
যখন আপনি একটি কমিউনিটি কানেক্টর তৈরি করেন, তখন স্কিমাতে সংজ্ঞায়িত প্রতিটি ফিল্ডের জন্য একটি ডেটা টাইপের প্রয়োজন হয়। ডেটা টাইপটি ফিল্ডটির প্রিমিটিভ টাইপ নির্ধারণ করে, যেমন BOOLEAN , STRING , NUMBER ) ইত্যাদি।
ডেটা টাইপের পাশাপাশি, ডেটা স্টুডিও সিমান্টিক টাইপও ব্যবহার করে। সিমান্টিক টাইপ ডেটাটি কী ধরনের তথ্য উপস্থাপন করে তা বর্ণনা করতে সাহায্য করে। উদাহরণস্বরূপ, NUMBER ডেটা টাইপের একটি ফিল্ড সিমান্টিকভাবে মুদ্রার পরিমাণ বা শতাংশ উপস্থাপন করতে পারে এবং STRING ডেটা টাইপের একটি ফিল্ড সিমান্টিকভাবে একটি শহর উপস্থাপন করতে পারে। কোন কোন সিমান্টিক টাইপ উপলব্ধ আছে তা দেখতে, অনুগ্রহ করে সিমান্টিক টাইপস ডকুমেন্টেশন দেখুন।
কমিউনিটি কানেক্টর স্কিমা এবং ডেটা স্টুডিও ফিল্ড
যখন আপনি আপনার কমিউনিটি কানেক্টরের জন্য স্কিমা নির্ধারণ করেন, তখন প্রতিটি ফিল্ডের বিভিন্ন প্রপার্টি থাকে যা নির্ধারণ করে যে ডেটা স্টুডিওতে ফিল্ডটি কীভাবে উপস্থাপিত ও ব্যবহৃত হবে। উদাহরণস্বরূপ:
- আপনার কানেক্টর স্কিমাতে
conceptTypeপ্রপার্টি ব্যবহার করে ` conceptType` সংজ্ঞায়িত করা হয়। এই প্রপার্টিটি নির্ধারণ করে যে ফিল্ডটিকে ডাইমেনশন নাকি মেট্রিক হিসেবে গণ্য করা হবে। মেট্রিক এবং ডাইমেনশনের মধ্যে পার্থক্য সম্পর্কে ব্যাখ্যা `Dimensions and metrics` অংশে পাওয়া যাবে। - সিমান্টিক টাইপটি কানেক্টর স্কিমাতে সংজ্ঞায়িত করা যেতে পারে, অথবা আপনার কানেক্টরে সংজ্ঞায়িত ডেটা টাইপ প্রপার্টি এবং আপনার কানেক্টর দ্বারা ফেরত দেওয়া ডেটা ভ্যালুগুলোর উপর ভিত্তি করে ডেটা স্টুডিও দ্বারা স্বয়ংক্রিয়ভাবে শনাক্ত করা যেতে পারে। এটি কীভাবে কাজ করে সে সম্পর্কে বিস্তারিত জানতে স্বয়ংক্রিয় সিমান্টিক টাইপ শনাক্তকরণ দেখুন।
- অ্যাগ্রিগেশন টাইপ নির্ধারণ করে যে মেট্রিক ভ্যালুগুলো (ডাইমেনশন উপেক্ষা করা হয়) পুনরায় অ্যাগ্রিগেট করা যাবে কিনা।
semantics.isReaggregatableপ্রপার্টিটিtrueতে সেট করলে ডিফল্টভাবেSUMঅ্যাগ্রিগেশন ব্যবহৃত হবে, অন্যথায় এটিAutoতে সেট করা থাকে। এছাড়াও আপনিdefaultAggregationTypeপ্রপার্টি ব্যবহার করে পুনরায় অ্যাগ্রিগেটযোগ্য ফিল্ডগুলোর জন্য ডিফল্ট অ্যাগ্রিগেশন টাইপ ম্যানুয়ালি সেট করতে পারেন।
আপনি যখন ডেটা স্টুডিওতে একটি কানেক্টর ব্যবহার করে কনফিগার এবং সংযোগ করেন, তখন ফিল্ডস এডিটরটি উপরে আপনার সংজ্ঞায়িত করা প্রোপার্টিগুলোর উপর ভিত্তি করে কানেক্টরটির সম্পূর্ণ স্কিমা দেখায়। আপনি যদি সিমান্টিক টাইপগুলো অন্তর্ভুক্ত করে থাকেন, তাহলে সেগুলো আপনার সংজ্ঞায়িত করা অবস্থাতেই প্রদর্শিত হবে। আপনি যদি স্বয়ংক্রিয় সিমান্টিক টাইপ ডিটেকশন ব্যবহার করেন, তাহলে ফিল্ডগুলো যেভাবে শনাক্ত করা হয়েছে সেভাবেই প্রদর্শিত হবে। 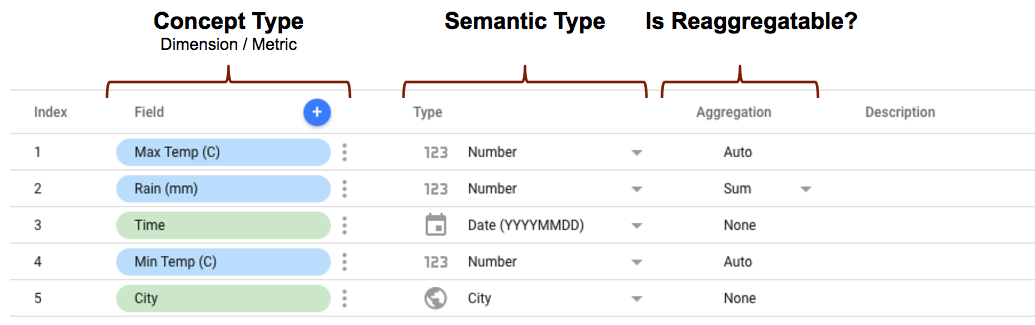
শব্দার্থগত তথ্য নির্ধারণ করা
শব্দার্থিক তথ্য সেট করার দুটি উপায় আছে। আপনি হয় ফিল্ডের শব্দার্থ ম্যানুয়ালি সেট করতে পারেন অথবা স্বয়ংক্রিয়ভাবে শনাক্ত করার জন্য ডেটা স্টুডিওর উপর নির্ভর করতে পারেন।
উদাহরণস্বরূপ, যদি আপনার কাছে এমন একটি সংখ্যা থাকে যা অর্থগতভাবে মার্কিন ডলারকে বোঝায়, তাহলে ডেটা স্টুডিও স্বয়ংক্রিয়ভাবে এই অর্থগত ধরণটি সনাক্ত করতে পারবে না। এছাড়াও, স্বয়ংক্রিয় অর্থগত সনাক্তকরণের জন্য ডেটা স্টুডিওকে আপনার স্কিমার প্রতিটি ফিল্ডের জন্য ডেটা আনার কল করতে হয়। এর পরিবর্তে আপনি যদি স্কিমাটি ম্যানুয়ালি নির্দিষ্ট করে দেন, তাহলে কোনো ডেটা আনার কল করা হবে না। যদি আপনি আপনার ডেটার অর্থগত ধরণ (যেমন মুদ্রা, শতাংশ, তারিখ, ইত্যাদি) জানেন, তাহলে নির্ভুলতা এবং পারফরম্যান্সের কারণে আমরা স্কিমাতে এটি স্পষ্টভাবে সেট করার পরামর্শ দিই।
ম্যানুয়ালি শব্দার্থিক প্রকার নির্ধারণ করা (প্রস্তাবিত)
আপনি যদি আপনার সিমান্টিক টাইপগুলো জানেন, তাহলে প্রতিটি স্কিমা ফিল্ডের জন্য ম্যানুয়ালি semantics নির্ধারণ করতে পারেন। আপনার জন্য কী কী প্রোপার্টি উপলব্ধ আছে তার সম্পূর্ণ বিবরণ ফিল্ড রেফারেন্স পেজে পাওয়া যাবে। আপনি যদি ম্যানুয়াল সিমান্টিক টাইপ নির্ধারণ করতে চান, তবে প্রতিটি ফিল্ডের জন্য semanticType এবং semanticGroup নির্ধারণ করার পরামর্শ দেওয়া হয়। এই প্রোপার্টিগুলো ম্যানুয়ালি প্রদান করলে, স্বয়ংক্রিয় সিমান্টিক টাইপ শনাক্তকরণ প্রক্রিয়াটি চলবে না। আপনি যদি আপনার কিছু ফিল্ড ম্যানুয়ালি সেট করেন, কিন্তু সবগুলো না করেন, তাহলে যেগুলো আপনি নির্দিষ্ট করেননি, সেগুলোর ডিফল্ট মান হবে Text , Number , বা Boolean , যা ফিল্ডটির জন্য নির্দিষ্ট করা dataType এর উপর নির্ভর করবে।
নিম্নলিখিতটি একটি সাধারণ স্কিমার উদাহরণ যেখানে ম্যানুয়ালি সিমান্টিক টাইপ সেট করা হয়। Income মুদ্রা হিসেবে এবং Filing Year তারিখ হিসেবে সেট করা হয়েছে।
সমস্যা সমাধান ম্যানুয়াল শব্দার্থিক প্রকার
যদি আপনি অন্তর্নিহিত ডেটার জন্য আপনার সিমান্টিক টাইপগুলো ভুলভাবে সেট করেন, তাহলে সেগুলো সঠিকভাবে কাজ করবে না। এটি পরীক্ষা করা কঠিন হতে পারে, কিন্তু সমস্যা খুঁজে বের করতে সাহায্য করার জন্য আপনি কয়েকটি কাজ করতে পারেন।
- আপনার ডেটার সবটুকুর পরিবর্তে সেখান থেকে ২ বা ৩টি সারি ফেরত দিন, তারপর নিজে হাতে তা পরীক্ষা করুন।
- ডেটা স্টুডিওতে এমন একটি টেবিল তৈরি করুন, যেখানে শুধু সেই ফিল্ডটিই ব্যবহৃত হবে যা আপনি যাচাই করতে চাইছেন।
-
GeoএবংDateফিল্ডগুলোর প্রতি বিশেষ মনোযোগ দিন, কারণ এগুলোর ফরম্যাট সবচেয়ে কঠোর।
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ
যদি আপনি আপনার স্কিমাতে কোনো সিমান্টিক টাইপ সংজ্ঞায়িত না করে থাকেন, তাহলে ডেটা স্টুডিও আপনার কানেক্টর দ্বারা ফেরত আসা ডেটা ভ্যালুগুলোর ডেটা টাইপ প্রপার্টি এবং ফরম্যাটের উপর ভিত্তি করে সেগুলোকে স্বয়ংক্রিয়ভাবে শনাক্ত করার চেষ্টা করবে।
স্বয়ংক্রিয় শনাক্তকরণ প্রক্রিয়ার ধাপগুলো নিম্নরূপ:
- আপনার কমিউনিটি কানেক্টরের
getSchemaফাংশনটি এক্সিকিউট করে স্কিমাটির জন্য অনুরোধ করুন। - কানেক্টর স্কিমাতে সংজ্ঞায়িত ফিল্ডগুলির ব্যাচের মধ্য দিয়ে পুনরাবৃত্তি করুন এবং ফিল্ডগুলির জন্য
getDataঅনুরোধ পাঠান।getDataঅনুরোধগুলিsampleExtractionপ্যারামিটারটিtrueতে সেট করে কার্যকর করা হয়, যা নির্দেশ করে যে ডেটা অনুরোধগুলি শব্দার্থগত সনাক্তকরণের উদ্দেশ্যে করা হচ্ছে। - ফিল্ডের ডেটা টাইপ এবং
getDataরিকোয়েস্ট থেকে প্রাপ্ত মানের ফরম্যাটের উপর ভিত্তি করে ফিল্ডটির সিমান্টিক টাইপ শনাক্ত করুন।
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ পরিচালনার বিকল্পগুলি
যখন ডেটা স্টুডিও সিমান্টিক ডিটেকশনের উদ্দেশ্যে কোনো কমিউনিটি কানেক্টরের getData ফাংশনটি এক্সিকিউট করে, তখন আগত রিকোয়েস্টটিতে একটি sampleExtraction প্রপার্টি থাকে, যার মান true সেট করা থাকে। আপনার কানেক্টর দ্বারা ফেরত আসা ডেটা ডেটা স্টুডিও শুধুমাত্র ফিল্ডটির সিমান্টিক টাইপ শনাক্ত করার জন্য ব্যবহার করে। যেহেতু এই মানটি অন্য কোনো উদ্দেশ্যে ব্যবহার করা হবে না, তাই এর জন্য আপনার বাহ্যিক উৎস থেকে কোনো প্রকৃত ডেটার প্রয়োজন হয় না।
আপনার কোডে সিমান্টিক টাইপ ডিটেকশন উন্নত করার বেশ কয়েকটি উপায় রয়েছে:
সুপারিশকৃত: পূর্বনির্ধারিত মান পাস করুন
প্রতিটি ফিল্ডের জন্য একটি পূর্বনির্ধারিত মান রিটার্ন করুন যা ফিল্ডটির সিমান্টিক টাইপকে সবচেয়ে ভালোভাবে উপস্থাপন করে এবং ডেটা স্টুডিও দ্বারা সঠিকভাবে শনাক্ত করা যায় বলে জানা যায়। উদাহরণস্বরূপ, যদি কোনো ফিল্ডের সিমান্টিক টাইপ ‘কান্ট্রি’ হয়, তাহলে ইতালির জন্যITমতো একটি মান রিটার্ন করুন। এই পদ্ধতির আরেকটি সুবিধা হলো এটি অনেক দ্রুত, কারণ এর জন্য ডেটার জন্য কোনো থার্ড-পার্টি সার্ভিসে HTTP রিকোয়েস্ট পাঠানোর প্রয়োজন হয় না।শুধুমাত্র n সংখ্যক রেকর্ড ফেরত দিন
আপনি যে থার্ড-পার্টি পরিষেবা থেকে ডেটা সংগ্রহ করছেন, সেটি যদি ডেটা অনুরোধ করার সময় সারির সংখ্যা সীমিত করার সুবিধা দেয়, তাহলে সম্পূর্ণ ডেটা সেটের পরিবর্তে ডেটা স্টুডিও-তে সারিগুলোর একটি ছোট উপসেট ফেরত পাঠান। এর ফলে প্রতিটি সিম্যান্টিক ডিটেকশন অনুরোধের জন্য ডেটা স্টুডিও-তে আপনার পাঠানো ডেটার পরিমাণ সীমিত থাকবে।সমস্ত কলামের জন্য অনুরোধ করুন এবং প্রতিক্রিয়াটি ক্যাশে করুন।
আপনি যে থার্ড-পার্টি পরিষেবা থেকে ডেটা সংগ্রহ করছেন, তার সমস্ত কলামের জন্য অনুরোধ করা যদি সম্ভব হয়, তাহলে ডেটা স্টুডিও থেকে প্রাপ্ত প্রথম সিমান্টিক ডিটেকশন অনুরোধে সমস্ত কলাম সংগ্রহ করুন এবং ফলাফলগুলো ক্যাশে করে রাখুন। পরবর্তী সিমান্টিক ডিটেকশন অনুরোধগুলোর জন্য, থার্ড-পার্টি পরিষেবাতে অতিরিক্ত HTTP অনুরোধ না করে ক্যাশে থেকে কলামের মানগুলো সংগ্রহ করুন।ভিন্ন কিছু করবেন না
যেসব অনুরোধের ক্ষেত্রেsampleExtractionমান `trueসেট করা থাকে, সেগুলোর জন্য আপনি কোনো নির্দিষ্ট ব্যবস্থা প্রয়োগ না করার সিদ্ধান্ত নিতে পারেন। এর ফলে সিমান্টিক ডিটেকশন প্রক্রিয়াটি ধীর হয়ে যাবে, কারণ ডেটা স্টুডিওকে এই প্রক্রিয়ার জন্য সমস্ত ডেটা সংগ্রহ করতে হবে। এছাড়াও, এটি আপনার বাহ্যিক ডেটা উৎসের অনুরোধের হারকে প্রভাবিত করবে, কারণ অনেকগুলো সিমান্টিক ডিটেকশন অনুরোধ সমান্তরালভাবে সম্পাদিত হবে।
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণের জন্য স্বীকৃত ফর্ম্যাট
তারিখ ও সময়
-
YYYY/MM/DD-HH:MM:SS -
YYYY-MM-DD [HH:MM:SS[.uuuuuu]] -
YYYY/MM/DD [HH:MM:SS[.uuuuuu]] -
YYYYMMDD [HH:MM:SS[.uuuuuu]] -
Sat, 24 May 2008 20:09:47 GMT -
2008-05-24T20:09:47Z - সময়: সেকেন্ড, মাইক্রো, মিলি এবং ন্যানোর জন্য ইপক।
জিও
- মহাদেশের নাম বা কোড
- উপ-মহাদেশের নাম বা কোড
- অঞ্চলের নাম বা কোড
- দেশের নাম বা কোড । আরও দেখুন ISO_3166-1 ।
- শহরের নাম
- কমা দ্বারা পৃথক করা অক্ষাংশ এবং দ্রাঘিমাংশের মান
- নির্ধারিত বিপণন এলাকা (ডিএমএ) নাম এবং কোড