บทแนะนำภาษา C++
ส่วนแรกๆ ของ บทแนะนำ ครอบคลุมเนื้อหาพื้นฐานที่นำเสนอไปแล้ว ใน 2 โมดูลสุดท้าย และให้ข้อมูลเพิ่มเติมเกี่ยวกับแนวคิดขั้นสูง โมดูลนี้จะอยู่ที่หน่วยความจำแบบไดนามิก และรายละเอียดเพิ่มเติมเกี่ยวกับออบเจ็กต์และคลาส นอกจากนี้ยังแนะนำหัวข้อขั้นสูง เช่น การสืบทอดค่า โพลีมอร์ฟิส เทมเพลต ข้อยกเว้นและเนมสเปซ เราจะศึกษาเรื่องนี้กันภายหลังในหลักสูตร C++ ขั้นสูง
การออกแบบที่มุ่งเน้นวัตถุ
นี่เป็น บทแนะนำเกี่ยวกับการออกแบบเชิงวัตถุ เราจะใช้ ซึ่งแสดงไว้ที่นี่ในโปรเจ็กต์ของโมดูลนี้
เรียนรู้จากตัวอย่างที่ 3
เรามุ่งเน้นโมดูลนี้ไปที่การฝึกฝนเพิ่มเติมโดยใช้ตัวชี้ และคำนึงถึงวัตถุ การออกแบบ อาร์เรย์แบบหลายมิติ และคลาส/วัตถุ โปรดทำตามขั้นตอนต่อไปนี้ ตัวอย่าง เราเน้นย้ำความสำคัญของการเป็นโปรแกรมเมอร์ที่ดีได้ คือการฝึกฝน ฝึก และฝึกต่อไปแบบฝึกหัดที่ 1: แบบฝึกหัดที่ 1 มากขึ้นด้วยเคอร์เซอร์
หากต้องการแนวทางปฏิบัติเพิ่มเติมเกี่ยวกับตัวชี้ โปรดอ่าน นี่ ทรัพยากร ซึ่งครอบคลุมเคอร์เซอร์ทุกด้านและมีตัวอย่างโปรแกรมมากมาย
ผลที่ได้จากโปรแกรมต่อไปนี้คืออะไร โปรดอย่าเรียกใช้โปรแกรม วาดภาพความทรงจำเพื่อกำหนดเอาต์พุต
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}เมื่อคุณกำหนดผลลัพธ์ด้วยตนเองแล้ว ให้เรียกใช้โปรแกรมเพื่อดูว่าคุณ ถูกต้อง
แบบฝึกหัดที่ 2: แบบฝึกหัดที่ 2 เกี่ยวกับคลาสและวัตถุ
หากคุณต้องการการฝึกเพิ่มเติมเกี่ยวกับคลาสและออบเจ็กต์ ที่นี่ เป็นแหล่งข้อมูลที่นำไปสู่การนำชั้นเรียนเล็กๆ 2 ชั้นเรียนไปใช้ ลองเลย ถึงเวลาออกกำลังกายแล้ว
แบบฝึกหัดที่ 3: อาร์เรย์หลายมิติ
ลองใช้โปรแกรมต่อไปนี้
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}มีบรรทัดหนึ่งในโปรแกรมนี้ที่ระบุว่า "สายนี้ทำงานอย่างไร" - คุณรู้ไหมว่า นี่คือคำอธิบายของเราที่นี่
เขียนโปรแกรมที่เริ่มต้นอาร์เรย์ 3 สลัวและแสดงมิติที่ 3 ด้วยผลรวมของดัชนีทั้ง 3 รายการ นี่คือวิธีแก้ปัญหา
แบบฝึกหัดที่ 4: ตัวอย่างการออกแบบ OO ที่ครอบคลุม
นี่คือรายละเอียด ตัวอย่างการออกแบบเชิงวัตถุ ซึ่งครอบคลุม ตั้งแต่ต้นจนจบ โค้ดเวอร์ชันสุดท้ายจะเขียนใน Java ภาษาโปรแกรมได้ แต่คุณจะสามารถอ่านจบได้ โดยพิจารณาว่า ใดบ้าง
โปรดใช้เวลากับตัวอย่างนี้ทั้งหมด ซึ่งดีมาก ภาพขั้นตอน และเครื่องมือออกแบบที่รองรับกระบวนการ
การทดสอบหน่วย
บทนำ
การทดสอบเป็นส่วนสำคัญของกระบวนการทางวิศวกรรมซอฟต์แวร์ การทดสอบ 1 หน่วย คือการทดสอบประเภทหนึ่ง ซึ่งจะตรวจสอบฟังก์ชันการทำงานของ ของซอร์สโค้ดวิศวกรจะดำเนินการทดสอบหน่วยเสมอ และ โดยปกติมักจะทำในเวลาเดียวกันกับการเขียนโค้ดโมดูล ไดรเวอร์การทดสอบที่คุณ ที่ใช้ทดสอบคลาส Composer และ Database เป็นตัวอย่างของการทดสอบหน่วย
การทดสอบหน่วยมีลักษณะดังต่อไปนี้ ผู้ลงโฆษณารายนี้...
- ทดสอบคอมโพเนนต์แยกต่างหาก
- เป็นเชิงกำหนด
- โดยปกติจะทำแผนที่คลาสเดียว
- หลีกเลี่ยงการพึ่งพาทรัพยากรภายนอก เช่น ฐานข้อมูล ไฟล์ เครือข่าย
- ดำเนินการอย่างรวดเร็ว
- สามารถทำงานในลำดับใดก็ได้
มีเฟรมเวิร์กและระเบียบวิธีวิจัยอัตโนมัติที่ให้การสนับสนุนและ ความสอดคล้องของการทดสอบ 1 หน่วยในองค์กรด้านวิศวกรรมซอฟต์แวร์ขนาดใหญ่ มีเฟรมเวิร์กการทดสอบหน่วยโอเพนซอร์สที่ซับซ้อนบางอย่าง ซึ่งเราจะ ดูรายละเอียดเพิ่มเติมภายหลังในบทเรียนนี้
ด้านล่างนี้คือภาพประกอบการทดสอบที่เกิดขึ้นโดยเป็นส่วนหนึ่งของการทดสอบ 1 หน่วย

ในโลกที่เหมาะสม เราจะทดสอบสิ่งต่อไปนี้
- อินเทอร์เฟซโมดูลได้รับการทดสอบเพื่อให้แน่ใจว่าข้อมูลไหลเข้าและออก อย่างถูกต้อง
- โครงสร้างข้อมูลในเครื่องจะได้รับการตรวจสอบเพื่อให้แน่ใจว่าจัดเก็บข้อมูลได้อย่างถูกต้อง
- ทดสอบเงื่อนไขขอบเขตเพื่อให้แน่ใจว่าโมดูลทำงานได้อย่างถูกต้อง อยู่ในขอบเขตที่จำกัดหรือจำกัดการประมวลผล
- เราทดสอบเส้นทางอิสระผ่านโมดูล เพื่อให้แน่ใจว่าแต่ละเส้นทาง
ดังนั้น แต่ละคำสั่งในโมดูลจะต้องดำเนินการอย่างน้อย 1 ครั้ง
- สุดท้าย เราต้องตรวจสอบว่ามีการจัดการข้อผิดพลาดอย่างเหมาะสมหรือไม่
ความครอบคลุมของโค้ด
แต่ในความเป็นจริงแล้ว เราไม่สามารถ "ครอบคลุมโค้ด" ได้อย่างสมบูรณ์ กับการทดสอบของเรา ความครอบคลุมของโค้ดเป็นวิธีการวิเคราะห์ที่กำหนดส่วนของซอฟต์แวร์ ได้ดำเนินการ (ครอบคลุม) โดยชุดกรณีทดสอบและส่วนใดที่ ไม่มีการดำเนินการ หากเราพยายามทำให้ได้รับความครอบคลุม 100% เราจะใช้เวลามากขึ้น การเขียนบททดสอบมากกว่าการเขียนรหัสจริงๆ ลองคิดหาหน่วยวัด เส้นทางอิสระทั้งหมดของรายการต่อไปนี้ สิ่งนี้อาจกลายเป็น อย่างทวีคูณ

ในแผนภาพนี้ เส้นสีแดงจะไม่ได้รับการทดสอบ ส่วนเส้นที่ไม่มีสี ที่มีการทดสอบ
แทนที่จะพยายามตรวจสอบให้ครอบคลุม 100% เราจะเน้นไปที่การทดสอบที่เพิ่มความมั่นใจของเรา ว่าโมดูลนี้ทำงานได้อย่างเหมาะสม โดยเราจะทดสอบสิ่งต่างๆ ต่อไปนี้
- เคส Null
- การทดสอบช่วง เช่น การทดสอบค่าบวก/ลบ
- กรณีสุดโต่ง
- กรณีการดำเนินการไม่สำเร็จ
- การทดสอบเส้นทางที่มีแนวโน้มจะดำเนินการมากที่สุด
กรอบการทดสอบหน่วย
เฟรมเวิร์ก ยูนิตเทสต์ ส่วนใหญ่จะใช้การยืนยันเพื่อทดสอบค่าต่างๆ ในระหว่างการดำเนินการ เส้นทาง การยืนยันคือข้อความที่ตรวจสอบว่าเงื่อนไขเป็นจริงหรือไม่ การยืนยันอาจเป็นผลจากความสำเร็จ ความล้มเหลวที่ไม่ร้ายแรง หรือความล้มเหลวร้ายแรง หลัง มีการยืนยันแล้ว โปรแกรมจะดำเนินต่อไปตามปกติหากผลลัพธ์เป็น ที่ประสบความสำเร็จหรือล้มเหลวที่ไม่ร้ายแรง ถ้าเกิดความล้มเหลวร้ายแรง ฟังก์ชันปัจจุบัน ถูกล้มเลิก
การทดสอบประกอบด้วยโค้ดที่ตั้งค่าสถานะหรือปรับเปลี่ยนโมดูลของคุณ โดยมีการยืนยันจำนวนหนึ่งซึ่งช่วยยืนยันผลลัพธ์ที่คาดหวังได้ หากการยืนยันทั้งหมด ในการทดสอบว่าได้ผล กล่าวคือ ส่งคืนค่าจริง แล้วการทดสอบสำเร็จ หรือไม่เช่นนั้น ก็ไม่สำเร็จ
กรอบการทดสอบประกอบด้วยการทดสอบอย่างน้อย 1 รายการ เราจัดกลุ่มการทดสอบเป็นกรอบการทดสอบที่ แสดงโครงสร้างของโค้ดที่ทดสอบ ในหลักสูตรนี้เราจะใช้ CPPUnit เป็นเฟรมเวิร์กการทดสอบ 1 หน่วยของเรา เฟรมเวิร์กนี้ช่วยให้เราเขียนการทดสอบ 1 หน่วย ใน C++ และเรียกใช้โดยอัตโนมัติเพื่อรายงานเกี่ยวกับความสำเร็จหรือความล้มเหลว ของการทดสอบ
การติดตั้ง CPPUnit
ดาวน์โหลดรหัส CPPUnit จาก SourceForge ค้นหาไดเรกทอรีที่เหมาะสมแล้ววางไฟล์ tar.gz ในนั้น จากนั้นป้อน คำสั่งต่อไปนี้ (ใน Linux, Unix) การแทนที่ไฟล์ cppunit ที่เหมาะสม ชื่อ:
gunzip filename.tar.gz tar -xvf filename.tar
หากใช้ Windows คุณอาจต้องหายูทิลิตีในการดึงข้อมูล tar.gz ขั้นตอนถัดไปคือคอมไพล์ไลบรารี เปลี่ยนเป็นไดเรกทอรี cppunit จะมีไฟล์ INSTALL ที่มีวิธีการเฉพาะ โดยทั่วไป ที่คุณต้องเรียกใช้
./configure make install
หากพบปัญหา โปรดดูไฟล์ INSTALL ปกติแล้วห้องสมุด ที่พบในไดเรกทอรี cppunit/src/cppunit หากต้องการตรวจสอบว่าคอมไพล์ทำงานได้ ไปที่ไดเรกทอรี cppunit/examples/simple และพิมพ์ "make" ถ้า ทุกอย่างคอมไพล์ได้เรียบร้อย เท่านี้ก็เรียบร้อย
มีบทแนะนำที่ยอดเยี่ยม ที่นี่ โปรดดูบทแนะนำนี้ และสร้างคลาสจำนวนเชิงซ้อน การทดสอบ 1 หน่วย มีตัวอย่างเพิ่มเติมหลายรายการในไดเรกทอรี cppunit/examples
เหตุใดฉันจึงต้องทำเช่นนี้
การทดสอบ 1 หน่วยมีความสำคัญอย่างยิ่งในอุตสาหกรรมด้วยเหตุผลหลายประการ คุณ เคยรู้เหตุผลหนึ่งแล้ว นั่นคือเราต้องมีวิธีตรวจสอบงาน กำลังพัฒนาโค้ด แม้ในขณะที่เรากำลังพัฒนาโปรแกรมขนาดเล็กมาก แต่โดยสัญชาตญาณ เขียนเครื่องมือตรวจสอบหรือไดรเวอร์ เพื่อให้แน่ใจว่าโปรแกรมของเราทำสิ่งตามที่คาดหวังไว้
จากประสบการณ์อันยาวนาน วิศวกรทราบดีว่าโอกาสที่โปรแกรมนั้นๆ จะทำงานได้ ในการลองครั้งแรกนั้นเป็นจำนวนที่น้อยมาก การทดสอบ 1 หน่วยต่อยอดจากแนวคิดนี้โดยทำการทดสอบ ในการตรวจสอบตนเองและทำซ้ำได้ การยืนยันจะเข้ามาแทนที่ กำลังตรวจสอบเอาต์พุต และเนื่องจากการทดสอบนั้น ง่ายในการตีความผลลัพธ์ (การทดสอบ ผ่านหรือไม่ผ่าน) การทดสอบสามารถทำได้ซ้ำแล้วซ้ำเล่า โดย ตาข่ายความปลอดภัยที่ทำให้โค้ดของคุณมีความยืดหยุ่นในการเปลี่ยนแปลงมากยิ่งขึ้น
ลองมาพูดให้เห็นภาพมากขึ้นก็คือ เมื่อคุณส่งโค้ดที่เสร็จสมบูรณ์ครั้งแรกใน CSV ก็ใช้งานได้ดีมาก และยังคงทำงานได้อย่างดีเยี่ยมไปสักระยะหนึ่ง จากนั้น วันหนึ่งมีคนอื่นเปลี่ยนรหัสของคุณ อีกไม่นานจะมีคนทำพัง โค้ดของคุณ คิดว่าผู้ชมจะสังเกตเห็นได้ด้วยตัวเองไหม ไม่มีแนวโน้ม แต่เมื่อคุณ เขียนการทดสอบ 1 หน่วย มีระบบที่ทำการทดสอบโดยอัตโนมัติทุกวันได้ ระบบเหล่านี้เรียกว่าระบบการผสานรวมแบบต่อเนื่อง ดังนั้นเมื่อวิศวกรคนนั้น X จะทำให้โค้ดของคุณเสียหาย ระบบจะส่งอีเมลที่ไม่เหมาะสมให้โค้ดจนกว่าโค้ดนั้นจะทำการแก้ไข ได้ แม้ว่าวิศวกร X คือคุณก็ตาม
นอกเหนือจากการช่วยคุณพัฒนาซอฟต์แวร์แล้วทำให้ซอฟต์แวร์นั้นปลอดภัยอยู่เสมอ เมื่อมีการเปลี่ยนแปลง การทดสอบ 1 หน่วย:
- สร้างข้อกำหนดเฉพาะที่เรียกใช้ได้และเอกสารประกอบที่จะซิงค์กันเสมอ พร้อมรหัส กล่าวคือ คุณสามารถอ่านการทดสอบ 1 หน่วยเพื่อเรียนรู้เกี่ยวกับ พฤติกรรมที่โมดูลรองรับ
- ช่วยคุณแยกข้อกำหนดออกจากการใช้งาน เพราะคุณกำลังยืนยัน พฤติกรรมที่คนภายนอกมองเห็นได้ คุณจะมีโอกาส พิจารณาเรื่องนี้อย่างชัดเจน แทนที่จะปนกันไปในแนวคิด เกี่ยวกับวิธีนำพฤติกรรมนี้ไปใช้
- สนับสนุนการทดลอง หากคุณมีตาข่ายนิรภัยเพื่อแจ้งเตือนเมื่อ คุณไม่ทำงานของโมดูล คุณก็น่าจะลองทำสิ่งต่างๆ เหล่านี้ และกำหนดค่าการออกแบบใหม่
- ปรับปรุงการออกแบบของคุณ คุณต้องเขียนแบบทดสอบ 1 หน่วยอย่างละเอียดจึงจะเขียนได้ ทำให้ทดสอบโค้ดได้มากขึ้น โค้ดที่ทดสอบได้มักเป็นโมดูลที่โมดูลทดสอบไม่ได้ โค้ด
- รักษาคุณภาพให้สูงอยู่เสมอ ข้อบกพร่องเล็กๆ น้อยๆ ในระบบที่สำคัญสามารถทำให้บริษัท ที่จะสูญเสียเงินหลายล้านดอลลาร์ หรือที่แย่ไปกว่านั้นคือความสุขหรือความไว้วางใจของผู้ใช้ ที่การทดสอบ 1 หน่วยจะช่วยลดความเป็นไปได้นี้ ด้วยการจับข้อบกพร่อง ตั้งแต่เนิ่นๆ ยังช่วยให้ทีม QA ใช้เวลาไปกับการทำงานที่ซับซ้อนและยากลำบากขึ้นได้ ที่ล้มเหลวมากกว่าการรายงานความล้มเหลวที่เห็นได้ชัดเจน
ใช้เวลาเขียนการทดสอบ 1 หน่วยโดยใช้ CPPUnit สำหรับแอปพลิเคชันฐานข้อมูล Composer โปรดดูไดเรกทอรี cppunit/examples/ สำหรับความช่วยเหลือ
วิธีการทำงานของ Google
บทนำลองนึกภาพพระสงฆ์ในยุคกลางกำลังดูต้นฉบับหลายพันเล่มใน ที่เก็บของอารามของเขา"อันนั้นของ Aristotle อยู่ไหน..."

โชคดีที่ต้นฉบับถูกจัดระเบียบตามเนื้อหาและจารึกไว้ โดยใช้สัญลักษณ์พิเศษเพื่ออำนวยความสะดวกในการดึงข้อมูลที่อยู่ใน อย่างละ 1 รายการ หากไม่มีองค์กรดังกล่าว ก็คงจะยากมากที่จะค้นหา ลายมือ
กิจกรรมของการจัดเก็บและเรียกข้อมูลที่เขียนจากคอลเล็กชันขนาดใหญ่ เรียกว่าการดึงข้อมูล (IR) กิจกรรมนี้มีจำนวนเพิ่มขึ้นเรื่อยๆ มีความสำคัญตลอดหลายศตวรรษ โดยเฉพาะงานประดิษฐ์อย่างกระดาษและการพิมพ์ กด เคยเป็นสถานที่ที่มีผู้คนเพียงไม่กี่คนเท่านั้น ตอนนี้ แต่ผู้คนหลายร้อยล้านคน มีส่วนร่วมในการดึงข้อมูล เมื่อใช้เครื่องมือค้นหาหรือค้นหาในเดสก์ท็อป
การเริ่มต้นใช้งานการดึงข้อมูล

ดร. ซูสส์เขียนหนังสือสำหรับเด็ก 46 เล่มตลอด 30 ปี หนังสือของเขาบอกว่า ของแมว วัว และช้าง ของใคร ยิ้ม และลอแร็กซ์ เธอจำได้ไหม สิ่งมีชีวิตใดอยู่ในเรื่องราวใด เฉพาะบุตรหลานเท่านั้นที่ทำได้ เว้นแต่คุณจะเป็นผู้ปกครอง เล่าให้ฟังว่าเรื่องราวของ ดร. ซูสส์ ส่วนไหนมีสัตว์อยู่
(COW และ BEE) หรือ CROWS
เราจะใช้โมเดลการดึงข้อมูลแบบคลาสสิกบางอย่างเพื่อช่วยในการแก้ปัญหานี้ ปัญหา
แนวทางที่ชัดเจนคือ Brute Force: ฟังเรื่องราวทั้ง 46 เรื่องของ Dr. Seuss และเริ่ม การอ่าน สำหรับหนังสือแต่ละเล่ม ให้ดูว่าหนังสือเล่มใดมีคำว่า COW และ BEE และ ในขณะเดียวกัน ให้มองหาหนังสือที่มีคำว่า CROWS คอมพิวเตอร์นั้นสำคัญมาก ได้เร็วกว่าเรา ถ้าเรามีข้อความทั้งหมดจากหนังสือของ ดร. ซูสส์ ในรูปแบบดิจิทัล เช่น เป็นไฟล์ข้อความ เราก็สามารถ grep ผ่านไฟล์ได้ สำหรับ คอลเล็กชันเล็กๆ อย่างหนังสือของดร. ซูสส์ เทคนิคนี้ใช้ได้ผลดี
อย่างไรก็ตาม มีสถานการณ์มากมายที่เราจำเป็นต้องใช้งาน เช่น คอลเล็กชัน ของข้อมูลทั้งหมดออนไลน์ในขณะนี้ ใหญ่เกินกว่าที่ grep จะจัดการได้ และเราไม่มี แค่ต้องการเอกสารที่ตรงกับเงื่อนไขของเรา เราก็เริ่มคุ้นเคยกับ ให้แคมเปญจัดอันดับตามความเกี่ยวข้อง
อีกวิธีหนึ่งนอกเหนือจาก grep คือการสร้างดัชนีเอกสารในคอลเล็กชัน ก่อนที่จะทำการค้นหา ดัชนีใน IR คล้ายกับดัชนีที่ ด้านหลังของหนังสือเรียน เราสร้างรายการคำ (หรือ ข้อกำหนด) ทั้งหมดในแต่ละคำ เรื่องราวของดร. ซูสส์ โดยละคำต่างๆ เช่น "the", "and" และความสัมพันธ์อื่นๆ คำบุพบท ฯลฯ (คำเหล่านี้เรียกว่า คำหยุด) จากนั้นเราจะนำเสนอ ข้อมูลนี้ในลักษณะที่เอื้อต่อการค้นหาคำและระบุ เรื่องราวที่ผู้อ่านเหล่านั้นดู
การนำเสนอแบบหนึ่งที่เป็นไปได้คือเมทริกซ์ที่แสดงเรื่องราวต่างๆ ทั้งด้านบน และ คำศัพท์ที่แสดงในแต่ละแถว "1" ในคอลัมน์หมายความว่าคำนั้นปรากฏ ในเรื่องราวสำหรับคอลัมน์นั้น
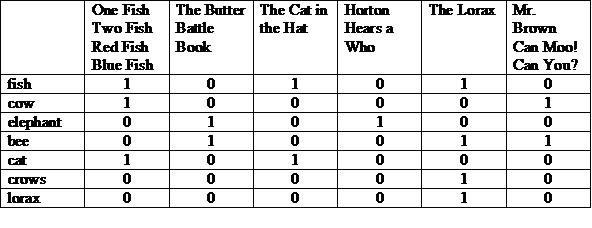
เราสามารถดูแต่ละแถวหรือคอลัมน์เป็นเวกเตอร์ของบิตได้ เวกเตอร์บิตของแถวจะระบุ ที่คำนี้ปรากฏในเรื่องราว เวกเตอร์บิตของคอลัมน์จะระบุคำศัพท์ ปรากฏในเรื่องราว
กลับไปที่ปัญหาเดิม
(COW และ BEE) หรือ CROWS
เราใช้เวกเตอร์ของบิตสำหรับคำเหล่านี้ แล้วทำมุมกว้างก่อน "และ" จากนั้นทำ เล็กน้อย OR กับผลลัพธ์
(100001 และ 010011) หรือ 000010 = 000011
คำตอบ: "คุณ Brown Can Moo! ได้ไหม" และ "The Lorax" นี่คือภาพประกอบ ของโมเดลการดึงข้อมูลบูลีน ซึ่งเป็นโมเดล "การทำงานแบบตรงทั้งหมด"
สมมติว่าเราจะขยายเมทริกซ์ให้ครอบคลุมเรื่องราวทั้งหมดของดร. ซูสส์และ คำที่เกี่ยวข้องในเรื่องราว เมทริกซ์จะเติบโตขึ้นอย่างมาก และ การสังเกตการณ์ส่วนใหญ่จะเป็น 0 เมทริกซ์คงไม่ดีที่สุด ตัวแทนสำหรับดัชนี เราต้องหาวิธีจัดเก็บเฉพาะ 1
การเพิ่มประสิทธิภาพบางอย่าง
โครงสร้างที่ใช้ใน IR เพื่อแก้ปัญหานี้เรียกว่าดัชนีกลับสี เราเก็บพจนานุกรมของคำศัพท์ไว้ และจะมีรายการสำหรับแต่ละคำ ที่บันทึกเอกสารที่มีคำดังกล่าว รายการนี้เรียกว่าการโพสต์ รายการที่ลิงก์กันเพียงอย่างเดียวจะใช้ได้ดีในการนำเสนอโครงสร้างนี้ ที่ด้านล่าง

หากคุณไม่คุ้นเคยกับรายการที่เชื่อมโยง เพียงทำการค้นหาบน Google ใน "ลิงก์แล้ว
ใน C++" และคุณจะพบแหล่งข้อมูล
มากมายที่อธิบายวิธีสร้าง
และวิธีใช้ เราจะอธิบายเรื่องนี้อย่างละเอียดยิ่งขึ้นในโมดูลถัดไป
โปรดทราบว่าเราใช้รหัสเอกสาร (DocIDs) แทนชื่อของ เรื่องราวของคุณ นอกจากนี้ เรายังจัดเรียงรหัสเอกสารเหล่านี้เพื่อให้ช่วยอำนวยความสะดวกในการประมวลผลการค้นหา
เราจะดำเนินการกับข้อความค้นหาอย่างไร สำหรับปัญหาเดิม เราเริ่มจากการโพสต์ COW ก่อน แล้วเลือกรายการการโพสต์ของ BEE จากนั้นเราจะ "รวม" องค์ประกอบเหล่านี้เข้าด้วยกัน
- เก็บเครื่องหมายไว้ในรายการทั้งสองและดูรายการโพสต์ทั้งสองรายการ พร้อมกัน
- ในแต่ละขั้นตอน ให้เปรียบเทียบรหัสเอกสารที่ชี้ไปโดยตัวชี้ทั้ง 2 อย่าง
- หากเหมือนกัน ให้ใส่ DocID นั้นในรายการผลลัพธ์ จากนั้นจะเลื่อนเคอร์เซอร์ไปข้างหน้า ซึ่งชี้ไปยัง docID ที่เล็กกว่า
นี่คือวิธีที่เราสามารถสร้างดัชนีกลับสี:
- กำหนดรหัสเอกสารให้กับเอกสารที่สนใจแต่ละฉบับ
- ระบุคำที่เกี่ยวข้อง (โทเค็น) สำหรับเอกสารแต่ละฉบับ
- สำหรับแต่ละคำ ให้สร้างระเบียนที่ประกอบด้วยคำ รหัสเอกสาร ซึ่ง และความถี่ในเอกสารนั้น โปรดทราบว่าอาจมี ระเบียนสำหรับคำหนึ่งๆ ถ้าปรากฏในเอกสารมากกว่า 1 รายการ
- จัดเรียงระเบียนตามคำ
- สร้างพจนานุกรมและรายการการโพสต์โดยการประมวลผลบันทึกเดี่ยวสำหรับ คำ และยังรวมบันทึกหลายรายการสำหรับคำที่ปรากฏใน เอกสารมากกว่า 1 ฉบับ สร้างรายการ DocID ที่ลิงก์ (ตามลำดับ) ชิ้น คำยังมีความถี่ซึ่งเป็นผลรวมของความถี่ในบันทึกทั้งหมด คำหนึ่ง
โครงการ
ค้นหาเอกสารข้อความธรรมดาขนาดยาวหลายฉบับที่คุณสามารถทดลองใช้ได้ คือการสร้างดัชนีกลับจากเอกสาร โดยใช้อัลกอริทึม ที่อธิบายไว้ข้างต้น คุณจะต้องสร้างอินเทอร์เฟซสำหรับการป้อนคำค้นหา และเครื่องมือสำหรับการประมวลผลเหล่านั้น คุณค้นหาพาร์ทเนอร์โปรเจ็กต์ได้ในฟอรัม
กระบวนการที่เป็นไปได้สำหรับการทำให้โครงการนี้เสร็จสมบูรณ์มีดังนี้
- สิ่งแรกที่ต้องทำคือการกำหนดกลยุทธ์สำหรับการระบุคำในเอกสาร สร้างรายการคำหยุดทั้งหมดที่คุณนึกออกและเขียนฟังก์ชัน อ่านคำในไฟล์ บันทึกคำ และลบคำหยุด คุณอาจต้องเพิ่มคำหยุดลงในรายการ ในขณะที่ตรวจดูรายการ จากการทำซ้ำ
- เขียนกรอบการทดสอบ CPPUnit เพื่อทดสอบการทำงาน และแต่งไฟล์เพื่อดึงทุกอย่างมา เพื่อการสร้างคุณ ตรวจสอบไฟล์เป็น CVS โดยเฉพาะอย่างยิ่งหากคุณ ในการทำงานร่วมกับพาร์ทเนอร์ คุณอาจต้องค้นคว้าวิธีเปิดอินสแตนซ์ CVS แก่วิศวกรระยะไกล
- เพิ่มการประมวลผลเพื่อรวมข้อมูลตำแหน่ง ซึ่งก็คือไฟล์และตำแหน่งใน ไฟล์นั้นเป็นคำใด คุณอาจต้องหาการคำนวณเพื่อกำหนด เลขหน้าหรือหมายเลขย่อหน้า
- เขียนกรณีการทดสอบ CPPUnit เพื่อทดสอบฟังก์ชันการทำงานเพิ่มเติมนี้
- สร้างดัชนีกลับสีและเก็บข้อมูลตำแหน่งไว้ในระเบียนของแต่ละคำ
- เขียนกรอบการทดสอบเพิ่มเติม
- ออกแบบอินเทอร์เฟซเพื่อให้ผู้ใช้ป้อนคำค้นหา
- ใช้อัลกอริทึมการค้นหาที่อธิบายไว้ข้างต้น ประมวลผลดัชนีที่สลับสี และ ส่งข้อมูลตำแหน่งให้กับผู้ใช้
- อย่าลืมใส่กรอบการทดสอบสำหรับส่วนสุดท้ายนี้ด้วย
เช่นเดียวกับที่เราทำกับทุกโปรเจ็กต์ คุณสามารถใช้ฟอรัมและแชทเพื่อค้นหาพาร์ทเนอร์โปรเจ็กต์ และแชร์ไอเดียได้ด้วย
ฟีเจอร์พิเศษ
ขั้นตอนการประมวลผลทั่วไปในระบบ IR จำนวนมากเรียกว่าการตัดคำ แนวคิดหลักเบื้องหลังการตัดข้อความคือ ผู้ใช้ที่กำลังค้นหาข้อมูลเกี่ยวกับ “การดึงข้อมูล” จะสนใจเอกสารที่มีข้อมูลที่มีคำว่า “ดึงข้อมูล” “ดึงข้อมูล” “ดึงข้อมูล” และอื่นๆ ระบบอาจเสี่ยงต่อการเกิดข้อผิดพลาดเนื่องจาก ไปจนถึงการแยกที่ไม่ดีเลย เรื่องนี้จึงค่อนข้างยาก ตัวอย่างเช่น ผู้ใช้ที่สนใจ ใน “การดึงข้อมูล” อาจได้รับเอกสารชื่อ “ข้อมูลเกี่ยวกับ Retrievers” เกิดจากการคำนวณผลที่ตามมา อัลกอริทึมที่มีประโยชน์สำหรับการตัดคำคือ อัลกอริทึมของพอร์ต