Instructivo del lenguaje C++
Las primeras secciones instructivo cubrirá el material básico ya presentado en los últimos dos módulos y brinda más información sobre conceptos avanzados. Nuestro en este módulo, nos enfocaremos en la memoria dinámica y en más detalles sobre objetos y clases. También se presentan algunos temas avanzados, como la herencia, el polimorfismo, las plantillas, y espacios de nombres. Las estudiaremos más adelante en el curso Avanzado de C++.
Diseño orientado a objetos
Este es un excelente instructivo sobre el diseño orientado a objetos. Aplicaremos las de aprendizaje automático que se presenta aquí en el proyecto de este módulo.
Aprendizaje del ejemplo 3
En este módulo, nos enfocaremos en adquirir más práctica con punteros, orientaciones el diseño, arrays multidimensionales, clases/objetos. Realiza las siguientes tareas ejemplos. No podemos enfatizar lo suficiente que la clave para convertirse en un buen programador es practicar, practicar.Ejercicio n.o 1: Más práctica con punteros
Si necesitas más práctica con los indicadores, lee este , que abarca todos los aspectos de los punteros y proporciona muchos ejemplos de programas.
¿Cuál es el resultado del siguiente programa? No ejecutes el programa, pero haz una imagen de la memoria para determinar el resultado.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Una vez que hayas determinado la salida manualmente, ejecuta el programa para ver si correcto
Ejercicio n.o 2: Practique más con las clases y los objetos
Si necesitas más práctica con clases y objetos, aquí es un recurso que pasa por la implementación de dos clases pequeñas. Toma un poco para hacer los ejercicios.
Ejercicio n.o 3: Arreglos multidimensionales
Considera el siguiente programa:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}En este programa, hay una línea que dice "¿Cómo funciona esta línea?". - ¿Puedes averiguarlo? Aquí encontrarás la explicación.
Escribir un programa que inicialice un array de 3 atenuaciones y rellene la 3a dimensión con la suma de los tres índices. Esta es nuestra solución.
Ejercicio n.o 4: Ejemplo de diseño de OO extensivo
A continuación, se incluye de diseño orientado a objetos, que abarca toda la de principio a fin. El código final se escribe en el código lenguaje de programación, pero podrás leerlo según lo lejos que que han llegado.
Tómate el tiempo para revisar este ejemplo completo. Este es un ilustración del proceso y las herramientas de diseño que lo respaldan.
Prueba de unidades
Introducción
Las pruebas son una parte fundamental del proceso de ingeniería de software. Una prueba de unidades es un tipo particular de prueba, que comprueba la funcionalidad de una sola pequeña de código fuente.La prueba de unidades siempre la realiza el ingeniero por lo general, al mismo tiempo que codifican el módulo. Las pruebas que te llevan que se usan para probar las clases Composer y Database son ejemplos de pruebas de unidades.
Las pruebas de unidades tienen las siguientes características. Ellos...
- probar un componente de forma aislada
- son deterministas.
- generalmente se asignan a una sola clase
- evitar las dependencias de recursos externos, p.ej., bases de datos, archivos, redes
- ejecutar rápidamente
- pueden ejecutarse en cualquier orden
Hay metodologías y frameworks automatizados que brindan asistencia y coherencia para las pruebas de unidades en grandes organizaciones de ingeniería de software. Existen algunos frameworks sofisticados de prueba de unidades de código abierto aprenderás más adelante en esta lección.
A continuación, se muestran las pruebas que se realizan como parte de las pruebas de unidades.

En un mundo ideal, probamos lo siguiente:
- La interfaz del módulo se prueba para garantizar que la información entre y salga correctamente.
- Las estructuras de datos locales se examinan para garantizar que almacenen los datos de forma adecuada.
- Se prueban las condiciones de los límites para garantizar que el módulo funcione correctamente. en los límites que limitan o restringen el procesamiento.
- Probamos rutas independientes en el módulo para asegurarnos de que cada una
por lo tanto, cada instrucción del módulo se ejecuta al menos una vez.
- Por último, debemos verificar que los errores se manejen correctamente.
Cobertura de código
En realidad, no podemos alcanzar una "cobertura de código" completa con nuestras pruebas. La cobertura de código es un método de análisis que determina qué partes de un software de casos de prueba ejecutados (cubiertos) por el paquete y qué partes no se ejecutaron. Si intentamos alcanzar el 100% de cobertura, dedicaremos más tiempo escribir pruebas de unidades que escribir el código real. Considera crear una unidad realiza pruebas para todas las rutas de acceso independientes de lo siguiente. Esto puede convertirse rápidamente un problema exponencial.
En este diagrama, las líneas rojas no se prueban, mientras que las líneas sin color se y cómo se entrenó y probó el modelo.
En lugar de intentar una cobertura del 100%, nos enfocamos en pruebas que aumentan nuestra confianza que el módulo funcione correctamente. Realizamos pruebas para detectar lo siguiente:
- Casos nulos
- Pruebas de rango, p.ej., pruebas de valor positivo o negativo
- Casos extremos
- Casos de falla
- Prueba las rutas de acceso que tienen más probabilidades de ejecutarse la mayor parte del tiempo
Marcos de trabajo de prueba de unidades
La mayoría de los frameworks de prueba de unidades usan aserciones para probar valores durante la ejecución de una ruta. Las aserciones son declaraciones que verifican si una condición es verdadera. El resultado de una aserción puede ser éxito, falla recuperable o falla irrecuperable. Después del una aserción, el programa continúa normalmente si el resultado es el éxito o la falla recuperable. Si se produce una falla irrecuperable, la función actual se anula.
Las pruebas consisten en código que configura el estado o manipula tu módulo, con un número de aserciones que verifican los resultados esperados. Si todas las aserciones en una prueba son exitosas, es decir, devuelven un valor true, luego la prueba tiene éxito; de lo contrario falla.
Un caso de prueba contiene una o más pruebas. Agrupamos las pruebas en casos de prueba reflejan la estructura del código probado. En este curso, usaremos CPPUnit como marco de trabajo de prueba de unidades. Con este framework, podemos escribir pruebas de unidades en C++ y ejecutarlas automáticamente y obtener un informe sobre el éxito o el fracaso de pruebas.
Instalación de CPPUnit
Descarga el código CPPUnit de SourceForge. Busca un directorio apropiado y coloca el archivo tar.gz allí. Luego, ingresa siguientes comandos (en Linux, Unix), sustituyendo el archivo cppunit apropiado nombre:
gunzip filename.tar.gz tar -xvf filename.tar
Si trabajas en Windows, es posible que debas buscar una utilidad para extraer tar.gz. archivos. El siguiente paso es compilar las bibliotecas. Cambia al directorio cppunit. Allí encontrarás un archivo INSTALL que brinda instrucciones específicas. Generalmente, debes ejecutar:
./configure make install
Si tienes problemas, consulta el archivo INSTALL. Por lo general, las bibliotecas que se encuentra en el directorio cppunit/src/cppunit. Para comprobar que la compilación funcionó, ve al directorio cppunit/examples/simple y escribe "make". Si todo se compila bien, entonces está todo listo.
Hay un instructivo excelente disponible aquí. Lee este instructivo y crea la clase de número compleja y sus elementos asociados. y pruebas de unidades. Encontrarás varios ejemplos adicionales en el directorio cppunit/examples.
¿Por qué debo hacer esto?
Las pruebas de unidades es muy importante en la industria por varios motivos. Está ya estamos familiarizados con una razón: Necesitamos alguna forma de revisar nuestro trabajo mientras desarrollar código. Incluso cuando desarrollamos un programa muy pequeño, escribiremos algún tipo de verificador o controlador para garantizar que el programa haga lo que se espera.
Gracias a su larga experiencia, los ingenieros saben que las posibilidades de que un programa funcione en el primer intento son muy pequeñas. Las pruebas de unidades se basan en esta idea mediante la ejecución de pruebas programas autocontrolados y repetibles. Las aserciones sustituyen a las operaciones inspeccionando los resultados. Y, debido a que es fácil de interpretar los resultados (la pasa o reprueba), las pruebas se pueden ejecutar una y otra vez, lo que proporciona una red de seguridad que haga que tu código sea más resistente al cambio.
Hagamos esto en términos concretos: cuando envíes por primera vez tu código finalizado a CVS, funciona a la perfección. Y sigue funcionando perfectamente durante un tiempo. Después algún día, alguien más cambiará tu código. Tarde o temprano, alguien se romperá tu código. ¿Crees que lo notarán solos? No es probable. Pero cuando escribir pruebas de unidades, existen sistemas que pueden ejecutarlas automáticamente todos los días. Estos se denominan sistemas de integración continua. Cuando ese ingeniero X rompe tu código, el sistema le enviará correos electrónicos desagradables hasta que lo corrijan que la modifica. ¡Incluso si el ingeniero X eres TÚ!
Además de ayudarte a desarrollar software y, luego, mantenerlo seguro ante el cambio, pruebas de unidades:
- Crea una especificación ejecutable y documentación que se mantiene sincronizada con el código. En otras palabras, puedes leer una prueba de unidades para saber qué y el comportamiento que admite el módulo.
- Te ayuda a separar los requisitos de la implementación. Dado que afirmas comportamiento visible externamente, tienes la oportunidad de pensarlo explícitamente en lugar de mezclar ideas sobre cómo implementar el comportamiento.
- Admite la experimentación. Si tienes una red de seguridad que te avisa cuando rompiste el comportamiento de un módulo, es más probable que pruebes y reconfigurar tus diseños.
- Mejora tus diseños. Escribir pruebas de unidades exhaustivas a menudo requiere que y hacer que tu código sea más fácil de probar. El código que se puede probar suele ser más modular que el que no se puede probar. código.
- Mantiene un alto nivel de calidad. Un pequeño error en un sistema crítico puede hacer que una empresa perder millones de dólares o, peor aún, la felicidad o confianza de un usuario. El la red de seguridad que proporcionan las pruebas de unidades disminuye esta posibilidad. Cazando insectos también permiten que los equipos de QA en lugar de informar fallas obvias.
Tómate un tiempo para escribir pruebas de unidades con CPPUnit en la aplicación de base de datos de Composer. Consulta el directorio cppunit/examples/ para obtener ayuda.
Cómo trabaja Google
IntroducciónImagina un monje de la Edad Media que observa los miles de manuscritos en los archivos de su monasterio."¿Dónde está ese de Aristóteles..."

Afortunadamente para él, los manuscritos están organizados por contenido y están inscritos con símbolos especiales para facilitar la recuperación de información incluida en cada uno. Sin dicha organización, sería muy difícil encontrar los recursos manuscrito.
La actividad de almacenar y recuperar información escrita de grandes colecciones se denomina recuperación de información (IR). Esta actividad se ha vuelto cada vez más importante a lo largo de los siglos, especialmente con inventos como el papel y la impresión. presionar. Solía ser algo en el que solo algunas personas estaban ocupadas. Ahora, Sin embargo, cientos de millones de personas se dedican a recuperar información de cada día cuando usan un motor de búsqueda o realizan búsquedas en su computadora de escritorio.
Cómo comenzar con la recuperación de información

Dr. Seuss escribió 46 libros infantiles en el transcurso de 30 años. Sus libros cuentan de gatos, vacas y elefantes; de quién son, grinches y lórax. ¿Recuerdas ¿Cuáles son las criaturas en qué historia? A menos que seas madre o padre, solo los niños pueden te dicen en qué conjunto de historias de Dr. Seuss estas criaturas tienen:
(COW y BEE) o CROWS
Aplicaremos algunos modelos clásicos de recuperación de información para ayudarnos a resolver este problema problema.
Un enfoque obvio es la fuerza bruta: obtén las 46 historias de Dr. Seuss y comienza lectura. Para cada libro, toma nota de cuáles contienen las palabras COW y BEE, y Al mismo tiempo, busca libros que contengan la palabra CROWS. Las computadoras son mucho más rápido que nosotros. Si tenemos todo el texto de los libros de Dr. Seuss en formato digital, por ejemplo, como archivos de texto, podemos hacer un grep de los archivos. Para un en una pequeña colección como los libros de Dr. Seuss, esta técnica funciona bien.
Sin embargo, hay muchas situaciones en las que necesitamos más. Por ejemplo, la colección de todos los datos en línea en este momento son demasiado grandes para que lo controle grep. Tampoco solo queremos los documentos que coinciden con nuestra condición, nos hemos acostumbrado clasificándolos según su relevancia.
Otro enfoque, además del grep, es crear un índice de los documentos en una colección antes de realizar la búsqueda. Un índice en IR es similar a un índice en el del reverso de un libro de texto. Hacemos una lista de todas las palabras (o términos) de cada una Dr. Seuss, dejando de lado palabras como "el", "y" y otras conexiones, preposiciones, etc. (se denominan palabras irrelevantes). Luego, representamos esta información de manera que facilite la búsqueda de los términos y la identificación las historias en las que se encuentran.
Una representación posible es una matriz con las historias en la parte superior, y los términos enumerados en cada fila. Un "1" en una columna indica que el término aparece en la historia de esa columna.
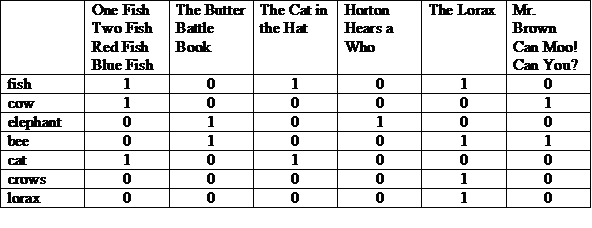
Podemos ver cada fila o columna como un vector de bits. El vector de bits de una fila indica en las que aparece el término. El vector de bits de una columna indica qué términos aparecer en la historia.
Volviendo a nuestro problema original:
(COW y BEE) o CROWS
Tomamos los vectores de bits para estos términos y, primero, aplicamos el operador AND a nivel de bits, luego, un OR a nivel de bits en el resultado.
(100001 y 010011) o 000010 = 000011
La respuesta es “Sr. Marrón puede moo. ¿Puedes hacerlo tú?” y “El Lorax”. Esta es una ilustración del modelo de recuperación booleana, que es un modelo de "concordancia exacta".
Supongamos que expandimos la matriz para incluir todas las historias de Dr. Seuss y todas términos relevantes en las historias. La matriz creciera considerablemente y sería importante observación es que la mayoría de las entradas serían 0. Una matriz probablemente no es la mejor para el índice. Necesitamos encontrar una manera de almacenar solo los 1.
Algunas mejoras
La estructura que se usa en IR para resolver este problema se denomina índice invertido. Mantenemos un diccionario de términos y, para cada uno, tenemos una lista que registre los documentos en los que aparece el término. Esta lista se denomina publicaciones lista. Una lista vinculada de forma única funciona bien para representar esta estructura como se muestra a continuación.

Si no conoces las listas vinculadas, haz una búsqueda de Google en "vinculadas
list in C++”, y encontrarás muchos recursos que describen cómo crear uno,
y cómo se usan. Abordaremos esto con más detalle en otro módulo.
Ten en cuenta que usamos los IDs de documento (DocIDs) en lugar del nombre del historia. También ordenamos estos DocID, ya que facilita el procesamiento de consultas.
¿Cómo procesamos una consulta? Para el problema original, primero encontramos las publicaciones de COW y luego la lista de publicaciones de BEE. Luego, los “fusionamos”:
- Mantén los marcadores en ambas listas y revisa las dos listas de publicaciones. al mismo tiempo.
- En cada paso, compara el DocID al que apuntan ambos punteros.
- Si son iguales, coloca ese DocID en una lista de resultados o haz que el puntero avance. que apunta al docID más pequeño.
A continuación, se muestra cómo se puede crear un índice invertido:
- Asigna un DocID a cada documento de interés.
- Para cada documento, identifica los términos relevantes (asignación de token).
- Para cada término, crea un registro que consista en el término, el DocID donde cada búsqueda y una frecuencia en ese documento. Ten en cuenta que puede haber varias de un término específico si aparece en más de un documento.
- Ordena los registros por término.
- Crear el diccionario y la lista de publicaciones procesando los registros únicos de un término, además de combinar los múltiples registros de los términos que aparecen en más de un documento. Crea una lista vinculada de los DocID (en orden). Cada también tiene una frecuencia, que es la suma de las frecuencias en todos los registros por un período.
El proyecto
Busca varios documentos extensos de texto simple con los que puedes experimentar. El proyecto es crear un índice invertido de los documentos mediante los algoritmos descrita anteriormente. También deberás crear una interfaz para la entrada de consultas y un motor de procesamiento. Puedes encontrar un socio para el proyecto en el foro.
A continuación, se muestra un posible proceso para completar este proyecto:
- Lo primero que hay que hacer es definir una estrategia para identificar términos en los documentos. Hacer una lista de todas las palabras irrelevantes que se te ocurran y escribir una función que lee las palabras de los archivos, las guarda y elimina las palabras irrelevantes. Es posible que tengas que agregar más palabras irrelevantes a la lista mientras revisas la lista de términos de una iteración.
- Escribe casos de prueba CPPUnit para probar tu función y un archivo makefile para incorporar todo. para la compilación. Guarda tus archivos en CVS, especialmente si trabajar con socios. Recomendamos que investigues cómo abrir tu instancia CVS a ingenieros remotos.
- Agrega procesamiento para incluir datos de ubicación, es decir, qué archivo y dónde se encuentra un término en el archivo? Es posible que quieras averiguar un cálculo para definir el número de página o de párrafo.
- Escribe casos de prueba CPPUnit para probar esta funcionalidad adicional.
- Crea un índice invertido y almacena los datos de ubicación en el registro de cada término.
- Escribir más casos de prueba
- Diseñar una interfaz que permita que un usuario ingrese una consulta
- Con el algoritmo de búsqueda descrito anteriormente, procesa el índice invertido y mostrar los datos de ubicación al usuario.
- Asegúrate de incluir también casos de prueba para esta parte final.
Como ya lo hicimos en todos los proyectos, use el foro y el chat para encontrar socios. y compartir ideas.
Una función adicional
Un paso de procesamiento común en muchos sistemas IR se denomina lematización. El La idea principal detrás de la derivación es que los usuarios que buscan información sobre la “recuperación” también le interesan los documentos con información que contiene los términos “recuperar”, “recuperar”, “recuperar”, etcétera. Los sistemas pueden generar errores debido a a una lematización deficiente, lo que es un poco complicado. Por ejemplo, un usuario interesado en “recuperación de información” podría obtener un documento titulado “Información sobre Retrievers” debido a la lematización. Un algoritmo útil para la lematización es la Algoritmo de Porter.