
1. Before you begin
TensorFlow is a multipurpose machine learning framework. It can be used for training huge models across clusters in the cloud, or running models locally on an embedded system like your phone.
This codelab uses TensorFlow Lite to run an audio classification model on an Android device.
What you'll learn
- How to find a pre-trained machine learning model ready to be used.
- How to do audio classification on audio captured in real time.
- How to use the TensorFlow Lite Support Library to preprocess model input and postprocess model output.
- How to use the Audio Task Library to do all audio related work.
What you'll build
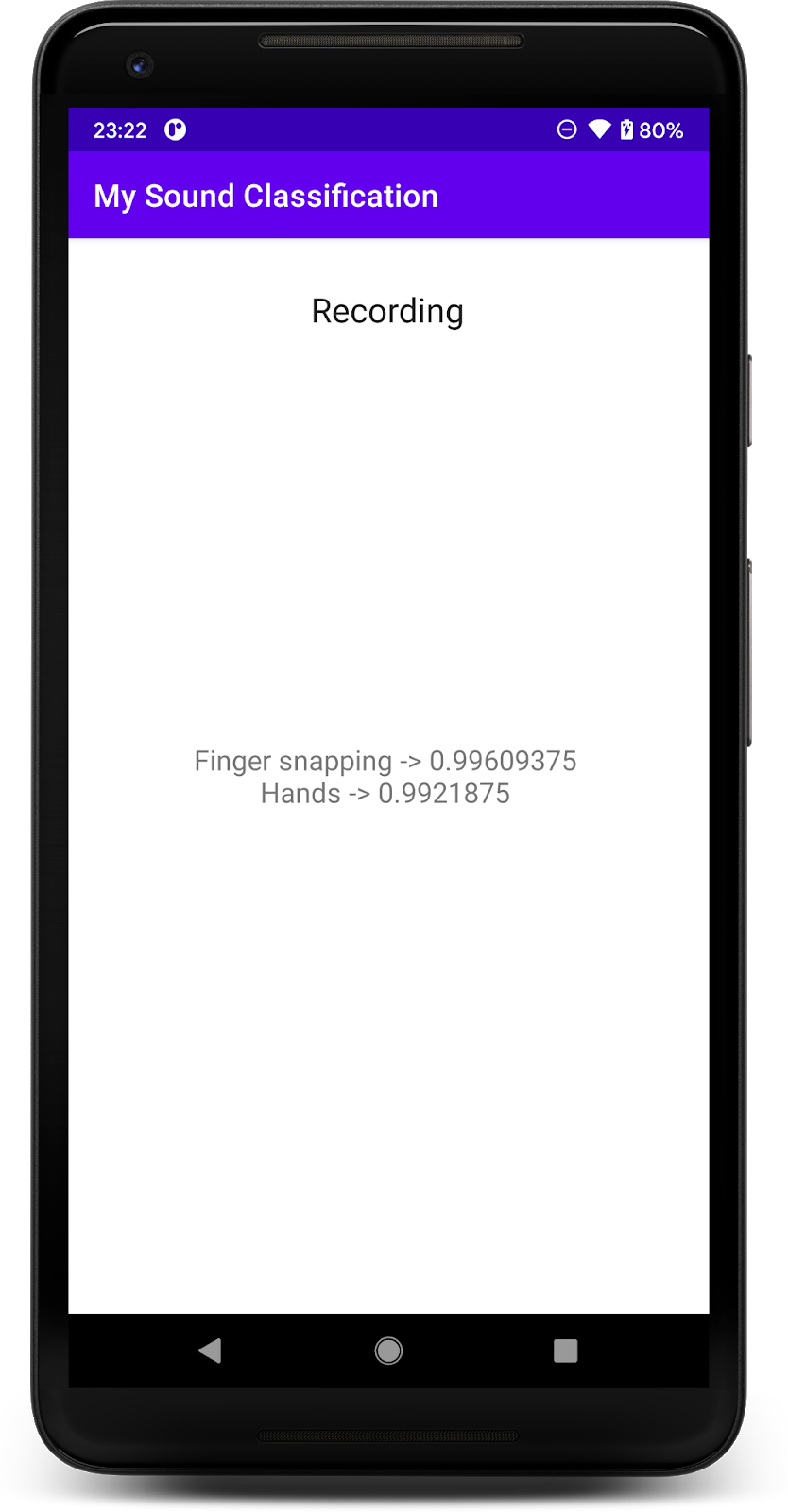
A simple audio recognizer app that runs a TensorFlow Lite audio recognition model to identify audios from the microphone in real time
What you'll need
- A recent version of Android Studio (v4.1.2+)
- Physical Android device with Android version at API 23 (Android 6.0)
- The sample code
- Basic knowledge of Android development in Kotlin
2. Get the sample code
Download the Code
Click the following link to download all the code for this codelab:
Unpack the downloaded zip file. This will unpack a root folder (odml-pathways) with all of the resources you will need. For this codelab, you will only need the sources in the audio_classification/codelab1/android subdirectory.
Note: If you prefer you can clone the repository:
git clone https://github.com/googlecodelabs/odml-pathways.git
The android subdirectory in the audio_classification/codelab1/android repository contains two directories:
 starter—Starting code that you build upon for this codelab.
starter—Starting code that you build upon for this codelab.- final—Completed code for the finished sample app.
Import the starter app
Let's start by importing the starter app into the Android Studio.
- Open Android Studio and select Import Project (Gradle, Eclipse ADT, etc.)
- Open the
starterfolder (audio_classification/codelab1/android/starter) from the source code you downloaded earlier.

To be sure that all dependencies are available to your app, you should sync your project with gradle files when the import process has finished.
- Select Sync Project with Gradle Files (
 ) from the Android Studio toolbar.
) from the Android Studio toolbar.
Run the starter app
Now that you have imported the project into Android Studio, you're ready to run the app for the first time.
Connect your Android device via USB to your computer and click Run (  ) in the Android Studio toolbar.
) in the Android Studio toolbar.
3. Find a pre-trained model
To do Audio Classification, you're going to need a model. Start with a pre-trained model so you don't have to train one yourself.
To find pre-trained models you will use TensorFlow Hub ( www.tfhub.dev).
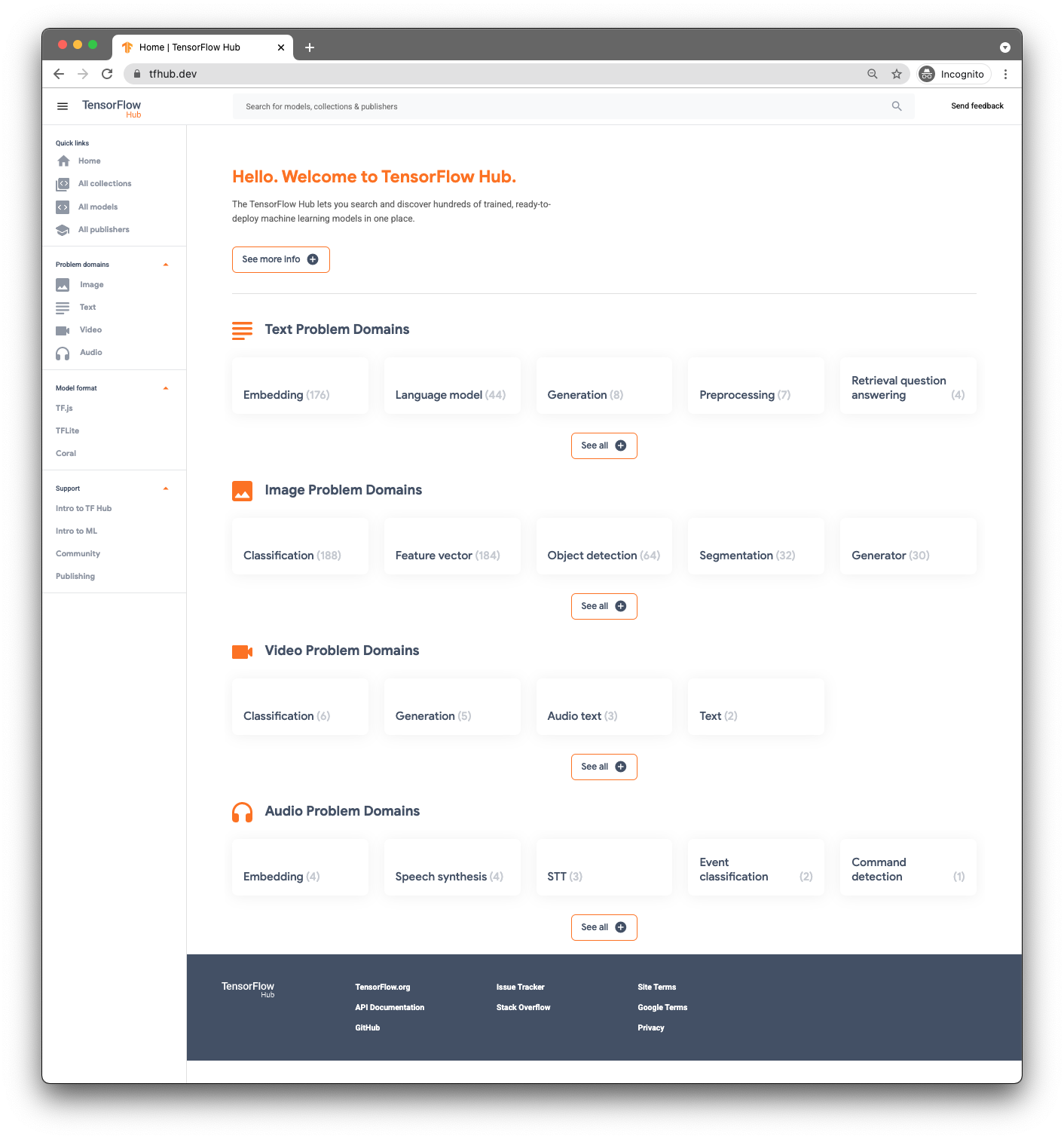
Models are categorized by domains. The one you need right now is from the Audio Problem Domains.
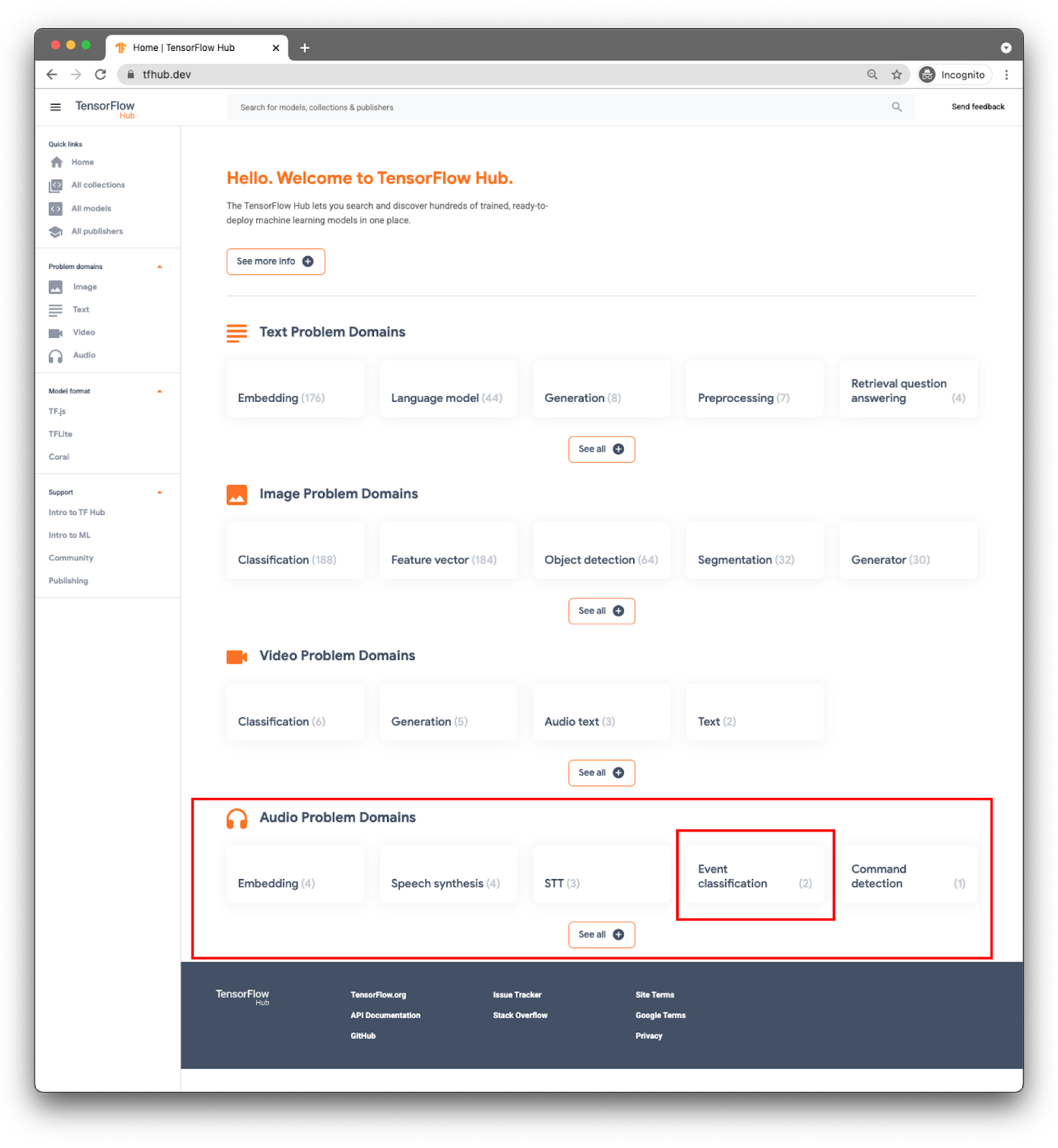
For your app, you will do event classification with the YAMNet model.
YAMNet is an audio event classifier that takes audio waveform as input and makes independent predictions for each of 521 audio events.
The model yamnet/classification is already converted to TensorFlow Lite and has specific metadata that enables the TFLite Task Library for Audio to make the model's usage easier to use on mobile devices.
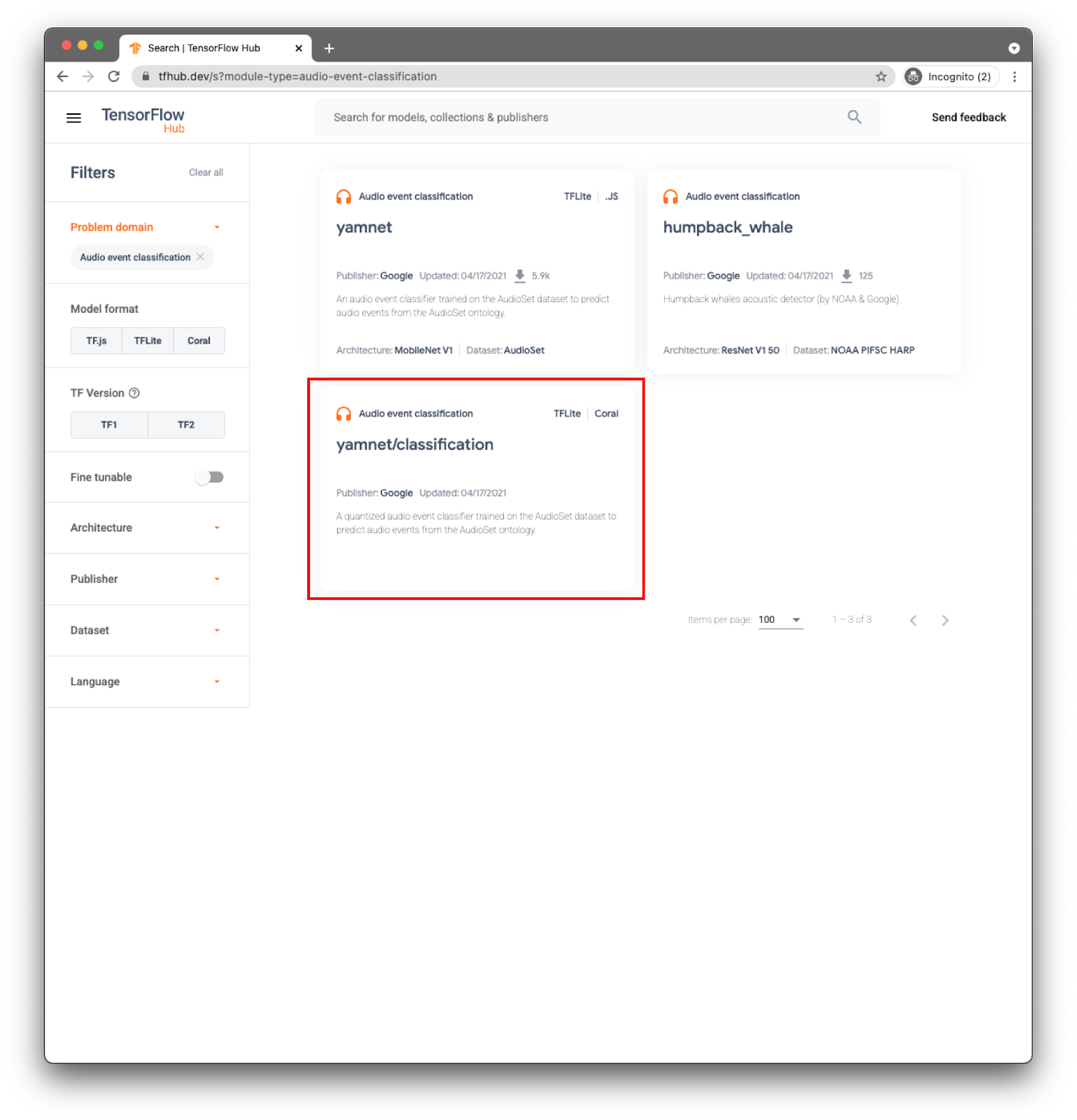
Choose the right tab: TFLite (yamnet/classification/tflite), and click Download. You can also see the model's metadata at the bottom.
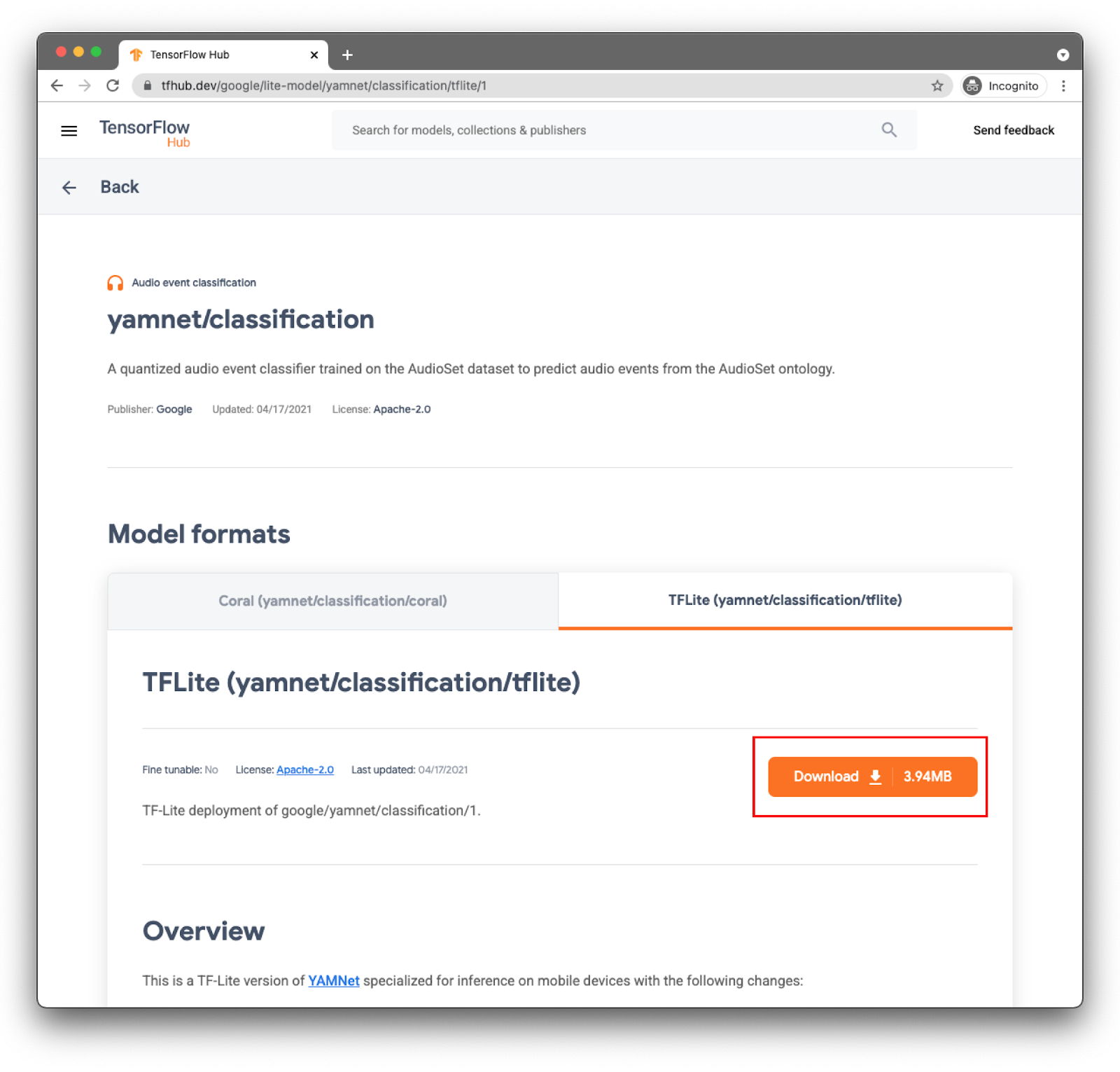
This model file (lite-model_yamnet_classification_tflite_1.tflite) will be used in the next step.
4. Import the new model to the base app
The first step is to move the downloaded model from the previous step to the assets folder in your app.
In Android Studio, in the project explorer, right-click the assets folder.
You'll see a popup with a list of options. One of these will be to open the folder in your file system. On a Mac this will be Reveal in Finder, on Windows it will be Open in Explorer, and on Ubuntu it will be Show in Files. Find the appropriate one for your operating system and select it.

Then copy the downloaded model into it.
Once you've done this, go back to Android Studio, and you should see your file within the assets folder.

5. Load the new model on the base app
Now you'll follow some of the TODOs and enable audio classification with the model you have just added to the project in the previous step.
To make it easy to find the TODOs, in Android Studio, go into the menu: View > Tool Windows > TODO. It will open a window with the list, and you can just click it to go straight to the code.
In the file build.gradle (the module version) you will find the first task.
TODO 1 is to add the Android dependencies:
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.2.0'
All the rest of code changes are going to be on the MainActivity
TODO 2.1 creates the variable with the model's name to load on next steps.
var modelPath = "lite-model_yamnet_classification_tflite_1.tflite"
TODO 2.2 you'll define a minimum threshold to accept a prediction from the model. This variable will be used later.
var probabilityThreshold: Float = 0.3f
TODO 2.3 is where you'll load the model from the assets folder. The AudioClassifier class defined in the Audio Task Library is prepared to load the model and give you all the necessary methods to run inference and also to help create an Audio Recorder.
val classifier = AudioClassifier.createFromFile(this, modelPath)
6. Capture audio
The Audio Tasks API has some helper methods to help you create an audio recorder with the proper configuration that your model expects (eg: Sample Rate, Bitrate, number of channels). With this you don't need to find it by hand and also create configuration objects.
TODO 3.1: Create the tensor variable that will store the recording for inference and build the format specification for the recorder.
val tensor = classifier.createInputTensorAudio()
TODO 3.2: Show the audio recorder specs that were defined by the model's metadata in the previous step.
val format = classifier.requiredTensorAudioFormat
val recorderSpecs = "Number Of Channels: ${format.channels}\n" +
"Sample Rate: ${format.sampleRate}"
recorderSpecsTextView.text = recorderSpecs

TODO 3.3: Create the audio recorder and start recording.
val record = classifier.createAudioRecord()
record.startRecording()
As of now, your app is listening on your phone's microphone, but it's still not doing any inference. You'll address this in the next step.
7. Add the inference to your model
In this step you'll add the inference code to your app and show it on the screen. The code already has a timer thread that is executed every half a second, and that's where the inference will be run.
The parameters for the method scheduleAtFixedRate are how long it will wait to start execution and the time between successive task execution, in the code below every 500 milliseconds.
Timer().scheduleAtFixedRate(1, 500) {
...
}
TODO 4.1 Add the code to use the model. First load the recording into an audio tensor and than pass it to the classifier:
tensor.load(record)
val output = classifier.classify(tensor)
TODO 4.2 to have better inference results, you'll filter out any classification that has a very low probability. Here you'll use the variable created in a previous step (probabilityThreshold):
val filteredModelOutput = output[0].categories.filter {
it.score > probabilityThreshold
}
TODO 4.3: To make reading the result easier, let's create a String with the filtered results:
val outputStr = filteredModelOutput.sortedBy { -it.score }
.joinToString(separator = "\n") { "${it.label} -> ${it.score} " }
TODO 4.4 Update the UI. In this very simple app, the result is just shown in a TextView. Since the classification is not on the Main Thread, you'll need to use a handler to make this update.
runOnUiThread {
textView.text = outputStr
}
You've added all the code necessary to:
- Load the model from the assets folder
- Create an audio recorder with the correct configuration
- Running inference
- Show the best results on the screen
All that's needed now is testing the app.
8. Run the final app
You have integrated the audio classification model to the app, so let's test it.
Connect your Android device, and click Run (  ) in the Android Studio toolbar.
) in the Android Studio toolbar.
On the first execution, you will need to grant the app audio recording permissions.
After giving the permission, the app on start will use the phone's microphone. To test, start speaking near the phone since one of the classes that YAMNet detects is speech. Another class easy to test is finger snapping or clapping.
You can also try to detect a dog's barks, and many other possible events (521). For a full list you can check out their source code or you can also read the metadata with the labels file directly
9. Congratulations!
In this codelab, you learned how to find a pre-trained model for audio classification and deploy it to your mobile app using TensorFlow Lite. To learn more about TFLite, take a look at other TFLite samples.
What we've covered
- How to deploy a TensorFlow Lite model on an Android app.
- How to find and use models from TensorFlow Hub.
Next Steps
- Customize the model with your own data.
Learn More
- TensorFlow Lite documentation
- TensorFlow Lite Support Library
- TensorFlow Lite Task Library
- TensorFlow Hub documentation
- On-device Machine Learning with Google technologies