지도 학습의 태스크는 잘 정의되어 있으며 스팸 식별이나 강수량 예측과 같은 다양한 시나리오에 적용할 수 있습니다.
지도 학습의 기본 개념
감독 머신러닝은 다음과 같은 핵심 개념을 기반으로 합니다.
- 데이터
- 모델
- 학습
- 평가
- 추론
데이터
데이터는 ML의 원동력입니다. 데이터는 테이블에 저장된 단어와 숫자의 형식 또는 이미지와 오디오 파일에 캡처된 픽셀과 웨이브폼의 값으로 제공됩니다. Google에서는 관련 데이터를 데이터 세트에 저장합니다. 예를 들어 다음과 같은 데이터 세트가 있을 수 있습니다.
- 고양이 이미지
- 주택 가격
- 날씨 정보
데이터 세트는 특성과 라벨이 포함된 개별 예시로 구성됩니다. 이 예시는 스프레드시트의 단일 행과 유사하다고 생각할 수 있습니다. 특성은 감독 모델이 라벨을 예측하는 데 사용하는 값입니다. 라벨은 '답변' 또는 모델이 예측할 값입니다. 강우량을 예측하는 날씨 모델에서 지형지물은 위도, 경도, 온도, 습도, 운량, 풍향, 기압일 수 있습니다. 라벨은 강수량입니다.
특성과 라벨이 모두 포함된 예시를 라벨이 지정된 예시라고 합니다.
라벨이 지정된 두 가지 예

반면 라벨이 지정되지 않은 예에는 특징은 있지만 라벨은 없습니다. 모델을 만든 후 모델은 특성에서 라벨을 예측합니다.
라벨이 없는 예시 2개
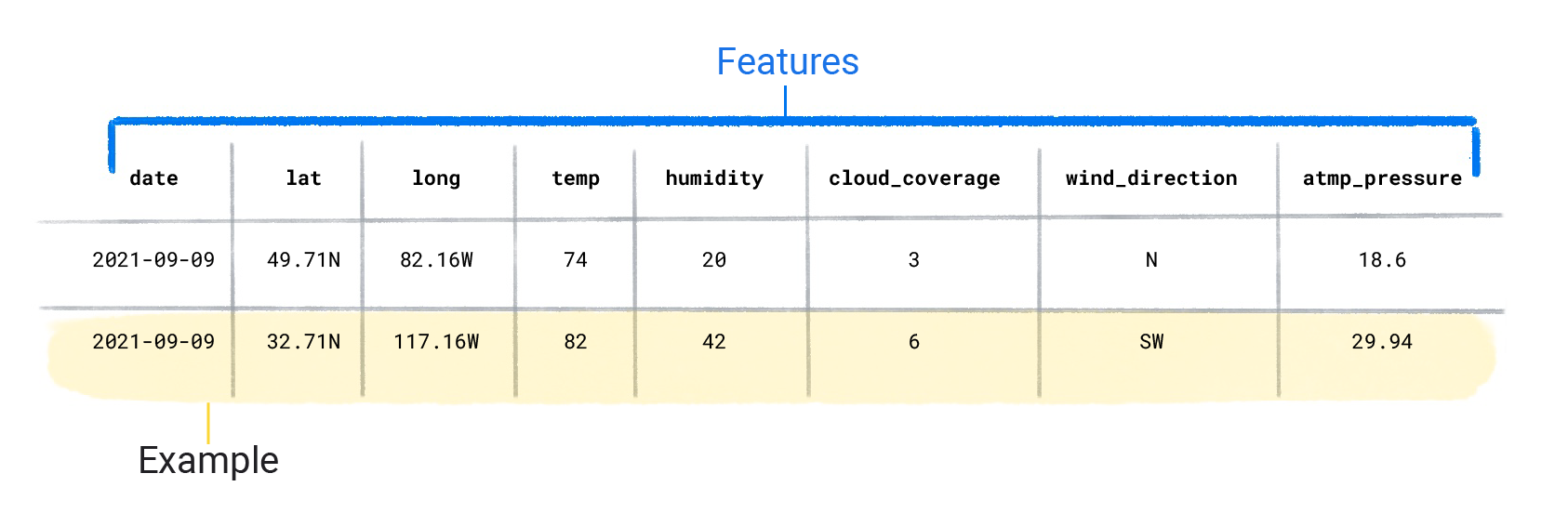
데이터 세트 특성
데이터 세트는 크기와 다양성으로 구분됩니다. 크기는 예시 수를 나타냅니다. 다양성은 이러한 예시가 다루는 범위를 나타냅니다. 좋은 데이터 세트는 규모가 크고 다양합니다.
데이터 세트는 크고 다양하거나 크지만 다양하지 않거나 작지만 매우 다양할 수 있습니다. 즉, 대규모 데이터 세트는 충분한 다양성을 보장하지 않으며, 다양성이 매우 높은 데이터 세트는 충분한 예시를 보장하지 않습니다.
예를 들어 데이터 세트에 100년 동안의 데이터가 포함되어 있지만 7월에 대한 데이터만 포함되어 있을 수 있습니다. 이 데이터 세트를 사용하여 1월의 강우량을 예측하면 좋지 않은 예측이 나옵니다. 반대로 데이터 세트는 몇 년 동안만 적용되지만 매월 포함될 수 있습니다. 이 데이터 세트는 변동성을 고려하기에 충분한 연도가 포함되어 있지 않으므로 예측이 좋지 않을 수 있습니다.
이해도 확인
데이터 세트는 지형지물의 개수로 특성화할 수도 있습니다. 예를 들어 일부 날씨 데이터 세트에는 위성 이미지부터 구름 덮음 값에 이르기까지 수백 개의 지형지물이 포함될 수 있습니다. 다른 데이터 세트에는 습도, 기압, 온도와 같은 3~4개의 지형지물만 포함될 수 있습니다. 기능이 더 많은 데이터 세트를 사용하면 모델이 추가 패턴을 발견하고 더 정확하게 예측할 수 있습니다. 하지만 특성이 더 많은 데이터 세트가 더 나은 예측을 하는 모델을 생성하는 것은 항상 그런 것은 아닙니다. 일부 특성은 라벨과 인과 관계가 없을 수 있기 때문입니다.
모델
지도 학습에서 모델은 특정 입력 특성 패턴에서 특정 출력 라벨 값으로의 수학적 관계를 정의하는 복잡한 숫자 모음입니다. 모델은 학습을 통해 이러한 패턴을 발견합니다.
학습
감독 모델이 예측을 수행하려면 먼저 학습이 이루어져야 합니다. 모델을 학습시키려면 라벨이 지정된 예시가 포함된 데이터 세트를 모델에 제공합니다. 모델의 목표는 특성에서 라벨을 예측하는 데 가장 적합한 솔루션을 찾는 것입니다. 모델은 예측 값을 라벨의 실제 값과 비교하여 최적의 솔루션을 찾습니다. 예측 값과 실제 값의 차이(손실로 정의됨)를 기반으로 모델은 솔루션을 점진적으로 업데이트합니다. 즉, 모델은 특성과 라벨 간의 수학적 관계를 학습하여, 보지 않은 데이터에 대해 가장 정확한 예측을 할 수 있습니다.
예를 들어 모델이 비가 1.15 inches일 것이라고 예측했지만 실제 값은 .75 inches이면 모델은 예측이 .75 inches에 더 가까워지도록 솔루션을 수정합니다. 모델이 데이터 세트의 각 예시를 살펴본 후(경우에 따라 여러 번) 각 예시를 평균적으로 가장 잘 예측하는 솔루션에 도달합니다.
다음은 모델 학습을 보여줍니다.
모델은 단일 라벨이 지정된 예시를 입력받고 예측을 제공합니다.
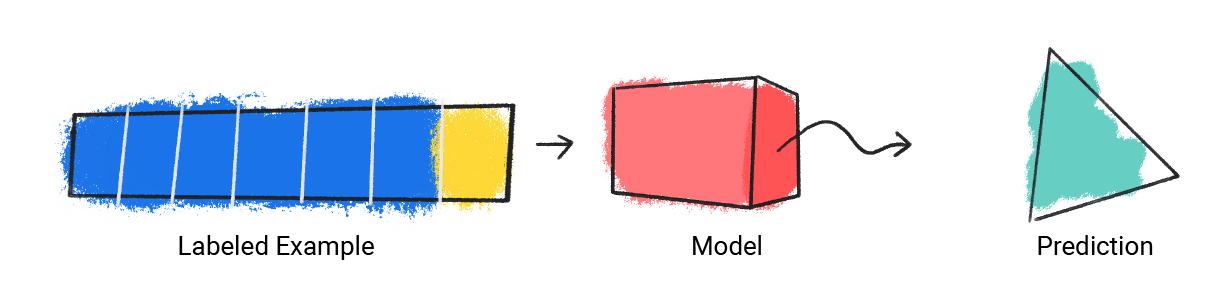
그림 1. 라벨이 지정된 예시에서 예측을 수행하는 ML 모델
모델은 예측 값을 실제 값과 비교하고 솔루션을 업데이트합니다.
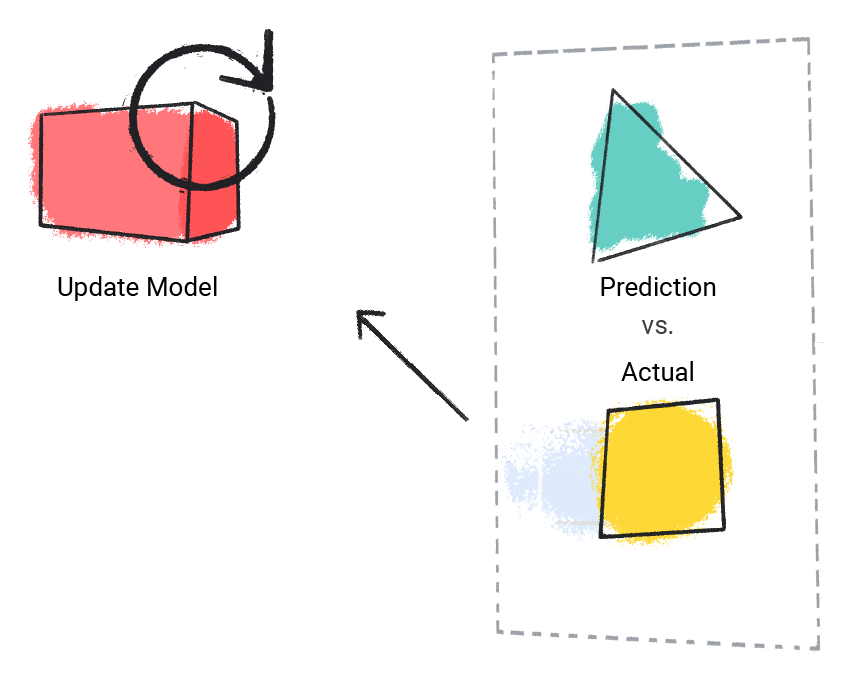
그림 2. 예측 값을 업데이트하는 ML 모델
모델은 데이터 세트의 라벨이 지정된 각 예시에서 이 프로세스를 반복합니다.
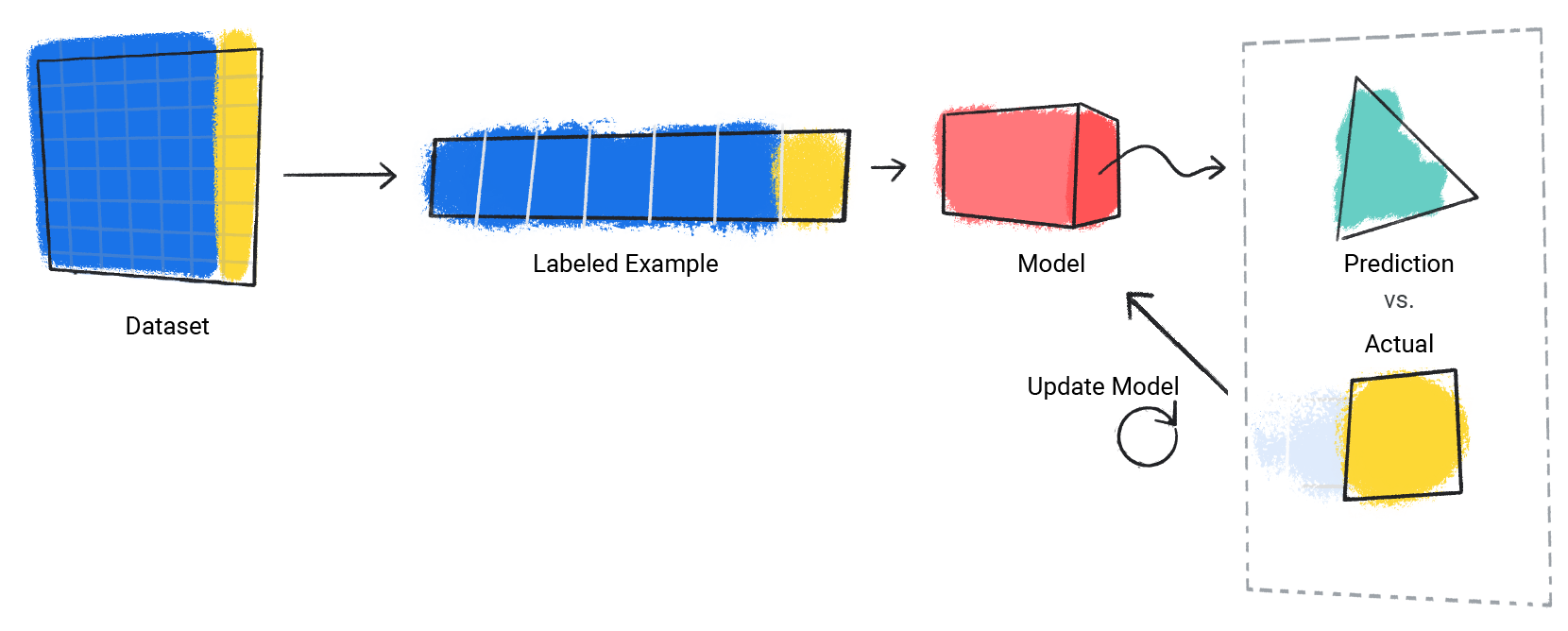
그림 3. 학습 데이터 세트의 라벨이 지정된 각 예시의 예측을 업데이트하는 ML 모델입니다.
이렇게 하면 모델이 특성과 라벨 간의 올바른 관계를 점차 학습합니다. 이러한 점진적인 이해는 대규모의 다양한 데이터 세트가 더 나은 모델을 생성하는 이유이기도 합니다. 모델은 더 다양한 값을 가진 더 많은 데이터를 확인했으며 특성과 라벨 간의 관계에 대한 이해를 개선했습니다.
학습 중에 ML 전문가는 모델이 예측하는 데 사용하는 구성과 기능을 미세하게 조정할 수 있습니다. 예를 들어 특정 기능은 다른 기능보다 예측력이 더 높습니다. 따라서 ML 전문가는 학습 중에 모델이 사용하는 특성을 선택할 수 있습니다. 예를 들어 날씨 데이터 세트에time_of_day가 지형지물로 포함되어 있다고 가정해 보겠습니다. 이 경우 ML 전문가는 학습 중에 time_of_day를 추가하거나 삭제하여 모델이 time_of_day 유무와 관계없이 더 나은 예측을 하는지 확인할 수 있습니다.
평가
학습된 모델을 평가하여 학습 정도를 확인합니다. 모델을 평가할 때는 라벨이 지정된 데이터 세트를 사용하지만 모델에는 데이터 세트의 특성만 제공합니다. 그런 다음 모델의 예측을 라벨의 실제 값과 비교합니다.
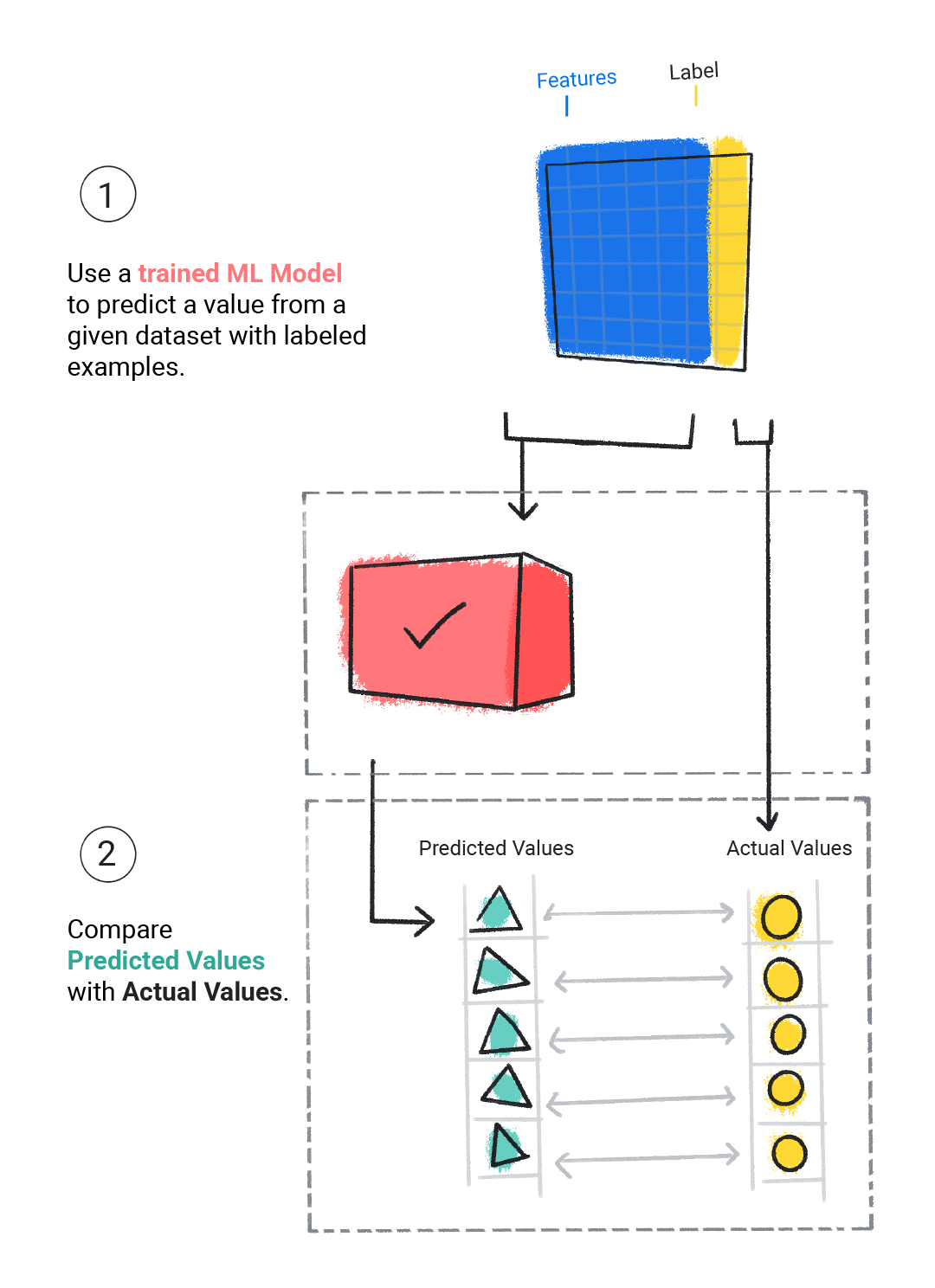
그림 4. 예측을 실제 값과 비교하여 ML 모델을 평가합니다.
모델의 예측에 따라 실제 애플리케이션에 모델을 배포하기 전에 더 많은 학습과 평가를 진행할 수 있습니다.
이해도 확인
추론
모델 평가 결과가 만족스러우면 모델을 사용하여 라벨이 없는 예시에서 추론이라고 하는 예측을 할 수 있습니다. 날씨 앱 예시에서는 모델에 온도, 기압, 상대 습도와 같은 현재 날씨 상태를 제공하면 모델이 강우량을 예측합니다.