
Wenn Sie einen Community Connector erstellen, ist für jedes Feld, das Sie im Schema definieren, ein Datentyp erforderlich. Der Datentyp definiert den primitiven Typ des Felds, z. B. BOOLEAN, STRING oder NUMBER.
Neben Datentypen werden in Looker Studio auch semantische Typen verwendet.
Semantische Typen helfen, die Art der Informationen zu beschreiben, die die Daten darstellen. Ein Feld mit dem Datentyp NUMBER kann beispielsweise semantisch einen Währungsbetrag oder einen Prozentsatz darstellen und ein Feld mit dem Datentyp STRING kann semantisch eine Stadt darstellen. Informationen zu den verfügbaren semantischen Typen finden Sie in der Dokumentation zu semantischen Typen.
Community Connector-Schema und Looker Studio-Felder
Wenn Sie das Schema für Ihren Community-Connector definieren, gibt es verschiedene Eigenschaften für jedes Feld, die bestimmen, wie das Feld in Looker Studio dargestellt und verwendet wird. Beispiel:
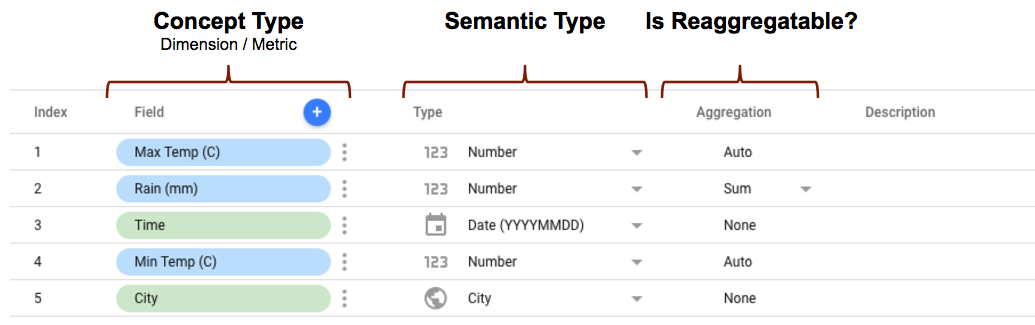
- Der conceptType wird in Ihrem Connectorschema mit dem Attribut
conceptTypedefiniert. Mit dieser Eigenschaft wird festgelegt, ob das Feld als Dimension oder Messwert behandelt wird. Eine Erklärung zum Unterschied zwischen Messwerten und Dimensionen finden Sie unter Dimensionen und Messwerte. - Der semantische Typ kann entweder im Connector-Schema definiert oder von Looker Studio automatisch anhand des Attributs Datentyp, das in Ihrem Connector definiert ist, und der von Ihrem Connector zurückgegebenen Datenwerte erkannt werden. Weitere Informationen zur Funktionsweise finden Sie unter Automatische Erkennung semantischer Typen.
- Der Zusammenfassungstyp bestimmt, ob die Messwerte (Dimensionen werden ignoriert) neu zusammengefasst werden können. Wenn die Eigenschaft
semantics.isReaggregatableauftruegesetzt ist, wird standardmäßig die AggregationSUMverwendet. Andernfalls wird sie aufAutogesetzt. Sie können den Standardaggregationstyp für Felder, die neu aggregiert werden können, auch manuell mit der EigenschaftdefaultAggregationTypefestlegen.
Wenn Sie einen Connector in Looker Studio konfigurieren und eine Verbindung damit herstellen, wird im Feldeditor das vollständige Schema für den Connector angezeigt, das auf den oben definierten Attributen basiert. Wenn Sie die semantischen Typen angegeben haben, werden sie so angezeigt, wie Sie sie definiert haben. Wenn Sie die automatische Erkennung semantischer Typen verwenden, werden die Felder so angezeigt, wie sie erkannt wurden.
Semantische Informationen festlegen
Es gibt zwei Möglichkeiten, semantische Informationen festzulegen. Sie können die Semantik von Feldern entweder manuell festlegen oder Looker Studio die automatische Erkennung überlassen.
Wenn Sie beispielsweise eine Zahl haben, die semantisch US-Dollar darstellt, kann Looker Studio diesen semantischen Typ nicht automatisch erkennen. Außerdem muss Looker Studio für die automatische semantische Erkennung Datenabrufe für jedes Feld Ihres Schemas ausführen. Wenn Sie das Schema stattdessen manuell angeben, werden keine Datenabrufaufrufe ausgeführt. Wenn Sie den semantischen Typ Ihrer Daten kennen (z. B. Währung, Prozent, Datum), empfehlen wir, ihn aus Gründen der Genauigkeit und Leistung explizit im Schema festzulegen.
Semantische Typen manuell festlegen (empfohlen)
Wenn Sie Ihre semantischen Typen kennen, können Sie semantics für jedes Schemefeld manuell definieren. Hier finden Sie eine vollständige Liste der verfügbaren Eigenschaften. Wenn Sie manuelle semantische Typen definieren, sollten Sie für jedes Feld semanticType und semanticGroup definieren. Wenn Sie diese Eigenschaften manuell angeben, wird die automatische Erkennung semantischer Typen nicht ausgeführt. Wenn Sie einige Ihrer Felder manuell festlegen, aber nicht alle, werden die Felder, die Sie nicht angeben, standardmäßig auf Text, Number oder Boolean festgelegt, je nach dataType, die für das Feld angegeben ist.
Das folgende Beispiel zeigt ein einfaches Schema, in dem semantische Typen manuell festgelegt werden. Income ist als Währung und Filing Year als Datum festgelegt.
Fehlerbehebung bei manuellen semantischen Typen
Wenn Sie die semantischen Typen für die zugrunde liegenden Daten falsch festlegen, funktionieren sie nicht richtig. Das kann schwierig zu testen sein, aber es gibt einige Dinge, die Sie tun können, um Probleme zu finden.
- Geben Sie nur zwei oder drei Zeilen Ihrer Daten zurück und sehen Sie sie sich dann manuell an.
- Erstellen Sie in Looker Studio eine Tabelle, in der nur das Feld verwendet wird, das Sie prüfen möchten.
- Achten Sie besonders auf die Felder
GeoundDate, da sie das strengste Format haben.
Automatische Erkennung des semantischen Typs
Wenn Sie in Ihrem Schema keine semantischen Typen definiert haben, versucht Looker Studio, sie automatisch anhand der Eigenschaft Datentyp und des Formats der von Ihrem Connector zurückgegebenen Datenwerte zu erkennen.
Der automatische Erkennungsprozess umfasst die folgenden Schritte:
- Fordern Sie das Schema an, indem Sie die Funktion
getSchemaIhres Community-Connectors ausführen. - Durchlaufen Sie Batches von Feldern, die im Connector-Schema definiert sind, und senden Sie
getData-Anfragen für die Felder. DiegetData-Anfragen werden mit dem ParametersampleExtractionausgeführt, der auftruegesetzt ist, um anzugeben, dass die Datenanfragen für die semantische Erkennung bestimmt sind. - Ermitteln Sie anhand des Datentyps des Felds und des Formats des von der
getData-Anfrage zurückgegebenen Werts den semantischen Typ des Felds.
Optionen für die automatische Erkennung semantischer Typen
Wenn Looker Studio die getData-Funktion eines Community-Connectors zur semantischen Erkennung ausführt, enthält die eingehende Anfrage das Attribut sampleExtraction, das auf true gesetzt ist. Die von Ihrem Connector zurückgegebenen Daten werden nur von Looker Studio verwendet, um den semantischen Typ des Felds zu ermitteln. Da der Wert nicht für andere Zwecke verwendet wird, sind keine tatsächlichen Daten aus Ihrer externen Quelle erforderlich.
Es gibt mehrere Möglichkeiten, die Erkennung semantischer Typen in Ihrem Code zu verbessern:
Empfohlen: Vordefinierte Werte übergeben
Geben Sie für jedes Feld einen vordefinierten Wert zurück, der den semantischen Typ des Felds am besten repräsentiert und von Looker Studio richtig erkannt wird. Wenn der semantische Typ für ein Feld beispielsweise Land ist, geben Sie einen Wert wieITfür Italien zurück. Ein weiterer Vorteil dieses Ansatzes ist, dass er viel schneller ist, da Sie keine HTTP-Anfragen an den Drittanbieterdienst für Daten senden müssen.Nur n Datensätze zurückgeben
Wenn der Drittanbieterdienst, aus dem Sie Daten abrufen, Zeilenlimits beim Anfordern von Daten unterstützt, geben Sie an Looker Studio nur eine kleine Teilmenge von Zeilen anstelle des vollständigen Datasets zurück. Dadurch wird die Datenmenge begrenzt, die Sie für jede Anfrage zur semantischen Erkennung an Looker Studio übergeben müssen.Alle Spalten anfordern und Antwort im Cache speichern
Wenn es möglich ist, alle Spalten für den Drittanbieterdienst abzurufen, von dem Sie Daten abrufen, rufen Sie bei der ersten semantischen Erkennungsanfrage, die von Looker Studio empfangen wird, alle Spalten ab und speichern Sie die Ergebnisse im Cache. Bei nachfolgenden semantischen Erkennungsanfragen werden Spaltenwerte aus dem Cache abgerufen, anstatt zusätzliche HTTP-Anfragen an den Drittanbieterdienst zu senden.Nichts ändern
Sie können Anfragen, bei denensampleExtractionauftruegesetzt ist, unverändert lassen. Dadurch wird die semantische Erkennung verlangsamt, da Looker Studio alle Daten für diesen Prozess abrufen muss. Außerdem wirkt sich dies auf die Anfragerate an Ihre externe Datenquelle aus, da viele semantische Erkennungsanfragen parallel ausgeführt werden.
Erkannte Formate für die automatische Erkennung semantischer Typen
Datum und Uhrzeit
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- Zeit: Epoche für Sekunde, Mikrosekunde, Millisekunde und Nanosekunde.
Geo
- Name oder Code des Kontinents
- Name oder Code des Subkontinents
- Name oder Code der Region
- Name oder Code des Landes Siehe auch ISO_3166-1.
- City Name (Ort)
- Durch Komma getrennter Breiten- und Längengrad
- Name und Code der DMA (Designated Marketing Area)