
कम्यूनिटी कनेक्टर बनाते समय, स्कीमा में तय किए गए हर फ़ील्ड के लिए, डेटा टाइप की ज़रूरत होती है. डेटा टाइप, फ़ील्ड के प्रिमिटिव टाइप को तय करता है. जैसे, BOOLEAN, STRING, NUMBER वगैरह.
डेटा टाइप के अलावा, Data Studio सिमैंटिक टाइप का भी इस्तेमाल करता है.
सिमैंटिक टाइप से यह पता चलता है कि डेटा किस तरह की जानकारी दिखाता है. उदाहरण के लिए, NUMBER डेटा टाइप वाला फ़ील्ड, सिमैंटिक तौर पर मुद्रा की रकम या प्रतिशत को दिखा सकता है. वहीं, STRING डेटा टाइप वाला फ़ील्ड, सिमैंटिक तौर पर किसी शहर को दिखा सकता है. कौनसे सिमैंटिक टाइप उपलब्ध हैं, यह देखने के लिए कृपया सिमैंटिक टाइप का दस्तावेज़ देखें
कम्यूनिटी कनेक्टर का स्कीमा और Data Studio के फ़ील्ड
अपने कम्यूनिटी कनेक्टर के लिए स्कीमा तय करते समय, हर फ़ील्ड के लिए अलग-अलग प्रॉपर्टी होती हैं. इनसे यह तय होता है कि Data Studio में फ़ील्ड को कैसे दिखाया जाएगा और उसका इस्तेमाल कैसे किया जाएगा. उदाहरण के लिए:
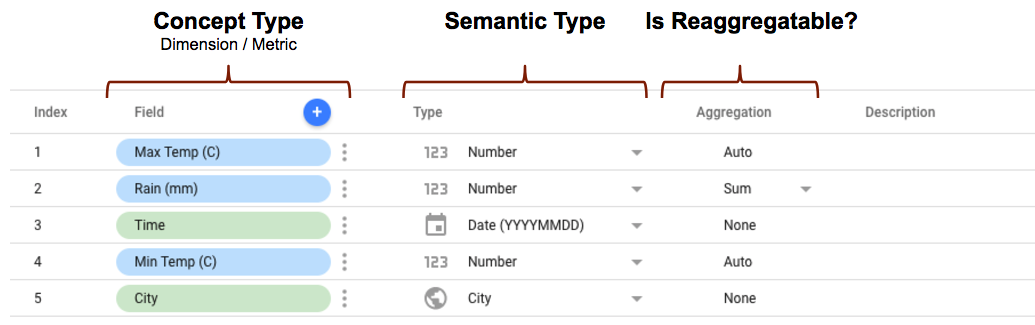
- conceptType को
conceptTypeप्रॉपर्टी का इस्तेमाल करके, कनेक्टर स्कीमा में तय किया जाता है. इस प्रॉपर्टी से यह तय होता है कि फ़ील्ड को डाइमेंशन के तौर पर माना जाए या मेट्रिक के तौर पर. मेट्रिक और डाइमेंशन के बीच अंतर के बारे में जानकारी यहां दी गई है: डाइमेंशन और मेट्रिक. - सिमैंटिक टाइप को कनेक्टर स्कीमा में तय किया जा सकता है. इसके अलावा, Data Studio इसे अपने-आप भी पहचान सकता है. ऐसा, कनेक्टर में तय की गई डेटा टाइप प्रॉपर्टी और कनेक्टर से मिली डेटा वैल्यू के आधार पर होता है. यह सुविधा कैसे काम करती है, इस बारे में जानने के लिए सिमैंटिक टाइप का अपने-आप पता लगाने की सुविधा लेख पढ़ें.
- एग्रीगेशन टाइप से यह तय होता है कि मेट्रिक वैल्यू (डाइमेंशन को अनदेखा किया जाता है) को फिर से एग्रीगेट किया जा सकता है या नहीं.
semantics.isReaggregatableप्रॉपर्टी कोtrueपर सेट करने पर, डिफ़ॉल्ट रूप सेSUMएग्रीगेशन लागू होगा. ऐसा न करने पर, इसेAutoपर सेट किया जाएगा.defaultAggregationTypeप्रॉपर्टी का इस्तेमाल करके, रीएग्रीगेट किए जा सकने वाले फ़ील्ड के लिए डिफ़ॉल्ट एग्रीगेशन टाइप को मैन्युअल तरीके से भी सेट किया जा सकता है.
Data Studio में किसी कनेक्टर का इस्तेमाल करके कॉन्फ़िगर और कनेक्ट करने पर, फ़ील्ड एडिटर, कनेक्टर का पूरा स्कीमा दिखाता है. यह स्कीमा, ऊपर बताई गई प्रॉपर्टी के आधार पर तय होता है. अगर आपने सिमैंटिक टाइप शामिल किए हैं, तो वे आपकी तय की गई सेटिंग के हिसाब से दिखेंगे. अगर सिमैंटिक टाइप का अपने-आप पता लगाने की सुविधा का इस्तेमाल किया जा रहा है, तो फ़ील्ड वैसे ही दिखेंगे जैसे उनका पता लगाया गया था.
सिमेंटिक जानकारी सेट करना
सिमैंटिक जानकारी सेट करने के दो तरीके हैं. फ़ील्ड के सिमैंटिक को मैन्युअल तरीके से सेट किया जा सकता है. इसके अलावा, Data Studio को अपने-आप इसका पता लगाने दिया जा सकता है.
उदाहरण के लिए, अगर आपके पास कोई ऐसा नंबर है जो सेमैंटिक तौर पर अमेरिकी डॉलर को दिखाता है, तो Data Studio इस सेमैंटिक टाइप का अपने-आप पता नहीं लगा पाएगा. इसके अलावा, अपने-आप सिमैंटिक का पता लगाने की सुविधा के लिए, Data Studio को आपके स्कीमा के हर फ़ील्ड के लिए डेटा फ़ेच करने के अनुरोध करने होते हैं. अगर आपने स्कीमा को मैन्युअल तरीके से तय किया है, तो डेटा फ़ेच करने के लिए कोई कॉल नहीं किया जाएगा. अगर आपको अपने डेटा के लिए सिमैंटिक टाइप (जैसे, मुद्रा, प्रतिशत, तारीख वगैरह) के बारे में पता है, तो हम सुझाव देते हैं कि आप इसे स्कीमा में साफ़ तौर पर सेट करें. इससे, सटीक जानकारी मिलती है और परफ़ॉर्मेंस बेहतर होती है.
सिमैंटिक टाइप को मैन्युअल तरीके से सेट करना (सुझाया गया)
अगर आपको अपने सिमैंटिक टाइप के बारे में पता है, तो हर स्कीमा फ़ील्ड के लिए मैन्युअल तरीके से semantics तय किया जा सकता है. आपको कौनसी प्रॉपर्टी उपलब्ध हैं, इसकी पूरी जानकारी फ़ील्ड रेफ़रंस पेज पर मिलेगी. अगर आपको मैन्युअल तरीके से सिमैंटिक टाइप तय करने हैं, तो हमारा सुझाव है कि आप हर फ़ील्ड के लिए semanticType और semanticGroup तय करें. इन प्रॉपर्टी को मैन्युअल तरीके से उपलब्ध कराने पर, सिमैंटिक टाइप का अपने-आप पता लगाने की प्रोसेस नहीं चलेगी. अगर आपने कुछ फ़ील्ड को मैन्युअल तरीके से सेट किया है, लेकिन सभी को नहीं, तो जिन फ़ील्ड को आपने सेट नहीं किया है वे Text, Number या Boolean पर डिफ़ॉल्ट रूप से सेट हो जाएंगे. यह इस बात पर निर्भर करता है कि फ़ील्ड के लिए dataType क्या तय किया गया है.
यहां एक सामान्य स्कीमा का उदाहरण दिया गया है. इसमें सिमैंटिक टाइप को मैन्युअल तरीके से सेट किया गया है. Income को मुद्रा के तौर पर और Filing Year को तारीख के तौर पर सेट किया गया है.
मैन्युअल सिमैंटिक टाइप से जुड़ी समस्याओं को हल करना
अगर आपने डेटा के लिए सेमैंटिक टाइप गलत तरीके से सेट किए हैं, तो वे ठीक से काम नहीं करेंगे. इसकी जांच करना मुश्किल हो सकता है. हालांकि, समस्याओं का पता लगाने के लिए, यहां दिए गए कुछ तरीके आज़माए जा सकते हैं.
- अपने डेटा की सभी पंक्तियों के बजाय, सिर्फ़ दो या तीन पंक्तियां दिखाएं. इसके बाद, उनकी मैन्युअल तरीके से जांच करें.
- Data Studio में एक ऐसी टेबल बनाएं जिसमें सिर्फ़ उस फ़ील्ड का इस्तेमाल किया गया हो जिसकी आपको जांच करनी है.
GeoऔरDateफ़ील्ड पर खास ध्यान दें, क्योंकि इनका फ़ॉर्मैट सबसे ज़्यादा सख्त होता है.
सिमैंटिक टाइप का अपने-आप पता लगाने की सुविधा
अगर आपने अपने स्कीमा में कोई सिमैंटिक टाइप तय नहीं किया है, तो Data Studio उन्हें अपने-आप पता लगाने की कोशिश करेगा. ऐसा डेटा टाइप प्रॉपर्टी और आपके कनेक्टर से मिली डेटा वैल्यू के फ़ॉर्मैट के आधार पर किया जाएगा.
अपने-आप पता लगाने की प्रोसेस के चरण यहां दिए गए हैं:
- अपने कम्यूनिटी कनेक्टर के
getSchemaफ़ंक्शन को लागू करके, स्कीमा का अनुरोध करें. - कनेक्टर स्कीमा में तय किए गए फ़ील्ड के बैच को दोहराता है और फ़ील्ड के लिए
getDataअनुरोध जारी करता है.getDataअनुरोधों कोsampleExtractionपैरामीटर के साथtrueपर सेट करके लागू किया जाता है. इससे यह पता चलता है कि डेटा के अनुरोध, सिमैंटिक डिटेक्शन के मकसद से किए गए हैं. - फ़ील्ड के डेटा टाइप और
getDataअनुरोध से मिली वैल्यू के फ़ॉर्मैट के आधार पर, फ़ील्ड के सिमैंटिक टाइप की पहचान करें.
सिमैंटिक टाइप का अपने-आप पता लगाने की सुविधा को मैनेज करने के विकल्प
जब Data Studio, सिमैंटिक डिटेक्शन के लिए कम्यूनिटी कनेक्टर के getData फ़ंक्शन को लागू करता है, तो आने वाले अनुरोध में sampleExtraction प्रॉपर्टी शामिल होगी. इसे true पर सेट किया जाएगा. आपके कनेक्टर से मिले डेटा का इस्तेमाल, Data Studio सिर्फ़ फ़ील्ड के सिमैंटिक टाइप की पहचान करने के लिए करता है. इस वैल्यू का इस्तेमाल किसी अन्य मकसद के लिए नहीं किया जाएगा. इसलिए, इसके लिए आपके बाहरी सोर्स से मिले असल डेटा की ज़रूरत नहीं है.
अपने कोड में सिमैंटिक टाइप का पता लगाने की सुविधा को बेहतर बनाने के कई तरीके हैं:
सुझाया गया: पहले से तय की गई वैल्यू पास करें
हर फ़ील्ड के लिए, पहले से तय की गई ऐसी वैल्यू दिखाएं जो फ़ील्ड के सिमैंटिक टाइप को सबसे सही तरीके से दिखाती हो. साथ ही, Data Studio को इस वैल्यू का पता हो. उदाहरण के लिए, अगर किसी फ़ील्ड का सिमैंटिक टाइप Country है, तो इटली के लिएITजैसी वैल्यू दिखाएं. इस तरीके का एक और फ़ायदा यह है कि यह बहुत तेज़ी से काम करता है. ऐसा इसलिए, क्योंकि इसके लिए आपको तीसरे पक्ष की सेवा को डेटा के लिए एचटीटीपी अनुरोध करने की ज़रूरत नहीं होती.सिर्फ़ n रिकॉर्ड दिखाएं
अगर डेटा का अनुरोध करते समय, तीसरे पक्ष की सेवा पंक्तियों की सीमा तय करने की सुविधा देती है, तो पूरे डेटा सेट के बजाय, Data Studio को पंक्तियों का छोटा सबसेट दिखाएं. इससे, हर सिमैंटिक डिटेक्शन अनुरोध के लिए, Data Studio को पास किए जाने वाले डेटा की मात्रा सीमित हो जाएगी.सभी कॉलम के लिए अनुरोध करें और जवाब को कैश मेमोरी में सेव करें
अगर डेटा फ़ेच करने के लिए इस्तेमाल की जा रही तीसरे पक्ष की सेवा के सभी कॉलम के लिए अनुरोध किया जा सकता है, तो Data Studio से मिले पहले सिमैंटिक डिटेक्शन अनुरोध पर सभी कॉलम फ़ेच करें और नतीजों को कैश मेमोरी में सेव करें. इसके बाद, सिमैंटिक डिटेक्शन के अनुरोधों के लिए, तीसरे पक्ष की सेवा को अतिरिक्त एचटीटीपी अनुरोध भेजने के बजाय, कैश मेमोरी से कॉलम की वैल्यू फ़ेच करें.कोई बदलाव न करें
आपके पास उन अनुरोधों के लिए, किसी खास सुविधा को लागू न करने का विकल्प होता है जहांsampleExtractionकोtrueपर सेट किया गया है. इससे सिमैंटिक डिटेक्शन की प्रोसेस धीमी हो जाएगी, क्योंकि Data Studio को सिमैंटिक डिटेक्शन की प्रोसेस के लिए पूरा डेटा फ़ेच करना होगा. इसके अलावा, इससे आपके बाहरी डेटा सोर्स के लिए अनुरोध की दर पर भी असर पड़ेगा. ऐसा इसलिए, क्योंकि सिमैंटिक डिटेक्शन के कई अनुरोध एक साथ पूरे किए जाएंगे.
सिमेंटिक टाइप का अपने-आप पता लगाने के लिए, पहचाने गए फ़ॉर्मैट
तारीख और समय
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- समय: सेकंड, माइक्रो, मिली, और नैनो के लिए epoch.
Geo
- महाद्वीप का नाम या कोड
- उपमहाद्वीप का नाम या कोड
- इलाके का नाम या कोड
- देश का नाम या कोड. इसके अलावा, ISO_3166-1 देखें.
- शहर का नाम
- कॉमा लगाकर अलग की गई अक्षांश और देशांतर की वैल्यू
- खास तौर पर बनाए गए बाज़ार (डीएमए) का नाम और कोड