
Lorsque vous créez un connecteur de communauté, chaque champ que vous définissez dans le schéma nécessite un type de données. Le type de données définit le type primitif du champ, tel que BOOLEAN, STRING, NUMBER, etc.
En plus des types de données, Looker Studio utilise également des types sémantiques.
Les types sémantiques permettent de décrire le type d'informations que représentent les données. Par exemple, un champ avec un type de données NUMBER peut représenter sémantiquement un montant ou un pourcentage de devise, et un champ avec un type de données STRING peut représenter sémantiquement une ville. Pour connaître les types sémantiques disponibles, veuillez consulter la documentation sur les types sémantiques.
Schéma du connecteur de la communauté et champs Looker Studio
Lorsque vous définissez le schéma de votre connecteur de communauté, chaque champ comporte différentes propriétés qui déterminent la façon dont il est représenté et utilisé dans Looker Studio. Exemple :
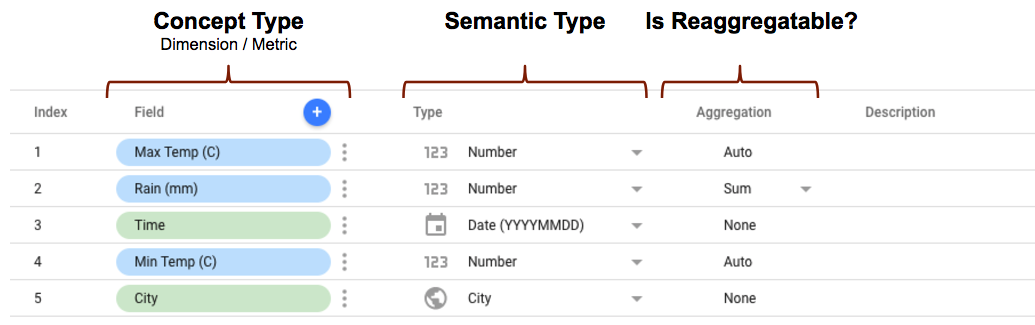
- Le conceptType est défini dans le schéma de votre connecteur à l'aide de la propriété
conceptType. Cette propriété détermine si le champ est traité comme une dimension ou une métrique. Pour en savoir plus sur la différence entre les métriques et les dimensions, consultez Dimensions et métriques. - Le type sémantique peut être défini dans le schéma du connecteur ou être détecté automatiquement par Looker Studio en fonction de la propriété type de données définie dans votre connecteur et des valeurs de données renvoyées par votre connecteur. Pour en savoir plus sur le fonctionnement de cette fonctionnalité, consultez Détection automatique des types sémantiques.
- Le type d'agrégation détermine si les valeurs de métrique (les dimensions sont ignorées) peuvent être réagrégées. Si vous définissez la propriété
semantics.isReaggregatablesurtrue, l'agrégationSUMest utilisée par défaut. Sinon, la propriété est définie surAuto. Vous pouvez également définir manuellement le type d'agrégation par défaut pour les champs réagrégables à l'aide de la propriétédefaultAggregationType.
Lorsque vous configurez et connectez un connecteur dans Looker Studio, l'éditeur de champs affiche le schéma complet du connecteur en fonction de la façon dont vous avez défini les propriétés ci-dessus. Si vous avez inclus les types sémantiques, ils s'afficheront tels que vous les avez définis. Si vous utilisez la détection automatique du type sémantique, les champs s'affichent tels qu'ils ont été détectés.
Définir des informations sémantiques
Il existe deux façons de définir des informations sémantiques. Vous pouvez définir la sémantique des champs manuellement ou laisser Looker Studio la détecter automatiquement.
Par exemple, si vous avez un nombre qui représente sémantiquement des dollars américains, Looker Studio ne pourra pas détecter automatiquement ce type sémantique. De plus, la détection sémantique automatique nécessite que Looker Studio effectue des appels de récupération de données pour chaque champ de votre schéma. Si vous spécifiez manuellement le schéma, aucun appel de récupération de données ne sera effectué. Si vous connaissez le type sémantique de vos données (par exemple, devise, pourcentage, date, etc.), nous vous recommandons de le définir explicitement dans le schéma pour des raisons d'exactitude et de performances.
Définir manuellement les types sémantiques (recommandé)
Si vous connaissez vos types sémantiques, vous pouvez définir manuellement semantics pour chaque champ de schéma. Pour en savoir plus sur les propriétés disponibles, consultez la page de référence des champs. Si vous choisissez de définir des types sémantiques manuels, nous vous recommandons de définir semanticType et semanticGroup pour chaque champ. Si vous fournissez manuellement ces propriétés, le processus de détection automatique du type sémantique ne s'exécutera pas. Si vous définissez manuellement certains de vos champs, mais pas tous, ceux que vous ne spécifiez pas sont définis par défaut sur Text, Number ou Boolean, selon le dataType spécifié pour le champ.
Voici un exemple de schéma simple qui définit manuellement les types sémantiques. Income est défini comme une devise et Filing Year comme une date.
Résoudre les problèmes liés aux types sémantiques manuels
Si vous définissez incorrectement vos types sémantiques pour les données sous-jacentes, ils ne fonctionneront pas correctement. Il peut être difficile de tester cela, mais vous pouvez faire plusieurs choses pour identifier les problèmes.
- Renvoie deux ou trois lignes de vos données au lieu de toutes, puis examinez-les manuellement.
- Créez un tableau dans Looker Studio qui n'utilise que le champ que vous essayez de vérifier.
- Portez une attention particulière aux champs
GeoetDate, car ils sont soumis au format le plus strict.
Détection automatique du type sémantique
Si vous n'avez défini aucun type sémantique dans votre schéma, Looker Studio tentera de les détecter automatiquement en fonction de la propriété type de données et du format des valeurs de données renvoyées par votre connecteur.
Voici les étapes du processus de détection automatique :
- Demandez le schéma en exécutant la fonction
getSchemade votre connecteur de communauté. - Parcourez les lots de champs définis dans le schéma du connecteur et émettez des requêtes
getDatapour les champs. Les requêtesgetDatasont exécutées avec le paramètresampleExtractiondéfini surtruepour indiquer que les demandes de données sont destinées à la détection sémantique. - En fonction du type de données du champ et du format de la valeur renvoyée par la requête
getData, identifiez le type sémantique du champ.
Options pour gérer la détection automatique des types sémantiques
Lorsque Looker Studio exécute la fonction getData d'un connecteur de communauté à des fins de détection sémantique, la requête entrante contient une propriété sampleExtraction définie sur true. Les données renvoyées par votre connecteur ne sont utilisées par Looker Studio que pour identifier le type sémantique du champ. Comme la valeur ne sera utilisée à aucune autre fin, elle ne nécessite pas de données réelles provenant de votre source externe.
Il existe plusieurs façons d'améliorer la détection des types sémantiques dans votre code :
Recommandation : Transmettez des valeurs prédéfinies
Retournez une valeur prédéfinie pour chaque champ qui représente le mieux le type sémantique du champ et qui est connu pour être correctement détecté par Looker Studio. Par exemple, si le type sémantique d'un champ est Pays, renvoyez une valeur telle queITpour l'Italie. L'autre avantage de cette approche est qu'elle est beaucoup plus rapide, car elle ne vous oblige pas à envoyer de requêtes HTTP au service tiers pour obtenir des données.Ne renvoyer que n enregistrements
Si le service tiers à partir duquel vous récupérez des données accepte les limites de lignes lorsque vous demandez des données, renvoyez un petit sous-ensemble de lignes à Looker Studio au lieu de l'ensemble de données complet. Cela limitera la quantité de données que vous devrez transmettre à Looker Studio pour chaque demande de détection sémantique.Demander toutes les colonnes et mettre en cache la réponse
Si vous pouvez demander toutes les colonnes pour le service tiers à partir duquel vous récupérez des données, récupérez toutes les colonnes et mettez en cache les résultats lors de la première demande de détection sémantique reçue de Looker Studio. Pour les requêtes de détection sémantique ultérieures, les valeurs de colonne sont extraites du cache au lieu d'envoyer des requêtes HTTP supplémentaires au service tiers.Ne rien faire de particulier
Vous pouvez choisir de ne pas mettre en œuvre d'adaptation spécifique pour les requêtes oùsampleExtractionest défini surtrue. Le processus de détection sémantique sera alors plus lent, car Looker Studio devra extraire toutes les données pour ce processus. De plus, cela affectera le taux de requêtes envoyées à votre source de données externe, car de nombreuses requêtes de détection sémantique seront exécutées en parallèle.
Formats reconnus pour la détection automatique des types sémantiques
Date et heure
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Heure : epoch pour les secondes, microsecondes, millisecondes et nanosecondes.
Données géographiques
- Nom ou code du continent
- Nom ou code du sous-continent
- Nom ou code de la région
- Nom ou code du pays. Voir aussi ISO_3166-1.
- Nom de la ville
- Valeur de latitude et de longitude séparées par une virgule
- Nom et code de la zone de marché désignée (DMA)