C++ लैंग्वेज ट्यूटोरियल
इसके शुरुआती सेक्शन ट्यूटोरियल इसमें पहले से मौजूद बुनियादी कॉन्टेंट को शामिल किया गया है और बेहतर कॉन्सेप्ट के बारे में ज़्यादा जानकारी दी है. हमारे इस मॉड्यूल का फ़ोकस डाइनैमिक मेमोरी पर है. साथ ही, ऑब्जेक्ट और क्लास की ज़्यादा जानकारी दी गई है. इसमें कुछ ऐडवांस लेवल के विषय भी शामिल होते हैं. जैसे, इनहेरिटेंस, पॉलीमॉर्फ़िज़्म, टेंप्लेट, अपवाद और नेमस्पेस. बाद में, हम इन विषयों के बारे में ऐडवांस C++ कोर्स करेंगे.
ऑब्जेक्ट-ओरिएंटेड डिज़ाइन
यह एक बेहतरीन ऑब्जेक्ट-ओरिएंटेड डिज़ाइन पर ट्यूटोरियल देखें. हम पद्धति यहां दी गई है जो इस मॉड्यूल के प्रोजेक्ट में है.
उदाहरण #3 से सीखें
इस मॉड्यूल में हमारा फ़ोकस, पॉइंटर, ऑब्जेक्ट-ओरिएंटेड की मदद से ज़्यादा प्रैक्टिस करने पर है और क्लास/ऑब्जेक्ट असाइन किए जा सकते हैं. इन्हें ठीक करें उदाहरण. हम एक अच्छा प्रोग्रामर बनने के लिए, इस बात पर ज़्यादा ज़ोर नहीं दे सकते कि प्रैक्टिस करें, प्रैक्टिस करें, प्रैक्टिस करें!व्यायाम #1: पॉइंटर की मदद से प्रैक्टिस करें
अगर आपको पॉइंटर के साथ ज़्यादा प्रैक्टिस करनी है, तो इसे पढ़ें यह संसाधन जिसमें पॉइंटर के सभी पहलू शामिल होते हैं और प्रोग्राम के कई उदाहरण मिलते हैं.
इस प्रोग्राम से क्या नतीजा मिलता है? कृपया प्रोग्राम न चलाएं, लेकिन आउटपुट तय करने के लिए मेमोरी तस्वीर बनाएं.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}मैन्युअल रूप से आउटपुट तय करने के बाद, प्रोग्राम को चलाकर देखें कि आप सही है.
व्यायाम #2: क्लास और ऑब्जेक्ट की मदद से प्रैक्टिस करें
अगर आपको क्लास और ऑब्जेक्ट में कुछ और प्रैक्टिस करने की ज़रूरत है, यहां एक ऐसा संसाधन है जो दो छोटी क्लास को लागू करने से गुज़रता है. थोड़ा आराम करें व्यायाम करने का समय हो जाएगा.
व्यायाम #3: बहु-आयामी सरणियां
यह प्रोग्राम देखें:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}इस प्रोग्राम में "यह लाइन कैसे काम करती है?" के रूप में एक लाइन है - क्या तुम समझ सकती हो? इसके बारे में, यहां बताया गया है.
ऐसा प्रोग्राम लिखें जो 3-डिम अरे को शुरू करता हो और तीसरे डाइमेंशन को भरता हो सभी तीन इंडेक्स के योग के साथ वैल्यू. हमारा समाधान यहां है.
कसरत #4: OO डिज़ाइन का एक बहुत बड़ा उदाहरण
यहां पूरी जानकारी दी गई है ऑब्जेक्ट-ओरिएंटेड डिज़ाइन का उदाहरण, जो शुरू से आखिर तक प्रोसेस करते रहें. आखिरी कोड, Java में लिखा जाता है प्रोग्रामिंग भाषा है, लेकिन इसके बाद से आप इसे पढ़ सकते हैं आ गए हैं.
कृपया इस पूरे उदाहरण पर काम करने के लिए समय निकालें. यह बहुत बढ़िया है पूरी प्रोसेस की इमेज और उन डिज़ाइन टूल की जानकारी दी गई है जो इसके साथ काम करते हैं.
यूनिट की टेस्टिंग
परिचय
टेस्टिंग, सॉफ़्टवेयर इंजीनियरिंग प्रोसेस का एक अहम हिस्सा है. यूनिट टेस्ट एक खास तरह का टेस्ट है, जो किसी एक छोटे सोर्स कोड का मॉड्यूल.यूनिट की जांच हमेशा इंजीनियर करता है और आम तौर पर उसी समय किया जाता है जब वे मॉड्यूल की कोडिंग करते हैं. टेस्ट ड्राइवर इसका इस्तेमाल Composer और डेटाबेस क्लास की जांच करने के लिए किया जाता है. ये यूनिट टेस्ट के उदाहरण हैं.
यूनिट टेस्ट में ये विशेषताएं होती हैं. उनका मकसद...
- कॉम्पोनेंट को अलग से टेस्ट करना
- डिटरमिनिस्टिक्स होते हैं
- आम तौर पर एक ही क्लास पर मैप होता है
- बाहरी संसाधनों पर निर्भर रहने से बचें, जैसे कि डेटाबेस, फ़ाइलें, नेटवर्क
- तेज़ी से लागू करना
- किसी भी क्रम में चलाया जा सकता है
ऐसे ऑटोमेटेड फ़्रेमवर्क और तरीके हैं जो सहायता करने और बड़े सॉफ़्टवेयर इंजीनियरिंग संगठनों में यूनिट टेस्टिंग के लिए लगातार काम कर रहा है. कुछ जटिल ओपन सोर्स यूनिट टेस्टिंग फ़्रेमवर्क हैं, जिन्हें हम के बारे में इस लेसन में आगे बताया है.
यूनिट टेस्टिंग के तहत होने वाले टेस्ट का उदाहरण नीचे दिया गया है.
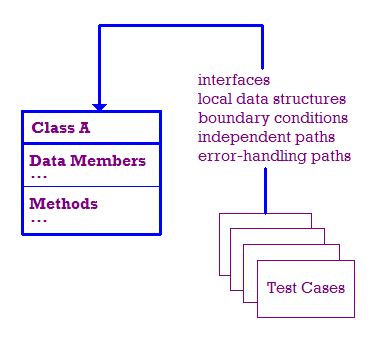
एक आदर्श दुनिया में, हम इन चीज़ों की जांच करते हैं:
- मॉड्यूल इंटरफ़ेस की जांच की जाती है, ताकि यह पक्का किया जा सके कि जानकारी अंदर और बाहर भेजी जा रही है या नहीं सही तरीके से.
- स्थानीय डेटा स्ट्रक्चर की जांच की जाती है, ताकि यह पक्का किया जा सके कि उनमें डेटा सही तरीके से सेव हो रहा है.
- मॉड्यूल सही तरीके से काम कर रहा है, यह पक्का करने के लिए, सीमाओं की शर्तों की जांच की जाती है उन सीमाओं तक पहुंचना होगा जो प्रोसेसिंग को सीमित या प्रतिबंधित करती हैं.
- हम मॉड्यूल के ज़रिए अलग-अलग पाथ की जांच करते हैं, ताकि यह पक्का कर सकें कि हर पाथ का इस्तेमाल किया जा रहा है और
इसलिए, मॉड्यूल में हर स्टेटमेंट को कम से कम एक बार एक्ज़ीक्यूट किया जाता है.
- आखिर में, हमें यह जांचना होगा कि गड़बड़ियां ठीक से हैंडल की जा रही हैं या नहीं.
कोड कवरेज
असल में, हम पूरा "कोड कवरेज" हासिल नहीं कर सकते को ध्यान में रखकर बनाया गया है. कोड कवरेज, विश्लेषण का एक तरीका होता है. इससे पता चलता है कि सॉफ़्टवेयर का कौनसा हिस्सा सिस्टम का इस्तेमाल, टेस्ट केस सुइट में किया गया है और इसके कुछ हिस्से नहीं किया गया है. अगर हम कोशिश करते हैं और 100% कवरेज हासिल कर लेते हैं, तो हम ज़्यादा समय खर्च करेंगे यूनिट की जांच करने का विकल्प होता है! यूनिट बनाने के बारे में सोचें के सभी इंडिपेंडेंट पाथ की जांच कर सकते हैं. यह तुरंत ही घातांकीय सवाल.
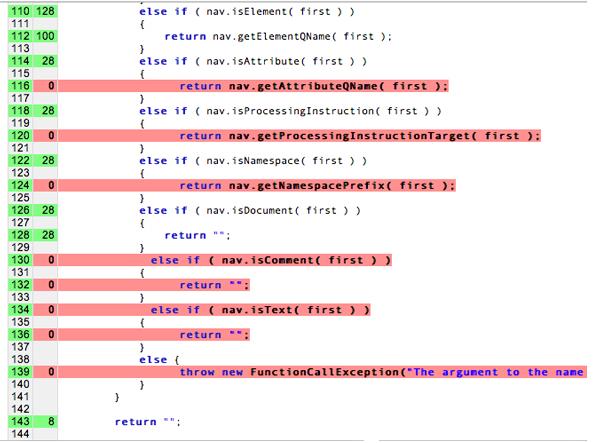
इस डायग्राम में लाल लाइनों की जांच नहीं की गई है, जबकि बिना रंग वाली लाइनों को परीक्षण किया गया.
100% कवरेज की कोशिश करने के बजाय, हम ऐसी जांचों पर फ़ोकस करते हैं जिनसे हमारा आत्मविश्वास बढ़ता है कि मॉड्यूल ठीक से काम कर रहा है. हम इन चीज़ों की जांच करते हैं:
- शून्य केस
- रेंज टेस्ट, जैसे कि पॉज़िटिव/नेगेटिव वैल्यू टेस्ट
- किनारे वाले केस
- गड़बड़ी के मामले
- ऐसे पाथ की जांच करना जो ज़्यादातर समय एक्ज़ीक्यूट हो सकते हैं
यूनिट टेस्ट फ़्रेमवर्क
ज़्यादातर यूनिट टेस्ट फ़्रेमवर्क, एक पाथ. दावे ऐसे स्टेटमेंट होते हैं जिनसे पता चलता है कि कोई शर्त सही है या नहीं. कॉन्टेंट बनाने किसी दावे का नतीजा सफल, गैर-घातक विफलता या घातक विफलता हो सकती है. इस तारीख के बाद दावा किया जाता है, तो प्रोग्राम सामान्य रूप से जारी रहता है. ऐसा तब होता है, जब नतीजा सफलता या गैर-घातक विफलता. यदि कोई गंभीर विफलता होती है, तो वर्तमान फ़ंक्शन रद्द किया जाता है.
टेस्ट में ऐसा कोड शामिल होता है जो आपके मॉड्यूल की स्थिति सेट करता है या उसमें बदलाव करता है. के साथ कई दावे किए गए हैं. इससे सही नतीजों की पुष्टि की जा सकती है. अगर सभी दावे किसी टेस्ट में सफल होने का मतलब है कि वह सही नतीजे देता है, फिर टेस्ट सफल होता है; अन्य मामलों में यह काम नहीं करता.
टेस्ट केस में एक या कई टेस्ट शामिल होते हैं. हम टेस्ट को ऐसे टेस्ट केस में ग्रुप करते हैं जिनमें इससे जांचे गए कोड का स्ट्रक्चर दिखता है. इस कोर्स में, हम पब्लिशर के लिए CPPUnit को हमारे यूनिट टेस्ट फ़्रेमवर्क के तौर पर इस्तेमाल किया जा सकता है. इस फ़्रेमवर्क की मदद से, हम यूनिट टेस्ट लिख सकते हैं और उन्हें अपने-आप चलने दें. इससे आपको उनकी सफलता या असफलता की रिपोर्ट मिलेगी सकता है.
CPPUnit इंस्टॉलेशन
यहां से CPPUnit कोड डाउनलोड करें SourceForge शामिल हो सकता है. कोई सही डायरेक्ट्री ढूंढें और tar.gz फ़ाइल को वहां रखें. इसके बाद, निम्न कमांड (Linux, Unix में) का उपयोग करते हुए, उचित cppunit फ़ाइल को हटाकर नाम:
gunzip filename.tar.gz tar -xvf filename.tar
अगर आप Windows में काम कर रहे हैं, तो आपको tar.gz निकालने के लिए उपयोगिता ढूंढनी पड़ सकती है फ़ाइलें शामिल हैं. अगला कदम, लाइब्रेरी को इकट्ठा करना है. cppunit डायरेक्ट्री में बदलें. वहां एक INSTALL फ़ाइल मौजूद है, जिसमें खास निर्देश दिए गए हैं. आम तौर पर, आपको चलाने की ज़रूरत है:
./configure make install
अगर आपको समस्याएं आती हैं, तो INSTALL फ़ाइल देखें. आम तौर पर, लाइब्रेरी यह आपको cppunit/src/cppunit डायरेक्ट्री में मिलेगा. यह देखने के लिए कि कंपाइलेशन काम कर रहा है या नहीं, cppunit/examples/simple डायरेक्ट्री में जाएं और "make" टाइप करें. अगर आपने हर चीज़ ठीक हो जाती है, तो आप पूरी तरह से तैयार हैं.
एक बेहतरीन ट्यूटोरियल उपलब्ध है यहां पढ़ें. कृपया यह ट्यूटोरियल देखें और कॉम्प्लेक्स नंबर वाली क्लास और उससे जुड़ी क्लास बनाएं यूनिट टेस्ट का इस्तेमाल कर सकते हैं. cppunit/examples डायरेक्ट्री में कई और उदाहरण हैं.
मुझे ऐसा क्यों करना होगा\
इंडस्ट्री में यूनिट की जांच करना कई वजहों से अहम है. कोई बकाया राशि नहीं है हमें पहले से ही एक वजह पता है: हम देखते हैं कि इस समय हमें अपने काम की जांच करने के लिए कोई तरीका चाहिए कोड डेवलप करना. भले ही हम बहुत छोटा सा प्रोग्राम बना रहे हों, फिर भी हम यह पक्का करने के लिए कि हमारा प्रोग्राम उम्मीद के मुताबिक काम कर रहा है या नहीं, उसकी जांच करने वाले और ड्राइवर लिखें.
लंबे अनुभव के आधार पर, इंजीनियरों को पता है कि कोई प्रोग्राम काम करेगा या नहीं वे बहुत कम हैं. यूनिट टेस्ट में टेस्टिंग का इस्तेमाल करके इस आइडिया पर काम किया जा सकता है जो अपने-आप जांचने और बार-बार इस्तेमाल किए जा सकते हों. दावों की जगह मैन्युअल रूप से आउटपुट की जाँच करता है. दरअसल, इस टेस्ट के नतीजों को समझना आसान है. चाहे वह पास हो जाए या फ़ेल हो जाए), तो टेस्ट बार-बार चलाए जा सकते हैं. एक ऐसा सुरक्षा नेट है जो आपके कोड को बदलने के लिए ज़्यादा लचीला बनाता है.
आइए, इसे ठोस रूप में समझते हैं: जब आप पहली बार अपना तैयार कोड CVS बिलकुल सही तरीके से काम करता है. और यह कुछ समय तक ठीक से काम करता है. इसके बाद एक दिन, कोई अन्य व्यक्ति आपका कोड बदलता है. जल्दी या बाद में, क्योंकि कोई ब्रेक हो सकता है आपका कोड. क्या आपको लगता है कि वे खुद इस पर ध्यान देंगे? संभावना नहीं है. हालांकि, जब यूनिट टेस्ट लिखें, ऐसे सिस्टम मौजूद हैं जो उन्हें हर दिन अपने-आप चला सकते हैं. इन्हें लगातार इंटिग्रेशन सिस्टम कहा जाता है. इसलिए, जब वह इंजीनियर X आपका कोड तोड़ देता है, सिस्टम उन्हें तब तक खराब ईमेल भेजेगा, जब तक वे ठीक नहीं हो जाते इसे. भले ही इंजीनियर X आप ही हों!
सॉफ़्टवेयर बनाने और उस सॉफ़्टवेयर को सुरक्षित रखने में मदद करने के अलावा में ये उपाय अपनाएं:
- एक एक्ज़ीक्यूटेबल स्पेसिफ़िकेशन और दस्तावेज़ सिंक करने की सुविधा देता है सेट करें. दूसरे शब्दों में, यूनिट टेस्ट पढ़कर यह जाना जा सकता है कि वह व्यवहार जो मॉड्यूल में काम करता हो.
- ज़रूरी शर्तों को लागू करने से अलग करने में आपकी मदद करता है. क्योंकि आप दावा कर रहे हैं का इस्तेमाल करते हैं, तो आपको इसके बारे में साफ़ तौर पर सोचने का मौका मिलता है ध्यान देने की ज़रूरत नहीं होती.
- एक्सपेरिमेंट करने में मदद करता है. अगर आपके पास सुरक्षा के लिए ऐसा जाल है जिससे आपको सूचना मिलेगी कि तो मॉड्यूल का व्यवहार टूट गया है, तो चीज़ों को आज़माने की ज़्यादा संभावना है और अपने डिज़ाइन को फिर से कॉन्फ़िगर करें.
- आपके डिज़ाइन को बेहतर बनाता है. यूनिट की जांच के बारे में अच्छी तरह से लिखने के लिए, आपको अक्सर अपने कोड को और टेस्ट करने लायक बनाएं. टेस्ट करने लायक कोड, टेस्ट न किए जा सकने वाले कोड के मुकाबले ज़्यादा मॉड्यूलर होता है कोड.
- इससे क्वालिटी अच्छी बनी रहती है. ज़रूरी सिस्टम में आने वाले एक छोटे से बग की वजह से किसी कंपनी को जिससे उपयोगकर्ता की खुशी या भरोसे को कम किया जा सकता है. कॉन्टेंट बनाने यूनिट टेस्ट से इस संभावना को कम किया जा सकता है. गड़बड़ियों के बारे में जानकर साथ ही, QA टीम को ज़्यादा बेहतर और मुश्किल काम करने में मदद मिलती है. होने वाली गड़बड़ियों की रिपोर्ट करने में मदद मिलती है.
Composer डेटाबेस ऐप्लिकेशन के लिए CPPUnit का इस्तेमाल करके यूनिट टेस्ट लिखने के लिए कुछ समय निकालें. सहायता के लिए, cppunit/examples/ डायरेक्ट्री देखें.
Google कैसे काम करता है
शुरुआती जानकारीकल्पना करें कि मध्य युग के एक भिक्षु की हज़ारों पांडुस्क्रिप्ट देख रहे हों उनके मठ के संग्रह को.“अरस्तू का वह गाना कहां है...”

यह उनके लिए अच्छी बात है कि किताब की पांडुस्क्रिप्ट, कॉन्टेंट के हिसाब से व्यवस्थित की जाती हैं और उनके लिखे उसमें शामिल जानकारी को वापस पाने में मदद करने के लिए, उसमें खास सिंबल का इस्तेमाल किया गया हो हर एक. ऐसे संगठन के बिना, यह पता लगाना बहुत मुश्किल होगा कि पढ़ें.
बड़े कलेक्शन की लिखित जानकारी को सेव और वापस पाने की गतिविधि इसे जानकारी वापस पाना (आईआर) कहा जाता है. इस गतिविधि में लगातार बढ़ोतरी हुई है सदियों से महत्वपूर्ण रहा है, खास तौर पर काग़ज़ और प्रिंटिंग जैसे आविष्कारों में दबाएं. पहले इसमें कुछ ही लोग शामिल थे. अब, हालांकि, करोड़ों लोग जानकारी वापस पाने के लिए उस दिन जब वे किसी सर्च इंजन का इस्तेमाल करते हैं या अपना डेस्कटॉप खोजते हैं.
जानकारी वापस पाने की प्रोसेस शुरू करना

डॉ॰ सियस ने 30 सालों में, बच्चों के लिए 46 किताबें लिखी हैं. उनकी किताबों के बारे में बिल्लियों, गायों, और हाथियों के साथ इंटरैक्ट करते हैं. क्या तुम्हें याद है किस कहानी में कौनसे जीव-जंतु थे? अगर आप माता-पिता नहीं हैं, तो सिर्फ़ बच्चे डॉ. सियस की कहानियों के किस सेट में जीव हैं:
(COW और BEE) या CROWS
इस समस्या को हल करने में मदद करने के लिए, हम जानकारी वापस पाने के कुछ क्लासिक मॉडल लागू करेंगे समस्या.
जानवरों का बल इस्तेमाल करना सबसे ज़रूरी है: डॉ॰ सियस की सभी 46 कहानियां हासिल करें और शुरुआत करें पढ़ना. हर किताब के लिए, ध्यान दें कि किस किताब में COW और BEE शब्द हैं और उसी समय, ऐसी किताबें खोजें जिनमें CROWS शब्द हो. कंप्यूटर आम तौर पर इस समय हमारी तुलना में अधिक तेज़ है. अगर हमारे पास डॉ॰ सियस की किताबों के सभी टेक्स्ट हों डिजिटल रूप में, जैसे टेक्स्ट फ़ाइलों की तरह, हम फ़ाइलों को ग्रेप कर सकते हैं. जैसी छोटी सी किताबों का संग्रह है, तो यह तकनीक अच्छे से काम करती है.
हालांकि, ऐसी कई स्थितियां हैं जहां हमें और चीज़ों की ज़रूरत होती है. उदाहरण के लिए, ग्रेप के लिए ऑनलाइन उपलब्ध डेटा बहुत बड़ा है. हम यह भी नहीं करते हैं केवल ऐसे दस्तावेज़ चाहिए जो हमारी स्थिति से मेल खाते हों, लेकिन हम इसके अभ्यस्त हो गए हैं काम के हिसाब से उनकी रैंकिंग तय करना.
ग्रेप के अलावा दूसरा तरीका, किसी कलेक्शन में दस्तावेज़ों का इंडेक्स बनाना है करने से पहले उन्हें शामिल कर लिया जाता है. IR का इंडेक्स, किताब के पिछले हिस्से पर जाना पड़ सकता है. हम प्रत्येक कीवर्ड में सभी शब्दों (या पद) की सूची बनाते हैं डॉ. सियस की कहानी, जिसमें “द”, “और” और अन्य जुड़ाव महसूस कराने वाले शब्द शामिल नहीं किए गए हैं, पूर्वसर्ग, वगैरह (इन्हें स्टॉप-वर्ड कहा जाता है). इसके बाद, हम इस जानकारी से शर्तों को आसानी से समझा जा सकता है. जिनमें वे मौजूद हैं.
ऐसा हो सकता है कि इसमें एक मैट्रिक्स हो, जिसमें खबरें सबसे ऊपर दिखती हों और प्रत्येक पंक्ति में सूचीबद्ध शब्द देखें. कॉलम में “1” आने का मतलब है कि यह शब्द दिखता है उस कॉलम की कहानी में.
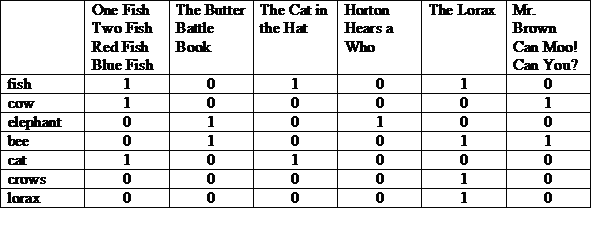
हम हर पंक्ति या कॉलम को बिट वेक्टर के रूप में देख सकते हैं. किसी पंक्ति का बिट वेक्टर संकेत देता है किन खबरों में शब्द दिखेगा. कॉलम का बिट वेक्टर बताता है कि कौनसे शब्द दिखाई नहीं देती हैं.
हम अपने मूल सवाल पर वापस आते हैं:
(COW और BEE) या CROWS
हम इन शब्दों के लिए बिट वेक्टर लेते हैं और पहले थोड़ा-बहुत काम करते हैं और फिर थोड़ा-बहुत या फिर सटीक जवाब देता है.
(100001 और 010011) या 000010 = 000011
जवाब: “मिस्टर ब्राउन कैन मू! क्या तुम कर सकते हो?” और “द लॉरैक्स”. यह एक इलस्ट्रेशन है बूलियन रिकवरी मॉडल का इस्तेमाल करता है, जो “एग्ज़ैक्ट मैच” मॉडल है.
मान लीजिए कि हमें डॉ. सियस की सभी कहानियों और सभी कहानियों में मिलते-जुलते शब्दों का इस्तेमाल करें. मैट्रिक्स में काफ़ी बढ़ोतरी होगी और एक अहम का मतलब है कि ज़्यादातर एंट्री 0 होंगी. शायद मैट्रिक्स सबसे अच्छा नहीं होता इंडेक्स की वैल्यू भी दिखाएं. हमें सिर्फ़ 1 को सेव करने का तरीका चाहिए.
कुछ सुधार
इस समस्या को हल करने के लिए, IR में इस्तेमाल किए जाने वाले स्ट्रक्चर को इनवर्टेड इंडेक्स कहा जाता है. हम शब्दों का एक शब्दकोश बनाते हैं और फिर हर शब्द के लिए, हमारे पास एक सूची होती है जो उन दस्तावेज़ों को रिकॉर्ड करता है जिनमें उस टर्म की खोज होती है. इस सूची को पोस्टिंग कहा जाता है सूची. इस स्ट्रक्चर को दिखाने के लिए, एक-एक करके लिंक की गई सूची अच्छी तरह काम करती है देखें.
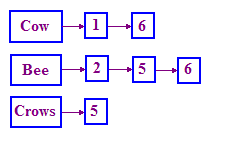
अगर आपको लिंक की गई सूचियों के बारे में नहीं पता है, तो Google पर जाकर "लिंक किया गया"
लिस्ट किया गया है और आपको कई संसाधन मिलेंगे, जो
और उसका इस्तेमाल कैसे किया जाता है. हम इसके बारे में बाद के मॉड्यूल में ज़्यादा जानकारी देंगे.
ध्यान दें कि हम दस्तावेज़ आईडी (DocIDs) का इस्तेमाल पब्लिश करें. हम इन DocID को क्रम से भी लगाते हैं, क्योंकि इससे क्वेरी को प्रोसेस करने में मदद मिलती है.
हम क्वेरी को कैसे प्रोसेस करते हैं? मूल समस्या के लिए, हम पहले COW की पोस्ट देखते हैं सूची, फिर बीईई पोस्टिंग सूची. इसके बाद हम उन्हें “मर्ज” करते हैं:
- दोनों सूचियों में मार्कर बनाए रखें और दोनों सूचियों में बदलाव करें साथ-साथ
- हर चरण में, दोनों पॉइंटर से बताए गए DocID की तुलना करें.
- अगर वे एक जैसे हैं, तो उस DocID को नतीजे की सूची में रखें या पॉइंटर को आगे ले जाएं जो छोटे docID पर ले जाते हैं.
इन्वर्टेड इंडेक्स बनाने का तरीका यहां बताया गया है:
- हर पसंदीदा दस्तावेज़ के लिए एक DocID असाइन करें.
- हर दस्तावेज़ के लिए, उससे जुड़े शब्दों की पहचान करें (टोकनाइज़ करें).
- हर शब्द के लिए, एक रिकॉर्ड बनाएं जिसमें शब्द शामिल हो, जहां DocID होता है पाया गया है और उस दस्तावेज़ में उसकी फ़्रीक्वेंसी भी शामिल है. ध्यान दें कि एक से ज़्यादा विकल्प हो सकते हैं किसी खास शब्द के लिए रिकॉर्ड करता है. हालांकि, इसके लिए ज़रूरी है कि शब्द एक से ज़्यादा दस्तावेज़ों में मौजूद हो.
- रिकॉर्ड को शब्द के हिसाब से क्रम में लगाएं.
- इनके लिए एकल रिकॉर्ड प्रोसेस करके शब्दकोश और पोस्ट की सूची बनाएं एक शब्द, और उन शब्दों के लिए एक से ज़्यादा रिकॉर्ड को मिलाना भी जो ज़्यादा खोज नतीजों में दिखते हैं एक दस्तावेज़ से ज़्यादा. DocID की लिंक की गई सूची (क्रम से लगाए गए) बनाएं. हर शब्द की एक फ़्रीक्वेंसी भी होती है, जो सभी रिकॉर्ड में फ़्रीक्वेंसी का योग होता है एक शब्द के लिए.
प्रोजेक्ट
ऐसे कई लंबे सादे टेक्स्ट वाले दस्तावेज़ ढूंढें जिनके साथ प्रयोग किया जा सकता है. कॉन्टेंट बनाने प्रोजेक्ट में, एल्गोरिदम का इस्तेमाल करके दस्तावेज़ों के लिए इन्वर्टेड इंडेक्स को ऊपर बताया गया है. क्वेरी के इनपुट के लिए आपको एक इंटरफ़ेस भी बनाना होगा और उन्हें प्रोसेस करने का एक इंजन. आपको फ़ोरम पर कोई प्रोजेक्ट पार्टनर मिल सकता है.
इस प्रोजेक्ट को पूरा करने की संभावित प्रोसेस यहां दी गई है:
- सबसे पहले, दस्तावेज़ों में शब्दों की पहचान करने की रणनीति तय करें. ऐसे सभी स्टॉप-वर्ड की एक सूची बनाएं जिनके बारे में आपको लगता है और एक ऐसा फ़ंक्शन लिखो फ़ाइलों के शब्दों को पढ़ता है, शर्तों को सेव करता है, और रोके गए शब्दों को हटा देता है. आपको अपनी सूची में, स्टॉप-शब्द जोड़ने पड़ सकते हैं बार-बार इस्तेमाल किया जा सकता है.
- अपने फ़ंक्शन की जांच करने के लिए, CPPUnit टेस्ट केस लिखें और हर चीज़ को सही तरीके से टेस्ट करने के लिए एक मेकफ़ाइल बनाएं एक साथ मिलकर काम करें. अपनी फ़ाइलों को CVS में देखें, खासकर तब, जब आप अपने पार्टनर के साथ मिलकर काम करते हैं. CVS इंस्टेंस खोलने के तरीके के बारे में थोड़ी जानकारी मिल सकती है की अहमियत को समझता है.
- जगह की जानकारी का डेटा, जैसे कि कौनसी फ़ाइल और कहां मौजूद है, जैसी जानकारी शामिल करने के लिए प्रोसेसिंग जोड़ें फ़ाइल में कोई शब्द मौजूद है या नहीं? उदाहरण के लिए, शायद आप या पैराग्राफ़ संख्या.
- इस अतिरिक्त फ़ंक्शन की जांच करने के लिए, CPPUnit टेस्ट केस लिखें.
- इनवर्टेड इंडेक्स बनाएं और हर शब्द के रिकॉर्ड में जगह का डेटा स्टोर करें.
- ज़्यादा टेस्ट केस लिखें.
- उपयोगकर्ता को क्वेरी डालने की अनुमति देने के लिए इंटरफ़ेस डिज़ाइन करें.
- ऊपर बताए गए खोज एल्गोरिदम का इस्तेमाल करके, इन्वर्टेड इंडेक्स को प्रोसेस करें और उपयोगकर्ता को स्थान डेटा दिखाएं.
- इस आखिरी हिस्से के लिए, टेस्ट केस भी शामिल करें.
जैसा कि हमने सभी प्रोजेक्ट में किया है. प्रोजेक्ट पार्टनर ढूंढने के लिए, फ़ोरम का इस्तेमाल करें और चैट करें साथ ही, अलग-अलग आइडिया शेयर करना भी शामिल है.
एक और सुविधा
कई आईआर सिस्टम में प्रोसेसिंग के एक सामान्य चरण को स्टेमिंग कहा जाता है. कॉन्टेंट बनाने स्टेमिंग के पीछे का मुख्य मकसद यह है कि उपयोगकर्ता “रिकवरी” के बारे में जानकारी ढूंढते हैं आपकी रुचि ऐसे दस्तावेज़ों में भी होगी जिनमें “वापस पाना” शामिल हो, “वापस लाया गया”, “वापस लाया जा रहा है” वगैरह. सिस्टम में इन वजहों से गड़बड़ियां हो सकती हैं स्टेमिंग कम है, इसलिए यह थोड़ा मुश्किल है. उदाहरण के लिए, अगर किसी उपयोगकर्ता ने हो सकता है कि आपको “सूचनाएँ हासिल करना” टाइटल वाला दस्तावेज़ मिले. स्टेमिंग की वजह से, रिकवर होने वाले लोग”. स्टेमिंग के लिए एक उपयोगी एल्गोरिदम पोर्टर एल्गोरिदम.