
1. Прежде чем начать
TensorFlow — это многоцелевая среда машинного обучения. Его можно использовать для обучения огромных моделей в кластерах в облаке или локального запуска моделей во встроенной системе, такой как ваш телефон.
Эта лаборатория кода использует TensorFlow Lite для запуска модели классификации звука на устройстве Android.
Что вы узнаете
- Как найти предварительно обученную модель машинного обучения, готовую к использованию.
- Как выполнить классификацию аудио для аудио, записанного в реальном времени.
- Как использовать библиотеку поддержки TensorFlow Lite для предварительной обработки входных данных модели и постобработки выходных данных модели.
- Как использовать библиотеку аудиозадач для выполнения всей работы, связанной со звуком.
Что вы будете строить
Простое приложение для распознавания звука, которое запускает модель распознавания звука TensorFlow Lite для идентификации звука с микрофона в режиме реального времени.
Что вам понадобится
- Последняя версия Android Studio (v4.1.2+)
- Физическое устройство Android с версией Android на API 23 (Android 6.0)
- Пример кода
- Базовые знания Android-разработки на Kotlin
2. Получите пример кода
Скачать код
Щелкните следующую ссылку, чтобы загрузить весь код для этой лаборатории кода:
Распакуйте загруженный zip-файл. Это распакует корневую папку ( odml-pathways ) со всеми необходимыми ресурсами. Для этой лаборатории кода вам понадобятся только исходники в audio_classification/codelab1/android .
Примечание. При желании вы можете клонировать репозиторий:
git clone https://github.com/googlecodelabs/odml-pathways.git
Подкаталог android в репозитории audio_classification/codelab1/android содержит два каталога:
 starter — начальный код, на основе которого вы строите эту лабораторию кода.
starter — начальный код, на основе которого вы строите эту лабораторию кода. - final — Завершенный код для готового примера приложения.
Импортировать стартовое приложение
Начнем с импорта начального приложения в Android Studio.
- Откройте Android Studio и выберите «Импорт проекта» (Gradle, Eclipse ADT и т. д.).
- Откройте начальную папку (
audio_classification/codelab1/android/starterstarterиз исходного кода, который вы скачали ранее.

Чтобы убедиться, что все зависимости доступны для вашего приложения, вы должны синхронизировать свой проект с файлами gradle после завершения процесса импорта.
- Выберите «Синхронизировать проект с файлами Gradle» (
 ) на панели инструментов Android Studio.
) на панели инструментов Android Studio.
Запустите стартовое приложение
Теперь, когда вы импортировали проект в Android Studio, вы готовы запустить приложение в первый раз.
Подключите Android-устройство через USB к компьютеру и нажмите «Выполнить» (  ) на панели инструментов Android Studio.
) на панели инструментов Android Studio.
3. Найдите предварительно обученную модель
Чтобы выполнить классификацию аудио, вам понадобится модель. Начните с предварительно обученной модели, чтобы вам не пришлось обучать ее самостоятельно.
Чтобы найти предварительно обученные модели, вы будете использовать TensorFlow Hub ( www.tfhub.dev ).
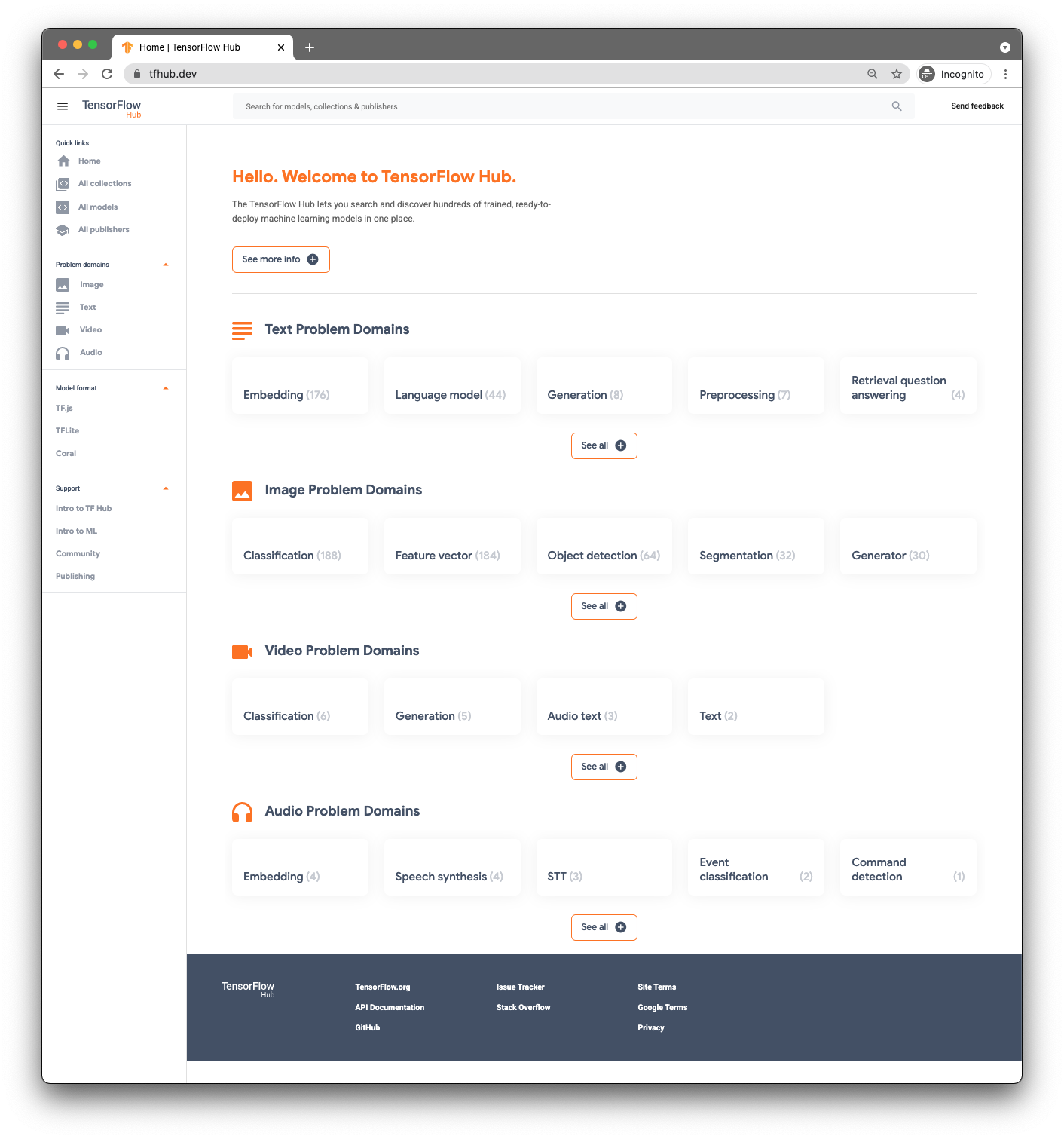
Модели классифицируются по доменам. Тот, который вам сейчас нужен, взят из Audio Problem Domains .
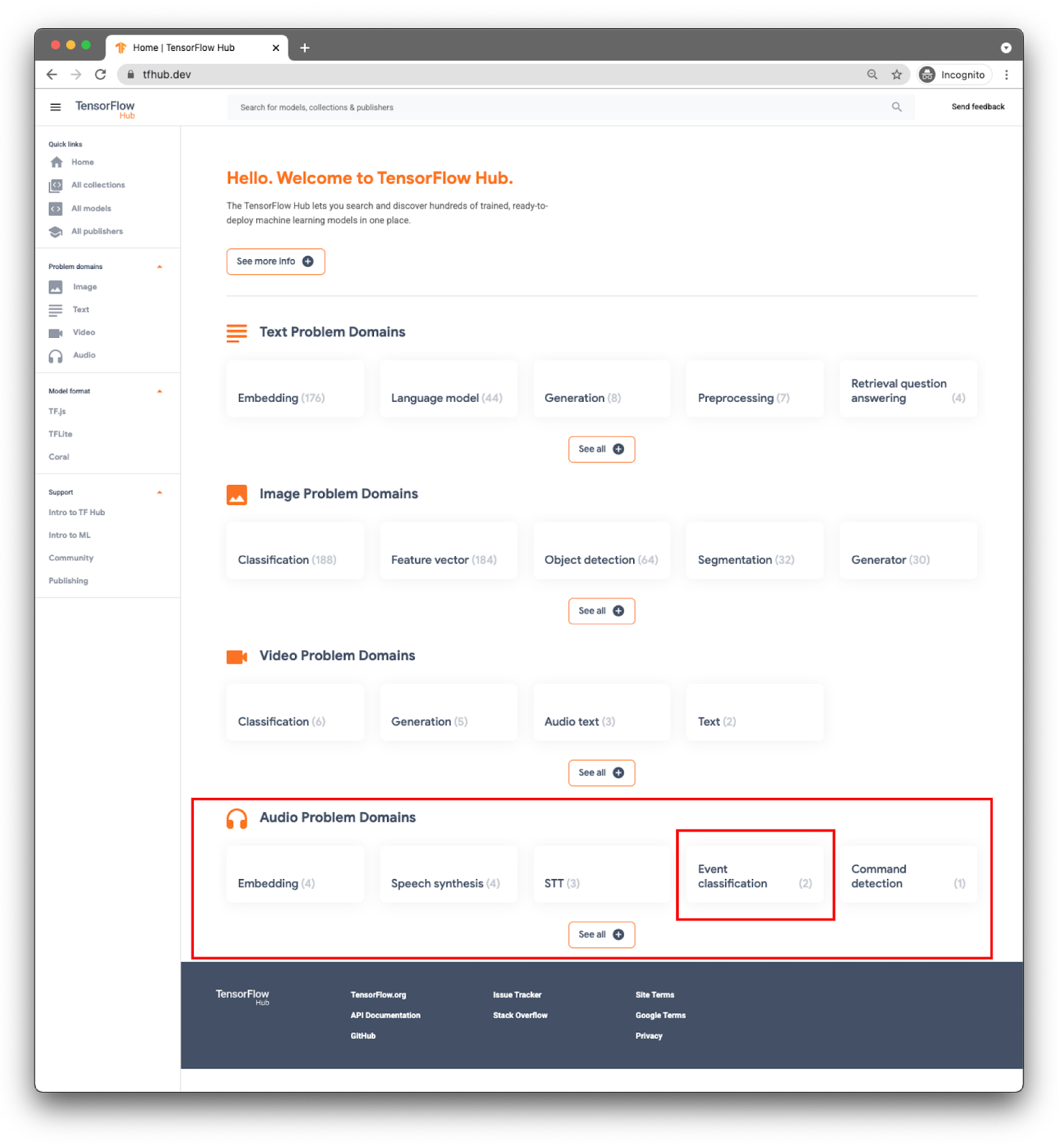
Для вашего приложения вы будете выполнять классификацию событий с помощью модели YAMNet .
YAMNet — это классификатор аудиособытий, который принимает форму аудиосигнала в качестве входных данных и делает независимые прогнозы для каждого из 521 аудиособытия.
Модель yamnet/classification уже преобразована в TensorFlow Lite и имеет определенные метаданные , которые позволяют библиотеке задач TFLite для аудио упростить использование модели на мобильных устройствах.
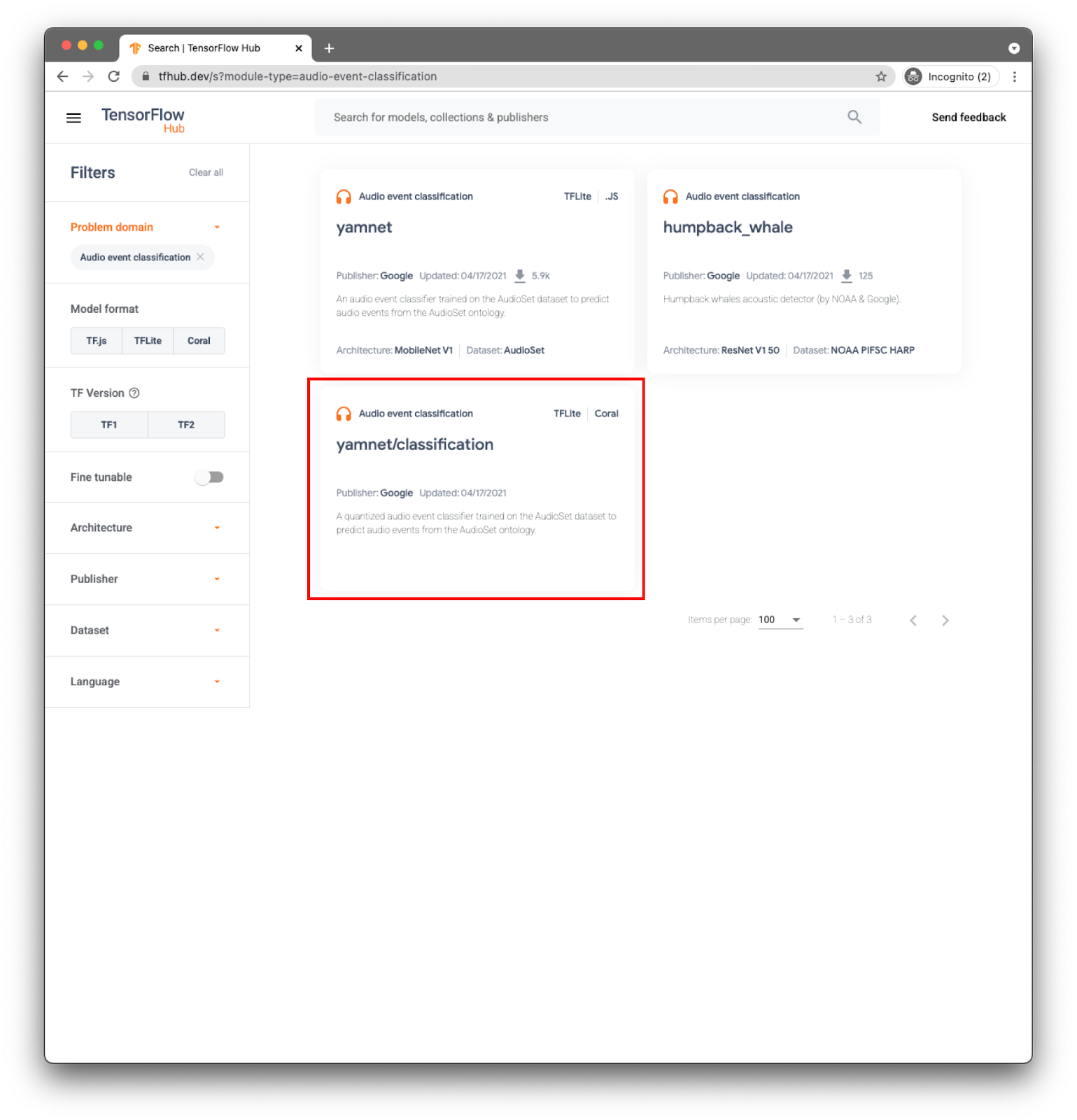
Выберите нужную вкладку: TFLite (yamnet/classification/tflite) и нажмите « Загрузить ». Вы также можете увидеть метаданные модели внизу.
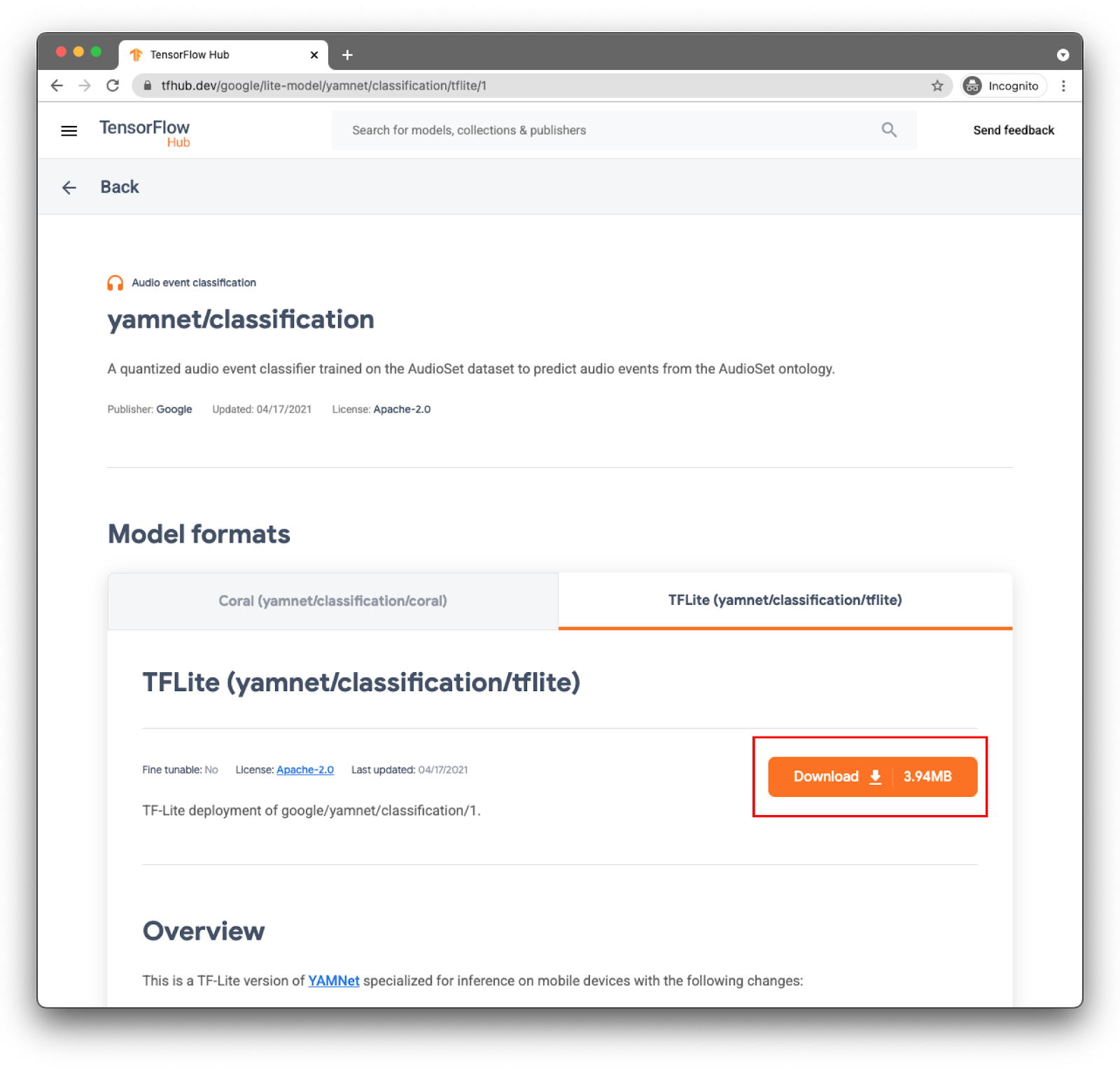
Этот файл модели ( lite-model_yamnet_classification_tflite_1.tflite ) будет использоваться на следующем шаге.
4. Импортируйте новую модель в базовое приложение.
Первый шаг — переместить загруженную модель из предыдущего шага в папку ресурсов в вашем приложении.
В Android Studio в проводнике проекта щелкните правой кнопкой мыши папку ресурсов .
Вы увидите всплывающее окно со списком параметров. Одним из них будет открытие папки в вашей файловой системе. На Mac это будет «Открыть в Finder », в Windows — « Открыть в проводнике », а в Ubuntu — « Показать в файлах» . Найдите подходящий для вашей операционной системы и выберите его.
Затем скопируйте в него загруженную модель.
Сделав это, вернитесь в Android Studio, и вы должны увидеть свой файл в папке с ресурсами .
5. Загрузите новую модель в базовое приложение.
Теперь вы выполните некоторые из TODO и включите классификацию звука с моделью, которую вы только что добавили в проект на предыдущем шаге.
Чтобы упростить поиск TODO, в Android Studio перейдите в меню: View > Tool Windows > TODO . Откроется окно со списком, и вы можете просто щелкнуть его, чтобы перейти прямо к коду.
В файле build.gradle (версия модуля) вы найдете первую задачу.
TODO 1 — добавить зависимости Android:
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
Все остальные изменения кода будут в MainActivity
TODO 2.1 создает переменную с именем модели для загрузки на следующих шагах.
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
TODO 2.2 вы определите минимальный порог, чтобы принять прогноз от модели. Эта переменная будет использоваться позже.
var probabilityThreshold: Float = 0.3f
В TODO 2.3 вы загрузите модель из папки с ресурсами. Класс AudioClassifier, определенный в библиотеке аудиозадач, готов загрузить модель и предоставить вам все необходимые методы для выполнения логического вывода, а также для помощи в создании аудиорекордера.
val classifier = AudioClassifier.createFromFile(this, modelPath)
6. Захват аудио
API Audio Tasks имеет несколько вспомогательных методов, которые помогут вам создать аудиорекордер с правильной конфигурацией, ожидаемой вашей моделью (например, частота дискретизации, битрейт, количество каналов). При этом вам не нужно искать его вручную, а также создавать объекты конфигурации.
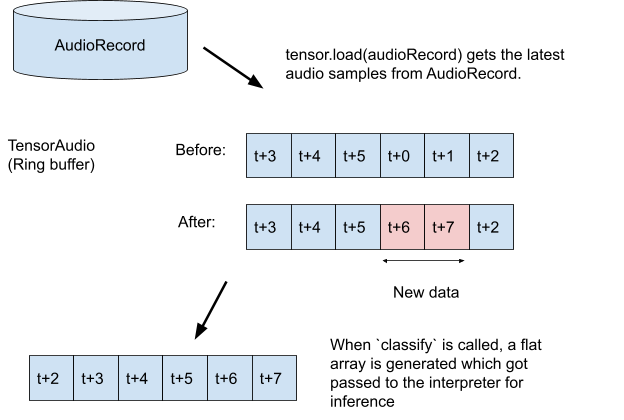
TODO 3.1: Создайте тензорную переменную, в которой будет храниться запись для логического вывода, и создайте спецификацию формата для записывающего устройства.
val tensor = classifier.createInputTensorAudio()
TODO 3.2: Показать спецификации аудиорекордера, которые были определены метаданными модели на предыдущем шаге.
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
TODO 3.3 : Создайте аудиорекордер и начните запись.
val record = classifier.createAudioRecord()
record.startRecording()
На данный момент ваше приложение слушает микрофон вашего телефона, но по-прежнему не делает никаких выводов. Вы решите это на следующем шаге.
7. Добавьте вывод в свою модель
На этом шаге вы добавите код логического вывода в свое приложение и отобразите его на экране. В коде уже есть поток таймера , который выполняется каждые полсекунды, и именно здесь будет выполняться вывод.
Параметры метода scheduleAtFixedRate — это время ожидания начала выполнения и время между последовательными выполнениями задачи, в приведенном ниже коде каждые 500 миллисекунд.
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 Добавьте код для использования модели. Сначала загрузите запись в звуковой тензор, а затем передайте ее классификатору:
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2 , чтобы получить лучшие результаты логического вывода, вы отфильтруете любую классификацию с очень низкой вероятностью. Здесь вы будете использовать переменную, созданную на предыдущем шаге ( probabilityThreshold ):
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3: Чтобы упростить чтение результата, давайте создадим строку с отфильтрованными результатами:
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4 Обновите пользовательский интерфейс. В этом очень простом приложении результат просто отображается в TextView. Поскольку классификация находится не в основном потоке, вам потребуется использовать обработчик для выполнения этого обновления.
runOnUiThread {
textView.text = outputStr
}
Вы добавили весь код, необходимый для:
- Загрузите модель из папки с ресурсами
- Создайте аудиорекордер с правильной конфигурацией
- Вывод
- Показать лучшие результаты на экране
Все, что нужно сейчас, это протестировать приложение.
8. Запустите финальное приложение
Вы интегрировали модель классификации аудио в приложение, так что давайте протестируем ее.
Подключите устройство Android и нажмите «Выполнить» (  ) на панели инструментов Android Studio.
) на панели инструментов Android Studio.
При первом выполнении вам нужно будет предоставить приложению разрешения на запись звука.
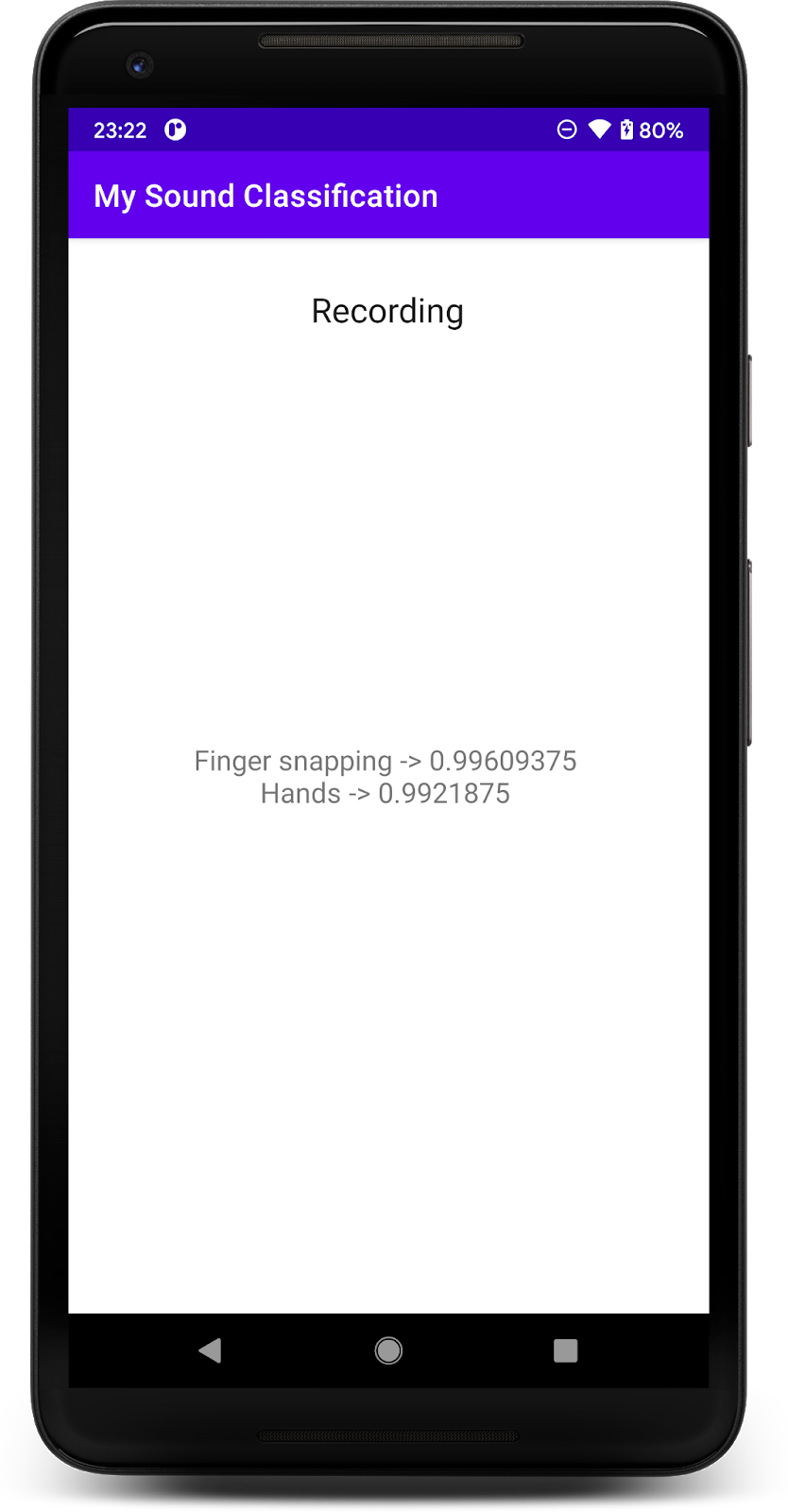
После предоставления разрешения приложение при запуске будет использовать микрофон телефона. Для проверки начните говорить рядом с телефоном, так как одним из классов, которые обнаруживает YAMNet, является речь. Еще один класс, который легко проверить, — это щелканье пальцами или хлопки в ладоши.
Вы также можете попытаться обнаружить лай собаки и многие другие возможные события (521). Для получения полного списка вы можете проверить их исходный код или прочитать метаданные непосредственно в файле меток.
9. Поздравляем!
В этой лаборатории кода вы узнали, как найти предварительно обученную модель для классификации звука и развернуть ее в своем мобильном приложении с помощью TensorFlow Lite. Чтобы узнать больше о TFLite, взгляните на другие образцы TFLite.
Что мы рассмотрели
- Как развернуть модель TensorFlow Lite в приложении для Android.
- Как найти и использовать модели из TensorFlow Hub.
Следующие шаги
- Настройте модель с вашими данными.
Учить больше
- Документация TensorFlow Lite
- Библиотека поддержки TensorFlow Lite
- Библиотека задач TensorFlow Lite
- Документация TensorFlow Hub
- Машинное обучение на устройстве с помощью технологий Google