
There are several ML example applications available that you can try out with the Coralboard. All of this code is available from the Synaptics Coralboard repository here.
Voice actions
Use natural language to invoke commands on real-world physical systems.
A Gemma LLM model runs fully on-device, mapping the intent from human language input and converting it to APIs that control LEDs and a buzzer on the Synaptics Coralboard. For example, "change the color to color", "make it blink n times", "beep n times". Achieved through a hybrid, multimodal architecture integrating MoonshineAI's Speech-to-Text model running on the Torq-Coral NPU, and Google FunctionGemma 270M running on the dual-core Arm CPU. The Gemma model can be fine-tuned to a specific vocabulary.
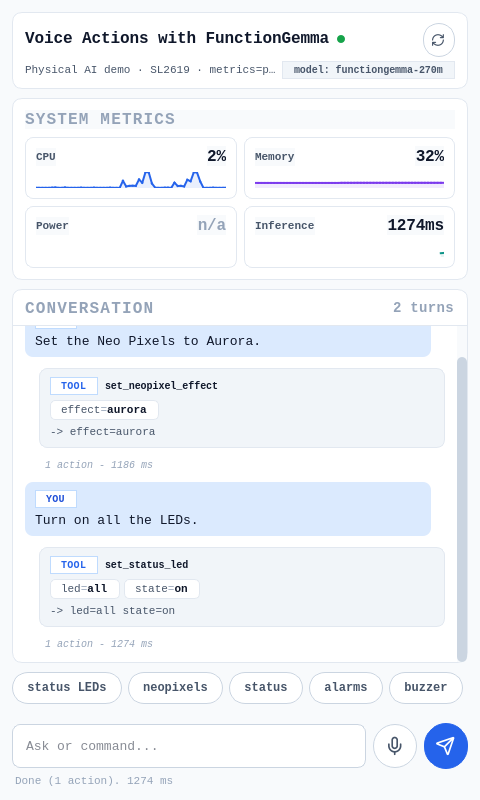
See the Readme for more details.
Language translation
Use on-device translation to translate spoken sentences between languages.
A speech-to-text transformer captures the spoken words, encoding them into tokens that are passed into Gemma LLM for translation. This demo supports translation from English to multiple languages, including Spanish and French. Additional languages can be supported with fine tuning.
This application is achieved through a hybrid, multimodal architecture integrating MoonshineAI's speech-to-text model and Google's Gemma3-270M for translation, both running on the Torq-Coral NPU.
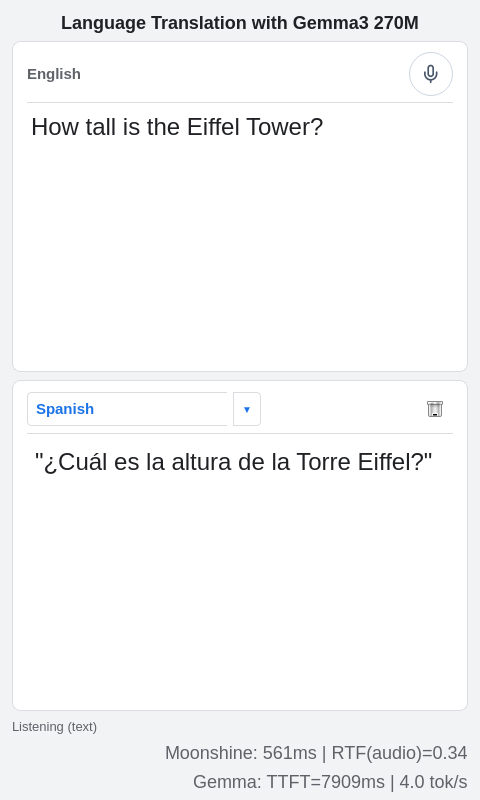
See the Readme for more details.
Image recognition
A single CNN that detects, recognizes, and tracks objects in images.
Use a Yolov8 object detection model running on the NPU that can detect, recognize, or track objects in the image frame. This demo is trained on the Coco Common Objects dataset, and can be retrained on other datasets for specific use cases, for example pose detection. A pose detection demo is also available.
See the Readme for more details.
Scene transcription
Combines a Vision Transformer (ViT) and small LLM to describe the contents of an image using natural language.
Use a SigLip2 VisionTransformer running on the NPU to generate image tokens. These tokens are fed into a quantized version of Gemma3-270M running on the NPU which uses natural language to transcribe the image details.
See the Readme for more details.
Generative audio, aka "Jellectronica"
Combines an image recognition CNN and audio generation RNN for a mixed modality pipeline that creates music.
Use a Yolo v8 object detection model running on the NPU that tracks live-streamed or recorded jellyfish movements. These positional coordinates feed into a MelodyRNN running on the CPU to create live music. A lightweight version of the Google I/O 2026 preshow experience Jellectronica, running completely on-device. Swap the video stream with your own and experiment with generative concepts.
See the Readme for more technical details.
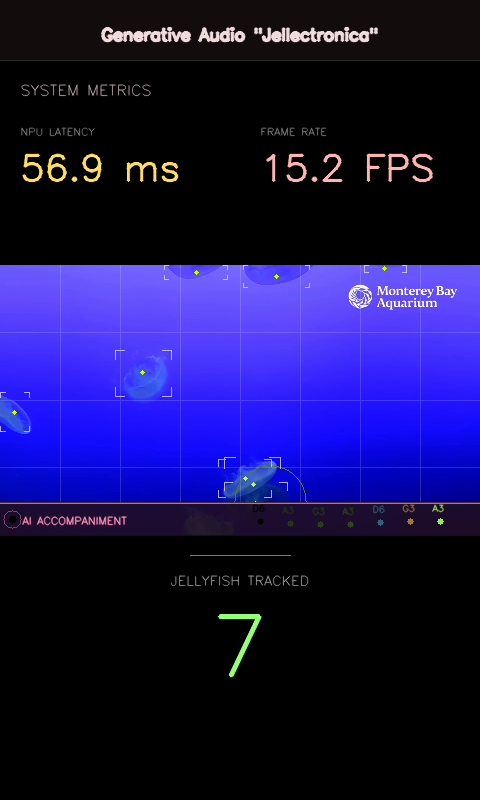
Jellectronica at Google I/O 2026
This Jellectronica demo is being featured at the developers' conference in May of 2026, using a live webcam feed of jellyfish from the nearby Monterey Bay Aquarium. This stunning video serves as the real-time data source for a novel demonstration of several new Google AI technologies.
The creative intent behind this project is to demonstrate that AI, particularly in music, can enable new forms of creativity rather than replacing human effort. It also demonstrates the potential of hyper-efficient edge compute to enable powerful AI experiences. The Jellectronica application creates a "human-jellyfish AI collaboration" to achieve something not previously possible.
How it works
Jellectronica transforms the motion of the jellyfish into an evolving symphony by combining real-time edge processing with cutting-edge generative AI models:
- Real-time object detection: The system processes a 720p live video feed from the aquarium using Python and a custom-trained YOLOv8 (You Only Look Once) object detection model. This tracks the swimming jellyfish in real-time at 20 frames-per-second.
- High-fidelity audio with Lyria 3: The positional data gathered from the jellyfish is used to generate MIDI, which triggers music made with Google’s Lyria 3 model. Created by Google DeepMind, Lyria 3 is Google's most advanced AI music generation model, allowing users to build high-fidelity music tracks directly from simple text descriptions or images.
- Edge ML acceleration: To process this feed efficiently, the ML model code runs on the Coral NPU accelerator. This accelerator is part of the Synaptics Astra™ SL2619 SoC, housed on a Coralboard development platform.
Motion to music
How do swimming jellyfish conduct a live soundtrack?
The Coral NPU processor ingests the live video feed and converts the motion of jellyfish into a stream of positional data. This positional data is output as raw numbers to higher-level machines where the numbers are converted to MIDI musical data. The system uses pre-generated digital musical stems created by Lyria. Stems are individual, grouped audio tracks (such as drums, vocals, or bass) exported from a mixed song to allow for independent remixing and manipulation.
The positional and interaction data of the jellyfish are used to trigger and select these stems, controlling factors such as the intensity and type of instrumentation. Because the jellyfish dictate these factors, every moment of the Jellectronica experience is uniquely orchestrated by nature in real-time.
And more ...
Look for more good stuff in the Synaptics Developer Zone.