דף זה מכיל מונחי מילון מונחים של וכן 'יערות ההחלטה'. לכל המונחים במילון המונחים, לחצו כאן.
A
דגימת מאפיינים
טקטיקה לאימון יער החלטות שבה כל עץ החלטות מתייחס רק לקבוצת משנה אקראית של תכונות אפשריות ללמידה של התנאי. באופן כללי, מתבצעת דגימה של תת-תכונות שונות לכל צומת. לעומת זאת, כשמאמנים עץ החלטות ללא דגימת מאפיינים, כל התכונות האפשריות נלקחות בחשבון בכל צומת.
תנאי יישור לציר
בעץ החלטות, תנאי שכולל רק תכונה אחת. לדוגמה, אם שטח הוא ישות, התנאי הבא הוא תנאי ליישור ציר:
area > 200
ניגודיות של מצב אלכסוני.
B
הבאג
שיטה לאימון הרכב שבו כל מודל מקיים אימון על קבוצת משנה אקראית של דוגמאות אימון שנדגמו עם החלפה. לדוגמה, יער אקראי הוא אוסף של עצי החלטה שאומן בתיקים.
המונח bagging הוא קיצור של bootstrap aggregat.
תנאי בינארי
בעץ החלטות, תנאי שיש לו רק שתי תוצאות אפשריות, בדרך כלל yes או no. לדוגמה, התנאי הבא הוא תנאי בינארי:
temperature >= 100
ניגודיות עם תנאי לא בינארי.
C
מצב
בעץ החלטות, כל צומת שמעריך ביטוי. לדוגמה, החלק הבא בעץ החלטות מכיל שני תנאים:
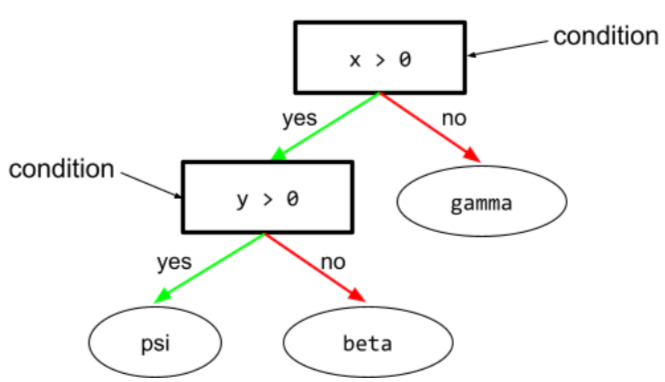
תנאי נקרא גם פיצול או בדיקה.
מצב ניגודיות עם עלה.
לעיונך:
D
החלטה ביער
מודל שנוצר מכמה עצי החלטות. יער החלטות יוצר חיזוי על ידי צבירת התחזיות של עצי ההחלטות שלו. הסוגים הפופולריים של יערות ההחלטה כוללים יערות אקראיים ועצים משודרגים הדרגתיים.
עץ החלטות
מודל של למידה מונחית שמורכב מקבוצה של conditions וconditions שמסודרים בהיררכיה. לדוגמה, הנה עץ החלטות:
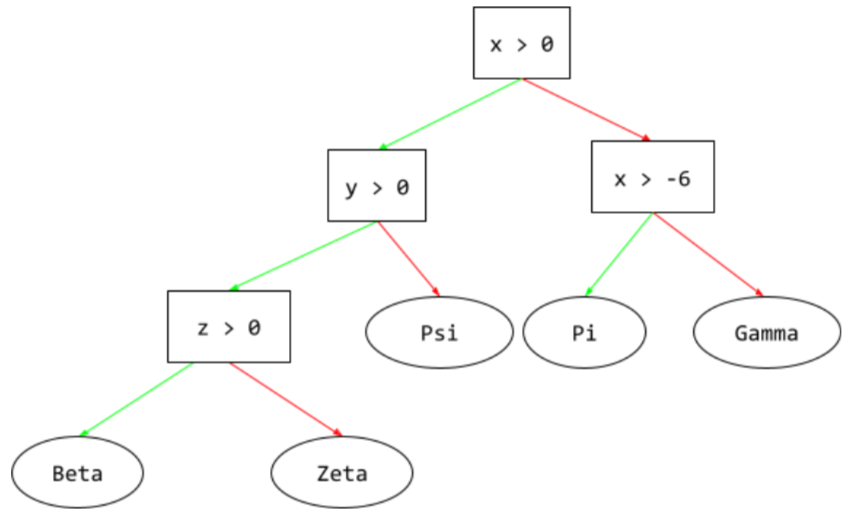
ה.
אנטרופיה
ב תורת המידע, תיאור שמתאר עד כמה לא צפויה התפלגות ההסתברות, לחלופין, האנטרופיה מוגדרת גם ככמות המידע שכל דוגמה מכילה. להתפלגות יש האנטרופיה הגבוהה ביותר האפשרית כאשר לכל הערכים של משתנה אקראי יש סבירות שווה.
האנטרופיה של קבוצה עם שני ערכים אפשריים '0' ו-'1' (לדוגמה, התוויות בבעיה בסיווג בינארי) כוללת את הנוסחה הבאה:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
איפה:
- H היא האנטרופיה.
- p הוא החלק של הדוגמאות "1".
- q הוא החלק היחסי של הדוגמאות "0". חשוב לזכור ש-q = (1 - p)
- log הוא בדרך כלל יומן2. במקרה הזה, יחידת האנטרופיה היא קצת יותר.
לדוגמה, נניח ש:
- 100 דוגמאות מכילות את הערך '1'
- 300 דוגמאות מכילות את הערך "0"
לכן, ערך האנטרופיה הוא:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 ביטים לדוגמה
למערך מאוזן לחלוטין (לדוגמה, 200 "0" ו-200 "1") תהיה אנטרופיה של 1.0 ביט לכל דוגמה. כשקבוצה הופכת ללא מאוזנת, האנטרופיה נעה לכיוון 0.0.
בעצי החלטה, האנטרופיה עוזרת לנסח מידע כדי לעזור למפצל לבחור את התנאים במהלך הצמיחה של עץ החלטות סיווג.
השוואה בין האנטרופיה ל:
- טוהר ג'יני
- פונקציית אובדן cross-entropy
לעיתים קרובות, האנטרופיה נקראת האנטרופיה של שאנון.
נ
חשיבות תכונות
מילה נרדפת לחשיבות משתנה.
G
טושטת ג'יני
מדד דומה ל-אנטרופיה. מפצלים משתמשים בערכים שמקורם בטוהר של ג'יני או מאנטרופיה כדי להרכיב תנאים לסיווג עצי החלטה. רווח מידע נגזר מאנטרופיה. אין מונח מקביל מקובל בכל העולם למדד שנגזר מגיני טומעם. עם זאת, המדד הזה ללא שם חשוב לא פחות מצבירת מידע.
טושטת ג'יני נקראת גם אינדקס ג'יני, או פשוט ג'יני.
עצים מגובבים בהדרגתיות (החלטה) (GBT)
סוג של יער החלטות שבו:
- האימון מתבסס על שיפור הדרגתי.
- המודל החלש הוא עץ החלטות.
שיפור הדרגתי
אלגוריתם אימון שבו מודלים חלשים מאומנים לשפר באופן חזרתי את האיכות (להפחית את האובדן) של מודל חזק. לדוגמה, מודל חלש יכול להיות מודל עץ החלטות לינארי או מודל קטן. המודל החזקה הופך לסכום של כל המודלים החלשים שאומנו קודם לכן.
בצורה הפשוטה ביותר של הגדלה הדרגתית, בכל איטרציה מודל חלש מאומן לחזות את השיפוע האובדן של המודל החזקה. לאחר מכן, הפלט של המודל החזקה מתעדכן על ידי חיסור ההדרגתיות החזויה, בדומה לירידה בהדרגתיות.
איפה:
- $F_{0}$ הוא המודל הטוב ביותר להתחלה.
- $F_{i+1}$ הוא המודל החזקה הבא.
- $F_{i}$ הוא המודל החזקה הנוכחי.
- $\xi$ הוא ערך בין 0.0 ל-1.0 שנקרא כיווץ, שדומה לקצב הלמידה בירידה הדרגתית.
- $f_{i}$ הוא המודל החלש שאומן לחזות את שיפוע האובדן של $F_{i}$.
וריאציות מודרניות של הגדלת ההדרגתיות כוללות גם את הנגזרת השנייה (הסיאנית) של האובדן בחישוב שלהן.
עצי החלטה משמשים בדרך כלל כמודלים חלשים לשיפור הדרגה. ראו עצים עם עלייה הדרגתית (החלטה).
I
נתיב הסקת
בעץ החלטות, במהלך הסקה, המסלול שדוגמה מסוימת לוקחת מהשורש לתנאים אחרים, והוא מסתיים בעלה. לדוגמה, בעץ ההחלטות הבא, החיצים העבים יותר מציגים את נתיב ההסקה לדוגמה עם ערכי התכונות הבאים:
- x = 7
- y = 12
- z = -3
באיור הבא, נתיב ההסקה עובר דרך שלושה תנאים לפני ההגעה לעלות (Zeta).
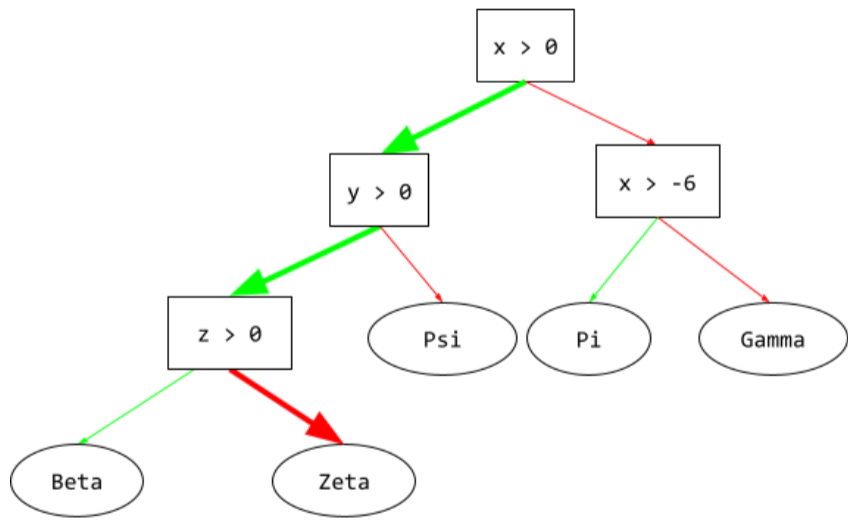
שלושת החיצים העבים מייצגים את נתיב ההסקה.
צבירת מידע
ביערות החלטה, ההפרש בין האנטרופיה של צומת לבין הסכום המשוקלל (לפי מספר דוגמאות) של האנטרופיה של צמתים הצאצאים שלו. האנטרופיה של צומת היא האנטרופיה של הדוגמאות באותו צומת.
לדוגמה, שימו לב לערכי האנטרופיה הבאים:
- האנטרופיה של צומת ההורה = 0.6
- של צומת צאצא אחד עם 16 דוגמאות רלוונטיות = 0.2
- של צומת צאצא אחר עם 24 דוגמאות רלוונטיות = 0.1
כך ש-40% מהדוגמאות נמצאות בצומת צאצא אחד ו-60% נמצאים בצומת הצאצא האחר. לכן:
- סכום האנטרופיה המשוקלל של צמתים צאצאים = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
אם כך, רווח המידע הוא:
- מידע מצטבר = אנטרופיה של צומת הורה - סכום אנטרופיה משוקלל של צמתים צאצאים
- תוספת מידע = 0.6 - 0.14 = 0.46
רוב המפצלים נועדו ליצור תנאים כדי למקסם את איסוף המידע.
תנאי מוגדר
בעץ החלטות, תנאי שבודק אם יש פריט אחד בקבוצה של פריטים. לדוגמה, התנאי הבא הוא תנאי מוגדר:
house-style in [tudor, colonial, cape]
בשלב ההסקה, אם הערך של תכונה בסגנון בית הוא tudor או colonial או cape, התנאי הזה יקבל את הערך 'כן'. אם הערך של התכונה 'סגנון בית' הוא משהו אחר (למשל, ranch), התנאי הזה מקבל את הערך 'לא'
בדרך כלל, תנאי הגדרה מובילים לעצי החלטות יעילים יותר מאשר תנאים שבודקים תכונות של קידוד עם קידוד אחיד.
L
עלה
כל נקודת קצה בעץ ההחלטות. בניגוד לתנאי, עלה לא מבצע בדיקה. במקום זאת, עלה הוא חיזוי אפשרי. עלה הוא גם הצומת הטרמינלי של נתיב ההסקה.
לדוגמה, עץ ההחלטות הבא מכיל שלושה עלים:
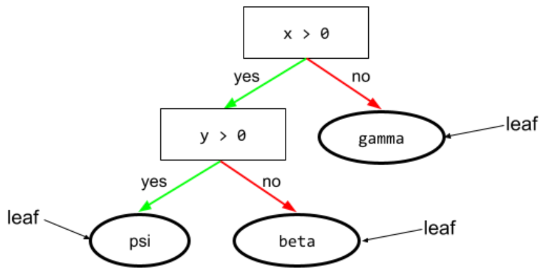
לא
צומת (עץ החלטות)
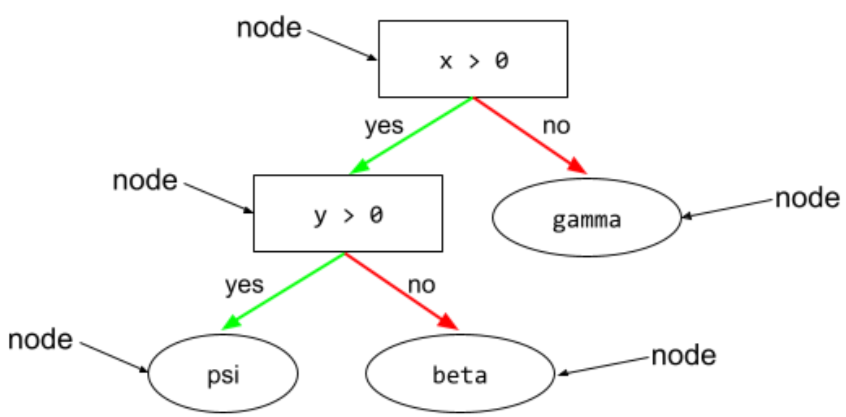
תנאי לא בינארי
מצב שמכיל יותר משתי תוצאות אפשריות. לדוגמה, התנאי הלא-בינארי הבא מכיל שלוש תוצאות אפשריות:
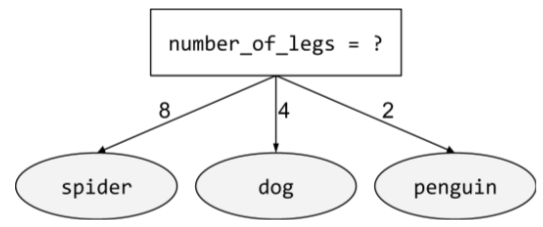
O
מצב עקום
בעץ החלטות, תנאי שכולל יותר מתכונה אחת. לדוגמה, אם גובה ורוחב הם שתי תכונות, התנאי הבא הוא תנאי נטול:
height > width
הניגודיות של תנאי יישור לציר.
הערכה "מחוץ לתיק" (הערכת OOB)
מנגנון להערכת האיכות של יער החלטות על ידי בדיקה של כל עץ החלטות מול הדוגמאות לא שנעשה בהן שימוש במהלך ההדרכה של עץ ההחלטות הזה. לדוגמה, בתרשים הבא, שימו לב שהמערכת מאמנת כל עץ החלטות לפי שני שליש מהדוגמאות, ואז מבצעת הערכה ביחס לשליש הנותרים מהדוגמאות.
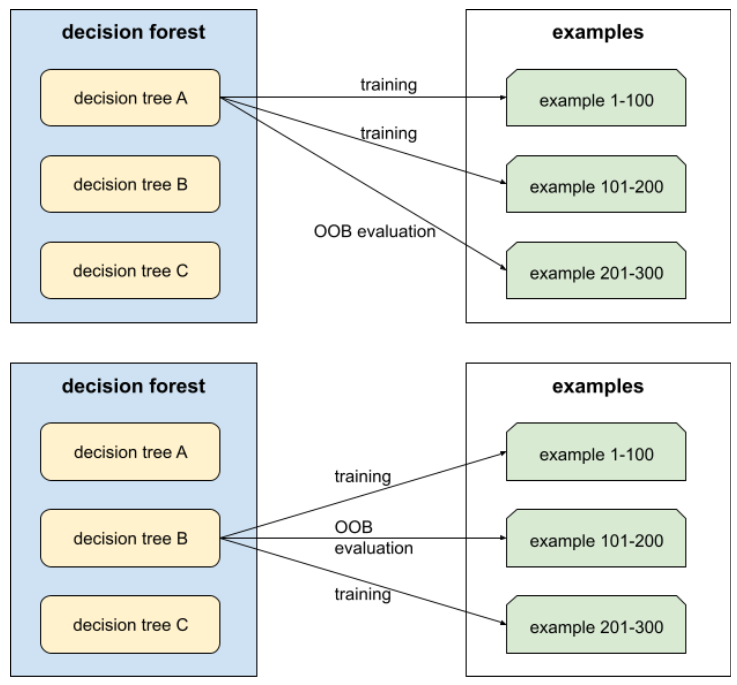
הערכה "מחוץ לתיק" היא הערכה יעילה מבחינה חישובית של מנגנון אימות צולב. בתהליך של אימות צולב, אימון של מודל אחד לכל סבב של אימות צולב (לדוגמה, 10 מודלים עוברים אימון של 10 מודלים של אימות צולב). עם הערכת OOB, מודל יחיד מאומן. מכיוון שקיבוץ נתונים מונע נתונים מסוימים מכל עץ במהלך האימון, הערכת ה-OOB יכולה להשתמש בנתונים האלה כדי להעריך אימות צולב.
P
חשיבות משתנה של תמורה
סוג של חשיבות משתנה שבודק את העלייה בשגיאת החיזוי של מודל אחרי החלפה של ערכי התכונה. חשיבות המשתנה של התמורות היא מדד בלתי תלוי במודל.
R
יער אקראי
מערך של עצי החלטה שבו כל עץ החלטות מאומן בעזרת רעש אקראי ספציפי, כמו bagging.
יערות אקראיים הם סוג של יער החלטות.
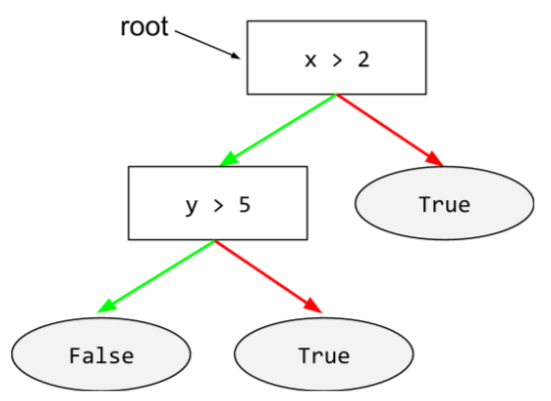
הרמה הבסיסית (root)
הצומת ההתחלתי (התנאי הראשון) בעץ החלטות. לפי המוסכמה, דיאגרמות מציבים את השורש בחלק העליון של עץ ההחלטות. למשל:
S
דגימות עם החלפה
שיטה לבחירת פריטים מתוך קבוצה של פריטים אפשריים שבהם אפשר לבחור את אותו פריט מספר פעמים. המשמעות של הביטוי 'עם החלפה' היא שאחרי כל בחירה, הפריט שנבחר מוחזר למאגר הפריטים האפשריים. בשיטה ההפוכה, דגימה ללא החלפה, אפשר לבחור פריט מועמד רק פעם אחת.
לדוגמה, שקול את ערכת הפירות הבאה:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
נניח שהמערכת בוחרת באקראי את fig כפריט הראשון.
אם משתמשים בדגימה עם החלפה, המערכת בוחרת את הפריט השני מתוך הקבוצה הבאה:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
כן, זו אותה קבוצה כמו קודם, כך שהמערכת עשויה לבחור שוב ב-fig.
אם משתמשים בדגימה ללא החלפה, לאחר שבוחרים דגימה, אי אפשר לבחור אותה שוב. לדוגמה, אם המערכת בוחרת באקראי את fig בתור הדגימה הראשונה, אי אפשר לבחור שוב את fig. לכן, המערכת בוחרת את הדוגמה השנייה מהקבוצה (המוקטנת):
fruit = {kiwi, apple, pear, cherry, lime, mango}
כיווץ
היפר-פרמטר בשיפור הדרגתי שקובע את הוספת יתר. כיווץ השיפור ההדרגתי מקביל לקצב הלמידה בירידה הדרגתית. הכיווץ הוא ערך עשרוני בין 0.0 ל-1.0. ערך הכיווץ נמוך מפחית את התאמת היתר מאשר ערך גדול יותר של הכיווץ.
פיצול
מפצל
בזמן אימון של עץ החלטות, התרחיש (והאלגוריתם) שאחראי למציאת התנאי הטוב ביותר בכל צומת.
T
test
סף (לעצי החלטות)
בתנאי יישור לציר, הערך שאליו מתבצעת השוואה של תכונה. לדוגמה, 75 הוא ערך הסף בתנאי הבא:
grade >= 75
V
חשיבות משתנה
קבוצת ציונים שמציינת את החשיבות היחסית של כל תכונה למודל.
לדוגמה, כדאי לשקול להשתמש בעץ החלטות שמעריך את מחירי הבית. נניח שלעץ ההחלטות הזה יש שלוש תכונות: גודל, גיל וסגנון. במקרה שסדרת חשיבות משתנה של שלוש התכונות מחושבת באופן הבא: {size=5.8, age=2.5, style=4.7}, הגודל חשוב יותר לעץ ההחלטות מאשר גיל או סגנון.
יש מדדים שונים של חשיבות משתנה, שיכולים לעזור למומחי למידת מכונה על היבטים שונים של המודלים.
W
חוכמת ההמונים
לרוב, חישוב הממוצע של הדעות או האומדנים של קבוצה גדולה של אנשים ("הקהל") מניב תוצאות מפתיעות. לדוגמה, חשבו על משחק שבו אנשים מנחשים את מספר הפולים שארוזים בצנצנת גדולה. על אף שרוב הניחושים האישיים לא יהיו מדויקים, הממוצע של כל הניחושים הוכח באופן מפתיע שקרוב באופן מפתיע למספר האמיתי של סוכריות ג'לי בצנצנת.
רכיבים הם תוכנות אנלוגיות של חוכמת הקהל. גם אם מודלים נפרדים מבצעים חיזויים לא מדויקים במיוחד, ממוצע התחזיות של מודלים רבים יוצר בדרך כלל תחזיות טובות באופן מפתיע. לדוגמה, על אף שעץ החלטות מסוים עשוי ליצור תחזיות גרועות, יער החלטות לרוב מניב חיזויים טובים מאוד.