
Podczas tworzenia złącza społecznościowego każde pole zdefiniowane w schemacie wymaga typu danych. Typ danych określa typ podstawowy pola, np. BOOLEAN, STRING, NUMBER itp.
Oprócz typów danych Looker Studio korzysta też z typów semantycznych.
Typy semantyczne pomagają opisywać rodzaj informacji, które reprezentują dane. Na przykład pole z NUMBER może semantycznie reprezentować kwotę w walucie lub wartość procentową, a pole z STRING może semantycznie reprezentować miasto. Aby sprawdzić, które typy semantyczne są dostępne, zapoznaj się z dokumentacją typów semantycznych.
Schemat oprogramowania sprzęgającego społecznościowego i pola Looker Studio
Podczas definiowania schematu oprogramowania sprzęgającego społecznościowego dla każdego pola możesz określić różne właściwości, które będą decydować o tym, jak pole jest reprezentowane i używane w Looker Studio. Na przykład:
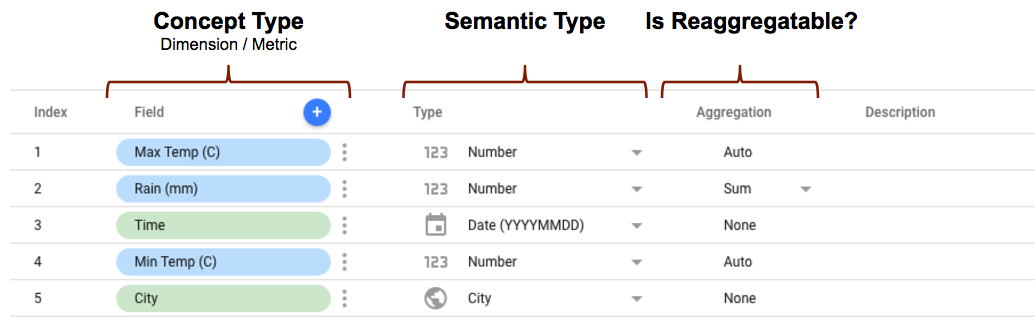
- Typ conceptType jest zdefiniowany w schemacie łącznika za pomocą właściwości
conceptType. Ta właściwość określa, czy pole jest traktowane jako wymiar czy rodzaj danych. Wyjaśnienie różnicy między danymi a wymiarami znajdziesz w artykule Wymiary i dane. - Typ semantyczny może być zdefiniowany w schemacie łącznika lub automatycznie wykrywany przez Looker Studio na podstawie właściwości typu danych zdefiniowanej w łączniku oraz wartości danych zwracanych przez łącznik. Więcej informacji o tym, jak to działa, znajdziesz w artykule Automatyczne wykrywanie typu semantycznego.
- Rodzaj grupowania określa, czy wartości danych (wymiary są ignorowane) można ponownie zgrupować. Ustawienie właściwości
semantics.isReaggregatablenatruespowoduje domyślne ustawienie agregacjiSUM, w przeciwnym razie zostanie ona ustawiona naAuto. Możesz też ręcznie ustawić domyślny rodzaj grupowania dla pól, które można ponownie grupować, za pomocą właściwościdefaultAggregationType.
Gdy skonfigurujesz połączenie za pomocą łącznika w Looker Studio, w edytorze pól zobaczysz pełny schemat łącznika na podstawie zdefiniowanych powyżej właściwości. Jeśli uwzględnisz typy semantyczne, będą one wyświetlane zgodnie z Twoimi ustawieniami. Jeśli używasz automatycznego wykrywania typu semantycznego, pola będą wyświetlane tak, jak zostały wykryte.
Ustawianie informacji semantycznych
Informacje semantyczne można ustawić na 2 sposoby. Semantykę pól możesz ustawić ręcznie lub polegać na automatycznym wykrywaniu przez Looker Studio.
Jeśli na przykład masz liczbę, która semantycznie reprezentuje dolary amerykańskie, Looker Studio nie będzie w stanie automatycznie wykryć tego typu semantycznego. Automatyczne wykrywanie semantyczne wymaga też, aby Looker Studio wykonywało wywołania pobierania danych dla każdego pola schematu. Jeśli zamiast tego ręcznie określisz schemat, nie zostaną wykonane żadne wywołania pobierania danych. Jeśli znasz typ semantyczny danych (np. waluta, procent, data itp.), zalecamy jego wyraźne ustawienie w schemacie ze względu na dokładność i wydajność.
Ręczne ustawianie typów semantycznych (zalecane)
Jeśli znasz typy semantyczne, możesz ręcznie zdefiniować semantics dla każdego pola schematu. Szczegółowe informacje o dostępnych właściwościach znajdziesz na stronie z informacjami o polach. Jeśli zdecydujesz się zdefiniować ręczne typy semantyczne, zalecamy zdefiniowanie semanticType i semanticGroup dla każdego pola. Jeśli podasz te właściwości ręcznie, automatyczne wykrywanie typu semantycznego nie zostanie uruchomione. Jeśli ręcznie ustawisz niektóre pola, ale nie wszystkie, te, których nie określisz, będą miały domyślnie wartość Text, Number lub Boolean w zależności od wartości dataType określonej dla pola.
Poniżej znajdziesz przykład prostego schematu, w którym ręcznie ustawiono typy semantyczne. Income jest ustawiony jako waluta, a Filing Year jako data.
Rozwiązywanie problemów z ręcznymi typami semantycznymi
Jeśli ustawisz nieprawidłowe typy semantyczne dla danych źródłowych, nie będą one działać prawidłowo. Może to być trudne do sprawdzenia, ale możesz wykonać kilka czynności, które pomogą Ci znaleźć problemy.
- Zamiast wszystkich danych zwróć 2 lub 3 wiersze, a następnie sprawdź je ręcznie.
- Utwórz w Looker Studio tabelę, która będzie zawierać tylko pole, które chcesz sprawdzić.
- Zwróć szczególną uwagę na pola
GeoiDate, ponieważ mają one najbardziej rygorystyczny format.
Automatyczne wykrywanie typu semantycznego
Jeśli w schemacie nie zdefiniowano żadnych typów semantycznych, Looker Studio spróbuje wykryć je automatycznie na podstawie właściwości typu danych i formatu wartości danych zwracanych przez łącznik.
Proces automatycznego wykrywania przebiega w ten sposób:
- Poproś o schemat, wykonując funkcję
getSchemaw ramach łącznika społeczności. - Iteruj po partiach pól zdefiniowanych w schemacie oprogramowania sprzęgającego i wysyłaj żądania
getDatadotyczące tych pól. ŻądaniagetDatasą wykonywane z parametremsampleExtractionustawionym natrue, co oznacza, że żądania danych służą do wykrywania semantycznego. - Na podstawie typu danych pola i formatu wartości zwróconej z żądania
getDataokreśl typ semantyczny pola.
Opcje obsługi automatycznego wykrywania typu semantycznego
Gdy Looker Studio wykonuje funkcję getData społecznościowego oprogramowania sprzęgającego na potrzeby wykrywania semantycznego, przychodzące żądanie zawiera właściwość sampleExtraction, która jest ustawiona na true. Dane zwracane przez oprogramowanie sprzęgające są używane przez Looker Studio tylko do określania typu semantycznego pola. Wartość nie będzie używana do żadnych innych celów, więc nie wymaga rzeczywistych danych ze źródła zewnętrznego.
Istnieje kilka sposobów na poprawę wykrywania typu semantycznego w kodzie:
Zalecane: przekazywanie wstępnie zdefiniowanych wartości
Zwróć wstępnie zdefiniowaną wartość dla każdego pola, która najlepiej reprezentuje typ semantyczny pola i jest prawidłowo wykrywana przez Looker Studio. Jeśli np. typ semantyczny pola to Country, zwróć wartość taką jakITw przypadku Włoch. Kolejną zaletą tego podejścia jest to, że jest ono znacznie szybsze, ponieważ nie wymaga wysyłania żądań HTTP do usługi innej firmy w celu uzyskania danych.Zwracaj tylko n rekordów
Jeśli usługa innej firmy, z której pobierasz dane, obsługuje limity wierszy podczas wysyłania żądań danych, zwracaj do Looker Studio mały podzbiór wierszy zamiast pełnego zbioru danych. Ograniczy to ilość danych, które musisz przekazywać do Looker Studio w przypadku każdego żądania wykrywania semantycznego.Żądaj wszystkich kolumn i buforuj odpowiedź
Jeśli można zażądać wszystkich kolumn usługi zewnętrznej, z której pobierasz dane, to w przypadku pierwszego żądania wykrywania semantycznego otrzymanego ze Studia Looker pobierz wszystkie kolumny i zapisz wyniki w pamięci podręcznej. W przypadku kolejnych żądań wykrywania semantycznego pobieraj wartości kolumn z pamięci podręcznej zamiast wysyłać dodatkowe żądania HTTP do usługi innej firmy.Nie rób niczego innego
Możesz zrezygnować z wdrażania konkretnych rozwiązań w przypadku żądań, w których parametrsampleExtractionma wartośćtrue. Spowoduje to spowolnienie procesu wykrywania semantycznego, ponieważ Looker Studio będzie musiało pobrać wszystkie dane na potrzeby tego procesu. Wpłynie to też na częstotliwość wysyłania żądań do zewnętrznego źródła danych, ponieważ wiele żądań wykrywania semantycznego będzie wykonywanych równolegle.
Rozpoznawane formaty automatycznego wykrywania typu semantycznego
Data i godzina
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Czas: epoka w przypadku sekund, mikrosekund, milisekund i nanosekund.
Geo
- Nazwa lub kod kontynentu
- Nazwa lub kod subkontynentu
- Nazwa lub kod regionu
- Nazwa lub kod kraju. Zobacz też ISO_3166-1.
- Nazwa miasta
- Wartość szerokości i długości geograficznej rozdzielona przecinkami
- Nazwa i kod rynku docelowego (DMA)