
1. 始める前に
TensorFlow は多目的の機械学習フレームワークです。クラウド内のクラスタ全体で大規模なモデルをトレーニングしたり、スマートフォンなどの組み込みシステムでモデルをローカルで実行したりできます。
この Codelab では、TensorFlow Lite を使用して Android デバイスで音声分類モデルを実行します。
学習内容
- 事前トレーニング済み機械学習モデルの入手方法
- キャプチャした音声をリアルタイムで分類する方法
- TensorFlow Lite サポート ライブラリを使用して、モデルの入力を前処理し、モデルの出力を後処理する方法。
- 音声タスク ライブラリを使用して音声に関連するすべての処理を行う方法。
作成するアプリの概要
TensorFlow Lite 音声認識モデルを実行してマイクからの音声をリアルタイムで識別するシンプルな音声認識アプリ
必要なもの
- 最新バージョンの Android Studio(v4.1.2 以降)
- API バージョン 23(Android 6.0)の Android 搭載実機
- サンプルコード
- Kotlin による Android 開発の基本的な知識
2. サンプルコードを取得する
コードをダウンロードする
次のリンクをクリックして、この Codelab のコードをすべてダウンロードします。
ダウンロードした zip ファイルを解凍すると、ルートフォルダ(odml-pathways)が展開され、必要なリソースがすべて揃います。この Codelab では、audio_classification/codelab1/android サブディレクトリ内のソースのみが必要です。
注: 必要に応じてリポジトリのクローンを作成できます。
git clone https://github.com/googlecodelabs/odml-pathways.git
audio_classification/codelab1/android リポジトリの android サブディレクトリには、次の 2 つのディレクトリがあります。
 starter: この Codelab で土台として使うコードを元に、
starter: この Codelab で土台として使うコードを元に、- final: 完成したサンプルアプリの完成したコードです。
スターター アプリをインポートする
まず、スターター アプリを Android Studio にインポートします。
- Android Studio を開き、[Import Project (Gradle, Eclipse ADT, etc.)] を選択します。
- 先ほどダウンロードしたソースコードから
starterフォルダ(audio_classification/codelab1/android/starter)を開きます。

すべての依存関係をアプリで使用できるようにするには、インポート プロセスの完了後に、プロジェクトを Gradle ファイルと同期する必要があります。
- Android Studio のツールバーで [Sync Project with Gradle Files](
 )を選択します。
)を選択します。
スターター アプリを実行する
Android Studio にプロジェクトがインポートされたので、アプリを初めて実行する準備が整いました。
Android デバイスを USB 経由でパソコンに接続し、Android Studio のツールバーで実行アイコン( )をクリックします。
)をクリックします。
3. 事前トレーニング済みモデルを見つける
音声分類を行うには、モデルが必要です。事前トレーニング済みモデルから始めて、自分でトレーニングする必要はありません。
事前トレーニング済みモデルを見つけるには、TensorFlow Hub(www.tfhub.dev)を使用します。
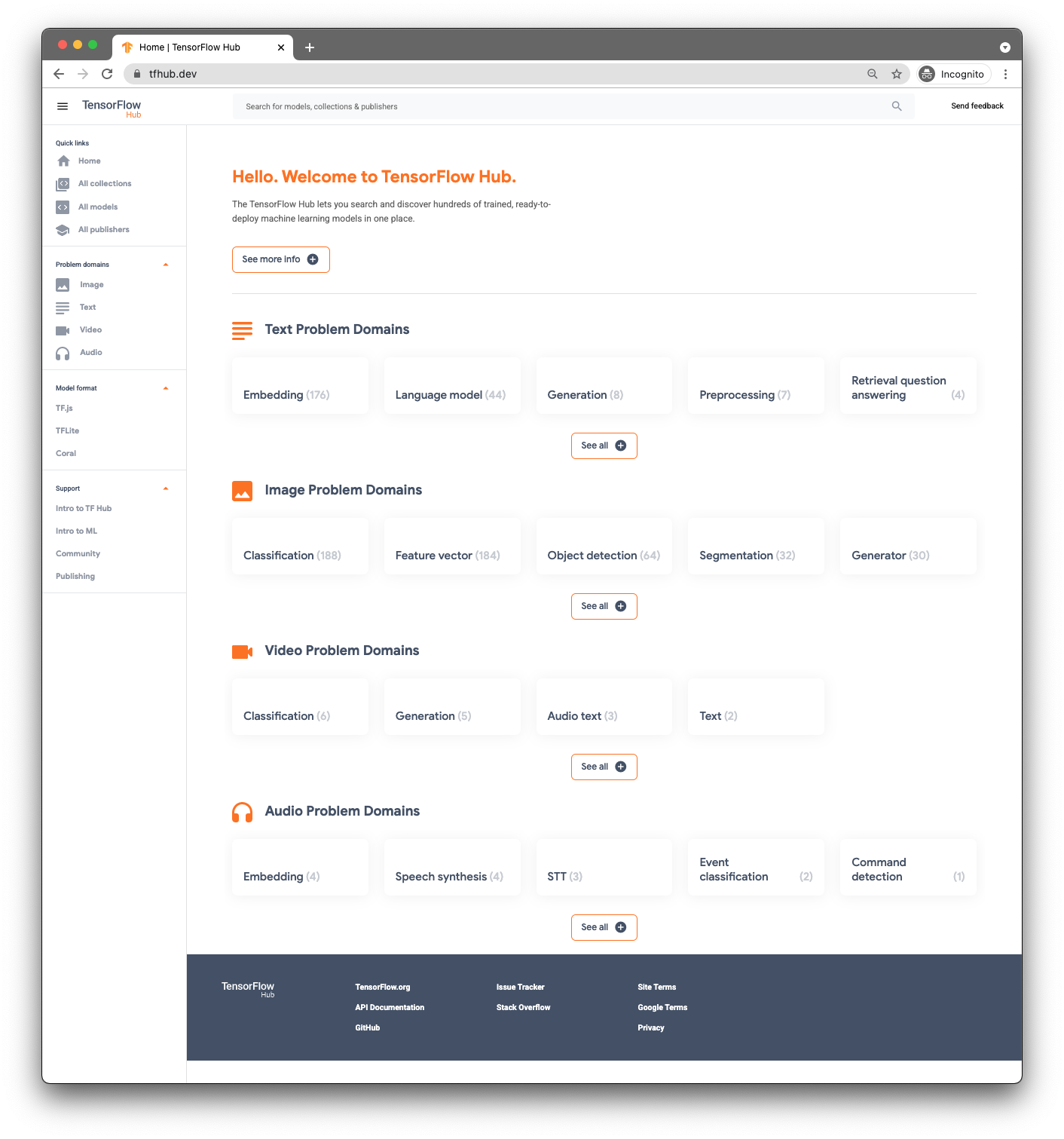
モデルはドメイン別に分類されています。今必要なのは、オーディオに関する問題のドメインです。
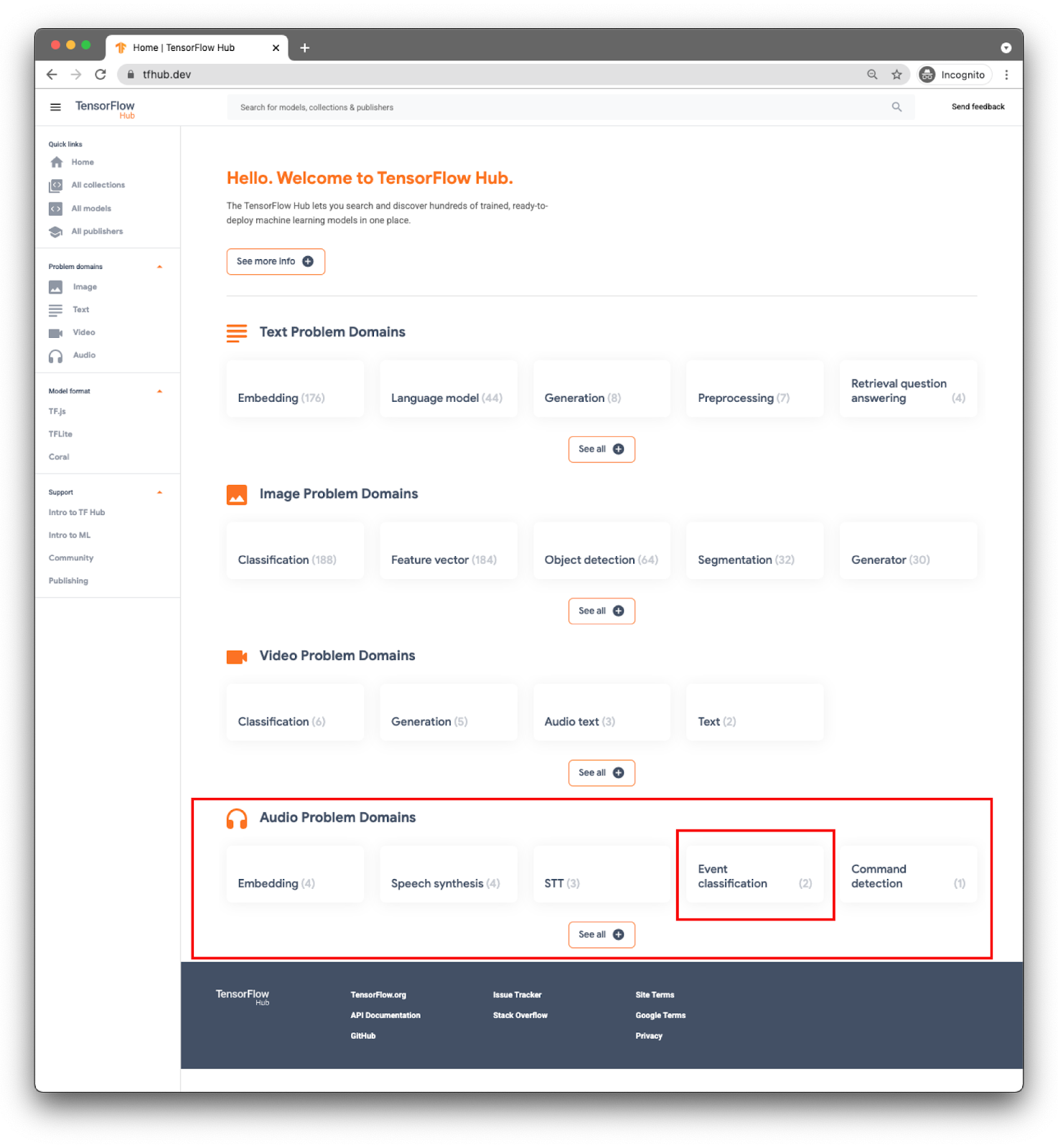
アプリでは、YAMNet モデルを使用してイベント分類を行います。
YAMNet は、音声波形を入力として受け取り、521 の音声イベントごとに個別に予測を行う音声イベント分類器です。
モデル yamnet/分類はすでに TensorFlow Lite に変換されており、特定のメタデータにより TFLite Task Library for Audio が使用されているため、モバイル デバイスでのモデルの使用が簡単になります。
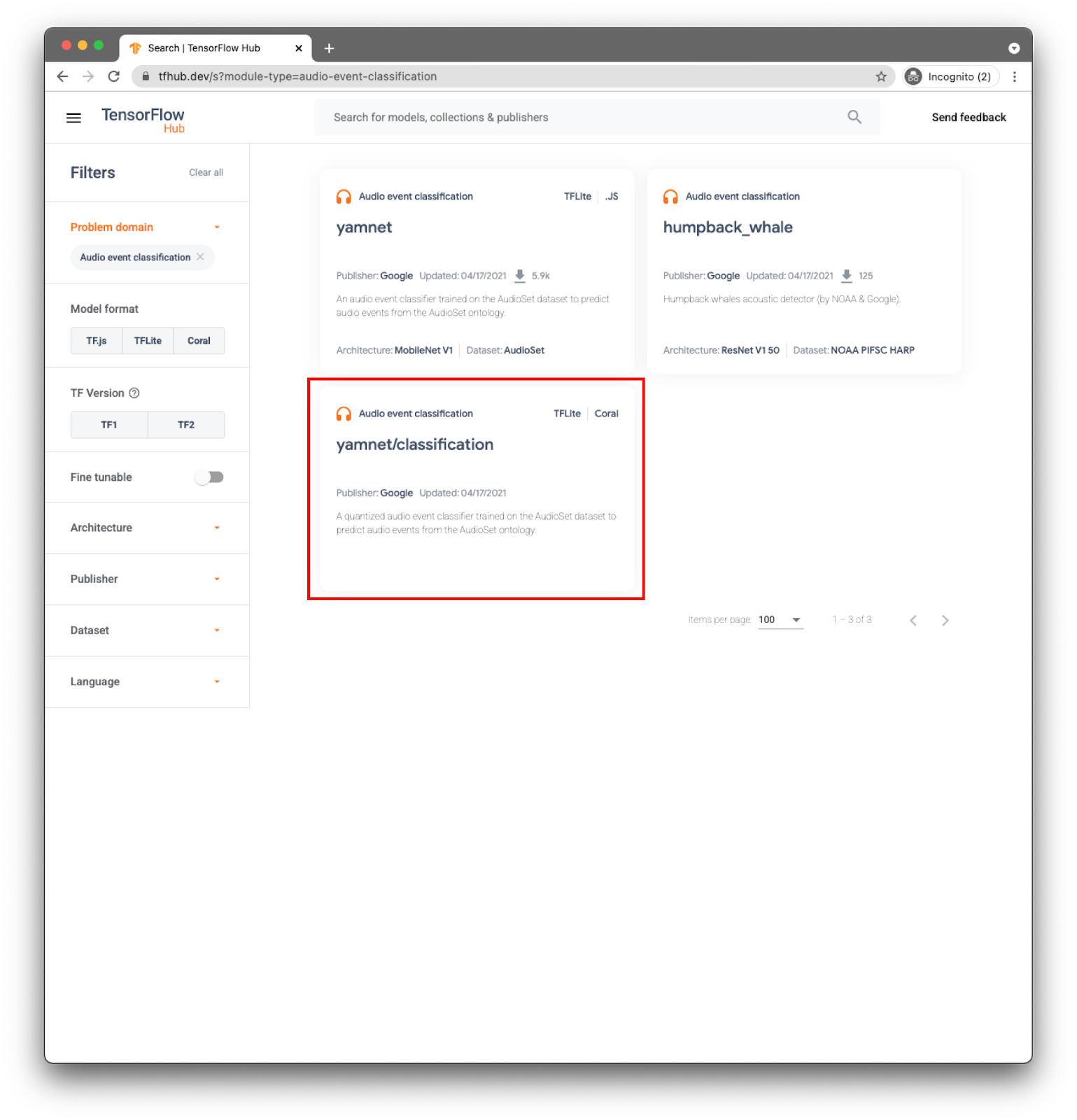
適切なタブ: TFLite(yamnet/classification/tflite)を選択し、[Download] をクリックします。下部にモデルのメタデータも表示されます。
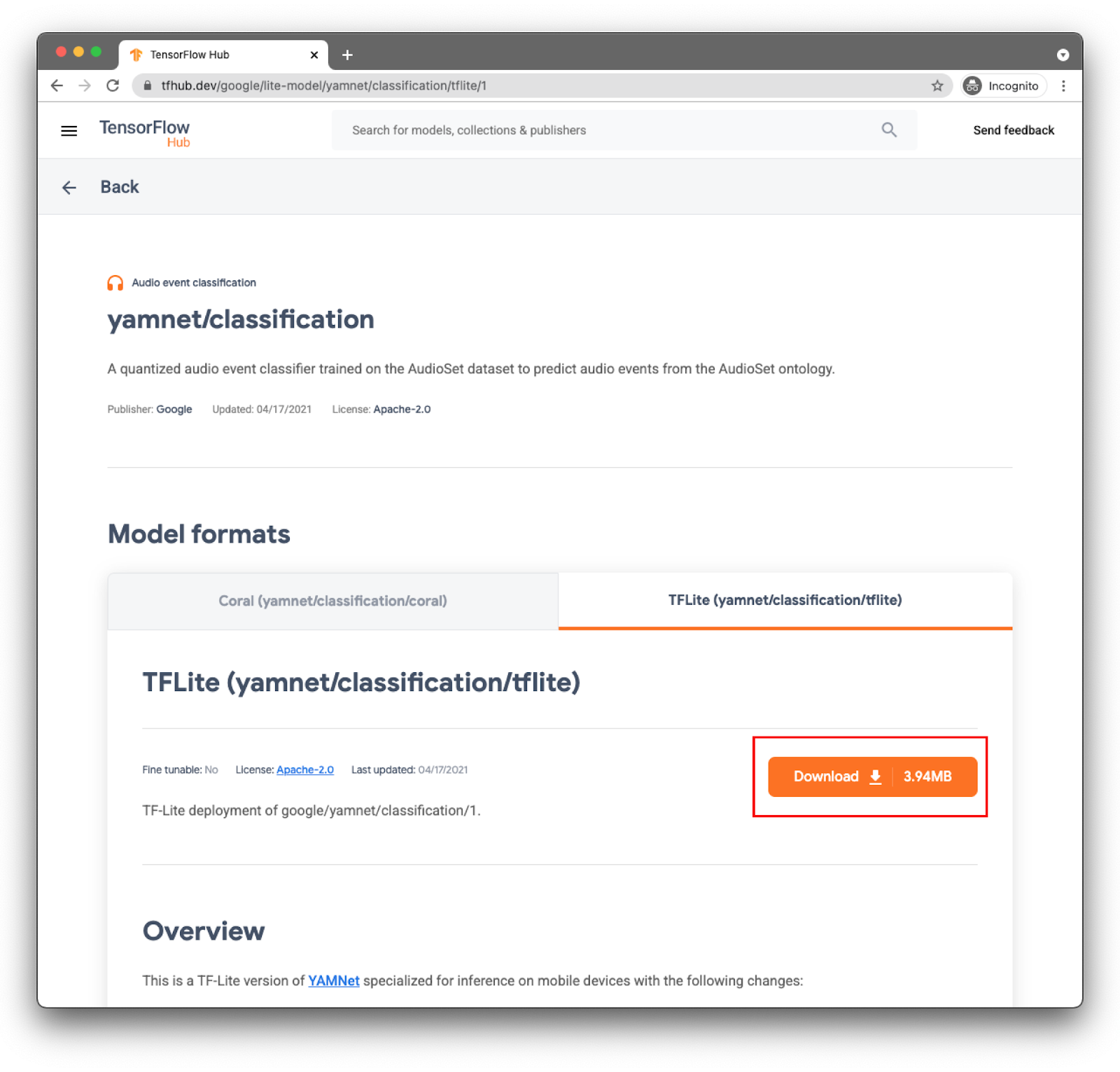
このモデルファイル(lite-model_yamnet_classification_tflite_1.tflite)は、次のステップで使用します。
4.新しいモデルをベースアプリにインポートする
まず、ダウンロードしたモデルを前のステップからアプリのアセット フォルダに移動します。
Android Studio のプロジェクト エクスプローラで、[assets] フォルダを右クリックします。
ポップアップが開き、オプションが表示されます。そのうちの 1 つが、ファイル システムでフォルダを開くことです。Mac では [Finder in Shower]、Windows では [Open in Explorer]、Ubuntu では [Show in Files] に表示されます。使用しているオペレーティング システムに合ったものを選択します。
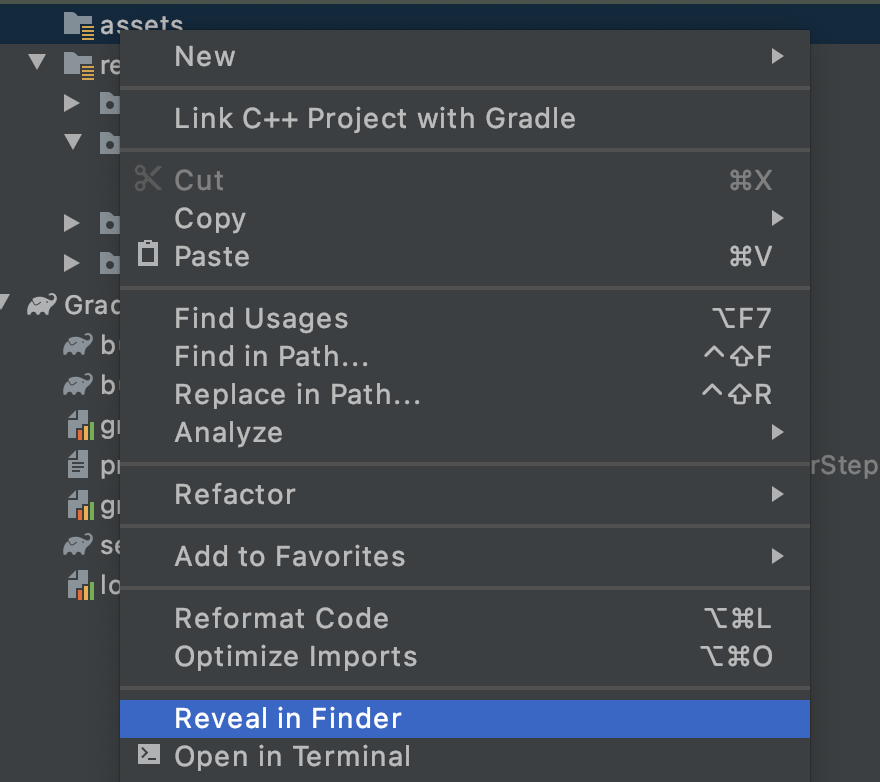
ダウンロードしたモデルをコピーします。
確認したら、Android Studio に戻ると、assets フォルダにファイルが表示されます。
5. ベースアプリに新しいモデルを読み込む
TODO をいくつか確認し、前のステップでプロジェクトに追加したモデルを使用して、音声分類を有効にします。
TODO を簡単に見つけられるようにするには、Android Studio で、メニューの [View] > [Tool Windows] > [TODO] に移動します。ウィンドウがリストで開き、クリックするだけでコードにアクセスできます。
build.gradle ファイル(モジュール バージョン)には、最初のタスクがあります。
TODO 1 では、Android の依存関係を追加します。
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
残りのコード変更は MainActivity で行います
TODO 2.1 は、次のステップを読み込むための名前を含む変数を作成します。
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
TODO 2.2: モデルからの予測を受け入れる最小しきい値を定義します。この変数は後で使用します。
var probabilityThreshold: Float = 0.3f
TODO 2.3 は、アセット フォルダからモデルを読み込む場所です。音声タスク ライブラリで定義された AudioClassifier クラスは、モデルを読み込んで、推論の実行とオーディオ レコーダーの作成に必要なすべてのメソッドを提供する準備が整っています。
val classifier = AudioClassifier.createFromFile(this, modelPath)
6. 音声のキャプチャ
Audio Tasks API には、モデルが想定する適切な構成(サンプルレート、ビットレート、チャンネル数など)のオーディオ レコーダーの作成に役立つヘルパー メソッドが用意されています。この方法では、手作業で見つける必要も、構成オブジェクトを作成する必要もありません。
TODO 3.1: 推論用に録音を保存するテンソル変数を作成し、レコーダーの形式仕様を作成します。
val tensor = classifier.createInputTensorAudio()
TODO 3.2: 前のステップでモデルのメタデータで定義されたオーディオ レコーダーの仕様を表示します。
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs
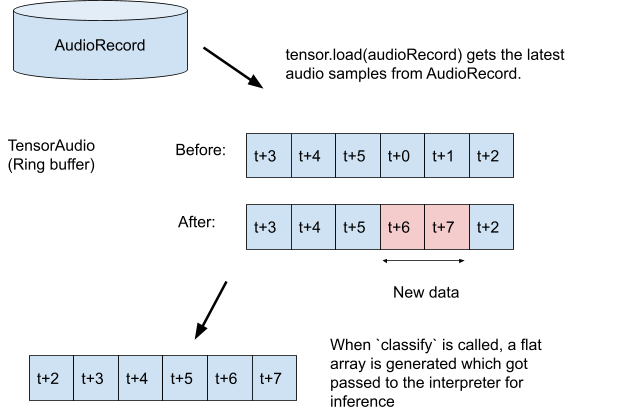
TODO 3.3: オーディオ レコーダーを作成して録音を開始します。
val record = classifier.createAudioRecord()
record.startRecording()
この時点では、アプリはスマートフォンのマイクをリッスンしていますが、推論は行っていません。これは次のステップで対処します。
7. モデルに推論を追加する
このステップでは、アプリに推論コードを追加し、それを画面に表示します。コードには、半時間ごとに実行されるタイマー スレッドがすでに存在しており、ここで推論が実行されます。
scheduleAtFixedRate メソッドのパラメータは、500 ミリ秒未満のコードで、実行の開始待機時間とタスク実行の継続時間です。
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 モデルを使用するコードを追加します。まず、録音をテンソルに読み込み、それを分類器に渡します。
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2 は、より適切な推論結果を得るために、非常に低い確率を持つ分類を除外します。ここでは、前の手順で作成した変数(probabilityThreshold)を使用します。
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3: 結果を読みやすくするために、フィルタリングされた結果を含む文字列を作成します。
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4: UI を更新する。この非常にシンプルなアプリでは、結果は TextView に表示されます。分類はメインスレッドにないため、この更新を行うにはハンドラを使用する必要があります。
runOnUiThread {
textView.text = outputStr
}
必要なコードをすべて追加しました。
- アセット フォルダからモデルを読み込む
- 正しい設定でオーディオ レコーダーを作成する
- 推論の実行
- 最適な検索結果を画面に表示する
必要な手順はアプリのテストのみです。
8. 最終アプリを実行する
音声分類モデルをアプリに組み込んだので、テストしてみましょう。
Android デバイスを接続し、Android Studio ツールバーの [Run]( )をクリックします。
)をクリックします。
初回実行時には、アプリに音声録音の権限を付与する必要があります。
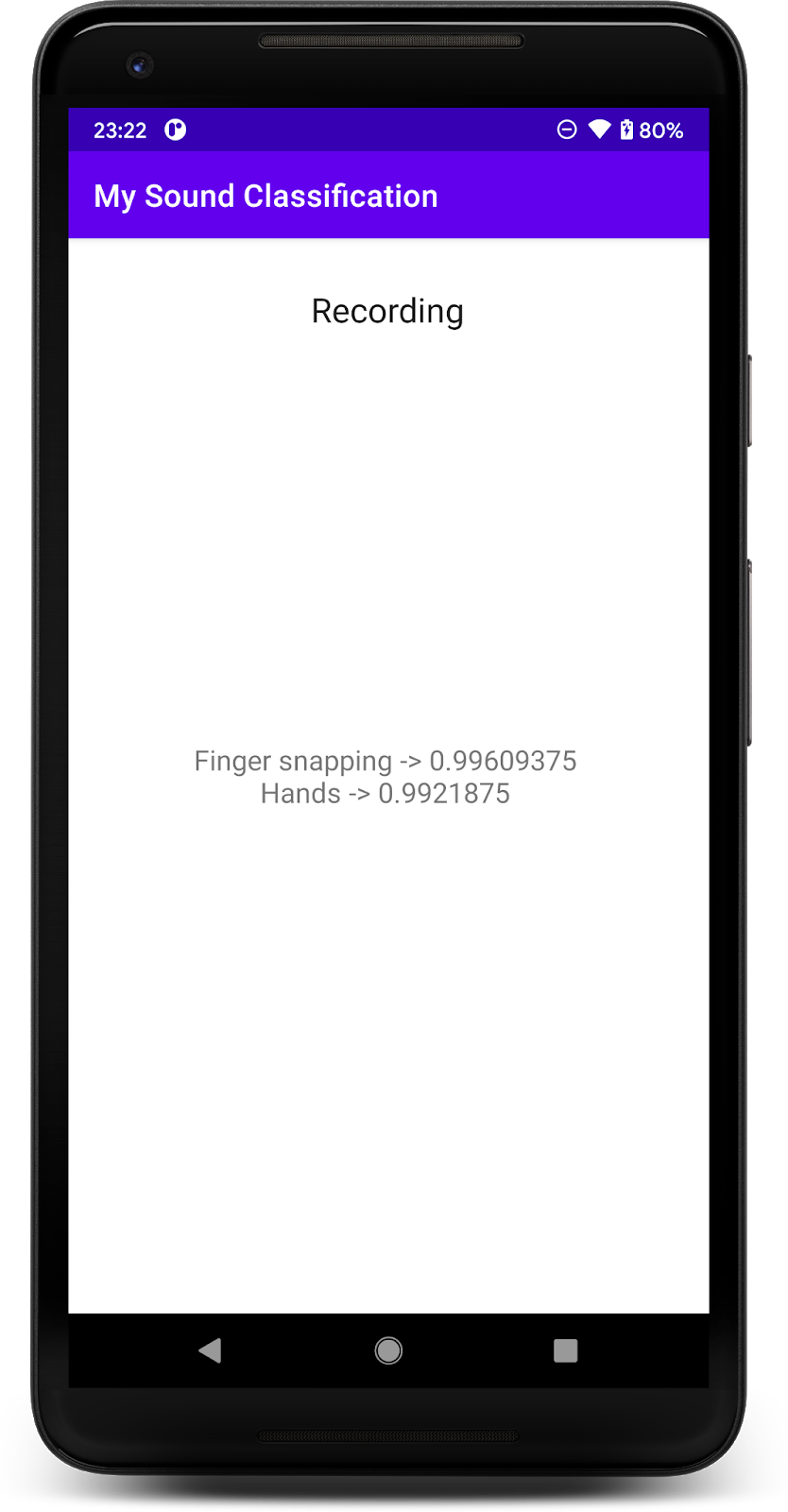
アクセスを許可すると、開始時にアプリはスマートフォンのマイクを使用します。YAMNet が検出したクラスの 1 つが音声であるため、テストのために電話の近くで話し始めます。テストが簡単なもう 1 つのクラスは、指をパチンと叩きます。
犬の吠える声など、さまざまなイベントを検出することもできます(521)。完全なリストについては、ソースコードを確認するか、ラベルファイルで直接メタデータを読み取ることもできます
9. 完了
この Codelab では、音声分類用の事前トレーニング済みモデルを見つけ、TensorFlow Lite を使用してモバイルアプリにデプロイする方法を学びました。TFLite の詳細については、他の TFLite のサンプルをご覧ください。
学習した内容
- Android アプリに TensorFlow Lite モデルをデプロイする方法。
- TensorFlow Hub からモデルを見つけて使用する方法。
次の手順
- 独自のデータでモデルをカスタマイズできます。
詳細
- TensorFlow Lite のドキュメント
- TensorFlow Lite サポート ライブラリ
- TensorFlow Lite タスク ライブラリ
- TensorFlow Hub のドキュメント
- オンデバイス機械学習と Google テクノロジー