
כשיוצרים מחבר לקהילה, צריך להגדיר סוג נתונים לכל שדה בסכימה. סוג הנתונים מגדיר את הסוג הפרימיטיבי של השדה, כמו BOOLEAN, STRING, NUMBER וכו'.
בנוסף לסוגי נתונים, Looker Studio משתמש גם בסוגים סמנטיים.
סוגים סמנטיים עוזרים לתאר את סוג המידע שהנתונים מייצגים. לדוגמה, שדה עם סוג הנתונים NUMBER יכול לייצג סכום כספי או אחוז, ושדה עם סוג הנתונים STRING יכול לייצג עיר. כדי לראות אילו סוגים סמנטיים זמינים, אפשר לעיין בתיעוד של הסוגים הסמנטיים.
סכימה של פלאגין חיבור למקור נתונים ושדות ב-Looker Studio
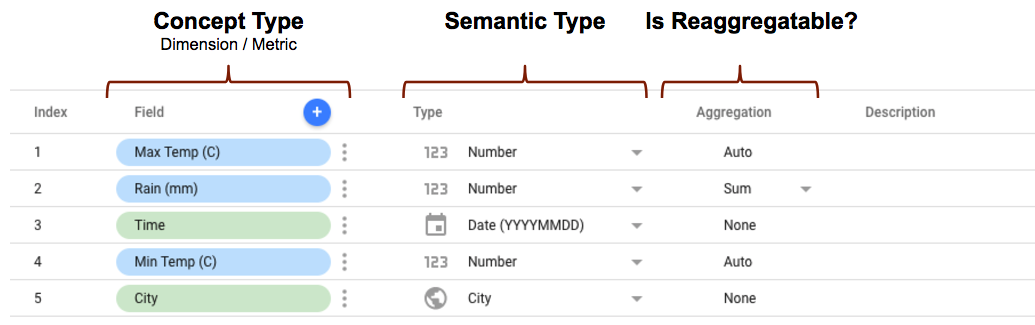
כשמגדירים את הסכימה של מחבר הקהילה, יש מאפיינים שונים לכל שדה שקובעים איך השדה יוצג וישמש ב-Looker Studio. לדוגמה:
- המאפיין conceptType מוגדר בסכימת המחבר באמצעות המאפיין
conceptType. המאפיין הזה קובע אם השדה מטופל כמאפיין או כמדד. הסבר על ההבדל בין מדדים למאפיינים מופיע במאמר מאפיינים ומדדים. - אפשר להגדיר את הסוג הסמנטי בסכימת המחבר, או שמערכת Looker Studio יכולה לזהות אותו באופן אוטומטי על סמך מאפיין סוג הנתונים שהוגדר במחבר וערכי הנתונים שמוחזרים על ידי המחבר. פרטים נוספים על אופן הפעולה של התכונה זמינים במאמר בנושא זיהוי אוטומטי של סוגים סמנטיים.
- סוג הצבירה קובע אם אפשר לצבור מחדש את ערכי המדדים (המערכת מתעלמת מהמאפיינים). אם מגדירים את המאפיין
semantics.isReaggregatableכ-true, ברירת המחדל היא צבירה שלSUM, אחרת המאפיין מוגדר כ-Auto. אפשר גם להגדיר ידנית את סוג הצבירה שמוגדר כברירת מחדל לשדות שאפשר לחשב מצטבר באמצעות המאפייןdefaultAggregationType.
כשמגדירים ומתחברים באמצעות מחבר ב-Looker Studio, בשדה העריכה מוצגת הסכימה המלאה של המחבר על סמך האופן שבו הגדרתם את המאפיינים שלמעלה. אם כללתם את הסוגים הסמנטיים, הם יוצגו כמו שהגדרתם אותם. אם אתם משתמשים בזיהוי אוטומטי של סוגים סמנטיים, השדות יופיעו כמו שהם זוהו.
הגדרת מידע סמנטי
יש שתי דרכים להגדיר מידע סמנטי. אתם יכולים להגדיר את הסמנטיקה של השדות באופן ידני או להסתמך על Looker Studio שיזהה אותה באופן אוטומטי.
לדוגמה, אם יש לכם מספר שמייצג סמנטית דולר ארה"ב, Looker Studio לא יוכל לזהות אוטומטית את הסוג הסמנטי הזה. בנוסף, כדי שהמערכת תוכל לבצע זיהוי סמנטי אוטומטי, Looker Studio צריך לבצע קריאות לאחזור נתונים לכל שדה בסכימה. אם מציינים את הסכימה באופן ידני, לא יתבצעו קריאות לשליפת נתונים. אם אתם יודעים מה הסוג הסמנטי של הנתונים (למשל, מטבע, אחוז, תאריך וכו'), מומלץ להגדיר אותו באופן מפורש בסכימה כדי לשפר את הדיוק והביצועים.
הגדרה ידנית של סוגים סמנטיים (מומלץ)
אם אתם יודעים מהם הסוגים הסמנטיים, אתם יכולים להגדיר באופן ידני את semantics לכל שדה סכימה. פרטים מלאים על המאפיינים שזמינים לכם מופיעים בדף העזר בנושא שדות. אם בוחרים להגדיר סוגים סמנטיים באופן ידני, מומלץ להגדיר את semanticType ואת semanticGroup לכל שדה. אם תספקו את המאפיינים האלה באופן ידני, תהליך הזיהוי האוטומטי של סוגים סמנטיים לא יפעל. אם מגדירים חלק מהשדות באופן ידני, אבל לא את כולם, השדות שלא צוינו יקבלו את ערך ברירת המחדל Text, Number או Boolean, בהתאם לערך dataType שצוין בשדה.
הדוגמה הבאה היא של סכימה פשוטה שבה סוגים סמנטיים מוגדרים באופן ידני. Income מוגדר כמטבע ו-Filing Year מוגדר כתאריך.
פתרון בעיות שקשורות לסוגים סמנטיים ידניים
אם מגדירים את הסוגים הסמנטיים בצורה שגויה עבור הנתונים הבסיסיים, הם לא יפעלו כמו שצריך. יכול להיות שיהיה קשה לבדוק את זה, אבל יש כמה דברים שאפשר לעשות כדי לנסות למצוא בעיות.
- להחזיר 2 או 3 שורות מהנתונים במקום את כל הנתונים, ואז לבדוק אותם באופן ידני.
- יוצרים ב-Looker Studio טבלה שמשתמשת רק בשדה שרוצים לבדוק.
- חשוב לשים לב לשדות
Geoו-Dateכי הפורמט שלהם הכי מחמיר.
זיהוי אוטומטי של סוגים סמנטיים
אם לא הגדרתם סוגים סמנטיים בסכימה, מערכת Looker Studio תנסה לזהות אותם באופן אוטומטי על סמך מאפיין סוג הנתונים והפורמט של ערכי הנתונים שמוחזרים על ידי המחבר.
אלה השלבים בתהליך הזיהוי האוטומטי:
- כדי לבקש את הסכימה, מריצים את הפונקציה
getSchemaשל מחבר הקהילה. - מבצעים איטרציה על קבוצות של שדות שמוגדרים בסכימת המחבר ושולחים בקשות
getDataלשדות. הבקשותgetDataמבוצעות עם הפרמטרsampleExtractionשמוגדר לערךtrueכדי לציין שהבקשות לנתונים מיועדות לזיהוי סמנטי. - על סמך סוג הנתונים של השדה והפורמט של הערך שמוחזר מהבקשה
getData, מזהים את הסוג הסמנטי של השדה.
אפשרויות לטיפול בזיהוי אוטומטי של סוגים סמנטיים
כש-Looker Studio מפעיל את הפונקציה getData של מחבר קהילתי לצורך זיהוי סמנטי, הבקשה הנכנסת תכיל את המאפיין sampleExtraction שיוגדר לערך true. הנתונים שמוחזרים על ידי המחבר משמשים את Looker Studio רק כדי לזהות את הסוג הסמנטי של השדה. הערך לא ישמש לשום מטרה אחרת, ולכן לא נדרשים נתונים בפועל מהמקור החיצוני.
יש כמה דרכים לשפר את הזיהוי של סוגים סמנטיים בקוד:
מומלץ: העברת ערכים מוגדרים מראש
החזרת ערך מוגדר מראש לכל שדה שמייצג בצורה הטובה ביותר את הסוג הסמנטי של השדה, ושמזוהה בצורה תקינה על ידי Looker Studio. לדוגמה, אם הסוג הסמנטי של שדה הוא Country, הפונקציה תחזיר ערך כמוITעבור איטליה. יתרון נוסף של הגישה הזו הוא שהיא מהירה יותר, כי לא צריך לשלוח בקשות HTTP לשירות של צד שלישי כדי לקבל נתונים.Return only n number of records
אם שירות הצד השלישי שממנו אתם מאחזרים נתונים תומך בהגבלת מספר השורות כשמבקשים נתונים, אפשר להחזיר קבוצת משנה קטנה של שורות ל-Looker Studio במקום מערך הנתונים המלא. כך תצטרכו להעביר ל-Looker Studio פחות נתונים לכל בקשה לזיהוי סמנטי.שליחת בקשה לכל העמודות ושמירת התגובה במטמון
אם אפשר לשלוח בקשה לכל העמודות בשירות הצד השלישי שממנו מאחזרים נתונים, אז בבקשת הזיהוי הסמנטי הראשונה שמתקבלת מ-Looker Studio, מאחזרים את כל העמודות ושומרים את התוצאות במטמון. בבקשות הבאות לזיהוי סמנטי, המערכת מאחזרת את ערכי העמודות מהמטמון במקום לשלוח בקשות HTTP נוספות לשירות של הצד השלישי.לא לבצע שינוי
אתם יכולים לבחור שלא להטמיע התאמות ספציפיות לבקשות שבהן הערך שלsampleExtractionהואtrue. הפעולה הזו תגרום לתהליך של זיהוי סמנטי להיות איטי יותר, כי Looker Studio יצטרך לאחזר את כל הנתונים לתהליך הזה. בנוסף, זה ישפיע על קצב הבקשות למקור הנתונים החיצוני, כי הרבה בקשות לזיהוי סמנטי יבוצעו במקביל.
פורמטים מוכרים לזיהוי אוטומטי של סוגים סמנטיים
תאריך ושעה
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- זמן: תקופת זמן המערכת בשניות, במיקרו-שניות, באלפיות השנייה ובננו-שניות.
Geo
- שם או קוד של יבשת
- שם או קוד של תת-יבשת
- שם או קוד של אזור
- שם המדינה או הקוד שלה. אפשר גם לעיין בISO_3166-1.
- שם העיר
- ערך של קו רוחב וקו אורך מופרדים בפסיקים
- השם והקוד של אזור שוק ייעודי (DMA)