Tutorial Bahasa C++
Bagian awal dari tutorial membahas materi dasar yang sudah disajikan dalam dua modul terakhir, dan memberikan lebih banyak informasi tentang konsep lanjutan. Dengan modul ini akan berfokus pada memori dinamis, serta detail lainnya tentang objek dan class. Beberapa topik lanjutan juga diperkenalkan, seperti pewarisan, polimorfisme, {i>template<i}, pengecualian dan namespace. Kita akan mempelajarinya nanti di pelatihan C++ Lanjutan.
Desain Berorientasi Objek
Ini adalah pengalaman tutorial tentang desain berorientasi objek. Kami akan menerapkan yang disajikan di sini dalam proyek modul ini.
Belajar dengan Contoh #3
Fokus kita dalam modul ini adalah untuk mendapatkan lebih banyak latihan dengan pointer, berorientasi objek desain, array multi-dimensi, dan kelas/objek. Selesaikan langkah-langkah berikut contoh. Kami sangat menekankan bahwa kunci untuk menjadi {i>programmer<i} yang baik adalah latihan, latihan, latihan!Latihan #1: Lebih Banyak Latihan dengan Pointer
Jika Anda memerlukan latihan tambahan dengan pointer, baca ini yang mencakup semua aspek pointer dan menyediakan banyak contoh program.
Apa output dari program berikut? Jangan jalankan program, tetapi menggambar gambar memori untuk menentukan {i>output<i}.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Setelah Anda menentukan {i>output<i} secara manual, jalankan program untuk melihat apakah Anda benar.
Latihan #2: Lebih Banyak Berlatih dengan Class dan Objek
Jika Anda memerlukan latihan tambahan dengan class dan objek, di sini adalah resource yang melewati implementasi dua class kecil. Coba waktu untuk melakukan latihan.
Latihan #3: Array Multi-Dimensi
Pertimbangkan program berikut:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Terdapat baris dalam program ini yang ditandai "Bagaimana cara kerja baris ini?" - bisakah kamu mengetahuinya? Berikut adalah penjelasan kami.
Menulis program yang menginisialisasi array 3-dim dan mengisi dimensi ke-3 dengan jumlah ketiga indeks. Berikut adalah solusi kami.
Latihan #4: Contoh Desain OO yang Luas
Berikut ini adalah contoh desain berorientasi objek, yang membahas seluruh dari awal hingga akhir. Kode akhir ditulis dalam Java bahasa pemrograman tertentu, tetapi Anda akan dapat membacanya seberapa jauh jarak yang Anda datang.
Luangkan waktu untuk mempelajari seluruh contoh ini. Enak sekali ilustrasi proses, dan alat desain yang mendukungnya.
Pengujian Unit
Pengantar
Pengujian adalah bagian penting dari proses rekayasa perangkat lunak. Pengujian unit adalah jenis pengujian tertentu, yang memeriksa fungsi dari modul kode sumber.Pengujian unit selalu dilakukan oleh insinyur, dan biasanya dilakukan bersamaan saat mereka melakukan {i>coding<i} modul. Tes pengemudi yang Anda yang digunakan untuk menguji class Composer dan Database adalah contoh pengujian unit.
Pengujian Unit memiliki karakteristik berikut. Mereka...
- menguji komponen secara terpisah
- bersifat determenistik
- biasanya dipetakan ke satu class
- menghindari ketergantungan pada sumber daya eksternal, misalnya database, file, jaringan
- jalankan dengan cepat
- dapat dijalankan dalam urutan apa pun
Ada kerangka kerja dan metodologi otomatis yang memberikan dukungan dan konsistensi untuk pengujian unit di organisasi software engineering yang besar. Ada beberapa framework pengujian unit open source yang canggih, yang akan pelajari nanti di materi ini.
Pengujian yang terjadi sebagai bagian dari pengujian unit diilustrasikan di bawah.

Idealnya, kami menguji hal berikut:
- Antarmuka modul diuji untuk memastikan informasi mengalir masuk dan keluar dengan benar.
- Struktur data lokal diperiksa untuk memastikan struktur tersebut menyimpan data dengan benar.
- Kondisi batas diuji untuk memastikan modul beroperasi dengan benar pada batas-batas yang membatasi atau membatasi pemrosesan.
- Kita menguji jalur independen melalui modul
untuk memastikan setiap jalur, dan
jadi setiap pernyataan dalam modul akan dieksekusi minimal sekali.
- Terakhir, kita perlu memeriksa apakah error sudah ditangani dengan benar.
Cakupan Kode
Pada kenyataannya, kami tidak dapat mencapai "cakupan kode" yang lengkap pada pengujian. Cakupan kode adalah metode analisis yang menentukan bagian mana dari suatu perangkat lunak dijalankan (dicakup) oleh rangkaian kasus pengujian dan bagian mana yang memiliki belum dieksekusi. Jika kita mencoba mencapai cakupan 100%, kita akan menghabiskan lebih banyak waktu menulis pengujian unit daripada menulis kode yang sebenarnya. Pertimbangkan untuk membuat unit pengujian untuk semua jalur independen berikut. Hal ini dapat dengan cepat menjadi eksponensial.
Dalam diagram ini, garis merah tidak diuji, sedangkan garis yang tidak berwarna diuji.
Daripada mencoba cakupan 100%, kami berfokus pada pengujian yang meningkatkan keyakinan kami bahwa modul berfungsi dengan baik. Kami menguji hal-hal seperti:
- Kasus null
- Uji rentang, misalnya, uji nilai positif/negatif
- Kasus ekstrem
- Kasus kegagalan
- Menguji jalur yang paling sering dijalankan
Framework Pengujian Unit
Sebagian besar framework pengujian unit menggunakan pernyataan untuk menguji nilai selama eksekusi {i>path<i}. Pernyataan adalah pernyataan yang memeriksa apakah suatu kondisi benar. Tujuan hasil pernyataan dapat berupa keberhasilan, kegagalan nonfatal , atau kegagalan fatal. Sesudah pernyataan dijalankan, program akan berlanjut secara normal jika hasilnya salah berhasil atau tidak fatal. Jika terjadi kegagalan fatal, fungsi saat ini dibatalkan.
Pengujian terdiri dari kode yang menyiapkan status atau memanipulasi modul Anda, dengan sejumlah pernyataan yang memverifikasi hasil yang diharapkan. Jika semua pernyataan dalam pengujian berhasil, yaitu menghasilkan nilai benar (true), maka pengujian berhasil; sebaliknya model tersebut gagal.
Satu kasus pengujian berisi satu atau beberapa pengujian. Kita mengelompokkan pengujian ke dalam kasus pengujian yang mencerminkan struktur kode yang diuji. Di materi ini, kita akan menggunakan CPPUnit sebagai framework pengujian unit kami. Dengan framework ini, kita dapat menulis pengujian unit di C++ dan menjalankannya secara otomatis, memberikan laporan tentang keberhasilan atau kegagalan pengujian.
Penginstalan CPPUnit
Download kode CPPUnit dari SourceForge. Temukan direktori yang sesuai dan letakkan file tar.gz di sana. Lalu, masukkan perintah berikut (di Linux, Unix), menggantikan file cppunit yang sesuai nama:
gunzip filename.tar.gz tar -xvf filename.tar
Jika Anda bekerja di Windows, Anda mungkin perlu menemukan utilitas untuk mengekstrak {i>tar.gz<i} . Langkah berikutnya adalah mengompilasi library. Ubah ke direktori cppunit. Ada file INSTALL di sana yang memberikan petunjuk khusus. Biasanya, Anda harus menjalankan:
./configure make install
Jika Anda mengalami masalah, lihat file INSTALL. Library ini biasanya yang ditemukan di direktori cppunit/src/cppunit. Untuk memeriksa apakah kompilasi berfungsi, masuk ke direktori cppunit/examples/simple dan ketik "make". Jika semuanya mengkompilasi baik-baik saja, maka Anda akan siap.
Ada tutorial yang sangat bagus di sini. Buka tutorial ini dan buat class bilangan kompleks, beserta class yang terkait pengujian unit iklan. Ada beberapa contoh tambahan dalam direktori cppunit/examples.
Mengapa Saya Harus Melakukan Ini?
Pengujian unit sangat penting dalam industri karena beberapa alasan. Anda berada sudah mengetahui satu alasan: Kami perlu suatu cara untuk memeriksa pekerjaan sekaligus mengembangkan kode. Bahkan ketika kami mengembangkan program yang sangat kecil, kami secara naluriah menulis semacam pemeriksa atau {i>driver<i} untuk memastikan bahwa program kita melakukan apa yang diharapkan.
Dari pengalaman panjang, para insinyur tahu bahwa peluang bahwa suatu program akan berhasil pada percobaan pertama sangat kecil. Pengujian unit dibuat berdasarkan ide ini dengan membuat pengujian program yang memeriksa mandiri dan dapat diulang. Pernyataan menggantikan memeriksa {i>output<i}. Dan, karena mudah untuk menginterpretasikan hasilnya (pengujian lulus atau gagal), pengujian bisa dijalankan berulang kali, dengan menyediakan jaring pengaman yang membuat kode Anda lebih tahan terhadap perubahan.
Mari kita bahas secara konkret: Saat Anda pertama kali mengirimkan kode yang sudah jadi ke CVS, ini bekerja dengan sempurna. Dan alat ini terus bekerja dengan sempurna untuk sementara waktu. Selanjutnya suatu hari, seseorang mengubah kode Anda. Cepat atau lambat seseorang akan merusak kode Anda. Apakah menurut Anda mereka akan menyadarinya sendiri? Tidak mungkin. Tapi ketika Anda menulis pengujian unit, ada sistem yang dapat menjalankannya secara otomatis, setiap hari. Keduanya disebut sistem continuous integration. Jadi, ketika insinyur/perekayasa itu X memecahkan kode Anda, sistem akan mengirimkan email jahat kepada mereka sampai mereka anotasi. Bahkan jika insinyur X adalah ANDA!
Selain membantu Anda mengembangkan perangkat lunak, dan menjaga keamanan perangkat lunak tersebut dalam menghadapi perubahan, pengujian unit:
- Menciptakan spesifikasi yang dapat dieksekusi, dan dokumentasi yang tetap sinkron kode. Dengan kata lain, Anda dapat membaca pengujian unit untuk mempelajari tentang apa perilaku yang didukung modul.
- Membantu Anda memisahkan persyaratan dari penerapan. Karena Anda menegaskan perilaku yang terlihat secara eksternal, Anda mendapat kesempatan untuk memikirkannya secara eksplisit alih-alih mencampur ide tentang cara menerapkan perilaku tersebut.
- Mendukung eksperimen. Jika Anda memiliki jaring pengaman untuk memperingatkan Anda ketika Anda telah merusak perilaku modul, Anda lebih cenderung untuk mencoba berbagai hal dan mengkonfigurasi ulang desain Anda.
- Meningkatkan kualitas desain Anda. Menulis pengujian unit secara menyeluruh sering kali mengharuskan Anda untuk membuat kode Anda lebih mudah diuji. Kode yang dapat diuji sering kali lebih bersifat modular daripada yang tidak dapat diuji pada kode sumber.
- Menjaga kualitas tetap tinggi. {i>Bug<i} kecil dalam sistem kritis dapat menyebabkan perusahaan kehilangan jutaan dolar, atau lebih buruk lagi, kebahagiaan atau kepercayaan pengguna. Tujuan jaring pengaman yang disediakan oleh pengujian unit mengurangi kemungkinan ini. Dengan menangkap serangga lebih awal, mereka juga memungkinkan tim QA untuk meluangkan waktu pada skenario kegagalan, daripada melaporkan kegagalan yang nyata.
Luangkan waktu untuk menulis pengujian unit menggunakan CPPUnit untuk aplikasi database Composer. Lihat direktori cppunit/examples/ untuk mendapatkan bantuan.
Cara Kerja Google
PengantarBayangkan seorang biksu pada Abad Pertengahan melihat ribuan manuskrip di arsip biaranya.“Di mana yang itu dari Aristotle...”

Untungnya baginya, naskah-naskah diatur menurut konten dan ditulis dengan simbol khusus untuk memfasilitasi pengambilan informasi yang terkandung dalam masing-masing. Tanpa pengaturan seperti itu, akan sangat sulit untuk menemukan menggunakan manuskrip.
Aktivitas menyimpan dan mengambil informasi tertulis dari koleksi berukuran besar disebut Pengambilan Informasi (IR). Kegiatan ini menjadi semakin penting selama berabad-abad, terutama dengan penemuan seperti kertas dan pencetakan tekan. Dahulu, hanya ada beberapa orang saja yang bekerja. Sekarang, namun, ratusan juta orang terlibat dalam pengambilan informasi setiap hari ketika mereka menggunakan mesin telusur atau mencari di {i>desktop<i}.
Memulai Pengambilan Informasi

Dr. Seuss menulis 46 buku anak-anak selama 30 tahun. Buku-bukunya menceritakan kucing, sapi dan gajah, siapa, cengeng, dan lorax. Apa kamu ingat Makhluk mana yang ada di cerita mana? Kecuali Anda adalah orang tua, hanya anak yang dapat ceritakan rangkaian cerita Dr. Seuss mana yang memiliki makhluk:
(COW dan BEE) atau CROWS
Kita akan menerapkan beberapa model pengambilan informasi klasik untuk membantu kita mengatasi ini masalah.
Pendekatan yang jelas adalah kekerasan: Dapatkan semua 46 cerita Dr. Seuss, dan mulailah sebelumnya. Untuk setiap buku, perhatikan mana yang berisi kata-kata COW dan BEE, dan pada saat yang sama, cari buku yang berisi kata CROWS. Komputer jauh lebih cepat daripada kami. Jika kita memiliki semua teks dari buku Dr. Seuss dalam bentuk digital, misalkan sebagai file teks, kita cukup mengenali file tersebut. Untuk kecil seperti buku Dr. Seuss, teknik ini cukup efektif.
Namun, ada banyak situasi yang membutuhkan lebih banyak lagi. Misalnya, koleksi dari semua data yang saat ini {i>online<i} terlalu besar untuk ditangani {i>grep<i}. Kami juga tidak hanya ingin dokumen yang sesuai dengan kondisi kita, kita sudah terbiasa mengurutkannya sesuai dengan relevansinya.
Pendekatan lain selain {i>grep<i}, adalah untuk membuat indeks dokumen dalam koleksi sebelum melakukan pencarian. Indeks dalam IR serupa dengan indeks pada bagian belakang buku teks. Kami membuat daftar semua kata (atau istilah) di setiap Kisah Dr. Seuss, meninggalkan kata-kata seperti “the”, “dan”, dan kata penghubung lainnya, preposisi, dll. (ini disebut kata stop). Kemudian, kita merepresentasikan informasi ini dengan cara yang memudahkan untuk menemukan istilah dan mengidentifikasi cerita yang mereka masuki.
Salah satu representasi yang mungkin adalah matriks dengan cerita di bagian atas, dan istilah yang tercantum di setiap baris. Angka “1” di kolom menunjukkan bahwa istilah tersebut muncul dalam artikel berita untuk kolom tersebut.
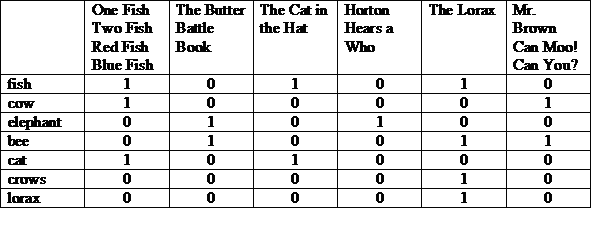
Kita dapat melihat setiap baris atau kolom sebagai vektor bit. Vektor bit baris menunjukkan di artikel mana istilah tersebut muncul. Vektor bit kolom menunjukkan istilah apa muncul dalam cerita.
Kembali ke masalah awal:
(COW dan BEE) atau CROWS
Kita mengambil vektor bit untuk istilah-istilah ini dan pertama-tama melakukan sedikit-{i>wise<i} AND, kemudian melakukan sedikit bijaksana OR pada hasilnya.
(100001 dan 010011) atau 000010 = 000011
Jawabannya: “Tn. Cokelat Bisa Moo! Apakah Anda Bisa?” dan "The Lorax". Ini adalah ilustrasi dari model Pengambilan Boolean, yang merupakan model “pencocokan persis”.
Misalkan kita memperluas matriks untuk menyertakan semua cerita Dr. Seuss dan semua istilah yang relevan dalam artikel. Matriksnya akan berkembang pesat, dan komponen penting pengamatan adalah sebagian besar entrinya adalah 0. Matriks mungkin bukan yang terbaik untuk indeks. Kita perlu menemukan cara untuk menyimpan angka 1 saja.
Beberapa Peningkatan
Struktur yang digunakan dalam IR untuk memecahkan masalah ini disebut indeks terbalik. Kami menyimpan kamus istilah, lalu untuk setiap istilah, kami memiliki daftar yang mencatat dokumen di mana istilah itu muncul. Daftar ini disebut postingan daftar. Daftar tertaut tunggal berfungsi dengan baik untuk mewakili struktur ini seperti yang ditunjukkan di bawah ini.

Jika Anda belum familier dengan daftar tertaut, cukup lakukan penelusuran Google di "linked
di C++", dan Anda akan menemukan banyak
sumber daya yang menjelaskan cara membuatnya,
dan cara penggunaannya. Kita akan membahas hal ini secara lebih mendetail di modul berikutnya.
Perhatikan bahwa kita menggunakan ID Dokumen (DocIDs) bukan nama cerita Anda. Kami juga mengurutkan DocID ini karena memfasilitasi pemrosesan kueri.
Bagaimana cara memproses kueri? Untuk masalah aslinya, pertama-tama kita menemukan postingan COW lalu daftar posting BEE. Kemudian, kita “menggabungkannya” bersama-sama:
- Tempatkan penanda di kedua daftar dan periksa kedua daftar postingan secara bersamaan.
- Pada setiap langkah, bandingkan DocID yang ditunjuk oleh kedua pointer.
- Jika sama, masukkan DocID tersebut dalam daftar hasil, atau lanjutkan pointer menunjuk ke docID yang lebih kecil.
Berikut adalah cara membuat indeks terbalik:
- Tetapkan DocID untuk setiap dokumen yang diinginkan.
- Untuk setiap dokumen, identifikasi istilah yang relevan (tokenisasi).
- Untuk setiap istilah, buat catatan yang terdiri dari istilah, DocID yang memiliki ditemukan, dan frekuensi dalam dokumen tersebut. Perhatikan bahwa bisa ada beberapa {i>record<i} untuk istilah tertentu jika muncul di lebih dari satu dokumen.
- Mengurutkan data berdasarkan istilah.
- Buat daftar kamus dan posting dengan memproses {i>record<i} tunggal untuk satu istilah, dan juga menggabungkan beberapa catatan untuk istilah yang muncul di lebih dari satu dokumen. Buat daftar DocID tertaut (dalam urutan yang diurutkan). Masing-masing juga memiliki frekuensi yang merupakan jumlah frekuensi di semua kumpulan data untuk suatu istilah.
Proyek
Temukan beberapa dokumen teks biasa yang panjang yang dapat Anda gunakan untuk bereksperimen. Tujuan proyek adalah membuat indeks terbalik dari dokumen, menggunakan algoritma yang dijelaskan di atas. Anda juga perlu membuat antarmuka untuk input kueri dan mesin untuk memprosesnya. Anda dapat menemukan partner proyek di forum.
Berikut adalah proses yang mungkin untuk menyelesaikan proyek ini:
- Hal pertama yang harus dilakukan adalah mendefinisikan strategi untuk mengidentifikasi istilah dalam dokumen. Buatlah daftar semua kata pengantar yang dapat Anda pikirkan, dan tulis fungsi yang membaca kata-kata di dalam file, menyimpan persyaratan, dan menghilangkan kata-kata penutup. Anda mungkin harus menambahkan lebih banyak kata pengantar ke daftar Anda saat Anda meninjau daftar syarat dari iterasi.
- Tulis kasus pengujian CPPUnit untuk menguji fungsi Anda, dan makefile untuk mencakup semuanya bersama-sama untuk build Anda. Periksa {i>file<i} Anda ke dalam CVS, terutama jika Anda bekerja sama dengan mitra. Anda mungkin ingin mencari tahu cara membuka {i>instance<i} CVS Anda hingga insinyur jarak jauh.
- Tambahkan pemrosesan untuk menyertakan data lokasi, yaitu file yang mana dan lokasinya filenya adalah sebuah istilah? Anda mungkin ingin menghitung kalkulasi untuk menentukan nomor halaman atau nomor paragraf.
- Tulis kasus pengujian CPPUnit untuk menguji fungsi tambahan ini.
- Buat indeks terbalik dan simpan data lokasi dalam catatan setiap istilah.
- Menulis kasus pengujian lainnya.
- Desain antarmuka yang memungkinkan pengguna memasukkan kueri.
- Menggunakan algoritma pencarian yang dijelaskan di atas, proses indeks terbalik dan menampilkan data lokasi kepada pengguna.
- Pastikan untuk menyertakan kasus pengujian untuk bagian akhir ini juga.
Seperti yang telah kami lakukan pada semua project, gunakan forum dan chat untuk menemukan partner project dan untuk berbagi ide.
Fitur Tambahan
Langkah pemrosesan yang umum di banyak sistem IR disebut stemmer. Tujuan Ide utama di balik penentuan adalah bahwa pengguna mencari informasi tentang "pengambilan" juga akan tertarik pada dokumen yang memiliki informasi yang berisi “{i>fetch<i}”, "diambil", "mengambil", dan seterusnya. Sistem rentan terhadap kesalahan karena {i>steim <i}yang buruk, jadi hal ini cukup rumit. Misalnya, seorang pengguna yang tertarik di bagian "pengambilan informasi" mungkin mendapatkan dokumen berjudul "Informasi tentang Emas Pengambil” karena stemming. Algoritma yang berguna untuk {i>stemmer<i} adalah Algoritma porter.