Ta strona zawiera terminy z glosariusza Las Decision Forest. Aby zobaczyć wszystkie terminy ze glosariusza, kliknij tutaj.
O
próbkowanie atrybutów
Taktyka trenowania lasu decyzyjnego, w której każde drzewo decyzji podczas poznawania warunku uwzględnia tylko losowy podzbiór możliwych funkcji. Ogólnie dla każdego węzła próbkowany jest inny podzbiór cech. Natomiast w przypadku trenowania drzewa decyzyjnego bez próbkowania atrybutów, w przypadku każdego węzła uwzględniane są wszystkie możliwe cechy.
warunek wyrównany do osi
W drzewie decyzyjnym warunek, który obejmuje tylko 1 cechę. Jeśli np. obiekt jest obiektem, warunek jest wyrównany do osi w ten sposób:
area > 200
Skontrastowanie względem warunku ukośnego.
B
bagażowanie
Metoda trenowania zestawu, w którym każdy model składowy trenuje na losowym podzbiorze przykładów treningowych próbkowanych z zastąpieniem. Na przykład losowy las to zbiór drzew decyzyjnych wytrenowanych z użyciem worków.
Termin bagging to skrót od bootstrap aggregating.
warunek binarny
W drzewie decyzyjnym warunek ma tylko 2 możliwe wyniki – zwykle tak lub nie. Na przykład taki warunek binarny:
temperature >= 100
Porównaj z warunkem niebinarnym.
C
stan
W drzewie decyzyjnym każdy węzeł, który ocenia wyrażenie. Na przykład ta część drzewa decyzji zawiera 2 warunki:
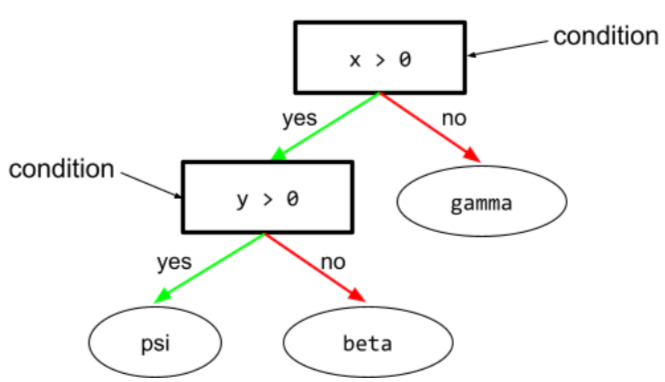
Warunek jest nazywany też podziałem lub testem.
Warunek kontrastu z liściem.
Zobacz także:
- warunek binarny
- warunek niebinarny.
- axis-aligned-condition (warunek wyrównany do osi)
- warunek skośny
D
las decyzji
Model utworzony na podstawie wielu drzew decyzyjnych. Las decyzyjny polega na agregowaniu prognoz dotyczących drzew decyzyjnych. Popularne rodzaje lasów decyzyjnych to lasy losowe i drzewa o podwyższonym standardzie gradientowym.
drzewo decyzyjne
Nadzorowany model uczenia się składający się z uporządkowanego hierarchicznie zestawu conditions i conditions. Tak wygląda na przykład schemat decyzyjny:
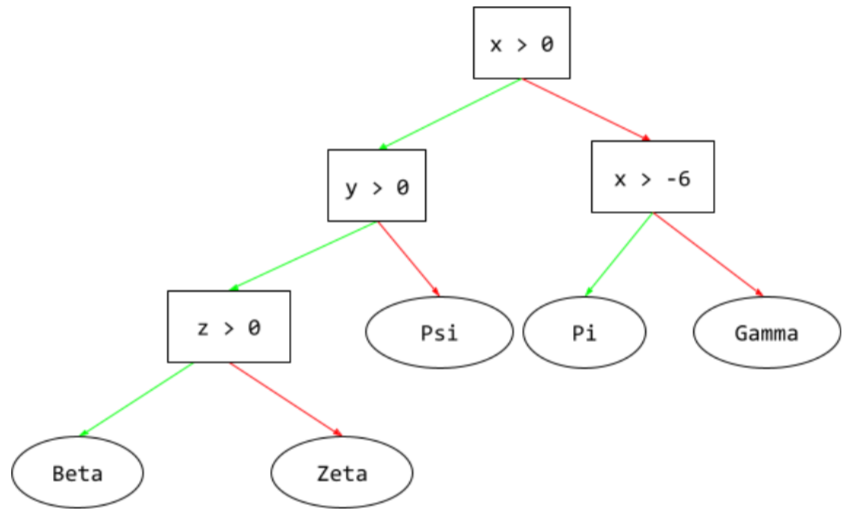
E
entropia
W teorii informacji jest to opis nieprzewidywalności rozkładu prawdopodobieństwa. Entropia jest też definiowana jako ilość informacji w poszczególnych przykładach. Rozkład ma najwyższą możliwą entropię, gdy wszystkie wartości zmiennej losowej są jednakowe.
Entropia zbioru z 2 możliwymi wartościami „0” i „1” (np. etykiety w problemie z klasyfikacją binarną) ma taki wzór:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
gdzie:
- H to entropia.
- p to ułamek z przykładów „1”.
- q to ułamek z przykładów „0”. Zwróć uwagę, że q = (1 - p)
- log to zwykle log2. W tym przypadku jednostka entropii jest nieco większa.
Załóżmy na przykład, że:
- 100 przykładów zawiera wartość „1”
- 300 przykładów zawiera wartość „0”
Dlatego wartość entropii wynosi:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) – (0,75)log2(0,75) = 0,81 bitów na przykład
Idealnie zrównoważony zestaw (np.200 „0” i 200 „1”) będzie miał na przykład 1, 0 bitu. W miarę jak zestaw staje się bardziej niezrównoważony, jego entropia przesuwa się w kierunku 0,0.
W drzewach decyzyjnych entropia pomaga w formułowaniu zysku informacji, aby ułatwić rozdzielanie warunków w trakcie rozwoju drzewa decyzyjnego.
Porównaj entropię z:
- nieczystość gini
- Funkcja utraty entropii krzyżowej
Entropia jest często nazywana entropią Shannona.
F
znaczenie cech
Synonim dla znaczenia zmiennych.
G
nieczystość gini
Wartość podobna do entropii. Rozdzielacze wykorzystują wartości uzyskane na podstawie zanieczyszczenia ginu lub entropii, aby utworzyć warunki klasyfikacji drzew decyzyjnych. Zdobycie informacji pochodzi z entropii. Nie ma powszechnie przyjętego równoważnego terminu oznaczającego dane pochodzące ze zanieczyszczenia ginu. Te nienazwane dane są jednak tak samo ważne jak zdobywanie informacji.
Nieczystość ginu jest również nazywana indeksem gini lub po prostu gini.
drzewa z wzmocnieniem gradientowym (GBT)
Rodzaj lasu decyzji, w którym:
- Trenowanie bazuje na wzmocnieniu gradientu.
- Słaby model to drzewo decyzji.
wzmocnienie gradientu
Algorytm trenowania, w którym słabe modele są trenowane w celu iteracyjnej poprawy jakości (zmniejszenia utraty) silnego modelu. Słabym modelem może być np. liniowy lub mały model drzewa decyzyjnego. Silny model staje się sumą wszystkich słabych modeli wytrenowanych wcześniej.
W najprostszej formie wzmocnienia gradientu przy każdej iteracji trenowany jest słaby model, aby przewidywać gradient straty silnego modelu. Następnie dane wyjściowe modelu są aktualizowane przez odjęcie przewidywanego gradientu, podobnie jak w przypadku spadku gradientu.
gdzie:
- Dobrym modelem początkowym jest $F_{0}$.
- Następnym solidnym modelem jest $F_{i+1}$.
- Obecny solidny model: $F_{i}$.
- $\xi$ to wartość z zakresu od 0,0 do 1,0 nazywana kurczeniem, która odpowiada szybkości uczenia się podczas zejścia gradientu.
- $f_{i}$ to słaby model wytrenowany do prognozowania gradientu utraty wartości $F_{i}$.
Nowoczesne odmiany wzmocnienia gradientu obejmują również drugą (heskijską) pochodną straty w obliczeniach.
Drzewa decyzyjne są zwykle używane jako słabe modele przy wzmocnieniu gradientowym. Zobacz drzewa o wzmocnieniu gradientu (decyzja).
I
ścieżka wnioskowania
W drzewie decyzyjnym w trakcie wnioskowania trasa konkretnego przykładu prowadzi z pierwiastka do innych warunków i kończy się liściem. Na przykład w tym drzewie decyzyjnym grubsze strzałki oznaczają ścieżkę wnioskowania dla przykładu z tymi wartościami cech:
- x = 7
- y = 12
- Z = –3
Ścieżka wnioskowania na ilustracji poniżej przechodzi przez 3 warunki, zanim dotrze do liścia (Zeta).
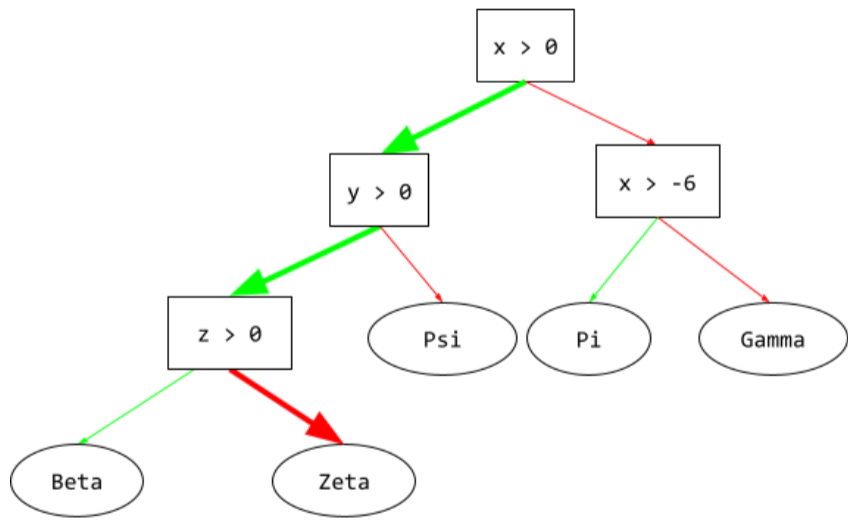
Trzy grube strzałki oznaczają ścieżkę wnioskowania.
zdobywanie informacji
W lasach decyzyjnych różnica między entropią węzła a ważoną (według liczby przykładów) sumą entropii węzłów podrzędnych. Entropia węzła to entropia przykładów w tym węźle.
Na przykład rozważ te wartości entropii:
- entropia węzła nadrzędnego = 0,6
- entropia jednego węzła podrzędnego z 16 odpowiednimi przykładami = 0,2
- entropia innego węzła podrzędnego z 24 odpowiednimi przykładami = 0,1
Dlatego 40% przykładów znajduje się w jednym węźle podrzędnym, a 60% w innym węźle podrzędnym. Dlatego:
- suma entropii ważona węzłów podrzędnych = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Uzyskana informacja to:
- zysk informacji = entropia węzła nadrzędnego – suma entropii ważona węzłów podrzędnych
- zysk informacyjny = 0,6 - 0,14 = 0,46
Większość narzędzi do podziału danych stara się tworzyć warunki, które maksymalizują dostęp do informacji.
warunek w zestawie
warunek w drzewie decyzyjnym, który sprawdza obecność jednego elementu w zestawie elementów; Na przykład taki warunek jest w zestawie:
house-style in [tudor, colonial, cape]
Jeśli w trakcie wnioskowania wartość cechy w stylu domu to tudor, colonial lub cape, ten warunek przyjmuje wartość Tak. Jeśli wartością obiektu w stylu domu jest coś innego (np. ranch), ten warunek przyjmuje wartość Nie.
Warunki wbudowane pozwalają zwykle na tworzenie skuteczniejszych drzew decyzyjnych niż warunki, które testują funkcje zakodowane jednorazowo.
L
liść
Dowolny punkt końcowy w drzewie decyzji. W przeciwieństwie do warunku liść nie przeprowadza testu. Liść jest prawdopodobną przewidywaną. Liść jest też końcowym węzłem ścieżki wnioskowania.
Na przykład to drzewo decyzyjne zawiera 3 liście:
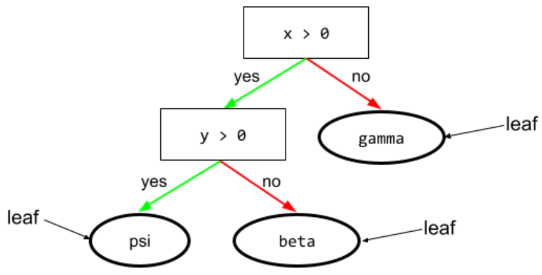
N
węzeł (drzewo decyzji)
W drzewie decyzyjnym dowolny warunek lub liść.
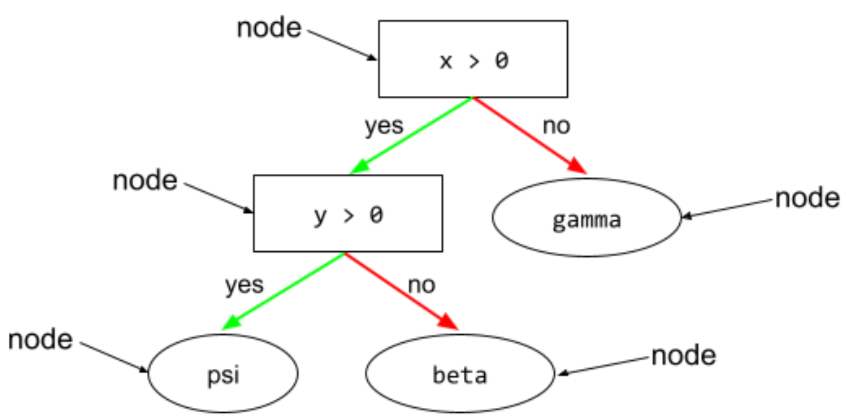
warunek niebinarny
Warunek obejmujący więcej niż 2 możliwe wyniki. Na przykład taki niebinarny warunek obejmuje 3 możliwe rezultaty:
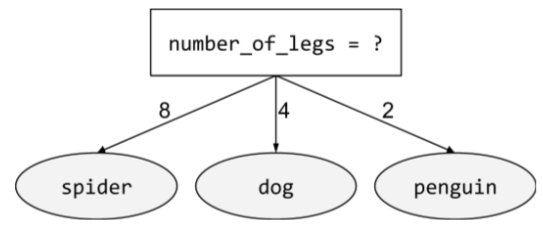
O
warunek skośny
W drzewie decyzyjnym warunek obejmujący więcej niż 1 cechę. Jeśli np. wysokość i szerokość to oba te elementy, warunek jest taki:
height > width
Skontrastowanie względem warunku wyrównanego do osi.
ocena poza torbą (ocena OOB)
Mechanizm oceny jakości lasu decyzyjnego poprzez testowanie każdego drzewa decyzyjnego z uwzględnieniem przykładów nie używanych podczas trenowania tego drzewa decyzyjnego. Na przykład na poniższym diagramie zauważ, że system trenuje każde drzewo decyzyjne w około 2/3 przykładów, a następnie porównuje z pozostałą jedną trzecią przykładów.
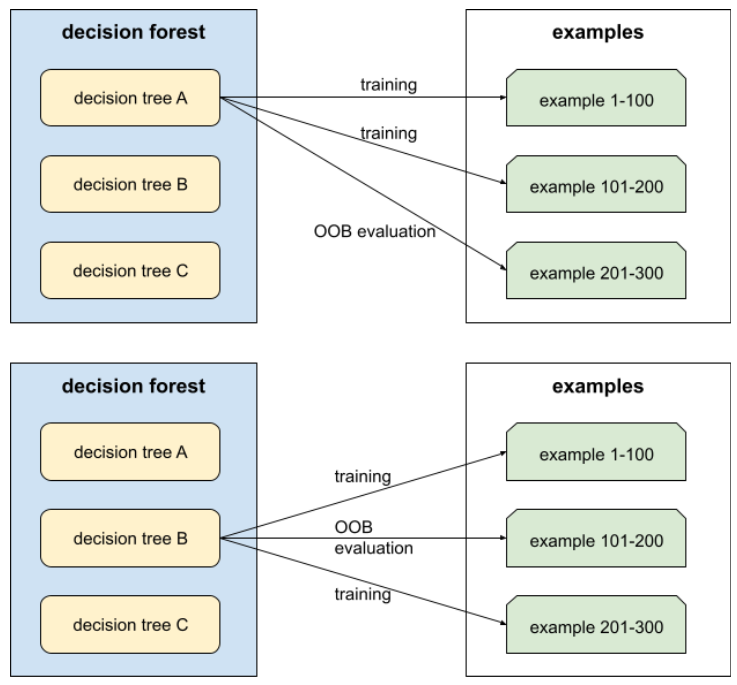
Ocena poza ramką to wydajne i ostrożne podejście do mechanizmu weryfikacji krzyżowej. W ramach weryfikacji krzyżowej trenowany jest 1 model na każdą rundę weryfikacji krzyżowej (np. 10 modeli jest trenowanych w ramach 10-krotnej weryfikacji krzyżowej). W przypadku oceny OOB trenowany jest pojedynczy model. Ponieważ podczas trenowania funkcja bagażania pomija niektóre dane z każdego drzewa podczas trenowania, ocena OOB może używać tych danych do przybliżonej weryfikacji krzyżowej.
P
Znaczenie zmiennej permutacji
Rodzaj znaczenia zmiennej, który ocenia wzrost błędu prognozy modelu po zmianie wartości cechy. Znaczenie zmiennej permutacji jest wartością niezależną od modelu.
R
Losowy las
Grupa drzew decyzyjnych, w której każde drzewo decyzyjne jest trenowane za pomocą określonego losowego szumu, na przykład bagażu.
Lasy losowe są rodzajem lasu decyzyjnego.
poziom główny
Początkowy węzeł (pierwszy warunek) w drzewie decyzji. Zgodnie z konwencją diagramy u góry drzewa decyzyjnego leżą korzenie. Na przykład:
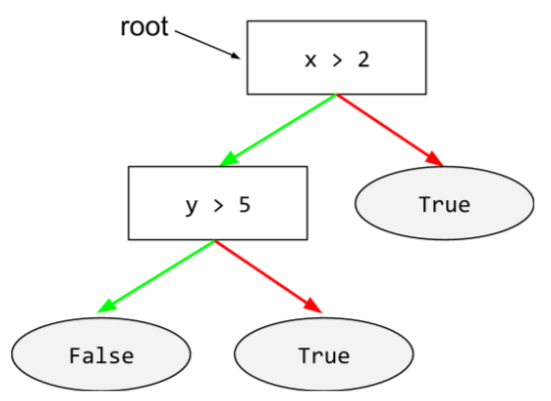
S
próbkowanie z zastąpieniem
Metoda wybierania elementów ze zbioru elementów kandydujących, w którym ten sam element można wybrać kilka razy. Sformułowanie „z zamiennikiem” oznacza, że po każdym zaznaczeniu wybrany element jest zwracany do puli elementów kandydujących. Metoda odwrotna, próbkowanie bez zamiennika, oznacza, że kandydujący element może zostać wybrany tylko raz.
Weźmy na przykład taki zestaw owoców:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Załóżmy, że system losowo wybiera fig jako pierwszy element.
Jeśli stosujesz próbkowanie z zamiennikiem, system wybiera drugi element z tego zbioru:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Tak, jest taka sama jak wcześniej, więc system może ponownie wybrać typ fig.
Jeśli używasz próbkowania bez zastąpienia, po wybraniu próbki nie można wybrać jej ponownie. Jeśli np. system losowo wybierze fig jako pierwszą próbkę, wtedy fig nie będzie można wybrać ponownie. Dlatego system wybiera drugą próbkę z tego (zmniejszonego) zbioru:
fruit = {kiwi, apple, pear, cherry, lime, mango}
kurczenie
Hiperparametr we wzmocnieniu gradientu, który kontroluje nadmierne dopasowanie. Zmniejszenie wzmocnienia gradientu jest analogiczne do szybkości uczenia się w spadku gradientu. Zmniejszanie jest wartością dziesiętną z zakresu od 0,0 do 1,0. Niższa wartość kurczenia ogranicza nadmierne dopasowanie niż większa wartość kurczenia.
podział : fragment
w drzewie decyzji inna nazwa warunku,
podział
Podczas trenowania drzewa decyzyjnego rutyna (i algorytm) odpowiada za znalezienie najlepszego warunku w każdym węźle.
T
test
w drzewie decyzji inna nazwa warunku,
próg (w przypadku drzew decyzyjnych)
Wartość w warunku wyrównania do osi, z którą porównywana jest funkcja. Na przykład 75 to wartość progowa w przypadku tego warunku:
grade >= 75
V
zmienne znaczenia
Zbiór wyników wskazujący względne znaczenie poszczególnych cech dla modelu.
Rozważmy na przykład drzewo decyzji do szacowania cen domów. Załóżmy, że to drzewo decyzyjne ma 3 cechy: rozmiar, wiek i styl. Jeśli zbiór zmiennych znaczenia tych trzech cech obliczymy jako {size=5.8, age=2.5, style=4.7}, rozmiar jest ważniejszy dla drzewa decyzji niż wiek czy styl.
Istnieją różne wskaźniki ważności, które mogą przekazywać ekspertom ML informacje o różnych aspektach modeli.
Ś
mądrość tłumu
koncepcja, że uśrednianie opinii lub szacunków dużej grupy osób („tłum”) często daje zaskakująco dobre wyniki. Weźmy na przykład grę, w której ludzie zgadują, ile galaretki w dużym słoiku. Choć większość przypuszczeń jest niedokładna, średnia wszystkich domysłów jest zaskakująco zbliżona do rzeczywistej liczby galaretek w słoiku.
Ensembles to programowy odpowiednik mądrości tłumu. Nawet wtedy, gdy poszczególne modele generują bardzo niedokładne prognozy, uśrednione prognozy wielu modeli często generują zaskakująco dobre prognozy. Na przykład drzewo decyzji może generować słabe prognozy, ale las decyzji często tworzy bardzo trafne prognozy.