C++ ভাষা টিউটোরিয়াল
এই টিউটোরিয়ালের প্রাথমিক বিভাগগুলি ইতিমধ্যে শেষ দুটি মডিউলে উপস্থাপিত মৌলিক উপাদানগুলিকে কভার করে এবং উন্নত ধারণাগুলির উপর আরও তথ্য প্রদান করে। এই মডিউলে আমাদের ফোকাস ডায়নামিক মেমরি, এবং বস্তু এবং ক্লাসের উপর আরো বিস্তারিত। উত্তরাধিকার, পলিমরফিজম, টেমপ্লেট, ব্যতিক্রম এবং নামস্থানের মতো কিছু উন্নত বিষয়ও চালু করা হয়েছে। আমরা এগুলি পরে অ্যাডভান্সড সি++ কোর্সে অধ্যয়ন করব।
অবজেক্ট-ওরিয়েন্টেড ডিজাইন
এটি অবজেক্ট-ওরিয়েন্টেড ডিজাইনের একটি চমৎকার টিউটোরিয়াল । আমরা এই মডিউলের প্রকল্পে এখানে উপস্থাপিত পদ্ধতি প্রয়োগ করব।
উদাহরণ #3 দ্বারা শিখুন
এই মডিউলে আমাদের ফোকাস হল পয়েন্টার, অবজেক্ট-ওরিয়েন্টেড ডিজাইন, মাল্টি-ডাইমেনশনাল অ্যারে এবং ক্লাস/অবজেক্টের সাথে আরও অনুশীলন করা। নিম্নলিখিত উদাহরণগুলির মাধ্যমে কাজ করুন। আমরা যথেষ্ট জোর দিতে পারি না যে একজন ভাল প্রোগ্রামার হওয়ার চাবিকাঠি হল অনুশীলন, অনুশীলন, অনুশীলন!ব্যায়াম # 1: পয়েন্টারগুলির সাথে আরও অনুশীলন করুন
আপনার যদি পয়েন্টারগুলির সাথে অতিরিক্ত অনুশীলনের প্রয়োজন হয় তবে এই সংস্থানটি পড়ুন যা পয়েন্টারগুলির সমস্ত দিক কভার করে এবং অনেকগুলি প্রোগ্রামের উদাহরণ প্রদান করে।
নিম্নলিখিত প্রোগ্রামের আউটপুট কি? অনুগ্রহ করে প্রোগ্রামটি চালাবেন না, তবে আউটপুট নির্ধারণ করতে মেমরি ছবি আঁকুন।
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}একবার আপনি হাতে আউটপুট নির্ধারণ করার পরে, আপনি সঠিক কিনা তা দেখতে প্রোগ্রামটি চালান।
ব্যায়াম #2: ক্লাস এবং অবজেক্টের সাথে আরও অনুশীলন করুন
আপনার যদি ক্লাস এবং অবজেক্টের সাথে অতিরিক্ত অনুশীলনের প্রয়োজন হয় তবে এখানে একটি সংস্থান রয়েছে যা দুটি ছোট ক্লাস বাস্তবায়নের মধ্য দিয়ে যায়। ব্যায়াম করতে কিছু সময় নিন।
ব্যায়াম #3: মাল্টি-ডাইমেনশনাল অ্যারে
নিম্নলিখিত প্রোগ্রাম বিবেচনা করুন:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}এই প্রোগ্রামে একটি লাইন আছে "এই লাইন কিভাবে কাজ করে?" - তুমি কি এটা বের করতে পারো? এখানে আমাদের ব্যাখ্যা.
একটি প্রোগ্রাম লিখুন যা একটি 3-ডিম অ্যারে শুরু করে এবং তিনটি সূচকের যোগফল দিয়ে 3য় মাত্রার মান পূরণ করে। এখানে আমাদের সমাধান.
ব্যায়াম #4: একটি বিস্তৃত OO ডিজাইনের উদাহরণ
এখানে একটি বিশদ অবজেক্ট-ওরিয়েন্টেড ডিজাইনের উদাহরণ রয়েছে, যা শুরু থেকে শেষ পর্যন্ত পুরো প্রক্রিয়ার মধ্য দিয়ে যায়। চূড়ান্ত কোডটি জাভা প্রোগ্রামিং ভাষায় লেখা, তবে আপনি কতদূর এসেছেন তা দিয়ে আপনি এটি পড়তে সক্ষম হবেন।
এই সম্পূর্ণ উদাহরণ মাধ্যমে কাজ করার জন্য সময় নিন. এটি প্রক্রিয়াটির একটি দুর্দান্ত চিত্র এবং এটিকে সমর্থন করে এমন ডিজাইনের সরঞ্জামগুলি।
ইউনিট পরীক্ষা
ভূমিকা
টেস্টিং সফটওয়্যার ইঞ্জিনিয়ারিং প্রক্রিয়ার একটি গুরুত্বপূর্ণ অংশ। একটি ইউনিট পরীক্ষা হল একটি নির্দিষ্ট ধরণের পরীক্ষা, যা সোর্স কোডের একটি একক, ছোট মডিউলের কার্যকারিতা পরীক্ষা করে। ইউনিট টেস্টিং সবসময় ইঞ্জিনিয়ার দ্বারা করা হয়, এবং সাধারণত একই সময়ে তারা মডিউল কোডিং করা হয়. কম্পোজার এবং ডাটাবেস ক্লাস পরীক্ষা করার জন্য আপনি যে টেস্ট ড্রাইভারগুলি ব্যবহার করেছেন তা হল ইউনিট পরীক্ষার উদাহরণ।
ইউনিট টেস্টের নিম্নলিখিত বৈশিষ্ট্য রয়েছে। তারা...
- বিচ্ছিন্নভাবে একটি উপাদান পরীক্ষা করুন
- নির্ধারক
- সাধারণত একটি একক শ্রেণীতে মানচিত্র
- বাহ্যিক সম্পদের উপর নির্ভরতা এড়ান, যেমন ডাটাবেস, ফাইল, নেটওয়ার্ক
- দ্রুত কার্যকর করা
- যেকোনো ক্রমে চালানো যেতে পারে
স্বয়ংক্রিয় কাঠামো এবং পদ্ধতি রয়েছে যা বড় সফ্টওয়্যার ইঞ্জিনিয়ারিং সংস্থাগুলিতে ইউনিট পরীক্ষার জন্য সমর্থন এবং ধারাবাহিকতা প্রদান করে। কিছু অত্যাধুনিক ওপেন সোর্স ইউনিট টেস্টিং ফ্রেমওয়ার্ক রয়েছে, যা আমরা এই পাঠে পরে শিখব।
ইউনিট পরীক্ষার একটি অংশ হিসাবে যে পরীক্ষাগুলি ঘটে তা নীচে চিত্রিত করা হয়েছে।

একটি আদর্শ বিশ্বে, আমরা নিম্নলিখিতগুলির জন্য পরীক্ষা করি:
- তথ্য সঠিকভাবে ভিতরে এবং বাইরে প্রবাহিত হয় তা নিশ্চিত করতে মডিউল ইন্টারফেস পরীক্ষা করা হয়।
- স্থানীয় ডেটা স্ট্রাকচারগুলি সঠিকভাবে ডেটা সংরক্ষণ করে তা নিশ্চিত করার জন্য পরীক্ষা করা হয়।
- মডিউলটি প্রক্রিয়াকরণকে সীমাবদ্ধ বা সীমাবদ্ধ করে এমন সীমানায় সঠিকভাবে কাজ করে তা নিশ্চিত করার জন্য সীমানা শর্তগুলি পরীক্ষা করা হয়।
- আমরা প্রতিটি পাথ নিশ্চিত করতে মডিউলের মাধ্যমে স্বাধীন পাথ পরীক্ষা করি এবং এইভাবে মডিউলের প্রতিটি বিবৃতি অন্তত একবার কার্যকর করা হয়েছে।
- অবশেষে, আমাদের পরীক্ষা করা দরকার যে ত্রুটিগুলি সঠিকভাবে পরিচালনা করা হয়েছে।
কোড কভারেজ
বাস্তবে, আমরা আমাদের পরীক্ষার মাধ্যমে সম্পূর্ণ "কোড কভারেজ" অর্জন করতে পারি না। কোড কভারেজ হল একটি বিশ্লেষণ পদ্ধতি যা নির্ধারণ করে যে একটি সফ্টওয়্যার সিস্টেমের কোন অংশগুলি টেস্ট কেস স্যুট দ্বারা কার্যকর করা হয়েছে (কভার করা হয়েছে) এবং কোন অংশগুলি কার্যকর করা হয়নি৷ যদি আমরা চেষ্টা করি এবং 100% কভারেজ অর্জন করি, আমরা প্রকৃত কোড লেখার চেয়ে ইউনিট পরীক্ষা লিখতে আরও বেশি সময় ব্যয় করব! নিম্নলিখিত সমস্ত স্বাধীন পথের জন্য ইউনিট পরীক্ষা নিয়ে আসার কথা বিবেচনা করুন। এটি দ্রুত একটি সূচকীয় সমস্যা হয়ে উঠতে পারে।
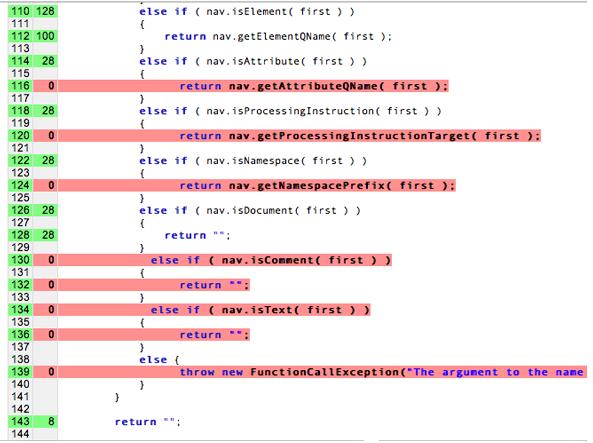
এই চিত্রটিতে, লাল রেখাগুলি পরীক্ষা করা হয় না, যখন রঙহীন রেখাগুলি পরীক্ষা করা হয়।
100% কভারেজের চেষ্টা করার পরিবর্তে, আমরা এমন পরীক্ষাগুলিতে ফোকাস করি যা আমাদের আত্মবিশ্বাস বাড়ায় যে মডিউলটি সঠিকভাবে কাজ করছে। আমরা যেমন জিনিসগুলির জন্য পরীক্ষা করি:
- শূন্য মামলা
- রেঞ্জ পরীক্ষা, যেমন, ইতিবাচক/নেতিবাচক মান পরীক্ষা
- প্রান্ত মামলা
- ব্যর্থতার মামলা
- পাথ পরীক্ষা করা অধিকাংশ সময় কার্যকর করার সম্ভাবনা বেশি
ইউনিট টেস্ট ফ্রেমওয়ার্ক
বেশিরভাগ ইউনিট টেস্ট ফ্রেমওয়ার্ক একটি পাথ কার্যকর করার সময় মান পরীক্ষা করার জন্য দাবী ব্যবহার করে। দাবী হল বিবৃতি যা একটি শর্ত সত্য কিনা তা পরীক্ষা করে। একটি দাবির ফলাফল সাফল্য, অপ্রাণ ব্যর্থতা বা মারাত্মক ব্যর্থতা হতে পারে। একটি দাবী সঞ্চালিত হওয়ার পরে, প্রোগ্রামটি স্বাভাবিকভাবে চলতে থাকে যদি ফলাফল হয় সাফল্য বা অপ্রত্যাশিত ব্যর্থতা হয়। একটি মারাত্মক ব্যর্থতা ঘটলে, বর্তমান ফাংশন বাতিল করা হয়।
পরীক্ষাগুলি এমন কোড নিয়ে গঠিত যা আপনার মডিউলকে স্টেট আপ করে বা ম্যানিপুলেট করে, এবং অনেকগুলি দাবির সাথে মিলিত হয় যা প্রত্যাশিত ফলাফল যাচাই করে। যদি একটি পরীক্ষায় সমস্ত দাবী সফল হয়, অর্থাৎ, সত্যে ফিরে আসে, তাহলে পরীক্ষা সফল হয়; অন্যথায় এটি ব্যর্থ হয়।
একটি পরীক্ষার ক্ষেত্রে এক বা একাধিক পরীক্ষা থাকে। আমরা পরীক্ষাগুলিকে পরীক্ষার ক্ষেত্রে গোষ্ঠীবদ্ধ করি যা পরীক্ষিত কোডের গঠন প্রতিফলিত করে। এই কোর্সে, আমরা আমাদের ইউনিট টেস্ট ফ্রেমওয়ার্ক হিসাবে CPPUnit ব্যবহার করতে যাচ্ছি। এই কাঠামোর সাহায্যে, আমরা C++ এ ইউনিট পরীক্ষা লিখতে পারি এবং পরীক্ষার সাফল্য বা ব্যর্থতা সম্পর্কে একটি প্রতিবেদন দিয়ে স্বয়ংক্রিয়ভাবে সেগুলি চালাতে পারি।
CPPUnit ইনস্টলেশন
SourceForge থেকে CPPUnit কোড ডাউনলোড করুন। একটি উপযুক্ত ডিরেক্টরি খুঁজুন এবং সেখানে tar.gz ফাইলটি রাখুন। তারপরে, উপযুক্ত cppunit ফাইলের নাম প্রতিস্থাপন করে নিম্নলিখিত কমান্ডগুলি (লিনাক্স, ইউনিক্সে) লিখুন:
gunzip filename.tar.gz tar -xvf filename.tar
আপনি যদি উইন্ডোজে কাজ করেন তবে আপনাকে tar.gz ফাইলগুলি বের করার জন্য একটি ইউটিলিটি খুঁজতে হতে পারে। পরবর্তী ধাপ হল লাইব্রেরি কম্পাইল করা। cppunit ডিরেক্টরিতে পরিবর্তন করুন। সেখানে একটি ইন্সটল ফাইল আছে যা নির্দিষ্ট নির্দেশনা প্রদান করে। সাধারণত, আপনাকে চালাতে হবে:
./configure make install
আপনি যদি সমস্যার সম্মুখীন হন, তাহলে ইন্সটল ফাইলটি পড়ুন। লাইব্রেরিগুলো সাধারণত cppunit/src/cppunit ডিরেক্টরিতে পাওয়া যায়। কম্পাইল কাজ করেছে কিনা তা পরীক্ষা করতে, cppunit/examples/simple ডিরেক্টরিতে যান এবং "make" টাইপ করুন। সবকিছু ঠিকঠাক কম্পাইল হলে, তারপর আপনি সব প্রস্তুত.
এখানে একটি চমৎকার টিউটোরিয়াল উপলব্ধ আছে। অনুগ্রহ করে এই টিউটোরিয়ালের মধ্য দিয়ে যান এবং জটিল সংখ্যার শ্রেণী এবং এর সংশ্লিষ্ট ইউনিট পরীক্ষা তৈরি করুন। cppunit/examples ডিরেক্টরিতে বেশ কিছু অতিরিক্ত উদাহরণ রয়েছে।
কেন আমি এটা করতে হবে???
ইউনিট পরীক্ষা বিভিন্ন কারণে শিল্পে সমালোচনামূলকভাবে গুরুত্বপূর্ণ। আপনি ইতিমধ্যে একটি কারণের সাথে পরিচিত: কোড তৈরি করার সময় আমাদের কাজ পরীক্ষা করার কিছু উপায় প্রয়োজন। এমনকি যখন আমরা একটি খুব ছোট প্রোগ্রাম তৈরি করছি, তখন আমরা স্বভাবতই কিছু ধরণের চেকার বা ড্রাইভার লিখি তা নিশ্চিত করার জন্য যে আমাদের প্রোগ্রামটি প্রত্যাশিতভাবে কাজ করে।
দীর্ঘ অভিজ্ঞতা থেকে, প্রকৌশলীরা জানেন যে একটি প্রোগ্রাম প্রথম চেষ্টায় কাজ করার সম্ভাবনা খুব কম। ইউনিট পরীক্ষাগুলি পরীক্ষামূলক প্রোগ্রামগুলিকে স্ব-পরীক্ষা এবং পুনরাবৃত্তিযোগ্য করে এই ধারণাটি তৈরি করে। দাবীগুলি ম্যানুয়ালি আউটপুট পরিদর্শনের স্থান নেয়। এবং, যেহেতু ফলাফলগুলি ব্যাখ্যা করা সহজ (পরীক্ষাটি হয় পাস হয় বা ব্যর্থ হয়), পরীক্ষাগুলি বারবার চালানো যেতে পারে, একটি সুরক্ষা জাল প্রদান করে যা আপনার কোডকে পরিবর্তনের জন্য আরও স্থিতিস্থাপক করে তোলে৷
আসুন এটিকে সুনির্দিষ্ট ভাষায় রাখি: আপনি যখন প্রথমে আপনার সমাপ্ত কোড CVS-এ জমা দেন, তখন এটি পুরোপুরি কাজ করে। এবং এটি কিছু সময়ের জন্য নিখুঁতভাবে কাজ করতে থাকে। তারপর একদিন, অন্য কেউ আপনার কোড পরিবর্তন করে। শীঘ্রই বা পরে যে কেউ আপনার কোড ভাঙবে। আপনি কি মনে করেন তারা নিজেরাই লক্ষ্য করবেন? সম্ভাবনা নেই। কিন্তু আপনি যখন ইউনিট পরীক্ষা লেখেন, তখন এমন সিস্টেম রয়েছে যা প্রতিদিন স্বয়ংক্রিয়ভাবে সেগুলি চালাতে পারে। এগুলোকে একটানা ইন্টিগ্রেশন সিস্টেম বলা হয়। সুতরাং যখন সেই প্রকৌশলী X আপনার কোডটি ভাঙবে, তখন সিস্টেমটি তাদের কাছে খারাপ ইমেল পাঠাবে যতক্ষণ না তারা এটি ঠিক করে। আপনি এক্স ইঞ্জিনিয়ার হলেও!
আপনাকে সফ্টওয়্যার বিকাশে সহায়তা করার পাশাপাশি, এবং তারপরে পরিবর্তনের মুখে সেই সফ্টওয়্যারটিকে সুরক্ষিত রাখতে, ইউনিট টেস্টিং:
- একটি এক্সিকিউটেবল স্পেসিফিকেশন এবং ডকুমেন্টেশন তৈরি করে যা কোডের সাথে সিঙ্কে থাকে। অন্য কথায়, মডিউলটি কোন আচরণ সমর্থন করে সে সম্পর্কে জানতে আপনি একটি ইউনিট পরীক্ষা পড়তে পারেন।
- আপনাকে বাস্তবায়ন থেকে আলাদা প্রয়োজনীয়তা সাহায্য করে। যেহেতু আপনি বাহ্যিকভাবে দৃশ্যমান আচরণের দাবি করছেন, আপনি কীভাবে আচরণটি বাস্তবায়ন করবেন সে সম্পর্কে ধারণাগুলি মিশ্রিত করার পরিবর্তে এটি সম্পর্কে স্পষ্টভাবে চিন্তা করার সুযোগ পান।
- পরীক্ষা সমর্থন করে। আপনি যখন কোনও মডিউলের আচরণ ভেঙেছেন তখন আপনাকে সতর্ক করার জন্য যদি আপনার কাছে একটি সুরক্ষা জাল থাকে, তবে আপনি জিনিসগুলি চেষ্টা করে দেখতে এবং আপনার ডিজাইনগুলি পুনরায় কনফিগার করার সম্ভাবনা বেশি।
- আপনার ডিজাইন উন্নত করে। পুঙ্খানুপুঙ্খ ইউনিট পরীক্ষা লেখার জন্য প্রায়ই আপনার কোডকে আরও পরীক্ষাযোগ্য করে তুলতে হয়। পরীক্ষাযোগ্য কোড প্রায়ই আন-টেস্টেবল কোডের চেয়ে বেশি মডুলার হয়।
- মান উচ্চ রাখে। একটি সমালোচনামূলক সিস্টেমে একটি ছোট বাগ একটি কোম্পানিকে লক্ষ লক্ষ ডলার বা তার চেয়েও খারাপ, ব্যবহারকারীর সুখ বা বিশ্বাস হারাতে পারে৷ ইউনিট পরীক্ষা যে নিরাপত্তা জাল প্রদান করে তা এই সম্ভাবনাকে কমিয়ে দেয়। বাগগুলিকে তাড়াতাড়ি ধরার মাধ্যমে, তারা QA দলগুলিকে সুস্পষ্ট ব্যর্থতার রিপোর্ট করার পরিবর্তে আরও পরিশীলিত এবং কঠিন ব্যর্থতার পরিস্থিতিতে সময় ব্যয় করতে সক্ষম করে।
কম্পোজার ডাটাবেস অ্যাপ্লিকেশনের জন্য CPPUnit ব্যবহার করে ইউনিট পরীক্ষা লিখতে কিছু সময় নিন। সাহায্যের জন্য cppunit/examples/ ডিরেক্টরি পড়ুন।
কিভাবে Google কাজ করে
ভূমিকাকল্পনা করুন মধ্যযুগের একজন সন্ন্যাসী তার মঠের আর্কাইভে হাজার হাজার পাণ্ডুলিপি দেখছেন। "কোথায় এরিস্টটলের লেখা..."

সৌভাগ্যবশত তার জন্য, পান্ডুলিপিগুলি বিষয়বস্তু অনুসারে সংগঠিত এবং প্রতিটিতে থাকা তথ্য পুনরুদ্ধারের সুবিধার্থে বিশেষ চিহ্ন দিয়ে খোদাই করা হয়েছে। এই ধরনের সংস্থা ছাড়া, প্রাসঙ্গিক পাণ্ডুলিপি খুঁজে পাওয়া খুব কঠিন হবে।
বৃহৎ সংগ্রহ থেকে লিখিত তথ্য সংরক্ষণ ও পুনরুদ্ধারের কার্যকলাপকে বলা হয় তথ্য পুনরুদ্ধার (IR) । এই কার্যকলাপটি কয়েক শতাব্দী ধরে ক্রমবর্ধমান গুরুত্বপূর্ণ হয়ে উঠেছে, বিশেষ করে কাগজ এবং ছাপাখানার মত উদ্ভাবনের সাথে। এটি এমন কিছু ছিল যেখানে শুধুমাত্র কিছু লোকের দখল ছিল। এখন, যাইহোক, যখন তারা একটি সার্চ ইঞ্জিন ব্যবহার করে বা তাদের ডেস্কটপে অনুসন্ধান করে তখন কয়েক মিলিয়ন মানুষ প্রতিদিন তথ্য পুনরুদ্ধারে নিযুক্ত হন।
তথ্য পুনরুদ্ধার সঙ্গে শুরু করা

ডঃ সিউস 30 বছর ধরে 46 টি শিশুতোষ বই লিখেছেন। তার বইগুলি বিড়াল, গরু এবং হাতি, হু, গ্রিনচেস এবং লরাক্স সম্পর্কে বলা হয়েছিল। কোন গল্পে কোন প্রাণী ছিল মনে আছে? আপনি একজন অভিভাবক না হলে, শুধুমাত্র শিশুরাই আপনাকে বলতে পারবে ড. সিউসের গল্পের কোন সেটে প্রাণী আছে:
(কাউ এবং বিইই) বা কাক
এই সমস্যা সমাধানে সাহায্য করার জন্য আমরা কিছু ক্লাসিক তথ্য পুনরুদ্ধার মডেল প্রয়োগ করব।
একটি সুস্পষ্ট পদ্ধতি হ'ল পাশবিক শক্তি: সমস্ত 46টি ডাঃ সিউসের গল্পগুলি পান এবং পড়া শুরু করুন। প্রতিটি বইয়ের জন্য, নোট করুন যে কোনটিতে COW এবং BEE শব্দ রয়েছে এবং একই সময়ে, CROWS শব্দ রয়েছে এমন বইগুলি সন্ধান করুন। কম্পিউটার আমাদের তুলনায় অনেক দ্রুত। যদি আমাদের কাছে ডিজিটাল আকারে ডাঃ সিউস বইয়ের সমস্ত পাঠ্য থাকে, পাঠ্য ফাইল হিসাবে বলুন, আমরা কেবল ফাইলগুলির মাধ্যমে গ্রেপ করতে পারি। ডাঃ সিউসের বইয়ের মতো একটি ছোট সংগ্রহের জন্য, এই কৌশলটি ভাল কাজ করে।
তবে এমন অনেক পরিস্থিতি রয়েছে যেখানে আমাদের আরও প্রয়োজন। উদাহরণস্বরূপ, বর্তমানে অনলাইনে সমস্ত ডেটা সংগ্রহ করা গ্রেপের পক্ষে পরিচালনা করা খুব বড়। আমরা শুধু আমাদের অবস্থার সাথে মেলে এমন নথি চাই না, আমরা তাদের প্রাসঙ্গিকতা অনুযায়ী র্যাঙ্ক করতে অভ্যস্ত হয়ে গেছি।
গ্রেপ ছাড়াও আরেকটি পদ্ধতি হল অনুসন্ধান করার আগে একটি সংগ্রহে নথিগুলির একটি সূচক তৈরি করা। IR-এ একটি সূচক একটি পাঠ্যপুস্তকের পিছনে একটি সূচকের অনুরূপ। আমরা প্রতিটি ডক্টর সিউসের গল্পে সমস্ত শব্দের (বা পদ ) একটি তালিকা তৈরি করি, “the”, “and”, এবং অন্যান্য সংযোজক, অব্যয়, ইত্যাদি শব্দগুলি বাদ দিয়ে (এগুলিকে বলা হয় স্টপ-ওয়ার্ড )। তারপরে আমরা এই তথ্যগুলিকে এমনভাবে উপস্থাপন করি যা শর্তগুলি খুঁজে পেতে এবং তারা যে গল্পগুলিতে রয়েছে তা সনাক্ত করতে সহায়তা করে৷
একটি সম্ভাব্য উপস্থাপনা হল একটি ম্যাট্রিক্স যেখানে শীর্ষ জুড়ে গল্পগুলি এবং প্রতিটি সারিতে তালিকাভুক্ত পদগুলি রয়েছে৷ একটি কলামে একটি "1" নির্দেশ করে যে শব্দটি সেই কলামের গল্পে উপস্থিত হয়৷
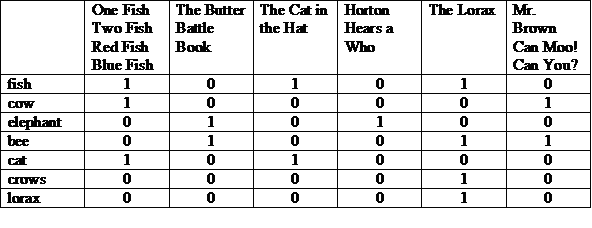
আমরা প্রতিটি সারি বা কলামকে বিট ভেক্টর হিসাবে দেখতে পারি। একটি সারির বিট ভেক্টর নির্দেশ করে কোন গল্পে শব্দটি উপস্থিত হয়। একটি কলামের বিট ভেক্টর নির্দেশ করে যে গল্পে কোন পদগুলি উপস্থিত হবে।
আমাদের মূল সমস্যায় ফিরে যাচ্ছি:
(কাউ এবং বিইই) বা কাক
আমরা এই পদগুলির জন্য বিট ভেক্টর নিই এবং প্রথমে একটি বিট-ওয়াইজ AND করি, তারপর ফলাফলের উপর OR-বিট-ওয়াইজ করি।
(100001 এবং 010011) বা 000010 = 000011
উত্তর: "মি. ব্রাউন ক্যান মু! পারবে?" এবং "দ্য লরাক্স"। এটি বুলিয়ান রিট্রিভাল মডেলের একটি চিত্র, যা একটি "সঠিক মিল" মডেল।
ধরুন আমরা ডাঃ সিউসের সমস্ত গল্প এবং গল্পের সমস্ত প্রাসঙ্গিক পদ অন্তর্ভুক্ত করার জন্য ম্যাট্রিক্সকে প্রসারিত করতে চাই। ম্যাট্রিক্স যথেষ্ট বৃদ্ধি পাবে, এবং একটি গুরুত্বপূর্ণ পর্যবেক্ষণ হল বেশিরভাগ এন্ট্রি 0 হবে। একটি ম্যাট্রিক্স সম্ভবত সূচকের জন্য সেরা উপস্থাপনা নয়। আমরা শুধু 1 এর সংরক্ষণ করার একটি উপায় খুঁজে বের করতে হবে.
কিছু উন্নতি
এই সমস্যা সমাধানের জন্য IR-এ যে কাঠামো ব্যবহার করা হয় তাকে বলা হয় ইনভার্টেড ইনডেক্স । আমরা পদগুলির একটি অভিধান রাখি, এবং তারপরে প্রতিটি পদের জন্য, আমাদের কাছে একটি তালিকা রয়েছে যা নথিগুলি রেকর্ড করে যেখানে শব্দটি ঘটে। এই তালিকাটিকে পোস্টিং তালিকা বলা হয়। একটি এককভাবে লিঙ্কযুক্ত তালিকা নীচে দেখানো হিসাবে এই কাঠামোর প্রতিনিধিত্ব করতে ভাল কাজ করে।
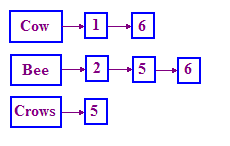
আপনি যদি লিঙ্ক করা তালিকার সাথে পরিচিত না হন তবে শুধুমাত্র "C++ এ লিঙ্ক করা তালিকা"-এ একটি Google অনুসন্ধান করুন এবং আপনি কীভাবে একটি তৈরি করবেন এবং কীভাবে এটি ব্যবহার করা হয় তা বর্ণনা করে অনেক সংস্থান পাবেন। আমরা পরবর্তী মডিউলে এটি আরও বিশদে কভার করব।
লক্ষ্য করুন যে আমরা গল্পের নামের পরিবর্তে ডকুমেন্ট আইডি ( DocIDs ) ব্যবহার করি। আমরা এই ডকআইডিগুলিকেও বাছাই করি কারণ এটি প্রশ্নগুলি প্রক্রিয়াকরণের সুবিধা দেয়৷
কিভাবে আমরা একটি প্রশ্ন প্রক্রিয়া? আসল সমস্যার জন্য, আমরা প্রথমে COW পোস্টিং তালিকা খুঁজে পাই, তারপর BEE পোস্টিং তালিকা। আমরা তারপরে তাদের একসাথে "একত্রীকরণ" করি:
- উভয় তালিকায় মার্কার বজায় রাখুন এবং একই সাথে দুটি পোস্টিং তালিকার মধ্য দিয়ে যান।
- প্রতিটি ধাপে, উভয় পয়েন্টার দ্বারা নির্দেশিত DocID তুলনা করুন।
- যদি সেগুলি একই হয়, তাহলে সেই DocIDটিকে ফলাফলের তালিকায় রাখুন, অন্যথায় ছোট docID-এর দিকে নির্দেশক পয়েন্টারটিকে অগ্রসর করুন৷
এখানে আমরা কিভাবে একটি উল্টানো সূচক তৈরি করতে পারি:
- আগ্রহের প্রতিটি নথিতে একটি DocID বরাদ্দ করুন।
- প্রতিটি নথির জন্য, এর প্রাসঙ্গিক শর্তাবলী চিহ্নিত করুন (টোকেনাইজ)।
- প্রতিটি পদের জন্য, শব্দটি, যেখানে এটি পাওয়া যায় সেই DocID এবং সেই নথিতে একটি ফ্রিকোয়েন্সি সহ একটি রেকর্ড তৈরি করুন। নোট করুন যে একটি নির্দিষ্ট শব্দের একাধিক রেকর্ড হতে পারে যদি এটি একাধিক নথিতে প্রদর্শিত হয়।
- মেয়াদ অনুসারে রেকর্ডগুলি সাজান।
- একটি শব্দের জন্য একক রেকর্ড প্রক্রিয়াকরণ করে অভিধান এবং পোস্টিং তালিকা তৈরি করুন এবং একাধিক নথিতে প্রদর্শিত পদগুলির জন্য একাধিক রেকর্ড একত্রিত করুন৷ DocID-এর একটি লিঙ্ক করা তালিকা তৈরি করুন (বাছাই ক্রমে)। প্রতিটি শব্দের একটি ফ্রিকোয়েন্সি রয়েছে যা একটি মেয়াদের জন্য সমস্ত রেকর্ড জুড়ে ফ্রিকোয়েন্সির সমষ্টি।
প্রকল্প
বেশ কিছু লম্বা প্লেইনটেক্সট ডকুমেন্ট খুঁজুন যার সাথে আপনি পরীক্ষা করতে পারেন। প্রকল্পটি উপরে বর্ণিত অ্যালগরিদমগুলি ব্যবহার করে নথিগুলি থেকে একটি উল্টানো সূচক তৈরি করা। আপনাকে প্রশ্নগুলির ইনপুটের জন্য একটি ইন্টারফেস এবং সেগুলি প্রক্রিয়া করার জন্য একটি ইঞ্জিন তৈরি করতে হবে। আপনি ফোরামে একটি প্রকল্প অংশীদার খুঁজে পেতে পারেন.
এই প্রকল্পটি সম্পূর্ণ করার জন্য এখানে একটি সম্ভাব্য প্রক্রিয়া রয়েছে:
- নথিতে শর্তাদি সনাক্ত করার জন্য একটি কৌশল নির্ধারণ করা প্রথম জিনিস। আপনি যে সমস্ত স্টপ-শব্দের কথা ভাবতে পারেন তার একটি তালিকা তৈরি করুন এবং একটি ফাংশন লিখুন যা ফাইলের শব্দগুলি পড়ে, পদগুলি সংরক্ষণ করে এবং স্টপ-শব্দগুলিকে সরিয়ে দেয়। আপনি একটি পুনরাবৃত্তি থেকে পদের তালিকা পর্যালোচনা করার সাথে সাথে আপনার তালিকায় আরও স্টপ-শব্দ যোগ করতে হতে পারে।
- আপনার ফাংশন পরীক্ষা করার জন্য CPPUnit টেস্ট কেস এবং আপনার বিল্ডের জন্য সবকিছু একত্রিত করার জন্য একটি মেকফাইল লিখুন। CVS-এ আপনার ফাইলগুলি পরীক্ষা করুন, বিশেষ করে যদি আপনি অংশীদারদের সাথে কাজ করেন। আপনি রিমোট ইঞ্জিনিয়ারদের কাছে কীভাবে আপনার সিভিএস উদাহরণ খুলবেন তা গবেষণা করতে চাইতে পারেন।
- অবস্থান তথ্য অন্তর্ভুক্ত করার জন্য প্রক্রিয়াকরণ যোগ করুন, অর্থাৎ, কোন ফাইল এবং কোথায় ফাইলে একটি শব্দ অবস্থিত? আপনি পৃষ্ঠা নম্বর বা অনুচ্ছেদ নম্বর সংজ্ঞায়িত করার জন্য একটি গণনা বের করতে চাইতে পারেন।
- এই অতিরিক্ত কার্যকারিতা পরীক্ষা করতে CPPUnit পরীক্ষার ক্ষেত্রে লিখুন।
- একটি উল্টানো সূচক তৈরি করুন এবং প্রতিটি পদের রেকর্ডে অবস্থানের ডেটা সংরক্ষণ করুন।
- আরও পরীক্ষার ক্ষেত্রে লিখুন।
- একটি ইন্টারফেস ডিজাইন করুন যাতে একজন ব্যবহারকারী একটি প্রশ্নে প্রবেশ করতে পারে।
- উপরে বর্ণিত অনুসন্ধান অ্যালগরিদম ব্যবহার করে, উল্টানো সূচকটি প্রক্রিয়া করুন এবং ব্যবহারকারীর কাছে অবস্থানের ডেটা ফেরত দিন।
- এই চূড়ান্ত অংশের জন্য পরীক্ষার ক্ষেত্রেও অন্তর্ভুক্ত করতে ভুলবেন না।
আমরা যেমন সমস্ত প্রকল্পে করেছি, ফোরাম ব্যবহার করুন এবং প্রকল্প অংশীদারদের খুঁজে পেতে এবং ধারনা শেয়ার করতে চ্যাট করুন৷
একটি অতিরিক্ত বৈশিষ্ট্য
অনেক IR সিস্টেমে একটি সাধারণ প্রক্রিয়াকরণ ধাপকে স্টেমিং বলা হয়। স্টেমিংয়ের পিছনে মূল ধারণাটি হল যে ব্যবহারকারীরা "পুনরুদ্ধার" সম্পর্কিত তথ্য অনুসন্ধান করে এমন নথিতেও আগ্রহী হবেন যেখানে "পুনরুদ্ধার করা", "পুনরুদ্ধার করা", "পুনরুদ্ধার করা" ইত্যাদি তথ্য রয়েছে। দুর্বল স্টেমিংয়ের কারণে সিস্টেমগুলি ত্রুটির জন্য সংবেদনশীল হতে পারে, তাই এটি একটু কঠিন। উদাহরণস্বরূপ, "তথ্য পুনরুদ্ধার" এ আগ্রহী একজন ব্যবহারকারী স্টেমিংয়ের কারণে "গোল্ডেন রিট্রিভার্সের তথ্য" শিরোনামের একটি নথি পেতে পারেন। স্টেমিংয়ের জন্য একটি দরকারী অ্যালগরিদম হল পোর্টার অ্যালগরিদম ।