Введение в программирование и C++
В этом онлайн-руководстве рассматриваются более сложные концепции — прочтите Часть III. В этом модуле мы сосредоточимся на использовании указателей и начале работы с объектами.
Учитесь на примере №2
В этом модуле основное внимание уделяется получению большей практики в декомпозиции, пониманию указателей и началу работы с объектами и классами. Проработайте следующие примеры. Пишите программы сами, когда вас об этом просят, или проводите эксперименты. Мы не можем не подчеркнуть, что ключом к тому, чтобы стать хорошим программистом, является практика, практика, практика!
Пример № 1: Больше практики декомпозиции
Рассмотрим следующий результат простой игры:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
Первое наблюдение — это вводный текст, который отображается один раз при выполнении программы. Нам нужен генератор случайных чисел, чтобы определять расстояние до противника для каждого раунда. Нам нужен механизм для получения данных об угле от игрока, и это, очевидно, имеет циклическую структуру, поскольку она повторяется до тех пор, пока мы не столкнемся с врагом. Еще нам понадобится функция для расчета расстояния и угла. Наконец, мы должны отслеживать, сколько выстрелов потребовалось для поражения врага, а также сколько врагов мы поразили за время выполнения программы. Вот возможный план основной программы.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
Процедура Fire управляет ходом игры. В этой функции мы вызываем генератор случайных чисел, чтобы определить расстояние до врага, а затем создаем цикл, чтобы получить входные данные игрока и вычислить, поразил ли он врага или нет. Условие защиты в цикле показывает, насколько близко мы подошли к поражению врага.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Из-за вызовов cos() и sin() вам нужно будет включить math.h. Попробуйте написать эту программу — это отличная практика декомпозиции задач и хороший обзор основ C++. Не забывайте выполнять только одну задачу в каждой функции. Это самая сложная программа, которую мы написали на данный момент, поэтому ее выполнение может занять у вас некоторое время. Вот наше решение.
Пример №2: Практика с указателями
При работе с указателями следует помнить четыре вещи:- Указатели — это переменные, которые содержат адреса памяти. Во время выполнения программы все переменные сохраняются в памяти, каждая по своему уникальному адресу или местоположению. Указатель — это особый тип переменной, которая содержит адрес памяти, а не значение данных. Точно так же, как данные изменяются при использовании обычной переменной, значение адреса, хранимого в указателе, изменяется при манипулировании переменной-указателем. Вот пример:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Обычно мы говорим, что указатель «указывает» на место, которое он сохраняет («указатель»). Итак, в приведенном выше примере intptr указывает на точку 5.

Обратите внимание на использование оператора «new» для выделения памяти для нашего целочисленного указателя. Это то, что мы должны сделать, прежде чем пытаться получить доступ к указателю.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.Оператор * используется для разыменования в C. Одна из наиболее распространенных ошибок, которые программисты C/C++ допускают при работе с указателями, — это забывание инициализировать указатель. Иногда это может привести к сбою во время выполнения, поскольку мы обращаемся к участку памяти, содержащему неизвестные данные. Если мы попытаемся изменить эти данные, мы можем вызвать незаметное повреждение памяти, из-за которого эту ошибку будет сложно отследить.
- Назначение указателя между двумя указателями заставляет их указывать на одного и того же указателя. Итак, назначение y = x; заставляет y указывать на тот же пункт, что и x. Назначение указателя не касается указателя. Он просто меняет один указатель, чтобы он находился в том же месте, что и другой указатель. После назначения указателя два указателя «разделяют» указателя.
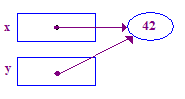
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Вот трассировка этого кода:
| 1. Выделите два указателя x и y. Распределение указателей не выделяет никаких указателей. |  |
| 2. Выделите указатель и установите x, чтобы он указывал на него. |  |
| 3. Разыменование x для сохранения 42 в его указателе. Это базовый пример операции разыменования. Начните с точки x, следуйте за стрелкой, чтобы получить доступ к ее наконечнику. |  |
| 4. Попробуйте разыменовать y, чтобы сохранить 13 в его указателе. Это дает сбой, потому что у y нет указателя - он никогда не был назначен. | 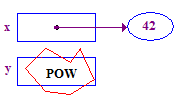 |
| 5. Присвоить y = x; так что y указывает на точку x. Теперь x и y указывают на одну и ту же точку — они «делятся». |  |
| 6. Попробуйте разыменовать y, чтобы сохранить 13 в его указателе. На этот раз это сработало, потому что предыдущее задание дало вам пуант. |  |
Как видите, изображения очень помогают понять использование указателей. Вот еще один пример.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Обратите внимание, что в этом примере мы никогда не выделяли память с помощью оператора «new». Мы объявили обычную целочисленную переменную и манипулировали ею с помощью указателей.
В этом примере мы иллюстрируем использование оператора удаления, который освобождает память кучи, и как мы можем выделить ее для более сложных структур. Мы рассмотрим организацию памяти (кучу и стек времени выполнения) на другом уроке. А пока просто думайте о куче как о свободном хранилище памяти, доступном для запуска программ.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
В этом последнем примере мы покажем, как указатели используются для передачи значений по ссылке в функцию. Вот как мы изменяем значения переменных внутри функции.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Если бы мы исключили символы & из аргументов в определении функции дублирования, мы передавали переменные «по значению», т. е. создавалась копия значения переменной. Любые изменения, внесенные в переменную в функции, изменяют копию. Они не изменяют исходную переменную.
Когда переменная передается по ссылке, мы не передаем копию ее значения, мы передаем в функцию адрес переменной. Любая модификация локальной переменной фактически изменяет переданную исходную переменную.
Если вы программист на C, это новый поворот. Мы могли бы сделать то же самое в C, объявив Duulate() как Duulate(int *x) , и в этом случае x является указателем на int, затем вызвав Duulate() с аргументом &x (адрес x ) и используя de- ссылка на x внутри Duulate() (см. ниже). Но C++ предоставляет более простой способ передачи значений функциям по ссылке, хотя старый способ «C» все еще работает.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Обратите внимание, что при использовании ссылок C++ нам не нужно передавать адрес переменной или разыменовывать переменную внутри вызываемой функции.
Что выводит следующая программа? Чтобы разобраться в этом, нарисуйте изображение воспоминаний.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Запустите программу и проверьте, правильный ли ответ вы получили.
Пример №3: Передача значений по ссылке
Напишите функцию ускорения(), которая принимает в качестве входных данных скорость транспортного средства и ее величину. Функция добавляет величину скорости для ускорения автомобиля. Параметр скорости следует передавать по ссылке, а количество — по значению. Вот наше решение.
Пример №4: Классы и объекты
Рассмотрим следующий класс:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Обратите внимание, что переменные-члены класса имеют завершающее подчеркивание. Это сделано для того, чтобы различать локальные переменные и переменные класса.
Добавьте в этот класс метод уменьшения. Вот наше решение.
Чудеса науки: информатика
Упражнения
Как и в первом модуле этого курса, мы не даем решения упражнений и проектов.
Помните, что хорошая программа...
... логически разлагается на функции, где любая функция выполняет одну и только одну задачу.
... есть основная программа, которая читается как описание того, что будет делать программа.
... имеет описательные функции, имена констант и переменных.
... использует константы, чтобы избежать каких-либо «магических» чисел в программе.
... имеет дружественный пользовательский интерфейс.
Разминочные упражнения
- Упражнение 1
Целое число 36 обладает необычным свойством: оно представляет собой правильный квадрат, а также является суммой целых чисел от 1 до 8. Следующее такое число — 1225, то есть 352, и сумма целых чисел от 1 до 49. Найдите следующее число, которое является полным квадратом, а также суммой ряда 1...n. Следующее число может быть больше 32767. Вы можете использовать известные вам библиотечные функции (или математические формулы), чтобы ускорить работу вашей программы. Также можно написать эту программу, используя циклы for, чтобы определить, является ли число точным квадратом или суммой ряда. (Примечание: в зависимости от вашей машины и вашей программы поиск этого номера может занять некоторое время.)
- Упражнение 2
Книжный магазин вашего колледжа нуждается в вашей помощи в оценке своего бизнеса на следующий год. Опыт показал, что продажи во многом зависят от того, необходима ли книга для курса или просто необязательна, а также от того, использовалась ли она на занятиях ранее или нет. Новый необходимый учебник продадут 90% потенциальных учащихся, но если он использовался в классе раньше, купят только 65%. Аналогичным образом, 40% потенциальных учащихся купят новый дополнительный учебник, но если он использовался в классе раньше, купят только 20%. (Обратите внимание, что слово «использованные» здесь не означает подержанные книги.)
Напишите программу, которая принимает на вход серию книг (пока пользователь не введет дозорного). Для каждой книги запросите: код книги, стоимость одного экземпляра книги, текущее количество книг в наличии, предполагаемое количество зачисленных в класс и данные, указывающие, требуется ли книга/необязательна, новая/использовалась ли она в прошлом. . В качестве вывода покажите всю входную информацию на красиво отформатированном экране, а также количество книг, которые необходимо заказать (если таковые имеются, обратите внимание, что заказываются только новые книги), общую стоимость каждого заказа.
Затем, после того как все вводимые данные будут завершены, покажите общую стоимость всех заказов книг и ожидаемую прибыль, если магазин заплатит 80% прейскурантной цены. Поскольку мы еще не обсуждали способы обработки большого набора данных, поступающих в программу (следите за обновлениями!), просто обрабатывайте одну книгу за раз и покажите выходной экран для этой книги. Затем, когда пользователь завершит ввод всех данных, ваша программа должна вывести значения общей суммы и прибыли.
Прежде чем приступить к написанию кода, подумайте о дизайне этой программы. Разложите его на набор функций и создайте функцию main(), которая читается как схема решения проблемы. Убедитесь, что каждая функция выполняет одну задачу.
Вот пример вывода:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Проект базы данных
В этом проекте мы создаем полнофункциональную программу на C++, реализующую простое приложение для работы с базой данных.
Наша программа позволит нам управлять базой данных композиторов и соответствующей информацией о них. Возможности программы включают в себя:
- Возможность добавить нового композитора
- Возможность ранжировать композитора (т. е. указать, насколько нам нравится или не нравится музыка композитора)
- Возможность просмотра всех композиторов в базе данных
- Возможность просмотра всех композиторов по рангу
«Есть два способа создания проекта программного обеспечения: один способ — сделать его настолько простым, чтобы не было очевидных недостатков, а другой — сделать его настолько сложным, чтобы не было очевидных недостатков. Первый метод гораздо сложнее. ." - АВТОМОБИЛЬ Хоар
Многие из нас научились проектировать и кодировать, используя «процедурный» подход. Центральный вопрос, с которого мы начнем: «Что должна делать программа?». Мы разлагаем решение проблемы на задачи, каждая из которых решает часть проблемы. Эти задачи соответствуют функциям в нашей программе, которые вызываются последовательно из функции main() или из других функций. Этот пошаговый подход идеально подходит для решения некоторых проблем, которые нам необходимо решить. Но чаще всего наши программы — это не просто линейная последовательность задач или событий.
При объектно-ориентированном (ОО) подходе мы начинаем с вопроса: «Какие объекты реального мира я моделирую?» Вместо разделения программы на задачи, как описано выше, мы делим ее на модели физических объектов. Эти физические объекты имеют состояние, определяемое набором атрибутов, а также набором поведения или действий, которые они могут выполнять. Действия могут изменять состояние объекта или вызывать действия других объектов. Основная предпосылка заключается в том, что объект сам «знает», как что-то делать.
В объектно-ориентированном проектировании мы определяем физические объекты в терминах классов и объектов; атрибуты и поведение. Обычно в объектно-ориентированной программе имеется большое количество объектов. Однако многие из этих объектов по сути одинаковы. Рассмотрим следующее.


На этой диаграмме мы определили два объекта класса Apple. Каждый объект имеет те же атрибуты и действия, что и класс, но объект определяет атрибуты для определенного типа яблок. Кроме того, действие «Показать» отображает атрибуты этого конкретного объекта, например «Зеленый» и «Кислый».
Объектно-ориентированный проект состоит из набора классов, данных, связанных с этими классами, и набора действий, которые могут выполнять классы. Нам также необходимо определить способы взаимодействия различных классов. Это взаимодействие может осуществляться объектами одного класса, вызывающими действия объектов других классов. Например, у нас мог бы быть класс AppleOutputer, который выводит цвет и вкус массива объектов Apple, вызывая метод Display() каждого объекта Apple.
Вот шаги, которые мы выполняем при создании объектно-ориентированного дизайна:
- Определите классы и определите в целом, что объект каждого класса хранит в качестве данных и что может делать объект.
- Определите элементы данных каждого класса
- Определите действия каждого класса и то, как некоторые действия одного класса могут быть реализованы с помощью действий других связанных классов.
Для большой системы эти шаги выполняются итеративно на разных уровнях детализации.
Для системы базы данных композитора нам нужен класс Composer, который инкапсулирует все данные, которые мы хотим сохранить в отдельном композиторе. Объект этого класса может повышать или понижать себя (изменять свой ранг), а также отображать свои атрибуты.
Нам также нужна коллекция объектов Composer. Для этого мы определяем класс базы данных, который управляет отдельными записями. Объект этого класса может добавлять или извлекать объекты Composer, а также отображать отдельные из них, вызывая действие отображения объекта Composer.
Наконец, нам нужен какой-то пользовательский интерфейс для обеспечения интерактивных операций с базой данных. Это класс-заполнитель, т. е. мы еще не знаем, как будет выглядеть пользовательский интерфейс, но знаем, что он нам понадобится. Может быть, он будет графический, может быть, текстовый. На данный момент мы определяем заполнитель, который мы можем заполнить позже.
Теперь, когда мы определили классы для приложения базы данных композитора, следующим шагом будет определение атрибутов и действий для классов. В более сложном приложении мы садились бы с карандашом и бумагой, карточками UML , CRC или OOD , чтобы наметить иерархию классов и то, как взаимодействуют объекты.
Для нашей базы данных композиторов мы определяем класс Composer, который содержит соответствующие данные, которые мы хотим хранить в каждом композиторе. Он также содержит методы для управления рейтингами и отображения данных.
Классу Database нужна какая-то структура для хранения объектов Composer. Нам нужно иметь возможность добавлять в структуру новый объект Composer, а также получать определенный объект Composer. Мы также хотели бы отображать все объекты либо в порядке их появления, либо по рангу.
Класс User Interface реализует интерфейс, управляемый меню, с обработчиками, которые вызывают действия в классе Database.
Если классы легко понять, а их атрибуты и действия понятны, как в приложении-композиторе, спроектировать классы относительно легко. Но если у вас есть какие-либо вопросы относительно того, как классы связаны и взаимодействуют, лучше сначала нарисовать это и проработать детали, прежде чем приступать к написанию кода.
Как только мы получим четкое представление о проекте и оценим его (подробнее об этом позже), мы определяем интерфейс для каждого класса. На этом этапе нас не волнуют детали реализации — просто какие атрибуты и действия и какие части состояния и действий класса доступны другим классам.
В C++ мы обычно делаем это, определяя файл заголовка для каждого класса. Класс Composer имеет частные члены данных для всех данных, которые мы хотим хранить в композиторе. Нам нужны аксессоры (методы «get») и мутаторы (методы «set»), а также основные действия для класса.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Класс базы данных также прост.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Обратите внимание, как мы тщательно инкапсулировали данные, специфичные для композитора, в отдельный класс. Мы могли бы поместить структуру или класс в класс базы данных, представляющий запись Composer, и обращаться к ней напрямую оттуда. Но это было бы «недостаточной объективацией», т. е. мы не моделируем объекты настолько, насколько могли бы.
Когда вы начнете работать над реализацией классов Composer и Database, вы увидите, что гораздо проще иметь отдельный класс Composer. В частности, наличие отдельных атомарных операций над объектом Composer значительно упрощает реализацию методов Display() в классе Database.
Конечно, существует и такая вещь, как «чрезмерная объективация», когда мы пытаемся сделать все классом или у нас есть больше классов, чем нам нужно. Чтобы найти правильный баланс, нужна практика, и вы обнаружите, что у отдельных программистов будут разные мнения.
Определить, чрезмерно или недостаточно вы объективируете, часто можно, тщательно построив диаграммы своих классов. Как упоминалось ранее, важно разработать дизайн класса, прежде чем приступить к программированию, и это может помочь вам проанализировать ваш подход. Обычно для этой цели используется обозначение UML (унифицированный язык моделирования). Теперь, когда у нас есть классы, определенные для объектов Composer и Database, нам нужен интерфейс, который позволит пользователю взаимодействовать с базой данных. Простое меню поможет вам:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Мы могли бы реализовать пользовательский интерфейс как класс или как процедурную программу. Не все в программе C++ должно быть классом. Фактически, если обработка является последовательной или ориентированной на задачу, как в этой программе меню, ее можно реализовать процедурно. Важно реализовать его таким образом, чтобы он оставался «заполнителем», т.е. если мы захотим в какой-то момент создать графический интерфейс пользователя, нам не придется ничего менять в системе, кроме пользовательского интерфейса.
Последнее, что нам нужно для завершения приложения, — это программа для тестирования классов. Для класса Composer нам нужна программа main(), которая принимает входные данные, заполняет объект композитора и затем отображает его, чтобы убедиться, что класс работает правильно. Мы также хотим вызвать все методы класса Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Нам нужна аналогичная тестовая программа для класса Database.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Обратите внимание, что эти простые тестовые программы являются хорошим первым шагом, но они требуют, чтобы мы вручную проверили выходные данные, чтобы убедиться, что программа работает правильно. По мере того, как система становится больше, ручная проверка результатов быстро становится непрактичной. На следующем уроке мы познакомим вас с самопроверяемыми тестовыми программами в виде модульных тестов.
Разработка нашего приложения завершена. Следующим шагом является реализация файлов .cpp для классов и пользовательского интерфейса. Для начала скопируйте/вставьте приведенный выше код .h и тестового драйвера в файлы и скомпилируйте их. Используйте тестовые драйверы для тестирования своих классов. Затем реализуйте следующий интерфейс:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Используйте методы, определенные в классе Database, для реализации пользовательского интерфейса. Сделайте свои методы устойчивыми к ошибкам. Например, рейтинг всегда должен находиться в диапазоне от 1 до 10. Не позволяйте никому добавлять 101 композитора, если только вы не планируете изменить структуру данных в классе базы данных.
Помните: весь ваш код должен соответствовать нашим соглашениям по кодированию, которые повторены здесь для вашего удобства:
- Каждая программа, которую мы пишем, начинается с комментария к заголовку, в котором указывается имя автора, его контактная информация, краткое описание и способ использования (если применимо). Каждая функция/метод начинается с комментария о работе и использовании.
- Мы добавляем пояснительные комментарии, используя полные предложения, всякий раз, когда код не документирует себя, например, если обработка сложна, неочевидна, интересна или важна.
- Всегда используйте описательные имена: переменные — это слова в нижнем регистре, разделенные знаком _, как в my_variable. В именах функций/методов для обозначения слов используются заглавные буквы, как в MyExcitingFunction(). Константы начинаются с буквы «k» и для обозначения слов используются заглавные буквы, как в kDaysInWeek.
- Отступ кратен двум. Первый уровень - два помещения; если необходимы дополнительные отступы, мы используем четыре пробела, шесть пробелов и т. д.
Добро пожаловать в реальный мир!
В этом модуле мы представляем два очень важных инструмента, используемых в большинстве организаций, занимающихся разработкой программного обеспечения. Первый — это инструмент сборки, а второй — система управления конфигурацией. Оба эти инструмента необходимы в промышленной разработке программного обеспечения, где многие инженеры часто работают над одной большой системой. Эти инструменты помогают координировать и контролировать изменения в базе кода, а также предоставляют эффективные средства для компиляции и связывания системы из множества программ и файлов заголовков.
Make-файлы
Процесс сборки программы обычно управляется с помощью инструмента сборки, который компилирует и связывает необходимые файлы в правильном порядке. Довольно часто файлы C++ имеют зависимости, например, функция, вызываемая в одной программе, находится в другой программе. Или, возможно, файл заголовка необходим для нескольких разных файлов .cpp. Инструмент сборки определяет правильный порядок компиляции на основе этих зависимостей. Он также скомпилирует только те файлы, которые изменились с момента последней сборки. Это может сэкономить много времени в системах, состоящих из нескольких сотен или тысяч файлов.
Обычно используется инструмент сборки с открытым исходным кодом, называемый make. Чтобы узнать об этом, прочитайте эту статью . Посмотрите, сможете ли вы создать граф зависимостей для приложения Composer Database, а затем перевести его в make-файл. Вот наше решение.
Системы управления конфигурацией
Второй инструмент, используемый при разработке промышленного программного обеспечения, — это управление конфигурациями (CM). Это используется для управления изменениями. Допустим, Боб и Сьюзен оба являются техническими писателями и оба работают над обновлениями технического руководства. Во время встречи их менеджер поручает каждому обновить раздел одного и того же документа.
Техническое руководство хранится на компьютере, к которому имеют доступ и Боб, и Сьюзен. Без какого-либо инструмента или процесса CM может возникнуть ряд проблем. Один из возможных сценариев заключается в том, что компьютер, на котором хранится документ, может быть настроен так, что Боб и Сьюзен не смогут одновременно работать над руководством. Это значительно замедлит их движение.
Более опасная ситуация возникает, когда компьютер-хранилище позволяет одновременно открыть документ Бобу и Сьюзен. Вот что может произойти:
- Боб открывает документ на своем компьютере и работает над своим разделом.
- Сьюзен открывает документ на своем компьютере и работает над своим разделом.
- Боб завершает свои изменения и сохраняет документ на компьютере-хранилище.
- Сьюзан завершает внесение изменений и сохраняет документ на компьютере-хранилище.
На этом рисунке показана проблема, которая может возникнуть, если в единственном экземпляре технического руководства отсутствуют элементы управления. Когда Сьюзен сохраняет свои изменения, она перезаписывает изменения, внесенные Бобом.
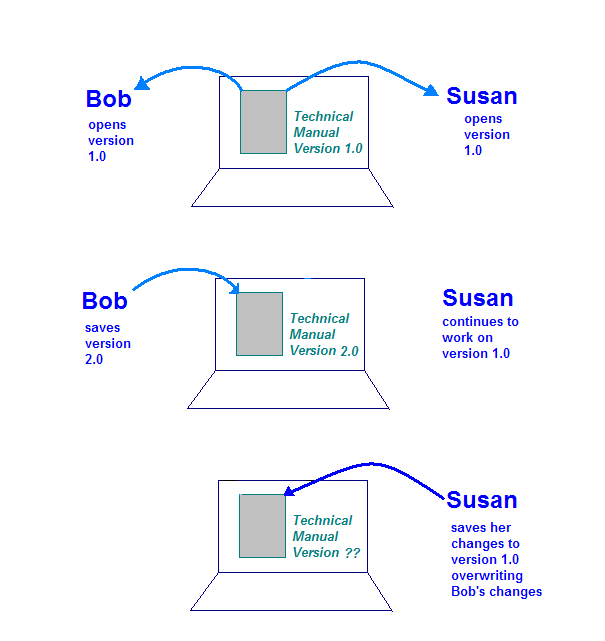
Это именно та ситуация, которую может контролировать система CM. При использовании системы CM и Боб, и Сьюзен «проверяют» свою копию технического руководства и работают над ней. Когда Боб снова возвращает свои изменения, система знает, что Сьюзен выписала свою собственную копию. Когда Сьюзен регистрирует свою копию, система анализирует изменения, внесенные Бобом и Сьюзен, и создает новую версию, объединяющую два набора изменений.
Системы CM имеют ряд функций, помимо управления одновременными изменениями, как описано выше. Многие системы хранят архивы всех версий документа с момента его первого создания. В случае технического руководства это может быть очень полезно, если у пользователя есть старая версия руководства и он задает вопросы техническому писателю. Система CM позволит техническому писателю получить доступ к старой версии и увидеть то, что видит пользователь.
Системы CM особенно полезны для контроля изменений, вносимых в программное обеспечение. Такие системы называются системами управления конфигурацией программного обеспечения (SCM). Если вы примете во внимание огромное количество отдельных файлов исходного кода в крупной организации, занимающейся разработкой программного обеспечения, и огромное количество инженеров, которые должны вносить в них изменения, становится ясно, что система SCM имеет решающее значение.
Управление конфигурацией программного обеспечения
Системы SCM основаны на простой идее: полные копии ваших файлов хранятся в центральном хранилище. Люди извлекают копии файлов из репозитория, работают с этими копиями, а затем возвращают их обратно, когда они закончены. Системы SCM управляют и отслеживают изменения, внесенные несколькими людьми, в одном основном наборе.
Все системы SCM обладают следующими важными функциями:
- Управление параллелизмом
- Управление версиями
- Синхронизация
Давайте рассмотрим каждую из этих особенностей более подробно.
Управление параллелизмом
Параллелизм означает одновременное редактирование файла более чем одним человеком. Мы хотим, чтобы при большом репозитории люди могли это делать, но это может привести к некоторым проблемам.
Рассмотрим простой пример из инженерной области: предположим, мы разрешаем инженерам одновременно изменять один и тот же файл в центральном хранилище исходного кода. Клиенту1 и Клиенту2 необходимо одновременно внести изменения в файл:
- Клиент1 открывает bar.cpp.
- Клиент2 открывает bar.cpp.
- Клиент1 изменяет файл и сохраняет его.
- Клиент2 изменяет файл и сохраняет его, перезаписывая изменения Клиента1.
Очевидно, мы не хотим, чтобы это произошло. Даже если бы мы контролировали ситуацию, заставив двух инженеров работать над отдельными копиями, а не непосредственно над основным набором (как на иллюстрации ниже), копии необходимо каким-то образом согласовать. Большинство систем SCM решают эту проблему, позволяя нескольким инженерам проверять файл («синхронизировать» или «обновлять») и вносить изменения по мере необходимости. Затем система SCM запускает алгоритмы для объединения изменений по мере того, как файлы возвращаются («отправить» или «фиксировать») в репозиторий.

Эти алгоритмы могут быть простыми (попросите инженеров разрешить конфликтующие изменения) или не очень простыми (определите, как разумно объединить конфликтующие изменения, и спрашивайте инженера только в том случае, если система действительно застряла).
Управление версиями
Управление версиями означает отслеживание версий файла, что позволяет воссоздать предыдущую версию файла (или вернуться к ней). Это делается либо путем создания архивной копии каждого файла при его возврате в репозиторий, либо путем сохранения каждого изменения, внесенного в файл. В любой момент мы можем воспользоваться архивами или изменить информацию для создания предыдущей версии. Системы управления версиями также могут создавать отчеты журналов о том, кто зарегистрировал изменения, когда они были возвращены и какие это были изменения.
Синхронизация
В некоторых системах SCM отдельные файлы фиксируются и извлекаются из репозитория. Более мощные системы позволяют извлекать более одного файла одновременно. Инженеры проверяют свою собственную полную копию репозитория (или его части) и работают с файлами по мере необходимости. Затем они периодически фиксируют свои изменения обратно в главный репозиторий и обновляют свои личные копии, чтобы оставаться в курсе изменений, внесенных другими людьми. Этот процесс называется синхронизацией или обновлением.
Подрывная деятельность
Subversion (SVN) — это система контроля версий с открытым исходным кодом. Он обладает всеми описанными выше функциями.
SVN использует простую методологию при возникновении конфликтов. Конфликт — это когда два или более инженера вносят разные изменения в одну и ту же область базы кода, а затем оба отправляют свои изменения. SVN только предупреждает инженеров о наличии конфликта, и инженеры должны его разрешить.
На протяжении всего курса мы будем использовать SVN, чтобы помочь вам познакомиться с управлением конфигурацией. Такие системы очень распространены в промышленности.
Первым шагом является установка SVN в вашей системе. Нажмите здесь, чтобы получить инструкции. Найдите свою операционную систему и загрузите соответствующий двоичный файл.
Некоторая терминология SVN
- Ревизия: изменение в файле или наборе файлов. Ревизия — это один «снимок» постоянно меняющегося проекта.
- Репозиторий: мастер-копия, в которой SVN хранит полную историю изменений проекта. Каждый проект имеет один репозиторий.
- Рабочая копия: копия, в которой инженер вносит изменения в проект. Может существовать множество рабочих копий данного проекта, каждая из которых принадлежит отдельному инженеру.
- Выезд: запросить рабочую копию из репозитория. Рабочая копия соответствует состоянию проекта на момент его извлечения.
- Зафиксировать: отправить изменения из вашей рабочей копии в центральный репозиторий. Также известно как регистрация или отправка.
- Обновление: чтобы перенести изменения других пользователей из репозитория в вашу рабочую копию или указать, есть ли в вашей рабочей копии какие-либо незафиксированные изменения. Это то же самое, что и синхронизация, описанная выше. Таким образом, обновление/синхронизация обновляет вашу рабочую копию с копией репозитория.
- Конфликт: ситуация, когда два инженера пытаются внести изменения в одну и ту же область файла. SVN указывает на конфликты, но разрешить их должны инженеры.
- Сообщение журнала: комментарий, который вы прикрепляете к ревизии при ее фиксации и описывает ваши изменения. Журнал предоставляет сводную информацию о том, что происходит в проекте.
Теперь, когда у вас установлен SVN, мы выполним некоторые основные команды. Первое, что нужно сделать, это настроить репозиторий в указанном каталоге. Вот команды:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
Команда импорта копирует содержимое каталога mytree в проект каталога в репозитории. Мы можем просмотреть каталог в репозитории с помощью команды list .
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
Импорт не создает рабочую копию. Для этого вам нужно использовать команду svn checkout . При этом создается рабочая копия дерева каталогов. Давайте сделаем это сейчас:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Теперь, когда у вас есть рабочая копия, вы можете вносить изменения в файлы и каталоги, находящиеся в ней. Ваша рабочая копия ничем не отличается от любого другого набора файлов и каталогов — вы можете добавлять новые или редактировать их, перемещать и даже удалять всю рабочую копию. Обратите внимание: если вы копируете и перемещаете файлы в своей рабочей копии, важно использовать svn copy и svn move вместо команд операционной системы. Чтобы добавить новый файл, используйте svn add , а для удаления файла используйте svn delete . Если все, что вам нужно, это редактировать, просто откройте файл в редакторе и редактируйте!
Существует несколько стандартных имен каталогов, которые часто используются в Subversion. Каталог «trunk» содержит основное направление развития вашего проекта. Каталог «ветви» содержит любую версию ветки, над которой вы, возможно, работаете.
$ svn list file:///usr/local/svn/repos /trunk /branches
Итак, допустим, вы внесли все необходимые изменения в свою рабочую копию и хотите синхронизировать ее с репозиторием. Если над этой областью репозитория работает много других инженеров, важно поддерживать вашу рабочую копию в актуальном состоянии. Вы можете использовать команду svn status для просмотра внесенных вами изменений.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Обратите внимание, что в команде состояния имеется множество флагов для управления этим выводом. Если вы хотите просмотреть конкретные изменения в измененном файле, используйте svn diff .
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Наконец, чтобы обновить рабочую копию из репозитория, используйте команду svn update .
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
Это одно из мест, где может произойти конфликт. В приведенном выше выводе буква «U» указывает на то, что в версии этих файлов в репозитории не было внесено никаких изменений и было выполнено обновление. «G» означает, что произошло слияние. Версия репозитория была изменена, но изменения не противоречили вашей. Буква «С» указывает на конфликт. Это значит, что изменения из репозитория наложились на ваши, и теперь вам предстоит выбирать между ними.
Для каждого конфликтующего файла Subversion помещает в вашу рабочую копию три файла:
- file.mine: это ваш файл в том виде, в каком он существовал в вашей рабочей копии до ее обновления.
- file.rOLDREV: это файл, который вы извлекли из репозитория перед внесением изменений.
- file.rNEWREV: Этот файл является текущей версией в репозитории.
Вы можете сделать одну из трех вещей, чтобы разрешить конфликт:
- Пройдите файлы и сделайте слияние вручную.
- Скопируйте один из временных файлов, созданных SVN, по версии вашей рабочей копии.
- Запустите SVN, возвращайте , чтобы выбросить все ваши изменения.
После того, как вы решили конфликт, вы дали SVN знать, запустив SVN . Это удаляет три временных файла, а SVN больше не просматривает файл в состоянии конфликта.
Последнее, что нужно сделать, это совершить свою окончательную версию в репозиторий. Это делается с командой Commit Svn . Когда вы совершаете изменение, вам необходимо предоставить сообщение журнала, которое описывает ваши изменения. Это сообщение журнала прикреплено к созданию, которую вы создаете.
svn commit -m "Update files to include new headers."
В SVN есть гораздо больше, чтобы узнать о том, как он может поддерживать крупные проекты по разработке программного обеспечения. В Интернете доступны обширные ресурсы - просто сделайте поиск в Google по «подрывной деятельности».
Для практики создайте репозиторий для вашей системы базы данных композиторов и импортируйте все ваши файлы. Затем проверьте рабочую копию и пройдите по командам, описанным выше.
Ссылки
Онлайн -книга подрывной деятельности
Применение: исследование по анатомии
Проверьте эскелеты из Техасского университета в Остине