.
עומק
סכום הערכים הבאים ברשת נוירונים:
- מספר השכבות המוסתרות
- מספר שכבות הפלט, שהוא בדרך כלל
- המספר של שכבות הטמעה
לדוגמה, לרשת נוירונים עם חמש שכבות מוסתרות ושכבת פלט אחת יש עומק של 6.
שימו לב ששכבת הקלט לא משפיעה על העומק.
תכונה נפרדת
תכונה עם קבוצה סופית של ערכים אפשריים. לדוגמה, ישות שהערכים שלה יכולים להיות רק בעל חיים, ירק או מינרל היא תכונה נפרדת (או קטגורית).
בניגוד לתכונה רציפה.
דינמי
משהו שמתבצע לעיתים קרובות או באופן רציף. המונחים דינמי ואונליין הם מילים נרדפות בלמידת מכונה. דוגמאות לשימושים נפוצים בלמידת מכונה דינמית ואונליין:
- מודל דינמי (או מודל אונליין) הוא מודל שעבר אימון מחדש לעיתים קרובות או באופן רציף.
- אימון דינמי (או הדרכה אונליין) הוא תהליך של אימון מתמשך או מתמשך.
- הסקה דינמית (או הסקה אונליין) היא התהליך של יצירת חיזויים על פי דרישה.
מודל דינמי
model שעובר אימון מחדש לעיתים קרובות (אולי גם באופן מתמשך). מודל דינמי הוא מודל ל "למידה במשך כל החיים", שמשתנה כל הזמן בהתאם לנתונים מתפתחים. מודל דינמי נקרא גם מודל אונליין.
ליצור ניגודיות עם מודל סטטי.
ה.
עצירה מוקדמת
שיטה להתאמה שכוללת סיום של אימונים לפני שהפסדת האימון מסתיים. בעצירה מוקדמת, האימון של המודל נפסק באופן מכוון כשהאובדן של מערך הנתונים לאימות מתחיל לגדול, כלומר כשהביצועים של ההכללה יורדים.
שכבת הטמעה
שכבה נסתרת מיוחדת שמאפשרת אימון על תכונה קטגורית בממדים גבוהים כדי ללמוד בהדרגה וקטור הטמעה של מאפיינים נמוכים יותר. שכבת הטמעה מאפשרת לרשת נוירונים לאמן הרבה יותר ביעילות מאשר אימון רק על התכונה הקטגורית בעלת הממדים הגבוהים.
לדוגמה, כדור הארץ תומך כרגע בכ-73,000 זני עצים. נניח שמיני עצים הם תכונה במודל, ולכן שכבת הקלט של המודל כוללת וקטור אחד חם באורך 73,000 רכיבים.
לדוגמה, אפשר לייצג את baobab בצורה הבאה:

מערך של 73,000 רכיבים הוא ארוך מאוד. אם לא תוסיפו למודל שכבת הטמעה, האימון יהיה ארוך מאוד עקב הכפלה של 72,999 אפסים. אולי תבחרו בשכבת ההטמעה שתהיה כוללת 12 מימדים. כתוצאה מכך, שכבת ההטמעה תלמד בהדרגה וקטור הטמעה חדש לכל סוג של עץ.
במצבים מסוימים, גיבוב הוא חלופה סבירה לשכבת הטמעה.
תקופה של זמן מערכת
העברת אימון מלא על כל ערכת האימון, כך שכל דוגמה עובדה פעם אחת.
תקופה של זמן מערכת (epoch) מייצגת N/גודל אצווה איטרציות, כאשר N הוא מספר הדוגמאות הכולל.
לדוגמה, נניח ש:
- מערך הנתונים מכיל 1,000 דוגמאות.
- גודל האצווה הוא 50 דוגמאות.
לכן, תקופה אחת של זמן מערכת מחייבת 20 איטרציות:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
דוגמה
הערכים של שורה אחת של תכונות ואולי גם תווית. דוגמאות ללמידה מונחית מתחלקות לשתי קטגוריות כלליות:
- דוגמה עם תווית כוללת תכונה אחת או יותר ותווית. במהלך האימון משתמשים בדוגמאות לתוויות.
- דוגמה ללא תווית כוללת תכונה אחת או יותר, אבל ללא תווית. במהלך ההסקה, נעשה שימוש בדוגמאות ללא תוויות.
לדוגמה, נניח שאתם מאמנים מודל כדי לקבוע את ההשפעה של תנאי מזג האוויר על ציוני בחינות של תלמידים. הנה שלוש דוגמאות לתוויות:
| תכונות | לייבל | ||
|---|---|---|---|
| טמפרטורה | לחות | לחץ | ציון הבחינה |
| 15 | 47 | 998 | טוב |
| 19 | 34 | 1020 | מצוינת |
| 18 | 92 | 1012 | גרועה |
הנה שלוש דוגמאות ללא תווית:
| טמפרטורה | לחות | לחץ | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
לדוגמה, השורה של מערך נתונים היא בדרך כלל המקור הגולמי. כלומר, דוגמה בדרך כלל מורכבת מקבוצת משנה של העמודות במערך הנתונים. בנוסף, התכונות בדוגמה יכולות לכלול גם תכונות סינתטיות, כמו צלבי תכונות.
נ
שלילי שגוי (FN)
דוגמה שבה המודל חוזה בטעות את המחלקה השלילית. לדוגמה, המודל חוזה שהודעת אימייל מסוימת היא לא ספאם (המחלקה השלילית), אבל הודעת האימייל הזו היא באמת ספאם.
תוצאה חיובית שקרית (FP)
דוגמה שבה המודל חוזה בטעות את הסיווג החיובי. לדוגמה, המודל חוזה שהודעת אימייל מסוימת היא ספאם (הכיתה החיובית), אבל הודעת האימייל שלמעשה היא לא ספאם.
שיעור חיובי כוזב (FPR)
היחס של הדוגמאות השליליות בפועל שעבורן המודל חזה בטעות את הסיווג החיובי. הנוסחה הבאה מחשבת את השיעור החיובי השגוי:
השיעור החיובי השגוי הוא ציר ה-X בעקומת ROC.
מאפיין
משתנה קלט למודל למידת מכונה. דוגמה כוללת תכונה אחת או יותר. לדוגמה, נניח שאתם מאמנים מודל כדי לקבוע את השפעת תנאי מזג האוויר על ציוני בחינות של תלמידים. בטבלה הבאה מוצגות שלוש דוגמאות, שכל אחת מהן מכילה שלוש תכונות ותווית אחת:
| תכונות | לייבל | ||
|---|---|---|---|
| טמפרטורה | לחות | לחץ | ציון הבחינה |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
יוצרים ניגודיות עם תווית.
צלב תכונות
תכונה סינתטית שנוצרה על ידי תכונות קטגוריותיות או מקטגוריות 'מצטלבות'.
לדוגמה, יש להשתמש במודל 'חיזוי מצב רוח' שמייצג את הטמפרטורה באחד מארבעת הקטגוריות הבאות:
freezingchillytemperatewarm
ומייצג את מהירות הרוח באחד משלושת הקטגוריות הבאות:
stilllightwindy
ללא צלבי תכונות, המודל הלינארי מתאמן באופן עצמאי על כל אחת משבע הקטגוריות השונות שקדמו לה. למשל, המודל מתאמן על freezing בלי קשר לאימון של windy, למשל.
לחלופין, אפשר ליצור שילוב של טמפרטורה ומהירות רוח. לתכונה הסינתטית האלה יהיו 12 הערכים האפשריים הבאים:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
הודות לשילובי תכונות שונים, המודל יכול לזהות הבדלים בין מצבי הרוח
בין יום אחד (freezing-windy) לבין יום אחד (freezing-still).
אם יוצרים תכונה סינתטית משתי תכונות שלכל אחת מהן יש הרבה קטגוריות שונות, לצלב התכונות שיתקבל יהיה מספר עצום של שילובים אפשריים. לדוגמה, אם בתכונה אחת יש 1,000 קטגוריות ובתכונה השנייה יש 2,000 קטגוריות, הצלב של התכונות שמתקבל כולל 2,000,000 קטגוריות.
באופן רשמי, צלב הוא מוצר קרטזי.
שילובי תכונות משמשים בעיקר במודלים ליניאריים, ורק לעיתים נדירות משתמשים בהם ברשתות נוירונים.
הנדסת פיצ'רים (feature engineering)
תהליך שכולל את השלבים הבאים:
- להחליט אילו תכונות יכולות להועיל לאימון המודל.
- המרת נתונים גולמיים ממערך הנתונים לגרסאות יעילות של התכונות האלה.
לדוגמה, יכול להיות שתגלו ש-temperature יכול להיות תכונה מועילה. לאחר מכן תוכלו להתנסות בקטגוריות כדי לבצע אופטימיזציה של מה שהמודל יכול ללמוד מטווחים שונים של temperature.
לפעמים הנדסת התכונות נקראת חילוץ תכונות או פיצ'ר.
קבוצת תכונות
קבוצת התכונות שהמודל של למידת המכונה מתאמן עליה. לדוגמה, המיקוד, גודל הנכס ומצב הנכס עשויים לכלול קבוצת תכונות פשוטה למודל לחיזוי מחירי הדיור.
וקטור מאפיין
המערך של ערכי feature שמהם מורכבת דוגמה. הווקטור של התכונה הוא קלט במהלך אימון ובמהלך הֶקֵּשׁ. לדוגמה, וקטור התכונה של מודל עם שתי תכונות נפרדות עשוי להיות:
[0.92, 0.56]
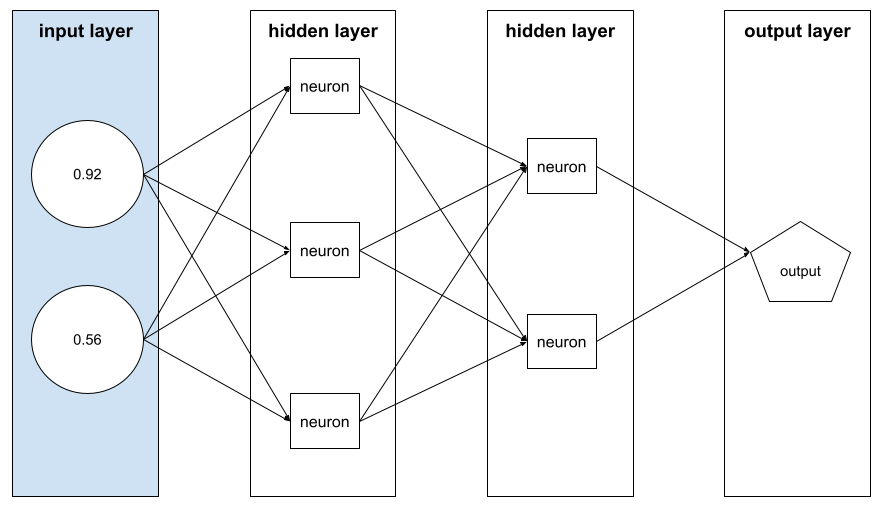
כל דוגמה מספקת ערכים שונים לווקטור המאפיין, כך שהווקטור של התכונה בדוגמה הבאה יכול להיות משהו כמו:
[0.73, 0.49]
הנדסת תכונות קובעת איך לייצג תכונות בווקטור המאפיין. לדוגמה, מאפיין בינארי קטגורי עם חמישה ערכים אפשריים עשוי להיות מיוצג באמצעות קידוד חמים אחד. במקרה כזה, החלק של וקטור התכונה בדוגמה מסוימת יכלול ארבעה אפסים ו-1.0 אחד במיקום השלישי, באופן הבא:
[0.0, 0.0, 1.0, 0.0, 0.0]
דוגמה נוספת, נניח שהמודל שלך מורכב משלוש תכונות:
- מאפיין בינארי קטגורי עם חמישה ערכים אפשריים, שמיוצגים באמצעות קידוד חד-פעמי, לדוגמה:
[0.0, 1.0, 0.0, 0.0, 0.0] - מאפיין בינארי קטגורי נוסף עם שלושה ערכים אפשריים המיוצגים באמצעות קידוד לוהט אחד. לדוגמה:
[0.0, 0.0, 1.0] - פיצ'ר של נקודה צפה (floating-point). לדוגמה:
8.3.
במקרה הזה, הווקטור של המאפיין בכל דוגמה ייוצג על ידי 9 ערכים. בהתאם לערכים לדוגמה שמפורטים ברשימה הקודמת, וקטור התכונה יהיה:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
לולאת משוב
בלמידת מכונה, מצב שבו התחזיות של המודל משפיעים על נתוני האימון של אותו מודל או של מודל אחר. לדוגמה, מודל שממליץ על סרטים ישפיע על הסרטים שאנשים צופים בו, וכך ישפיע על המודלים הבאים של המלצות על סרטים.
G
הכללה
היכולת של מודל לבצע חיזויים נכונים על נתונים חדשים, שלא נצפו בעבר. מודל שיכול להכליל הוא ההפך ממודל מתאים יותר.
עקומת הכללה
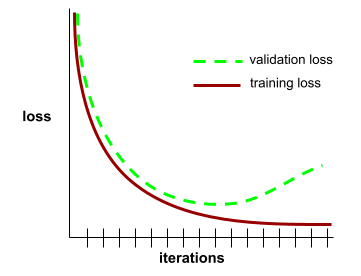
תרשים של הפסד אימון ואובדן אימות כפונקציה של מספר האיטרציות.
בעזרת עקומת ההכללה תוכלו לזהות הוספת יתר אפשרית. לדוגמה, עקומת ההכללה הבאה מרמזת על כך שאובדן האימות גבוה משמעותית מאובדן האימון.
ירידה הדרגתית
שיטה מתמטית למזעור ההפסד. ירידה הדרגתית מבצעת התאמות באופן חזרתי של המשקלים וההטיות, ומוצאת בהדרגתיות את השילוב הטוב ביותר כדי למזער את ההפסד.
ירידה הדרגתית היא תקופה ישנה יותר, הרבה יותר ישנה יותר מלמידת מכונה.
אמת מהותית
של המציאות.
הדבר שקרה בפועל.
לדוגמה, כדאי להשתמש במודל סיווג בינארי שחוזה אם תלמיד בשנה הראשונה באוניברסיטה יסיים את הלימודים תוך שש שנים. האמת הבסיסית במודל הזה היא אם התלמיד/ה סיים את הלימודים תוך שש שנים.
H
שכבה נסתרת
שכבה ברשת נוירונים בין שכבת הקלט (המאפיינים) לשכבת הפלט (החיזוי). כל שכבה מוסתרת מורכבת מנוירון אחד או יותר. לדוגמה, רשת הנוירונים הבאה מכילה שתי שכבות נסתרות, הראשונה עם שלושה נוירונים והשנייה עם שני נוירונים:
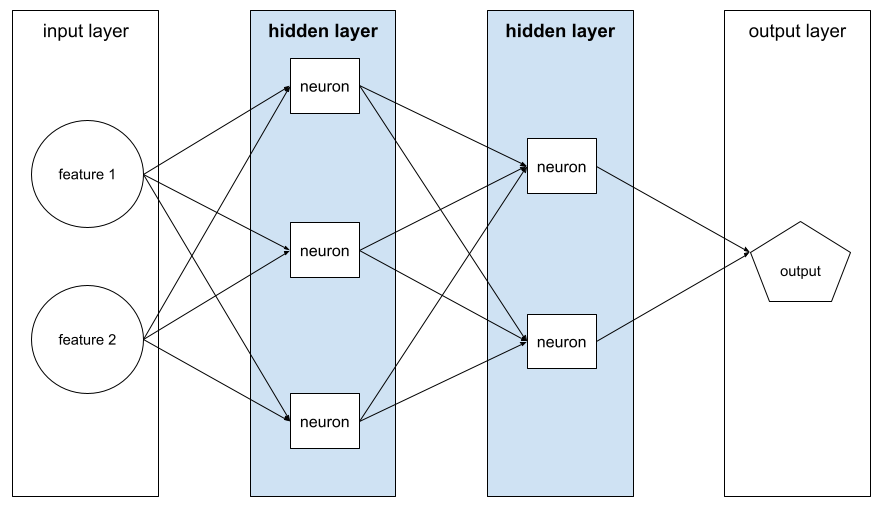
רשת נוירונים עמוקה מכילה יותר משכבה נסתרת אחת. לדוגמה, האיור שלמעלה הוא רשת נוירונים עמוקה כי המודל מכיל שתי שכבות נסתרות.
היפר-פרמטר
המשתנים שאתם או שירות כוונון של היפר-פרמטר משנים במהלך הרצות עוקבות של אימון מודל. לדוגמה, קצב הלמידה הוא היפר-פרמטר. אפשר להגדיר את קצב הלמידה ל-0.01 לפני מפגש הדרכה אחד. אם קבעתם ש-0.01 גבוה מדי, אולי תוכלו לשנות את קצב הלמידה ל-0.003 עבור מפגש האימון הבא.
לעומת זאת, פרמטרים הם המשקלים וההטיות השונות שהמודל לומד במהלך האימון.
I
שהופצה באופן עצמאי וזהה (כלומר
הנתונים שנלקחים מהתפלגות שלא משתנה, וכל ערך שנשלף לא תלוי בערכים ששורטטו קודם לכן. אחד מהם הוא הגז האידיאלי של למידת המכונה – מבנה מתמטי שימושי שכמעט אף פעם לא נמצא בעולם האמיתי. לדוגמה, התפלגות המבקרים בדף אינטרנט עשויה לנבוע מחלון זמן קצר. כלומר, ההתפלגות לא משתנה במהלך חלון קצר זה, וביקור של אדם אחד בדרך כלל אינו תלוי בביקור של אדם אחר. עם זאת, אם תרחיבו את חלון הזמן הזה, עשויים להופיע הבדלים עונתיים בין המבקרים בדף האינטרנט.
כדאי לעיין גם בקטע לא אזרחיות.
מסקנה
בלמידת מכונה, תהליך יצירת התחזיות על ידי החלת מודל מאומן על דוגמאות ללא תוויות.
להסקה יש משמעות מעט שונה בסטטיסטיקה. לפרטים נוספים, אפשר לעיין ב מאמר על הסקה סטטיסטית בוויקיפדיה.
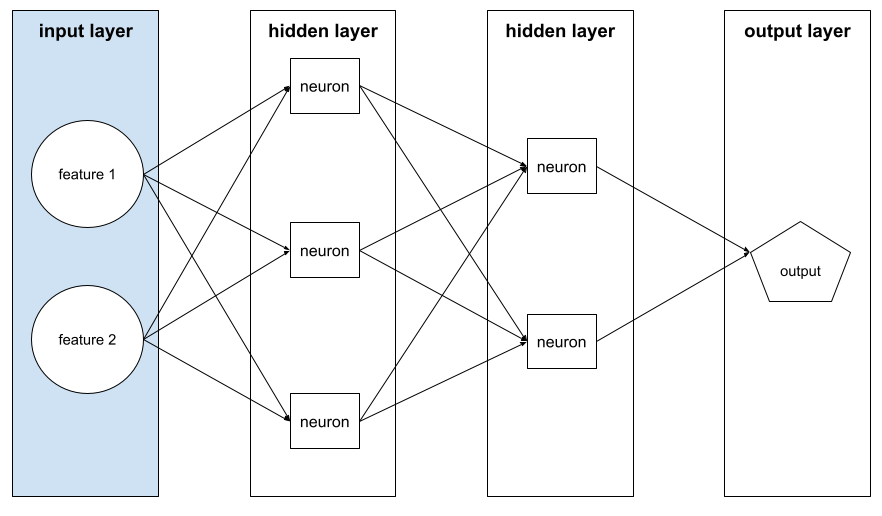
שכבת קלט
השכבה של רשת נוירונים שמכילה את וקטור התכונות. כלומר, שכבת הקלט מספקת דוגמאות לאימון או להסקה. לדוגמה, שכבת הקלט ברשת הנוירונים הבאה מורכבת משתי תכונות:
פרשנות
היכולת להסביר או להציג לבני אדם את ההיגיון של מודל למידת מכונה במונחים מובן.
לדוגמה, רוב המודלים של רגרסיה לינארית ניתנים לפירוש. (צריך רק לבחון את המשקולות המאומנות לכל תכונה). גם יערות קבלת החלטות ניתנים לפירוש. עם זאת, חלק מהמודלים דורשים תצוגה מתוחכמת כדי שניתן יהיה לפרש אותם.
אפשר להשתמש בכלי לפירוש נתונים (LIT) כדי לפרש מודלים של למידת מכונה.
איטרציה
עדכון יחיד של הפרמטרים של המודל – המשקלים וההטיות של המודל – במהלך ההדרכה. גודל האצווה קובע כמה דוגמאות המודל יעובד באיטרציה אחת. לדוגמה, אם גודל האצווה הוא 20, המודל יעבד 20 דוגמאות לפני התאמת הפרמטרים.
כשמאמנים רשת נוירונים, איטרציה אחת כוללת את שני המעברים הבאים:
- כרטיס קדימה שמשמש להערכת ההפסד באצווה אחת.
- העברה לאחור (הפצה לאחור) להתאמת הפרמטרים של המודל על סמך אובדן וקצב הלמידה.
L
רגולציית L0
סוג של ריקול שבמסגרתו מווסת המספר הכולל של משקלים שאינם אפס במודל. לדוגמה, במודל שיש בו 11 משקולות שאינן מאפס, יוטל קנס יותר מאשר על מודל דומה שיש בו 10 משקולות שאינן אפס.
רגולציית L0 נקראת לפעמים רגולזציה של L0-norm.
הפסד של L1
פונקציית הפסד שמחשבת את הערך המוחלט של ההפרש בין ערכי label בפועל לבין הערכים שמודל חוזה. לדוגמה, כך מחשבים את ההפסד של L1 עבור אצווה של חמש דוגמאות:
| הערך בפועל של הדוגמה | הערך החזוי של המודל | ערך מוחלט של דלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = הפסד של L1 | ||
אובדן L1 הוא פחות רגיש לחריגים לעומת הפסד L2.
השגיאה האבסולוטית הממוצעת היא ההפסד הממוצע של 1 לכל דוגמה.
רגולציה L1
סוג של ריקול שיש בו משקלים ביחס לסכום הערך המוחלט של המשקולות. הרגולזציה של L1 עוזרת להעלות את ערך המשקולות של תכונות לא רלוונטיות או כמעט רלוונטיות ל-0 בדיוק. בפועל, תכונה במשקל 0 מוסרת מהמודל.
הניגוד לרדירזציה של L2.
הפסד של L2
פונקציית הפסד שמחשבת את הריבוע של ההפרש בין ערכי label בפועל לבין הערכים שמודל חוזה. לדוגמה, כך מחשבים את ההפסד של L2 עבור אצווה של חמש דוגמאות:
| הערך בפועל של הדוגמה | הערך החזוי של המודל | ריבוע הדלתא |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = הפסד של L2 | ||
כתוצאה מצבירה, אובדן L2 מגביר את ההשפעה של ציונים חריגים. כלומר, אובדן L2 מגיב חזק יותר לתחזיות רעות מאשר לאובדן L1. לדוגמה, אובדן L1 של האצווה הקודמת יהיה 8 במקום 16. שימו לב שאף גורם חיצוני אחראי ל-9 מתוך 16.
מודלים של רגרסיה בדרך כלל משתמשים באובדן L2 כפונקציית אובדן.
השגיאה הממוצעת בריבוע היא הפסד של L2 בממוצע לכל דוגמה. Squared Loss (אובדן Squared) הוא שם נוסף לאובדן של L2.
רגולציית L2
סוג של ריקול שיש בו משקלים ביחס לסכום של הריבועים של המשקולות. הרגולזציה של L2 עוזרת להשיג משקלים חריגים (בעלי ערכים חיוביים או נמוכים נמוכים) קרוב ל-0 אבל לא די ל-0. תכונות עם ערכים קרובים מאוד ל-0 נשארות במודל, אבל לא משפיעות על חיזוי המודל במידה רבה.
הרגולזציה של L2 תמיד משפרת את ההכללה במודלים לינאריים.
בניגוד לרגולזציה של L1.
label
בלמידת מכונה מבוקרת, החלק "תשובה" או "תוצאה" מדוגמה.
כל דוגמה עם תווית כוללת תכונה אחת או יותר ותווית. לדוגמה, במערך נתונים לזיהוי ספאם, התווית תהיה ככל הנראה 'ספאם' או 'לא ספאם'. במערך נתונים של משקעים, התווית יכולה להיות כמות הגשם שירד בתקופה מסוימת.
דוגמה עם תווית
דוגמה שכוללת לפחות תכונות וגם תווית. לדוגמה, הטבלה הבאה מציגה שלוש דוגמאות בעזרת תוויות ממודל של הערכת בית, שלכל אחת יש שלוש תכונות ותווית אחת:
| מספר חדרי שינה | מספר חדרי הרחצה | גיל הבית | מחיר לבית (תווית) |
|---|---|---|---|
| 3 | 2 | 15 | 1380,000 ש"ח |
| 2 | 1 | 72 | 716,000 ש"ח |
| 4 | 2 | 34 | 1,568,000 ש"ח |
בלמידת מכונה מפוקחת, המודלים מתאמנים על דוגמאות מסומנות ויוצרים תחזיות על דוגמאות ללא תוויות.
ניגודיות בין דוגמה עם תווית לדוגמאות ללא תוויות.
למבדה
מילה נרדפת לשיעור רגולטור.
למבדה הוא מונח עמוס מדי. כאן אנחנו מתמקדים בהגדרת המונח, במסגרת הרמוניה.
שכבה
קבוצה של נוירונים ברשת נוירונים. קיימים שלושה סוגים נפוצים של שכבות:
- שכבת הקלט, שמספקת ערכים לכל התכונות.
- שכבות מוסתרות אחת או יותר, שמוצאות קשרים לא לינאריים בין התכונות לבין התווית.
- שכבת הפלט, שמספקת את החיזוי.
לדוגמה, באיור הבא מוצגת רשת נוירונים עם שכבת קלט אחת, שתי שכבות מוסתרות ושכבת פלט אחת:
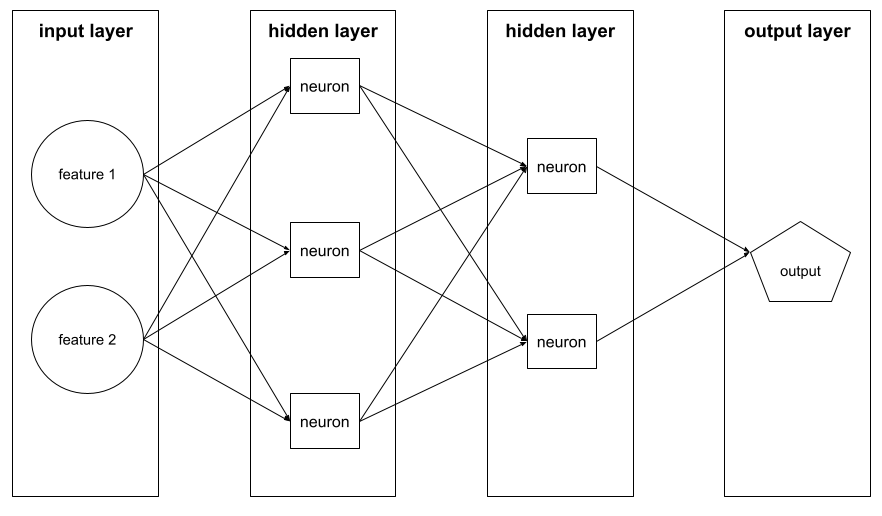
ב-TensorFlow, layers הן גם פונקציות Python שמקבלות את Tensors ואפשרויות הגדרה כקלט, ומייצרות tensorים אחרים כפלט.
קצב למידה
מספר עם נקודה צפה (floating-point) שמציין לאלגוריתם של הירידה בהדרגתיות עד כמה חזקה לצורך התאמה של משקלים והטיות בכל איטרציה. לדוגמה, קצב למידה של 0.3 ישנה את המשקולות וההטיות בעוצמה גבוהה פי שלושה מקצב למידה של 0.1.
קצב הלמידה הוא היפר-פרמטר מרכזי. אם קצב הלמידה יהיה נמוך מדי, האימון יימשך יותר מדי זמן. אם תגדירו את קצב הלמידה גבוה מדי, לעיתים קרובות לא תהיה לכם אפשרות להגיע להמרות בירידה הדרגתית.
ליניארי
קשר בין שני משתנים או יותר שאפשר לייצג רק באמצעות חיבור וכפל.
התרשים של קשר לינארי הוא קו.
הניגודיות לערך לא לינארי.
מודל לינארי
model שמקצה model אחד לכל model לצורך יצירת model. (במודלים לינאריים יש גם הטיה). לעומת זאת, הקשר בין תכונות לחיזויים במודלים עמוקים הוא בדרך כלל לא לינארי.
בדרך כלל קל יותר לאמן מודלים לינאריים והם יכולים לפרש אותם יותר מאשר מודלים עמוקים. עם זאת, מודלים עמוקים יכולים ללמוד בין תכונות של קשרים מורכבים.
רגרסיה לינארית ורגרסיה לוגיסטית הם שני סוגים של מודלים לינאריים.
רגרסיה ליניארית
סוג של מודל למידת מכונה שבו מתקיימים שני התנאים הבאים:
- המודל הוא מודל לינארי.
- החיזוי הוא ערך של נקודה צפה (floating-point). (זהו החלק של הרגרסיה של רגרסיה לינארית).
בצעו השוואה בין רגרסיה לינארית לרגרסיה לוגיסטית. כמו כן, רגרסיה של ניגודיות באמצעות סיווג.
רגרסיה לוגיסטית
סוג של מודל רגרסיה שצופה הסתברות. מודלים של רגרסיה לוגיסטית כוללים את המאפיינים הבאים:
- התווית היא קטגורית. המונח 'רגרסיה לוגיסטית' מתייחס בדרך כלל לרגרסיה לוגיסטית בינארית, כלומר למודל שמחשב הסתברויות לתוויות עם שני ערכים אפשריים. וריאנט פחות נפוץ רגרסיה לוגיסטית רב-נומית מחשב הסתברויות לתוויות עם יותר משני ערכים אפשריים.
- פונקציית האובדן במהלך האימון היא Log Loss. (ניתן למקם מספר יחידות של אובדן יומן רישום במקביל לתוויות שיש להן יותר משני ערכים אפשריים).
- למודל יש ארכיטקטורה לינארית, ולא רשת נוירונים עמוקה. עם זאת, שאר ההגדרה הזו חלה גם על מודלים עמוקים שחוזים הסתברויות לתוויות קטגוריות.
לדוגמה, כדאי להשתמש במודל רגרסיה לוגיסטי שמחשב את ההסתברות שאימייל קלט כלשהו יהיה ספאם או לא ספאם. במהלך ההסקה, נניח שהמודל חוזה 0.72. לכן, המודל מספק הערכה של:
- סיכוי של 72% שהאימייל יהיה ספאם.
- יש סיכוי של 28% שהאימייל לא יהיה ספאם.
מודל רגרסיה לוגיסטי משתמש בארכיטקטורה הדו-שלבית הבאה:
- המודל יוצר חיזוי גולמי (y) על ידי החלת פונקציה לינארית של תכונות קלט.
- המודל משתמש בחיזוי הגולמי הזה כקלט של פונקציית סיגמואיד, שממירה את החיזוי הגולמי לערך בין 0 ל-1, לא כולל.
בדומה לכל מודל רגרסיה, מודל רגרסיה לוגיסטי חוזה מספר. עם זאת, המספר הזה בדרך כלל הופך לחלק ממודל סיווג בינארי, באופן הבא:
- במקרה שהמספר החזוי גבוה מסף הסיווג, מודל הסיווג הבינארי יוצר תחזית לגבי המחלקה החיובית.
- במקרה שהמספר החזוי נמוך מסף הסיווג, מודל הסיווג הבינארי יוצר תחזית לגבי המחלקה השלילית.
אובדן יומן
פונקציית loss שמשמשת לרגרסיה לוגיסטית בינארית.
פונקציות יומן
הלוגריתם של הסיכויים לאירוע מסוים.
הפסד
במהלך ההדרכה של המודל בפיקוח, זהו מדד למרחק החיזוי מהתווית של המודל.
פונקציית loss מחשבת את האובדן.
עקומת אובדן
תרשים של loss כפונקציה של מספר החזרות לאימון. בתרשים הבא מוצגת עקומת הפסד אופיינית:
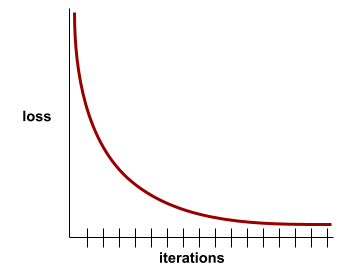
עקומות אובדן יכולות לעזור לכם לקבוע מתי המודל מתמזג או מתאים יותר.
עקומות אובדן יכולות להציג את כל סוגי ההפסדים הבאים:
- הפסד אימון
- אובדן אימות
- test Loss (הפסד בדיקה)
תוכלו לקרוא גם על עקומת ההכללה.
פונקציית אובדן
במהלך אימון או בדיקה, פונקציה מתמטית שמחשבת את פונקציית האובדן באצווה של דוגמאות. פונקציית אובדן מחזירה אובדן נמוך יותר למודלים שמספקים חיזויים טובים, מאשר למודלים שמספקים חיזויים גרועים.
בדרך כלל מטרת האימון היא למזער את האובדן שפונקציית אובדן מחזירה.
קיימים סוגים רבים ושונים של פונקציות אובדן. בחרו את פונקציית האובדן המתאימה לסוג המודל שאתם בונים. למשל:
- הפסד L2 (או שגיאה בריבוע הממוצע) הוא פונקציית האובדן של רגרסיה לינארית.
- Log Loss הוא פונקציית האובדן של רגרסיה לוגיסטית.
M
למידת מכונה
תוכנה או מערכת שמאמנות מודל מנתוני הקלט. המודל שעבר אימון יכול לספק תחזיות שימושיות מנתונים חדשים (שלא נצפו בעבר) שנלקחים מאותה התפלגות כמו זו ששימשה לאימון המודל.
למידת מכונה מתייחסת גם לתחום המחקר שרלוונטי לתוכניות או למערכות האלה.
מעמד הרוב
התווית הנפוצה יותר במערך נתונים לא מאוזן לסיווג. לדוגמה, בהינתן מערך נתונים שמכיל 99% תוויות שליליות ו-1% תוויות חיוביות, התוויות השליליות הן סיווג הרוב.
להשוות אותו לערך של סיווג מיעוט.
מיני אצווה
קבוצת משנה קטנה שנבחרה באופן אקראי של אצווה שמעובדת באיטרציה אחת. גודל האצווה הוא בדרך כלל בין 10 ל-1,000 דוגמאות.
לדוגמה, נניח שקבוצת האימון כולה (האצווה המלאה) כוללת 1,000 דוגמאות. בנוסף, נניח שהגדרתם את גודל האצווה של כל אצווה קטנה ל-20. לכן, כל איטרציה קובעת את האובדן ב-20 אקראיות מתוך 1,000 הדוגמאות, ולאחר מכן משנה את השקלולים וההטיות בהתאם.
הרבה יותר יעיל לחשב את האובדן על אצווה קטנה מאשר את ההפסד של כל הדוגמאות באצווה המלאה.
שיעור מיעוט
התווית הפחות נפוצה במערך נתונים לא מאוזן לסיווג. לדוגמה, בהינתן מערך נתונים שמכיל 99% תוויות שליליות ו-1% תוויות חיוביות, התוויות החיוביות הן קבוצות מיעוט.
הניגודיות לערך של סיווג רוב.
model
באופן כללי, כל מבנה מתמטי שמעבד נתוני קלט ומחזיר פלט. בניסוח שונה, מודל הוא קבוצת הפרמטרים והמבנה שדרושים למערכת כדי ליצור חיזויים. בלמידת מכונה מפוקחת, המודל לוקח דוגמה כקלט ומסיק חיזוי כפלט. המודלים של למידת מכונה מבוקרת שונים מעט. למשל:
- מודל רגרסיה לינארי מורכב מקבוצה של משקלים והטיה.
- מודל של רשת נוירונים כולל:
- קבוצה של שכבות מוסתרות, שכל אחת מהן מכילה נוירונים אחד או יותר.
- המשקולות וההטיות שקשורות לכל נוירון.
- מודל של עץ החלטות כולל:
- צורת העץ. כלומר, התבנית שבה התנאים והעלים מחוברים.
- התנאים והעלים.
אפשר לשמור מודל, לשחזר אותו או ליצור עותקים שלו.
למידת מכונה ללא פיקוח יוצרת גם מודלים, בדרך כלל פונקציה שיכולה למפות דוגמת קלט לאשכול המתאים ביותר.
סיווג מרובה-סיווגים
בלמידה מונחית, בעיית סיווג שבה מערך הנתונים מכיל יותר משתי סיווגים של תוויות. לדוגמה, התוויות במערך הנתונים של Iris חייבות להיות אחת משלוש המחלקות הבאות:
- איריס סטוסה
- איריס וירג'יקה
- קשתית בצבעי הקשת
מודל שאומן על מערך הנתונים של Iris שחוזה את הסוג של Iris על סמך דוגמאות חדשות, מבצע סיווג מרובה מחלקות.
לעומת זאת, בעיות סיווג שמבדילות בין שתי מחלקות בדיוק הן מודלים בינאריים של סיווג. לדוגמה, מודל אימייל שחוזה ספאם או לא ספאם הוא מודל סיווג בינארי.
בבעיות אשכולות, סיווג מרובה מחלקות מתייחס ליותר משני אשכולות.
לא
סיווג להחרגה
בסיווג בינארי, מחלקה אחת נקראת חיובי והשנייה נקראת שלילית. המחלקה החיובית היא הדבר או האירוע שהמודל בודק לגביהם, והסיווג השלילי הוא האפשרות הנוספת. למשל:
- הסיווג השלילי בבדיקה רפואית עשוי להיות "לא גידול".
- הסיווג השלילי במסווג אימייל עשוי להיות 'לא ספאם'.
הניגודיות לערך של סיווג חיובי.
רשת הזרימה קדימה
model שמכיל לפחות model אחת. רשת נוירונים עמוקה היא סוג של רשת נוירונים שמכילה יותר משכבה נסתרת אחת. לדוגמה, בתרשים הבא מוצגת רשת נוירונים עמוקה שמכילה שתי שכבות נסתרות.
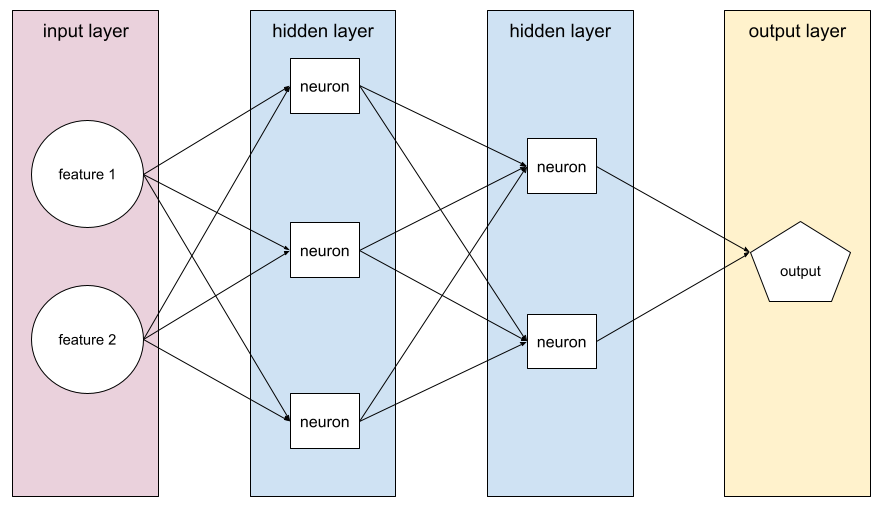
כל נוירון ברשת נוירונים מתחבר לכל הצמתים בשכבה הבאה. לדוגמה, בתרשים הקודם, שימו לב שכל אחד משלושת הנוירונים בשכבה המוסתרת הראשונה מתחברים בנפרד לשני הנוירונים בשכבה המוסתרת השנייה.
רשתות נוירונים שמוטמעות במחשבים נקראות לפעמים רשתות נוירונים מלאכותיות, על מנת להבדיל בינן לבין רשתות נוירונים שנמצאות במוח ובמערכות עצבים אחרות.
רשתות נוירונים מסוימות יכולות לחקות קשרים לא ליניאריים מורכבים מאוד בין תכונות שונות לבין התווית.
למידע נוסף, ראו רשת עצבית מתקפלת ורשת נוירונים חוזרת.
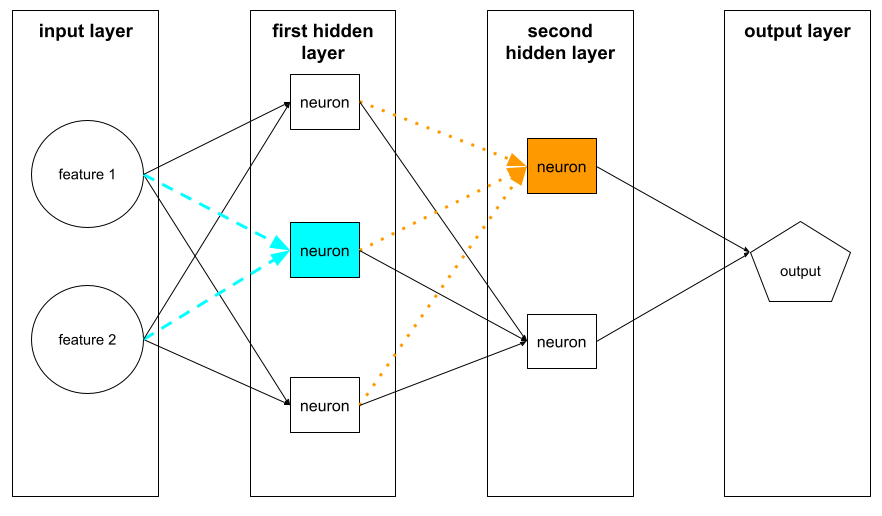
נוירונים
בלמידת מכונה, יחידה ייחודית בתוך שכבה מוסתרת של רשת נוירונים. כל נוירון מבצע את הפעולה הדו-שלבית הבאה:
- הפונקציה מחשבת את הסכום המשוקלל של ערכי הקלט כפול המשקולות שלהם.
- הפונקציה מחזירה את הסכום המשוקלל כקלט לפונקציית הפעלה.
נוירון בשכבה המוסתרת הראשונה מקבל קלט מערכי התכונות בשכבת הקלט. נוירון בכל שכבה נסתרת מחוץ לראשונה מקבל קלט מהנוירונים בשכבה המוסתרת הקודמת. לדוגמה, נוירון בשכבה המוסתרת השנייה מקבל קלט מהנוירונים בשכבה המוסתרת הראשונה.
באיור הבא מדגישים שני נוירונים ואת הקלט שלהם.
נוירונים ברשת נוירונים מחקה את ההתנהגות של נוירונים במוח ובחלקים אחרים של מערכות העצבים.
צומת (רשת נוירונים)
לא ליניארי
קשר בין שני משתנים או יותר שאי אפשר לייצג רק באמצעות חיבור וכפל. אפשר לייצג קשר לינארי כקו. אי אפשר לייצג קשר לא לינארי כקו. לדוגמה, נבחן שני מודלים שמקשרים בין תכונה אחת לתווית אחת. המודל משמאל הוא לינארי והמודל מימין הוא לא ליניארי:

לא סטייה
תכונה שהערכים שלה משתנים במאפיין אחד או יותר, בדרך כלל זמן. לדוגמה, שימו לב לדוגמאות הבאות של נאמנות לא אזרחית:
- מספר בגדי ים שנמכרים בחנות מסוימת משתנה בהתאם לעונה.
- כמות הפירות הנקצרים באזור מסוים היא אפס ברוב השנה, אבל לפרק זמן קצר.
- עקב שינויי האקלים, הטמפרטורות הממוצעות השנתיות משתנות.
הניגודיות של המשרד.
נירמול
באופן כללי, זהו תהליך ההמרה של טווח הערכים בפועל של משתנה לטווח ערכים סטנדרטי, כמו:
- -1 עד +1
- 0 על 1
- את ההתפלגות הנורמלית
לדוגמה, נניח שטווח הערכים בפועל של תכונה מסוימת הוא 800 עד 2,400. במסגרת הנדסת תכונות, אפשר לנרמל את הערכים בפועל עד לטווח סטנדרטי, כמו -1 עד +1.
נורמליזציה היא משימה נפוצה בהנדסת תכונות. מודלים בדרך כלל מתאמנים מהר יותר (ויוצרים חיזויים טובים יותר) כשלכל תכונה מספרית בוקטור התכונות יש פחות או יותר אותו טווח.
נתונים מספריים
תכונות מיוצגות כמספרים שלמים או כמספרים בעלי ערך אמיתי. לדוגמה, מודל של הערכת בית כנראה מייצג את גודל הבית (במטרים רבועים או במטרים רבועים) כנתונים מספריים. הצגת תכונה כנתונים מספריים מציינת שלערכי התכונה יש קשר מתמטי לתווית. כלומר, למספר המטרים רבועים בבית יש ככל הנראה קשר מתמטי כלשהו לערך של הבית.
לא כל הנתונים במספרים שלמים צריכים להיות מיוצגים כנתונים מספריים. לדוגמה, בחלקים מסוימים בעולם מספרי מיקוד הם מספרים שלמים. עם זאת, מספרי מיקוד שלמים לא צריכים להיות מיוצגים כנתונים מספריים במודלים. הסיבה לכך היא שהמיקוד של 20000 אינו בעל עוצמה כפולה (או חצי) ממיקוד של 10000. בנוסף, למרות שמספרי מיקוד שונים תואמים לערכי נדל"ן שונים, אנחנו לא יכולים להניח שערכי הנדל"ן במיקוד 20000 חשובים פי שניים מערכי הנדל"ן במיקוד 10000.
במקום זאת, המיקוד צריך להיות מיוצג כנתונים קטגוריים.
תכונות מספריות נקראות לפעמים תכונות רציפות.
O
אופליין
מילה נרדפת לסטטי.
מסקנות אופליין
התהליך של מודל שיוצר קבוצה של חיזויים ולאחר מכן שומר את החיזויים האלה במטמון (שמירה). לאחר מכן האפליקציות יכולות לגשת לחיזוי שהוסק מהמטמון במקום להריץ מחדש את המודל.
לדוגמה, כדאי להשתמש במודל שיוצר תחזיות מזג אוויר מקומיות (חיזויים) פעם בארבע שעות. אחרי כל הרצה של מודל, המערכת שומרת במטמון את כל תחזיות מזג האוויר המקומיות. אפליקציות מזג אוויר מאחזרות את התחזיות מהמטמון.
הסקת מסקנות אופליין נקראת גם הסקה סטטית.
בניגוד להשערות אונליין.
קידוד בחום אחיד
ייצוג נתונים קטגוריים כווקטור שבו:
- רכיב אחד מוגדר ל-1.
- כל שאר הרכיבים מוגדרים כ-0.
קידוד חד-פעמי משמש בדרך כלל לייצוג מחרוזות או מזהים שיש להם קבוצה סופית של ערכים אפשריים.
לדוגמה, נניח שלתכונה קטגורית מסוימת בשם Scandinavia יש חמישה ערכים אפשריים:
- "דנמרק"
- "שוודיה"
- "נורווגיה"
- "פינלנד"
- 'איסלנד'
קידוד חם אחד יכול לייצג כל אחד מחמשת הערכים באופן הבא:
| country | וקטור | ||||
|---|---|---|---|---|---|
| "דנמרק" | 1 | 0 | 0 | 0 | 0 |
| "שוודיה" | 0 | 1 | 0 | 0 | 0 |
| "נורווגיה" | 0 | 0 | 1 | 0 | 0 |
| "פינלנד" | 0 | 0 | 0 | 1 | 0 |
| 'איסלנד' | 0 | 0 | 0 | 0 | 1 |
הודות לקידוד בוהק אחד, המודל יכול ללמוד חיבורים שונים לפי כל אחת מחמש המדינות.
ייצוג של תכונה כנתונים מספריים הוא חלופה לקידוד חד-פעמי. לצערי, ייצוג מספרי של המדינות הסקנדינביות הוא לא בחירה טובה. לדוגמה, כדאי לשקול את הייצוג המספרי הבא:
- הערך של "דנמרק" הוא 0
- "Sweden" הוא 1
- 'נורווגיה' הוא 2
- 'פינלנד' היא 3
- 'איסלנד' היא 4
בעזרת קידוד מספרי, מודל יפרש את המספרים הגולמיים באופן מתמטי וינסה לאמן את המספרים האלה. עם זאת, איסלנד לא גדולה פי שניים (או חצי) מנורווגיה, כך שהמודל יסיק מסקנות מוזרות.
אחד נגד כולם
במקרה שיש בעיית סיווג עם N מחלקות, פתרון שמורכב מ-N מסווגים בינאריים נפרדים – מסווג בינארי אחד לכל תוצאה אפשרית. לדוגמה, בהינתן מודל שמסווג דוגמאות לבעלי חיים, לירקות או למינרלים, פתרון של 'אחד לעומת כולם' יספק את שלושת המסווגים הבינאריים הנפרדים הבאים:
- בעל חיים לעומת לא בעל חיים
- ירקות לעומת לא ירקות
- מינרל לעומת לא מינרל
online
מילה נרדפת ל-dynamic (דינמי).
מסקנה אונליין
יצירת תחזיות על פי דרישה. לדוגמה, נניח שאפליקציה מעבירה קלט למודל ומנפיקה בקשה לחיזוי. מערכת שמשתמשת בהֶקֵּשׁ אונליין מגיבה לבקשה באמצעות הרצת המודל (והחזרת החיזוי לאפליקציה).
בניגוד להסקת מסקנות אופליין.
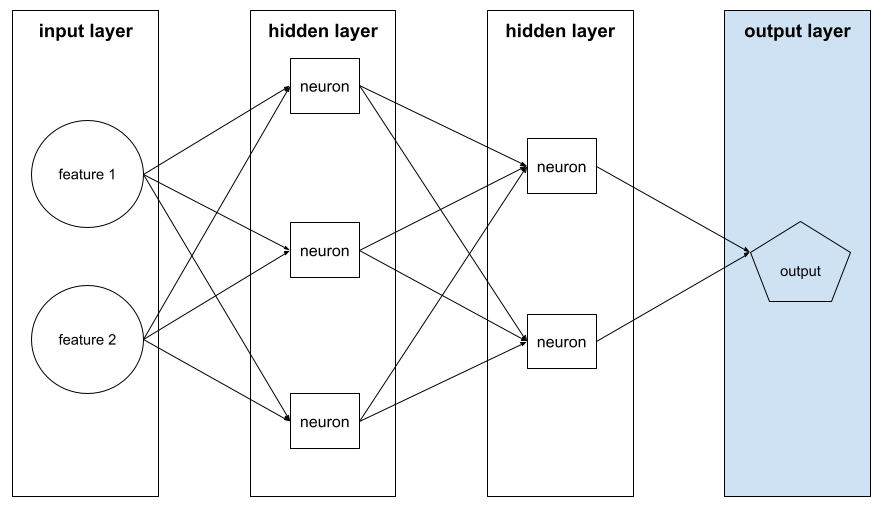
שכבת פלט
השכבה 'האחרונה' של רשת נוירונים. שכבת הפלט מכילה את החיזוי.
באיור הבא מוצגת רשת נוירונים עמוקה קטנה עם שכבת קלט, שתי שכבות נסתרות ושכבת פלט:
התאמת יתר (overfitting)
יצירת model שתואם לmodel עד כדי כך שהמודל לא מצליח לספק תחזיות נכונות לגבי נתונים חדשים.
העברה סדירה עשויה להפחית התאמת יתר. אימון סדרת אימונים גדולה ומגוונת יכולה גם לצמצם עומס יתר.
P
פנדות
API לניתוח נתונים מוכוון עמודות שמבוסס על numpy. מסגרות רבות של למידת מכונה, כולל TensorFlow, תומכות במבני נתונים של פנדות כקלט. למידע נוסף, תוכלו לקרוא את התיעוד של פנדות.
פרמטר
המשקלים וההטיות שהמודל לומד במהלך האימון. לדוגמה, במודל רגרסיה לינארית, הפרמטרים כוללים את ההטיות (b) ואת כל המשקולות (w1, w2, וכן הלאה) בנוסחה הבאה:
לעומת זאת, היפר-פרמטר הוא הערכים שאתם (או היפר-פרמטר להפעלת שירות) מספקים למודל. לדוגמה, קצב הלמידה הוא היפר-פרמטר.
שיעור חיובי
הכיתה שבחרת לבדוק.
לדוגמה, המחלקה החיובית במודל סרטן יכולה להיות 'גידול'. הכיתה החיובית במסווג אימיילים עשויה להיות "ספאם".
בניגוד לסיווג שלילי.
עיבוד תמונה (post-processing)
התאמת הפלט של מודל אחרי הפעלת המודל. לאחר עיבוד הנתונים אפשר לאכוף אילוצי הוגנות בלי לשנות את המודלים עצמם.
לדוגמה, אפשר להחיל אחרי עיבוד על מסווג בינארי על ידי הגדרת סף סיווג כך ששוויון הזדמנויות יישמר במאפיין מסוים, על ידי בדיקה שהשיעור החיובי האמיתי זהה בכל הערכים של המאפיין.
חיזוי (prediction)
הפלט של המודל. למשל:
- החיזוי של מודל סיווג בינארי הוא המחלקה החיובית או המחלקה השלילית.
- החיזוי של מודל סיווג מרובה מחלקות הוא מחלקה אחת.
- החיזוי של מודל רגרסיה ליניארי הוא מספר.
תוויות לשרת proxy
נתונים שמשמשים להערכה של תוויות שלא זמינות ישירות במערך נתונים.
לדוגמה, נניח שאתם צריכים לאמן מודל כדי לחזות את רמת הלחץ של העובדים. מערך הנתונים מכיל הרבה תכונות חיזוי, אבל הוא לא מכיל תווית בשם רמת המתח. בוחרים את התווית 'תאונות במקום העבודה' כתווית של שרת proxy לרמת הלחץ, בלי להתבייש. אחרי הכול, עובדים שנמצאים בלחץ גבוה קורים ליותר תאונות מאשר עובדים רגועים. או שאולי לא? אולי תאונות במקום העבודה עולות ויורדים מסיבות שונות.
דוגמה שנייה, נניח שאתם רוצים שהאם יורד גשם? בתור תווית בוליאנית למערך הנתונים, אבל מערך הנתונים לא מכיל נתוני גשם. אם יש לכם תמונות, תוכלו ליצור תמונות של אנשים שסוחבים מטריות כתווית שמייצגת את האם יורד גשם? האם זו תווית טובה לשרת proxy? יכול להיות, אבל לאנשים בתרבויות מסוימות יש סיכוי גדול יותר לשאת מטריות כדי להגן מפני השמש מאשר הגשם.
תוויות של שרת proxy לעיתים קרובות לא מושלמות. כשהדבר אפשרי, כדאי לבחור תוויות בפועל במקום תוויות של שרת proxy. עם זאת, אם חסרה תווית של שרת proxy, חשוב לבחור את התווית של שרת ה-proxy בקפידה ולבחור את התווית של שרת ה-proxy הכי פחות גרועה.
R
ר"מ
קיצור של יצירה משופרת באחזור.
מדרג
אדם שמספק תוויות לדוגמאות. 'עם הערות' הוא שם נוסף של המדרג.
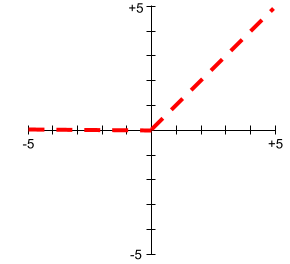
יחידה לינארית תקינה (ReLU)
פונקציית הפעלה עם ההתנהגות הבאה:
- אם הקלט הוא שלילי או אפס, אז הפלט הוא 0.
- אם הקלט הוא חיובי, הפלט שווה לקלט.
למשל:
- אם הקלט הוא 3-, אז הפלט הוא 0.
- אם הקלט הוא 3+, הפלט הוא 3.0.
הנה תרשים של ReLU:
ReLU היא פונקציית הפעלה פופולרית מאוד. למרות ההתנהגות הפשוטה שלה, ReLU עדיין מאפשר לרשת נוירונים ללמוד על קשרים לא לינאריים בין תכונות לבין התווית.
מודל רגרסיה
באופן לא רשמי, מודל שיוצר חיזוי מספרי. (לעומת זאת, מודל הסיווג יוצר חיזוי מחלקה). לדוגמה, אלה כל המודלים של רגרסיה:
- מודל שחוזה את הערך של בית מסוים, למשל 423,000 אירו.
- מודל שחוזה את תוחלת החיים של עץ מסוים, למשל 23.2 שנים.
- מודל לחיזוי כמות הגשם שתירד בעיר מסוימת בשש השעות הבאות, למשל 0.18 אינץ'.
שני סוגים נפוצים של מודלים של רגרסיה הם:
- רגרסיה לינארית, שמוצאת את הקו המתאים ביותר לערכי תוויות לתכונות.
- רגרסיה לוגיסטית, שיוצרת הסתברות בין 0.0 ל-1.0 שהמערכת בדרך כלל ממפה לחיזוי כיתתי.
לא כל מודל שמפיק חיזויים מספריים הוא מודל רגרסיה. במקרים מסוימים, חיזוי מספרי הוא בעצם מודל סיווג שיש לו שמות מחלקות מספריים. לדוגמה, מודל שחוזה את המיקוד המספרי הוא מודל סיווג, ולא מודל רגרסיה.
רגולריזציה (regularization)
כל מנגנון שמפחית את הוספת יתר. סוגים נפוצים של רגולציה כוללים:
- התאמה 1
- התאמה 2
- תהליך רגולציה חדשני מסוג נטישה
- עצירה מוקדמת (זו לא שיטת רגולטור רשמית, אבל היא יכולה להגביל ביעילות התאמת יתר)
אפשר להגדיר רגולציה כזאת גם כעונש על מורכבות המודל.
שיעור התאמה לשוק
מספר שמציין את החשיבות היחסית של ריכוז במהלך האימון. הגדלת קצב הרגולריזציה מפחיתה את ההתאמה, אבל עשויה להפחית את כוח החיזוי של המודל. לעומת זאת, הפחתה או השמטה של שיעור הרגולציה מגדילה את התאמת יתר.
ReLU
קיצור של יחידה לינארית ממופה.
יצירה משופרת באחזור (RAG)
שיטה לשיפור האיכות של הפלט של מודל שפה גדול (LLM) על ידי ביסוס שלו על מקורות מידע שאוחזרו אחרי אימון המודל. שיטת RAG משפרת את הדיוק של תשובות LLM באמצעות מתן גישה ל-LLM שעבר אימון, למידע שאוחזר ממאגרי ידע או ממסמכים מהימנים.
המטרות הנפוצות לשימוש ביצירה לשיפור אחזור כוללות:
- שיפור הדיוק העובדתי של התשובות שהמודל יוצר.
- להעניק למודל גישה לידע שהוא לא אומן.
- שינוי הידע שבו המודל משתמש.
- הפעלת המודל לצטט מקורות.
לדוגמה, נניח שאפליקציית כימיה משתמשת ב-PaLM API כדי ליצור סיכומים שקשורים לשאילתות של משתמשים. כשהקצה העורפי של האפליקציה מקבל שאילתה, הקצה העורפי:
- חיפושים ("אחזורים") של נתונים שרלוונטיים לשאילתת המשתמש.
- צירוף ("תוספים") של נתוני הכימיה הרלוונטיים לשאילתת המשתמש.
- מורה ל-LLM ליצור סיכום על סמך הנתונים המצורפים.
עקומת ROC (מאפיין הפעלה של מקלט)
תרשים של שיעור חיובי אמיתי לעומת שיעור חיובי שגוי עבור ערכי סף שונים לסיווג בסיווג בינארי.
הצורה של עקומת ROC מרמזת על היכולת של מודל סיווג בינארי להפריד בין סיווגים חיוביים למחלקות שליליות. לדוגמה, נניח שמודל סיווג בינארי מפריד בצורה מושלמת בין כל המחלקות השליליות לבין כל המחלקות החיוביות:
עקומת ROC למודל הקודם נראית כך:
לעומת זאת, האיור הבא מציג את הערכים הגולמיים של הרגרסיה הלוגיסטית למודל איום שלא יכול להפריד בכלל בין מחלקות שליליות למחלקות חיוביות:
עקומת ROC למודל הזה נראית כך:
לעומת זאת, בעולם האמיתי, רוב המודלים של סיווג בינארי מפרידים במידה מסוימת בין סיווגים חיוביים ושליליים, אבל בדרך כלל הם לא מושלמים. לכן, עקומת ROC טיפוסית נמצאת במקום כלשהו בין שתי הקיצוניות הקיצוניות:
הנקודה על עקומת ROC הקרובה ביותר ל-(0.0,1.0) מזהה באופן תיאורטי את סף הסיווג האידאלי. עם זאת, יש כמה בעיות אחרות בעולם האמיתי שמשפיעות על הבחירה של סף הסיווג האידיאלי לסיווג. לדוגמה, אולי תוצאות שליליות שקריות גורמות להרבה יותר כאב מאשר תוצאות חיוביות מוטעות.
מדד מספרי שנקרא AUC מסכם את עקומת ROC לערך של נקודה צפה (floating-point).
שורש השגיאה בריבוע הממוצע (RMSE)
השורש הריבועי של השגיאה הממוצעת בריבוע.
S
פונקציית סיגמואיד
פונקציה מתמטית ש'מדחיקה' ערך קלט לטווח מוגבל, בדרך כלל 0 עד 1 או -1 עד +1. כלומר, אפשר להעביר כל מספר (שני, מיליון, מיליארד שלילי או לא כל דבר) לסיגמואיד, והפלט עדיין יהיה בטווח המוגבל. תרשים של פונקציית ההפעלה סיגמואיד נראה כך:
לפונקציה סיגמואיד יש מספר שימושים בלמידת מכונה, כולל:
- המרת התפוקה הגולמית של מודל רגרסיה לוגיסטית או של רגרסיה מולטינומית להסתברות.
- היא משמשת כפונקציית הפעלה ברשתות נוירונים מסוימות.
softmax
פונקציה שקובעת הסתברויות לכל מחלקה אפשרית במודל סיווג מרובה מחלקות. ההסתברויות מסתכמות ל-1.0 בדיוק. לדוגמה, הטבלה הבאה מראה איך softmax מחלק הסתברויות שונות:
| התמונה היא... | Probability |
|---|---|
| כלב | .85 |
| cat | 13. |
| סוס | 02. |
softmax נקרא גם softmax מלא.
בניגוד לדגימת מועמד.
ישות מועטה
תכונה שהערכים שלה הם בעיקר אפס או ריקים. לדוגמה, מאפיין שמכיל ערך בודד של 1 ומיליון ערכים הוא 0 הוא חלקי. לעומת זאת, לתכונה צפופה יש ערכים שהם בעיקר לא אפס או ריקים.
בלמידת מכונה יש מעט תכונות שהן מעטות. תכונות קטגוריות הן בדרך כלל ישויות מועטות. לדוגמה, מתוך 300 זני העצים האפשריים ביער, דוגמה אחת יכולה לזהות רק עץ מייפל. או, מתוך מיליוני הסרטונים האפשריים בספריית סרטונים, רק דוגמה אחת יכולה לזהות את קזבלנקה.
במודל, אתם בדרך כלל מייצגים תכונות מיעוט באמצעות קידוד one-hot. אם הקידוד החד-פעמי גדול, אפשר להוסיף שכבת הטמעה על גבי הקידוד החד-פעמי כדי לשפר את היעילות.
ייצוג דל
אחסון רק את המיקום(או המיקומים) של רכיבים שאינם אפס בתכונה מצומצמת.
לדוגמה, נניח שתכונה קטגורית בשם species מזהה את 36 זני העצים ביער מסוים. בנוסף, נניח שכל דוגמה מזהה רק מין אחד.
בכל דוגמה אפשר להשתמש בווקטור חם אחד כדי לייצג את מין העצים.
וקטור אחד החם יכלול 1 יחיד (שמייצג את סוג העצים הספציפי בדוגמה הזו) ו-35 פריטי 0 (שמייצג את 35 זני העצים לא בדוגמה הזו). אז הייצוג החם ביותר של maple עשוי להיראות כך:

לחלופין, ייצוג דל פשוט יזהה את המיקום של המינים האלה. אם maple נמצא במיקום 24, הייצוג המועט של maple יהיה פשוט:
24
שימו לב שהייצוג הדליל הוא הרבה יותר קומפקטי מהייצוג בחום אחד.
לוחצים על הסמל כדי לראות דוגמה קצת יותר מורכבת.
נניח שכל דוגמה במודל שלך צריכה לייצג את המילים - אבל לא את הסדר של המילים האלה - במשפט באנגלית. באנגלית יש כ-170,000 מילים, כך שאנגלית היא קטגוריה שכוללת כ-170,000 רכיבים. ברוב המשפטים באנגלית משתמשים בחלק זעיר מאוד מתוך 170,000 המילים האלה, כך שקבוצת המילים בדוגמה אחת כמעט ודאית תהיה מועטה.
נשקול את המשפט הבא:
My dog is a great dog
אפשר להשתמש בווריאנט של וקטור חם אחד כדי לייצג את המילים במשפט הזה. בווריאנט הזה, כמה תאים בווקטור יכולים להכיל ערך שהוא לא אפס. בנוסף, בווריאנט הזה, תא יכול להכיל מספר שלם אחר. למרות שהמילים "my", "is", "a" ו-"נהדר" מופיעות רק פעם אחת במשפט, המילה "כלב" מופיעה פעמיים. השימוש בווריאנט הזה של וקטורים חמים אחדות כדי לייצג את המילים במשפט מניב את הווקטור הבא של 170,000 רכיבים:

ייצוג דלי של אותו משפט יהיה פשוט:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
וקטור sparse
וקטור שהערכים שלו הם בעיקר אפסים. למידע נוסף, אפשר לקרוא את המאמרים ניתוח נתונים וsparsity.
הפסד בריבוע
מילה נרדפת להפסד L2.
סטטי
פעולה שנעשתה פעם אחת ולא באופן רציף. המונחים סטטי ולא מקוון הם מילים נרדפות. ריכזנו כאן שימושים נפוצים בלמידת מכונה סטטית ואופליין:
- מודל סטטי (או מודל אופליין) הוא מודל שאומן פעם אחת ולאחר מכן משתמשים בו למשך זמן מה.
- אימון סטטי (או אימון אופליין) הוא התהליך של אימון מודל סטטי.
- הסקה סטטית (או הסקה אופליין) היא תהליך שבו מודל יוצר קבוצה של חיזויים בכל פעם.
ניגודיות לביטוי דינמי.
הסקה סטטית
מילה נרדפת להסקת מסקנות אופליין.
סטטוס נייח
תכונה שהערכים שלה לא משתנים במאפיין אחד או יותר, בדרך כלל זמן. לדוגמה, בתכונה שהערכים שלה דומים ב-2021 וב-2023 מוצגת ייצוג נייח.
בעולם האמיתי, מעט מאוד פריטים מציגים ייצוג נייח. ערכים נרדפים ליציבות (כמו גובה פני הים) לאורך זמן.
הניגוד לאידיאולוגיית נאמנות.
ירידה סטוכסטית בשיפוע (SGD)
אלגוריתם של ירידה הדרגתית שבו גודל האצווה הוא 1. במילים אחרות, SGD מאמן לפי דוגמה אחת שנבחרת באופן אקראי באופן אקראי מקבוצת אימון.
למידת מכונה מבוקרת
אימון model מ-model והmodel התואמות שלהן. למידת מכונה מבוקרת מקבילה ללמידת נושא, על ידי בחינת קבוצת שאלות והתשובות התואמות להן. אחרי שהם שולטים במיפוי בין השאלות והתשובות, התלמידים יכולים לענות על שאלות חדשות (שאף פעם לא ראיתם) באותו נושא.
בהשוואה ללמידת מכונה לא מונחית.
תכונה סינתטית
תכונה שלא קיימת בין תכונות הקלט, אלא מורכבת מאחת או יותר מהן. השיטות ליצירת תכונות סינתטיות כוללות:
- Bucketing – תכונה רציפה לסלי טווחים.
- יצירת מעבר תכונות.
- הכפלה (או חילוק) של ערך של תכונה אחת בערכי תכונה אחרים או בפני עצמה. לדוגמה, אם
aו-bהן תכונות של קלט, לפניכם דוגמאות לתכונות סינתטיות:- ab
- א2
- החלה של פונקציה טרנסצנדנטלית על ערך של תכונה. לדוגמה, אם
cהיא תכונה של קלט, לפניכם דוגמאות לתכונות סינתטיות:- sin(c)
- ln(c)
תכונות שנוצרו על ידי נרמול או קנה מידה תכונות לבדן לא נחשבות כסינתיות.
T
אובדן בדיקה
מדד שמייצג את ההפסד של המודל מול קבוצת הבדיקה. כשאתם יוצרים model, בדרך כלל כדאי לצמצם את אובדן הבדיקות. הסיבה לכך היא שהפסד נמוך בבדיקות הוא אות איכות חזק יותר מהפסד נמוך באימון או אובדן נמוך של האימות.
לפעמים, פער גדול בין אובדן של בדיקות לבין אובדן אימון או אובדן אימות – מצביע על כך שצריך להגדיל את שיעור הרגולטור.
הדרכה
תהליך קביעת הפרמטרים האידיאליים (משקולות והטיות) שמרכיבים מודל. במהלך האימון, המערכת קוראת דוגמאות ומתאימה את הפרמטרים בהדרגה. באימון אנחנו משתמשים בכל דוגמה, בין כמה פעמים למיליארדי פעמים.
אובדן אימון
מדד שמייצג את ההפסד של מודל במהלך איטרציה מסוימת של אימון. לדוגמה, נניח שפונקציית האובדן היא שגיאה בריבוע הממוצע. אולי אובדן האימון (Rean Squared Error) 2.2 באיטרציה העשירית הוא 2.2 ואובדן האימון באיטרציה ה-100 הוא 1.9.
בעקומת הפסד מוצג תרשים של אובדן אימון לעומת מספר החזרות. עקומת הפסד מספקת את הרמזים הבאים לגבי אימון:
- שיפוע כלפי מטה מצביע על כך שהמודל משתפר.
- שיפוע כלפי מעלה מרמז שהמודל מחמיר.
- אם יש שיפוע ישר, זה אומר שהמודל הגיע להמרות.
לדוגמה, עקומת ההפסד שעברה אידיאליזציה במידה מסוימת מציגה:
- שיפוע תלול כלפי מטה במהלך האיטרציות הראשוניות, שמרמז על שיפור מהיר של המודל.
- שיפוע הדרגתי (אבל עדיין כלפי מטה) עד קרוב לסוף האימון, מה שמרמז על המשך שיפור המודל בקצב מעט איטי יותר מאשר במהלך האיטרציות הראשוניות.
- שיפוע ישר לקראת סוף האימון, דבר המרמז על התכנסות.
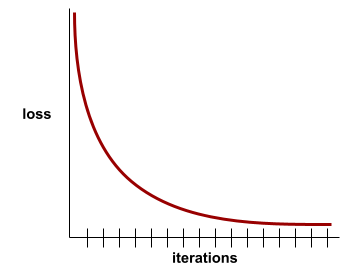
למרות שאובדן האימון חשוב, כדאי לקרוא גם את ההכללה.
training-serving skew
ההבדל בין ביצועי המודל במהלך האימון לבין הביצועים של אותו מודל במהלך הצגת המודעות.
ערכת אימון
קבוצת המשנה של מערך הנתונים שמשמש לאימון מודל.
באופן מסורתי, הדוגמאות במערך הנתונים מחולקות לשלוש קבוצות משנה נפרדות:
- ערכת אימון
- קבוצת אימות
- קבוצת בדיקה
באופן אידיאלי, כל דוגמה במערך הנתונים צריכה להשתייך רק לאחת מקבוצות המשנה הקודמות. לדוגמה, דוגמה אחת לא צריכה להשתייך גם לערכת האימון וגם לקבוצת התיקוף.
true negative (TN)
דוגמה שבה המודל חוזה נכון את המחלקה השלילית. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא לא ספאם ושהודעת האימייל באמת היא לא ספאם.
חיובי אמיתי (TP)
דוגמה שבה המודל חוזה נכון את הסיווג החיובי. לדוגמה, המודל מסיק שהודעת אימייל מסוימת היא ספאם ושהודעת האימייל באמת היא ספאם.
שיעור חיובי נכון (TPR)
מילה נרדפת לrecall. כלומר:
הקצב החיובי האמיתי הוא ציר ה-Y בעקומת ROC.
U
התאמה מלאה
יצירת model עם יכולת חיזוי נמוכה כי המודל לא השלים את המורכבות של נתוני האימון. הרבה בעיות יכולות לגרום להתאמה מלאה, כולל:
- הדרכה על קבוצה שגויה של תכונות.
- אימונים במשך מעט מדי תקופות של זמן או קצב למידה נמוך מדי.
- אימון עם שיעור רגולטור גבוה מדי.
- יצירת מעט מדי שכבות מוסתרות ברשת נוירונים עמוקה.
דוגמה ללא תווית
דוגמה שמכילה תכונות אבל לא תווית. לדוגמה, בטבלה הבאה מוצגות שלוש דוגמאות ללא תווית ממודל של הערכת בית, שלכל אחת יש שלוש תכונות אבל ללא ערך בית:
| מספר חדרי שינה | מספר חדרי הרחצה | גיל הבית |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
בלמידת מכונה מפוקחת, המודלים מתאמנים על דוגמאות מסומנות ויוצרים תחזיות על דוגמאות ללא תוויות.
בלמידה בפיקוח חצי וללא פיקוח, משתמשים בדוגמאות ללא תוויות במהלך האימון.
להשוות בין דוגמה ללא תווית לבין דוגמה עם תווית.
למידת מכונה בלתי מונחית
אימון model כדי למצוא דפוסים במערך נתונים, בדרך כלל במערך נתונים ללא תווית.
השימוש הנפוץ ביותר בלמידת מכונה לא מונחית הוא קיבוץ של נתונים לקבוצות של דוגמאות דומות. לדוגמה, אלגוריתם של למידה חישובית ללא פיקוח יכול לקבץ שירים באשכולות על סמך מאפיינים שונים של המוזיקה. האשכולות שמתקבלים יכולים להפוך לקלט של אלגוריתמים אחרים של למידת מכונה (לדוגמה, לשירות המלצות על מוזיקה). אשכולות יכולים לעזור כשתוויות שימושיות חסרות או חסרות. לדוגמה, בדומיינים כמו מניעת ניצול לרעה והונאה, אשכולות יכולים לעזור לאנשים להבין טוב יותר את הנתונים.
בניגוד ללמידת מכונה מבוקרת.
V
אימות
ההערכה הראשונית של איכות המודל. במסגרת האימות נבדקת איכות התחזיות של המודל מול קבוצת האימות.
מכיוון שקבוצת האימות שונה מערכת האימון, האימות עוזר להגן מפני התאמה יתר.
אפשר לחשוב על הערכת המודל מול מערך האימות שהוגדר בתור סבב הבדיקה הראשון, והערכה של המודל מול קבוצת הבדיקה כסבב הבדיקה השני.
אובדן של אימות
מדד שמייצג את ההפסד של המודל בקבוצת האימות במהלך איטרציה מסוימת של אימון.
תוכלו לקרוא גם על עקומת ההכללה.
קבוצת אימות
קבוצת המשנה של מערך הנתונים שמבצעת הערכה ראשונית מול מודל שעבר אימון. בדרך כלל, אתם בוחנים את המודל שעבר אימון מול קבוצת האימות כמה פעמים לפני שמעריכים את המודל מול קבוצת הבדיקה.
באופן מסורתי, מחלקים את הדוגמאות במערך הנתונים לשלוש קבוצות משנה נפרדות:
- ערכת אימון
- קבוצת אימות
- קבוצת בדיקה
באופן אידיאלי, כל דוגמה במערך הנתונים צריכה להשתייך רק לאחת מקבוצות המשנה הקודמות. לדוגמה, דוגמה אחת לא צריכה להשתייך גם לערכת האימון וגם לקבוצת התיקוף.
W
משקל
ערך שמודל מכפיל בערך אחר. אימון הוא התהליך של קביעת המשקולות האידיאליות של מודל. הֶקֵּשׁ הוא תהליך השימוש במשקולות שנלמדו כדי ליצור תחזיות.
סכום משוקלל
הסכום של כל ערכי הקלט הרלוונטיים כפול המשקולות התואמות שלהם. לדוגמה, נניח שהקלט הרלוונטי מכיל את הפרטים הבאים:
| ערך קלט | משקל הקלט |
| 2 | 1.3- |
| -1 | 0.6 |
| 3 | 0.4 |
לכן הסכום המשוקלל הוא:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
סכום משוקלל הוא ארגומנט הקלט של פונקציית הפעלה.
Z
נירמול ציון Z
שיטת התאמה לעומס (scaling) שמחליפה ערך גולמי של תכונה בערך של נקודה צפה (floating-point) שמייצג את מספר סטיות התקן מהממוצע של התכונה. לדוגמה, חשבו על תכונה שהממוצע שלה הוא 800 והסטיית התקן שלה היא 100. הטבלה הבאה מראה איך הנורמליזציה של ציון ה-Z תמפה את הערך הגולמי לציון ה-Z שלו:
| ערך גולמי | ציון Z |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | 2.25- |
לאחר מכן, המודל של למידת המכונה מתאמן על ציוני ה-Z לפי התכונה הזו ולא על הערכים הגולמיים.