प्रोग्रामिंग और C++ के बारे में जानकारी
यह ऑनलाइन ट्यूटोरियल ज़्यादा बेहतर सिद्धांतों के साथ जारी है - कृपया भाग III पढ़ें. इस मॉड्यूल में हमारा फ़ोकस, पॉइंटर का इस्तेमाल करने और ऑब्जेक्ट के साथ शुरू करने पर होगा.
उदाहरण #2 से सीखें
इस मॉड्यूल में हमारा फ़ोकस डिकम्पोज़िशन के साथ ज़्यादा प्रैक्टिस करने, पॉइंटर को समझने, और ऑब्जेक्ट और क्लास के साथ शुरुआत करने पर है. नीचे दिए गए उदाहरणों के ज़रिए काम करें. पूछे जाने पर, खुद प्रोग्राम लिखें या ये एक्सपेरिमेंट करें. हम इतना ज़ोर नहीं दे सकते कि एक अच्छा प्रोग्रामर बनने के लिए सिर्फ़ प्रैक्टिस, प्रैक्टिस, और प्रैक्टिस की सुविधा ज़रूरी है!
उदाहरण #1: डीकंपोज़िशन की ज़्यादा प्रैक्टिस
किसी आसान गेम से मिले नतीजों के बारे में सोचें:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
पहली जानकारी शुरुआती टेक्स्ट है. इसे हर प्रोग्राम के लिए एक बार दिखाया जाता है लागू करता है. हमें हर दुश्मनों की दूरी तय करने के लिए, रैंडम नंबर जनरेटर की ज़रूरत होती है राउंड. हमें प्लेयर से ऐंगल इनपुट पाने के लिए एक तरीका चाहिए और इस वह एक लूप स्ट्रक्चर में बना हुआ है, क्योंकि यह दुश्मन को हराने तक इस गेम को दोहराता रहता है. हमने यह भी दूरी और कोण की गणना करने के लिए एक फलन की आवश्यकता होती है. आख़िर में, हमें निगरानी रखनी होगी हमने दुश्मन को मारने के लिए कितने शॉट लगाए और हमारे पास कितने दुश्मन हैं प्रोग्राम के तहत निपटारा जाता है. यहां मुख्य प्रोग्राम के बारे में जानकारी दी गई है.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
आग लगने की प्रक्रिया के तहत गेम खेले जाते हैं. उस फ़ंक्शन में, हम किसी दुश्मन की दूरी पता करने के लिए एक रैंडम नंबर जनरेटर और फिर लूप को खिलाड़ी से इनपुट लें और हिसाब लगाएं कि उन्होंने दुश्मन को नुकसान पहुंचाया है या नहीं. कॉन्टेंट बनाने हम दुश्मन से कितने दूर हैं.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
cos() और sin() को कॉल करने की वजह से, आपको मैथ.h को शामिल करना होगा. आज़माएँ यह प्रोग्राम लिखना - यह समस्या को हल करने का एक अच्छा तरीका है और यह एक अच्छा C++ के बेसिक वर्शन की समीक्षा कर सकते हैं. याद रखें कि हर फ़ंक्शन में सिर्फ़ एक टास्क करना है. यह है अब तक हमने लिखा है कि यह सबसे जटिल प्रोग्राम है. इसलिए, आपको समय आ गया है.हमारा समाधान यहां है.
उदाहरण #2: पॉइंटर के साथ प्रैक्टिस करें
पॉइंटर के साथ काम करते समय इन चार चीज़ों को याद रखना ज़रूरी है:- पॉइंटर ऐसे वैरिएबल होते हैं जिनमें मेमोरी के पते होते हैं. प्रोग्राम के एक्ज़ीक्यूट होने के दौरान,
सभी वैरिएबल, मेमोरी में सेव होते हैं. हर वैरिएबल के पते या जगह की जानकारी होती है.
पॉइंटर एक खास तरह का वैरिएबल होता है. इसमें इसके बजाय मेमोरी का पता होता है
डेटा वैल्यू से ज़्यादा होता है. जिस तरह किसी सामान्य वैरिएबल का इस्तेमाल किए जाने पर डेटा में बदलाव किया जाता है,
पॉइंटर में सेव किए गए पते की वैल्यू को, पॉइंटर वैरिएबल के तौर पर बदला गया हो
छेड़छाड़ की गई है. यहां एक उदाहरण दिया गया है:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - आम तौर पर हम कहते हैं कि एक पॉइंटर "पॉइंट" उस जगह ले जाएं जहां यह सेव हो रहा है
("पॉइंटी"). इसलिए, ऊपर दिए गए उदाहरण में, इंटीप्टर पॉइंटी को पॉइंट करता है
5.

"नए" के उपयोग पर ध्यान दें हमारे पूर्णांक के लिए मेमोरी बांटने के लिए ऑपरेटर पॉइंटी. यह ऐसा काम है जो हमें पॉइंटी को ऐक्सेस करने से पहले करना चाहिए.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.* ऑपरेटर का इस्तेमाल C में डीरेफ़रेंस करने के लिए किया जाता है. सबसे सामान्य गड़बड़ियों में से एक पॉइंटर के साथ काम करने वाले C/C++ प्रोग्रामर शुरू करना भूल जाते हैं पॉइंटी. इसकी वजह से कभी-कभी रनटाइम क्रैश हो सकता है, क्योंकि हम ऐक्सेस कर रहे हैं मेमोरी में मौजूद कोई ऐसी जगह जिसमें अज्ञात डेटा मौजूद हो. अगर हम अपने हिसाब से बदलाव करने की कोशिश करते हैं, करते हैं, तो हम सूक्ष्म मेमोरी खराब होने का कारण बन सकते हैं, जिससे इसे ट्रैक करना एक कठिन बग हो जाता है.
- दो पॉइंटर के बीच पॉइंटर असाइन करने से, वे एक ही पॉइंटी पर ले जाते हैं.
इसलिए, असाइनमेंट y = x; y पॉइंट को उसी पॉइंटी पर ले जाता है जिस पर x बनाया गया है. पॉइंटर असाइनमेंट
पॉइंटी को नहीं छूता है. इससे सिर्फ़ एक पॉइंटर में ही बदलाव होता है
का इस्तेमाल करें. पॉइंटर असाइनमेंट के बाद, दो पॉइंटर "शेयर करें" यह
पॉइंटी.
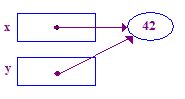
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
यहां इस कोड का ट्रेस दिया गया है:
| 1. दो पॉइंटर x और y तय करें. पॉइंटर असाइन करने से यह होता है न सकते हैं. |  |
| 2. एक पॉइंटी असाइन करें और उस पर पॉइंट करने के लिए x को सेट करें. |  |
| 3. पॉइंटी में 42 स्टोर करने के लिए x को डिकोड करना. यह एक सामान्य उदाहरण है में बदलाव कर सकते हैं. x से शुरू करें और ऐक्सेस करने के लिए, दिए गए तीर के निशान को फ़ॉलो करें पॉइंटी. | 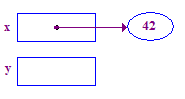 |
| 4. 13 को उसके पॉइंटी में स्टोर करने के लिए, y को डिकोड करने की कोशिश करें. यह क्रैश हो जाता है, क्योंकि उसके पास पॉइंटी नहीं है -- इसे कभी भी असाइन नहीं किया गया था. | 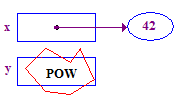 |
| 5. असाइन करें y = x; ताकि y पॉइंट x के पॉइंटर पर हो. अब x और y इस पर ले जाता है एक ही बात है - वे "शेयर" हो रहे हैं. |  |
| 6. 13 को उसके पॉइंटी में स्टोर करने के लिए, y को डिकोड करने की कोशिश करें. इस बार जवाब सही है, क्योंकि पिछले असाइनमेंट में आपको एक पॉइंटी दिया गया था. | 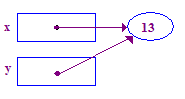 |
जैसा कि यहां देखा जा सकता है, पॉइंटर के इस्तेमाल को समझने में तस्वीरें बहुत मददगार होती हैं. यहां है दूसरा उदाहरण.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
इस उदाहरण में ध्यान दें कि हमने "नए" के साथ मेमोरी कभी असाइन नहीं की ऑपरेटर का इस्तेमाल करें. हमने एक सामान्य पूर्णांक वैरिएबल का एलान किया और पॉइंटर की मदद से उसमें बदलाव किया.
इस उदाहरण में, हम Analytics को हटाने वाले ऑपरेटर के इस्तेमाल की जानकारी देते हैं हीप मेमोरी होती है और हम ज़्यादा जटिल स्ट्रक्चर के लिए बजट तय करने का तरीका क्या बताते हैं. हम कवर करेंगे मेमोरी व्यवस्थित करने (हीप और रनटाइम स्टैक) की ज़रूरत होती है. अभी के लिए, बस इस हीप को प्रोग्राम चलाने के लिए उपलब्ध मेमोरी के मुफ़्त स्टोर के तौर पर देखें.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
इस आखिरी उदाहरण में हमने दिखाया है कि रेफ़रंस के हिसाब से वैल्यू पास करने के लिए, पॉइंटर का इस्तेमाल कैसे किया जाता है फ़ंक्शन में बदलना है. हम किसी फ़ंक्शन में वैरिएबल की वैल्यू में इस तरह से बदलाव करते हैं.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
अगर हमें डुप्लीकेट फ़ंक्शन की परिभाषा में सभी आर्ग्युमेंट और बंद करने का विकल्प दिखाया जाता, तो हम "वैल्यू के हिसाब से" वैरिएबल पास करते हैं. इसका मतलब है कि एक कॉपी वैरिएबल. फ़ंक्शन में वैरिएबल में किए गए किसी भी बदलाव से, कॉपी में बदलाव होता है. वे ओरिजनल वैरिएबल में बदलाव नहीं करते.
जब किसी वैरिएबल को रेफ़रंस से पास किया जाता है, तब हम उसकी वैल्यू की कॉपी पास नहीं करते, हम वैरिएबल का पता फ़ंक्शन में पास कर रहे हैं. ऐसा कोई भी संशोधन जो की मदद से हम लोकल वैरिएबल में पास किए गए ओरिजनल वैरिएबल को असल में संशोधित करते हैं.
अगर आप C प्रोग्रामर हैं, तो यह एक नया ट्विस्ट है. हम C में ऐसा ही कर सकते हैं डुप्लीकेट() का एलान करना डुप्लीकेट(int *x) के तौर पर, किस मामले में x एक पूर्णांक का पॉइंटर है, फिर डुप्लीकेट() को आर्ग्युमेंट &x (x का पता) के साथ कॉल करता है और x के अंदर डुप्लीकेट() (नीचे देखें). हालांकि, C++, फ़ंक्शन को वैल्यू पास करने का आसान तरीका मुहैया कराता है. इससे, संदर्भ दिया हो, भले ही पुरानी "C" काम करती रहती है.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
C++ संदर्भ के साथ सूचना दें, न ही हमें वैरिएबल का पता पास करने की ज़रूरत है और न ही क्या हमें कॉल किए गए फ़ंक्शन में वैरिएबल का रेफ़रंस देना होगा.
नीचे दिया गया प्रोग्राम क्या देता है? यह तय करने के लिए कि क्या याद है, उसका चित्र बनाएं.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} प्रोग्राम चलाकर देखें कि आपको सही जवाब मिला है या नहीं.
उदाहरण #3: रेफ़रंस के हिसाब से वैल्यू पास करना
गति() नाम का एक फ़ंक्शन लिखें, जो किसी वाहन की गति और मात्रा को इनपुट के रूप में लेता है. यह फ़ंक्शन, वाहन की रफ़्तार बढ़ाने के लिए रफ़्तार में जानकारी जोड़ता है. स्पीड पैरामीटर को रेफ़रंस के हिसाब से और रकम के हिसाब से वैल्यू के हिसाब से पास किया जाना चाहिए. इसका हल यहां है.
उदाहरण #4: क्लास और ऑब्जेक्ट
इस क्लास के बारे में सोचें:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
ध्यान दें कि क्लास मेंबर वैरिएबल के आगे अंडरस्कोर होता है. ऐसा लोकल वैरिएबल और क्लास वैरिएबल के बीच अंतर करने के लिए किया जाता है.
इस क्लास में कम करने का कोई तरीका जोड़ें. इसका हल यहां है.
द वंडर्स ऑफ़ साइंस: कंप्यूटर साइंस
अभ्यास
इस कोर्स के पहले मॉड्यूल की तरह ही, हम अलग-अलग तरह की कसरतों और प्रोजेक्ट के लिए समाधान नहीं देते हैं.
याद रखें कि एक अच्छा प्रोग्राम...
... को लॉजिकल तरीके से फ़ंक्शन में बांटा जाता है, जहां किसी एक फ़ंक्शन को सिर्फ़ एक ही टास्क करता है.
... एक मुख्य प्रोग्राम मौजूद है, जो बताता है कि प्रोग्राम क्या करेगा.
... में जानकारी देने वाले फ़ंक्शन, कॉन्स्टेंट, और वैरिएबल के नाम हैं.
... "मैजिक" से बचने के लिए, कॉन्सटेंट का इस्तेमाल किया जाता है का इस्तेमाल करते हैं.
... यूज़र इंटरफ़ेस का यूज़र इंटरफ़ेस आसान है.
वॉर्म-अप व्यायाम
- व्यायाम 1
पूर्णांक 36 की एक खास प्रॉपर्टी है: यह एक पूर्ण वर्ग है, और 1 से 8 तक के पूर्णांकों का योग. अगली ऐसी संख्या 1225 है, जो 352 है और 1 से 49 तक के पूर्णांकों का योग है. अगला नंबर ढूंढें यह एक सटीक स्क्वेयर है और सीरीज़ 1...n का योग भी है. यह अगला नंबर 32767 से ज़्यादा हो सकती है. लाइब्रेरी के उन फ़ंक्शन का इस्तेमाल किया जा सकता है जिनके बारे में आपको पता है, (या गणित के फ़ॉर्मूले) का इस्तेमाल करें, ताकि आपका प्रोग्राम तेज़ी से चले. यह भी संभव है 'लूप' का इस्तेमाल करके इस कार्यक्रम को लिखें, ताकि यह पता लगाया जा सके कि कोई संख्या सटीक है या नहीं वर्ग या किसी सीरीज़ का कुल योग. (नोट: आपकी मशीन और आपके प्रोग्राम के आधार पर, इस नंबर को ढूंढने में थोड़ा समय लग सकता है.)
- व्यायाम 2
आपके कॉलेज की किताबों की दुकान को, आने वाले समय में अपने कारोबार का अनुमान लगाने में आपकी मदद चाहिए साल. अनुभव से पता चला है कि बिक्री काफ़ी हद तक इस बात पर निर्भर करती है कि किताब खरीदने की ज़रूरत है या नहीं या सिर्फ़ ज़रूरी नहीं है और उसका इस्तेमाल क्लास में किया गया है या नहीं से पहले. एक नई, ज़रूरी किताब, सभी संभावित रजिस्ट्रेशन वाले 90% लोगों को बेची जाएगी, लेकिन अगर इसे पहले क्लास में इस्तेमाल किया गया है, तो सिर्फ़ 65% लोग ही इसे खरीदेंगे. इसी तरह, संभावित रजिस्ट्रेशन वाले 40% लोग एक नई, वैकल्पिक किताब खरीदेंगे, लेकिन अगर यह पहले से क्लास में इस्तेमाल कर लिया है, लेकिन सिर्फ़ 20% लोग खरीदारी करेंगे. (ध्यान दें कि यहां "इस्तेमाल किया गया" तो इसका मतलब सेकंड-हैंड किताबों से नहीं है.)
एक ऐसा प्रोग्राम लिखें जो इनपुट के तौर पर किताबों की सीरीज़ को स्वीकार कर सके (जब तक उपयोगकर्ता, किताब के अंदर नहीं आता एक सेंटिनल) हर किताब के लिए: किताब के लिए एक कोड, उसकी एक कॉपी की कीमत किताब, उपलब्ध किताबों की मौजूदा संख्या, संभावित क्लास के लिए रजिस्ट्रेशन, और डेटा जो यह बताता हो कि क्या किताब ज़रूरी है/वैकल्पिक है, नई है/इस्तेमाल की गई है. जैसे आउटपुट, सभी इनपुट जानकारी को एक अच्छी तरह से प्रारूपित स्क्रीन के साथ में दिखाएगा कितनी किताबों का ऑर्डर देना ज़रूरी है (अगर है, तो ध्यान दें कि सिर्फ़ नई किताबों का ऑर्डर दिया जाता है), हर ऑर्डर की कुल कीमत.
फिर, सभी इनपुट पूरे होने के बाद, सभी किताब ऑर्डर की कुल कीमत दिखाएं और अगर स्टोर, कीमत का 80% चुकाता है, तो आपको अनुमानित मुनाफ़ा होगा. क्योंकि अभी तक कार्यक्रम में आने वाले डेटा के एक बड़े सेट को मैनेज करने के किसी भी तरीके के बारे में चर्चा की (सिर्फ़ ट्यून किया गया है!), एक बार में बस एक किताब प्रोसेस करें और उस किताब की आउटपुट स्क्रीन दिखाएं. इसके बाद, जब उपयोगकर्ता सारे डेटा को डाल लेता है, तो आपके प्रोग्राम से कुल और मुनाफ़े की वैल्यू.
कोड लिखना शुरू करने से पहले, थोड़ा समय निकालकर इस प्रोग्राम के डिज़ाइन के बारे में सोचें. फ़ंक्शन के सेट में डिकंपोज़ करें और एक Main() फ़ंक्शन बनाएं, जो ऐसा हो समस्या के समाधान के लिए एक आउटलाइन. पक्का करें कि हर फ़ंक्शन एक ही टास्क करे.
आउटपुट का सैंपल यहां दिया गया है:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
डेटाबेस प्रोजेक्ट
इस प्रोजेक्ट में, हम पूरी तरह से फ़ंक्शनल C++ प्रोग्राम बनाते हैं, जो डेटाबेस ऐप्लिकेशन में सेव किए जा सकते हैं.
हमारे प्रोग्राम से हमें कंपोज़र के डेटाबेस और काम की जानकारी को मैनेज करने में मदद मिलेगी उनके बारे में जानकारी. इस प्रोग्राम के तहत ये सुविधाएं मिलती हैं:
- नया संगीतकार जोड़ने की सुविधा
- किसी कंपोज़र को रैंक देने की सुविधा. जैसे, यह बताना कि हमें कितना पसंद या नापसंद है संगीतकार का संगीत)
- डेटाबेस में सभी कंपोज़र देखने की सुविधा
- सभी कंपोज़र को रैंक के हिसाब से देखने की सुविधा
"इसे बनाने के दो तरीके हैं सॉफ़्टवेयर डिज़ाइन: एक तरीका यह है कि इसे इतना आसान बनाया जाए कि कोई कमी नहीं होगी, और दूसरा तरीका यह है कि इसे इतना जटिल कमियां नहीं हैं. पहला तरीका तो बहुत मुश्किल है." - सी॰ए॰आर॰ Hoare
हम में से कई अप्रोच का इस्तेमाल करें. सबसे अहम सवाल यह है कि "प्रोग्राम को क्या करना चाहिए?". बुध समाधान को टास्क में बदल देते हैं. इनमें से हर एक उस समस्या को हल कर सकें. ये टास्क हमारे प्रोग्राम में मौजूद फ़ंक्शन में शामिल होते हैं जिन्हें क्रम के मुताबिक Main() या अन्य फ़ंक्शन से लिया जाता है. कुछ लोगों के लिए यह सिलसिलेवार तरीका सही है जिन्हें हल करना ज़रूरी है. हालांकि, अक्सर हमारे प्रोग्राम सिर्फ़ लीनियर टास्क या इवेंट का क्रम तय करें.
ऑब्जेक्ट-ओरिएंटेड (ओओ) तरीके से, हम इस सवाल से शुरुआत करते हैं कि "असल दुनिया में किन चीज़ों के लिए मैं मॉडल बना रही हूँ?" प्रोग्राम को टास्क में बांटने के बजाय, बताए गए टास्क में बांटें ऊपर, हम इसे भौतिक वस्तुओं के मॉडल में विभाजित करते हैं. इन भौतिक वस्तुओं में विशेषताओं के एक सेट और व्यवहार या कार्रवाइयों के एक सेट से तय होने वाली स्थिति है वे कर सकते हैं. ये कार्रवाइयां ऑब्जेक्ट की स्थिति बदल सकती हैं या अन्य ऑब्जेक्ट की कार्रवाइयों को शुरू करता है. बुनियादी सिद्धांत यह है कि ऑब्जेक्ट "जानता है" कैसे अपने-आप चीज़ें करने में मदद मिलती है.
OO डिज़ाइन में, फ़िज़िकल ऑब्जेक्ट को क्लास और ऑब्जेक्ट के तौर पर परिभाषित किया जाता है; एट्रिब्यूट और व्यवहार. आम तौर पर, किसी OO प्रोग्राम में बड़ी संख्या में ऑब्जेक्ट मौजूद होते हैं. हालांकि, इनमें से कई ऑब्जेक्ट एक जैसे हैं. इसके लिए, इन्हें आज़माएं.

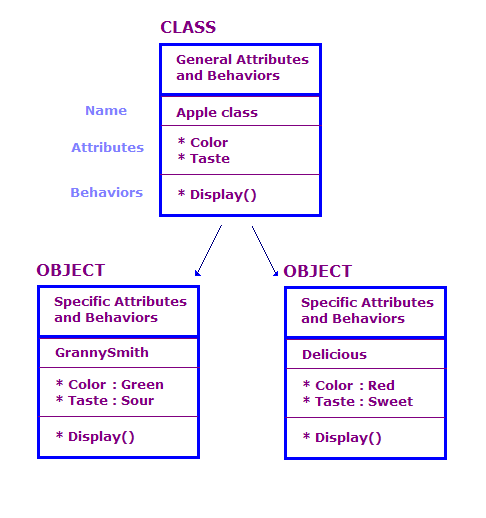
इस डायग्राम में, हमने दो ऐसे ऑब्जेक्ट के बारे में बताया है जो Apple क्लास के हैं. हर ऑब्जेक्ट में क्लास जैसी ही विशेषताएं और कार्रवाइयां होती हैं, लेकिन ऑब्जेक्ट एक खास तरह के सेब के एट्रिब्यूट के बारे में बताता है. इसके अलावा, Display कार्रवाई उस खास ऑब्जेक्ट के लिए एट्रिब्यूट दिखाती है, जैसे कि "ग्रीन" और "खट्टा".
OO डिज़ाइन में क्लास का एक सेट होता है. इसमें इन क्लास से जुड़ा डेटा होता है, साथ ही, उन कार्रवाइयों का सेट भी शामिल होता है जिन्हें क्लास कर सकती हैं. हमें यह भी पता लगाना होगा कि किस तरह से अलग-अलग क्लास के साथ इंटरैक्ट करती हैं. यह इंटरैक्शन ऑब्जेक्ट से किया जा सकता है अन्य क्लास के ऑब्जेक्ट की कार्रवाइयों को शुरू करने वाली क्लास की. उदाहरण के लिए, हम हो सकता है कि एक AppleOutputer क्लास हो, जो किसी अरे के रंग और स्वाद को आउटपुट करता हो की जांच करने के लिए, Display() तरीके का इस्तेमाल करें.
ओओ डिज़ाइन करने के लिए, हम यह तरीका अपनाते हैं:
- क्लास की पहचान करें और सामान्य तौर पर बताएं कि हर क्लास का ऑब्जेक्ट क्या है डेटा के तौर पर सेव करता है. साथ ही, यह भी बताता है कि कोई ऑब्जेक्ट क्या कर सकता है.
- हर क्लास के डेटा एलिमेंट तय करें
- हर क्लास की कार्रवाइयां तय करें और यह भी बताएं कि एक क्लास की कुछ कार्रवाइयां कैसे हो सकती हैं
अन्य संबंधित क्लास की कार्रवाइयों का इस्तेमाल करके लागू किया जाता है.
किसी बड़े सिस्टम में, ये चरण ब्यौरे के अलग-अलग लेवल पर बार-बार होते हैं.
कंपोज़र डेटाबेस सिस्टम के लिए, हमें एक ऐसी कंपोज़र क्लास की ज़रूरत है जिसमें सभी वह डेटा जिसे हम किसी कंपोज़र पर संग्रहित करना चाहते हैं. इस क्लास का एक ऑब्जेक्ट यह कर सकता है खुद को बढ़ावा देना या घटाना (उसकी रैंक बदलना), और एट्रिब्यूट दिखाना.
हमें Composer ऑब्जेक्ट का कलेक्शन भी चाहिए. इसके लिए, हम एक डेटाबेस क्लास तय करते हैं जो अलग-अलग रिकॉर्ड को मैनेज करती है. इस क्लास का ऑब्जेक्ट, जोड़ सकता है या वापस आ सकता है कंपोज़र ऑब्जेक्ट, और डिसप्ले ऐक्शन को शुरू करके अलग-अलग ऑब्जेक्ट दिखाएं एक Composer ऑब्जेक्ट है.
आखिर में, हमें इंटरैक्टिव ऑपरेशन उपलब्ध कराने के लिए एक यूज़र इंटरफ़ेस की ज़रूरत है डेटाबेस में मौजूद है. यह एक प्लेसहोल्डर क्लास है, जिसका मतलब है कि हमें असल में यह पता नहीं है कि का यूज़र इंटरफ़ेस अब भी दिखेगा, लेकिन हमें पता है कि हमें इसकी ज़रूरत होगी. शायद तो यह ग्राफ़िकल होगा, शायद टेक्स्ट आधारित हो. फ़िलहाल, हम एक प्लेसहोल्डर तय करते हैं जो जिसे हम बाद में भर सकते हैं.
अब जबकि हमने कंपोज़र के डेटाबेस ऐप्लिकेशन के लिए क्लास की पहचान कर ली है, अगला चरण क्लास के लिए एट्रिब्यूट और कार्रवाइयां तय करना है. ज़्यादा समय में करने के लिए, हम पेंसिल और काग़ज़ लेकर बैठ सकते हैं या UML या सीआरसी कार्ड या OOD का इस्तेमाल करें.
अपने कंपोज़र डेटाबेस के लिए, हमने एक कंपोज़र क्लास तय की है. इसमें जिसे हम हर कंपोज़र पर स्टोर करना चाहते हैं. इसमें हेर-फेर करने के तरीके भी शामिल होते हैं रैंकिंग तैयार की जा सकती हैं, और डेटा दिखाया जा सकता है.
डेटाबेस क्लास को कंपोज़र ऑब्जेक्ट होल्ड करने के लिए किसी तरह के स्ट्रक्चर की ज़रूरत होती है. हमें स्ट्रक्चर में नया कंपोज़र ऑब्जेक्ट जोड़ने के साथ-साथ, किसी खास कंपोज़र ऑब्जेक्ट को वापस पाएं. हम उन सभी ऑब्जेक्ट को भी दिखाना चाहते हैं या तो एंट्री के हिसाब से या रैंकिंग के हिसाब से.
यूज़र इंटरफ़ेस क्लास, मेन्यू-ड्रिवन इंटरफ़ेस लागू करती है. इस इंटरफ़ेस में, ऐसे हैंडलर शामिल होते हैं जो डेटाबेस क्लास में कॉल की कार्रवाइयों की सुविधा का इस्तेमाल कर सकते हैं.
अगर क्लास को आसानी से समझा जा सकता है और उनकी विशेषताएं और काम आसानी से समझ में आ जाते हैं, तो कंपोज़र ऐप्लिकेशन की तरह, क्लास को डिज़ाइन करना ज़्यादा आसान है. लेकिन अगर आपके मन में कोई सवाल है कि क्लास कैसे एक-दूसरे से कैसे जुड़ी हुई हैं और वे कैसे एक-दूसरे से कैसे इंटरैक्ट करती हैं, बेहतर होगा कि पहले इसे बनाएं और शुरू करने से पहले, पूरी जानकारी के साथ काम करें कोड करने के लिए.
डिज़ाइन की साफ़ जानकारी पाने और उसका आकलन करने के बाद (इसके बारे में ज़्यादा जानकारी पाएं) जल्द ही), हम हर क्लास के लिए इंटरफ़ेस तय करते हैं. हमें लागू करने के बारे में चिंता नहीं करनी पड़ती ब्यौरा - यह एट्रिब्यूट और कार्रवाइयां एक क्लास का' अन्य क्लास के लिए राज्य और कार्रवाइयाँ उपलब्ध हैं.
आम तौर पर, C++ में हर क्लास के लिए हेडर फ़ाइल तय करके ऐसा किया जाता है. द कंपोज़र क्लास में उस सभी डेटा के निजी डेटा सदस्य हैं, जिसे हम किसी कंपोज़र पर संग्रहित करना चाहते हैं. हमें ऐक्सेसर (“पाएं” मेथड) और म्यूटर (“सेट” मेथड) के साथ-साथ प्राथमिक कार्रवाइयों को पूरा किया जा सकता है.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
डेटाबेस क्लास आसान होती है.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
ध्यान दें कि हमने कंपोज़र के डेटा को, ध्यान से अलग-अलग रिपोर्ट में क्लास. हम डेटाबेस क्लास में एक निर्देश या क्लास लगा सकते थे, ताकि कंपोज़र ने रिकॉर्ड किया और इसे सीधे वहीं से ऐक्सेस किया. हालांकि, यह इसका मतलब है कि हम किसी ऑब्जेक्ट के साथ किया जा सकता था.
कंपोज़र और डेटाबेस को लागू करने पर काम शुरू करने पर आपको दिखेगा क्लास के साथ बेहतर तरीके से काम करता है. खास तौर पर, किसी Composer ऑब्जेक्ट पर अलग-अलग ऐटॉमिक ऑपरेशन होने की वजह से, इसे लागू करना काफ़ी आसान हो जाता है का इस्तेमाल किया जा सकता है.
बेशक, कुछ इस तरह की भी बात है, "अपनी चीज़ों को ज़्यादा अहमियत देना" जहां हम हर चीज़ को एक क्लास बनाने की कोशिश करते हैं या हमारे पास ज़रूरत से ज़्यादा क्लास हैं. यह ज़रूरी है तो सही संतुलन बनाने की प्रैक्टिस करें, और आपको पता चल जाएगा कि अलग-अलग प्रोग्रामर अलग-अलग राय होगी.
चीज़ों को ज़रूरत से ज़्यादा या कम शब्दों में तय किया जा सकता है डायग्राम बनाना शुरू कर देते हैं. जैसा कि हमने पहले बताया था, क्लास में कसरत करना बहुत ज़रूरी है डिज़ाइन करना शुरू करें. इससे आपको अपने तरीक़े का विश्लेषण करने में मदद मिलेगी. एक कॉमन इस उद्देश्य के लिए उपयोग किया गया नोटेशन है यूएमएल (यूनिफ़ाइड मॉडलिंग लैंग्वेज) अब जब हमारे पास Composer और डेटाबेस ऑब्जेक्ट के लिए तय की गई क्लास मौजूद हैं, तो हमें ऐसा इंटरफ़ेस जो उपयोगकर्ता को डेटाबेस से इंटरैक्ट करने की अनुमति देता है. आसान मेन्यू यह करके देखें:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
हम यूज़र इंटरफ़ेस को क्लास या प्रोसीजरल प्रोग्राम के तौर पर लागू कर सकते हैं. नहीं C++ प्रोग्राम में हर चीज़ एक क्लास होनी चाहिए. अगर प्रोसेसिंग क्रम में है, तो किया जा सकता है, जैसा कि इस मेन्यू प्रोग्राम में किया जा सकता है. इसे प्रोसेस के हिसाब से लागू किया जा सकता है. इसे इस तरह से लागू करना ज़रूरी है कि यह एक "प्लेसहोल्डर", इसका मतलब है कि अगर हमें कभी ग्राफ़िकल यूज़र इंटरफ़ेस बनाना चाहिए, तो हमें आपको सिस्टम में यूज़र इंटरफ़ेस को छोड़कर कुछ भी बदलने की ज़रूरत नहीं है.
इस आवेदन को पूरा करने के लिए, हमें क्लास की जांच करने वाला एक प्रोग्राम चाहिए. कंपोज़र क्लास के लिए, हमें एक Main() प्रोग्राम की ज़रूरत है जो इनपुट लेता है, कंपोज़र ऑब्जेक्ट को दिखाता है और यह पक्का करने के लिए उसे दिखाता है कि क्लास ठीक से काम कर रही है या नहीं. हम Composer क्लास में सभी तरीकों से कॉल करने की सुविधा चाहते हैं.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
डेटाबेस क्लास के लिए, हमें इससे मिलते-जुलते टेस्ट प्रोग्राम की ज़रूरत होती है.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
ध्यान दें कि ये आसान टेस्ट प्रोग्राम शुरुआत करने में अच्छे हैं, लेकिन इनके लिए हमें आउटपुट की मैन्युअल तौर पर जांच करें, ताकि यह पक्का किया जा सके कि प्रोग्राम सही तरीके से काम कर रहा है. जैसे एक सिस्टम पहले से बड़ा हो जाता है और आउटपुट की मैन्युअल तौर पर जांच तेज़ी से नहीं की जाती. अगले लेसन में, हम इस फ़ॉर्म में खुद की जांच करने वाले टेस्ट प्रोग्राम के बारे में बताएंगे का इस्तेमाल किया जा सकता है.
हमारे ऐप्लिकेशन का डिज़ाइन अब पूरा हो गया है. इसके बाद क्लास और यूज़र इंटरफ़ेस के लिए .cpp फ़ाइलें.शुरू करने के लिए, आगे बढ़ें और ऊपर दिए गए .h और टेस्ट ड्राइवर कोड को कॉपी करके फ़ाइलों में चिपकाएं और उन्हें कंपाइल करें.इस्तेमाल की जाने वाली चीज़ें टेस्ट ड्राइवर की मदद से क्लास की जांच करें. इसके बाद, नीचे दिया गया इंटरफ़ेस लागू करें:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
यूज़र इंटरफ़ेस लागू करने के लिए, डेटाबेस क्लास में बताए गए तरीकों का इस्तेमाल करें. पक्का करें कि आपके तरीके में कोई गड़बड़ी न हो. उदाहरण के लिए, रैंकिंग हमेशा सीमा में होनी चाहिए 1 से 10. किसी को भी 101 कंपोज़र जोड़ने न दें, जब तक कि आप डेटाबेस क्लास में डेटा स्ट्रक्चर की ज़रूरत होती है.
याद रखें - आपके सभी कोड, हमारे कोडिंग के पुराने तौर-तरीकों का पालन करते हैं. इन्हें दोहराया जाता है आपकी सुविधा के लिए यहां देखें:
- हमारे द्वारा लिखा जाने वाला हर प्रोग्राम एक हेडर टिप्पणी से शुरू होता है, जिसमें लेखक, उनकी संपर्क जानकारी, कम शब्दों में जानकारी, और इस्तेमाल के बारे में जानकारी (अगर ज़रूरी हो). हर फ़ंक्शन/तरीका, कार्रवाई और इस्तेमाल पर टिप्पणी करने से शुरू होता है.
- जब भी कोड ऐसा करता है, तब हम पूरे वाक्यों का इस्तेमाल करके, विस्तार से की गई टिप्पणियां जोड़ देते हैं अपने-आप दस्तावेज़ों में बदलाव नहीं कर सकते. उदाहरण के लिए, अगर प्रोसेसिंग पेचीदा, साफ़ तौर पर समझ में नहीं आती, दिलचस्प या ज़रूरी.
- हमेशा जानकारी देने वाले नाम का इस्तेमाल करें: वैरिएबल, छोटे अक्षरों में लिखे गए शब्दों से अलग किए जाते हैं _, जैसा कि my_variable में शामिल किया गया है. फ़ंक्शन/मेथड के नाम में अंग्रेज़ी के बड़े अक्षरों का इस्तेमाल करके शब्दों पर जानकारी देनी चाहिए. नियतांक "k" से शुरू होते हैं और शब्दों को मार्क करने के लिए, अंग्रेज़ी के बड़े अक्षरों का इस्तेमाल करें, जैसे कि kDaysInWEEK.
- इंडेंट दो के गुणजों में होता है. पहला लेवल दो स्पेस है; अगर थोड़ा और इंडेंट करना ज़रूरी है, हम चार स्पेस, छह स्पेस वगैरह का इस्तेमाल करते हैं.
असल दुनिया में आपका स्वागत है!
इस मॉड्यूल में, हमने ज़्यादातर सॉफ़्टवेयर इंजीनियरिंग में इस्तेमाल किए जाने वाले दो बेहद अहम टूल के बारे में बताया है संगठनों ने. पहला टूल बिल्ड टूल है और दूसरा कॉन्फ़िगरेशन मैनेजमेंट है सिस्टम. ये दोनों टूल इंडस्ट्रियल सॉफ़्टवेयर इंजीनियरिंग के लिए ज़रूरी हैं, जहां कई इंजीनियर अक्सर एक ही बड़े सिस्टम पर काम करते हैं. इन टूल से, आपको समाचार संगठनों के बीच तालमेल बनाने में मदद मिलती है. साथ ही, कोड बेस में होने वाले बदलावों को कंट्रोल कर सकते हैं और कंपाइल करने के बेहतर तरीके उपलब्ध करा सकते हैं और कई प्रोग्राम और हेडर फ़ाइलों से एक सिस्टम लिंक कर सकते हैं.
मेकफ़ाइल
प्रोग्राम बनाने की प्रोसेस को आम तौर पर बिल्ड टूल से मैनेज किया जाता है, जो और ज़रूरी फ़ाइलों को सही क्रम में लिंक करता है. अक्सर, C++ फ़ाइलों में डिपेंडेंसी. उदाहरण के लिए, एक प्रोग्राम में कॉल किया जाने वाला फ़ंक्शन, दूसरे प्रोग्राम में मौजूद होता है कार्यक्रम. या, शायद कई अलग-अलग .cpp फ़ाइलों के लिए हेडर फ़ाइल की ज़रूरत हो. ऐप्लिकेशन बिल्ड टूल इन डिपेंडेंसी से इकट्ठा किए जाने वाले सही ऑर्डर का पता लगाता है. यह काम करेगा साथ ही, यह सिर्फ़ उन फ़ाइलों को कंपाइल करता है जिनमें पिछले बिल्ड के बाद बदलाव हुआ है. इससे आपकी बचत होगी सिस्टम में लगने वाला समय होता है, जिसमें सैकड़ों या हज़ारों फ़ाइलें होती हैं.
आम तौर पर, 'मेक' नाम का एक ओपन सोर्स बिल्ड टूल इस्तेमाल किया जाता है. इसके बारे में जानने के लिए, पढ़ें इसके ज़रिए लेख. देखें कि क्या आप कंपोज़र डेटाबेस ऐप्लिकेशन के लिए डिपेंडेंसी ग्राफ़ बना सकते हैं, और फिर इसे एक मेकेफ़ाइल में अनुवाद करें.यहां दिखाता है हमारा समाधान.
कॉन्फ़िगरेशन मैनेजमेंट सिस्टम
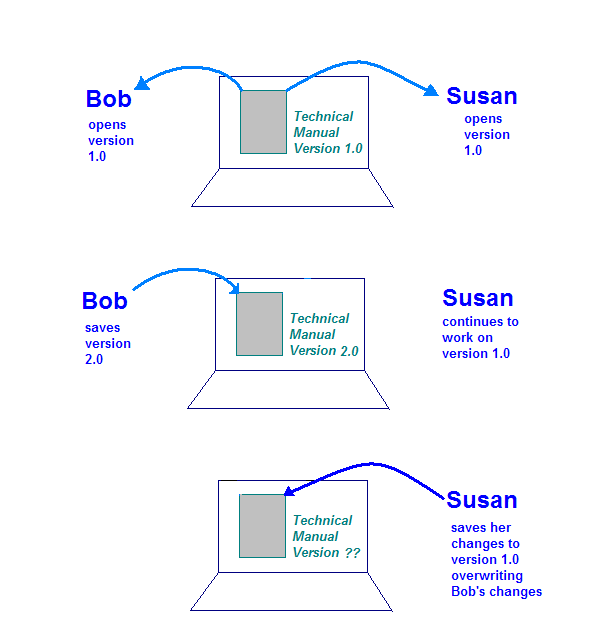
इंडस्ट्रियल सॉफ़्टवेयर इंजीनियरिंग में इस्तेमाल किया जाने वाला दूसरा टूल कॉन्फ़िगरेशन मैनेजमेंट है (सीएम). इसका इस्तेमाल बदलाव को मैनेज करने के लिए किया जाता है. मान लें कि बॉब और सुज़न दोनों तकनीकी लेखक हैं और ये दोनों ही तकनीकी मैन्युअल के अपडेट पर काम कर रहे हैं. मीटिंग के दौरान, मैनेजर उन्हें अपडेट करने के लिए, एक ही दस्तावेज़ का एक सेक्शन असाइन कर देता है.
तकनीकी मैन्युअल को ऐसे कंप्यूटर पर सेव किया गया है जिसे बॉब और सुज़ैन दोनों ऐक्सेस कर सकते हैं. किसी भी CM टूल या प्रोसेस के बिना, कई समस्याएं पैदा हो सकती हैं. एक संभावित स्थिति यह हो सकती है कि दस्तावेज़ को स्टोर करने वाला कंप्यूटर सेट अप किया गया हो, ताकि बॉब और सुज़ैन, दोनों मैन्युअल पर एक साथ काम नहीं कर सकते. इससे रफ़्तार धीमी हो जाएगी काफ़ी कम किया जा सकता है.
और खतरनाक स्थिति तब पैदा होती है, जब स्टोरेज कंप्यूटर, दस्तावेज़ को अपलोड करने की अनुमति देता है जिसे एक ही समय पर बॉब और सुज़ैन दोनों ने खोला होगा. यहां बताया गया है कि क्या हो सकता है:
- बॉब अपने कंप्यूटर पर दस्तावेज़ खोलता है और अपने सेक्शन में काम करता है.
- सुमन अपने कंप्यूटर पर दस्तावेज़ खोलती हैं और अपने सेक्शन में काम करती हैं.
- वैभव अपने बदलावों को पूरा करता है और दस्तावेज़ को स्टोरेज कंप्यूटर पर सेव कर लेता है.
- सुज़ैन अपने बदलावों को पूरा करती है और दस्तावेज़ को स्टोरेज कंप्यूटर पर सेव कर देती है.
इस इलस्ट्रेशन में, उन समस्याओं को दिखाया गया है जो कंट्रोल न होने पर हो सकती हैं तकनीकी मैन्युअल की एक प्रति पर. जब सुज़ैन अपने बदलावों को सेव करती है, तो बॉब के बनाए हुए को ओवरराइट करता है.
यह ऐसी स्थिति है जिसे CM सिस्टम कंट्रोल कर सकता है. कम्यूनिटी मैनेजर की मदद से सिस्टम, बॉब और सुज़ैन दोनों ने "चेक आउट" किया अपनी तकनीकी जानकारी की और उन पर काम करता है. जब वैभव अपने बदलावों की दोबारा जांच करता है, तो सिस्टम को पता होता है कि जिसके पास सुज़ैन की खुद की कॉपी है. जब सुज़ैन अपनी कॉपी में जांच करती है, तो सिस्टम बॉब और सुज़ैन दोनों के बदलावों का विश्लेषण करता है और एक नया वर्शन बनाता है, बदलावों के दोनों सेट को एक साथ मर्ज करता है.
CM सिस्टम में एक साथ होने वाले बदलावों को मैनेज करने के साथ-साथ और भी कई सुविधाएं हैं, जैसा कि बताया गया है पढ़ें. कई सिस्टम किसी दस्तावेज़ के सभी वर्शन के संग्रह को सबसे पहले सेव करते हैं उसे कब बनाया गया. अगर तकनीकी मैन्युअल के मामले में ऐसा करना है, तो यह काफ़ी मददगार हो सकता है जब किसी उपयोगकर्ता के पास मैन्युअल का पुराना वर्शन हो और वह टेक राइटर से सवाल पूछ रहा हो. सीएम सिस्टम की मदद से, टेक राइटर को पुराने वर्शन को ऐक्सेस करने और का इस्तेमाल करें.
सॉफ़्टवेयर में किए गए बदलावों को कंट्रोल करने में, CM सिस्टम खास तौर से मददगार होते हैं. इस तरह सिस्टम को सॉफ़्टवेयर कॉन्फ़िगरेशन मैनेजमेंट (एससीएम) सिस्टम कहा जाता है. अगर आपको सॉफ़्टवेयर इंजीनियरिंग में, अलग-अलग सोर्स कोड फ़ाइलों की बड़ी संख्या और बड़ी संख्या में इंजीनियर हैं जिन्हें उनमें बदलाव करने होते हैं, यह साफ़ है कि एससीएम सिस्टम ज़रूरी है.
सॉफ़्टवेयर कॉन्फ़िगरेशन मैनेजमेंट
एससीएम सिस्टम एक आसान आइडिया पर आधारित हैं: आपकी फ़ाइलों की तय कॉपी एक सेंट्रल रिपॉज़िटरी में रखे जाते हैं. लोग डेटा स्टोर करने की जगह से फ़ाइलों की कॉपी देखते हैं, उन प्रतियों पर काम करता है और जब वे पूर्ण हो जाते हैं तो उन्हें वापस जांचें. SCM सिस्टम एक ही मास्टर के लिए कई लोगों के संशोधनों को प्रबंधित और ट्रैक करते हैं. सेट.
सभी एससीएम सिस्टम में ये ज़रूरी सुविधाएं मिलती हैं:
- कॉन करंसी मैनेजमेंट
- वर्शन
- सिंक्रनाइज़ेशन
आइए, इनमें से हर सुविधा के बारे में ज़्यादा जानकारी पाएं.
कॉन करंसी मैनेजमेंट
किसी फ़ाइल को एक साथ कई लोग एक साथ एडिट कर सकते हैं. डेटा स्टोर करने की विशाल जगह के साथ, हम चाहते हैं कि लोग ऐसा कर पाएं. हालांकि, यह कुछ समस्याओं का सामना करना पड़ रहा है.
इंजीनियरिंग डोमेन के एक आसान उदाहरण पर गौर करें: मान लीजिए कि हम इंजीनियरों को काम करने की अनुमति देते हैं का इस्तेमाल करें. Client1 और Client2, दोनों को किसी फ़ाइल में एक साथ बदलाव करने होंगे:
- क्लाइंट1 बार.cpp खोलता है.
- Client2 बार.cpp को खोलता है.
- Client1 फ़ाइल को बदल देता है और उसे सेव कर लेता है.
- Client2 फ़ाइल को बदल देता है और उसे Client1 के बदलावों को ओवरराइट करके सेव कर देता है.
बेशक, हम ऐसा नहीं चाहते. भले ही हमने स्थिति को दो इंजीनियरों से किसी मास्टर पर काम करने के बजाय, अलग-अलग कॉपी पर काम करवाना (जैसा कि नीचे दिए गए उदाहरण में बताया गया है), तो इन कॉपी में किसी न किसी तरह से समस्या का समाधान होना चाहिए. ज़्यादातर एससीएम सिस्टम इस समस्या से निपटने के लिए, कई इंजीनियर को फ़ाइल की जांच करने की अनुमति देते हैं "सिंक करें" या "अपडेट करें") और ज़रूरत के हिसाब से बदलाव करें. द एससीएम फिर सिस्टम, फ़ाइलों की दोबारा जांच करने पर बदलावों को मर्ज करने के लिए एल्गोरिदम चलाता है ("सबमिट करें" या "समीक्षा करें") से शुरू करें.
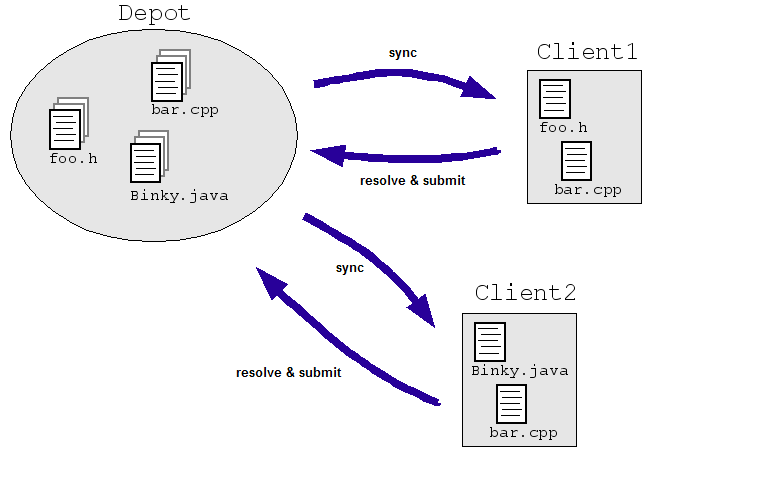
ये एल्गोरिदम आसान हो सकते हैं (इंजीनियरों से विरोधी बदलावों को हल करने के लिए कहें) या बहुत आसान नहीं (तय करें कि विरोधी बदलावों को समझदारी से कैसे मर्ज करें) किसी इंजीनियर से सिर्फ़ तब पूछें, जब सिस्टम सचमुच अटक जाए).
वर्शन
वर्शन का मतलब फ़ाइल में किए गए बदलावों पर नज़र रखना है. इससे ये काम किए जा सकते हैं फ़ाइल का पिछला वर्शन फिर से बनाएं या उसमें रोल बैक करें. ऐसा या तो किया जाता है जब डेटा स्टोर करने की जगह में चेक किया जाता है, तो हर फ़ाइल की एक संग्रह कॉपी बनाकर, करने के लिए, किसी फ़ाइल में किए गए हर बदलाव को सेव करें. हम किसी भी समय संग्रह का इस्तेमाल कर सकते हैं या पिछला वर्शन बनाने के लिए जानकारी को बदलें. वर्शन बनाने वाले सिस्टम बदलावों को किन लोगों ने चेक इन किया, उन्हें कब चेक इन किया, और किन चीज़ों के लिए लॉग इन किया गया, इसकी लॉग रिपोर्ट तैयार करता है बदलाव किए गए थे.
सिंक्रनाइज़ेशन
कुछ एससीएम सिस्टम में, रिपॉज़िटरी में अलग-अलग फ़ाइलों की जांच की जाती है और उनसे बाहर भी रखा जाता है. ज़्यादा असरदार सिस्टम की मदद से, एक बार में एक से ज़्यादा फ़ाइलों को चेक आउट किया जा सकता है. इंजीनियर अपनी खुद की, पूरी, रिपॉज़िटरी (या उसके किसी हिस्से) की कॉपी और काम फ़ाइलों पर उपयोग किया जा सकता है. इसके बाद, वे अपने बदलावों को वापस मास्टर डेटा स्टोर करने की जगह में ले जाते हैं और समय-समय पर अपनी निजी कॉपी को अपडेट करते रहें, ताकि वे बदलावों के साथ अप-टू-डेट रहें जिन्हें अन्य लोगों ने बनाया है. इस प्रोसेस को सिंक करना या अपडेट करना कहा जाता है.
सबवर्शन
सबवर्शन (SVN) एक ओपन सोर्स वर्शन कंट्रोल सिस्टम है. इसमें वे सभी चीज़ें हैं सुविधाओं के बारे में ज़्यादा जानें.
विरोधाभास होने पर, एसवीएन एक आसान तरीका अपनाता है. टकराव तब होता है, जब दो या कई इंजीनियर, कोड बेस के एक ही एरिया में अलग-अलग बदलाव करते हैं और फिर दोनों अपने बदलावों को सबमिट करते हैं. SVN, इंजीनियरों को सिर्फ़ यह सूचना देता है कि - इस समस्या को हल करना इंजीनियर की ज़िम्मेदारी है.
हम इस पूरे कोर्स में एसवीएन का इस्तेमाल करेंगे, ताकि आप इनके बारे में जान सकें कॉन्फ़िगरेशन मैनेजमेंट. इंडस्ट्री में ऐसे सिस्टम काफ़ी आम हैं.
सबसे पहले अपने सिस्टम पर SVN इंस्टॉल करें. क्लिक करें इसके लिए यहां जाएं निर्देश. अपना ऑपरेटिंग सिस्टम ढूंढें और सही बाइनरी डाउनलोड करें.
SVN की कुछ शब्दावली
- बदलाव: किसी फ़ाइल या फ़ाइलों के सेट में बदलाव. एक संशोधन है "स्नैपशॉट" लगातार बदलते प्रोजेक्ट में हैं.
- डेटा स्टोर करने की जगह: वह मास्टर कॉपी जहां SVN, प्रोजेक्ट के बदलावों का पूरा इतिहास सेव करता है. हर प्रोजेक्ट में एक रिपॉज़िटरी होती है.
- वर्किंग कॉपी: वह कॉपी जिसमें इंजीनियर किसी प्रोजेक्ट में बदलाव करता है. यह लीजिए किसी प्रोजेक्ट की कई कामकाजी कॉपी हो सकती हैं, जिनमें से हर एक का मालिकाना हक किसी इंजीनियर के पास होता है.
- चेक आउट करने का विकल्प: डेटा स्टोर करने की जगह से कॉपी का अनुरोध करने के लिए. वर्किंग कॉपी प्रोजेक्ट से चेक आउट किए जाने पर, उसकी स्थिति के बराबर होती है.
- कमिट: अपनी वर्किंग कॉपी से बदलावों को सेंट्रल रिपॉज़िटरी में भेजने के लिए. इसे चेक-इन या सबमिट करना भी कहा जाता है.
- अपडेट: दूसरों का रिपॉज़िटरी से आपकी कॉपी में किए गए बदलाव, या यह बताने के लिए कि आपकी कॉपी में कोई बदलाव नहीं हुआ है. यह है जैसा कि ऊपर बताया गया है. इसलिए, अपडेट/सिंक करने पर डेटा स्टोर करने की जगह की कॉपी के साथ अप-टू-डेट होना.
- विरोध: ऐसी स्थिति जब दो इंजीनियर एक ही चीज़ में बदलाव करने की कोशिश करते हैं फ़ाइल के एक हिस्से से दूसरे हिस्से में होना चाहिए. SVN, विवादों के बारे में बताता है, लेकिन इंजीनियर को उन्हें हल करना होता है.
- लॉग मैसेज: किसी बदलाव को लागू करने के बाद उसमें जोड़ी जाने वाली टिप्पणी, जो आपके बदलावों का वर्णन करता है. लॉग में कारोबार की मौजूदा गतिविधियों के बारे में जानकारी दी जाती है किसी प्रोजेक्ट में शामिल होते हैं.
अब आपने SVN इंस्टॉल कर लिया है, इसलिए हम कुछ बुनियादी निर्देशों की मदद से बात करेंगे. कॉन्टेंट बनाने सबसे पहले, किसी खास डायरेक्ट्री में डेटा स्टोर करने की जगह सेट अप करें. यहां दी गई जानकारी आदेश:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
इंपोर्ट करने का निर्देश, डायरेक्ट्री मिट्री के कॉन्टेंट को रिपॉज़िटरी में डायरेक्ट्री प्रोजेक्ट मौजूद होता है. हम डायरेक्ट्री में जाकर, list कमांड के साथ रिपॉज़िटरी
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
इंपोर्ट, काम करने वाली कॉपी नहीं बनाता. ऐसा करने के लिए, आपको svn चेकआउट कमांड. इससे डायरेक्ट्री ट्री की एक चालू कॉपी बन जाती है. आइए इसे अभी करें:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
अब आपके पास एक मान्य कॉपी है, इसलिए फ़ाइलों और डायरेक्ट्री में बदलाव किए जा सकते हैं वहाँ. आपकी कॉपी, फ़ाइलों और डायरेक्ट्री के किसी भी दूसरे कलेक्शन की तरह ही काम करती है - आप नए जोड़ सकते हैं या उन्हें संपादित कर सकते हैं, इधर-उधर ले जा सकते हैं, आप चाहें तो हटा भी सकते हैं काम की पूरी कॉपी. ध्यान दें कि अगर मौजूदा कॉपी में फ़ाइलें कॉपी और ट्रांसफ़र की जाती हैं, अपने बजाय svn कॉपी और svnmove का इस्तेमाल करना ज़रूरी है ऑपरेटिंग सिस्टम आदेश. नई फ़ाइल जोड़ने के लिए, svn जोड़ें का इस्तेमाल करें और मिटाएं svn delete का इस्तेमाल करके फ़ाइल को मिटाएं. अगर आपको बस बदलाव करना है, तो बस फ़ाइल को एडिट करें!
कुछ स्टैंडर्ड डायरेक्ट्री नाम हैं, जिनका इस्तेमाल अक्सर सबवर्शन के साथ किया जाता है. "ट्रंक" डायरेक्ट्री आपके प्रोजेक्ट के डेवलपमेंट का मुख्य हिस्सा होता है. "ब्रांच" डायरेक्ट्री किसी भी ब्रांच वर्शन को होल्ड करता है, जिस पर आप काम कर रहे हैं.
$ svn list file:///usr/local/svn/repos /trunk /branches
तो, मान लें कि आपने अपनी वर्किंग कॉपी में सभी ज़रूरी बदलाव कर लिए हैं और तो आपको इसे रिपॉज़िटरी के साथ सिंक करना हो. अगर कई और इंजीनियर काम कर रहे हैं यह ज़रूरी है कि आप अपनी वर्क कॉपी को अप-टू-डेट रखें. अपने बदलावों को देखने के लिए, svn स्थिति कमांड का इस्तेमाल किया जा सकता है बनाया गया.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
ध्यान दें कि इस आउटपुट को कंट्रोल करने के लिए, स्टेटस निर्देश पर कई फ़्लैग मौजूद हैं. अगर आपको बदली गई फ़ाइल में कोई खास बदलाव देखना हो, तो svn diff का इस्तेमाल करें.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...आखिर में, रिपॉज़िटरी से अपनी वर्किंग कॉपी अपडेट करने के लिए, svn अपडेट कमांड का इस्तेमाल करें.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
यही वह जगह है जहां विवाद हो सकता है. ऊपर दिए गए आउटपुट में, "U" दिखाता है इन फ़ाइलों के रिपॉज़िटरी वर्शन में कोई बदलाव नहीं किया गया और न ही कोई अपडेट हो गया था. "G" का मतलब है कि मर्ज हुआ. डेटा स्टोर करने की जगह के वर्शन में यह था को बदल दिया गया है, लेकिन उन परिवर्तनों का आपके साथ कोई अंतर्विरोध नहीं हुआ है. "C" दिखाता है विवाद. इसका मतलब है कि डेटा स्टोर करने की जगह में किए गए बदलाव, आपके मालिकाना हक वाले डेटा से ओवरलैप हो गए हैं, और अब आपको उनमें से कोई एक चुनना है.
विवाद वाली हर फ़ाइल के लिए, सबवर्शन आपकी फ़ाइल में तीन फ़ाइलें शामिल करता है कॉपी करें:
- file.mine: यह आपकी फ़ाइल है क्योंकि यह आपके काम करने से पहले आपकी मौजूदा कॉपी में मौजूद थी आपकी कॉपी अपडेट की गई.
- file.rOLDREV: यह वह फ़ाइल है जिसे आपने पहले, डेटा स्टोर करने की जगह से चेक आउट किया था जानकारी मिलेगी.
- file.rNEWREV: यह फ़ाइल रिपॉज़िटरी का मौजूदा वर्शन है.
विवाद सुलझाने के लिए, इनमें से कोई एक काम करें:
- फ़ाइलों को देखें और मैन्युअल तरीके से मर्ज करें.
- SVN की ओर से बनाई गई अस्थायी फ़ाइलों में से किसी एक को कॉपी करके, अपने मौजूदा कॉपी वर्शन पर कॉपी करें.
- अपने सभी बदलावों को हटाने के लिए, svn वापस लाएं को चलाएं.
समस्या को हल करने के बाद, svn हल किया गया को चलाकर SVN को इसकी जानकारी दी जाती है. इससे तीन अस्थायी फ़ाइलें हट जाती हैं और SVN, फ़ाइल को विवाद की स्थिति.
आखिरी काम यह है कि अपने आखिरी वर्शन को डेटा स्टोर करने की जगह के तौर पर सेव करें. यह svn पक्का कमांड की मदद से काम करता है. बदलाव करने के बाद, आपको किन चीज़ों की ज़रूरत होगी ताकि आपको अपने बदलावों के बारे में जानकारी मिल सके. यह लॉग मैसेज अटैच किया गया है संशोधन नहीं किया है.
svn commit -m "Update files to include new headers."
SVN के बारे में जानने और यह बड़े सॉफ़्टवेयर के साथ कैसे काम कर सकता है, के बारे में जानने के लिए बहुत कुछ है इंजीनियरिंग प्रोजेक्ट. वेब पर व्यापक संसाधन उपलब्ध हैं - बस "Subversion" पर Google पर खोज करें.
प्रैक्टिस करने के लिए, अपने कंपोज़र डेटाबेस सिस्टम के लिए रिपॉज़िटरी बनाएं और इंपोर्ट करें आपकी सभी फ़ाइलें. फिर एक चालू कॉपी की चेकआउट करें और बताए गए निर्देशों का पालन करें पढ़ें.
रेफ़रंस
ऐप्लिकेशन: अ स्टडी इन एनाटॉमी
यूनिवर्सिटी के eSkeletons देखें टेक्सस ऐट ऑस्टिन