Hướng dẫn ngôn ngữ C++
Các phần đầu của nội dung này hướng dẫn đề cập đến những tài liệu cơ bản đã trình bày trong hai mô-đun cuối cùng, đồng thời cung cấp thêm thông tin về các khái niệm nâng cao. Trọng tâm trong mô-đun này là vào bộ nhớ động và thông tin chi tiết khác về các đối tượng và lớp. Chúng tôi cũng giới thiệu một số chủ đề nâng cao, như tính kế thừa, tính đa hình, mẫu, ngoại lệ và không gian tên. Chúng ta sẽ nghiên cứu những khía cạnh này sau trong khoá học C++ nâng cao.
Thiết kế hướng đối tượng
Đây là một tính năng xuất sắc hướng dẫn về thiết kế hướng đối tượng. Chúng tôi sẽ áp dụng được trình bày ở đây trong dự án của học phần này.
Tìm hiểu theo Ví dụ 3
Trọng tâm của chúng ta trong học phần này là cách thực hành nhiều hơn với con trỏ, hướng đối tượng thiết kế, mảng đa chiều và lớp/đối tượng. Hãy thực hiện các bước sau ví dụ. Chúng tôi không thể nhấn mạnh đủ rõ rằng chìa khoá để trở thành một lập trình viên giỏi là thực hành, thực hành và thực hành!Bài tập số 1: Thực hành thêm bằng con trỏ
Nếu bạn cần thực hành thêm về con trỏ, hãy đọc hết thế này Tài nguyên này bao gồm tất cả các khía cạnh của con trỏ và cung cấp nhiều ví dụ về chương trình.
Kết quả của chương trình sau đây là gì? Vui lòng không chạy chương trình, nhưng vẽ hình ảnh bộ nhớ để xác định đầu ra.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Khi bạn đã tự xác định được kết quả, hãy chạy chương trình để xem liệu bạn chính xác.
Bài tập số 2: Thực hành thêm với lớp và đối tượng
Nếu cần thực hành thêm về lớp và đối tượng, tại đây là một tài nguyên trải qua quá trình triển khai hai lớp nhỏ. Chụp một số thời gian thực hiện các bài tập thể dục.
Bài tập số 3: Mảng nhiều chiều
Hãy cân nhắc sử dụng chương trình sau:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Có một dòng trong chương trình này được đánh dấu là "Đường kẻ này hoạt động như thế nào?" – bạn có thể tìm ra không? Đây là nội dung giải thích của chúng tôi.
Viết một chương trình khởi tạo một mảng 3 mờ và lấp đầy chiều thứ 3 bằng tổng của cả ba chỉ số. Đây là giải pháp của chúng tôi.
Bài tập số 4: Ví dụ về thiết kế OO mở rộng
Sau đây là hướng dẫn chi tiết ví dụ về thiết kế hướng đối tượng, sẽ đi qua toàn bộ từ đầu đến cuối. Mã cuối cùng được viết bằng Java ngôn ngữ lập trình của mình, nhưng bạn sẽ có thể đọc qua ngôn ngữ đó mặc dù bạn đã đến.
Vui lòng dành thời gian để xem qua toàn bộ ví dụ này. Thật tuyệt vời hình minh hoạ quy trình và các công cụ thiết kế hỗ trợ quy trình đó.
Kiểm thử đơn vị
Giới thiệu
Kiểm thử là một phần quan trọng trong quy trình kỹ thuật phần mềm. Kiểm thử đơn vị là một loại kiểm thử cụ thể, kiểm tra chức năng của một đoạn mã mô-đun của mã nguồn.Việc kiểm thử đơn vị luôn do kỹ sư thực hiện và thường được thực hiện cùng lúc chúng mã hoá mô-đun. Trình điều khiển thử nghiệm mà bạn dùng để kiểm thử các lớp Composer và Database (Cơ sở dữ liệu) là các ví dụ về kiểm thử đơn vị.
Kiểm thử đơn vị có các đặc điểm sau. Họ...
- kiểm thử một thành phần riêng biệt
- mang tính tất định
- thường ánh xạ vào một lớp duy nhất
- tránh phụ thuộc vào tài nguyên bên ngoài, ví dụ: cơ sở dữ liệu, tệp, mạng
- thực thi nhanh chóng
- có thể chạy theo thứ tự bất kỳ
Có các khung và phương pháp tự động hỗ trợ và tính nhất quán để kiểm thử đơn vị trong các tổ chức kỹ thuật phần mềm lớn. Có một số khung kiểm thử đơn vị nguồn mở tinh vi mà chúng tôi sẽ sẽ tìm hiểu ở phần sau trong bài học này.
Các hoạt động kiểm thử diễn ra trong quá trình kiểm thử đơn vị được minh hoạ bên dưới.

Trong một thế giới lý tưởng, chúng tôi thử nghiệm những yếu tố sau:
- Kiểm thử giao diện mô-đun để đảm bảo thông tin được truyền vào và ra chính xác.
- Cấu trúc dữ liệu cục bộ sẽ được kiểm tra để đảm bảo lưu trữ dữ liệu đúng cách.
- Kiểm tra các điều kiện về ranh giới để đảm bảo mô-đun hoạt động chính xác tại các ranh giới giới hạn hoặc hạn chế việc xử lý.
- Chúng tôi kiểm thử các đường dẫn độc lập thông qua mô-đun này để đảm bảo mỗi đường dẫn, và
do đó, mỗi câu lệnh trong mô-đun sẽ được thực thi ít nhất một lần.
- Cuối cùng, chúng ta cần kiểm tra xem lỗi có được xử lý đúng cách hay không.
Mức độ bao phủ của mã
Trong thực tế, chúng ta không thể đạt được "mức độ sử dụng mã" hoàn chỉnh với thử nghiệm của chúng tôi. Mức độ sử dụng mã là một phương pháp phân tích giúp xác định phần nào của một phần mềm hệ thống đã được bộ trường hợp kiểm thử thực thi (bao gồm) và những phần nào được chưa được thực thi. Nếu cố gắng và đạt được mức độ phù hợp 100%, chúng tôi sẽ tốn nhiều thời gian hơn viết mã kiểm thử đơn vị thay vì viết mã thực tế! Hãy cân nhắc việc nghĩ ra đơn vị kiểm thử mọi đường dẫn độc lập của các mã sau. Điều này có thể nhanh chóng trở thành bài toán theo cấp số nhân.

Trong sơ đồ này, các đường màu đỏ không được kiểm tra, trong khi các đường không màu được đã kiểm tra.
Thay vì cố gắng đảm bảo mức độ phù hợp 100%, chúng tôi tập trung vào các thử nghiệm giúp tăng độ tin cậy rằng mô-đun đang hoạt động đúng cách. Chúng tôi kiểm tra những khía cạnh như:
- Trường hợp rỗng
- Kiểm tra phạm vi, ví dụ: kiểm tra giá trị dương/âm
- Vỏ máy cạnh
- Trường hợp lỗi
- Kiểm thử những đường dẫn có nhiều khả năng thực thi nhất
Khung kiểm thử đơn vị
Hầu hết các khung kiểm thử đơn vị đều sử dụng câu nhận định để kiểm thử giá trị trong quá trình thực thi một đường dẫn. Câu nhận định là những tuyên bố kiểm tra xem một điều kiện có đúng hay không. Chiến lược phát hành đĩa đơn kết quả của xác nhận có thể là thành công, thất bại không nghiêm trọng hoặc thất bại nghiêm trọng. Sau một xác nhận được thực hiện, chương trình sẽ tiếp tục bình thường nếu kết quả là thành công hay thất bại không nghiêm trọng. Nếu xảy ra lỗi nghiêm trọng, hàm hiện tại bị huỷ bỏ.
Kiểm thử bao gồm mã thiết lập trạng thái hoặc điều khiển mô-đun, kết hợp với một số câu nhận định xác minh kết quả mong đợi. Nếu tất cả câu nhận định trong một lượt kiểm thử có thành công, tức là trả về giá trị true thì kiểm thử thành công; nếu không thì ứng dụng sẽ không hoạt động.
Mỗi trường hợp kiểm thử chứa một hoặc nhiều lượt kiểm thử. Chúng tôi nhóm các bài kiểm thử thành các trường hợp kiểm thử phản ánh cấu trúc của mã được kiểm thử. Trong khoá học này, chúng tôi sẽ sử dụng CPPUnit làm khung kiểm thử đơn vị của chúng tôi. Với khung này, chúng ta có thể viết mã kiểm thử đơn vị trong C++ và chạy chúng tự động, đưa ra báo cáo về mức độ thành công hay không thành công kiểm thử.
Cài đặt CPPUnit
Tải mã CPPUnit từ SourceForge. Tìm một thư mục thích hợp và đặt tệp tar.gz ở đó. Sau đó, nhập các lệnh sau (trong Linux, Unix), thay thế tệp cppunit thích hợp tên:
gunzip filename.tar.gz tar -xvf filename.tar
Nếu đang làm việc trong Windows, bạn có thể cần phải tìm một tiện ích để trích xuất tar.gz tệp. Bước tiếp theo là biên dịch thư viện. Thay đổi thành thư mục cppunit. Ở đó có một tệp INSTALL cung cấp hướng dẫn cụ thể. Thông thường, bạn cần chạy:
./configure make install
Nếu bạn gặp vấn đề, hãy tham khảo tệp INSTALL. Các thư viện thường có trong thư mục cppunit/src/cppunit. Để kiểm tra xem quá trình biên dịch có hoạt động không, hãy chuyển đến thư mục cppunit/examples/simple rồi nhập "make". Nếu mọi thứ biên dịch được rồi, vậy là bạn đã hoàn tất.
Hiện có một hướng dẫn tuyệt vời tại đây. Vui lòng xem qua hướng dẫn này để tạo lớp số phức cùng với các lớp liên kết kiểm thử đơn vị. Có một số ví dụ khác trong thư mục cppunit/examples.
Tại sao tôi phải làm việc này{3}
Kiểm thử đơn vị có vai trò cực kỳ quan trọng trong ngành vì một số lý do. Bạn đã quen thuộc với một lý do: Chúng tôi cần một cách nào đó để kiểm tra công việc trong khi đang phát triển mã. Ngay cả khi đang phát triển một chương trình rất nhỏ, theo bản năng, chúng tôi hãy viết một số loại trình kiểm tra hoặc trình điều khiển để đảm bảo chương trình của chúng ta thực hiện những gì được mong đợi.
Với kinh nghiệm lâu năm, các kỹ sư sẽ biết rằng cơ hội để một chương trình thành công ở lần thử đầu tiên là rất nhỏ. Kiểm thử đơn vị dựa trên ý tưởng này bằng cách thực hiện kiểm thử chương trình tự kiểm tra và có thể lặp lại. Câu nhận định thay cho câu trả lời thủ công đang kiểm tra đầu ra. Và, vì dễ diễn giải kết quả (công cụ thử nghiệm dù đạt hoặc không đạt), có thể chạy đi chạy lại kiểm thử, cung cấp một mạng lưới an toàn giúp mã dễ thay đổi hơn.
Hãy đặt điều này một cách cụ thể: Khi bạn gửi mã hoàn chỉnh của mình lần đầu tiên vào CVS hoạt động hoàn hảo. Và nó vẫn tiếp tục hoạt động hoàn hảo trong một thời gian. Sau đó một ngày, người khác sẽ thay đổi mã của bạn. Chẳng bao lâu nữa có người sẽ tan vỡ mã của bạn. Bạn có cho rằng chúng sẽ tự mình chú ý đến không? Không có khả năng. Nhưng khi bạn viết mã kiểm thử đơn vị, có những hệ thống có thể tự động chạy kiểm thử đó mỗi ngày. Đây được gọi là các hệ thống tích hợp liên tục. Khi kỹ sư đó X làm hỏng mã của bạn, hệ thống sẽ gửi các email làm phiền cho họ cho đến khi họ khắc phục nó. Kể cả khi kỹ sư X chính là BẠN!
Ngoài việc giúp bạn phát triển phần mềm rồi bảo vệ an toàn phần mềm đó khi có thay đổi, kiểm thử đơn vị:
- Tạo một quy cách có thể thực thi và tài liệu luôn được đồng bộ hoá với mã. Nói cách khác, bạn có thể đọc một bài kiểm thử đơn vị để tìm hiểu về mà mô-đun hỗ trợ.
- Giúp bạn tách biệt yêu cầu với việc triển khai. Vì bạn đang xác nhận hành vi có thể thấy được bên ngoài, bạn sẽ có cơ hội để suy nghĩ về hành vi đó một cách rõ ràng thay vì kết hợp các ý tưởng về cách triển khai hành vi.
- Hỗ trợ thử nghiệm. Nếu có mạng lưới an toàn để cảnh báo cho bạn khi bạn đã phá vỡ hành vi của một mô-đun, có nhiều khả năng bạn sẽ thử mọi thứ và định cấu hình lại các thiết kế của mình.
- Cải thiện thiết kế của bạn. Việc viết mã kiểm thử đơn vị kỹ lưỡng thường yêu cầu bạn giúp mã dễ kiểm thử hơn. Mã có thể kiểm thử thường có tính mô-đun cao hơn so với mã không thể kiểm thử .
- Duy trì chất lượng cao. Lỗi nhỏ trong một hệ thống quan trọng có thể khiến công ty để mất hàng triệu đô la, hoặc thậm chí tệ hơn là niềm vui hoặc sự tin tưởng của người dùng. Chiến lược phát hành đĩa đơn mạng lưới an toàn giúp giảm thiểu khả năng này khi kiểm thử đơn vị. Bằng cách phát hiện lỗi từ sớm, chúng cũng cho phép nhóm QA dành thời gian vào những nội dung phức tạp và khó tình huống lỗi thay vì báo cáo các lỗi rõ ràng.
Dành thời gian viết mã kiểm thử đơn vị bằng CPPUnit cho ứng dụng cơ sở dữ liệu Composer. Hãy tham khảo thư mục cppunit/examples/ để được trợ giúp.
Cách Google hoạt động
Giới thiệuHãy tưởng tượng một nhà sư thời Trung Cổ đang xem hàng nghìn bản thảo bằng những kho lưu trữ tu viện của mình."Ở đâu bài hát của Aristotle..."

Thật may cho ông là các bản thảo được sắp xếp theo nội dung và được ghi chữ bằng các ký hiệu đặc biệt giúp truy xuất thông tin chứa trong mỗi. Nếu không có tổ chức như vậy, sẽ rất khó để tìm ra bản thảo.
Hoạt động lưu trữ và truy xuất thông tin dạng văn bản từ các tập hợp lớn có tên là Truy xuất thông tin (IR). Hoạt động này ngày càng trở nên đóng vai trò quan trọng qua nhiều thế kỷ, đặc biệt là với các phát minh như giấy và kỹ thuật in ấn bấm. Nơi đây từng là nơi chỉ có vài người có mặt. Bây giờ, Tuy nhiên, hàng trăm triệu người tham gia vào việc truy xuất thông tin mỗi ngày khi họ sử dụng công cụ tìm kiếm hoặc tìm kiếm trên máy tính để bàn của họ.
Bắt đầu truy xuất thông tin

Tiến sĩ Seuss đã viết 46 cuốn sách dành cho trẻ em trong suốt 30 năm. Sách của ông ấy bảo gồm mèo, bò và voi, về loài nào, cười toe toét và chim chóc. Bạn còn nhớ không sinh vật nào trong câu chuyện nào? Trừ phi bạn là cha mẹ, chỉ trẻ em mới có thể cho bạn biết loạt truyện nào về Tiến sĩ Seuss có các nhân vật:
(COW và BEE) hoặc CROWS
Chúng tôi sẽ áp dụng một số mô hình truy xuất thông tin cũ để giúp giải quyết vấn đề này vấn đề.
Một cách tiếp cận rõ ràng là brute force: Xem toàn bộ 46 câu chuyện về Tiến sĩ Seuss và bắt đầu đọc tin tức. Đối với mỗi cuốn sách, hãy chú ý xem(những) dòng nào chứa các từ COW và BEE, và cùng một lúc, hãy tìm những cuốn sách có chứa từ CROWS. Máy tính chiếm rất nhiều nhanh hơn chúng tôi. Nếu chúng ta có toàn bộ nội dung trong các cuốn sách về Tiến sĩ Seuss ở dạng kỹ thuật số, chẳng hạn như tệp văn bản, chúng tôi có thể chỉ cần grep thông qua các tệp. Đối với như những cuốn sách của bác sĩ Seuss, thì kỹ thuật này rất hiệu quả.
Tuy nhiên, trong nhiều trường hợp, chúng tôi cần thêm thông tin. Ví dụ: bộ sưu tập của tất cả dữ liệu hiện đang trực tuyến là quá lớn đối với grep để xử lý. Chúng tôi cũng không chỉ muốn có các tài liệu phù hợp với điều kiện của mình, chúng ta đã quen với để chúng được xếp hạng theo mức độ liên quan.
Một phương pháp khác ngoài grep là tạo chỉ mục của các tài liệu trong một tập hợp trước khi thực hiện tìm kiếm. Chỉ số ở IR tương tự như chỉ số ở mặt sau của một cuốn sách giáo khoa. Chúng tôi tạo một danh sách tất cả các từ (hoặc thuật ngữ) trong mỗi Câu chuyện của bác sĩ Seuss, bỏ qua những từ như "cái", "và" và các thành phần liên kết khác, giới từ, v.v. (được gọi là từ dừng). Sau đó, chúng tôi đại diện thông tin này theo cách dễ dàng hơn trong việc tìm các cụm từ và nhận dạng những câu chuyện mà họ đang góp mặt.
Một cách thể hiện khả thi là ma trận với các câu chuyện ở trên cùng, và các cụm từ được liệt kê trên mỗi hàng. Số "1" trong một cột cho biết từ khoá đó xuất hiện trong câu chuyện cho cột đó.
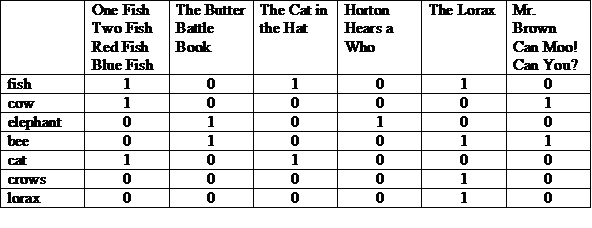
Chúng ta có thể xem mỗi hàng hoặc cột ở dạng vectơ bit. Vectơ bit của một hàng biểu thị có tin bài mà từ khoá đó xuất hiện. Vectơ bit của cột cho biết những thuật ngữ nào xuất hiện trong câu chuyện.
Quay lại vấn đề ban đầu của chúng ta:
(COW và BEE) hoặc CROWS
Chúng ta lấy các vectơ bit cho các số hạng này rồi trước tiên thực hiện phép toán bit AND, sau đó thực hiện một chút HOẶC cho kết quả.
(100001 và 010011) hoặc 000010 = 000011
Câu trả lời: “Mr. Nâu Can Moo! Bạn có thể không?” và "The Lorax". Đây là hình minh hoạ của mô hình Truy xuất Boolean, là mô hình "khớp chính xác".
Giả sử chúng ta mở rộng ma trận để đưa mọi câu chuyện của Tiến sĩ Seuss và tất cả từ ngữ liên quan trong tin bài. Ma trận sẽ phát triển đáng kể và đóng vai trò quan trọng quan sát là hầu hết các mục sẽ là 0. Ma trận có lẽ không phải là tốt nhất biểu diễn cho chỉ mục đó. Chúng ta cần tìm cách lưu trữ chỉ số 1.
Một số tính năng nâng cao
Cấu trúc được sử dụng trong IR để giải quyết vấn đề này được gọi là chỉ số đảo ngược. Chúng tôi lưu từ điển các thuật ngữ, và sau đó đối với mỗi thuật ngữ, chúng tôi có một danh sách ghi lại các tài liệu có cụm từ đó. Danh sách này gọi là bài đăng danh sách. Danh sách được liên kết đơn sẽ phù hợp để thể hiện cấu trúc này như minh hoạ bên dưới.

Nếu không quen với danh sách được liên kết, bạn chỉ cần tìm kiếm trên Google trên "được liên kết
trong C++" và bạn sẽ tìm thấy nhiều tài nguyên mô tả cách tạo một
tài nguyên,
và cách sử dụng. Chúng ta sẽ tìm hiểu kỹ hơn về vấn đề này trong một học phần sau.
Lưu ý rằng chúng ta sử dụng Mã tài liệu (DocIDs) thay vì tên của câu chuyện của bạn. Chúng tôi cũng sắp xếp các mã tài liệu này để hỗ trợ việc xử lý truy vấn.
Chúng tôi xử lý truy vấn như thế nào? Đối với vấn đề ban đầu, trước tiên, chúng tôi tìm các bài đăng COW danh sách bài đăng, rồi đến danh sách các bài đăng của BEE. Sau đó, chúng tôi “hợp nhất” chúng lại với nhau:
- Đưa các điểm đánh dấu vào cả hai danh sách và kiểm tra hai danh sách bài đăng đồng thời.
- Ở mỗi bước, hãy so sánh DocsID được cả hai con trỏ trỏ đến.
- Nếu chúng giống nhau, hãy đặt DocsID đó trong một danh sách kết quả, nếu không, con trỏ sẽ được đưa lên trỏ đến documentID nhỏ hơn.
Sau đây là cách chúng ta có thể tạo chỉ mục đảo ngược:
- Chỉ định một DocumentID cho từng tài liệu bạn quan tâm.
- Đối với mỗi tài liệu, hãy xác định các thuật ngữ có liên quan (tạo mã thông báo).
- Đối với mỗi cụm từ, hãy tạo một bản ghi bao gồm cụm từ, mã định danh DocsID, trong đó cụm từ đó tìm thấy và tần suất trong tài liệu đó. Xin lưu ý rằng có thể có nhiều các bản ghi cho một thuật ngữ cụ thể nếu thuật ngữ đó xuất hiện trong nhiều tài liệu.
- Sắp xếp bản ghi theo từ khoá.
- Tạo từ điển và danh sách bài đăng bằng cách xử lý các bản ghi đơn lẻ cho một cụm từ, đồng thời kết hợp nhiều bản ghi cho các cụm từ xuất hiện trong nhiều tài liệu. Tạo một danh sách liên kết của các Tài liệu (theo thứ tự được sắp xếp). Một số hạng còn có tần suất là tổng các tần số của tất cả bản ghi cho một cụm từ.
Dự án
Tìm một số tài liệu văn bản thuần tuý dài mà bạn có thể thử nghiệm. Chiến lược phát hành đĩa đơn dự án là tạo một chỉ mục đảo ngược từ các tài liệu bằng cách sử dụng các thuật toán được mô tả ở trên. Bạn cũng cần tạo một giao diện để nhập truy vấn và một công cụ để xử lý chúng. Bạn có thể tìm thấy một đối tác dự án trên diễn đàn.
Dưới đây là quy trình hoàn tất dự án này:
- Việc đầu tiên cần làm là xác định chiến lược để nhận diện các thuật ngữ trong tài liệu. Lập một danh sách tất cả các từ dừng mà bạn có thể nghĩ ra và viết một hàm đọc qua các từ trong tệp, lưu từ khoá và xoá các từ dừng. Bạn có thể phải thêm nhiều từ dừng hơn vào danh sách của mình khi xem xét danh sách số từ lặp lại.
- Viết các trường hợp kiểm thử CPPUnit để kiểm thử chức năng của bạn và một tệp makefile để mang mọi thứ cùng nhau cho bản dựng của bạn. Kiểm tra tệp của bạn trong CVS, đặc biệt nếu bạn khi làm việc với các đối tác. Bạn nên tìm hiểu cách mở thực thể CVS cho các kỹ sư làm việc từ xa.
- Thêm quy trình xử lý để bao gồm dữ liệu vị trí, tức là tệp nào và vị trí trong tệp có phải là một cụm từ không? Có thể bạn muốn tìm một phép tính để xác định số trang hoặc số của đoạn.
- Viết các trường hợp kiểm thử CPPUnit để kiểm thử chức năng bổ sung này.
- Tạo chỉ mục đảo ngược và lưu trữ dữ liệu vị trí trong bản ghi của mỗi thuật ngữ.
- Viết thêm các trường hợp kiểm thử khác.
- Thiết kế giao diện để cho phép người dùng nhập truy vấn.
- Sử dụng thuật toán tìm kiếm được mô tả ở trên, xử lý chỉ mục đảo ngược và trả về dữ liệu vị trí cho người dùng.
- Đừng quên thêm các trường hợp kiểm thử cho phần cuối cùng này.
Như chúng tôi đã làm với tất cả các dự án, hãy sử dụng diễn đàn và trò chuyện để tìm đối tác dự án và chia sẻ ý tưởng.
Tính năng bổ sung
Một bước xử lý phổ biến trong nhiều hệ thống hồng ngoại được gọi là bắt đầu từ đầu (stemming). Chiến lược phát hành đĩa đơn ý tưởng chính của từ xuất phát điểm là người dùng tìm kiếm thông tin về "truy xuất" cũng sẽ quan tâm đến các tài liệu có chứa thông tin "truy xuất", "truy xuất", "truy xuất", v.v. Hệ thống có thể dễ gặp lỗi do cho từ gốc kém, nên việc này hơi phức tạp. Ví dụ: một người dùng quan tâm trong phần "truy xuất thông tin" có thể nhận được tài liệu có tiêu đề "Thông tin về Golden Chó tha mồi" do có nguồn gốc từ chúng. Một thuật toán hữu ích để lấy từ gốc là Thuật toán trình chuyển đổi.