「敵対的生成ネットワーク」という名前の「生成」とはどういう意味ですか?「生成」は、判別モデルとは対照的な統計モデルのクラスを表します。
非公式:
- 生成モデルは新しいデータインスタンスを生成できます。
- 識別モデルは、さまざまな種類のデータインスタンスを区別します。
生成モデルは、本物の動物のように見える動物の新しい写真を生成できますが、識別モデルは犬と猫を区別できます。GAN は生成モデルの一種にすぎません。
より正式には、データ インスタンスのセット X とラベルのセット Y が与えられた場合:
- 生成モデルは、同時確率 p(X, Y) をキャプチャします。ラベルがない場合は、p(X) のみをキャプチャします。
- 識別モデルは、条件付き確率 p(Y | X) をキャプチャします。
生成モデルにはデータ自体の分布が含まれており、特定のサンプルの確率を示します。たとえば、シーケンス内の次の単語を予測するモデルは、単語のシーケンスに確率を割り当てることができるため、通常は生成モデル(通常は GAN よりもはるかに単純)です。
識別モデルは、特定のインスタンスの可能性に関する質問を無視し、ラベルがインスタンスに適用される可能性のみを通知します。
これは非常に一般的な定義です。生成モデルにはさまざまな種類があります。GAN は生成モデルの一種にすぎません。
確率のモデリング
どちらのモデルでも、確率を表す数値を返す必要はありません。分布を模倣することで、データの分布をモデル化できます。
たとえば、分類ツリーなどの識別分類子は、ラベルに確率を割り当てることなくインスタンスにラベルを付けることができます。このような分類子は、予測されたすべてのラベルの分布がデータ内のラベルの実際の分布をモデル化するため、引き続きモデルになります。
同様に、生成モデルは、その分布から抽出されたように見える説得力のある「偽の」データを生成することで、分布をモデル化できます。
生成モデルは難しい
生成モデルは、類似の識別モデルよりも難しいタスクに取り組んでいます。生成モデルはより多くのモデル化を行う必要があります。
画像の生成モデルは、「船に見えるものは水に見えるものの近くに現れる可能性が高い」や「額に目が現れる可能性は低い」などの相関関係を捉えることができます。これらは非常に複雑な分布です。
一方、識別モデルは、いくつかの特徴的なパターンを探すだけで、「ヨット」と「ヨット以外」の違いを学習できます。生成モデルが正しく把握する必要がある相関関係の多くを無視する可能性があります。
識別モデルはデータ空間に境界を描画しようとしますが、生成モデルは空間全体にデータが配置される方法をモデル化しようとします。たとえば、次の図は、手書きの数字の識別モデルと生成モデルを示しています。
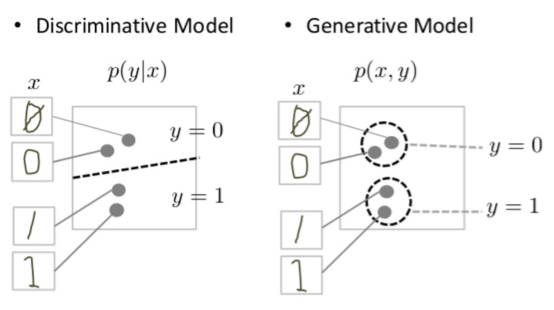
図 1: 手書きの数字の識別モデルと生成モデル。
識別モデルは、データ空間に線を引くことで、手書きの 0 と 1 の違いを判別しようとします。線が正しく分類されると、インスタンスが線の両側のデータ空間のどこに配置されているかを正確にモデリングしなくても、0 と 1 を区別できます。
一方、生成モデルは、データ空間内の実際の数字に近い数字を生成することで、説得力のある 1 と 0 を生成しようとします。データ空間全体に分布をモデル化する必要があります。
GAN は、このような豊富なモデルを実際の分布に似せてトレーニングする効果的な方法を提供します。仕組みを理解するには、GAN の基本構造を理解する必要があります。
理解度チェック: 生成モデルと識別モデル
- 6 面サイコロを 3 個振る。
- ロールに定数 w を乗算します。
- これを 100 回繰り返して、すべての結果の平均をとります。