Introduction à la programmation et à C++
Ce tutoriel en ligne se poursuit avec des concepts plus avancés. Veuillez consulter la partie III. Dans ce module, nous allons nous concentrer sur l'utilisation des pointeurs et la prise en main des objets.
Apprendre par l'exemple n° 2
Ce module se concentre sur l'apprentissage de la décomposition, la compréhension des pointeurs et la prise en main des objets et des classes. Examinez les exemples suivants. Écrivez les programmes vous-même si on vous le demande, ou faites des expériences. Nous ne soulignerons jamais assez que la clé pour devenir un bon programmeur, c'est de s'entraîner et de s'entraîner.
Exemple 1: Autres exercices de décomposition
Prenons la sortie suivante d'un jeu simple:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
La première observation est le texte d'introduction qui s'affiche une fois par programme l'exécution. Nous avons besoin d'un générateur de nombres aléatoires pour définir la distance de chaque ennemi arrondie. Nous avons besoin d'un mécanisme pour obtenir l'angle saisi par le lecteur. se répète évidemment jusqu'à ce que l'ennemi soit touché. Nous avons également ont besoin d'une fonction pour calculer la distance et l'angle. Enfin, nous devons suivre du nombre de tirs et du nombre d'ennemis en sa possession. lors de l'exécution du programme. Voici un aperçu possible du programme principal.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
La procédure Fire gère le jeu. Dans cette fonction, nous appelons un générateur de nombres aléatoires pour connaître la distance de l'ennemi, obtenir l'entrée du joueur et calculer s'il a touché l'ennemi ou non. La La condition de garde de la boucle indique à quel point nous sommes parvenus à atteindre l'ennemi.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
En raison des appels à cos() et sin(), vous devrez inclure math.h. Essayer écrire ce programme. C'est une excellente pratique de décomposition des problèmes et une bonne et une révision du langage C++ de base. N'oubliez pas de n'effectuer qu'une seule tâche dans chaque fonction. Il s'agit de la le programme le plus sophistiqué que nous ayons écrit jusqu'à présent, il vous faudra peut-être le temps de le faire.Pour en savoir plus, consultez cette page.
Exemple 2: S'entraîner avec des pointeurs
Il y a quatre points à retenir lorsque vous travaillez avec des pointeurs: <ph type="x-smartling-placeholder">- </ph>
- Les pointeurs sont des variables qui contiennent des adresses mémoire. Pendant l’exécution d’un programme,
toutes les variables sont stockées en mémoire, chacune dans sa propre adresse ou son propre emplacement.
Un pointeur est un type spécial de variable
qui contient une adresse mémoire au lieu
qu'une valeur de données. Tout comme les données sont modifiées
lorsqu'une variable normale est utilisée,
la valeur de l'adresse stockée dans un pointeur est modifiée en tant que variable de pointeur
est manipulé. Exemple :
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Nous disons généralement
qu'un pointeur « pointe » à l'emplacement de stockage
(le "pointu"). Ainsi, dans l'exemple ci-dessus, "intptr" pointe vers la pointe
5.
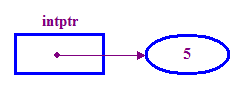
Notez l'utilisation du "nouveau" pour allouer de la mémoire à notre nombre entier Pointe. C'est quelque chose que nous devons faire avant d'essayer d'accéder à la pointee.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.L'opérateur * est utilisé pour le déréférencement en C. L'une des erreurs les plus courantes En travaillant avec les pointeurs, les programmeurs C/C++ oublient de s'initialiser la pointe. Cela peut parfois entraîner un plantage de l'environnement d'exécution, car nous accédons un emplacement en mémoire contenant des données inconnues. Si nous essayons de modifier ce données, nous pouvons provoquer une corruption subtile de la mémoire, ce qui en fait un bug difficile à détecter.
- L'affectation de pointeurs entre deux pointeurs les fait pointer vers le même point.
Ainsi, l'affectation y = x; pointe y vers la même pointe que x. Attribution du pointeur
ne touche pas la pointe. Cela modifie simplement un pointeur pour qu'il corresponde au même lieu
comme un autre pointeur. Après l'affectation du pointeur, les deux pointeurs "partagent" la
Pointe.

void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Voici une trace de ce code:
| 1. Allouez deux pointeurs x et y. L'allocation des pointeurs n'allonger aucun point. | 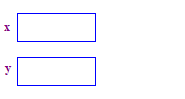 |
| 2. Allouez une pointe et définissez x pour qu'elle pointe vers elle. | 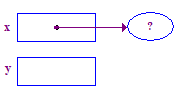 |
| 3. Déréférencez x pour stocker 42 dans sa pointe. Ceci est un exemple de base de l'opération de déréférencement. Commencez à x, puis suivez la flèche pour y accéder sa pointe. | 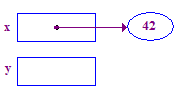 |
| 4. Essayez de déréférencer y pour en stocker 13 dans sa pointe. Cela plante, car y a n'ont pas de pointee, elles ne leur ont jamais été attribuées. | 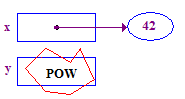 |
| 5. Attribuer y = x; de sorte que y pointe vers la pointe de x. Maintenant x et y pointent vers sur le même pointe - ce sont des « partages ». | 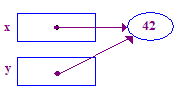 |
| 6. Essayez de déréférencer y pour en stocker 13 dans sa pointe. Cette fois, cela fonctionne, car le devoir précédent vous a donné une pointe. | 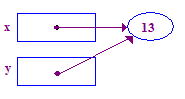 |
Comme vous pouvez le voir, les images sont très utiles pour comprendre l'utilisation du pointeur. Voici un autre exemple.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Notez que, dans cet exemple, nous n'avons jamais alloué de mémoire avec le paramètre "new" . Nous avons déclaré une variable entière normale et l'avons manipulée à l'aide de pointeurs.
Cet exemple illustre l'utilisation de l'opérateur "delete" (suppression) qui permet la désallocation la mémoire du tas de mémoire et comment l'allouer à des structures plus complexes. Nous aborderons l'organisation de la mémoire (tas de mémoire et pile d'exécution) dans une autre leçon. Pour l'instant, considérer le tas de mémoire comme un stockage sans frais de mémoire disponible pour les programmes en cours d’exécution.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
Dans ce dernier exemple, nous montrons comment les pointeurs sont utilisés pour transmettre des valeurs par référence. à une fonction. C'est ainsi que nous modifions les valeurs des variables dans une fonction.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Si nous laissons le « & » désactivé, les arguments dans la définition de la fonction Dupliquer, nous transmettons les variables "par valeur", c'est-à-dire qu'une copie de la valeur la variable. Toutes les modifications apportées à la variable dans la fonction modifient la copie. Ils ne modifient pas la variable d'origine.
Lorsqu'une variable est transmise par référence, nous ne transmettons pas de copie de sa valeur, nous transmettons l'adresse de la variable à la fonction. Toute modification qui que nous appliquons à la variable locale modifie en fait la variable d'origine transmise.
Si vous êtes un programmateur en C, c'est une nouvelle façon de jouer. Nous pourrions faire de même en C en déclarant Duplicate() au format Duplicate(int *x), auquel cas x pointe vers un int, puis appelle Duplicate() avec l'argument &x (adresse de x) et utilise le déréférencement de x dans Dupliquer() (voir ci-dessous). Mais C++ offre un moyen plus simple de transmettre des valeurs aux fonctions en même si l'ancien "C" la façon de le faire fonctionne toujours.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Notez qu'avec les références C++, il n'est pas nécessaire de transmettre l'adresse d'une variable, ni devons-nous déréférencer la variable dans la fonction appelée ?
Que renvoie le programme suivant ? Dessinez une image de votre mémoire pour le comprendre.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Exécutez le programme pour voir si vous avez obtenu la bonne réponse.
Exemple n° 3: Transmettre des valeurs par référence
Écrivez une fonction appelée accélérée() qui prend en entrée la vitesse d'un véhicule et une quantité. La fonction ajoute la valeur à la vitesse pour accélérer le véhicule. Le paramètre de vitesse doit être transmis par référence, et le montant par valeur. Notre solution est disponible sur cette page.
Exemple 4: Classes et objets
Prenons la classe suivante:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Notez que les variables de membre de classe se terminent par un trait de soulignement. Cela permet de différencier les variables locales des variables de classe.
Ajoutez une méthode de diminution à cette classe. Notre solution est disponible sur cette page.
Les merveilles de la science: l'informatique
Exercices
Comme dans le premier module de ce cours, nous ne fournissons pas de solutions aux exercices et aux projets.
Rappelez-vous qu'un bon programme...
... est décomposé logiquement en fonctions, où n'importe quelle fonction effectue une seule et même tâche.
... propose un programme principal qui donne les grandes lignes du programme.
... a des noms de fonctions descriptives, de constantes et de variables.
... utilise des constantes pour éviter toute "magie" de chiffres dans le programme.
... propose une interface utilisateur conviviale.
Exercices d'échauffement
- Exercice n° 1
L'entier 36 a une propriété particulière: c'est un carré parfait, qui est aussi la somme des entiers de 1 à 8. Le numéro suivant est 1225, est 352, et la somme des entiers de 1 à 49. Trouver le numéro suivant c'est un carré parfait, et aussi la somme d'une série 1...n. Ce nombre suivant peut être supérieur à 32767. Vous pouvez utiliser les fonctions de bibliothèque que vous connaissez, (ou formules mathématiques) pour que votre programme s'exécute plus rapidement. Il est également possible d'écrire ce programme en utilisant des boucles pour déterminer si un nombre est un carré ou une somme d'une série. (Remarque: selon votre machine et votre programme, cela peut prendre un certain temps.)
- Exercice 2
La librairie de votre université a besoin de votre aide pour estimer son activité pour l'avenir année. L'expérience a démontré que les ventes dépendent considérablement de la nécessité d'un livre ou non. pour un cours ou uniquement en option, et s'il a été utilisé ou non dans le cours auparavant. Un nouveau manuel obligatoire sera vendu à 90% des futurs élèves, mais s'il a déjà été utilisé dans la classe précédente, seuls 65% l'achèteront. De même, 40% des candidats potentiels achèteront un nouveau manuel, mais s'il a déjà été utilisé dans la classe avant que seuls 20% d'entre eux achèteront. Notez que le terme "d'occasion" ne désigne pas les livres d'occasion.)
Écrivez un programme qui accepte en entrée une série de livres (jusqu'à ce que l'utilisateur entre une sentinelle). Pour chaque livre, demandez un code, le coût de la copie unique pour le nombre de livres disponibles, le nombre d'inscriptions potentielles aux cours, et les données indiquant si le livre est obligatoire/facultatif, neuf/utilisé par le passé. En tant que afficher toutes les informations d'entrée dans un écran correctement formaté, le nombre de livres à commander (le cas échéant, seuls les nouveaux livres sont commandés) ; le coût total de chaque commande.
Ensuite, une fois toutes les saisies, affichez le coût total de toutes les commandes de livres. le bénéfice attendu si le magasin paye 80% du prix catalogue. Puisque nous n'avons pas encore discuté des façons de traiter un grand ensemble de données arrivant dans un programme (rester calibré !), traite un livre à la fois et affiche l'écran de sortie de ce livre. Ensuite, lorsque l'utilisateur a fini de saisir toutes les données, votre programme doit renvoyer les valeurs du total et des bénéfices.
Avant de commencer à écrire du code, prenez le temps de réfléchir à la conception de ce programme. Décomposer la fonction en un ensemble de fonctions et créer une fonction main() qui se lit comme suit : un aperçu de votre solution au problème. Assurez-vous que chaque fonction effectue une tâche.
Voici un exemple de résultat:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Projet de base de données
Dans ce projet, nous créons un programme C++ entièrement fonctionnel qui implémente un simple de votre application de base de données.
Notre programme nous permettra de gérer une base de données de compositeurs et d'autres informations pertinentes. à leur sujet. Ce programme inclut les éléments suivants:
- Possibilité d'ajouter un nouveau compositeur
- Capacité à classer un compositeur (c'est-à-dire à quel point nous aimons ou n'aimerons pas) la musique du compositeur)
- Possibilité d'afficher tous les compositeurs de la base de données
- La possibilité d'afficher tous les compositeurs par rang
« Il y a deux façons de construire un conception logicielle. L'une des solutions consiste à le rendre si simple qu'il existe aucune faille, et l'autre façon est de la rendre si compliquée qu'il ne présente pas de lacunes évidentes. La première méthode est beaucoup plus difficile." – C.A.R. Hoare
Beaucoup d'entre nous ont appris à concevoir et à coder en utilisant une méthode « procédurale » approche. La question centrale par laquelle nous commençons est "Que doit faire le programme ?". Mer décomposer la solution à un problème en tâches, chacune d'entre elles permettant de résoudre une partie le problème. Ces tâches sont mappées à des fonctions de notre programme, appelées de manière séquentielle de main() ou d'autres fonctions. Cette approche étape par étape est idéale pour certains les problèmes que nous devons résoudre. Mais le plus souvent, nos programmes ne sont pas seulement linéaires des séquences de tâches ou d'événements.
Avec une approche orientée objet, nous commençons par la question suivante : que je modélise ? » Au lieu de diviser un programme en tâches comme décrit nous le divisons en modèles d'objets physiques. Ces objets physiques ont un état défini par un ensemble d'attributs, et un ensemble de comportements ou d'actions qui qu'ils peuvent effectuer. Les actions peuvent modifier l'état de l'objet invoquer des actions d'autres objets. Le principe de base est qu'un objet "sait" comment de faire les choses par elles-mêmes.
Dans la conception OO, nous définissons des objets physiques en termes de classes et d'objets ; Attributs et comportements. Il y a généralement un grand nombre d'objets dans un programme OO. Cependant, nombre de ces objets sont essentiellement les mêmes. Tenez compte des points suivants.
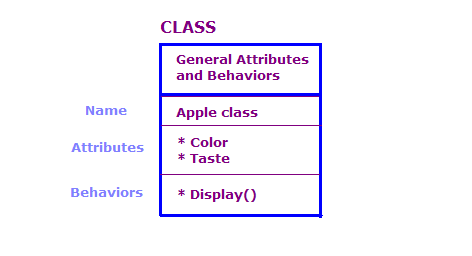
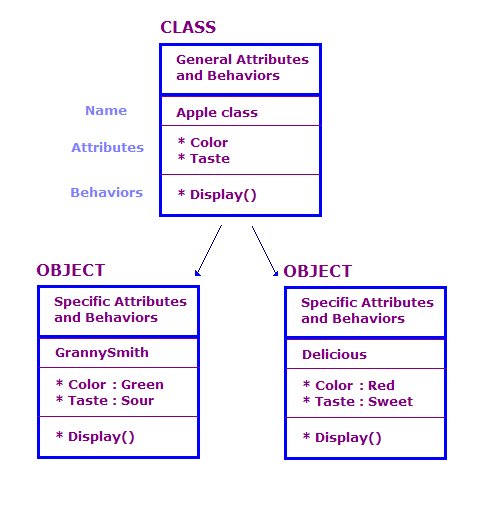
Dans ce schéma, nous avons défini deux objets de la classe Apple. Chaque objet possède les mêmes attributs et actions que la classe, mais l'objet définit les attributs d'un type spécifique de pomme. De plus, l'écran affiche les attributs de cet objet particulier, par exemple "Vert" et "Sour".
Une conception OO est constituée d'un ensemble de classes, les données associées à ces classes, et l'ensemble des actions qu'elles peuvent effectuer. Nous devons également identifier comment différentes classes interagissent. Cette interaction peut être effectuée par des objets d'une classe appelant les actions d'objets d'autres classes. Par exemple, nous peut avoir une classe AppleOutputer qui génère la couleur et le goût d'un tableau. des objets Apple, en appelant la méthode Display() de chaque objet Apple.
Voici les étapes que nous effectuons lors de la conception d'objets:
- Identifier les classes et définir de manière générale ce qu'est un objet de chaque classe stockées en tant que données et ce qu'un objet peut faire.
- Définir les éléments de données de chaque classe
- Définir les actions de chaque classe et la manière dont elles peuvent être réalisées
implémentées à l'aide d'actions
d'autres classes associées.
Pour un grand système, ces étapes se produisent de manière itérative à différents niveaux de détail.
Pour le système de base de données Composer, nous avons besoin d'une classe Composer qui encapsule tous les données que nous voulons stocker sur un compositeur individuel. Un objet de cette classe peut se promouvoir ou se rétrograder (modifier son classement), et afficher ses attributs.
Nous avons également besoin d'une collection d'objets Composer. Pour cela, nous définissons une classe Database qui gère les enregistrements individuels. Un objet de cette classe peut ajouter ou récupérer des objets Composer, et afficher des objets individuels en appelant l'action d'affichage de un objet Composer.
Enfin, nous avons besoin d'une sorte d'interface utilisateur pour fournir des opérations interactives de la base de données. Il s'agit d'une classe d'espace réservé, c'est-à-dire que nous ne savons pas exactement de l'interface utilisateur, mais nous savons que nous en aurons besoin. Peut-être elle sera graphique, peut-être basée sur du texte. Pour l'instant, nous définissons un espace réservé que nous pourrons remplir plus tard.
Maintenant que nous avons identifié les classes pour l'application de base de données Composer, l'étape suivante consiste à définir les attributs et les actions des classes. Dans un une application complexe, nous nous asseoirions avec un crayon et du papier ou UML ou cartes CRC ou OOD pour cartographier la hiérarchie des classes et la façon dont les objets interagissent.
Pour notre base de données Composer, nous définissons une classe Composer qui contient les éléments pertinents données que nous voulons stocker sur chaque compositeur. Il contient également des méthodes de manipulation le classement et l'affichage des données.
La classe Database a besoin d'une structure pour contenir les objets Composer. Nous devons être en mesure d'ajouter un objet Composer à la structure, ainsi que récupérer un objet Composer spécifique. Nous aimerions également afficher tous les objets par ordre d'entrée ou par classement.
La classe Interface utilisateur implémente une interface basée sur un menu, avec des gestionnaires qui dans la classe Database.
Si les classes sont faciles à comprendre et que leurs attributs et actions sont clairs, comme dans l'application Composer, la conception des classes est relativement simple. Toutefois, s'il y a des questions sur la façon dont les cours sont liés et interagissent, il est préférable de commencer par le dessiner, puis de passer en revue les détails avant de commencer au code.
Une fois que nous avons une idée claire de la conception et que nous l'avons évaluée (plus d'informations bientôt), nous définissons l'interface de chaque classe. Nous ne nous préoccupons pas de l'implémentation plus de détails à ce stade : quels sont les attributs et les actions, d'une classe' et les actions sont disponibles pour d'autres classes.
En C++, nous le faisons normalement en définissant un fichier d'en-tête pour chaque classe. Le compositeur a des membres de données privées pour toutes les données que nous voulons stocker sur un Composer. Nous avons besoin des accesseurs ("méthodes get") et des mutateurs ("méthodes set"), ainsi que du les actions principales pour la classe.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
La classe Database est également simple.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Notez que nous avons soigneusement encapsulé les données spécifiques au compositeur dans un fichier . Nous aurions pu placer un struct ou une classe dans la classe Database pour représenter Composer et y accéder directement. Mais ce serait « sous-objectification », c'est-à-dire que nous ne modélisons pas autant avec des objets que possible.
Lorsque vous commencerez à travailler sur l'implémentation de Composer et de Database , il est beaucoup plus facile d'avoir une classe Composer distincte. En particulier, avoir des opérations atomiques distinctes sur un objet Composer simplifie considérablement l'implémentation des méthodes Display() dans la classe Database.
Bien entendu, il existe aussi une approche de la surobjectification de l'objectif. où nous essayons de tout transformer en classe, ou nous avons plus de classes que nécessaire. Il faut pour trouver le bon équilibre. Vous constaterez que chaque programmeur auront des opinions divergentes.
Il est souvent possible de déterminer si votre objectif est au-dessus ou en dessous de votre objectif créer des diagrammes de vos classes. Comme nous l'avons vu, il est important de préparer un cours conception avant de commencer à coder, ce qui peut vous aider à analyser votre approche. Une approche utilisée à cette fin est UML (langage de modélisation unifié) Maintenant que nous avons défini les classes pour les objets Composer et Database, nous devons une interface qui permet à l'utilisateur d'interagir avec la base de données. Un menu simple faire l'astuce:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Nous pourrions implémenter l'interface utilisateur en tant que classe ou en tant que programme procédural. Non tout ce qui se trouve dans un programme C++ doit être une classe. En fait, si le traitement est séquentiel ou axée sur les tâches, comme dans ce programme de menu, vous pouvez l'implémenter de manière procédurale. Il est important de l'implémenter de telle sorte qu'elle reste un "espace réservé", Ainsi, si nous voulons créer une interface utilisateur graphique à un moment donné, nous devons n'avez pas à modifier quoi que ce soit dans le système, mais l'interface utilisateur.
La dernière chose dont nous avons besoin pour compléter l'application est un programme pour tester les classes. Pour la classe Composer, nous voulons un programme main() qui reçoit des entrées, remplit une Composer, puis l'affiche pour vérifier que la classe fonctionne correctement. Nous voulons également appeler toutes les méthodes de la classe Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Nous avons besoin d'un programme de test similaire pour la classe Database.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Ces programmes de test simples sont une bonne première étape, d'inspecter manuellement la sortie pour s'assurer que le programme fonctionne correctement. En tant que un système prend plus de place, l'inspection manuelle des résultats devient rapidement irréalisable. Dans une leçon ultérieure, nous présenterons des programmes de test d'auto-vérification sous la forme des tests unitaires.
La conception de notre application est maintenant terminée. L'étape suivante consiste à implémenter les fichiers .cpp pour les classes et l'interface utilisateur.Pour commencer, continuez et copiez/collez le code .h et le code du pilote de test ci-dessus dans des fichiers, puis compilez-les.Utilisez les pilotes de test pour tester vos classes. Implémentez ensuite l'interface suivante:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Utilisez les méthodes que vous avez définies dans la classe Database pour implémenter l'interface utilisateur. Assurez-vous que vos méthodes sont infaillibles. Par exemple, un classement doit toujours se situer dans la plage 1 à 10. Ne laissez personne ajouter 101 compositeurs non plus, à moins que vous ne prévoyiez de modifier la structure de données de la classe Database.
N'oubliez pas que tout votre code doit respecter nos conventions de codage, qui sont répétées ici pour plus de commodité:
- Chaque programme que nous écrivons commence par un commentaire d'en-tête, fournissant le nom du l'auteur, ses coordonnées, une brève description et l'usage qui en est fait (le cas échéant) Chaque fonction/méthode commence par un commentaire sur son fonctionnement et son utilisation.
- Nous ajoutons des commentaires explicatifs en utilisant des phrases complètes chaque fois que le code le fait. ne se documentent pas, par exemple, si le traitement est complexe ou peu évident intéressantes ou importantes.
- Utilisez toujours des noms descriptifs: les variables sont des mots en minuscules séparés par _, comme dans ma_variable. Les noms de fonction/méthode utilisent des lettres majuscules pour indiquer les mots, comme dans MyExcitingFunction(). Les constantes commencent par un "k" et utiliser des lettres majuscules pour marquer les mots, comme dans kDaysInWeek.
- Le retrait est un multiple de deux. Le premier niveau comprend deux espaces ; si vous souhaitez une indentation est nécessaire, nous utilisons quatre espaces, six espaces, etc.
Bienvenue dans le monde réel !
Dans ce module, nous présentons deux outils très importants utilisés dans la plupart des ingénieurs logiciel pour les entreprises. Le premier est un outil de compilation, et le second est un outil de gestion du système d'exploitation. Ces deux outils sont essentiels en ingénierie logicielle industrielle, où de nombreux ingénieurs travaillent souvent sur un grand système. Ces outils aident à coordonner et de contrôler les modifications apportées au code base et constituent un moyen efficace de compiler et de lier un système à partir de nombreux fichiers de programme et d'en-tête.
Fichiers de création
Le processus de création d'un programme est généralement géré avec un outil de compilation, qui compile et associe les fichiers requis, dans le bon ordre. Très souvent, les fichiers C++ ont dépendances : par exemple, une fonction appelée dans un programme se trouve dans un autre programme. Ou peut-être qu'un fichier d'en-tête est nécessaire pour plusieurs fichiers .cpp différents. A l'outil de compilation détermine l'ordre de compilation correct à partir de ces dépendances. Il va également uniquement les fichiers qui ont été modifiés depuis la dernière compilation. Cela peut vous faire gagner beaucoup de temps dans des systèmes composés de plusieurs centaines ou milliers de fichiers.
Un outil de compilation Open Source appelé make est couramment utilisé. Pour en savoir plus, consultez par ce . Essayez de créer un graphique de dépendances pour l'application de base de données Composer. puis le traduire en un fichier makefile.Voici notre solution.
Systèmes de gestion de configuration
Le deuxième outil utilisé en ingénierie logicielle industrielle est la gestion de configuration (CM). Ceci est utilisé pour gérer les modifications. Disons que Bob et Suzanne sont tous deux rédacteurs techniques et tous deux travaillent sur la mise à jour d’un manuel technique. Lors d'une réunion, ses le gestionnaire attribue à chacun une section du même document à mettre à jour.
Le manuel technique est stocké sur un ordinateur auquel Bob et Susan peuvent tous les deux accéder. Si aucun outil ou processus de gestion de la configuration n'est en place, un certain nombre de problèmes peuvent survenir. Un scénario possible est que l'ordinateur stockant le document peut être configuré de sorte que Bob et Suzanne ne peuvent pas travailler sur le manuel en même temps. Cela ralentirait considérablement.
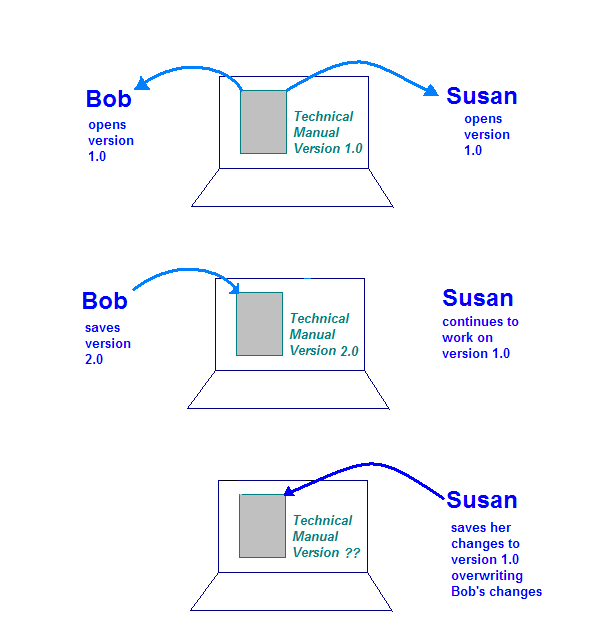
Une situation plus dangereuse se produit lorsque l'ordinateur de stockage autorise le document par Bob et Susan en même temps. Voici ce qui peut se produire:
- Bob ouvre le document sur son ordinateur et travaille sur sa section.
- Susan ouvre le document sur son ordinateur et travaille sur sa section.
- Bob termine ses modifications et enregistre le document sur l'ordinateur de stockage.
- Susan termine ses modifications et enregistre le document sur l'ordinateur de stockage.
Cette illustration montre le problème qui peut survenir en l'absence de commandes sur l'unique exemplaire du manuel technique. Lorsque Susan enregistre ses modifications, elle remplace celles créées par Bob.
C'est exactement le type de situation qu'un système de gestion de la configuration peut contrôler. Avec un Community Manager Bob et Suzanne retiennent tous les deux ses propres ressources techniques manuellement et de travailler dessus. Lorsque Bob vérifie à nouveau ses modifications, le système sait que Susan a vérifié sa propre copie. Lorsque Susan vérifie sa copie, le système analyse les modifications apportées par Bob et Susan, et crée une nouvelle version fusionne les deux ensembles de modifications.
Les systèmes de gestion de la configuration offrent un certain nombre de fonctionnalités qui vont au-delà de la gestion des modifications simultanées, comme décrit ici. ci-dessus. De nombreux systèmes stockent les archives de toutes les versions d'un document, de la première l'heure de création. Dans le cas d'un manuel technique, cela peut être très utile Lorsqu'un utilisateur a une ancienne version du manuel et pose des questions à un rédacteur technique. Un système CM permettrait au rédacteur technique d’accéder à l’ancienne version et de pouvoir pour voir ce que l'utilisateur voit.
Les systèmes CM sont particulièrement utiles pour contrôler les modifications apportées aux logiciels. Telles sont appelés systèmes de gestion de la configuration logicielle (SCM). Si vous envisagez le grand nombre de fichiers de code source individuels dans un grand organisation et le nombre colossal d'ingénieurs qui doivent les modifier, il est clair qu'un système SCM est essentiel.
Gestion de la configuration logicielle
Les systèmes SCM reposent sur une idée simple: les copies définitives de vos fichiers sont conservés dans un référentiel central. Les gens consultent des copies des fichiers du référentiel, travailler sur ces copies, puis les vérifier lorsqu'elles ont terminé. SCM les systèmes gèrent et suivent les révisions par plusieurs personnes sur un seul maître. défini.
Tous les systèmes SCM offrent les fonctionnalités essentielles suivantes:
- Gestion de la simultanéité
- Gestion des versions
- Synchronisation
Examinons chacune de ces fonctionnalités plus en détail.
Gestion de la simultanéité
La simultanéité fait référence à la modification simultanée d'un fichier par plusieurs personnes. Nous voulons que les utilisateurs puissent faire cela avec un dépôt volumineux, à certains problèmes.
Prenons un exemple simple dans le domaine de l'ingénierie: supposons que nous autorisions les ingénieurs de modifier le même fichier simultanément dans un dépôt central du code source. Les clients 1 et 2 doivent tous deux modifier un fichier en même temps:
- Client1 ouvre bar.cpp.
- Client2 ouvre bar.cpp.
- Client1 modifie le fichier et l'enregistre.
- Client2 modifie le fichier et l'enregistre en remplaçant les modifications apportées par Client1.
Évidemment, nous ne voulons pas que cela se produise. Même si nous contrôlions la situation en les deux ingénieurs travaillent sur des copies distinctes plutôt que directement sur un fichier maître. (comme dans l'illustration ci-dessous), les copies doivent être rapprochées. La plupart Les systèmes SCM gèrent ce problème en permettant à plusieurs ingénieurs de vérifier un fichier ("synchroniser" ou "mettre à jour") et apporter des modifications si nécessaire. Le SCM le système exécute ensuite des algorithmes pour fusionner les modifications à mesure que les fichiers sont réévalués ("envoyer" ou "commit") au dépôt.
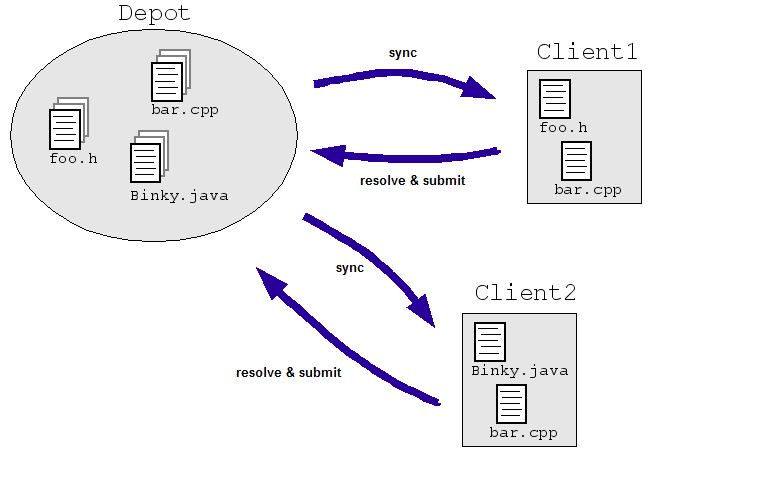
Ces algorithmes peuvent être simples (demander aux ingénieurs de résoudre les modifications incompatibles). ou pas si simple (déterminez comment fusionner intelligemment les modifications conflictuelles). et demandez uniquement à un ingénieur si le système se bloque vraiment).
Gestion des versions
La gestion des versions consiste à suivre les révisions de fichiers, ce qui permet recréer (ou effectuer un rollback) vers une version précédente du fichier Pour ce faire, en faisant une copie d’archive de chaque fichier lorsqu’il est enregistré dans le référentiel, ou en enregistrant chaque modification apportée à un fichier. Nous pouvons à tout moment utiliser les archives ou modifier des informations pour créer une version précédente. Les systèmes de gestion des versions peuvent également créer des rapports de journaux indiquant qui a signalé les modifications, à quel moment les changements ont été apportés.
Synchronisation
Avec certains systèmes SCM, des fichiers individuels sont enregistrés et retirés du dépôt. Des systèmes plus puissants vous permettent de consulter plusieurs fichiers à la fois. Ingénieurs découvrir sa propre copie complète du référentiel (ou une partie de celui-ci) et des travaux sur les fichiers selon les besoins. Ils valident ensuite leurs modifications dans le dépôt maître. régulièrement, et mettre à jour leurs propres copies personnelles pour vous tenir informé des changements. d'autres personnes. Ce processus est appelé synchronisation ou mise à jour.
Subversion
Subversion (SVN) est un système de contrôle des versions Open Source. Il contient toutes les les fonctionnalités décrites ci-dessus.
La SVN adopte une méthodologie simple en cas de conflit. Un conflit se produit lorsque deux ou plus d'ingénieurs apportent des modifications différentes à la même zone du code base. puis envoient tous les deux leurs modifications. Le service SVN avertit uniquement les ingénieurs qu'un le conflit - il appartient aux ingénieurs de le résoudre.
Nous allons utiliser SVN tout au long de ce cours pour vous aider à vous familiariser avec la gestion de la configuration. Ces systèmes sont très courants dans le secteur.
La première étape consiste à installer SVN sur votre système. Cliquez sur cliquez ici pour découvrir instructions. Recherchez votre système d'exploitation et téléchargez le binaire approprié.
Terminologie liée aux SVN
- Révision: modification apportée à un fichier ou à un ensemble de fichiers. Une révision est un "instantané" dans un projet en constante évolution.
- Dépôt: copie principale dans laquelle le SVN stocke l'historique complet des révisions d'un projet. Chaque projet dispose d'un dépôt.
- Working Copy (Copie de travail) : la copie dans laquelle un ingénieur apporte des modifications à un projet. Il y Il peut s'agir de plusieurs copies de travail d'un projet donné, chacune appartenant à un ingénieur individuel.
- Règlement: pour demander une copie de travail du dépôt. Une copie de travail est égal à l'état du projet au moment du paiement.
- Commit: pour envoyer les modifications de votre copie de travail vers le référentiel central. Également appelé "enregistrement" ou "envoi".
- Nouveauté: Pour inviter d'autres personnes les modifications du dépôt dans votre copie de travail, ou pour indiquer si votre copie de travail comporte des modifications non validées. Il s'agit de la identique à une synchronisation, comme décrit ci-dessus. Ainsi, la mise à jour/synchronisation apporte votre copie de travail à jour avec la copie du dépôt.
- Conflit: situation dans laquelle deux ingénieurs tentent d'apporter des modifications au même d'un fichier. SVN indique les conflits, mais les ingénieurs doivent les résoudre.
- Message de journal: commentaire que vous joignez à une révision lorsque vous la validez, et qui décrit vos modifications. Le journal fournit un résumé de ce qui s'est passé dans un projet.
Maintenant que SVN est installé, nous allons passer en revue quelques commandes de base. La la première chose à faire est de configurer un dépôt dans un répertoire spécifié. Voici les commandes:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
La commande import copie le contenu du répertoire mytree dans le dans le dépôt. Nous pouvons jeter un œil au répertoire à l'aide de la commande list.
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
L'importation ne crée pas de copie de travail. Pour ce faire, vous devez utiliser le fichier svn paiement. Cela crée une copie de travail de l'arborescence de répertoires. faites-le maintenant:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Maintenant que vous disposez d'une copie de travail, vous pouvez modifier les fichiers et les répertoires ici. Votre copie de travail est comme n'importe quelle autre collection de fichiers et de répertoires vous pouvez en ajouter d'autres, les modifier, les déplacer et même supprimer l'intégralité du texte de travail. Notez que si vous copiez et déplacez des fichiers dans votre copie de travail, utilisez svn copy et svn move plutôt que vos les commandes du système d'exploitation. Pour ajouter un fichier, utilisez svn add et pour supprimer utilisez la commande svn delete. Si vous souhaitez simplement effectuer des modifications, il vous suffit d'ouvrir le avec votre éditeur et modifiez-le !
Il existe certains noms de répertoire standard souvent utilisés avec Subversion. La "jonction" annuaire qui constitue la principale ligne de développement de votre projet. Une "branche" annuaire contient toutes les versions de branche sur lesquelles vous pourriez travailler.
$ svn list file:///usr/local/svn/repos /trunk /branches
Par conséquent, disons que vous avez apporté toutes les modifications nécessaires à votre copie de travail et vous souhaitez le synchroniser avec le dépôt. Si beaucoup d'autres ingénieurs travaillent dans cette zone du référentiel, il est important de maintenir votre copie de travail à jour. Utilisez la commande svn status pour afficher les modifications.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Notez que la commande status contient de nombreux indicateurs pour contrôler ce résultat. Si vous souhaitez afficher les modifications spécifiques apportées à un fichier modifié, utilisez la commande svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Enfin, pour mettre à jour votre copie de travail à partir du dépôt, utilisez la commande svn update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
C’est un endroit où un conflit peut se produire. Dans la sortie ci-dessus, le « U » indique aucune modification n'a été apportée aux versions du dépôt de ces fichiers et une mise à jour est terminée. Le "G" signifie qu'une fusion a eu lieu. La version du dépôt contenait ont été modifiées, mais qu'elles n'entrent pas en conflit avec les vôtres. Le "C" indique un conflit. Cela signifie que les modifications du dépôt chevauchent les vôtres, et maintenant vous devez choisir entre eux.
Pour chaque fichier en conflit, Subversion place trois fichiers dans votre fichier de travail copie:
- file.mine: il s'agit de votre fichier tel qu'il existait dans votre copie de travail avant que mis à jour votre copie de travail.
- file.rOLDREV: il s'agit du fichier que vous avez extrait du dépôt avant vous apportez vos modifications.
- file.rNEWREV: ce fichier correspond à la version actuelle dans le dépôt.
Pour résoudre le conflit, vous pouvez utiliser l'une des trois méthodes suivantes:
- Parcourez les fichiers et effectuez la fusion manuellement.
- Copiez l'un des fichiers temporaires créés par SVN sur votre version de travail.
- Exécutez svn return pour supprimer toutes vos modifications.
Une fois le conflit résolu, vous pouvez en informer SVN en exécutant la commande svn fixed. Cette opération supprime les trois fichiers temporaires, et SVN n'affiche plus le fichier dans une en conflit.
La dernière étape consiste à valider la version finale dans le dépôt. Ce s'effectue via la commande svn commit. Lorsque vous validez une modification, vous avez besoin pour fournir un message de journal décrivant vos modifications. Ce message de journal est joint à la révision que vous créez.
svn commit -m "Update files to include new headers."
Il y a tant de choses à apprendre sur SVN et sur la façon dont il peut prendre en charge des logiciels projets d’ingénierie. De nombreuses ressources sont disponibles sur le Web. recherchez "Subversion" sur Google.
Pour vous entraîner, créez un dépôt pour votre système de base de données Composer et importez tous vos fichiers. Ensuite, consultez une copie de travail et exécutez les commandes décrites ci-dessus.
Références
Online Subversion Book (Livre de sous-version en ligne)
Article Wikipédia sur l'extension SVN
Application: une étude sur l'anatomie
Découvrez les eSkeletons de l'université du Texas à Austin