
1. Zanim zaczniesz
W ciągu minionej dekady aplikacje internetowe stały się coraz bardziej społecznościowe i interaktywne, a obsługa multimediów i komentarzy odbywa się w czasie rzeczywistym przez potencjalnie dziesiątki tysięcy osób nawet na umiarkowanie popularnej stronie.
Dzięki temu spamerzy mogli również nadużywać systemów tego typu i kojarzyć mniej ostre treści z artykułami, filmami i postami napisanymi przez innych, by zwiększyć ich widoczność.
Starsze metody wykrywania spamu, takie jak lista blokowanych słów, można łatwo pominąć. Nie są one zatem zaawansowane w przypadku zaawansowanych botów spamowych, które nieustannie ewoluują. W przyszłości możemy skorzystać z modeli systemów uczących się wytrenowanych pod kątem wykrywania spamu.
Tradycyjnie model systemu uczącego się do wstępnego filtrowania komentarzy działałby po stronie serwera, ale dzięki TensorFlow.js możesz teraz uruchamiać po stronie klienta modele systemów uczących się w przeglądarce za pomocą JavaScriptu. Aby zapobiec spamowaniu, zanim dotrze on do zaplecza, możesz zaoszczędzić na kosztach po stronie serwera.
Jak pewnie wiesz, systemy uczące się są obecnie bardzo popularne w całej branży, ale jak możesz wykorzystać możliwości tych funkcji jako programista stron internetowych?
Dzięki nim dowiesz się, jak stworzyć aplikację internetową – z pustego obszaru roboczego – która rozwiązuje prawdziwy problem spamu w komentarzach, wykorzystując przetwarzanie języka naturalnego (czyli rozumienie języka ludzkiego na komputerze). Wielu deweloperów napotka ten problem podczas pracy nad coraz większą liczbą popularnych aplikacji internetowych, które teraz znajdziesz. Dzięki nim dowiesz się, jak skutecznie rozwiązywać tego typu problemy.
Wymagania wstępne
To ćwiczenie dla programistów zostało opracowane dla programistów, którzy dopiero zaczynają korzystać z systemów uczących się i chcą rozpocząć korzystanie z wytrenowanych modeli za pomocą TensorFlow.js.
W tym module zakładamy znajomość HTML5, CSS i JavaScript.
Czego się nauczysz:
W ramach ćwiczenia:
- Dowiedz się, co to jest TensorFlow.js i jakie modele są dostępne w przypadku przetwarzania języka naturalnego.
- Utwórz prostą stronę HTML / CSS / JS dla fikcyjnego bloga wideo z sekcją komentarzy w czasie rzeczywistym.
- Użyj TensorFlow.js, aby wczytać wytrenowany model systemów uczących się, który jest w stanie przewidzieć, czy dane zdanie może zawierać spam. Jeśli tak jest, poinformuj użytkownika, że komentarz został wstrzymany do moderacji.
- Koduj komentarze w sposób, który może wykorzystać model systemów uczących się do sklasyfikowania.
- Zinterpretuj dane wyjściowe modelu systemów uczących się, aby zdecydować, czy chcesz automatycznie zgłaszać komentarz. Te hipotetyczne UX można wykorzystać w każdej witrynie, nad którą pracujesz, i dostosować je do każdego przypadku użycia klienta – może to być zwykły blog, forum lub inny rodzaj systemu CMS, np. Drupal.
Ładnie. Czy trudno jest to zrobić? Nie. No to zaczynamy hakować...
Czego potrzebujesz
- Zalecamy korzystanie z konta Glitch.com. Możesz też użyć środowiska wyświetlania reklam, które możesz edytować i uruchamiać samodzielnie.
2. Co to jest TensorFlow.js?

TensorFlow.js to biblioteka systemów uczących się typu open source, która może działać w każdym języku JavaScript. Opiera się on na oryginalnej bibliotece TensorFlow napisanej w Pythonie i ma na celu odtworzenie tego doświadczenia dla deweloperów oraz zestawu interfejsów API dla ekosystemu JavaScript.
Gdzie można z niej korzystać?
Dzięki temu, że JavaScript jest łatwy do przenoszenia, możesz pisać w 1 języku i w łatwy sposób przeprowadzać systemy uczące się na wszystkich tych platformach:
- Po stronie klienta w przeglądarce za pomocą waniliowego kodu JavaScript
- Po stronie serwera, a nawet urządzenia IoT, takie jak Raspberry Pi, używając Node.js
- aplikacje komputerowe,
- natywne aplikacje mobilne korzystające z reklam natywnych React;
TensorFlow.js obsługuje też wiele backendów w każdym z tych środowisk (rzeczywistych środowiskach opartych na sprzęcie, takich jak procesor lub WebGL). &Backend" w tym kontekście nie oznacza po stronie serwera – backend do wykonywania może być na przykład po stronie klienta w WebGL, aby zapewnić zgodność i nie przerywać działania. Obecnie TensorFlow.js obsługuje:
- Uruchamianie WebGL na karcie graficznej urządzenia – jest to najszybszy sposób wykonywania większych modeli (o rozmiarze przekraczającym 3 MB) z akceleracją GPU.
- wykonanie zestawu sieciowego (WASM) na procesorze – aby poprawić wydajność procesora na różnych urządzeniach, np. na starszych telefonach komórkowych. Ta metoda sprawdza się lepiej w przypadku mniejszych modeli (mniej niż 3 MB), które mogą działać szybciej na procesorach WASM niż ze względu na koszty przesyłania treści do procesora graficznego.
- Wykonanie procesora – kreacja zastępcza nie powinna być dostępna w żadnym z innych środowisk. To jest najwolniejszy z 3 elementów, ale zawsze możesz się nim zająć.
Uwaga: możesz wymusić jeden z tych backendów, jeśli wiesz, na którym urządzeniu będziesz wykonywać zadania, albo pozwolić, aby kod TensorFlow.js za Ciebie określił te instrukcje.
Superfunkcje po stronie klienta
Uruchomienie kodu TensorFlow.js w przeglądarce na komputerze klienckim może przynieść kilka korzyści, które warto rozważyć.
Prywatność
Możesz trenować i klasyfikować dane na komputerze klienckim bez konieczności wysyłania danych na serwer WWW innej firmy. W niektórych przypadkach może to być wymagane, aby zachować zgodność z przepisami obowiązującymi w danym kraju, takimi jak RODO, lub podczas przetwarzania danych, które użytkownik chce zachować na swoim komputerze i nie wysyła do innej firmy.
Szybkość
Nie trzeba wysyłać danych na serwer zdalny, więc proces klasyfikowania danych (czyli klasyfikowania danych) może być szybsze. Co więcej, jeśli użytkownik przyzna Ci do niego dostęp, będziesz mieć bezpośredni dostęp do czujników urządzenia, takich jak aparat, mikrofon, GPS, akcelerometr.
Zasięg i skala
Wystarczy jedno kliknięcie, by wysłać link, otworzyć stronę internetową w przeglądarce i wykorzystać każdy utworzony przez siebie produkt. Zastosowanie systemu uczącego się nie wymaga skomplikowanej konfiguracji systemu Linux po stronie serwera ze sterownikami CUDA.
Koszt
Brak serwerów oznacza, że musisz tylko zapłacić za host CDN z plikami HTML, CSS, JS i modelami. Sieć CDN jest znacznie tańsza niż utrzymywanie serwera (nawet z dołączoną kartą graficzną) przez całą dobę.
Funkcje po stronie serwera
Wykorzystanie TensorFlow.js implementacji TensorFlow.js umożliwia korzystanie z poniższych funkcji.
Pełna obsługa CUDA
Jeśli chcesz przyspieszać karty graficzne po stronie serwera, musisz zainstalować sterowniki NVIDIA CUDA, aby umożliwić TensorFlow działanie z kartą graficzną (inaczej niż w przeglądarce, która używa WebGL – nie wymaga to instalacji). Jednak pełna obsługa CUDA pozwala w pełni wykorzystać możliwości karty graficznej niższego poziomu, co pozwala skrócić czas trenowania i wnioskowania. Wydajność jest zgodna z implementacją Pythona TensorFlow, ponieważ używają one tego samego backendu C++.
Rozmiar modelu
Jeśli chcesz przeprowadzić najnowocześniejsze modele z badań, być może pracujesz z bardzo dużymi modelami, na przykład gigabajtami. Obecnie nie można uruchomić tych modeli w przeglądarce z powodu ograniczeń związanych z wykorzystaniem pamięci przez poszczególne karty przeglądarki. Aby uruchomić większe modele, możesz użyć Node.js na własnym serwerze wraz ze specyfikacjami sprzętowymi, które są niezbędne do skutecznego działania tego modelu.
IOT
Node.js jest obsługiwany na popularnych komputerach z pojedynczym układem, takich jak Raspberry Pi, co oznacza, że na tych urządzeniach możesz też wykonywać modele TensorFlow.js.
Szybkość
Kod w Node.js jest napisany w języku JavaScript, co oznacza, że korzystnie odniesie się on do kompilacji w czasie. Oznacza to, że podczas korzystania z Node.js możesz często zauważyć wzrost wydajności, ponieważ zostanie on zoptymalizowany w czasie działania, zwłaszcza w przypadku wykonywanych w trakcie wstępnego przetwarzania danych. Świetnym przykładem takiego działania jest studium przypadku, które pokazuje, jak Hugging Face wykorzystał Node.js do dwukrotnego zwiększenia wydajności swojego modelu przetwarzania języka naturalnego.
Znasz już podstawy działania TensorFlow.js i wiesz, gdzie może ono działać, a niektóre korzyści płyną z tego, że możemy zacząć wykonywać przydatne zadania.
3. Wytrenowane modele
Dlaczego warto używać już wytrenowanego modelu?
Rozpoczęcie od popularnego już wytrenowanego modelu ma wiele zalet, jeśli pasuje do danego przypadku użycia:
- Nie musisz samodzielnie zbierać danych szkoleniowych. Przygotowanie danych w odpowiednim formacie i oznaczenie ich etykietami, tak by system uczące się mógł z nich korzystać, może być bardzo czasochłonne i kosztowne.
- Możliwość szybkiego prototypowania pomysłu przy niższych kosztach i czasie.
Nie ma nic szczególnego na tym, by lepiej analizować możliwości koła. Kiedy model wytrenowany może wystarczyć do zrobienia tego, czego potrzebujesz, możesz się więc skupić na wykorzystywaniu wiedzy uzyskanej przez model do wdrożenia swoich pomysłów. - Korzystanie z najnowocześniejszych badań. Wytrenowane modele są często oparte na popularnych badaniach, dzięki czemu masz dostęp do takich modeli, a jednocześnie badasz ich skuteczność w praktyce.
- Łatwość obsługi i bogata dokumentacja. Ze względu na popularność takich modeli.
- Przenoszenie możliwości nauki . Niektóre wytrenowane modele oferują możliwości systemów uczących się, które są zasadniczo praktyką przenoszenia informacji z jednego zadania systemów uczących się do drugiego podobnego przykładu. Model, który pierwotnie trenowano w celu rozpoznawania kotów, można wytrenować w taki sposób, aby rozpoznawał psy, jeśli dzięki temu uzyskasz nowe dane treningowe. To potrwa krócej, bo nie zaczynasz od pustego obszaru roboczego. Model może wykorzystać zdobytą już wiedzę, aby rozpoznać koty, a potem nauczyć się czegoś nowego – psy mają oczy i uszy także przecież, więc jeśli już wie, jak znaleźć te cechy, jesteśmy w połowie drogi. Naucz się tego znacznie szybciej.
Wytrenowany model wykrywania spamu w komentarzach
W przypadku wykrywania spamu w komentarzach będziesz używać modelu Średnie osadzanie słów, ale jeśli będziesz używać nieprzeszkolonego modelu, nie ma szans na zgadnięcie, czy zdania są spamem, czy nie.
Aby model był przydatny, musisz go wytrenować z użyciem danych niestandardowych. W tym przypadku musi on nauczyć się, jak wyglądają komentarze bez spamu. Dzięki temu będziemy mieć większe szanse na poprawną klasyfikację obiektów.
Ktoś już przeszkolił tę architekturę modelu dla tego zadania klasyfikacji spamu, więc możesz zacząć to od niego. Możesz znaleźć inne wytrenowane modele wykorzystujące tę samą architekturę modeli do różnych działań, takich jak wykrywanie języka, w którym napisano komentarz, lub przewidywanie, czy dane formularza kontaktowego w witrynie mają być automatycznie kierowane do określonego zespołu w firmie automatycznie na podstawie tekstu, np. sprzedaży (zapytania o produkt), czy inżynierii (błąd techniczny lub opinie). Mając odpowiednią ilość danych treningowych, taki model może nauczyć się klasyfikowania takiego tekstu w każdym przypadku. W ten sposób zapewnisz aplikacji internetowej większe możliwości i zwiększy wydajność organizacji.
Z dalszego modułu modułu kodu dowiesz się, jak korzystać z Kreatora modeli, aby ponownie wytrenować ten model spamu, i zwiększyć jego skuteczność na podstawie danych pochodzących z komentarzy. Na początek użyjesz dotychczasowego modelu wykrywania spamu w komentarzach, aby zacząć korzystać z aplikacji internetowej jako pierwszego prototypu.
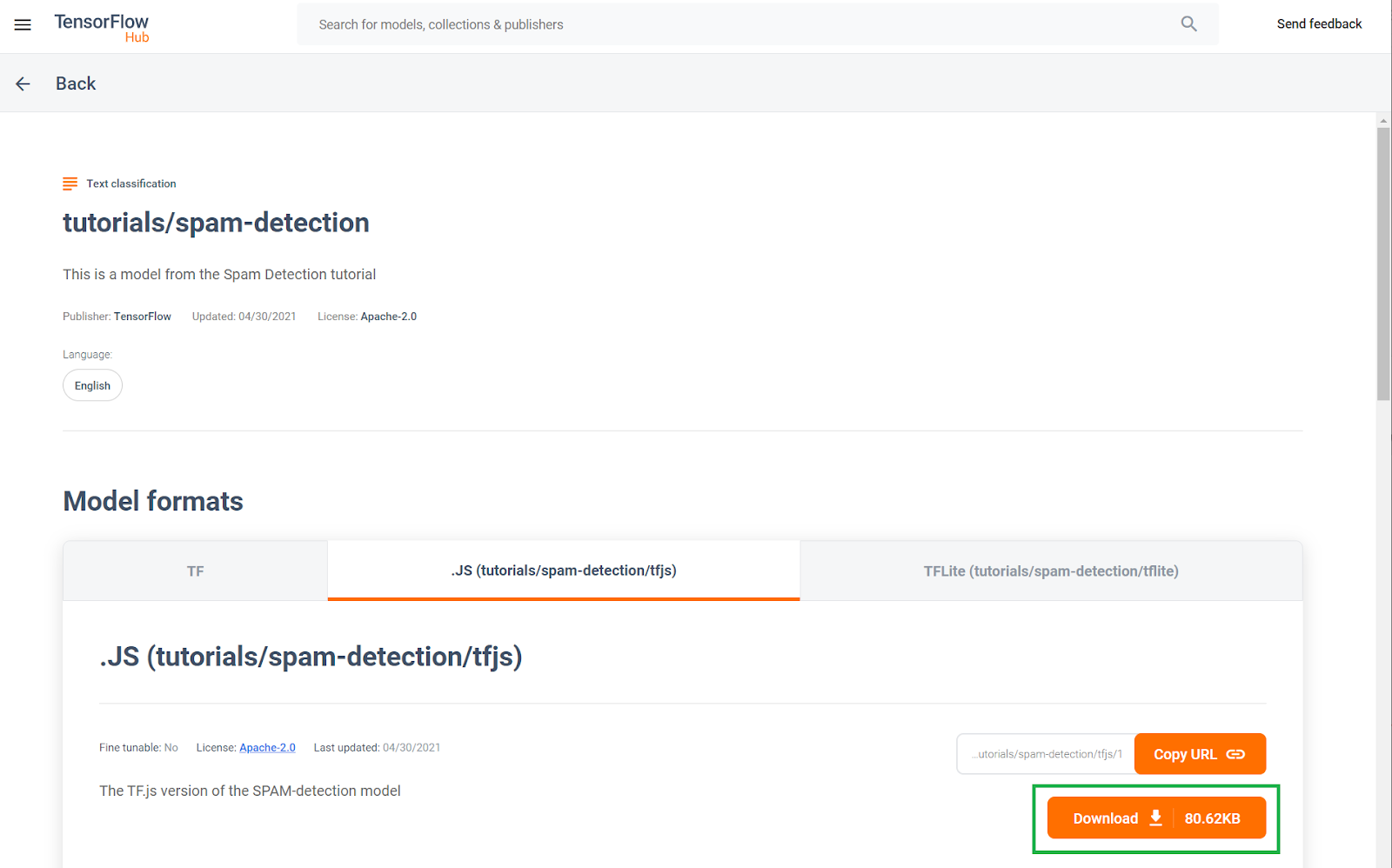
Ten wytrenowany model wykrywania spamu w komentarzach został opublikowany na stronie znanej jako TF Hub – repozytorium modeli systemów uczących się utrzymywane przez Google, gdzie programiści systemów uczących się mogą publikować swoje gotowe modele do wielu typowych zastosowań (np. teksty, wizje, dźwięki itp.) do różnych przypadków użycia w każdej z tych kategorii. Teraz pobierz pliki modeli, aby wykorzystać je w aplikacji internetowej w dalszej części tego ćwiczenia z programowania.
Kliknij przycisk pobierania modelu JS, jak pokazano poniżej:
4. Przygotowanie do programowania
Czego potrzebujesz
- Nowoczesna przeglądarka.
- Podstawowa wiedza o HTML, CSS, JavaScript i Narzędziach deweloperskich w Chrome (wyświetlanie wyników w konsoli).
Czas na kodowanie.
Opracowaliśmy szablon Glitch.com Node.js Express boilerplate, od którego możesz rozpocząć kopiowanie, wykonując podstawowy test w formie podstawowego modułu.
W Glitch kliknij przycisk "remix this, aby utworzyć rozwidlenie i utworzyć nowy zestaw plików, które możesz edytować.
Ten prosty szkielet dostarcza nam następujące pliki w folderze www:
- Strona HTML (index.html)
- Arkusz stylów (style.css)
- Plik do zapisu kodu JavaScript (script.js)
Dla ułatwienia dodaliśmy do pliku HTML import z biblioteki TensorFlow.js, który wygląda tak:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Następnie udostępniamy ten folder www przez prosty serwer Node Express obsługiwany przez package.json i server.js.
5. Podstawowy kod HTML aplikacji
Od czego zaczynasz?
Wszystkie prototypy wymagają pewnych podstawowych rusztowań HTML, na których można renderować wyniki. Skonfiguruj teraz. Dodasz:
- Tytuł strony.
- Tekst opisu
- Film zastępczy pokazujący wpis w blogu wideo
- Obszar, w którym można wyświetlać i pisać komentarze
Otwórz index.html i wklej ten kod w polu poniżej, aby skonfigurować funkcje powyżej:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Podział
Podzielmy część powyższego kodu HTML i wyróżnimy najważniejsze dodane przez Ciebie elementy.
- Dodano tag
<h1>dla tytułu strony oraz tag<a>przycisku logowania, które są zawarte w tagu<header>. Następnie dodajesz tytuł<h2>dla tytułu artykułu oraz tag<p>do opisu filmu. Nic specjalnego. - Dodano tag
iframe, który zawiera dowolny film z YouTube. Na razie używasz potężnego rapu TensorFlow.js jako symbolu zastępczego, ale możesz umieścić tu dowolny film, zmieniając URL elementu iframe. W przypadku witryny produkcyjnej wszystkie te wartości są renderowane przez backend dynamicznie w zależności od wyświetlanej strony. - Na koniec dodano atrybut
sectionz identyfikatorem i klasą "comments" zawierający zawartość, którą można edytować (div), a także opcjębutton, która umożliwia przesłanie nowego komentarza, który chcesz dodać, oraz nieuporządkowaną listę komentarzy. Podaj nazwę użytkownika i czas publikacji w taguspanw poszczególnych elementach listy, a potem komentarz w tagup. Dwa przykładowe komentarze są na stałe zakodowane jako zastępcze.
Jeśli teraz wyświetlisz podgląd wyników, powinien wyglądać mniej więcej tak:
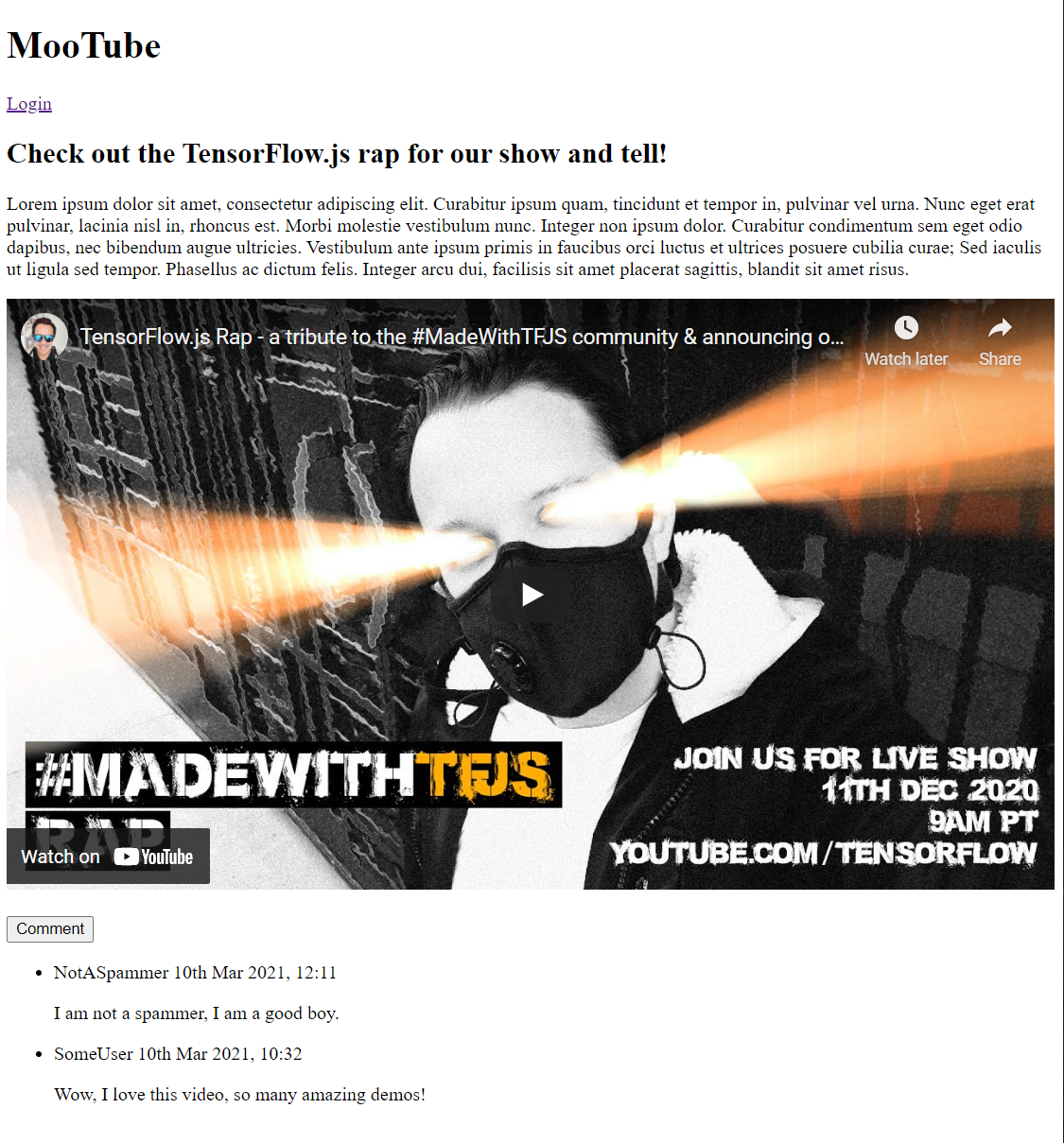
Wygląda to okropnie, więc czas dodać styl...
6. Dodaj styl
Wartości domyślne elementu
Najpierw dodaj style do dodanych przed chwilą elementów HTML, aby mieć pewność, że będą się prawidłowo renderować.
Zacznij od zastosowania przywracania CSS, by dodać punkt początkowy do wszystkich przeglądarek i systemów operacyjnych. Zastąp treść style.css tymi wartościami:
styl.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
Następnie dołącz do tego przydatnego kodu CSS, aby ożywić interfejs użytkownika.
Na końcu tego adresu (style.css) dodaj dodany poniżej kod CSS:
styl.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Świetnie. To wszystko. Jeśli udało Ci się zastąpić style przy użyciu 2 powyższych fragmentów kodu, podgląd na żywo powinien wyglądać tak:
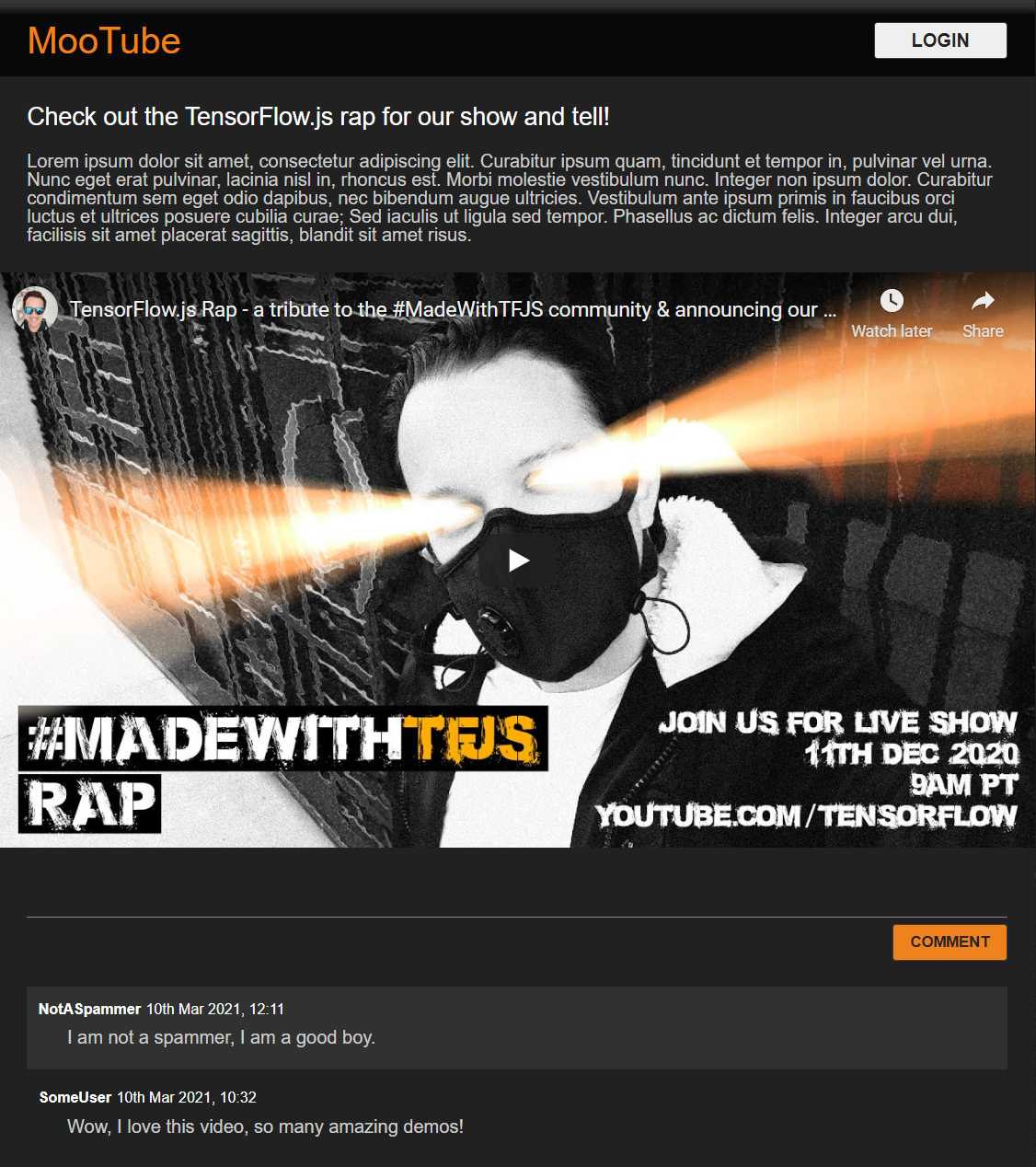
Słodkie tryby nocne i klimatyczne przejścia CSS wpływające na efekty najeżdżania kursorem na kluczowe elementy. Dobrze Ci idzie! Teraz przeprowadzimy integrację logiczną behawioralną za pomocą JavaScriptu.
7. JavaScript: manipulacja modelu DOM oraz moduły obsługi zdarzeń
Odwoływanie się do kluczowych elementów DOM
Najpierw upewnij się, że masz dostęp do kluczowych części strony, w przypadku których chcesz później manipulować lub uzyskiwać do nich dostęp, a także definiować pewne stałe klasy CSS dotyczące stylu.
Najpierw zastąp zawartość zmiennej script.js tymi wartościami:
skrypt.js.
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Postępowanie z komentarzami
Następnie dodaj detektor i obsługę zdarzeń do obiektu POST_COMMENT_BTN, by móc pobierać tekst komentarza i ustawiać klasę CSS wskazującą, że przetwarzanie zostało rozpoczęte. Sprawdź, czy nie został jeszcze kliknięty przycisk na wypadek, gdyby proces już był przetwarzany.
script.js,
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Świetnie. Gdy odświeżysz stronę i spróbujesz opublikować komentarz, przycisk komentarza i tekst zmienią kolor na szary, a w konsoli powinien się pojawić następujący komentarz:
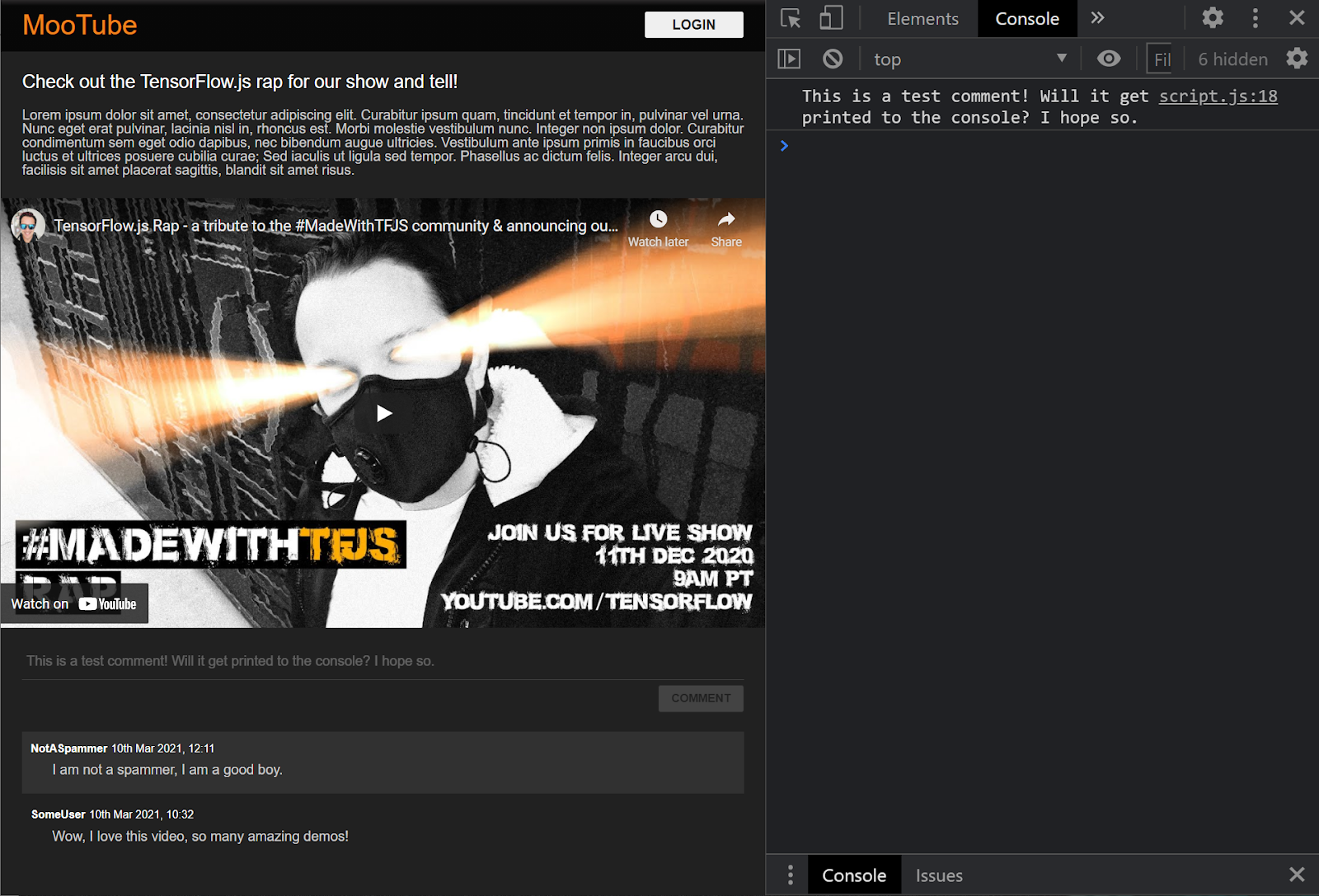
Gdy już masz podstawowy szkielet HTML / CSS / JS, czas wrócić do modelu systemów uczących się, by zintegrować go z piękną stroną internetową.
8. Zapewnij model systemów uczących się
Prawie gotowe do wczytania modelu. Aby to zrobić, musisz najpierw przesłać do witryny pliki modeli pobranych wcześniej w ramach ćwiczeń z programowania, aby można było je hostować i używać w kodzie.
Najpierw rozpakuj pobrane pliki z modelem na początku tych ćwiczeń z programowania. Powinien wyświetlić się katalog z tymi plikami:
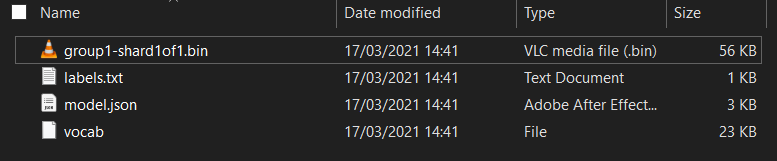
Co tu masz?
model.json– jeden z plików tworzących wytrenowany model TensorFlow.js. W przyszłości będziesz odwoływać się do tego konkretnego pliku w swoim kodzie TensorFlow.js.group1-shard1of1.bin– jest to plik binarny zawierający wytrenowane wagi (zasadniczo wiele z nich, które dobrze radziły sobie z klasyfikacją) modelu TensorFlow.js i trzeba go umieścić na serwerze w celu pobrania.vocab– ten dziwny plik bez rozszerzeń to plik z Kreatora modeli, który pokazuje, jak kodować słowa w zdaniach, aby model wiedział, jak ich używać. Więcej informacji na ten temat znajdziesz w następnej sekcji.labels.txt– zawiera tylko ostateczne nazwy klas, które model ma przewidzieć. Jeśli ten model zostanie otwarty w edytorze tekstu, to ma on w swoich wynikach prognozy.
Hostowanie plików modelu TensorFlow.js
Najpierw umieść model.json i pliki *.bin wygenerowane na serwerze WWW, aby były dostępne na stronie internetowej.
Przesyłanie plików do Glitch
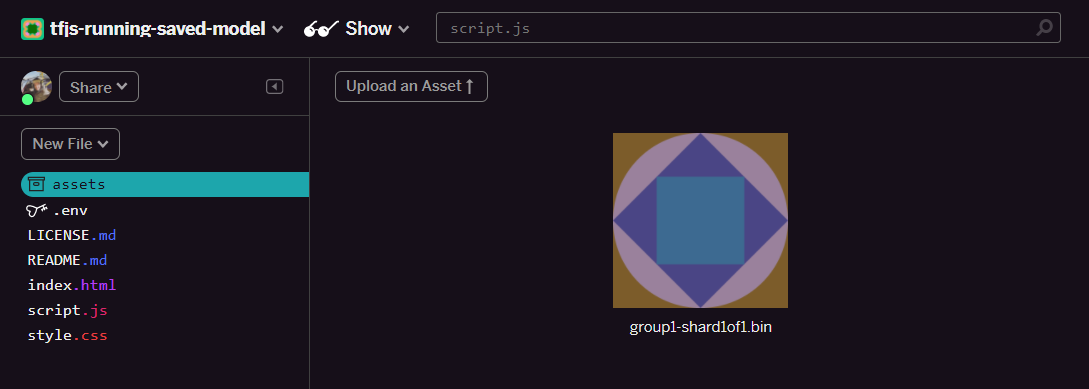
- Kliknij folder assets (zasoby) w panelu po lewej stronie projektu w Glitch.
- Kliknij prześlij zasób i wybierz
group1-shard1of1.bin, aby umieścić go w tym folderze. Po przesłaniu powinien wyglądać tak:
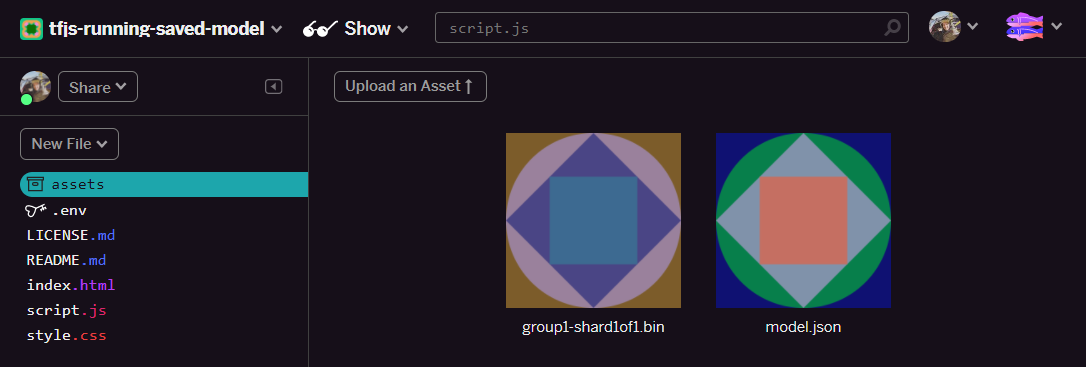
- Świetnie. To samo zrób w przypadku pliku
model.json. W folderze assets powinny znajdować się 2 pliki:
- Kliknij nowo przesłany plik
group1-shard1of1.bin. Możesz skopiować adres URL do jego lokalizacji. Skopiuj tę ścieżkę teraz, jak pokazano:
- W lewym dolnym rogu ekranu kliknij Narzędzia > Terminal. Poczekaj na wczytanie okna terminala. Po wczytaniu wpisz następujący tekst, a następnie naciśnij klawisz Enter, aby zmienić katalog na folder
www:
terminal:
cd www
- Następnie użyj
wget, by pobrać 2 przesłane pliki, zastępując adresy URL poniżej adresami wygenerowanymi dla plików w folderze assets w Glitch (sprawdź folder zasobów w przypadku każdego niestandardowego adresu URL). Zwróć uwagę, że odstęp między dwoma adresami URL i te, których musisz użyć, będą różne niż poniższe, ale będą wyglądać mniej więcej tak:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super, teraz masz kopię plików przesłanych do folderu www, ale teraz są pobierane z dziwnymi nazwami.
- Wpisz w terminalu
lsi naciśnij Enter. Zobaczysz coś takiego:

- Przy użyciu polecenia
mvmożesz zmienić nazwy plików. Wpisz w konsoli następujące polecenie i naciśnij <kbd>Enter</kbd> lub <kbd>return</kbd>, po każdym wierszu:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Odśwież projekt Glitch, wpisując w terminalu
refreshi naciskając <kbd>Enter</kbd>:
terminal:
refresh
- Po odświeżeniu w interfejsie użytkownika powinny pojawić się
model.jsonigroup1-shard1of1.binw folderzewww:
Świetnie. Teraz możesz już używać przesłanych plików modelu z prawdziwym kodem w przeglądarce.
9. Załaduj &&;użyj hostowanego modelu TensorFlow.js
Jesteś teraz w punkcie, w którym możesz przetestować wczytywanie przesłanego modelu TensorFlow.js z niektórymi danymi, by sprawdzić, czy działa.
W tej chwili przykładowe dane wejściowe, które zobaczysz poniżej, będą wyglądać nieco tajemniczo (tablica) i w jaki sposób zostały wygenerowane, wyjaśniamy w następnej sekcji. Na razie wyświetl go jako tablicę liczb. Na tym etapie ważne jest, aby sprawdzić, czy model przedstawia odpowiedź bez błędów.
Dodaj poniższy kod na końcu pliku script.js i pamiętaj o zastąpieniu wartości ciągu MODEL_JSON_URL ścieżką pliku model.json wygenerowanego podczas przesyłania pliku do folderu Zasoby w Glitch w poprzednim kroku. (aby znaleźć jego URL, wystarczy kliknąć plik w folderze assets w Glitch).
Przeczytaj komentarze do nowego kodu, aby dowiedzieć się, co robi każdy z tych wierszy:
script.js,
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Jeśli projekt jest prawidłowo skonfigurowany, w oknie konsoli powinien być widoczny komunikat podobny do tego:
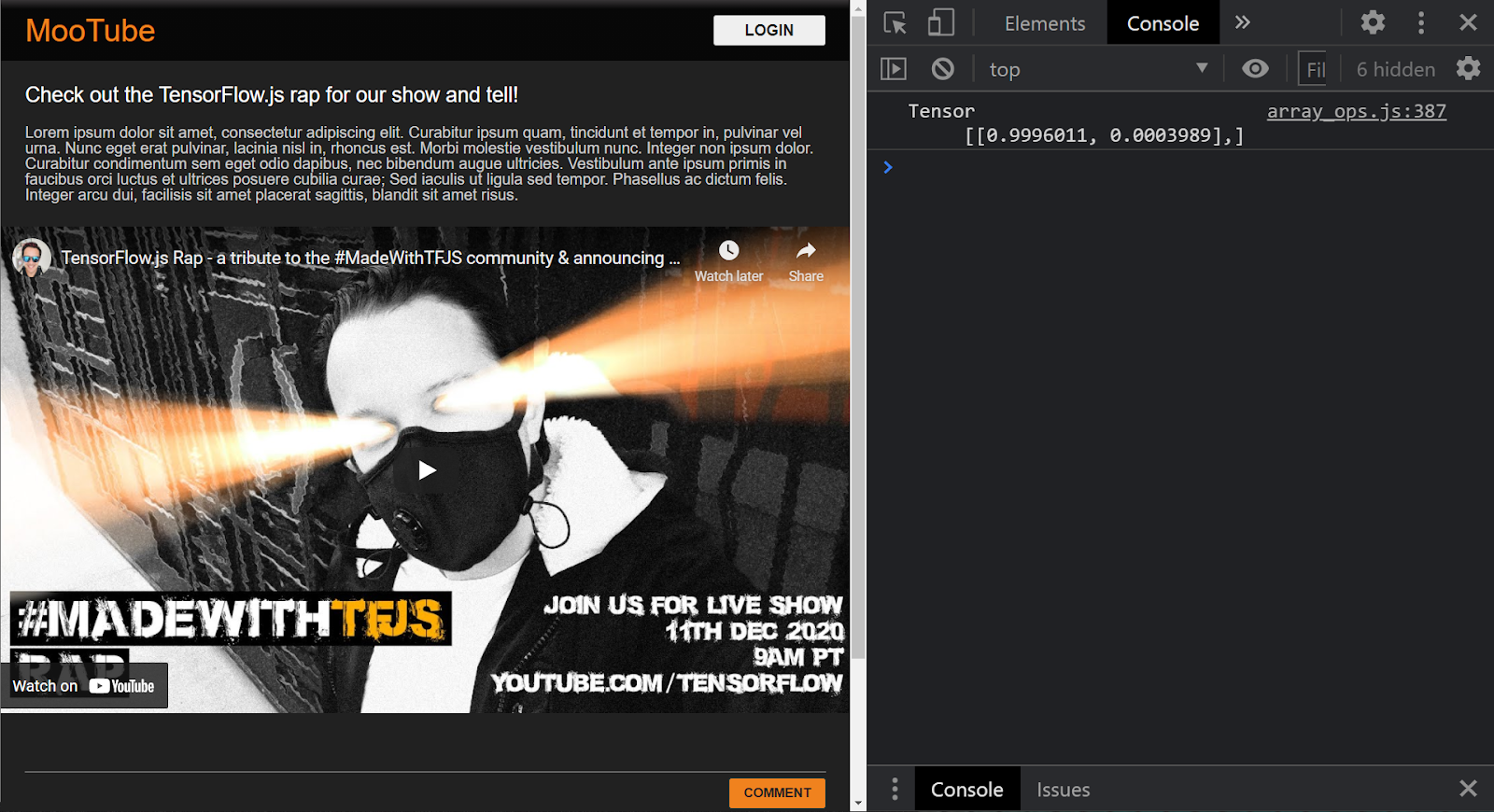
W konsoli zobaczysz 2 numery:
- 0,9996011
- 0,0003989
Choć może to wydawać się skomplikowane, wartości te odzwierciedlają prawdopodobieństwu klasyfikacji modelu dla danych wejściowych, które uznajesz za model. Ale co reprezentują?
Jeśli otworzysz plik labels.txt z pobranych plików modelu, które masz na komputerze lokalnym, zobaczysz, że zawiera on też 2 pola:
- Fałsz
- Prawda
Model ma w tym przypadku 99,96011% wartości (wyświetlany w obiekcie wyniku jako 0,9996011), że podane przez Ciebie dane (czyli [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] to NIE spam (tj. Fałsz).
Pamiętaj, że wartość false jest pierwszą etykietą w labels.txt i jest reprezentowana przez pierwsze dane wyjściowe w druku w konsoli. Dzięki temu wiesz, do czego służy dane wyjściowe prognozy.
Wiesz już, jak interpretować dane wyjściowe, ale jaka była duża liczba tych danych i jak przekonwertować zdania na ten format, by model mógł się na nich znaleźć? Aby to zrobić, trzeba poznać tokenizację i tensor. Czytaj dalej.
10. Tokenizacja & tensor
Tokenizacja
Okazało się więc, że modele systemów uczących się są w stanie zaakceptować tylko pewną liczbę liczb. Dlaczego? Zasadniczo wynika to z faktu, że model systemów uczących się to szereg łańcuchów operacji matematycznych. Jeśli więc podasz nam coś, co nie jest liczbą, trudno będzie Ci poradzić sobie z tym problemem. Pytanie o sposób przekształcania zdań w liczby do wykorzystania w ładowanym modelu?
Ten model różni się w zależności od modelu, ale w tym przypadku w pobranych plikach znajduje się jeszcze 1 plik o nazwie vocab,. To klucz procesu kodowania danych.
Otwórz plik vocab w lokalnym edytorze tekstu na komputerze, a zobaczysz coś podobnego:
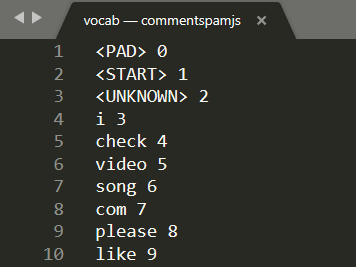
Zasadniczo jest to tabela przeglądowa pokazująca, jak przekonwertować znaczenie słów poznanych przez model na dane, które może zrozumieć. Istnieją również pewne szczególne przypadki na początku pliku <PAD>, <START> i <UNKNOWN>:
<PAD>– jest to krótka nazwa „"fill"”. Okazuje się, że modele systemów uczących się wymagają stałej liczby danych wejściowych, niezależnie od tego, jak długie jest zdanie. Używany model zakłada, że w danych wejściowych zawsze będzie 20 cyfr (jest on zdefiniowany przez twórcę modelu i można go zmienić, jeśli ponownie nauczysz model). Jeśli masz takie wyrażenie jak „" Lubię film&"”, wypełnij pozostałe spacje w tablicy znakiem 0', które reprezentują token<PAD>. Jeśli zdanie ma więcej niż 20 słów, musisz je podzielić, tak aby spełniało to wymaganie, i użyć wielu klasyfikacji w wielu mniejszych zdaniach.<START>– to zawsze pierwszy token wskazujący początek zdania. W przykładowych danych wejściowych w poprzednich krokach tablica cyfr zaczynała się od &&tt;1" oznaczała token<START>.<UNKNOWN>– jak można się domyślić, jeśli słowo nie istnieje w wyszukiwaniu, wystarczy użyć tokena<UNKNOWN>(reprezentowanego przez „"2"”).
Każde inne słowo występuje w wyszukiwaniu i jest powiązane ze specjalnym numerem, więc użyjesz go lub nie istnieje. W takim przypadku użyjesz numeru tokena <UNKNOWN>.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Jak widać, powinno to być zdanie składające się z 4 słów, a pozostałe to tokeny <START> lub <PAD>. W tablicy znajduje się 20 cyfr. OK, zaczynam wydawać więcej.
W tym zdaniu napisałem „Kocham mojego psa”. Jak widać na zrzucie ekranu powyżej, numer „I"” jest zamieniany na prawidłową liczbę „3”. Jeśli wyszukasz inne słowa, też pojawią się odpowiadające im liczby.
Tensory
Zanim model ML zaakceptuje wpisane dane, musi zostać jeszcze jedna przeszkoda. Trzeba przekonwertować tablicę liczb na coś zwany Tensor. I jak można się domyślić, TensorFlow nazywa się tak po części – przepływ Tensora przez model.
Co to jest Tensor?
Oficjalna definicja z TensorFlow.org brzmi:
&squo;Tensor to tablice wielowymiarowe o jednolitym typie. Wszystkie tensory są stałe: nie można aktualizować zawartości tensora, należy utworzyć nowy.
Jest to po prostu wyrafinowana nazwa matematyczna tablicy dowolnego wymiaru, która zawiera inne funkcje wbudowane w obiekty Tensora i przydatne dla nas jako programistów systemów uczących się. Należy jednak pamiętać, że w Tensors przechowywane są dane tylko 1 typu, np. wszystkie liczby całkowite lub wszystkie liczby zmiennoprzecinkowe, a utworzonego tensora nie można zmienić. Zawartość można więc traktować jako stałe pudełko liczbowe dla liczb.
Na razie nie martw się za bardzo. Najlepiej, aby był to wielowymiarowy mechanizm przechowywania danych, z którego korzystają modele systemów uczących się, dopóki nie zagłębisz się w dobrą książkę taką jak ta. Warto się z nimi zapoznać, jeśli chcesz dowiedzieć się więcej o Tensorach i o tym, jak ich używać.
Połącz wszystko: tensory i tokenizacja
Jak więc użyć tego pliku vocab w kodzie? To świetne pytanie.
Ten plik jest dla Ciebie jako programisty JS raczej nieprzydatny. Znacznie lepiej byłoby, gdyby był to obiekt JavaScript, który można po prostu zaimportować i zastosować. Można łatwo sprawdzić, jak można łatwo przekonwertować dane w tym pliku na taki format:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
Korzystając z ulubionego edytora tekstu, możesz łatwo przekształcić plik vocab na taki, który ma znaleźć i zastąpić. Aby to ułatwić, możesz też użyć tego narzędzia.
Jeśli wykonasz te czynności z wyprzedzeniem i zapiszesz plik vocab w odpowiednim formacie, nie będzie trzeba wykonywać tej konwersji i analizować go podczas każdego wczytywania strony, co zmarnuje zasoby procesora. Co więcej, obiekty JavaScript mają te właściwości:
"Nazwa właściwości obiektu może być dowolnym prawidłowym ciągiem znaków JavaScript lub dowolnym ciągiem, który może zostać przekonwertowany na ciąg znaków, w tym pustym ciągiem znaków. Dostęp do nazwy właściwości, która nie jest prawidłowym identyfikatorem JavaScript (na przykład nazwę usługi zawierającą spację, łącznik lub nazwę rozpoczynającą się od cyfry), jest dostępna tylko w zapisie w nawiasie kwadratowym.
Tak długo, jak użyjesz zapisu w nawiasie kwadratowym, możesz utworzyć prostą tabelę przeglądową, wykorzystując tę prostą przekształcenie.
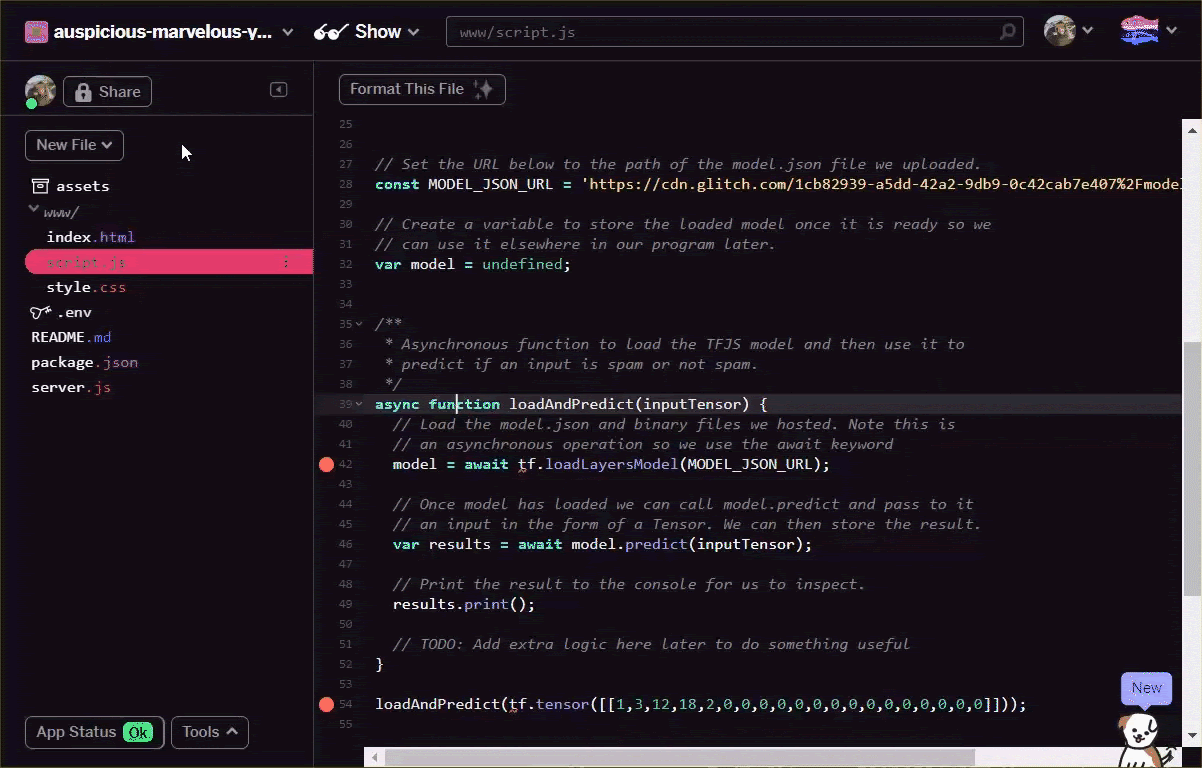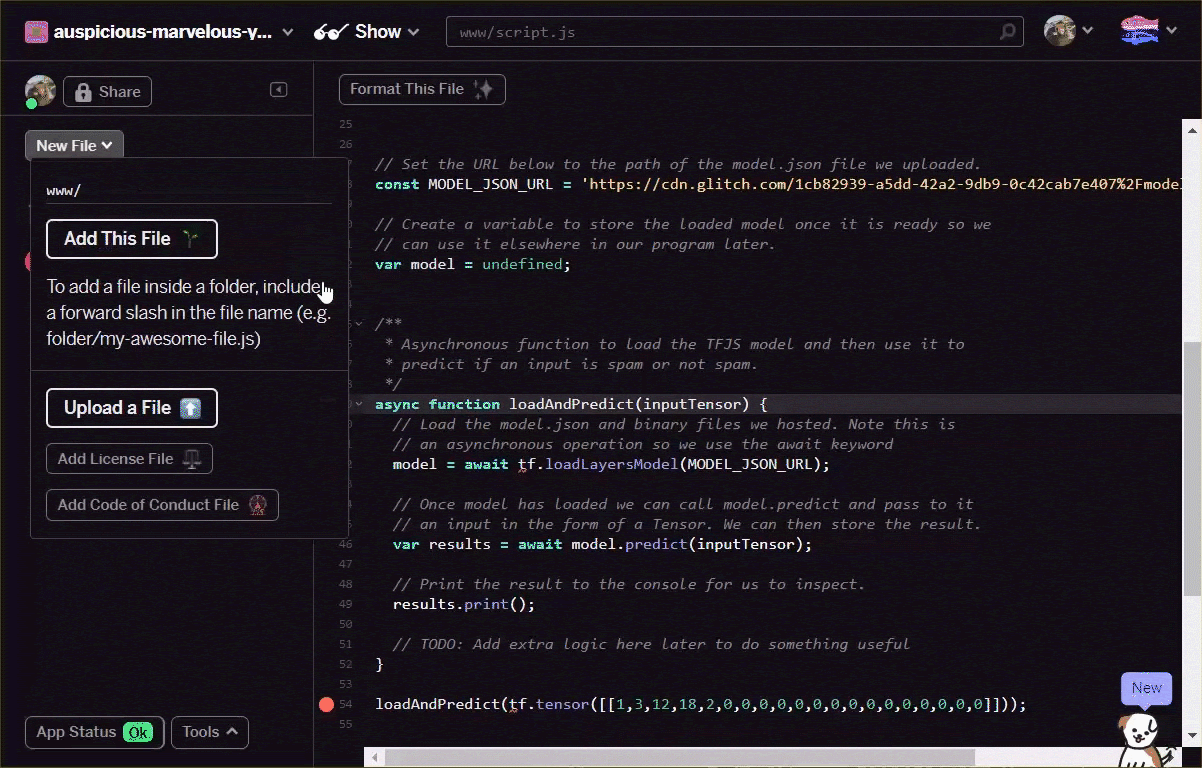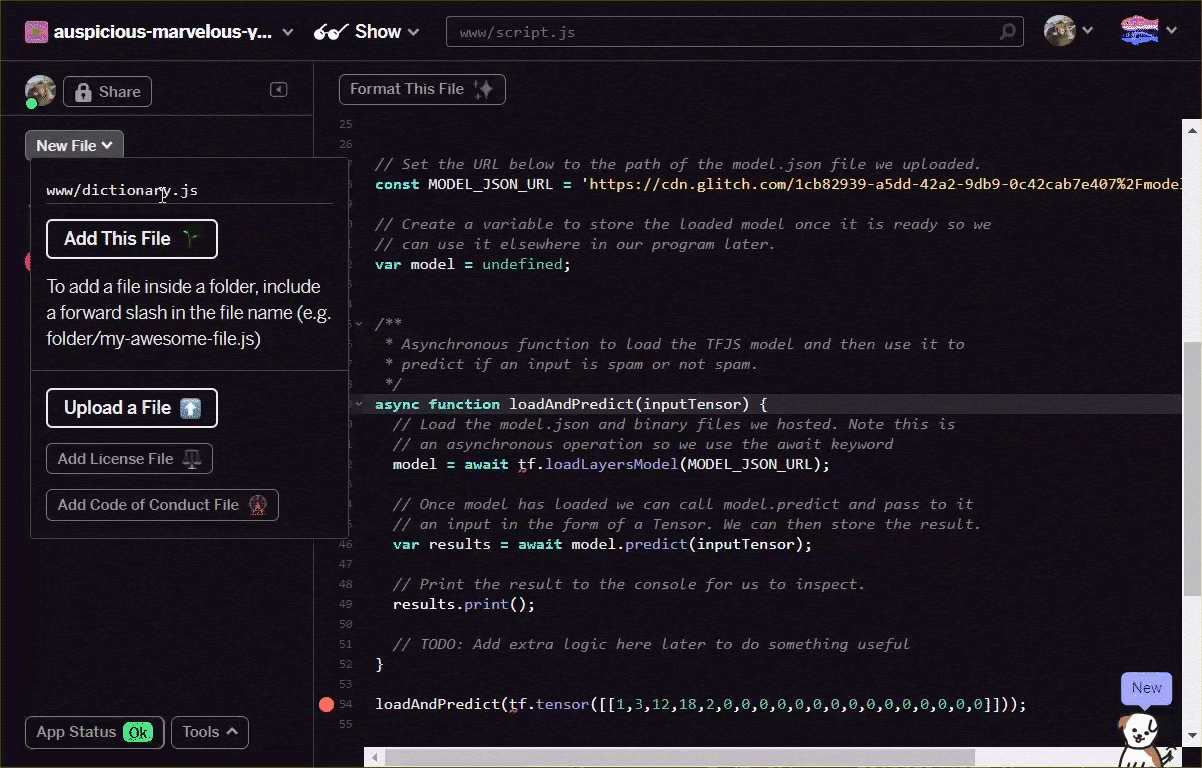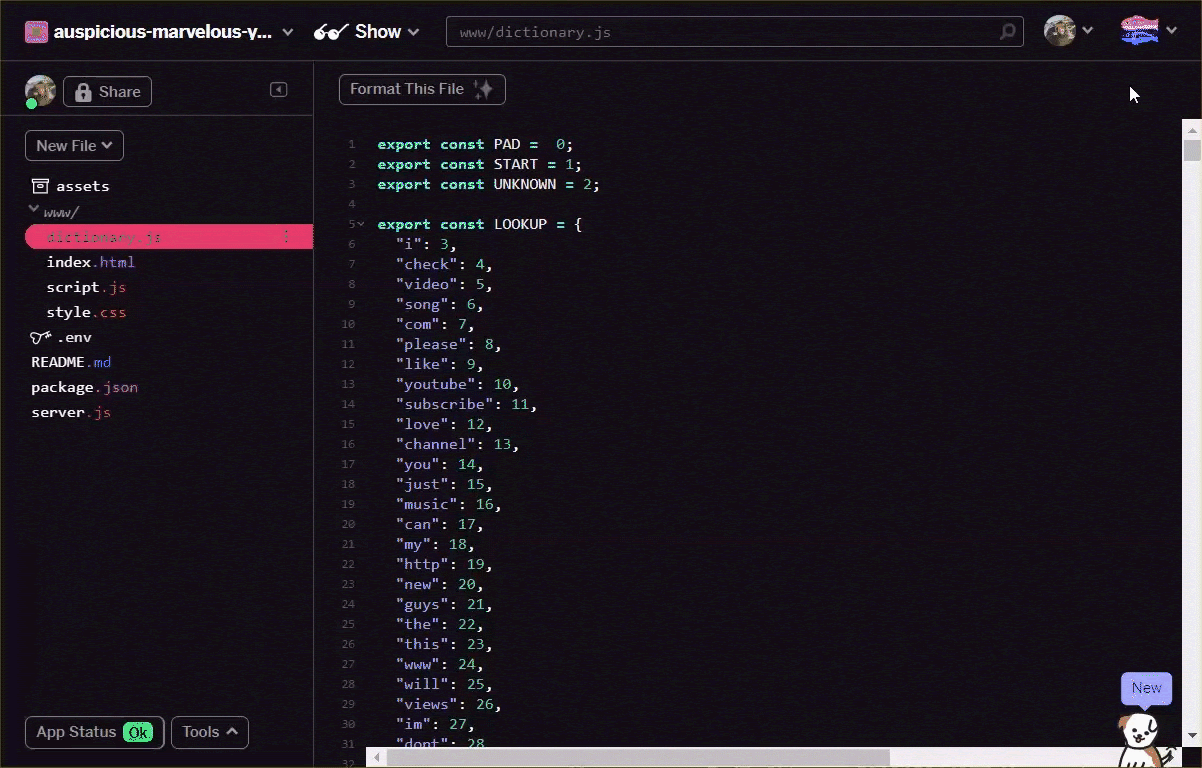
Konwertowanie na bardziej użyteczny format
Przekonwertuj plik pojęciowy na powyższy format, ręcznie w edytorze tekstu lub za pomocą tego narzędzia. Zapisz uzyskane dane wyjściowe w formacie dictionary.js w folderze www.
W Glitch wystarczy utworzyć nowy plik w tej lokalizacji i wkleić wynik konwersji, aby zapisać go w następujący sposób:
Po zapisaniu pliku dictionary.js w formacie opisanym powyżej możesz dodać ten kod na górze strony (script.js), by zaimportować nowo utworzony moduł dictionary.js. W tym miejscu definiujesz również dodatkową stałą ENCODING_LENGTH, aby wiedzieć, jak długo należy wstawić kod w późniejszym fragmencie, oraz funkcję tokenize, która posłuży do przekonwertowania tablicy słów na odpowiedni Tensor, który może służyć jako dane wejściowe modelu.
Zapoznaj się z komentarzami w poniższym kodzie, aby dowiedzieć się więcej o możliwościach poszczególnych wierszy:
script.js,
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Świetnie, wróć do funkcji handleCommentPost() i zastąp ją nową wersją.
Kod do dodawania komentarzy do dodanego materiału:
script.js,
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Na koniec zaktualizuj funkcję loadAndPredict(), by ustawić styl w przypadku wykrycia komentarza jako spamu.
Na razie wystarczy zmienić styl, ale później możesz wstrzymać komentarz lub wstrzymać jego wysyłanie.
script.js,
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Aktualizacje w czasie rzeczywistym: Node.js + Websockets
Teraz masz działający interfejs użytkownika do wykrywania spamu. Ostatnią łamigłówką jest użycie Node.js z niektórymi gniazdami protokołu webOS do komunikacji w czasie rzeczywistym i aktualizowania w czasie rzeczywistym wszelkich dodawanych komentarzy, które nie są spamem.
Socket.io
Socket.io to najpopularniejszy (w momencie zapisu) sposób korzystania z gniazd sieciowych za pomocą Node.js. Możesz przekazać Glitch, że chcesz umieścić bibliotekę Socket.io w kompilacji, edytując package.json w katalogu najwyższego poziomu (w folderze nadrzędnym www) tak, by zawierał socket.io jako jedną z zależności:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Świetnie. Po aktualizacji przejdź do następnej aktualizacji index.html w folderze www, aby uwzględnić bibliotekę socket.io.
Po prostu umieść ten wiersz kodu nad tagiem importowanego skryptu HTML.Jest on położony na końcu pliku index.html:
index.html
<script src="/socket.io/socket.io.js"></script>
Plik index.html powinien zawierać 3 tagi skryptu:
- pierwszy import biblioteki TensorFlow.js
- drugi dodany przez Ciebie socket.io
- a ostatni – import kodu skryptu.js.
Następnie edytuj server.js, aby skonfigurować socket.io w węźle i utworzyć prosty backend do przekazywania wiadomości odebranych do wszystkich połączonych klientów.
Wyjaśnienie działania kodu Node.js znajdziesz w komentarzach do kodu poniżej:
plik.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Świetnie. Masz teraz serwer WWW, który nasłuchuje zdarzeń socket.io. Inaczej mówiąc, masz zdarzenie comment, gdy pojawi się nowy komentarz klienta, a serwer emituje zdarzenia remoteComment, których kod po stronie klienta będzie nasłuchiwać, aby wykryć zdalny komentarz. Ostatnią rzeczą, jaką musisz zrobić, jest dodanie logiki socket.io do kodu po stronie klienta, aby można było emitować i obsługiwać te zdarzenia.
Najpierw dodaj na końcu script.js ten kod, by połączyć się z serwerem socket.io i odsłuchiwać / odbierać otrzymane zdarzenia zdalnej komentarzy:
script.js,
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Na koniec dodaj kod do funkcji loadAndPredict, by emitować zdarzenie socket.io, jeśli komentarz nie jest spamem. Umożliwi Ci to zaktualizowanie informacji o nowych klientach, ponieważ treść tej wiadomości zostanie im przesłana za pomocą podanego przez Ciebie powyżej kodu server.js.
Po prostu zastąp istniejącą funkcję loadAndPredict poniższym kodem, który dodaje instrukcję else do ostatniego sprawdzania spamu. Jeśli komentarz nie jest spamem, wywołujesz funkcję socket.emit(), aby wysłać wszystkie dane komentarza:
script.js,
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
Brawo! Jeśli prawidłowo to zrobisz, powinno już być możliwe otwarcie 2 wystąpień strony index.html.
Gdy publikujesz komentarze, które nie są spamem, powinny zostać automatycznie wyrenderowane w drugim kliencie. Jeśli komentarz jest spamem, nie zostanie nigdy wysłany i zostanie oznaczony jako frontend w interfejsie użytkownika, który wygenerował go w ten sposób:
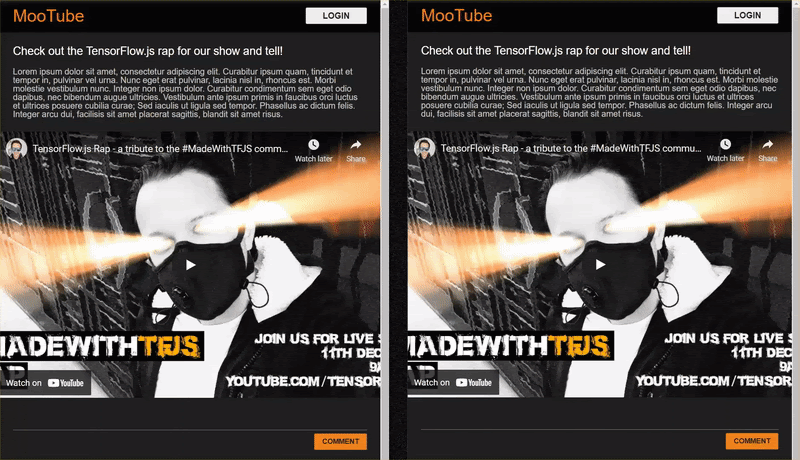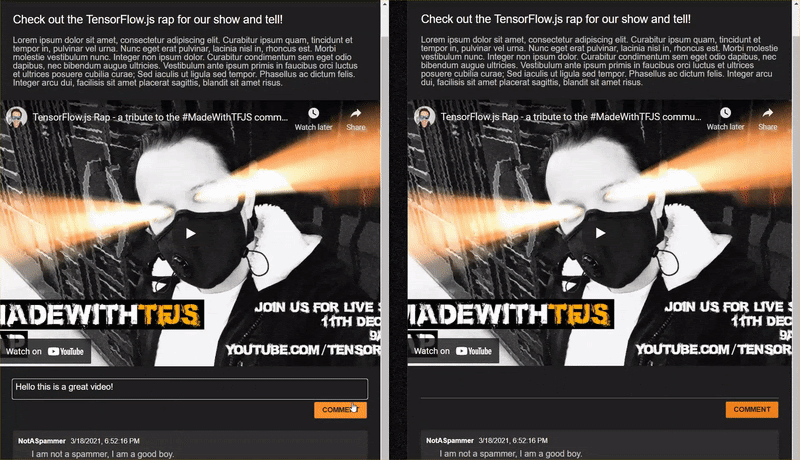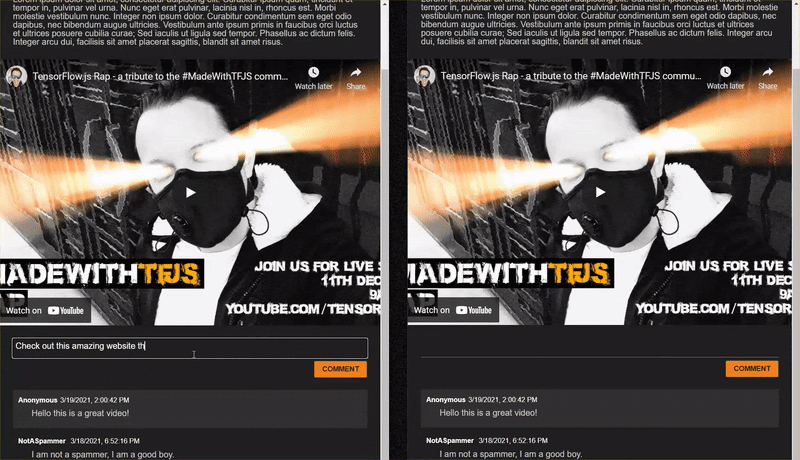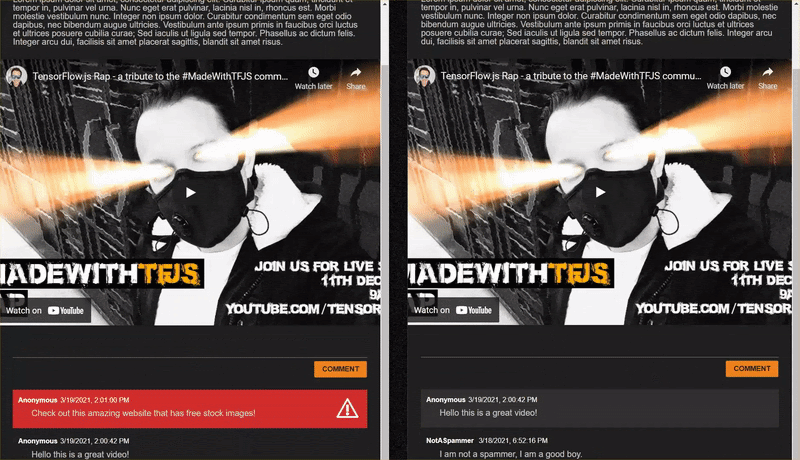
12. Gratulacje
Gratulujemy! Udało Ci się wykonać pierwsze kroki w korzystaniu z systemów uczących się w przeglądarce TensorFlow.js w przeglądarce, aby odkryć prawdziwy świat – w celu wykrywania spamu w komentarzach.
Wypróbuj go, wypróbuj różne komentarze, ale możesz zauważyć pewne problemy. Zauważysz też, że jeśli wpiszesz zdanie dłuższe niż 20 słów, aktualnie nie zadziała, ponieważ model będzie zakładał 20 słów.
W takim przypadku konieczne może być podzielenie długich zdań na grupy po 20 słów, a następnie wzięcie pod uwagę prawdopodobieństwa uzyskania spamu w każdym zdaniu w celu określenia, czy mają się one wyświetlać. Zostawimy to zadanie opcjonalne jako eksperyment do użytku, ponieważ jest wiele sposobów, które można wypróbować.
W ramach następnego ćwiczenia z ćwiczeniami pokażemy Ci, jak ponownie trenować ten model za pomocą niestandardowych danych komentarzy, które jeszcze nie są wykrywane, lub jak zmienić oczekiwaną wejściówkę modelu, tak aby obsługiwała zdania większe niż 20 słów. Następnie możesz wyeksportować i wykorzystać ten model za pomocą TensorFlow.js.
Jeśli z jakiegoś powodu masz problemy, porównaj kod z pełną wersją dostępną tutaj i sprawdź, czy niczego nie udało Ci się pominąć.
Podsumowanie
Dzięki nim dowiesz się:
- Wiesz, czym jest TensorFlow.js i jakie modele są dostępne w przypadku przetwarzania języka naturalnego
- Utworzyliśmy fikcyjną witrynę, na której w czasie rzeczywistym można dodawać komentarze do przykładowej witryny.
- Wczytano wytrenowany model systemów uczących się odpowiedni do wykrywania spamu w komentarzach przez TensorFlow.js na stronie internetowej.
- Nauczył się kodować zdania do użycia w załadowanym modelu systemów uczących się i dobudować kodowanie w Tensorze.
- Zinterpretowano dane wyjściowe modelu systemów uczących się, aby zadecydować, czy chcesz przesłać komentarz do sprawdzenia. Jeśli nie, został on wysłany na serwer w celu przekazania do innego połączonego klienta w czasie rzeczywistym.
Co dalej?
Skoro masz już za sobą pracę, jakie pomysły na opracowanie możesz wymyślić, aby rozszerzyć ten model wykorzystania systemów uczących się na realne zastosowanie, nad którym możesz pracować?
Podziel się z nami swoją opinią
To, czego szukasz, możesz łatwo rozszerzyć na potrzeby innych kreacji, dlatego warto myśleć nieszablonowo i kontynuować atakowanie.
Pamiętaj, aby oznaczyć nas tagiem w mediach społecznościowych za pomocą hashtagu #MadeWithTFJS. Dzięki temu Twój projekt pojawi się na naszym blogu TensorFlow, a nawet na przyszłych wydarzeniach. Z niecierpliwością czekamy na Wasze dzieła.
Więcej ćwiczeń z programowania w TensorFlow.js
- Zapoznaj się z częścią 2 tej serii, aby dowiedzieć się, jak ponownie nauczyć model rozpoznawania spamu w komentarzach, aby zapoznał się z przypadkami skrajnymi, które nie są obecnie wykrywane jako spam.
- używaj Hostingu Firebase do wdrażania i hostowania modelu TensorFlow.js na dużą skalę.
- Tworzenie inteligentnej kamery internetowej za pomocą gotowego modelu wykrywania obiektów za pomocą TensorFlow.js
Strony, na które trzeba zapłacić
- Oficjalna strona firmy TensorFlow.js
- Gotowe modele z TensorFlow.js
- Interfejs API TensorFlow.js
- TensorFlow.js Show & Talk – zainspiruj się i sprawdź, co utworzyli inni.