
وقتی یک رابط انجمن میسازید، هر فیلدی که در طرح تعریف میکنید به یک نوع داده نیاز دارد. نوع داده، نوع اولیه فیلد مانند BOOLEAN ، STRING ، NUMBER و غیره را تعریف میکند.
علاوه بر انواع داده، دیتا استودیو از انواع معنایی نیز استفاده میکند. انواع معنایی به توصیف نوع اطلاعاتی که دادهها نشان میدهند کمک میکنند. به عنوان مثال، فیلدی با نوع داده NUMBER ممکن است از نظر معنایی نشاندهنده مقدار یا درصد ارز باشد و فیلدی با نوع داده STRING ممکن است از نظر معنایی نشاندهنده یک شهر باشد. برای مشاهده انواع معنایی موجود، لطفاً به مستندات انواع معنایی مراجعه کنید.
طرحواره رابط جامعه و فیلدهای استودیو داده
وقتی طرحواره (schema) را برای رابط انجمن خود تعریف میکنید، برای هر فیلد ویژگیهای مختلفی وجود دارد که نحوه نمایش و استفاده از فیلد در Data Studio را تعیین میکند. به عنوان مثال:
- conceptType در طرحواره اتصال شما با استفاده از ویژگی
conceptTypeتعریف میشود. این ویژگی تعیین میکند که آیا فیلد به عنوان یک بُعد یا متریک در نظر گرفته شود. توضیحی در مورد تفاوت بین متریکها و ابعاد را میتوانید در Dimensions and metrics بیابید. - نوع معنایی میتواند یا در طرحواره کانکتور تعریف شود، یا میتواند به طور خودکار توسط Data Studio بر اساس ویژگی نوع داده تعریف شده در کانکتور شما و مقادیر دادهای که توسط کانکتور شما بازگردانده میشود، شناسایی شود. برای جزئیات بیشتر در مورد نحوه عملکرد این روش ، به تشخیص خودکار نوع معنایی مراجعه کنید.
- نوع تجمیع تعیین میکند که آیا مقادیر معیار (ابعاد نادیده گرفته میشوند) میتوانند دوباره تجمیع شوند یا خیر. تنظیم ویژگی
semantics.isReaggregatableرویtrue، تجمیع پیشفرضSUMرا فعال میکند، در غیر این صورت رویAutoتنظیم میشود. همچنین میتوانید با استفاده از ویژگیdefaultAggregationType، نوع تجمیع پیشفرض را برای فیلدهای قابل تجمیع به صورت دستی تنظیم کنید.
وقتی با استفاده از یک کانکتور در Data Studio پیکربندی و اتصال را انجام میدهید، ویرایشگر فیلدها طرح کلی کانکتور را بر اساس نحوه تعریف ویژگیهای بالا نشان میدهد. اگر انواع معنایی را درج کرده باشید، آنها همانطور که تعریف کردهاید نمایش داده میشوند. اگر از تشخیص خودکار نوع معنایی استفاده میکنید، فیلدها همانطور که شناسایی شدهاند نمایش داده میشوند. 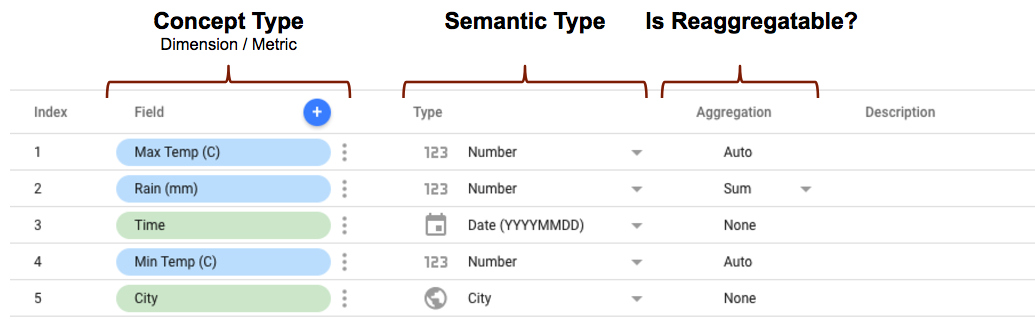
تنظیم اطلاعات معنایی
دو راه برای تنظیم اطلاعات معنایی وجود دارد. میتوانید یا به صورت دستی معنای فیلد را تنظیم کنید یا برای تشخیص خودکار به Data Studio تکیه کنید.
برای مثال، اگر عددی دارید که از نظر معنایی نمایانگر دلار آمریکا است، دیتا استودیو قادر به تشخیص خودکار این نوع معنایی نخواهد بود. علاوه بر این، تشخیص خودکار معنایی مستلزم آن است که دیتا استودیو برای هر فیلد از طرحواره شما فراخوانیهای واکشی داده انجام دهد. اگر به جای آن، طرحواره را به صورت دستی مشخص کنید، هیچ فراخوانی واکشی دادهای انجام نخواهد شد. در صورتی که نوع معنایی (مثلاً ارز، درصد، تاریخ و غیره) را برای دادههای خود میدانید، توصیه میکنیم به دلایل دقت و عملکرد، این مورد را به صراحت در طرحواره تنظیم کنید.
تنظیم دستی انواع معنایی (توصیه میشود)
اگر انواع معنایی خود را میدانید، میتوانید به صورت دستی برای هر فیلد طرحواره، semantics تعریف کنید. جزئیات کامل در مورد ویژگیهای موجود برای شما را میتوانید در صفحه مرجع فیلد پیدا کنید. اگر تصمیم به تعریف دستی انواع معنایی دارید، توصیه میشود semanticType و semanticGroup را برای هر فیلد تعریف کنید. با ارائه دستی این ویژگیها، فرآیند تشخیص خودکار نوع معنایی اجرا نخواهد شد. اگر برخی از فیلدهای خود را به صورت دستی تنظیم کنید، اما نه همه آنها، آنهایی که مشخص نکردهاید، بسته به dataType مشخص شده برای فیلد، به صورت پیشفرض روی Text ، Number یا Boolean تنظیم میشوند.
در ادامه مثالی از یک طرحواره ساده که به صورت دستی انواع معنایی را تنظیم میکند، آورده شده است. Income به عنوان واحد پول و Filing Year به عنوان تاریخ تنظیم شده است.
عیبیابی دستی انواع معنایی
اگر انواع معنایی خود را برای دادههای اساسی به طور نادرست تنظیم کنید، آنها به درستی کار نخواهند کرد. آزمایش این امر میتواند دشوار باشد، اما چند کار وجود دارد که میتوانید برای یافتن مشکلات انجام دهید.
- به جای کل دادهها، ۲ یا ۳ ردیف از آنها را برگردانید، سپس به صورت دستی آنها را بررسی کنید.
- در دیتا استودیو جدولی ایجاد کنید که فقط از فیلدی که میخواهید بررسی کنید استفاده کند.
- به فیلدهای
GeoوDateتوجه زیادی داشته باشید زیرا دقیقترین قالببندی را دارند.
تشخیص خودکار نوع معنایی
اگر هیچ نوع معنایی در طرحواره خود تعریف نکرده باشید، Data Studio تلاش میکند تا بر اساس ویژگی نوع داده و قالب مقادیر دادهای که توسط کانکتور شما بازگردانده میشود، به طور خودکار آنها را تشخیص دهد.
مراحل فرآیند تشخیص خودکار به شرح زیر است:
- با اجرای تابع
getSchemaاز کانکتور community خود، طرحواره را درخواست کنید. - دستههایی از فیلدهای تعریفشده در طرحواره کانکتور را پیمایش کنید و درخواستهای
getDataرا برای فیلدها صادر کنید. درخواستهایgetDataبا پارامترsampleExtractionکه رویtrueتنظیم شده است، اجرا میشوند تا نشان دهند که درخواستهای داده برای اهداف تشخیص معنایی هستند. - بر اساس نوع داده فیلد و قالب مقدار برگردانده شده از درخواست
getData، نوع معنایی فیلد را شناسایی کنید.
گزینههایی برای مدیریت تشخیص خودکار نوع معنایی
وقتی Data Studio تابع getData یک کانکتور community را به منظور تشخیص معنایی اجرا میکند، درخواست ورودی شامل یک ویژگی sampleExtraction خواهد بود که روی true تنظیم میشود. دادههای برگردانده شده توسط کانکتور شما فقط توسط Data Studio برای شناسایی نوع معنایی فیلد استفاده میشود. از آنجایی که این مقدار برای هیچ هدف دیگری استفاده نخواهد شد، نیازی به دادههای واقعی از منبع خارجی شما ندارد.
چندین روش برای بهبود تشخیص نوع معنایی در کد شما وجود دارد:
توصیه میشود: مقادیر از پیش تعریفشده را ارسال کنید
برای هر فیلد، یک مقدار از پیش تعریفشده که به بهترین شکل نوع معنایی فیلد را نشان میدهد و توسط Data Studio به درستی شناسایی میشود، برگردانید. برای مثال، اگر نوع معنایی یک فیلد Country باشد، مقداری مانندITبرای ایتالیا برگردانید. مزیت دیگر این رویکرد این است که بسیار سریعتر است زیرا نیازی به ارسال درخواست HTTP به سرویس شخص ثالث برای دادهها ندارد.فقط n تعداد رکورد را برمیگرداند
اگر سرویس شخص ثالثی که از آن دادهها را دریافت میکنید، هنگام درخواست داده، از محدودیتهای ردیف پشتیبانی میکند، به جای کل مجموعه دادهها، زیرمجموعه کوچکی از ردیفها را به Data Studio برگردانید. این کار مقدار دادههایی را که باید برای هر درخواست تشخیص معنایی به Data Studio ارسال کنید، محدود میکند.درخواست همه ستونها و ذخیره پاسخ
اگر امکان درخواست همه ستونها برای سرویس شخص ثالثی که از آن دادهها را دریافت میکنید، وجود دارد، در اولین درخواست تشخیص معنایی که از Data Studio دریافت میکنید، همه ستونها را دریافت کرده و نتایج را ذخیره کنید. برای درخواستهای تشخیص معنایی بعدی، به جای ارسال درخواستهای HTTP اضافی به سرویس شخص ثالث، مقادیر ستون را از حافظه پنهان دریافت کنید.هیچ کار متفاوتی انجام نده
شما میتوانید انتخاب کنید که هیچ تطبیق خاصی برای درخواستهایی کهsampleExtractionرویtrueتنظیم شده است، پیادهسازی نشود. این امر باعث میشود فرآیند تشخیص معنایی کندتر شود زیرا Data Studio باید تمام دادهها را برای فرآیند تشخیص معنایی واکشی کند. علاوه بر این، این امر بر نرخ درخواست به منبع داده خارجی شما تأثیر میگذارد زیرا بسیاری از درخواستهای تشخیص معنایی به صورت موازی اجرا میشوند.
قالبهای شناختهشده برای تشخیص خودکار نوع معنایی
تاریخ و زمان
-
YYYY/MM/DD-HH:MM:SS -
YYYY-MM-DD [HH:MM:SS[.uuuuuu]] -
YYYY/MM/DD [HH:MM:SS[.uuuuuu]] -
YYYYMMDD [HH:MM:SS[.uuuuuu]] -
Sat, 24 May 2008 20:09:47 GMT -
2008-05-24T20:09:47Z - زمان: دوره برای ثانیه، میکرو، میلی و نانو.
ژئو
- نام یا کد قاره
- نام یا کد شبه قاره
- نام یا کد منطقه
- نام یا کد کشور . همچنین به ISO_3166-1 مراجعه کنید.
- نام شهر
- مقدار طول و عرض جغرافیایی جدا شده با کاما
- نام و کد منطقه بازاریابی تعیینشده (DMA)