
1. Sebelum memulai
TensorFlow adalah framework machine learning serbaguna. Layanan ini dapat digunakan untuk melatih model besar di seluruh cluster di cloud, atau menjalankan model secara lokal di sistem sematan seperti ponsel Anda.
Codelab ini menggunakan TensorFlow Lite untuk menjalankan model klasifikasi audio di perangkat Android.
Yang akan Anda pelajari
- Cara menemukan model machine learning terlatih yang siap digunakan.
- Cara melakukan klasifikasi audio pada audio yang direkam secara real time.
- Cara menggunakan Support Library TensorFlow Lite untuk melakukan praproses input model dan output model pascaproses.
- Cara menggunakan Library Tugas Audio untuk melakukan semua pekerjaan terkait audio.
Yang akan Anda buat
Aplikasi pengenal audio sederhana yang menjalankan model pengenalan audio TensorFlow Lite untuk mengidentifikasi audio dari mikrofon secara real time
Yang Anda butuhkan
- Versi terbaru Android Studio (v4.1.2+)
- Perangkat Android fisik dengan versi Android pada API 23 (Android 6.0)
- Kode contoh
- Pengetahuan dasar tentang pengembangan Android di Kotlin
2. Mendapatkan kode contoh
Download Kode
Klik link berikut untuk mendownload semua kode untuk codelab ini:
Mengekstrak file zip yang didownload. Ini akan mengekstrak folder root (odml-pathways) dengan semua resource yang Anda butuhkan. Untuk codelab ini, Anda hanya memerlukan sumber di subdirektori audio_classification/codelab1/android.
Catatan: Jika mau, Anda dapat meng-clone repositori:
git clone https://github.com/googlecodelabs/odml-pathways.git
Subdirektori android dalam repositori audio_classification/codelab1/android berisi dua direktori:
 starter—Kode awal yang Anda build untuk codelab ini.
starter—Kode awal yang Anda build untuk codelab ini.- final—Kode lengkap untuk aplikasi contoh yang sudah selesai.
Mengimpor aplikasi awal
Mari mulai dengan mengimpor aplikasi awal ke Android Studio.
- Buka Android Studio dan pilih Import Project (Gradle, Eclipse ADT, etc.)
- Buka folder
starter(audio_classification/codelab1/android/starter) dari kode sumber yang Anda download sebelumnya.

Untuk memastikan bahwa semua dependensi tersedia untuk aplikasi Anda, Anda harus menyinkronkan project dengan file gradle saat proses impor selesai.
- Pilih Sync Project with Gradle Files (
 ) dari toolbar Android Studio.
) dari toolbar Android Studio.
Menjalankan aplikasi awal
Setelah mengimpor project ke Android Studio, Anda siap menjalankan aplikasi untuk pertama kalinya.
Hubungkan perangkat Android melalui USB ke komputer Anda, lalu klik Run (  ) pada toolbar Android Studio.
) pada toolbar Android Studio.
3 Menemukan model terlatih
Untuk melakukan Klasifikasi Audio, Anda memerlukan model. Mulai dengan model terlatih, sehingga Anda tidak perlu melatihnya sendiri.
Untuk menemukan model terlatih, Anda akan menggunakan TensorFlow Hub ( www.tfhub.dev).
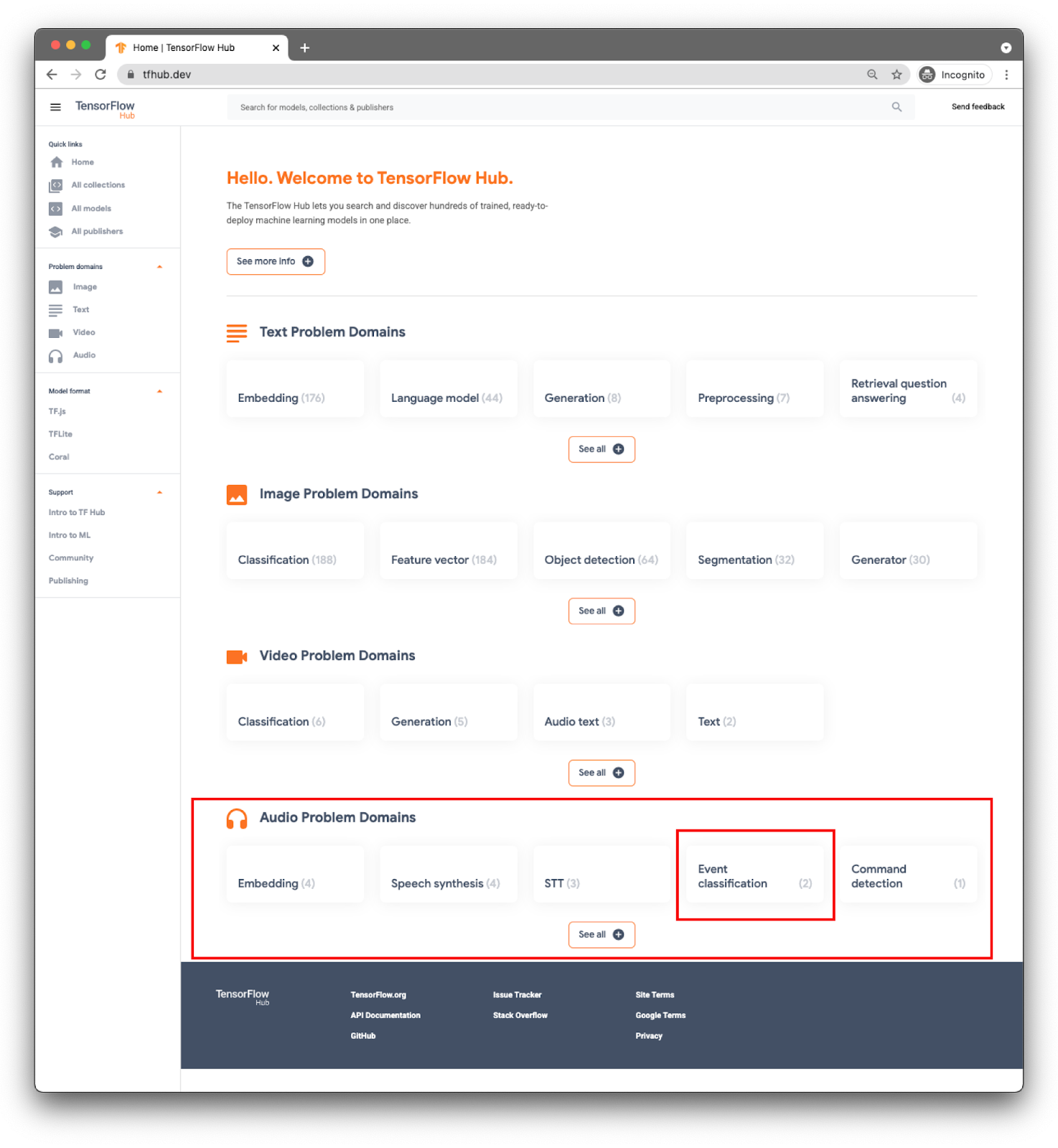
Model dikategorikan berdasarkan domain. Yang Anda perlukan saat ini adalah dari Domain Masalah Audio.
Untuk aplikasi, Anda akan melakukan klasifikasi peristiwa dengan model YAMNet.
YAMNet adalah pengklasifikasi peristiwa audio yang menggunakan bentuk gelombang audio sebagai input dan membuat prediksi independen untuk setiap 521 peristiwa audio.
Model yamnet/classify sudah dikonversi ke TensorFlow Lite dan memiliki metadata spesifik yang memungkinkan TFLite Task Library untuk Audio agar penggunaan model lebih mudah digunakan di perangkat seluler.
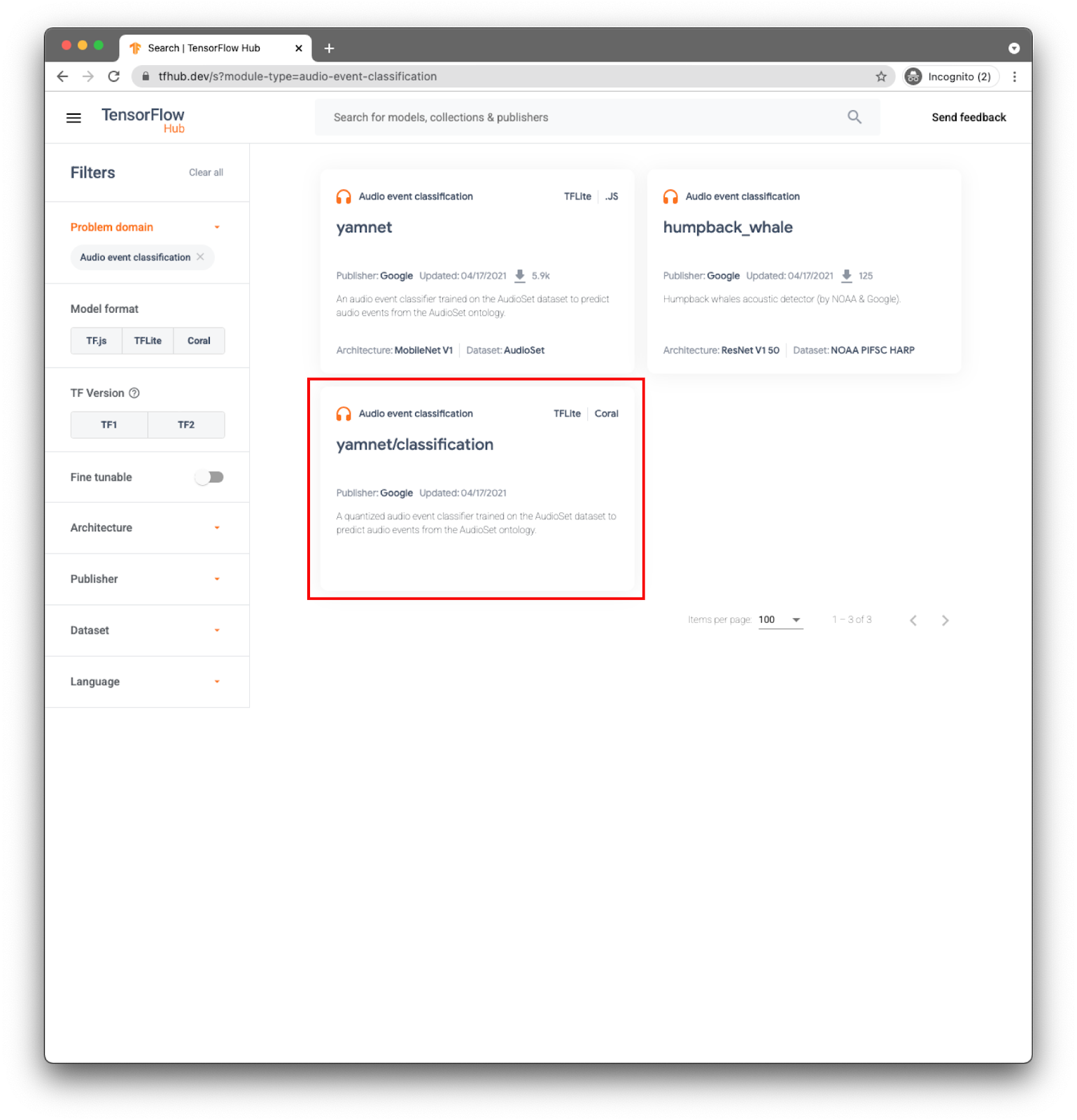
Pilih tab yang tepat: TFLite (yamnet/classify/tflite), dan klik Download. Anda juga dapat melihat metadata model di bagian bawah.
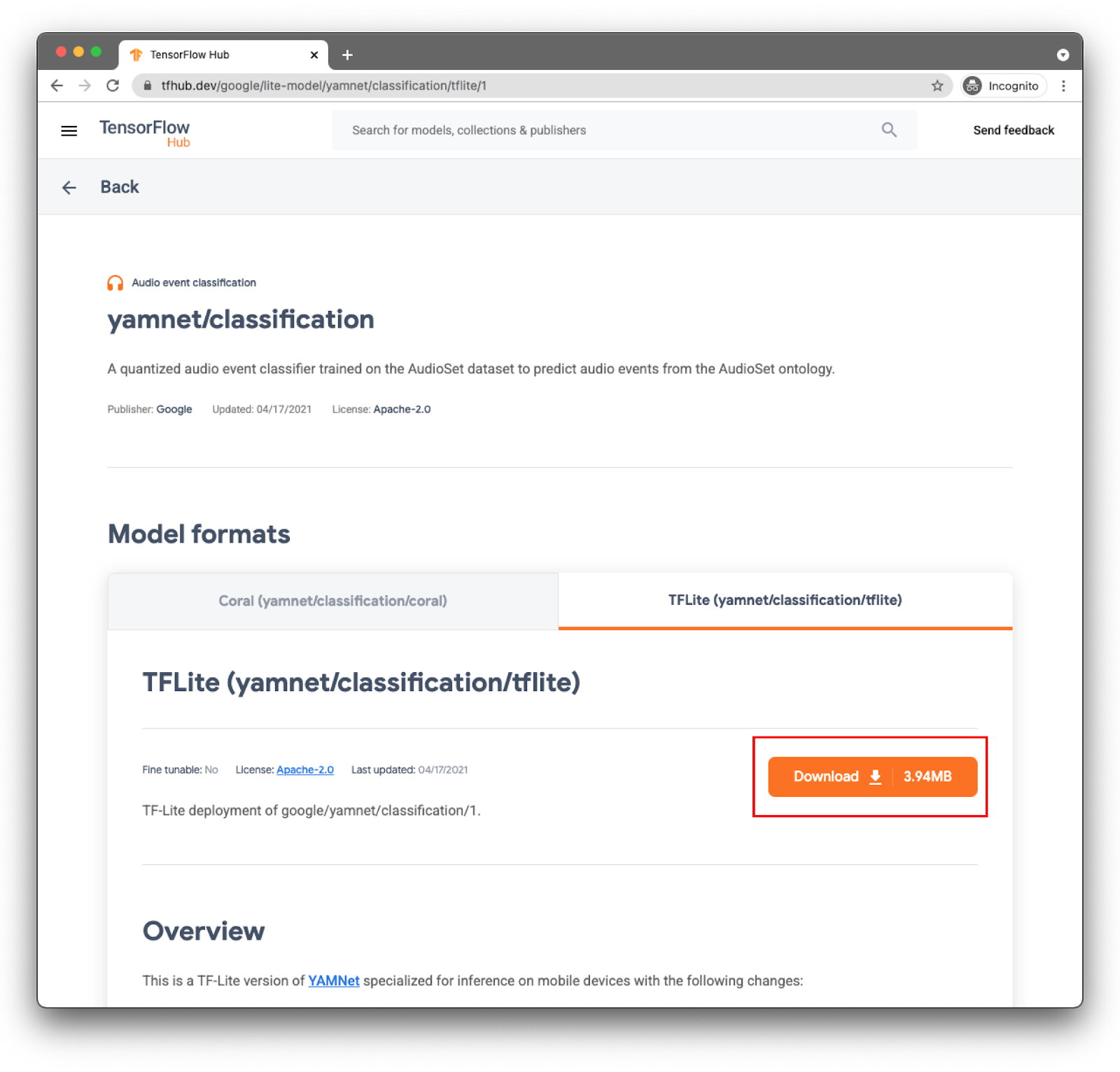
File model ini (lite-model_yamnet_classification_tflite_1.tflite) akan digunakan di langkah berikutnya.
4. Mengimpor model baru ke aplikasi dasar
Langkah pertama adalah memindahkan model yang didownload dari langkah sebelumnya ke folder aset dalam aplikasi Anda.
Di Android Studio, di penjelajah project, klik kanan folder assets.
Anda akan melihat pop-up yang berisi daftar opsi. Salah satunya adalah membuka folder di sistem file Anda. Di Mac, namanya adalah Reveal in Finder, di Windows akan menjadi Open in Explorer, dan di Ubuntu akan terlihat Show in Files. Temukan yang sesuai untuk sistem operasi Anda dan pilih.
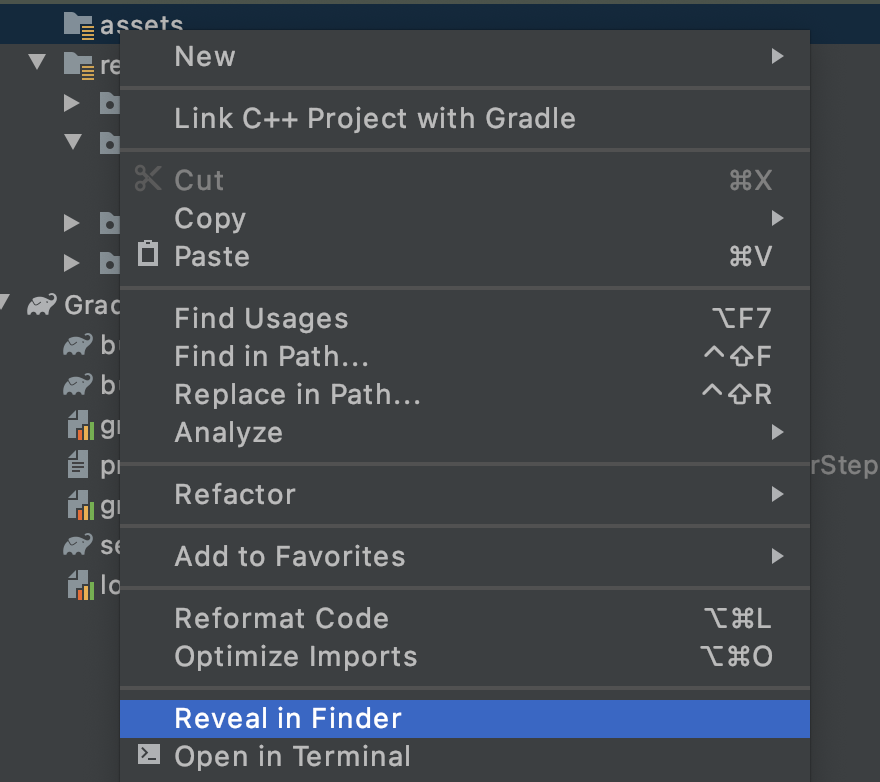
Kemudian, salin model yang didownload ke dalamnya.
Setelah melakukannya, kembali ke Android Studio, dan Anda akan melihat file dalam folder assets.
5. Memuat model baru di aplikasi dasar
Sekarang Anda akan mengikuti beberapa TODO dan mengaktifkan klasifikasi audio dengan model yang baru saja Anda tambahkan ke project pada langkah sebelumnya.
Untuk memudahkan Anda menemukan TODO, di Android Studio, buka menu: View > Tool Windows > TODO. Jendela yang berisi daftar akan terbuka, dan Anda dapat mengkliknya untuk langsung membuka kode.
Dalam file build.gradle (versi modul), Anda akan menemukan tugas pertama.
TODO 1 adalah menambahkan dependensi Android:
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
Semua perubahan kode lainnya akan ada di MainActivity
TODO 2.1 membuat variabel dengan nama model untuk dimuat pada langkah berikutnya.
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
TODO 2.2 Anda akan menentukan ambang batas minimum untuk menerima prediksi dari model tersebut. Variabel ini akan digunakan nanti.
var probabilityThreshold: Float = 0.3f
TODO 2.3 adalah tempat Anda akan memuat model dari folder aset. Class AudioClassifier yang ditentukan dalam Library Tugas Audio siap untuk memuat model dan memberi Anda semua metode yang diperlukan untuk menjalankan inferensi dan juga membantu membuat Perekam Audio.
val classifier = AudioClassifier.createFromFile(this, modelPath)
6. Rekam audio
Audio Tasks API memiliki sejumlah metode bantuan untuk membantu Anda membuat perekam audio dengan konfigurasi yang sesuai dengan kebutuhan model Anda (misalnya: Sample Rate, Bitrate, jumlah saluran). Dengan ini, Anda tidak perlu menemukannya secara manual dan juga membuat objek konfigurasi.
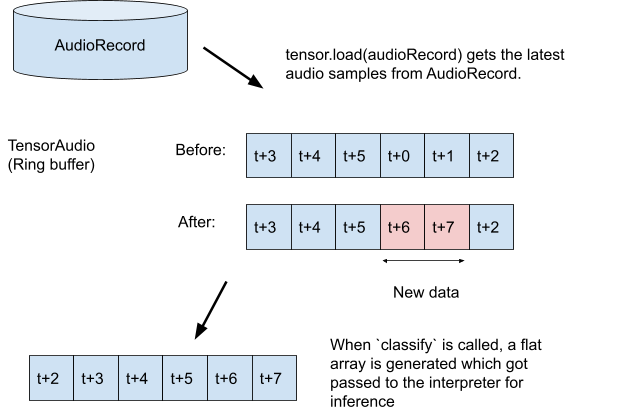
TODO 3.1: Buat variabel tensor yang akan menyimpan rekaman untuk inferensi dan buat spesifikasi format untuk perekam.
val tensor = classifier.createInputTensorAudio()
TODO 3.2: Menampilkan spesifikasi perekam audio yang ditentukan oleh metadata model di langkah sebelumnya.
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
TODO 3.3: Buat perekam audio dan mulai merekam.
val record = classifier.createAudioRecord()
record.startRecording()
Sekarang, aplikasi Anda sedang mendengarkan mikrofon ponsel, tetapi masih tidak melakukan inferensi apa pun. Anda akan menangani hal ini di langkah berikutnya.
7. Menambahkan inferensi ke model
Pada langkah ini, Anda akan menambahkan kode inferensi ke aplikasi dan menampilkannya di layar. Kode sudah memiliki thread timer yang dijalankan setiap setengah detik, dan di situlah inferensi akan dijalankan.
Parameter untuk metode scheduleAtFixedRate adalah waktu tunggu untuk memulai eksekusi dan waktu antara eksekusi tugas yang berurutan, dalam kode di bawah setiap 500 milidetik.
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 Tambahkan kode untuk menggunakan model. Pertama-tama muat rekaman ke tensor audio, lalu teruskan ke pengklasifikasi:
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2 untuk mendapatkan hasil inferensi yang lebih baik, Anda akan memfilter klasifikasi apa pun yang memiliki probabilitas sangat rendah. Di sini Anda akan menggunakan variabel yang dibuat pada langkah sebelumnya (probabilityThreshold):
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3: Untuk mempermudah membaca hasil, mari kita buat String dengan hasil yang difilter:
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4 Update UI. Dalam aplikasi yang sangat sederhana ini, hasilnya hanya ditampilkan dalam TextView. Karena klasifikasi tidak berada di Thread Utama, Anda harus menggunakan pengendali untuk melakukan pembaruan ini.
runOnUiThread {
textView.text = outputStr
}
Anda telah menambahkan semua kode yang diperlukan untuk:
- Memuat model dari folder aset
- Buat perekam audio dengan konfigurasi yang benar
- Menjalankan inferensi
- Tampilkan hasil terbaik di layar
Sekarang Anda hanya perlu menguji aplikasi.
8 Menjalankan aplikasi final
Anda telah mengintegrasikan model klasifikasi audio ke aplikasi, jadi mari kita uji.
Hubungkan perangkat Android, lalu klik Run (  ) di toolbar Android Studio.
) di toolbar Android Studio.
Pada eksekusi pertama, Anda harus memberikan izin perekaman audio aplikasi.
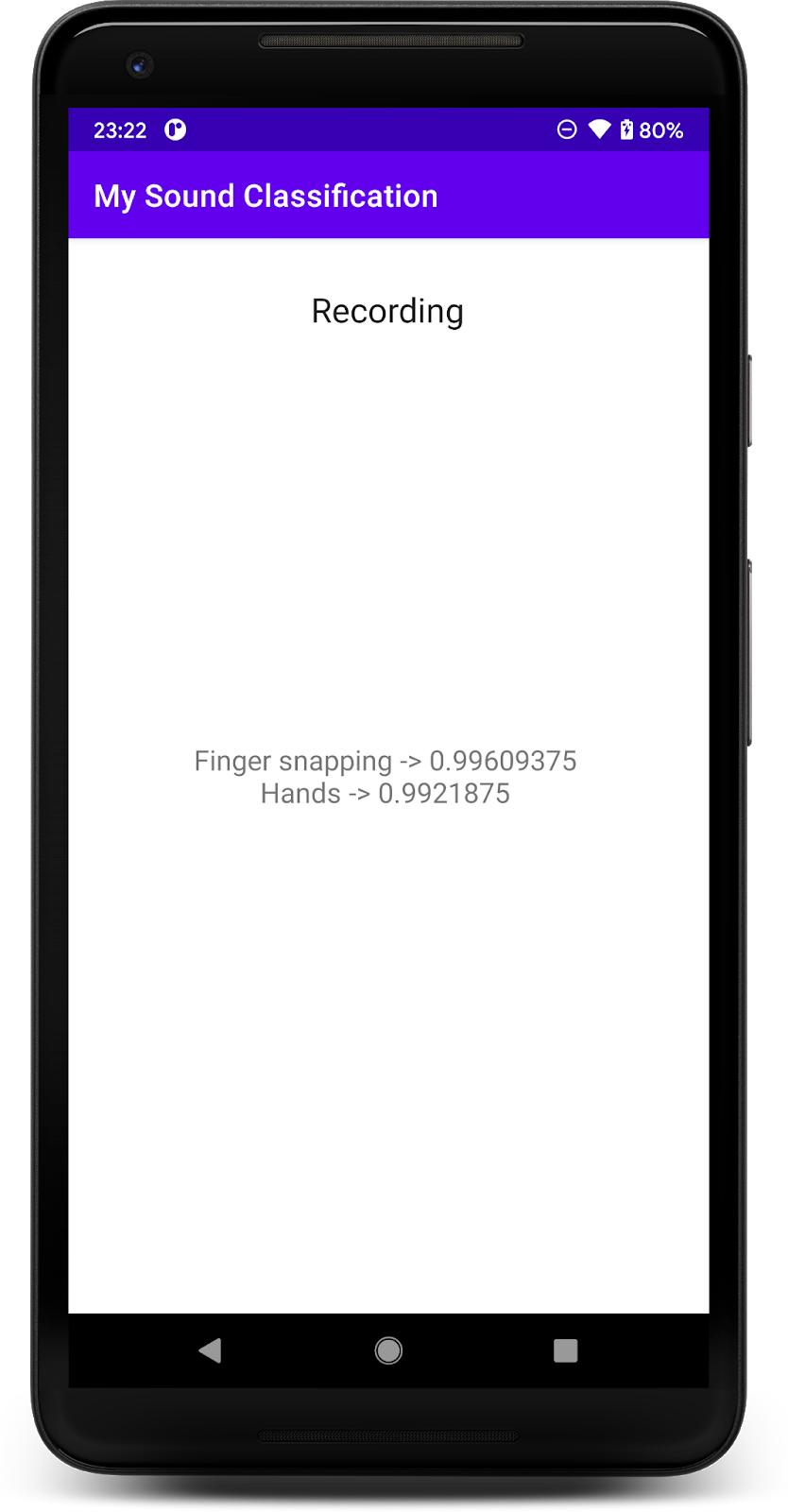
Setelah memberikan izin, aplikasi di awal akan menggunakan mikrofon ponsel. Untuk menguji, mulai bicaralah di dekat ponsel karena salah satu kelas yang terdeteksi oleh YAMNet adalah ucapan. Kelas lain yang mudah diuji adalah cubit atau tepuk tangan.
Anda juga dapat mencoba mendeteksi gonggongan anjing, dan berbagai kemungkinan peristiwa lainnya (521). Untuk daftar lengkapnya, Anda dapat melihat kode sumbernya atau Anda juga dapat membaca metadata dengan file label secara langsung.
9. Selamat!
Dalam codelab ini, Anda telah mempelajari cara menemukan model terlatih untuk klasifikasi audio dan men-deploy-nya ke aplikasi seluler menggunakan TensorFlow Lite. Untuk mempelajari TFLite lebih lanjut, lihat contoh TFLite lainnya.
Yang telah kita bahas
- Cara men-deploy model TensorFlow Lite di aplikasi Android.
- Cara menemukan dan menggunakan model dari TensorFlow Hub.
Langkah Berikutnya
- Menyesuaikan model dengan data Anda sendiri.
Pelajari Lebih Lanjut
- Dokumentasi TensorFlow Lite
- Support Library TensorFlow Lite
- Library Tugas TensorFlow Lite
- Dokumentasi TensorFlow Hub
- Machine Learning di perangkat dengan teknologi Google