Diese Seite enthält Glossarbegriffe zu ML Fundamentals. Alle Glossarbegriffe finden Sie hier.
A
Genauigkeit
Die Anzahl der korrekten Vorhersagen für die Klassifizierung geteilt durch die Gesamtzahl der Vorhersagen. Das bedeutet:
Ein Modell, das 40 richtige und 10 falsche Vorhersagen getroffen hat, hätte beispielsweise eine Genauigkeit von:
Die binäre Klassifizierung gibt den verschiedenen Kategorien von richtigen Vorhersagen und falschen Vorhersagen spezifische Namen. Die Genauigkeitsformel für die binäre Klassifizierung lautet also:
Dabei gilt:
- TP ist die Anzahl der richtig positiven (richtigen Vorhersagen).
- TN ist die Anzahl der richtig negativen Ergebnisse (richtige Vorhersagen).
- FP ist die Anzahl der falsch positiven Ergebnisse (falsche Vorhersagen).
- FN ist die Anzahl der falsch negativen (falschen Vorhersagen).
Die Genauigkeit mit Precision und Recall vergleichen und gegenüberstellen
Aktivierungsfunktion
Eine Funktion, mit der neuronale Netzwerke nicht lineare (komplexe) Beziehungen zwischen Features und dem Label lernen können.
Beliebte Aktivierungsfunktionen sind unter anderem:
Die Diagramme von Aktivierungsfunktionen bestehen nie aus einzelnen geraden Linien. Das Diagramm der ReLU-Aktivierungsfunktion besteht beispielsweise aus zwei geraden Linien:

Das Diagramm der Sigmoidaktivierungsfunktion sieht so aus:

Klicken Sie auf das Symbol, um ein Beispiel aufzurufen.
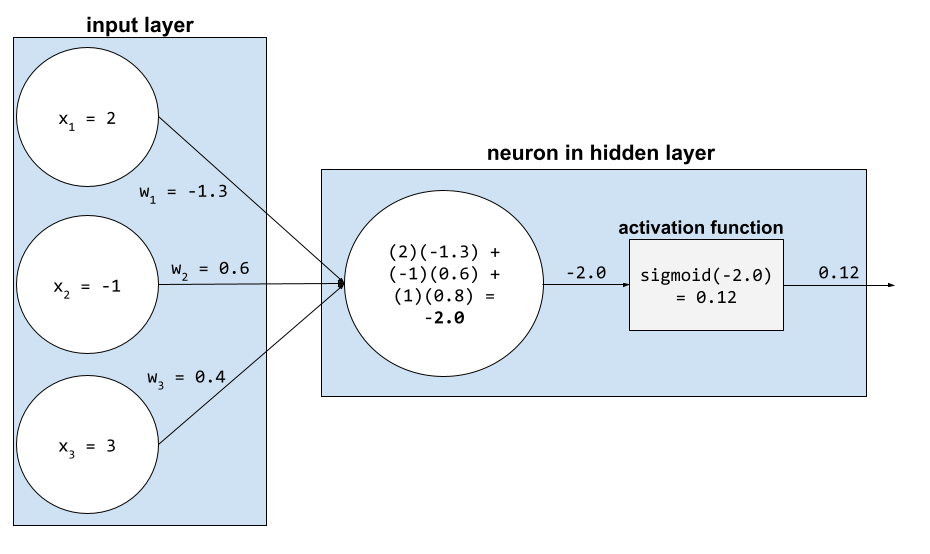
In einem neuronalen Netzwerk ändern Aktivierungsfunktionen die gewichtete Summe aller Eingaben in ein Neuron. Zur Berechnung einer gewichteten Summe addiert das Neuron die Produkte der relevanten Werte und Gewichtungen. Angenommen, die relevante Eingabe für ein Neuron besteht aus Folgendem:
| Eingabewert | Eingabegewichtung |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0Angenommen, der Designer dieses neuronalen Netzes wählt die Sigmoidfunktion als Aktivierungsfunktion aus. In diesem Fall berechnet das Neuron den Sigmoid von -2,0, was ungefähr 0,12 entspricht. Daher übergibt das Neuron 0,12 (statt -2,0) an die nächste Ebene im neuronalen Netzwerk. Die folgende Abbildung veranschaulicht den relevanten Teil des Prozesses:
künstliche Intelligenz
Ein nicht menschliches Programm oder model, das anspruchsvolle Aufgaben lösen kann Ein Programm oder Modell, das Text übersetzt, oder ein Programm oder Modell, das Krankheiten auf radiologischen Bildern identifiziert, weisen beide Arten von künstlicher Intelligenz auf.
Formell ist maschinelles Lernen ein Teilgebiet der künstlichen Intelligenz. In den letzten Jahren haben einige Unternehmen jedoch damit begonnen, die Begriffe künstliche Intelligenz und maschinelles Lernen austauschbar zu verwenden.
AUC (Fläche unter der ROC-Kurve)
Eine Zahl zwischen 0,0 und 1,0, die die Fähigkeit eines binären Klassifizierungsmodells darstellt, positive Klassen von negativen Klassen zu trennen. Je näher die AUC bei 1,0 liegt, desto besser ist das Modell in der Lage, Klassen voneinander zu trennen.
Die folgende Abbildung zeigt beispielsweise ein Klassifikatormodell, das positive Klassen (grüne Ovale) von negativen Klassen (violette Rechtecke) perfekt trennt. Dieses unrealistisch perfekte Modell hat eine AUC von 1,0:

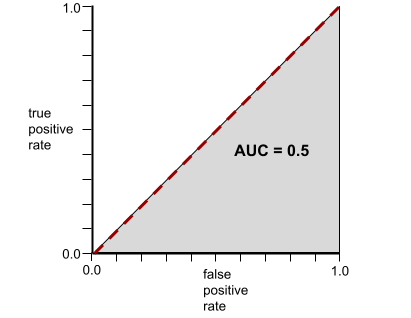
Umgekehrt zeigt die folgende Abbildung die Ergebnisse für ein Klassifikatormodell, das zufällige Ergebnisse generiert hat. Dieses Modell hat einen AUC von 0,5:

Ja, das vorherige Modell hat einen AUC von 0,5, nicht 0,0.
Die meisten Modelle befinden sich irgendwo zwischen den beiden Extremen. Das folgende Modell trennt beispielsweise Positive von negativen Werten etwas und hat daher einen AUC zwischen 0, 5 und 1, 0:

AUC ignoriert alle Werte, die Sie für den Klassifizierungsschwellenwert festgelegt haben. Stattdessen berücksichtigt AUC alle möglichen Klassifizierungsschwellenwerte.
Klicken Sie auf das Symbol, um mehr über die Beziehung zwischen AUC- und ROC-Kurven zu erfahren.
AUC steht für die Fläche unter einer ROC-Kurve. Die ROC-Kurve für ein Modell, das Positive von Negativen genau trennt, sieht beispielsweise so aus:
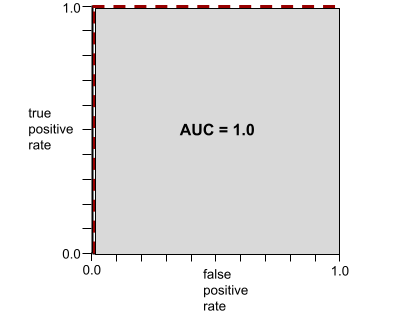
AUC ist die Fläche der grauen Region in der vorherigen Abbildung. In diesem ungewöhnlichen Fall ist der Bereich einfach die Länge des grauen Bereichs (1,0) multipliziert mit der Breite der grauen Region (1,0). Das Produkt von 1,0 und 1,0 ergibt also einen AUC-Wert von genau 1,0, was den höchstmöglichen AUC-Wert ist.
Umgekehrt sieht die ROC-Kurve für einen Klassifikator, der Klassen nicht trennen kann, so aus. Die Fläche dieser grauen Region beträgt 0,5.
Eine typischere ROC-Kurve sieht ungefähr so aus:
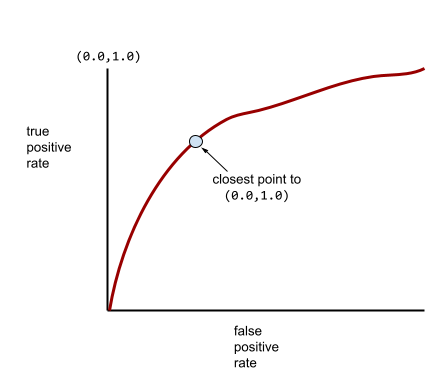
Es wäre mühsam, die Fläche unter dieser Kurve manuell zu berechnen. Deshalb berechnet ein Programm normalerweise die meisten AUC-Werte.
B
Backpropagation (Backpropagierung)
Der Algorithmus, der den Gradientenabstieg in neuronalen Netzwerken implementiert.
Das Training eines neuronalen Netzwerks umfasst viele Iterationen des folgenden Zyklus mit zwei Durchgängen:
- Während des Vorwärtsdurchlaufs verarbeitet das System einen Batch von Beispielen, um Vorhersagen zu liefern. Das System vergleicht jede Vorhersage mit jedem label-Wert. Die Differenz zwischen der Vorhersage und dem Labelwert ist der loss für dieses Beispiel. Das System aggregiert die Verluste für alle Beispiele, um den Gesamtverlust für den aktuellen Batch zu berechnen.
- Während der Rückpropagierung (Rückpropagierung) reduziert das System den Verlust, indem es die Gewichtung aller Neuronen in allen verborgenen Ebenen anpasst.
Neuronale Netzwerke enthalten oft viele Neuronen auf vielen verborgenen Schichten. Jedes dieser Neuronen trägt auf unterschiedliche Weise zum Gesamtverlust bei. Rückpropagierung bestimmt, ob die auf bestimmte Neuronen angewendeten Gewichtungen erhöht oder verringert werden.
Die Lernrate ist ein Multiplikator, der das Ausmaß festlegt, in dem jeder Rückwärtsdurchlauf jede Gewichtung erhöht oder verringert. Eine große Lernrate erhöht oder verringert jede Gewichtung um mehr als eine kleine Lernrate.
In der Kalkulation wird durch die Rückpropagierung die Kettenregel aus der Kalkulation implementiert. Das heißt, die Rückpropagierung berechnet die partielle Ableitung des Fehlers in Bezug auf jeden Parameter.
Vor Jahren mussten ML-Anwender Code schreiben, um die Backpropagation zu implementieren. Moderne ML-APIs wie TensorFlow implementieren jetzt die Backpropagation für Sie. Geschafft!
Batch
Die Beispiele, die in einer Trainingsiteration verwendet werden. Die Batchgröße bestimmt die Anzahl der Beispiele in einem Batch.
Informationen dazu, wie sich ein Batch auf eine Epoche bezieht, finden Sie unter Epoche.
Batchgröße
Die Anzahl der Beispiele in einem Batch. Wenn die Batchgröße beispielsweise 100 beträgt, verarbeitet das Modell 100 Beispiele pro Iteration.
Im Folgenden sind beliebte Strategien für die Batchgröße aufgeführt:
- Stochastic Gradient Descent (SGD) mit einer Batchgröße von 1.
- Vollständiger Batch, bei dem die Batchgröße die Anzahl der Beispiele im gesamten Trainingssatz ist. Wenn das Trainings-Dataset beispielsweise eine Million Beispiele enthält, beträgt die Batchgröße eine Million Beispiele. Ein vollständiger Batch ist normalerweise eine ineffiziente Strategie.
- Minibatch, bei denen die Batchgröße normalerweise zwischen 10 und 1.000 liegt. Mini-Batch ist in der Regel die effizienteste Strategie.
Voreingenommenheit (Ethik/Fairness)
1. Vorurteile, Vorurteile oder Bevorzugung bestimmter Dinge, Personen oder Gruppen gegenüber anderen. Diese Verzerrungen können sich auf die Erfassung und Interpretation von Daten, das Design eines Systems und die Interaktion von Nutzern mit einem System auswirken. Zu den Formen dieser Art von Verzerrung gehören:
- Automatisierungsverzerrung
- Bestätigungsfehler
- Voreingenommenheit der Testperson
- Gruppenattributionsverzerrung
- implizite Voreingenommenheit
- In-Group-Verzerrung
- Out-Group-Homogenitätsverzerrung
2. Systematischer Fehler, der durch eine Stichproben- oder Berichterstattung verursacht wird. Zu den Formen dieser Art von Verzerrung gehören:
- Abdeckungsverzerrung
- Non-Response Bias
- Beteiligungsverzerrung
- Verzerrung der Berichterstattung
- Stichprobenverzerrung
- Auswahlverzerrung
Nicht zu verwechseln mit dem Begriff Verzerrung in ML-Modellen oder Vorhersageverzerrung.
Voreingenommenheit (Mathematik) oder Voreingenommenheitsbegriff
Achsenabschnitt oder Versatz von einem Ursprung. Verzerrungen sind ein Parameter in Modellen für maschinelles Lernen, der durch eine der folgenden Aktionen symbolisiert wird:
- b
- W0
Beispielsweise ist Verzerrung das b in der folgenden Formel:
Bei einer einfachen zweidimensionalen Linie bedeutet Verzerrung lediglich einen „y-Achsenabschnitt“. Beispielsweise beträgt die Verzerrung der Linie in der folgenden Abbildung 2.
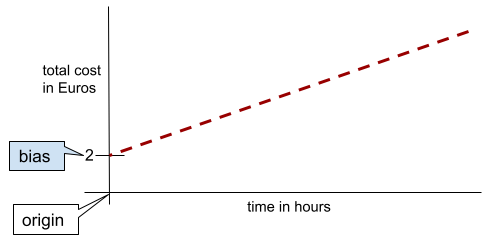
Es liegt eine Verzerrung vor, da nicht alle Modelle am Ursprung (0,0) beginnen. Beispiel: Ein Freizeitpark kostet 2 € und zusätzlich 0,5 € pro Stunde, die ein Kunde aufhält. Daher hat ein Modell, das die Gesamtkosten abbildet, eine Verzerrung von 2, da die niedrigsten Kosten 2 € sind.
Verzerrungen sind nicht mit Voreingenommenheit in Ethik und Fairness oder Vorhersageverzerrung zu verwechseln.
Binäre Klassifizierung
Ein Typ der Klassifizierungsaufgabe, die eine von zwei sich gegenseitig ausschließenden Klassen vorhersagt:
- der positiven Klasse
- die negative Klasse
Die folgenden beiden Modelle für maschinelles Lernen führen jeweils eine binäre Klassifizierung durch:
- Ein Modell, das bestimmt, ob E-Mails Spam (positive Klasse) oder kein Spam (negative Klasse) sind.
- Ein Modell, das medizinische Symptome bewertet, um festzustellen, ob eine Person eine bestimmte Krankheit (positive Klasse) oder nicht diese Krankheit (die negative Klasse) hat.
Kontrast mit der Klassifizierung mit mehreren Klassen
Weitere Informationen finden Sie unter Logistische Regression und Klassifizierungsschwellenwert.
Bucketing
Konvertieren eines einzelnen Features in mehrere binäre Features, die als Buckets oder Bins bezeichnet werden und in der Regel auf einem Wertebereich basieren. Das Chopped-Feature ist in der Regel ein kontinuierliches Feature.
Anstatt die Temperatur beispielsweise als einzelnes konstantes Gleitkommafeature darzustellen, können Sie Temperaturbereiche beispielsweise in separate Buckets aufteilen:
- <= 10 Grad Celsius wäre der „kalte“ Eimer.
- 11 bis 24 Grad Celsius wäre die Kategorie „Temperär“.
- >= 25 Grad Celsius wäre der „warme“ Eimer.
Das Modell behandelt jeden Wert im selben Bucket identisch. Beispielsweise befinden sich die Werte 13 und 22 beide im gemäßigten Bucket, sodass das Modell die beiden Werte identisch behandelt.
C
kategoriale Daten
Funktionen mit einem bestimmten Satz möglicher Werte Betrachten Sie beispielsweise ein kategoriales Feature namens traffic-light-state, das nur einen der folgenden drei möglichen Werte haben kann:
redyellowgreen
Durch Darstellung von traffic-light-state als kategoriales Feature kann ein Modell die unterschiedlichen Auswirkungen von red, green und yellow auf das Fahrerverhalten lernen.
Kategorische Merkmale werden manchmal als diskrete Merkmale bezeichnet.
Stellen Sie einen Kontrast zu numerischen Daten her.
Klasse
Eine Kategorie, zu der ein Label gehören kann. Beispiel:
- In einem binären Klassifizierungsmodell, das Spam erkennt, können die beiden Klassen Spam und Kein Spam sein.
- In einem Klassifizierungsmodell mit mehreren Klassen, das Hunderassen identifiziert, können die Klassen Pudel, Beagle, Mops usw. sein.
Ein Klassifizierungsmodell sagt eine Klasse vorher. Im Gegensatz dazu sagt ein Regressionsmodell eine Zahl statt einer Klasse vorher.
Klassifizierungsmodell
Ein model, dessen Vorhersage eine model ist. Im Folgenden finden Sie beispielsweise Klassifizierungsmodelle:
- Ein Modell, das die Sprache eines Eingabesatzes vorhersagt (Französisch? Spanisch? Italienisch?).
- Ein Modell, das Baumarten (Maple? Oak? Affenbrot?).
- Ein Modell, das die positive oder negative Klasse für eine bestimmte Krankheit vorhersagt.
Im Gegensatz dazu sagen Regressionsmodelle Zahlen statt Klassen voraus.
Zwei gängige Arten von Klassifizierungsmodellen sind:
Klassifizierungsschwellenwert
In einer binären Klassifizierung eine Zahl zwischen 0 und 1, die die Rohausgabe eines logistischen Regressionsmodells in eine Vorhersage der positiven Klasse oder der negativen Klasse umwandelt. Beachten Sie, dass der Klassifizierungsschwellenwert ein Wert ist, den ein Mensch auswählt, kein Wert, der durch das Modelltraining ausgewählt wird.
Ein logistisches Regressionsmodell gibt einen Rohwert zwischen 0 und 1 aus. Dann:
- Wenn dieser Rohwert größer als der Klassifizierungsschwellenwert ist, wird die positive Klasse vorhergesagt.
- Wenn dieser Rohwert kleiner als der Klassifizierungsschwellenwert ist, wird die negative Klasse vorhergesagt.
Angenommen, der Klassifizierungsschwellenwert beträgt 0,8. Ist der Rohwert 0,9, sagt das Modell die positive Klasse vorher. Wenn der Rohwert 0,7 ist, sagt das Modell die negative Klasse vorher.
Die Auswahl des Klassifizierungsschwellenwerts wirkt sich stark auf die Anzahl der falsch positiven und falsch negativen aus.
Dataset mit unausgeglichener Klasse
Ein Dataset für ein Klassifizierungsproblem, bei dem die Gesamtzahl der Labels jeder Klasse signifikant unterschiedlich ist. Betrachten Sie beispielsweise ein binäres Klassifizierungs-Dataset, dessen zwei Labels so unterteilt sind:
- 1.000.000 auszuschließende Labels
- 10 positive Labels
Das Verhältnis von negativen zu positiven Labels beträgt 100.000:1, also ist dies ein Dataset mit unausgeglichener Klasse.
Im Gegensatz dazu hat das folgende Dataset keine Klassenunausgeglichenheit, da das Verhältnis von negativen zu positiven Labels relativ nahe bei 1 liegt:
- 517 auszuschließende Labels
- 483 positive Labels
Datasets mit mehreren Klassen können auch ohne Klassenausgleichung vorliegen. Das folgende Klassifizierungs-Dataset mit mehreren Klassen ist beispielsweise ebenfalls klassenungleichmäßig, da ein Label weit mehr Beispiele hat als die anderen beiden:
- 1.000.000 Labels der Klasse „green“
- 200 Labels mit der Klasse „Lila“
- 350 Labels der Klasse „orange“
Weitere Informationen finden Sie unter Entropie, Mehrheitsklasse und Minderheitenklasse.
Clipping
Ein Verfahren zum Umgang mit Ausreißern, indem Sie einen oder beide der folgenden Schritte ausführen:
- Reduzieren der feature-Werte, die über einem maximalen Schwellenwert liegen, bis zu diesem maximalen Schwellenwert.
- Erhöhen der Featurewerte, die unter einem Mindestschwellenwert liegen, bis zu diesem Mindestschwellenwert.
Angenommen, < 0,5% der Werte für ein bestimmtes Feature liegen außerhalb des Bereichs von 40–60. In diesem Fall können Sie so vorgehen:
- Begrenzen Sie alle Werte über 60 (den maximalen Schwellenwert) auf genau 60.
- Begrenzen Sie alle Werte unter 40 (dem Mindestgrenzwert) so, dass sie genau 40 sind.
Ausreißer können Modelle beschädigen, was manchmal zu einem Überlauf von Gewichten während des Trainings führen kann. Einige Ausreißer können Messwerte wie die Genauigkeit erheblich beeinträchtigen. Clipping ist eine gängige Technik zur Begrenzung des Schadens.
Das Beschneiden von Farbverlauf erzwingt während des Trainings Gradientenwerte innerhalb eines bestimmten Bereichs.
Wahrheitsmatrix
Eine NxN-Tabelle, in der die Anzahl der richtigen und falschen Vorhersagen eines Klassifizierungsmodells zusammengefasst ist. Betrachten Sie beispielsweise die folgende Wahrheitsmatrix für ein binäres Klassifizierungsmodell:
| Tumor (prognostiziert) | Ohne Tumor (prognostiziert) | |
|---|---|---|
| Tumor (Ground Truth) | 18 (TP) | 1 (FN) |
| Kein Tumor (Ground Truth) | 6 (FP) | 452 (TN) |
Die obige Wahrheitsmatrix zeigt Folgendes:
- Von den 19 Vorhersagen, bei denen Ground Truth Tumor war, hat das Modell 18 richtig klassifiziert und 1 falsch klassifiziert.
- Von den 458 Vorhersagen, bei denen Ground Truth Nicht-Tumor war, hat das Modell 452 richtig klassifiziert und 6 falsch klassifiziert.
Die Wahrheitsmatrix für ein Klassifizierungsproblem mit mehreren Klassen kann Ihnen helfen, Fehlermuster zu identifizieren. Betrachten Sie beispielsweise die folgende Wahrheitsmatrix für ein 3-Klassen-Klassifizierungsmodell mit mehreren Klassen, das drei verschiedene Iris-Typen kategorisiert (Virginica, Versicolor und Setosa). Als Ground Truth Virginica war, zeigt die Wahrheitsmatrix, dass das Modell Versicolor mit größerer Wahrscheinlichkeit fälschlicherweise vorhergesagt hat als Setosa:
| Setosa (vorhergesagt) | Versicolor (vorhergesagt) | Virginica (vorhergesagt) | |
|---|---|---|---|
| Setosa (Ground Truth) | 88 | 12 | 0 |
| Versicolor (Ground Truth) | 6 | 141 | 7 |
| Virginica (Ground Truth) | 2 | 27 | 109 |
Als weiteres Beispiel könnte eine Wahrheitsmatrix zeigen, dass ein Modell, das für die Erkennung handschriftlicher Ziffern trainiert wurde, tendenziell fälschlicherweise 9 statt 4 oder fälschlicherweise 1 statt 7 vorhersagen.
Wahrheitsmatrixen enthalten genügend Informationen, um eine Vielzahl von Leistungsmesswerten wie Precision und Recall zu berechnen.
stetiges Feature
Ein Gleitkommawert mit einem unendlichen Bereich möglicher Werte, z. B. Temperatur oder Gewicht.
Kontrast mit der diskreten Funktion
Konvergenz
Ein Zustand, der erreicht wird, wenn sich die loss-Werte bei jeder Iteration nur sehr gering oder gar nicht ändern. Die folgende Verlustkurve deutet beispielsweise auf eine Konvergenz bei etwa 700 Iterationen hin:
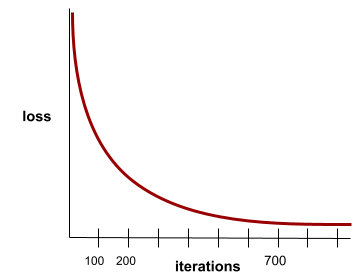
Ein Modell konvergiert, wenn es durch zusätzliches Training nicht verbessert wird.
Beim Deep Learning bleiben Verlustwerte manchmal während vieler Iterationen konstant oder annähernd so stark, bevor sie schließlich absteigen. Während eines langen Zeitraums konstanter Verlustwerte können Sie vorübergehend ein falsches Konvergenzgefühl bekommen.
Weitere Informationen finden Sie unter Frühzeitiges Beenden.
D
DataFrame
Ein beliebter Datentyp pandas zur Darstellung von Datasets im Arbeitsspeicher.
Ein DataFrame ist vergleichbar mit einer Tabelle oder einer Tabellenkalkulation. Jede Spalte eines DataFrames hat einen Namen (einen Header) und jede Zeile ist durch eine eindeutige Zahl gekennzeichnet.
Jede Spalte in einem DataFrame ist wie ein 2D-Array strukturiert, mit der Ausnahme, dass jeder Spalte ein eigener Datentyp zugewiesen werden kann.
Weitere Informationen finden Sie auf der offiziellen Referenzseite zu pandas.DataFrame.
Dataset oder Dataset
Eine Sammlung von Rohdaten, die üblicherweise (aber nicht ausschließlich) in einem der folgenden Formate organisiert werden:
- Tabelle
- Eine Datei im CSV-Format (comma-separated values, kommagetrennte Werte)
Deep Model
Ein neuronales Netzwerk mit mehr als einer verborgenen Ebene.
Ein tiefes Modell wird auch als neuronales Deep-Learning-Netzwerk bezeichnet.
Kontrast mit dem breiten Modell
vollbesetztes Feature
Ein Feature, bei dem die meisten oder alle Werte ungleich null sind, in der Regel ein Tensor von Gleitkommawerten. Der folgende Tensor mit 10 Elementen ist beispielsweise dicht, weil 9 seiner Werte ungleich null sind:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Kontrast mit dünnbesetztem Feature
Tiefe
Die Summe der folgenden Werte in einem neuronalen Netzwerk:
- die Anzahl der ausgeblendeten Ebenen
- die Anzahl der Ausgabeebenen (in der Regel 1)
- Anzahl der Einbettungsebenen
Ein neuronales Netzwerk mit fünf verborgenen Schichten und einer Ausgabeschicht hat beispielsweise eine Tiefe von 6.
Die Eingabeschicht hat keinen Einfluss auf die Tiefe.
diskretes Feature
Ein Feature mit einem endlichen Satz möglicher Werte. Beispielsweise ist ein Merkmal, dessen Werte nur Tier, Gemüse oder Mineral sein können, ein diskretes (oder kategoriales) Merkmal.
Kontrast mit der kontinuierlichen Funktion
dynamic
Etwas, das häufig oder fortlaufend ausgeführt wird. Die Begriffe dynamisch und online sind im maschinellen Lernen Synonyme. Im Folgenden werden gängige Anwendungsfälle von Dynamik und Online im maschinellen Lernen beschrieben:
- Ein dynamisches Modell (oder Online-Modell) ist ein Modell, das häufig oder kontinuierlich neu trainiert wird.
- Dynamisches Training (oder Onlinetraining) ist ein Prozess, bei dem häufig oder kontinuierlich trainiert wird.
- Dynamische Inferenz (oder Online-Inferenz) ist der Prozess, bei dem Vorhersagen bei Bedarf generiert werden.
dynamisches Modell
Ein model, das häufig (möglicherweise sogar kontinuierlich) neu trainiert wird. Ein dynamisches Modell ist ein „lebenslanger Lerner“, der sich kontinuierlich an sich ändernde Daten anpasst. Ein dynamisches Modell wird auch als Online-Modell bezeichnet.
Kontrast mit statischem Modell
E
vorzeitiges Beenden
Eine Methode für die Regularisierung, bei der das Training beendet wird, bevor der Trainingsverlust sinkt. Beim vorzeitigen Beenden beenden Sie absichtlich das Training des Modells, wenn der Verlust bei einem Validierungs-Dataset zunimmt, d. h. wenn sich die Leistung der Generalisierung verschlechtert.
Einbettungsebene
Eine spezielle verborgene Ebene, die mit einem hochdimensionalen kategorialen Feature trainiert, um schrittweise einen Einbettungsvektor mit niedrigerer Dimension zu lernen. Mit einer Einbettungsebene kann ein neuronales Netzwerk weitaus effizienter trainieren als nur das hochdimensionale kategoriale Merkmal zu trainieren.
Zum Beispiel unterstützt die Erde derzeit etwa 73.000 Baumarten. Angenommen, Baumarten sind ein Merkmal in Ihrem Modell. Daher umfasst die Eingabeebene Ihres Modells einen One-Hot-Vektor mit 73.000 Elementen.
So würde baobab unter Umständen in etwa so dargestellt werden:

Ein Array mit 73.000 Elementen ist sehr lang. Wenn Sie dem Modell keine Einbettungsebene hinzufügen, wird das Training aufgrund der Multiplikation von 72.999 Nullen sehr zeitaufwendig. Vielleicht wählen Sie die Einbettungsebene für 12 Dimensionen aus. Daher lernt die Einbettungsebene nach und nach einen neuen Einbettungsvektor für jede Baumart.
In bestimmten Situationen ist Hashing eine sinnvolle Alternative zu einer Einbettungsebene.
Epoche
Ein vollständiges Training umfasst den gesamten Trainingssatz, sodass jedes Beispiel einmal verarbeitet wurde.
Eine Epoche stellt die Trainings-Iterationen N/Batchgröße dar, wobei N die Gesamtzahl der Beispiele ist.
Nehmen wir beispielsweise Folgendes an:
- Das Dataset besteht aus 1.000 Beispielen.
- Die Batchgröße beträgt 50 Beispiele.
Daher sind für eine Epoche 20 Iterationen erforderlich:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Beispiel
Die Werte einer Zeile mit features und möglicherweise eines Labels. Beispiele beim überwachten Lernen lassen sich in zwei allgemeine Kategorien unterteilen:
- Ein Beispiel mit Label besteht aus einem oder mehreren Elementen und einem Label. Beispiele mit Labels werden während des Trainings verwendet.
- Ein Beispiel ohne Label besteht aus einem oder mehreren Elementen, aber ohne Label. Beispiele ohne Label werden während der Inferenz verwendet.
Angenommen, Sie trainieren ein Modell, um den Einfluss von Wetterbedingungen auf die Prüfungsergebnisse von Studenten zu ermitteln. Hier sind drei Beispiele mit Labels:
| Funktionen | Label | ||
|---|---|---|---|
| Temperatur | Luftfeuchtigkeit | Luftdruck | Prüfungspunktzahl |
| 15 | 47 | 998 | Gut |
| 19 | 34 | 1.020 | Großartig |
| 18 | 92 | 1012 | Schlecht |
Hier sind drei Beispiele ohne Labels:
| Temperatur | Luftfeuchtigkeit | Luftdruck | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Die Zeile eines Datasets ist in der Regel die Rohquelle für ein Beispiel. Das heißt, ein Beispiel besteht in der Regel aus einer Teilmenge der Spalten im Dataset. Darüber hinaus können die Features in einem Beispiel auch synthetische Features wie Feature Crosses enthalten.
F
Falsch-negativ (FN)
Ein Beispiel, in dem das Modell fälschlicherweise die negative Klasse vorhersagt. Das Modell sagt beispielsweise voraus, dass eine bestimmte E-Mail-Nachricht kein Spam (die negative Klasse), aber tatsächlich Spam ist.
falsch positives Ergebnis (FP)
Ein Beispiel, in dem das Modell fälschlicherweise die positive Klasse vorhersagt. Das Modell sagt beispielsweise voraus, dass eine bestimmte E-Mail-Nachricht Spam (die positive Klasse) ist, aber diese E-Mail-Nachricht tatsächlich kein Spam ist.
Rate falsch positiver Ergebnisse (FPR)
Der Anteil der tatsächlichen negativen Beispiele, für die das Modell versehentlich die positive Klasse vorhergesagt hat. Die folgende Formel berechnet die Falsch-Positiv-Rate:
Die Falsch-Positiv-Rate ist die x-Achse einer ROC-Kurve.
Feature
Eine Eingabevariable für ein Modell für maschinelles Lernen. Ein Beispiel besteht aus einem oder mehreren Features. Angenommen, Sie trainieren ein Modell, um den Einfluss von Wetterbedingungen auf die Prüfungsergebnisse von Studenten zu ermitteln. Die folgende Tabelle zeigt drei Beispiele, von denen jedes drei Elemente und ein Label enthält:
| Funktionen | Label | ||
|---|---|---|---|
| Temperatur | Luftfeuchtigkeit | Luftdruck | Prüfungspunktzahl |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1.020 | 84 |
| 18 | 92 | 1012 | 87 |
Stellen Sie einen Kontrast mit Label her.
Featureverknüpfung
Ein synthetisches Feature, das durch „Crossing“ von kategorialen oder Bucket-Features gebildet wird.
Nehmen wir als Beispiel ein Modell für Stimmungsprognosen, das die Temperatur in einem der folgenden vier Gruppen darstellt:
freezingchillytemperatewarm
Die Windgeschwindigkeit wird in einem der folgenden drei Gruppen dargestellt:
stilllightwindy
Ohne Feature-Crosses wird das lineare Modell unabhängig auf jedem der vorherigen sieben Buckets trainiert. Das Modell wird also beispielsweise unabhängig vom Training auf windy mit freezing trainiert.
Alternativ können Sie eine Feature-Kreuzung von Temperatur und Windgeschwindigkeit erstellen. Dieses synthetische Feature hätte die folgenden 12 möglichen Werte:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Dank Featureverknüpfungen kann das Modell Stimmungsunterschiede zwischen einem freezing-windy- und einem freezing-still-Tag lernen.
Wenn Sie ein synthetisches Merkmal aus zwei Merkmalen erstellen, die jeweils viele verschiedene Buckets haben, ergibt die resultierende Featureverknüpfung eine große Anzahl möglicher Kombinationen. Wenn ein Feature beispielsweise 1.000 Buckets und das andere 2.000 Buckets hat, umfasst die resultierende Featureverknüpfung 2.000.000 Buckets.
Formell ist ein Kreuz ein kartesisches Produkt.
Featureverknüpfungen werden meist mit linearen Modellen und selten mit neuronalen Netzwerken verwendet.
Feature Engineering
Ein Prozess, der die folgenden Schritte umfasst:
- Bestimmen, welche Features zum Trainieren eines Modells nützlich sein könnten.
- Konvertierung von Rohdaten aus dem Dataset in effiziente Versionen dieser Features.
So lässt sich beispielsweise festlegen, dass temperature ein nützliches Feature ist. Anschließend können Sie mit dem Bucketing experimentieren, um zu optimieren, was das Modell aus verschiedenen temperature-Bereichen lernen kann.
Feature Engineering wird manchmal als Feature-Extraktion oder Designisierung bezeichnet.
Feature-Set
Die Gruppe der Features, mit der Ihr Modell für maschinelles Lernen trainiert wird. Beispielsweise können Postleitzahl, Größe der Unterkunft und Zustand der Unterkunft einen einfachen Featuresatz für ein Modell umfassen, das Immobilienpreise vorhersagt.
Featurevektor
Das Array der feature-Werte, das ein Beispiel umfasst. Der Featurevektor wird während des Trainings und während der Inferenz eingegeben. Der Featurevektor für ein Modell mit zwei diskreten Features könnte beispielsweise so aussehen:
[0.92, 0.56]
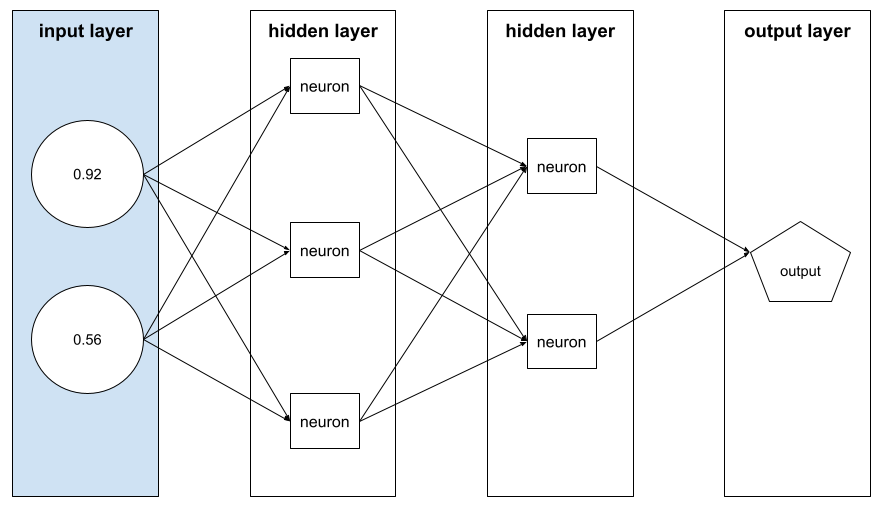
Jedes Beispiel stellt unterschiedliche Werte für den Featurevektor bereit, sodass der Featurevektor für das nächste Beispiel in etwa so aussehen könnte:
[0.73, 0.49]
Feature Engineering bestimmt, wie Features im Featurevektor dargestellt werden. Beispielsweise kann ein binäres kategoriales Feature mit fünf möglichen Werten mit One-Hot-Codierung dargestellt werden. In diesem Fall würde der Teil des Featurevektors für ein bestimmtes Beispiel aus vier Nullen und einer einzelnen 1,0 an der dritten Position bestehen:
[0.0, 0.0, 1.0, 0.0, 0.0]
Nehmen wir als weiteres Beispiel an, Ihr Modell besteht aus drei Merkmalen:
- ein binäres kategoriales Feature mit fünf möglichen Werten, die mit One-Hot-Codierung dargestellt werden. Beispiel:
[0.0, 1.0, 0.0, 0.0, 0.0] - ein weiteres binäres kategoriales Feature mit drei möglichen Werten, die mit One-Hot-Codierung dargestellt werden. Beispiel:
[0.0, 0.0, 1.0] - Ein Gleitkommazahl-Feature, z. B.
8.3.
In diesem Fall würde der Featurevektor für jedes Beispiel durch neun Werte dargestellt werden. Anhand der Beispielwerte in der vorherigen Liste würde der Featurevektor so aussehen:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Feedback-Schleife
Beim maschinellen Lernen eine Situation, in der die Vorhersagen eines Modells die Trainingsdaten für dasselbe oder ein anderes Modell beeinflussen. Ein Modell, das Filme empfiehlt, wirkt sich beispielsweise auf die Filme aus, die die Nutzer sehen. Dies wirkt sich dann auf nachfolgende Filmempfehlungsmodelle aus.
G
Generalisierung
Fähigkeit eines Modells, korrekte Vorhersagen für neue, zuvor unbekannte Daten zu treffen. Ein Modell, das generalisieren kann, ist das Gegenteil eines Modells mit Überanpassung.
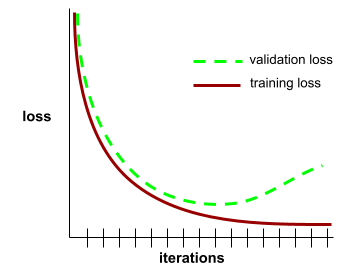
Generalisierungskurve
Diagramm des Trainingsverlusts und des Validierungsverlusts als Funktion der Anzahl der Iterationen
Mit einer Generalisierungskurve können Sie eine mögliche Überanpassung erkennen. Die folgende Generalisierungskurve deutet beispielsweise auf eine Überanpassung hin, da der Validierungsverlust letztendlich deutlich höher wird als der Trainingsverlust.
Gradientenabstieg
Eine mathematische Technik zur Minimierung von Verlust. Beim Gradientenabstieg werden Gewichtungen und Voreingenommenheiten schrittweise angepasst, um schrittweise die beste Kombination zu finden, um den Verlust zu minimieren.
Das Gradientenverfahren ist älter – also viel, viel älter – als maschinelles Lernen.
Ground Truth
Realität.
Was tatsächlich passiert ist.
Stellen Sie sich beispielsweise ein binäres Klassifizierungsmodell vor, das vorhersagt, ob ein Studierende im ersten Universitätsjahr den Abschluss innerhalb von sechs Jahren abschließen wird. Die Ground-Truth-Frage für dieses Modell ist, ob der Student den Abschluss tatsächlich innerhalb von sechs Jahren gemacht hat.
H
versteckte Schicht
Eine Schicht in einem neuronalen Netzwerk zwischen der Eingabeebene (den Features) und der Ausgabeebene (die Vorhersage). Jede verborgene Schicht besteht aus einem oder mehreren Neuronen. Das folgende neuronale Netzwerk enthält beispielsweise zwei versteckte Schichten, die erste mit drei Neuronen und die zweite mit zwei Neuronen:

Ein neuronales Deep-Learning-Netzwerk enthält mehr als eine verborgene Ebene. Die vorherige Abbildung ist beispielsweise ein neuronales Deep-Learning-Netzwerk, da das Modell zwei versteckte Ebenen enthält.
Hyperparameter
Die Variablen, die von Ihnen oder einem Hyperparameter-Abstimmungsdienstwährend aufeinanderfolgender Trainingsläufe eines Modells angepasst werden. Beispielsweise ist die Lernrate ein Hyperparameter. Sie können die Lernrate vor einer Trainingseinheit auf 0,01 setzen. Wenn Sie feststellen, dass 0,01 zu hoch ist, können Sie die Lernrate für die nächste Trainingssitzung auf 0,003 setzen.
Im Gegensatz dazu sind Parameter die verschiedenen Gewichtungen und Verzerrungen, die das Modell während des Trainings lernt.
I
unabhängig und identisch verteilt (i.i.d)
Daten, die aus einer Verteilung stammen, die sich nicht ändert, und bei der jeder gezeichnete Wert nicht von zuvor gezeichneten Werten abhängt. Ein I. D. ist das ideale Gas des maschinellen Lernens – ein nützliches mathematisches Konstrukt, das in der realen Welt jedoch fast nie genau zu finden ist. Die Verteilung der Besucher einer Webseite kann beispielsweise über ein kurzes Zeitfenster hinweg erfolgen, d. h., die Verteilung ändert sich während dieses kurzen Zeitraums nicht und der Besuch einer Person ist im Allgemeinen unabhängig vom Besuch einer anderen Person. Verlängern Sie dieses Zeitfenster jedoch, können saisonale Unterschiede bei den Besuchern der Webseite auftreten.
Weitere Informationen finden Sie unter Nichtstationarität.
Inferenz
Beim maschinellen Lernen der Prozess des Treffens von Vorhersagen, indem ein trainiertes Modell auf Beispiele ohne Label angewendet wird.
Die Inferenz hat in der Statistik eine andere Bedeutung. Weitere Informationen finden Sie im Wikipedia-Artikel zur statistischen Inferenz.
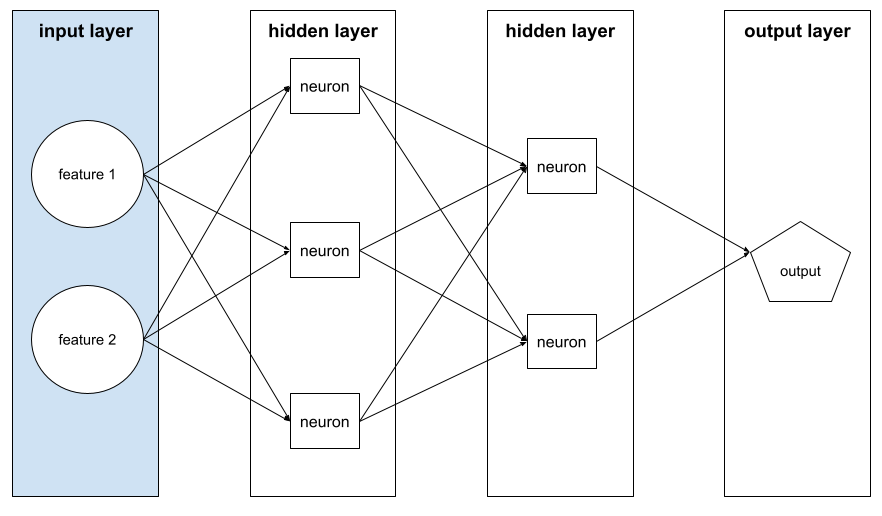
Eingabeschicht
Die Ebene eines neuronalen Netzwerks, das den Featurevektor enthält. Das heißt, die Eingabeschicht enthält Beispiele für Training oder Inferenz. Beispielsweise besteht die Eingabeschicht im folgenden neuronalen Netzwerk aus zwei Merkmalen:
Interpretierbarkeit
Die Fähigkeit, die Begründung eines ML-Modells einem Menschen verständlich zu erklären oder zu präsentieren.
Die meisten linearen Regressionsmodelle beispielsweise sind hochgradig interpretierbar. Sie müssen sich nur die trainierten Gewichtungen für jedes Feature ansehen. Außerdem lassen sich Entscheidungsbereiche sehr gut interpretieren. Einige Modelle erfordern jedoch eine ausgefeilte Visualisierung, um interpretierbar zu werden.
Zum Interpretieren von ML-Modellen können Sie das Learning Interpretability Tool (LIT) verwenden.
Iteration
Eine einzelne Aktualisierung der Modellparameter – der Gewichtungen und Verzerrungen des Modells während des Trainings. Die Batchgröße bestimmt, wie viele Beispiele das Modell in einer einzelnen Iteration verarbeitet. Wenn die Batchgröße beispielsweise 20 beträgt, verarbeitet das Modell 20 Beispiele, bevor die Parameter angepasst werden.
Beim Trainieren eines neuronalen Netzes umfasst ein einzelner Durchlauf die folgenden zwei Durchgänge:
- Ein Vorwärtsdurchlauf zur Bewertung des Verlusts bei einem einzelnen Batch.
- Einen Rückwärtstermin (Rückpropagierung), um die Parameter des Modells auf der Grundlage des Verlusts und der Lernrate anzupassen.
L
L0-Regularisierung
Eine Art der Regularisierung, die die Gesamtzahl der Gewichtungen ungleich null in einem Modell bestraft. Beispiel: Ein Modell mit 11 Gewichtungen ungleich null wird stärker bestraft als ein ähnliches Modell mit zehn Gewichtungen ungleich null.
Die L0-Regularisierung wird manchmal als L0-Norm-Regularisierung bezeichnet.
L1-Verlust
Eine Verlustfunktion, die den absoluten Wert der Differenz zwischen tatsächlichen label-Werten und den von einem Modell vorhergesagten Werten berechnet. Hier sehen Sie beispielsweise die Berechnung des L1-Verlusts für einen Batch mit fünf Beispielen:
| Tatsächlicher Wert des Beispiels | Vorhersagewert des Modells | Absoluter Wert der Differenz |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = Verlust von L1 | ||
Der L1-Verlust ist weniger empfindlich auf Ausreißer als L2-Verlust.
Der mittlere absolute Fehler ist der durchschnittliche L1-Verlust pro Beispiel.
L1-Regularisierung
Art der Regularisierung, bei der Gewichtungen proportional zur Summe des absoluten Werts der Gewichtungen bestraft werden. Mit der L1-Regularisierung kann die Gewichtung irrelevanter oder kaum relevanter Features auf genau 0 gesenkt werden. Ein Feature mit der Gewichtung 0 wird effektiv aus dem Modell entfernt.
Stellen Sie einen Kontrast mit der L2-Regularisierung her.
L2-Verlust
Eine Verlustfunktion, die das Quadrat der Differenz zwischen tatsächlichen label-Werten und den von einem Modell vorhergesagten Werten berechnet. Hier sehen Sie beispielsweise die Berechnung des L2-Verlusts für einen Batch aus fünf Beispielen:
| Tatsächlicher Wert des Beispiels | Vorhersagewert des Modells | Quadrat des Deltas |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2-Verlust | ||
Durch die Quadratformatierung verstärkt der L2-Verlust den Einfluss von Ausreißern. Das heißt, der L2-Verlust reagiert stärker auf schlechte Vorhersagen als der L1-Verlust. Der L1-Verlust für den vorherigen Batch wäre beispielsweise 8 statt 16. Beachten Sie, dass ein einzelner Ausreißer 9 von 16 Ausreißer darstellt.
Regressionsmodelle verwenden in der Regel den L2-Verlust als Verlustfunktion.
Der mittlere quadratische Fehler ist der durchschnittliche L2-Verlust pro Beispiel. Quadratischer Verlust ist eine andere Bezeichnung für L2-Verlust.
L2-Regularisierung
Art der Regularisierung, bei der Gewichtungen proportional zur Summe der Quadrate der Gewichtungen bestraft werden. Die L2-Regularisierung hilft dabei, Ausreißer-Gewichtungen (mit hohen positiven oder niedrigen negativen Werten) näher an 0, aber nicht ganz an 0 zu bewegen. Features mit Werten, die sehr nahe bei 0 liegen, verbleiben im Modell, haben aber keinen großen Einfluss auf die Vorhersage des Modells.
Die L2-Regularisierung verbessert immer die Generalisierung in linearen Modellen.
Stellen Sie einen Kontrast mit der L1-Regularisierung her.
Label
Beim überwachten maschinellen Lernen der „Antwort“- oder „Ergebnis“-Teil eines Beispiels.
Jedes Beispiel mit Label besteht aus einem oder mehreren Features und einem Label. In einem Dataset zur Spamerkennung würde das Label beispielsweise entweder „Spam“ oder „Kein Spam“ lauten. In einem Niederschlags-Dataset kann das Label die Regenmenge sein, die in einem bestimmten Zeitraum fiel.
Beispiel für ein Label
Ein Beispiel, das ein oder mehrere Features und ein Label enthält. Die folgende Tabelle enthält beispielsweise drei Beispiele mit Labels aus einem Hausbewertungsmodell mit jeweils drei Merkmalen und einem Label:
| Anzahl der Schlafzimmer | Anzahl der Badezimmer | Hausalter | Hauspreis (Label) |
|---|---|---|---|
| 3 | 2 | 15 | 345.000 $ |
| 2 | 1 | 72 | 179.000 $ |
| 4 | 2 | 34 | 392.000 $ |
Beim überwachten maschinellen Lernen werden Modelle anhand von Beispielen mit Labels trainiert und Vorhersagen für Beispiele ohne Label treffen.
Beispiel mit einem Label ohne Label und Beispiel ohne Label.
Lambda
Synonym für Regularisierungsrate.
Lambda ist ein überladener Begriff. Hier liegt der Fokus auf der Definition des Begriffs innerhalb der Regularisierung.
Layer
Eine Reihe von Neuronen in einem neuronalen Netz. Es gibt drei gängige Ebenentypen:
- Die Eingabeebene, die Werte für alle Features bereitstellt.
- Eine oder mehrere ausgeblendete Ebenen, die nicht lineare Beziehungen zwischen den Elementen und dem Label finden.
- Die Ausgabeschicht, die die Vorhersage bereitstellt.
Die folgende Abbildung zeigt beispielsweise ein neuronales Netzwerk mit einer Eingabeschicht, zwei verborgenen Ebenen und einer Ausgabeschicht:
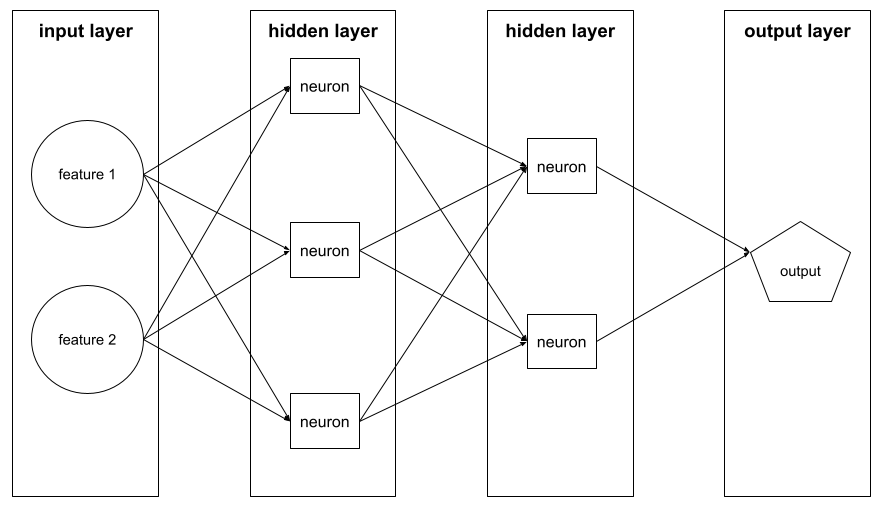
In TensorFlow sind Ebenen auch Python-Funktionen, die Tensoren und Konfigurationsoptionen als Eingabe nehmen und andere Tensoren als Ausgabe erzeugen.
Lernrate
Eine Gleitkommazahl, die dem Algorithmus für den Gradientenabstieg angibt, wie stark die Gewichtung und Verzerrungen bei jeder Iteration angepasst werden sollen. Bei einer Lernrate von 0,3 werden Gewichtungen und Verzerrungen beispielsweise dreimal stärker angepasst als bei einer Lernrate von 0,1.
Die Lernrate ist ein wichtiger Hyperparameter. Wenn Sie die Lernrate zu niedrig einstellen, dauert das Training zu lange. Wenn Sie die Lernrate zu hoch ansetzen, hat der Gradientenabstieg oft Schwierigkeiten, die Konvergenz zu erreichen.
Linear
Beziehung zwischen zwei oder mehr Variablen, die ausschließlich durch Addition und Multiplikation dargestellt werden kann.
In der Darstellung einer linearen Beziehung wird eine Linie dargestellt.
Stellen Sie einen Kontrast mit nicht linear her.
lineares Modell
Ein model, das eine model pro model zuweist, um model zu treffen. Lineare Modelle beinhalten auch eine Verzerrung. Im Gegensatz dazu ist das Verhältnis von Merkmalen zu Vorhersagen in tiefen Modellen in der Regel nicht linear.
Lineare Modelle sind in der Regel einfacher zu trainieren und interpretierbar als tiefe Modelle. Tiefe Modelle können jedoch komplexe Beziehungen zwischen Merkmalen erlernen.
Die lineare Regression und die logistische Regression sind zwei Arten von linearen Modellen.
lineare Regression
Ein Modell für maschinelles Lernen, bei dem die beiden folgenden Bedingungen zutreffen:
- Das Modell ist ein lineares Modell.
- Die Vorhersage ist ein Gleitkommawert. (Dies ist der Regressionsteil der linearen Regression.)
Stellen Sie der linearen Regression einen Vergleich mit der logistischen Regression gegenüber. Stellen Sie der Regression außerdem einen Unterschied zur Klassifizierung.
logistische Regression
Art von Regressionsmodell, das eine Wahrscheinlichkeit vorhersagt. Logistische Regressionsmodelle haben die folgenden Merkmale:
- Das Label ist kategorial. Der Begriff logistische Regression bezieht sich in der Regel auf binäre logistische Regression, d. h. auf ein Modell, das Wahrscheinlichkeiten für Labels mit zwei möglichen Werten berechnet. Mit einer weniger gängigen Variante, der multinomialen logistischen Regression, werden Wahrscheinlichkeiten für Labels mit mehr als zwei möglichen Werten berechnet.
- Die Verlustfunktion während des Trainings ist Logverlust. Mehrere Logverlusteinheiten können für Labels mit mehr als zwei möglichen Werten parallel platziert werden.
- Das Modell hat eine lineare Architektur, kein neuronales Deep-Learning-Netzwerk. Der Rest dieser Definition gilt jedoch auch für tiefe Modelle, die Wahrscheinlichkeiten für kategoriale Labels vorhersagen.
Nehmen wir als Beispiel ein logistisches Regressionsmodell, das die Wahrscheinlichkeit berechnet, dass eine eingegebene E-Mail Spam oder kein Spam ist. Angenommen, das Modell sagt während der Inferenz 0,72 voraus. Daher schätzt das Modell:
- Eine 72-prozentige Wahrscheinlichkeit, dass die E-Mail Spam ist.
- Eine 28-prozentige Wahrscheinlichkeit, dass die E-Mail kein Spam ist.
Ein logistisches Regressionsmodell verwendet die folgende zweistufige Architektur:
- Das Modell generiert eine Rohvorhersage (y') durch Anwenden einer linearen Funktion von Eingabemerkmalen.
- Das Modell verwendet diese Rohvorhersage als Eingabe in eine Sigmoidfunktion, die die Rohvorhersage in einen Wert zwischen 0 und 1 (ausschließlich) umwandelt.
Wie jedes Regressionsmodell sagt auch ein logistisches Regressionsmodell eine Zahl voraus. Diese Zahl wird jedoch in der Regel so Teil eines binären Klassifizierungsmodells:
- Wenn die vorhergesagte Zahl größer ist als der Klassifizierungsschwellenwert, sagt das binäre Klassifizierungsmodell die positive Klasse vorher.
- Wenn die vorhergesagte Zahl kleiner als der Klassifizierungsschwellenwert ist, sagt das binäre Klassifizierungsmodell die negative Klasse vorher.
Logarithmischer Verlust
Die Verlustfunktion, die in der binären logistischen Regression verwendet wird.
Log-Wahrscheinlichkeiten
Logarithmus der Chancen eines Ereignisses
Niederlage
Während des Trainings eines überwachten Modells wird gemessen, wie weit die Vorhersage eines Modells von seinem Label entfernt ist.
Eine Verlustfunktion berechnet den Verlust.
Verlustkurve
Ein Diagramm des Verlusts als Funktion der Anzahl der Trainingsdurchläufe. Das folgende Diagramm zeigt eine typische Verlustkurve:
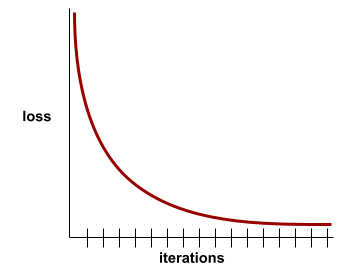
Verlustkurven können Ihnen dabei helfen zu bestimmen, wann Ihr Modell konvergent oder Überanpassung ist.
Verlustkurven können die folgenden Verlusttypen darstellen:
Siehe auch Generalisierungskurve.
Verlustfunktion
Während des Trainings oder des Tests eine mathematische Funktion, die den Verlust für einen Batch von Beispielen berechnet. Eine Verlustfunktion gibt einen geringeren Verlust für Modelle zurück, die gute Vorhersagen machen, als für Modelle, die schlechte Vorhersagen treffen.
Das Ziel des Trainings besteht in der Regel darin, den Verlust zu minimieren, den eine Verlustfunktion zurückgibt.
Es gibt viele verschiedene Arten von Verlustfunktionen. Wählen Sie die entsprechende Verlustfunktion für die Art des Modells aus, das Sie erstellen. Beispiel:
- L2-Verlust (oder mittlerer quadratischer Fehler) ist die Verlustfunktion bei der linearen Regression.
- Logverlust ist die Verlustfunktion für die logistische Regression.
M
Machine Learning
Ein Programm oder System, das ein Modell anhand von Eingabedaten trainiert. Das trainierte Modell kann nützliche Vorhersagen aus neuen (noch nie gesehenen) Daten treffen, die aus der gleichen Verteilung stammen, die auch zum Trainieren des Modells verwendet wird.
Maschinelles Lernen bezieht sich auch auf die Studienbereiche dieser Programme oder Systeme.
Mehrheitsklasse
Gängigeres Label in einem Dataset mit unausgeglichener Klasse. Bei einem Dataset, das beispielsweise 99% negative Labels und 1% positive Labels enthält, sind die negativen Labels die Mehrheitsklasse.
Stellen Sie einen Kontrast zur Minderheitsklasse her.
Minibatch
Eine kleine, zufällig ausgewählte Teilmenge eines Batches, das in einer Iteration verarbeitet wird. Die Batchgröße eines Mini-Batch liegt in der Regel zwischen 10 und 1.000 Beispielen.
Angenommen, der gesamte Trainingssatz (der vollständige Batch) besteht aus 1.000 Beispielen. Angenommen, Sie legen die Batchgröße jedes Minibatches auf 20 fest. Daher bestimmt jede Iteration den Verlust an zufälligen 20 der 1.000 Beispiele und passt dann die Gewichtungen und Verzerrungen entsprechend an.
Es ist viel effizienter, den Verlust eines Mini-Batch zu berechnen, als der Verlust bei allen Beispielen im vollständigen Batch.
Minderheitenklasse
Das weniger verbreitete Label in einem Dataset mit unausgeglichener Klasse. Wenn beispielsweise ein Dataset zu 99% negative Labels und zu 1% positive Labels enthält, sind die positiven Labels die Minderheitenklasse.
Im Kontrast zur Mehrheitsklasse
model
Im Allgemeinen jedes mathematische Konstrukt, das Eingabedaten verarbeitet und eine Ausgabe zurückgibt. Anders ausgedrückt: Ein Modell ist der Satz von Parametern und der Struktur, die ein System benötigt, um Vorhersagen zu treffen. Beim überwachten maschinellen Lernen nimmt ein Modell ein Beispiel als Eingabe und leitet eine Vorhersage als Ausgabe ab. Beim überwachten maschinellen Lernen unterscheiden sich die Modelle etwas. Beispiel:
- Ein lineares Regressionsmodell besteht aus einer Reihe von Gewichtungen und einer Verzerrung.
- Ein neuronales Netzwerkmodell besteht aus:
- Eine Reihe von ausgeblendeten Ebenen, die jeweils ein oder mehrere Neuronen enthalten.
- Gewichtungen und Verzerrungen, die mit jedem Neuron verbunden sind.
- Ein Entscheidungsbaum-Modell besteht aus:
- Die Form des Baums, d. h. das Muster, in dem die Bedingungen und Blätter miteinander verbunden sind.
- Die Bedingungen und Blätter.
Sie können ein Modell speichern, wiederherstellen oder kopieren.
Auch durch unüberwachtes maschinelles Lernen werden Modelle generiert. Dies ist in der Regel eine Funktion, mit der ein Eingabebeispiel dem am besten geeigneten Cluster zugeordnet werden kann.
Klassifizierung mit mehreren Klassen
Beim überwachten Lernen ein Klassifizierungsproblem, bei dem das Dataset mehr als zwei Klassen mit Labels enthält. Die Labels im Iris-Dataset müssen beispielsweise eine der folgenden drei Klassen sein:
- Iris Setosa
- Iris Virginica
- Iris Versicolor
Ein mit dem Iris-Dataset trainiertes Modell, das den Iris-Typ in neuen Beispielen vorhersagt, führt eine Klassifizierung mit mehreren Klassen durch.
Im Gegensatz dazu sind Klassifizierungsprobleme, die zwischen genau zwei Klassen unterscheiden, binäre Klassifizierungsmodelle. Beispielsweise ist ein E-Mail-Modell, das entweder Spam oder Kein Spam vorhersagt, ein binäres Klassifizierungsmodell.
Bei Clustering-Problemen bezieht sich die Klassifizierung mit mehreren Klassen auf mehr als zwei Cluster.
N
auszuschließende Klasse
Bei der binären Klassifizierung wird eine Klasse als positiv und die andere als negativ bezeichnet. Die positive Klasse ist das Objekt oder Ereignis, auf das bzw. das das Modell testet, und die negative Klasse ist die andere Möglichkeit. Beispiel:
- Die negative Klasse bei einem medizinischen Test könnte „kein Tumor“ sein.
- Die negative Klasse in einem E-Mail-Klassifikator ist möglicherweise „kein Spam“.
Im Kontrast zur positiven Klasse stehen.
neuronales Netzwerk
Ein model, das mindestens eine model enthält. Ein neuronales Deep-Learning-Netzwerk ist eine Art von neuronalem Netzwerk mit mehr als einer versteckten Schicht. Das folgende Diagramm zeigt beispielsweise ein neuronales Deep-Learning-Netzwerk mit zwei verborgenen Schichten.
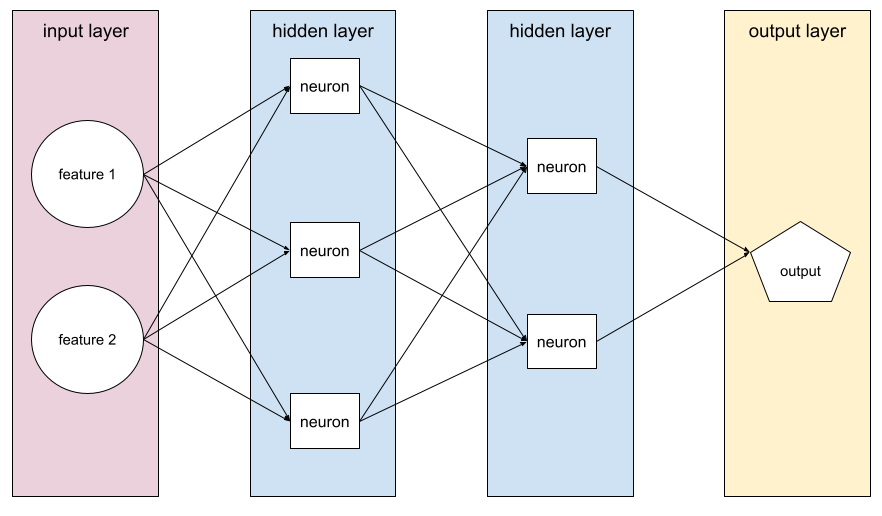
Jedes Neuron in einem neuronalen Netzwerk ist mit allen Knoten der nächsten Schicht verbunden. Im obigen Diagramm sehen Sie beispielsweise, dass jedes der drei Neuronen der ersten versteckten Schicht separat mit beiden Neuronen der zweiten versteckten Schicht verbunden ist.
Neuronale Netzwerke, die auf Computern implementiert sind, werden manchmal als künstliche neuronale Netzwerke bezeichnet, um sie von neuronalen Netzwerken in Gehirnen und anderen Nervensystemen zu unterscheiden.
Einige neuronale Netzwerke können extrem komplexe nicht lineare Beziehungen zwischen verschiedenen Merkmalen und dem Label imitieren.
Weitere Informationen finden Sie unter Convolutional Neural Network und Recurrent Neural Network.
Neuron
Beim maschinellen Lernen eine einzelne Einheit innerhalb einer verborgenen Schicht eines neuronalen Netzwerks. Jedes Neuron führt die folgende zweistufige Aktion aus:
- Berechnet die gewichtete Summe von Eingabewerten multipliziert mit ihren entsprechenden Gewichtungen.
- Übergibt die gewichtete Summe als Eingabe an eine Aktivierungsfunktion.
Ein Neuron auf der ersten verborgenen Ebene akzeptiert Eingaben von den Featurewerten der Eingabeschicht. Ein Neuron, das sich auf einer versteckten Schicht jenseits der ersten Schicht befindet, akzeptiert Eingaben von den Neuronen in der vorherigen verborgenen Schicht. Beispielsweise akzeptiert ein Neuron der zweiten verborgenen Schicht Eingaben von den Neuronen der ersten verborgenen Schicht.
In der folgenden Abbildung werden zwei Neuronen und ihre Eingaben gezeigt.
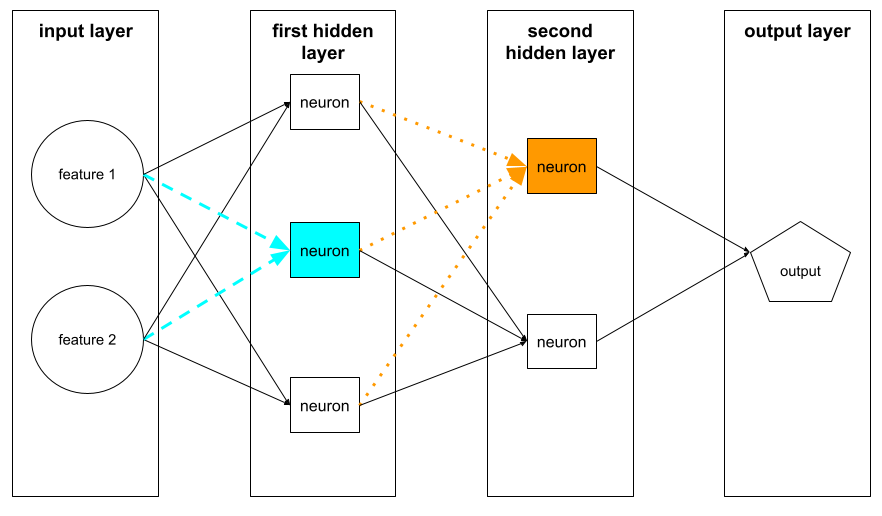
Ein Neuron in einem neuronalen Netzwerk ahmt das Verhalten von Neuronen im Gehirn und anderen Teilen von Nervensystemen nach.
Knoten (neuronales Netzwerk)
Ein Neuron in einer verborgenen Ebene.
nicht linear
Beziehung zwischen zwei oder mehr Variablen, die nicht ausschließlich durch Addition und Multiplikation dargestellt werden können. Eine lineare Beziehung kann als Linie dargestellt werden, eine nicht lineare Beziehung nicht als Linie. Betrachten Sie zum Beispiel zwei Modelle, die jeweils ein einzelnes Feature mit einem einzelnen Label verknüpfen. Das Modell auf der linken Seite ist linear und das Modell auf der rechten Seite nicht linear:

Nichtstationarität
Ein Element, dessen Werte sich in einer oder mehreren Dimensionen ändern, in der Regel zeitweise. Betrachten Sie zum Beispiel die folgenden Beispiele für Nichtstationarität:
- Die Anzahl der in einem bestimmten Geschäft verkauften Badebekleidung variiert je nach Saison.
- Die Menge einer bestimmten Frucht, die in einer bestimmten Region geerntet wird, ist für einen Großteil des Jahres bei null, für einen kurzen Zeitraum aber sehr groß.
- Aufgrund des Klimawandels ändern sich die Durchschnittstemperaturen im Jahr.
Stellen Sie einen Kontrast zu Stationarität her.
Normalisierung
Ganz allgemein gesagt, der Prozess der Umwandlung des tatsächlichen Wertebereichs einer Variablen in einen Standardbereich von Werten, z. B.:
- -1 bis +1
- 0 bis 1
- die Normalverteilung
Angenommen, der tatsächliche Wertebereich eines bestimmten Elements liegt zwischen 800 und 2.400. Im Rahmen von Feature Engineering können Sie die tatsächlichen Werte auf einen Standardbereich wie -1 bis +1 normalisieren.
Normalisierung ist eine gängige Aufgabe im Feature Engineering. Modelle werden normalerweise schneller trainiert (und liefern bessere Vorhersagen), wenn jedes numerische Feature im Featurevektor ungefähr den gleichen Bereich hat.
numerische Daten
Elemente, die als Ganzzahlen oder reellwertige Zahlen dargestellt werden. Beispielsweise würde ein Hausbewertungsmodell die Größe eines Hauses (in Quadratfuß oder Quadratmetern) wahrscheinlich als numerische Daten darstellen. Wenn ein Element als numerische Daten dargestellt wird, bedeutet dies, dass die Werte des Elements eine mathematische Beziehung zum Label haben. Das heißt, die Anzahl der Quadratmeter in einem Haus steht wahrscheinlich in einem mathematischen Verhältnis zum Wert des Hauses.
Nicht alle Ganzzahldaten sollten als numerische Daten dargestellt werden. Beispielsweise sind Postleitzahlen in einigen Teilen der Welt Ganzzahlen. Ganzzahlige Postleitzahlen sollten in Modellen nicht als numerische Daten dargestellt werden. Das liegt daran, dass die Postleitzahl 20000 nicht doppelt (oder halb) so stark wie die Postleitzahl 10000 ist. Obwohl verschiedene Postleitzahlen mit unterschiedlichen Immobilienwerten korrelieren, können wir nicht davon ausgehen, dass Immobilienwerte bei der Postleitzahl 20000 doppelt so wertvoll sind wie Immobilienwerte unter der Postleitzahl 10000.
Postleitzahlen sollten stattdessen als kategoriale Daten dargestellt werden.
Numerische Features werden manchmal als kontinuierliche Features bezeichnet.
O
Offlinegerät
Synonym für statisch.
Offline-Inferenz
Prozess eines Modells, bei dem ein Batch von Vorhersagen generiert und diese Vorhersagen dann im Cache gespeichert (gespeichert) werden. Anwendungen können dann auf die abgeleitete Vorhersage aus dem Cache zugreifen, anstatt das Modell noch einmal auszuführen.
Stellen Sie sich beispielsweise ein Modell vor, das alle vier Stunden lokale Wettervorhersagen (Vorhersagen) generiert. Nach jeder Modellausführung speichert das System alle lokalen Wettervorhersagen im Cache. Wetter-Apps rufen die Vorhersagen aus dem Cache ab.
Offlineinferenz wird auch als statische Inferenz bezeichnet.
Es steht ein Kontrast mit der Online-Inferenz zur Verfügung.
One-Hot-Codierung
Kategoriale Daten als Vektor darstellen, in dem:
- Ein Element ist auf „1“ festgelegt.
- Für alle anderen Elemente ist der Wert „0“ festgelegt.
Die One-Hot-Codierung wird im Allgemeinen zur Darstellung von Strings oder Kennungen verwendet, die einen begrenzten Satz möglicher Werte haben.
Angenommen, ein bestimmtes kategoriales Feature namens Scandinavia hat fünf mögliche Werte:
- "Dänemark"
- „Schweden“
- „Norwegen“
- „Finnland“
- „Island“
Die One-Hot-Codierung könnte jeden der fünf Werte so darstellen:
| country | Vektor | ||||
|---|---|---|---|---|---|
| "Dänemark" | 1 | 0 | 0 | 0 | 0 |
| „Schweden“ | 0 | 1 | 0 | 0 | 0 |
| „Norwegen“ | 0 | 0 | 1 | 0 | 0 |
| „Finnland“ | 0 | 0 | 0 | 1 | 0 |
| „Island“ | 0 | 0 | 0 | 0 | 1 |
Dank der One-Hot-Codierung kann ein Modell basierend auf jedem der fünf Länder unterschiedliche Verbindungen lernen.
Eine Alternative zur One-Hot-Codierung ist die Darstellung eines Elements als numerische Daten. Leider ist es keine gute Wahl, die skandinavischen Länder numerisch abzubilden. Betrachten Sie beispielsweise die folgende numerische Darstellung:
- „Dänemark“ ist 0
- „Schweden“ hat den Wert 1
- „Norwegen“ hat den Wert 2
- „Finnland“ hat den Wert 3
- „Island“ wird 4
Bei der numerischen Codierung würde ein Modell die Rohzahlen mathematisch interpretieren und versuchen, mit diesen Zahlen zu trainieren. Island ist jedoch nicht doppelt (oder halb so viel) wie Norwegen. Das Modell würde daher seltsame Schlussfolgerungen ziehen.
Einzel gegen alle
Bei einem Klassifizierungsproblem mit N Klassen eine Lösung, die aus N separaten binären Klassifikatoren besteht – einem binären Klassifikator für jedes mögliche Ergebnis. Bei einem Modell, das Beispiele als Tier, Gemüse oder Mineral klassifiziert, würde eine 1-gegen-all-Lösung beispielsweise die folgenden drei separaten binären Klassifikatoren bereitstellen:
- Tier oder kein Tier
- Gemüse oder nicht pflanzlich
- Mineralien und nicht Mineralien
online
Synonym für dynamisch.
Online-Inferenz
Vorhersagen werden bei Bedarf generiert. Angenommen, eine Anwendung übergibt eine Eingabe an ein Modell und stellt eine Anfrage für eine Vorhersage aus. Ein System, das Onlineinferenz verwendet, antwortet auf die Anfrage, indem es das Modell ausführt (und die Vorhersage an die Anwendung zurückgibt).
Stellen Sie einen Kontrast zur Offline-Inferenz her.
Ausgabeschicht
Die „letzte“ Schicht eines neuronalen Netzwerks. Die Ausgabeebene enthält die Vorhersage.
Die folgende Abbildung zeigt ein kleines neuronales Deep-Learning-Netzwerk mit einer Eingabeschicht, zwei verborgenen Schichten und einer Ausgabeschicht:
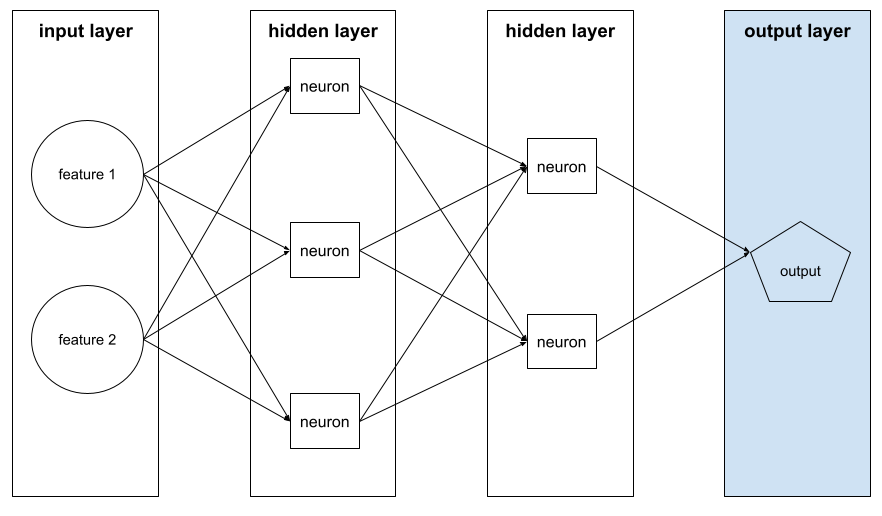
Überanpassung
Erstellen eines model, das den model so ähnlich ist, dass das Modell keine korrekten Vorhersagen für neue Daten trifft.
Regularisierung kann eine Überanpassung reduzieren. Das Training mit einem großen und vielfältigen Trainings-Dataset kann auch Überanpassung reduzieren.
P
pandas
Eine spaltenorientierte Datenanalyse-API, die auf numpy basiert. Viele Frameworks für maschinelles Lernen, einschließlich TensorFlow, unterstützen Pandas-Datenstrukturen als Eingaben. Weitere Informationen finden Sie in der pandas-Dokumentation.
Parameter
Die Gewichtungen und Verzerrungen, die ein Modell während des Trainings erlernt. In einem linearen Regressionsmodell bestehen die Parameter beispielsweise aus der Verzerrung (b) und allen Gewichtungen (w1, w2 usw.) in der folgenden Formel:
Im Gegensatz dazu sind Hyperparameter die Werte, die Sie (oder ein Hyperparameter-Drehdienst) für das Modell bereitstellen. Beispielsweise ist die Lernrate ein Hyperparameter.
positive Klasse
Der Kurs, für den Sie den Test durchführen.
Die positive Klasse in einem Krebsmodell könnte beispielsweise „Tumor“ sein. Die positive Klasse in einem E-Mail-Klassifikator kann „Spam“ sein.
Stellen Sie einen Kontrast mit der negativen Klasse dar.
Nachbearbeitung
Ausgabe eines Modells anpassen, nachdem das Modell ausgeführt wurde. Die Nachverarbeitung kann verwendet werden, um Fairness-Einschränkungen durchzusetzen, ohne die Modelle selbst zu ändern.
Sie können beispielsweise die Nachbearbeitung auf einen binären Klassifikator anwenden, indem Sie einen Klassifizierungsschwellenwert so festlegen, dass die Chancengleichheit für ein bestimmtes Attribut aufrechterhalten wird. Dazu wird geprüft, ob die Rate echt positiver Ergebnisse für alle Werte dieses Attributs gleich ist.
prognostizierter Wert
Die Ausgabe eines Modells. Beispiel:
- Die Vorhersage eines binären Klassifizierungsmodells ist entweder die positive oder die negative Klasse.
- Die Vorhersage eines Klassifizierungsmodells mit mehreren Klassen ist eine Klasse.
- Die Vorhersage eines linearen Regressionsmodells ist eine Zahl.
Proxy-Labels
Daten zur Annäherung von Labels, die in einem Dataset nicht direkt verfügbar sind.
Angenommen, Sie müssen ein Modell trainieren, um den Stresslevel von Mitarbeitern vorherzusagen. Ihr Dataset enthält viele Vorhersagemerkmale, aber kein Label mit dem Namen Stresslevel. Sie lassen sich nicht erschrecken und wählen „Arbeitsunfälle“ als Proxy-Label für das Stresslevel aus. Schließlich geraten Mitarbeitende unter starkem Stress mehr Unfällen als ruhige Mitarbeiter. Oder doch? Vielleicht steigen und fallen Arbeitsunfälle aus verschiedenen Gründen.
Nehmen wir als zweites Beispiel an, Sie möchten Is it raining? ein boolesches Label für Ihr Dataset sein, das Dataset enthält jedoch keine Regendaten. Wenn Fotos vorhanden sind, können Bilder von Personen mit Regenschirmen als Proxy-Label für Regnet es? verwendet werden. Ist das ein gutes Proxy-Label? Möglicherweise ist die Wahrscheinlichkeit, dass Menschen in einigen Kulturen einen Regenschirm zum Schutz vor Sonnenlicht tragen, höher als vor Regen.
Proxy-Labels sind oft nicht perfekt. Wenn möglich, sollten Sie tatsächliche Labels anstelle von Proxy-Labels verwenden. Wenn jedoch ein tatsächliches Proxy-Label fehlt, wählen Sie das Proxy-Label sehr sorgfältig aus und wählen Sie den am wenigsten schrecklichen Kandidat für das Proxy-Label aus.
R
RAG
Abkürzung für retrieval-augmented generation.
Bewerter
Ein Mensch, der Labels für Beispiele bereitstellt. „Kommentator“ ist ein anderer Name für Bewerter.
Rektifizierte lineare Einheit (ReLU)
Eine Aktivierungsfunktion mit folgendem Verhalten:
- Wenn die Eingabe negativ oder null ist, ist die Ausgabe 0.
- Wenn die Eingabe positiv ist, ist die Ausgabe gleich der Eingabe.
Beispiel:
- Wenn die Eingabe -3 ist, ist die Ausgabe 0.
- Wenn die Eingabe +3 ist, ist die Ausgabe 3,0.
Hier ist eine Darstellung von ReLU:
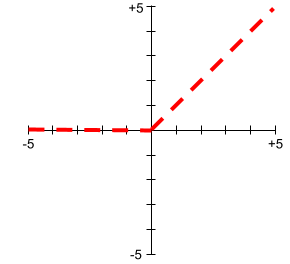
ReLU ist eine sehr beliebte Aktivierungsfunktion. Trotz seines einfachen Verhaltens ermöglicht ReLU ein neuronales Netzwerk, nicht lineare Beziehungen zwischen Features und dem Label zu erkennen.
Regressionsmodell
Inoffiziell ein Modell, das eine numerische Vorhersage generiert. Im Gegensatz dazu generiert ein Klassifizierungsmodell eine Klassenvorhersage. Im Folgenden finden Sie beispielsweise nur Regressionsmodelle:
- Ein Modell, das den Wert eines bestimmten Hauses vorhersagt,z. B. 423.000 €.
- Ein Modell, das die Lebenserwartung eines bestimmten Baums vorhersagt, z. B. 23,2 Jahre.
- Ein Modell, das die Regenmenge vorhersagt, die in einer bestimmten Stadt in den nächsten sechs Stunden fallen wird, z. B. 0,18 Zoll.
Zwei gängige Arten von Regressionsmodellen sind:
- Lineare Regression, die die Linie ermittelt, die am besten zu Labelwerten für Features passt.
- Logistische Regression, bei der eine Wahrscheinlichkeit zwischen 0,0 und 1,0 generiert wird, die ein System normalerweise dann einer Klassenvorhersage zuordnet.
Nicht jedes Modell, das numerische Vorhersagen ausgibt, ist ein Regressionsmodell. In manchen Fällen ist eine numerische Vorhersage eigentlich nur ein Klassifizierungsmodell, das zufällig numerische Klassennamen hat. Beispielsweise ist ein Modell, das eine numerische Postleitzahl vorhersagt, ein Klassifizierungsmodell und kein Regressionsmodell.
Regularisierung
Jeder Mechanismus, der eine Überanpassung reduziert. Zu den beliebtesten Arten der Regularisierung gehören:
- L1-Regularisierung
- L2-Regularisierung
- Dropout-Regularisierung
- frühes Anhalten: Dies ist keine formale Regularisierungsmethode, kann Überanpassung aber effektiv begrenzen.
Regularisierung kann auch als Nachteil für die Komplexität eines Modells definiert werden.
Regularisierungsrate
Eine Zahl, die die relative Bedeutung der Regularisierung während des Trainings angibt. Durch eine Erhöhung der Regularisierungsrate wird die Überanpassung reduziert, aber möglicherweise auch die Vorhersageleistung des Modells. Umgekehrt erhöht sich durch das Reduzieren oder Auslassen der Regularisierungsrate die Überanpassung.
ReLU
Abkürzung für Rektifizierte lineare Einheit.
Retrieval-Augmented Generation (RAG)
Verfahren zur Verbesserung der Qualität der Ausgabe von Large Language Models (LLM), indem sie auf Wissensquellen gelegt wird, die nach dem Training des Modells abgerufen wurden RAG verbessert die Genauigkeit von LLM-Antworten, indem es dem trainierten LLM Zugriff auf Informationen aus vertrauenswürdigen Wissensdatenbanken oder Dokumenten gewährt.
Häufige Gründe für die Verwendung der Abruf-erweiterten Generierung sind:
- Die faktische Genauigkeit der generierten Antworten eines Modells erhöhen.
- Dem Modell Zugriff auf Wissen gewähren, mit dem es nicht trainiert wurde.
- Ändern des Wissens, das das Modell verwendet.
- Das Modell zum Zitieren von Quellen aktivieren.
Angenommen, eine Chemieanwendung verwendet die PaLM API, um Zusammenfassungen zu Nutzerabfragen zu generieren. Wenn das Back-End der Anwendung eine Anfrage empfängt, führt das Back-End folgende Schritte aus:
- Sucht nach Daten, die für die Suchanfrage des Nutzers relevant sind („abruft“).
- Die relevanten Chemiedaten werden an die Suchanfrage des Nutzers angehängt.
- Weist das LLM an, anhand der angehängten Daten eine Zusammenfassung zu erstellen.
ROC-Kurve (Receiver Operating Curve)
Ein Diagramm der Rate echt positiver Ergebnisse im Vergleich zur Rate falsch positiver Ergebnisse für verschiedene Klassifizierungsschwellenwerte bei der binären Klassifizierung.
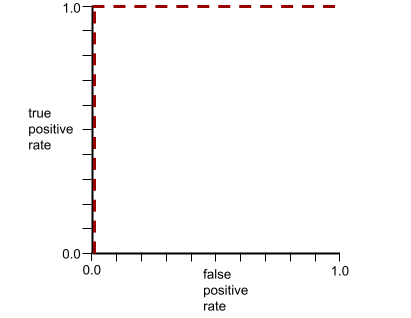
Die Form einer ROC-Kurve deutet auf die Fähigkeit eines binären Klassifizierungsmodells hin, positive von negativen Klassen zu trennen. Angenommen, ein binäres Klassifizierungsmodell trennt zum Beispiel alle negativen Klassen perfekt von allen positiven Klassen:
Die ROC-Kurve für das vorherige Modell sieht so aus:
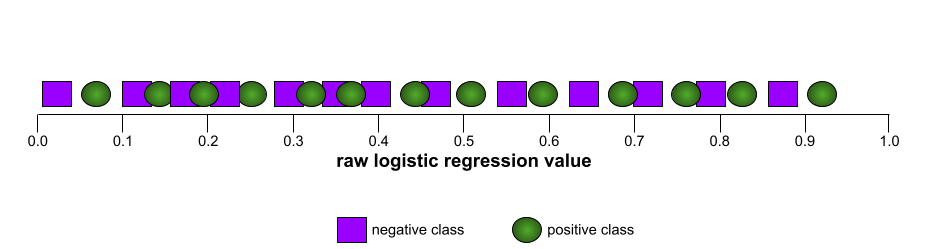
Im Gegensatz dazu werden in der folgenden Abbildung die unbearbeiteten logistischen Regressionswerte für ein schlechtes Modell grafisch dargestellt, das negative Klassen überhaupt nicht von positiven Klassen trennen kann:
Die ROC-Kurve für dieses Modell sieht so aus:
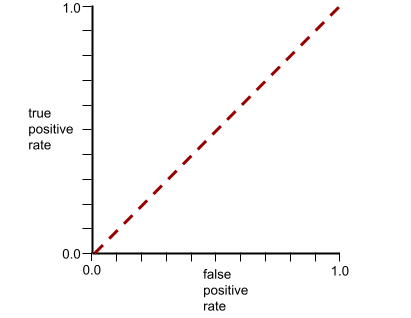
In der realen Welt trennen die meisten binären Klassifizierungsmodelle positive und negative Klassen zu einem gewissen Grad, aber in der Regel nicht perfekt. Eine typische ROC-Kurve liegt also irgendwo zwischen zwei Extremen:
Der Punkt auf einer ROC-Kurve, der (0,0;1,0) am nächsten ist, gibt theoretisch den idealen Klassifizierungsschwellenwert an. Die Auswahl des idealen Klassifizierungsschwellenwerts wird jedoch von einigen anderen realen Problemen beeinflusst. Falsch negative Ergebnisse bereiten beispielsweise viel schmerzhaftere Ergebnisse an als falsch positive.
Ein numerischer Messwert namens AUC fasst die ROC-Kurve in einen einzelnen Gleitkommawert zusammen.
Wurzel des mittleren quadratischen Fehlers (Root Mean Squared Error, RMSE)
Die Quadratwurzel des mittleren quadratischen Fehlers.
S
Sigmoidfunktion
Eine mathematische Funktion, mit der ein Eingabewert in einen eingeschränkten Bereich verschoben wird, in der Regel zwischen 0 und 1 oder -1 bis +1. Sie können also eine beliebige Zahl (zwei, eine Million, negative Milliarde usw.) an ein Sigmoid übergeben, und die Ausgabe bleibt im eingeschränkten Bereich. Das Diagramm der Sigmoidaktivierungsfunktion sieht so aus:
Die Sigmoidfunktion wird beim maschinellen Lernen mehrfach verwendet:
- Die Rohausgabe eines logistischen Regressionsmodells oder eines multinomialen Regressionsmodells in einen Wahrscheinlichkeitswert konvertieren
- In einigen neuronalen Netzwerken als Aktivierungsfunktion
Softmax-Funktion
Eine Funktion, die Wahrscheinlichkeiten für jede mögliche Klasse in einem Klassifizierungsmodell mit mehreren Klassen bestimmt. Die Wahrscheinlichkeiten ergeben insgesamt genau 1,0. Die folgende Tabelle zeigt beispielsweise, wie Softmax verschiedene Wahrscheinlichkeiten verteilt:
| Das Bild ist... | Probability |
|---|---|
| Hund | 0,85 |
| Cat | 0,13 |
| Pferd | ,02 |
Softmax wird auch als vollständiges Softmax bezeichnet.
Im Vergleich zur Stichprobenerhebung für Kandidaten
dünnbesetztes Feature
Ein Feature, dessen Werte überwiegend null oder leer sind. Beispiel: Ein Feature mit einem einzelnen Wert 1 und einer Million 0-Werten ist dünnbesetzt. Im Gegensatz dazu hat ein dichtes Feature Werte, die überwiegend nicht null oder leer sind.
Beim maschinellen Lernen gibt es erstaunlich viele Funktionen, die nur dünnbesetzt sind. Kategorische Merkmale sind in der Regel dünnbesetzte Merkmale. Beispielsweise könnte von den 300 möglichen Baumarten in einem Wald in einem einzelnen Beispiel nur ein Ahornbaum identifiziert werden. Oder unter den Millionen möglicher Videos in einer Videobibliothek könnte ein einzelnes Beispiel nur „Casablanca“ heißen.
In einem Modell stellen Sie dünnbesetzte Features in der Regel mit One-Hot-Codierung dar. Wenn die One-Hot-Codierung groß ist, können Sie für eine höhere Effizienz eine Einbettungsschicht über die One-Hot-Codierung legen.
dünnbesetzte Darstellung
Nur die Position(en) von Elementen ungleich null in einem dünnbesetzten Feature speichern.
Angenommen, ein kategoriales Feature namens species identifiziert die 36 Baumarten in einem bestimmten Wald. Nehmen wir weiter an, dass jedes Beispiel nur eine einzelne Art identifiziert.
Sie könnten einen One-Hot-Vektor verwenden, um die Baumarten in jedem Beispiel darzustellen.
Ein One-Hot-Vektor enthält eine einzelne 1 (zur Darstellung der jeweiligen Baumart in diesem Beispiel) und 35 0s (um die 35 Baumarten darzustellen, die in diesem Beispiel nicht). Die One-Hot-Darstellung von maple könnte also in etwa so aussehen:

Alternativ würde bei einer dünnbesetzten Darstellung einfach die Position der jeweiligen Art identifiziert werden. Wenn sich maple auf Position 24 befindet, würde die dünnbesetzte Darstellung von maple einfach so aussehen:
24
Beachten Sie, dass die dünnbesetzte Darstellung viel kompakter ist als die One-Hot-Darstellung.
Klicken Sie auf das Symbol, um ein etwas komplexeres Beispiel anzuzeigen.
Angenommen, jedes Beispiel in Ihrem Modell muss die Wörter – aber nicht die Reihenfolge dieser Wörter – in einem englischen Satz darstellen. Englisch besteht aus etwa 170.000 Wörtern. Englisch ist also ein kategoriales Merkmal mit etwa 170.000 Elementen. Die meisten englischen Sätze enthalten einen sehr winzigen Bruchteil dieser 170.000 Wörter, sodass die Wörter in einem einzigen Beispiel mit hoher Wahrscheinlichkeit wenig Daten enthalten.
Betrachten Sie den folgenden Satz:
My dog is a great dog
Sie können eine Variante eines One-Hot-Vektors verwenden, um die Wörter in diesem Satz darzustellen. Bei dieser Variante können mehrere Zellen im Vektor einen Wert ungleich null enthalten. Außerdem kann in dieser Variante eine Zelle eine andere Ganzzahl enthalten. Obwohl die Wörter „my“, „is“, „a“ und „great“ nur einmal im Satz vorkommen, kommt das Wort „Hund“ zweimal vor. Wenn Sie diese Variante von One-Hot-Vektoren zur Darstellung der Wörter in diesem Satz verwenden,ergibt sich der folgende Vektor mit 170.000 Elementen:

Eine dünnbesetzte Darstellung desselben Satzes wäre einfach:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
dünnbesetzter Vektor
Ein Vektor, dessen Werte hauptsächlich Nullen sind. Weitere Informationen finden Sie unter Sparse-Feature und Datendichte.
Quadratischer Verlust
Synonym für L2-Verlust.
Statisch
Einmal anstatt fortlaufend. Die Begriffe statisch und offline sind Synonyme. static und offline werden beim maschinellen Lernen häufig verwendet:
- Statisches Modell (oder Offline-Modell) ist ein Modell, das einmal trainiert und dann für eine gewisse Zeit verwendet wird.
- Statisches Training (oder Offlinetraining) ist der Prozess des Trainings eines statischen Modells.
- Eine statische Inferenz (oder Offlineinferenz) ist ein Prozess, bei dem ein Modell einen Batch von Vorhersagen auf einmal generiert.
Kontrast mit dynamisch
statische Inferenz
Synonym für Offlineinferenz.
stehen bleiben
Ein Element, dessen Werte sich in einer oder mehreren Dimensionen nicht ändern (in der Regel zeitbezogen). Beispiel: Ein Element, dessen Werte 2021 und 2023 ungefähr gleich aussehen, weist Schreibstabilität auf.
In der realen Welt weist nur sehr wenige Elemente Stationarität auf. Auch Funktionen, die für Stabilität bekannt sind (z. B. den Meeresspiegel), ändern sich im Laufe der Zeit.
Stellen Sie einen Kontrast zu Nichtstationarität her.
Stochastisches Gradientenabstieg (SGD)
Ein Algorithmus für den Gradientenabstieg, bei dem die Batchgröße eins ist. Mit anderen Worten, SGD wird anhand eines einzelnen Beispiels trainiert, das gleichmäßig aus einem Trainingssatz zufällig ausgewählt wird.
überwachtes maschinelles Lernen
Beim Trainieren eines model aus model und den entsprechenden model. Das überwachte maschinelle Lernen ist analog zum Erlernen eines Fachs, indem eine Reihe von Fragen und die entsprechenden Antworten untersucht werden. Nachdem der Schüler die Zuordnung von Fragen und Antworten gemeistert hat, kann er Antworten auf neue (bisher unbekannte) Fragen zum selben Thema geben.
Dies ist mit unüberwachtem maschinellem Lernen vergleichbar.
synthetisches Feature
Ein Feature, das nicht zu den Eingabefeatures gehört, aber aus einem oder mehreren dieser Features zusammengestellt wurde. Folgende Methoden zum Erstellen synthetischer Features sind verfügbar:
- Bucketing eines fortlaufenden Features in Bereichsbereiche.
- Eine Feature-Cross-Funktion erstellen
- Multiplizieren (oder Dividieren) eines Merkmalswerts mit anderen Merkmalswerten oder durch sich selbst. Wenn
aundbbeispielsweise Eingabefeatures sind, sind die folgenden Beispiele für synthetische Features:- ab
- a2
- Eine transzendentale Funktion auf einen Merkmalswert anwenden Wenn
cbeispielsweise ein Eingabefeature ist, dann finden Sie hier Beispiele für synthetische Features:- sin(c)
- ln(c)
Durch die Normalisierung oder Skalierung allein erstellte Features werden nicht als synthetische Features betrachtet.
T
Testverlust
Ein Messwert, der den Verlust eines Modells gegenüber dem Test-Dataset darstellt. Beim Erstellen eines model versuchen Sie in der Regel, den Testverlust zu minimieren. Das liegt daran, dass ein geringer Testverlust ein besseres Signal als ein niedriger Trainingsverlust oder ein geringer Validierungsverlust darstellt.
Eine große Lücke zwischen dem Testverlust und dem Trainings- oder Validierungsverlust weist manchmal darauf hin, dass Sie die Regularisierungsrate erhöhen müssen.
Training
Prozess zur Bestimmung der idealen Parameter (Gewichtungen und Voreingenommenheiten) in einem Modell. Während des Trainings liest ein System Beispiele ein und passt Parameter schrittweise an. Die einzelnen Beispiele werden beim Training einige Male bis mehrere Male verwendet.
Trainingsverlust
Ein Messwert, der den Verlust eines Modells während eines bestimmten Trainingsdurchlaufs darstellt. Angenommen, die Verlustfunktion ist mittlerer quadratischer Fehler. Vielleicht beträgt der Trainingsverlust (der mittlere quadratische Fehler) für den 10.Durchlauf 2,2 und der Trainingsverlust für den 100.Durchlauf 1,9.
In einer Verlustkurve wird der Trainingsverlust im Vergleich zur Anzahl der Iterationen dargestellt. Eine Verlustkurve liefert die folgenden Hinweise zum Training:
- Eine Steigung deutet darauf hin, dass sich das Modell verbessert.
- Eine Steigung deutet darauf hin, dass das Modell verschlechtert wird.
- Eine flache Steigung impliziert, dass das Modell eine Konvergenz erreicht hat.
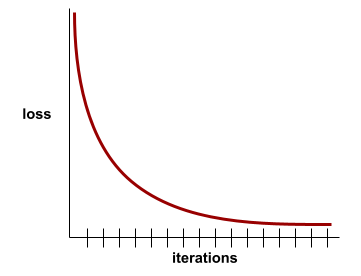
Die folgende etwas idealisierte Verlustkurve zeigt beispielsweise:
- Ein steiler Abfall während der ersten Iterationen, was eine schnelle Modellverbesserung impliziert.
- Eine allmähliche (aber immer weiter abfallende) Steigung bis zum Ende des Trainings, was eine kontinuierliche Modellverbesserung mit einem etwas langsameren Tempo als während der ersten Iterationen impliziert.
- Ein flacher Hang gegen Ende des Trainings, was eine Konvergenz suggeriert.
Obwohl der Trainingsverlust wichtig ist, siehe auch Generalisierung.
Abweichungen zwischen Training und Bereitstellung
Der Unterschied zwischen der Leistung eines Modells während des Trainings und der Leistung desselben Modells während der Bereitstellung.
Trainings-Dataset
Die Teilmenge des Datasets, die zum Trainieren eines Modells verwendet wird.
Traditionell werden Beispiele im Dataset in die folgenden drei Teilmengen unterteilt:
- ein Trainings-Dataset
- ein Validierungs-Dataset
- ein Test-Dataset
Idealerweise sollte jedes Beispiel im Dataset nur zu einer der vorhergehenden Teilmengen gehören. Beispielsweise sollte ein einzelnes Beispiel nicht sowohl zum Trainings- als auch zum Validierungs-Dataset gehören.
richtig negativ (TN)
Ein Beispiel, in dem das Modell die negative Klasse richtig vorhersagt. Das Modell leitet beispielsweise ab, dass eine bestimmte E-Mail-Nachricht kein Spam und diese E-Mail in Wirklichkeit kein Spam ist.
richtig positives Ergebnis (TP)
Ein Beispiel, in dem das Modell die positive Klasse richtig vorhersagt. Das Modell schlussfolgert beispielsweise, dass eine bestimmte E-Mail-Nachricht Spam und diese E-Mail-Nachricht in Wirklichkeit Spam ist.
Rate richtig positiver Ergebnisse (TPR)
Synonym für Recall. Das bedeutet:
Die Richtig-Positiv-Rate ist die Y-Achse in einer ROC-Kurve.
U
Unteranpassung
Erstellen eines model mit unzureichenden Vorhersagefähigkeiten, da das Modell die Komplexität der Trainingsdaten nicht vollständig erfasst hat. Viele Probleme können zu einer Unteranpassung führen, darunter:
- Es wird ein Training zu den falschen Funktionen durchgeführt.
- Das Training erfolgt über zu wenige Epochen oder mit einer zu niedrigen Lernrate.
- Training mit zu hoher Regularisierungsrate.
- Sie stellen zu wenige verborgene Ebenen in einem neuronalen Deep-Learning-Netzwerk bereit.
Beispiel ohne Label
Ein Beispiel, das Features, aber kein Label enthält. Die folgende Tabelle zeigt beispielsweise drei Beispiele ohne Label aus einem Hausbewertungsmodell mit jeweils drei Merkmalen, aber ohne Hauswert:
| Anzahl der Schlafzimmer | Anzahl der Badezimmer | Hausalter |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Beim überwachten maschinellen Lernen werden Modelle anhand von Beispielen mit Labels trainiert und Vorhersagen für Beispiele ohne Label treffen.
Beim halbüberwachten und unüberwachten Lernen werden während des Trainings Beispiele ohne Label verwendet.
Vergleichen Sie ein Beispiel ohne Label mit einem Beispiel mit Label.
unüberwachtes maschinelles Lernen
model trainieren, um Muster in einem Dataset zu erkennen – in der Regel in einem Dataset ohne Label
Unüberwachtes maschinelles Lernen wird am häufigsten verwendet, um Daten in Gruppen ähnlicher Beispiele zu gruppieren. Beispielsweise kann ein Algorithmus für unbeaufsichtigtes maschinelles Lernen Songs anhand verschiedener Eigenschaften der Musik gruppieren. Die resultierenden Cluster können als Eingabe für andere Algorithmen für maschinelles Lernen dienen (z. B. für einen Musikempfehlungsdienst). Clustering kann hilfreich sein, wenn nützliche Labels knapp sind oder fehlen. In Bereichen wie Missbrauch und Betrug können Cluster zum Beispiel Menschen helfen, die Daten besser zu verstehen.
Hier kommt überwachtes maschinelles Lernen zum Einsatz.
V
validation
Die anfängliche Bewertung der Qualität eines Modells. Bei der Validierung wird die Qualität der Vorhersagen eines Modells mit dem Validierungs-Dataset verglichen.
Da sich das Validierungs-Dataset vom Trainings-Dataset unterscheidet, schützt die Validierung vor einer Überanpassung.
Sie können sich die Bewertung des Modells anhand des Validierungs-Datasets als erste Testrunde und die Bewertung des Modells anhand des Test-Datasets als zweite Testrunde vorstellen.
Validierungsverlust
Ein Messwert, der den Verlust eines Modells im Validierungs-Dataset während einer bestimmten Iteration des Trainings darstellt.
Siehe auch Generalisierungskurve.
Validierungs-Dataset
Die Teilmenge des Datasets, die eine Erstbewertung für ein trainiertes Modell durchführt. In der Regel bewerten Sie das trainierte Modell mehrmals anhand des Validierungs-Datasets, bevor Sie es anhand des Test-Datasets evaluieren.
Traditionell unterteilen Sie die Beispiele im Dataset in die folgenden drei unterschiedlichen Teilmengen:
- ein Trainings-Set
- ein Validierungs-Dataset
- ein Test-Dataset
Idealerweise sollte jedes Beispiel im Dataset nur zu einer der vorhergehenden Teilmengen gehören. Beispielsweise sollte ein einzelnes Beispiel nicht sowohl zum Trainings- als auch zum Validierungs-Dataset gehören.
W
Gewicht
Wert, den ein Modell mit einem anderen Wert multipliziert. Beim Training werden die Idealgewichte eines Modells bestimmt. Bei der Inferenz werden diese gelernten Gewichtungen für Vorhersagen verwendet.
gewichtete Summe
Die Summe aller relevanten Eingabewerte multipliziert mit den entsprechenden Gewichtungen. Angenommen, die relevanten Eingaben bestehen aus Folgendem:
| Eingabewert | Eingabegewichtung |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Die gewichtete Summe ist daher:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Eine gewichtete Summe ist das Eingabeargument für eine Aktivierungsfunktion.
Z
Normalisierung des Z-Scores
Ein Skalierungsverfahren, bei dem ein Feature-Rohwert durch einen Gleitkommawert ersetzt wird, der die Anzahl der Standardabweichungen vom Mittelwert dieses Features darstellt. Betrachten Sie beispielsweise ein Feature mit einem Mittelwert von 800 und dessen Standardabweichung 100. Die folgende Tabelle zeigt, wie die Normalisierung bei der Z-Wertung den Rohwert seinem Z-Wert zuordnen würde:
| Unverarbeiteter Wert | Z-Score |
|---|---|
| 800 | 0 |
| 950 | +0,7 |
| 575 | -2,25 |
Das Modell für maschinelles Lernen wird dann anhand der Z-Werte für dieses Feature und nicht anhand der Rohwerte trainiert.