
1. 始める前に
過去 10 年間にわたり、ウェブアプリはソーシャル性と対話性を一層高めています。また、マルチメディアやコメントなどのサポートはすべて、数万人ものユーザーが、中程度に人気のあるウェブサイトでさえ、リアルタイムで発生する可能性があります。
これはまた、スパマーがそのようなシステムを悪用し、スパム行為のあったコンテンツを風通しの悪い記事や動画、投稿と関連付けて、より多くのユーザーの目に留まる機会を得る機会にもなっています。
ブロックする単語のリストなど、従来のスパム検出方法は簡単にバイパスできます。高度なスパムボットは単純に複雑になっていて、進化し続けるスパムボットとしては単純です。そして現在、このようなスパムを検出するようにトレーニングされた機械学習モデルを利用できるようになりました。
従来は、コメントの事前フィルタリングを行う機械学習モデルはサーバー側で実行されていましたが、TensorFlow.js ではブラウザで JavaScript を介して機械学習モデルを実行できるようになりました。バックエンドに到達する前にスパムを停止できるため、コストのかかるサーバー側のリソースを節約できる可能性があります。
ご存知のように、機械学習は最近の流行語として、世界中のほとんどの業界に触れていますが、こうした機能をウェブ デベロッパーとして利用するための第一歩を踏み出すにはどうすればよいでしょうか。
この Codelab では、自然言語処理(人間の言語をコンピュータで理解する技術)を使用して、コメントスパムの現実的な問題に取り組むウェブアプリを空白のキャンバスから作成します。この問題は、多くのウェブ アプリケーションにおいて増加の一途をたどって増加しているため、多くのウェブ デベロッパーが抱えています。この Codelab を使用すると、このような問題に効率的に対処できます。
要件
この Codelab は、機械学習が初めてで、TensorFlow.js で事前トレーニング済みモデルを使用することを検討しているウェブ デベロッパーを対象としています。
このラボでは、HTML5、CSS、JavaScript に精通していることを前提としています。
学習内容
このチュートリアルでは、次のことを行います。
- TensorFlow.js の概要と、自然言語処理用のモデルの詳細をご覧ください。
- リアルタイムのコメント欄がある架空の動画ブログ用に、シンプルな HTML / CSS / JS ウェブページを作成します。
- TensorFlow.js を使用して事前トレーニング済み機械学習モデルを読み込みます。このモデルでは、入力した文がスパムかどうかを予測したり、そのコメントがモデレーションのために保留されたことを警告したりできます。
- コメントセンテンスを機械学習モデルが分類できるような方法でエンコードし、分類します。
- 機械学習モデルの出力を解釈して、コメントに自動的にフラグを付けるかどうかを決定します。架空の UX は、自分の作業を行うウェブサイトでも再利用でき、あらゆるクライアントのユースケースに適合します。通常のブログやフォーラム、CMS のような CMS といった形態です。
とても便利な機能です。難しいですか?不正解です。さあ、ハッキングしよう...
必要なもの
- Glitch.com アカウントをフォローすることをおすすめしますが、ご自分で編集して運用できる快適なウェブサービス環境を利用することもできます。
2. TensorFlow.js とは

TensorFlow.js は、JavaScript を実行できる任意の場所で動作するオープンソースの機械学習ライブラリです。Python で記述されたオリジナルの TensorFlow ライブラリに基づいており、この開発者エクスペリエンスと JavaScript エコシステム向けの API セットの再作成を目的としています。
利用できる場所
JavaScript は移植性が高いため、1 つの言語で書いて、以下のプラットフォームすべてで簡単に機械学習を実行できます。
- ウェブブラウザのクライアントサイド(vanilla JavaScript を使用)
- Node.js を使用したサーバー側や Raspberry Pi などの IoT デバイス
- Electron を使用するデスクトップ アプリ
- React Native を使用するネイティブ モバイルアプリ
TensorFlow.js では、各環境内で複数のバックエンドをサポートします(CPU や WebGL など、ハードウェア内で実行される実際の環境など)。ここでの「バックエンド」とは、サーバー側の環境を意味するものではなく、互換性を確保して実行を高速化するために、実行のバックエンドは WebGL のクライアント側などとなります。現在、TensorFlow.js は以下をサポートしています。
- デバイスのグラフィック カードで使用できる WebGL 実行(GPU) - GPU アクセラレーションを使用して、より大きいモデル(3 MB を超えるモデル)を最速で実行できます。
- CPU での Web Assembly(WASM)の実行 -古い世代のスマートフォンなど、デバイス全体で CPU のパフォーマンスを改善します。これは、グラフィック プロセッサにコンテンツをアップロードするオーバーヘッドにより、WebGL よりも WASM を使用して CPU 上で実際に高速に実行できる小さなモデル(サイズが 3 MB 未満)に適しています。
- CPU の実行 - 他の環境を使用できない場合にフォールバックを使用します。これは 3 つのプロセスの中で最も遅いものですが、常に存在します。
注: 実行するデバイスの種類がわかっている場合は、これらのバックエンドのいずれかを強制的に使用することを選択できます。または、TensorFlow.js に判断させることもできます。これは指定しません。
クライアントサイドのスーパーパワー
クライアント コンピュータのウェブブラウザで TensorFlow.js を実行すると、検討すべきメリットがいくつかあります。
プライバシー
サードパーティのウェブサーバーにデータを送信せずに、クライアント マシンでデータをトレーニングして分類できます。GDPR などの地域の法律を遵守するための要件や、ユーザーがパソコンに保持して第三者に送信しないデータを処理する場合に、この要件が必要になることがあります。
速度
リモート サーバーにデータを送信する必要がないため、推論(データを分類する動作)にかかる時間を短縮できます。さらに、デバイスのセンサー(カメラ、マイク、GPS、加速度計など)に直接アクセスできれば、センサーに直接アクセスできます。
リーチと拡大
あなたが送信したリンクをワンクリックするだけで、誰でもブラウザ上でウェブページを開いて、あなたが編集したアプリを利用できます。サーバー側システム上の複雑な CUDA ドライバの設定などは必要ありません。機械学習システムを使用するだけで使用できます。
費用
サーバー不要というのは、HTML、CSS、JS、モデルの各ファイルをホストするための CDN があればよいということです。CDN の費用は、サーバーを 24 時間 365 日稼働し続けるよりもはるかに安価です(グラフィック カードが装着されている場合もある)。
サーバーサイドの機能
TensorFlow.js の Node.js 実装を活用すると、次の機能が有効になります。
CUDA によるフルサポート
グラフィック カード アクセラレーションのサーバー側では、NVIDIA CUDA ドライバをインストールして、TensorFlow がグラフィック カードと連携できるようにする必要があります(WebGL を使用するブラウザではインストールが不要です)。ただし、CUDA が完全にサポートされているため、グラフィック カードの下位レベルの機能を最大限に活用できるため、トレーニングと推論にかかる時間を短縮できます。どちらも同じ C++ バックエンドを共有しているため、パフォーマンスは Python TensorFlow 実装と同等です。
モデルサイズ
研究用の最先端のモデルの場合、非常に大きなモデル(数ギガバイト)を扱う可能性があります。現在のところ、これらのブラウザは、ブラウザタブごとのメモリ使用量の制限により、ウェブブラウザで実行できません。これらの大規模なモデルを実行するには、独自のモデルで Node.js を使用し、そのようなモデルを効率的に実行するために必要なハードウェア仕様を指定します。
IoT
Node.js は、Raspberry Pi のような一般的なシングルボード コンピュータでサポートされます。そのため、このようなデバイスでは TensorFlow.js モデルを実行することもできます。
速度
Node.js は JavaScript で記述されているため、短時間でコンパイルできます。このため、Node.js を使用すると実行時に改善されることがあり、特に前処理の場合はその時間が最適化されます。その好例が、こちらのケーススタディをご覧ください。Hugging Face が Node.js を使用して自然言語処理モデルの 2 倍のパフォーマンスを向上させた様子を紹介しています。
ここまで、TensorFlow.js の基本的な実行方法と、そのメリットについて学習しました。次は、実際に使ってみましょう。
3. 事前トレーニング済みモデル
事前トレーニング済みモデルを使用する理由
一般的な事前トレーニング済みモデルから始めて、望ましいユースケースに適応すると、次のようなメリットが得られます。
- トレーニング データを収集する必要はありません。 データを正しい形式で準備し、機械学習システムが学習に使用できるようにラベル付けすることによって、非常に時間と費用がかかる可能性があります。
- 費用と時間を削減してアイデアを迅速にプロトタイプ化する機能。
事前トレーニング済みのモデルがニーズに十分対応できる場合は「再定義」の必要性がなく、モデルで提供される知識を使ってクリエイティブなアイデアを出すことに集中できます。 - 最先端研究の活用。 多くの場合、事前トレーニング済みモデルは一般的な研究に基づいており、現実世界におけるパフォーマンスを把握しながら、そのようなモデルに触れることができます。
- 使いやすいドキュメントと豊富なドキュメント このようなモデルは人気があるため。
- 転移学習の機能: 一部の事前トレーニング済みモデルでは、転移学習機能が提供されます。これは基本的に、ある機械学習タスクから学習した情報を別の類似例に転送する手法です。たとえば、新しい認識データを提供すると、もともと猫を認識するようにトレーニングされたモデルを、犬を認識するように再トレーニングすることができます。空白のキャンバスで始める必要がないため、処理が速くなります。このモデルでは、学習したことを基に猫を認識し、新しいことを認識できます。犬には目と耳もあります。そのため、これらの機能を見つける方法をすでに知っている場合、移行は半ばです。はるかに高速に自分のデータでモデルを再トレーニングできます。
事前トレーニング済みのコメントスパム検出モデル
コメントスパム検出のニーズには平均単語埋め込みモデル アーキテクチャを使用しますが、トレーニングされていないモデルを使用しようとしても、文がスパムかどうかを推測できる確率は低くなります。
有用なモデルを作成するには、カスタムデータを使用してモデルをトレーニングする必要があります。この場合、そのモデルでスパムとスパム以外のコメントがどのように識別されるかを学習できます。そうすれば、今後、コンテンツを正しく分類できる可能性が高くなります。
幸いなことに、このコメントスパム分類タスクについては、すでにこのモデル アーキテクチャがトレーニングされているので、このモデル アーキテクチャを出発点として使用できます。コメントが書き込まれた言語の検出、記述されたテキストに基づいてウェブサイトの問い合わせデータを特定の企業チームに自動的にルーティングする必要があるかどうかの予測など、同じモデル アーキテクチャを使用して、他の事前トレーニング済みモデルが別の処理を行う場合があります。例: セールス(プロダクトに関する問い合わせ)またはエンジニアリング(技術的なバグまたはフィードバック)。十分なトレーニング データがあれば、このようなモデルは、いずれの場合もテキストを分類して、ウェブアプリに強力な機能を提供し、組織の効率を向上させる方法を学ぶことができます。
今後のコードラボでは、Model Maker を使用して、事前トレーニング済みのコメントスパム モデルを再トレーニングし、コメントデータに対するパフォーマンスを向上させる方法を学びます。 現時点では、既存のコメントスパム検出モデルを出発点として使用し、最初のウェブアプリを最初のプロトタイプとして機能させます。
この事前トレーニング済みのコメントスパム検出モデルは、TF Hub と呼ばれるウェブサイトに公開されています。TF Hub は Google が管理する機械学習モデルリポジトリで、ML エンジニアは多数の一般的なユースケースに対応する事前作成モデルを公開できます(カテゴリ、テキスト、ビジョン、サウンドなど) この Codelab の後半で、ウェブアプリで使用するモデルファイルをダウンロードします。
次のように、JS モデルのダウンロード ボタンをクリックします。
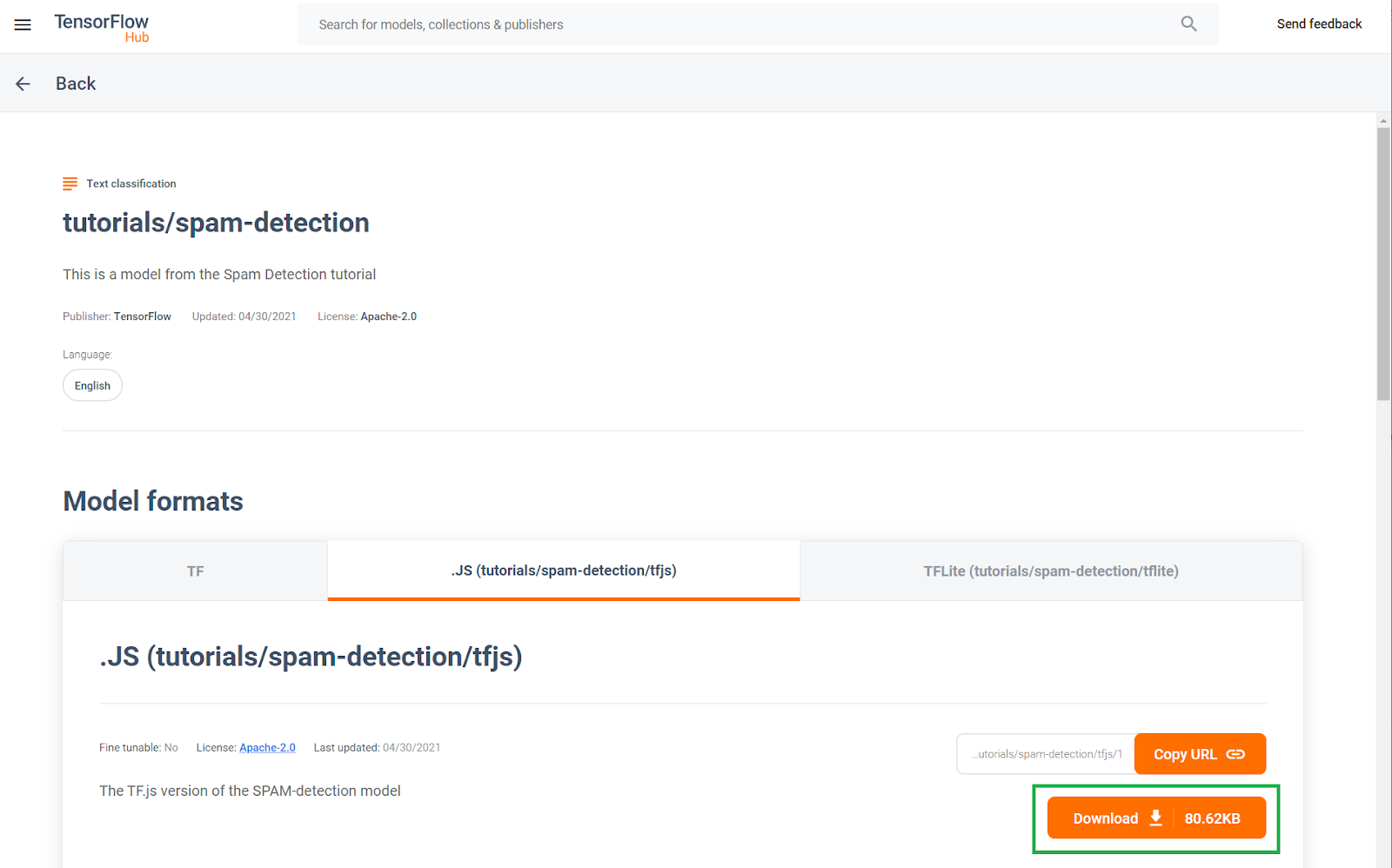
4.コードの設定
必要なもの
- 最新のウェブブラウザ。
- HTML、CSS、JavaScript、Chrome DevTools の基本的な知識(コンソール出力の表示)
コーディングを始めましょう。
Glitch.com Node.js Express ボイラープレート テンプレートが用意されています。このテンプレートから、この Codelab の基本状態としてワンクリックでクローンを作成できます。
Glitch で [リミックス] ボタンをクリックするだけで、フォークして編集できる新しいファイルセットが作成されます。
この非常にシンプルなスケルトンにより、www フォルダ内に次のファイルが提供されます。
- HTML ページ(index.html)
- スタイルシート(style.css)
- JavaScript コード(script.js)を書き込むファイル
便宜上、HTML ファイルには、次のような TensorFlow.js ライブラリのインポートが追加されています。
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
次に、package.json と server.js を介してシンプルな Node Express サーバー経由でこの www フォルダを提供します。
5. アプリの HTML ボイラープレート
出発点の概要
すべてのプロトタイプには、検出結果のレンダリング先となる基本的な HTML スキャフォールドが必要です。今すぐ設定してください。次を追加します:
- ページのタイトル
- 説明文
- 動画のブログエントリを表すプレースホルダ動画
- コメントの表示と入力が可能な領域
index.html を開き、既存のコードで次のコードを貼り付けて上記の機能を設定します。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
詳細
上の主な HTML コードの明細を細かく見てみましょう。
- ページタイトルの
<h1>タグと、<header>内のログインボタン用の<a>タグを追加しました。そして、記事のタイトルには<h2>を、動画の説明には<p>タグを追加しました。特別な予定はありません。 - 任意の YouTube 動画を埋め込む
iframeタグを追加しました。ここでは、TensorFlow.js のラップをプレースホルダとして使用していますが、iframe の URL を変更するだけで、任意の動画を配置できます。実際、本番環境のサイトでは、表示されているページに応じて、これらの値のすべてがバックエンドによって動的にレンダリングされます。 - 最後に、ID と「comments」のクラスを含む
sectionを追加しました。このコメントには、新しいコメントを書き込む インテリジェントなdivと、追加する新しいコメントを順序付けなしで送信するためのbuttonが含まれています。コメントのリスト 各リスト項目内のspanタグ内にユーザー名と投稿時間があり、最後にpタグ内にコメント自体があります。現在のところ、2 つのサンプル コメントはプレースホルダとしてハードコードされています。
出力を今すぐプレビューすると、次のようになります。
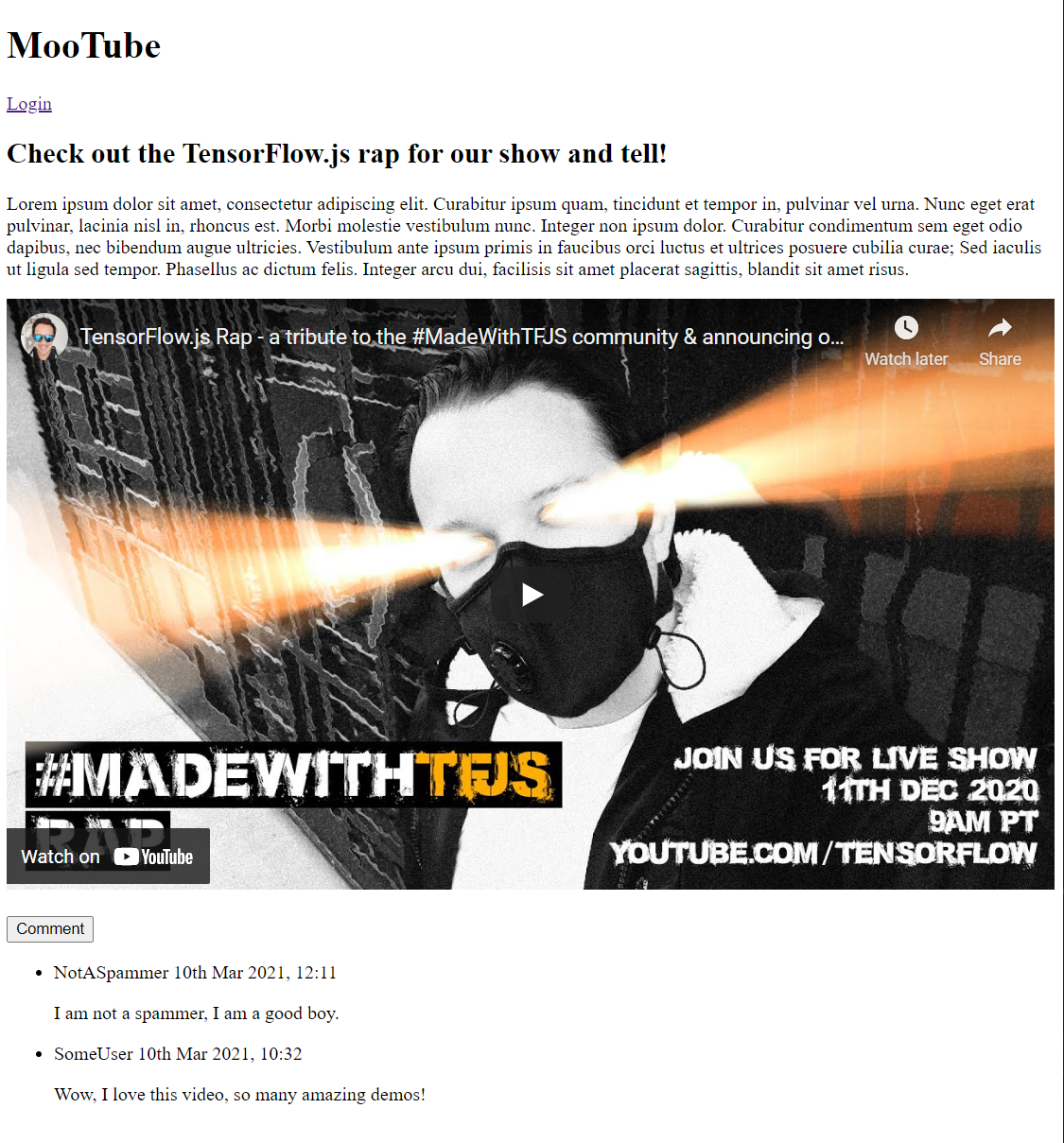
非常に悪いですね。それでは、スタイルを追加しましょう。
6. スタイルを追加する
要素のデフォルト
まず、先ほど追加した HTML 要素のスタイルを追加して、正しく表示されるようにします。
最初に、CSS リセットを適用して、すべてのブラウザと OS でコメントを開始するようにします。style.css の内容を次のように上書きします。
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
次に、ユーザー インターフェースを使いやすくする便利な CSS を追加します。
style.css の最後に、上記に追加したリセット用の CSS コードの下に次のコードを追加します。
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
次の必要な処理はこれだけです。上記の 2 つのコードでスタイルが正常に上書きされると、ライブ プレビューは次のようになります。
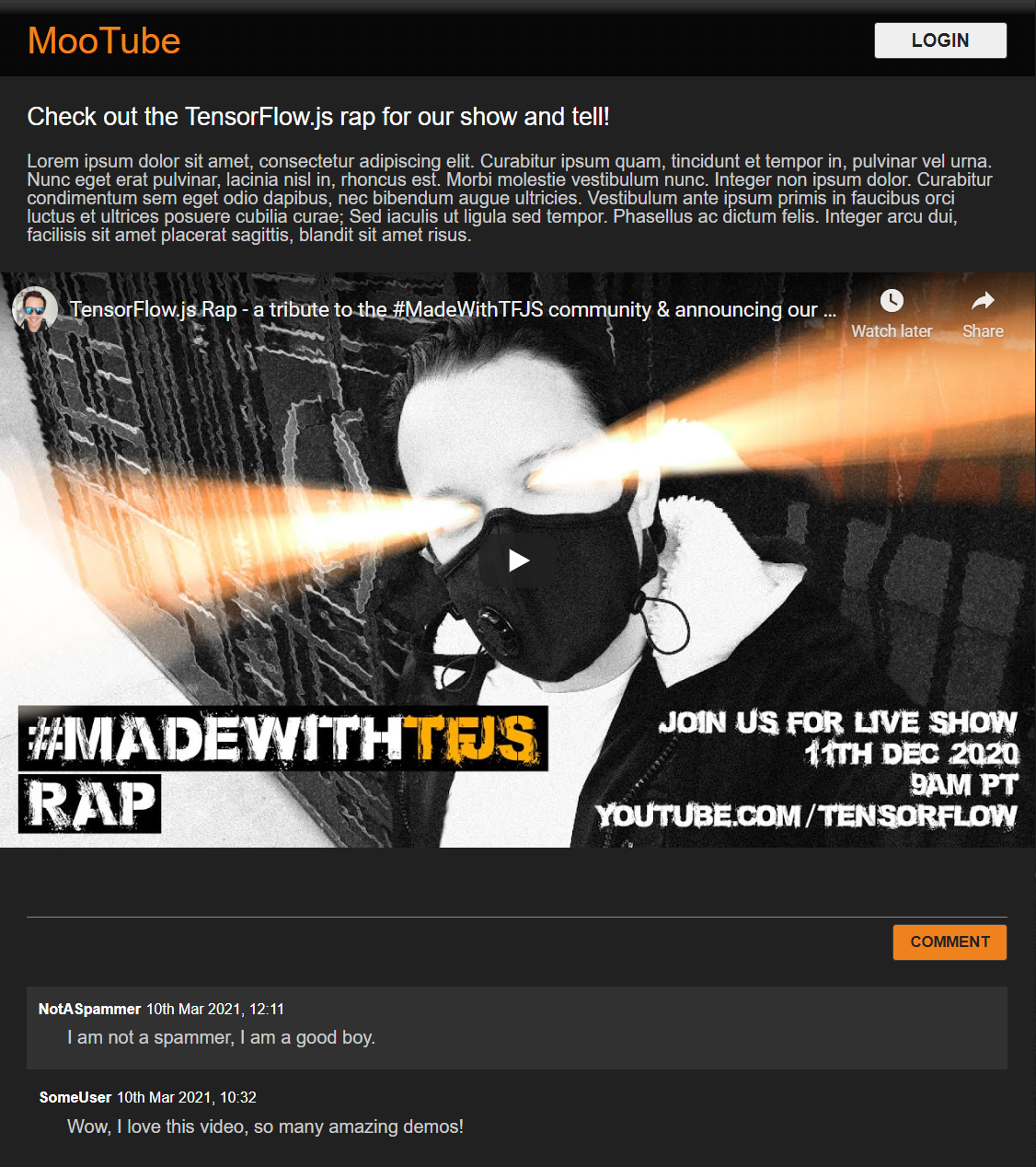
主要要素に対するカーソル効果に、スウィート、ナイトモード、魅力的な CSS 遷移を適用しました。いいですね。次に、JavaScript を使用して動作ロジックを統合します。
7. JavaScript: DOM 操作とイベント ハンドラ
主要な DOM 要素の参照
まず、スタイル設定に使用する CSS クラスの定数を定義し、後で操作またはアクセスする必要があるページのキー部分にアクセスできるようにします。
まず、script.js の内容を次の定数で置き換えます。
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
コメントの投稿を処理する
次に、イベント リスナーと処理機能を POST_COMMENT_BTN に追加して、書き込まれたコメント テキストを取得し、処理が開始するように CSS クラスを設定できるようにします。すでに処理が進行中の場合には、このボタンがまだクリックされていないことを確認してください。
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
次のウェブページを更新してコメントを投稿すると、コメントボタンとテキストがグレースケールになり、コンソールに次のようなコメントが出力されます。
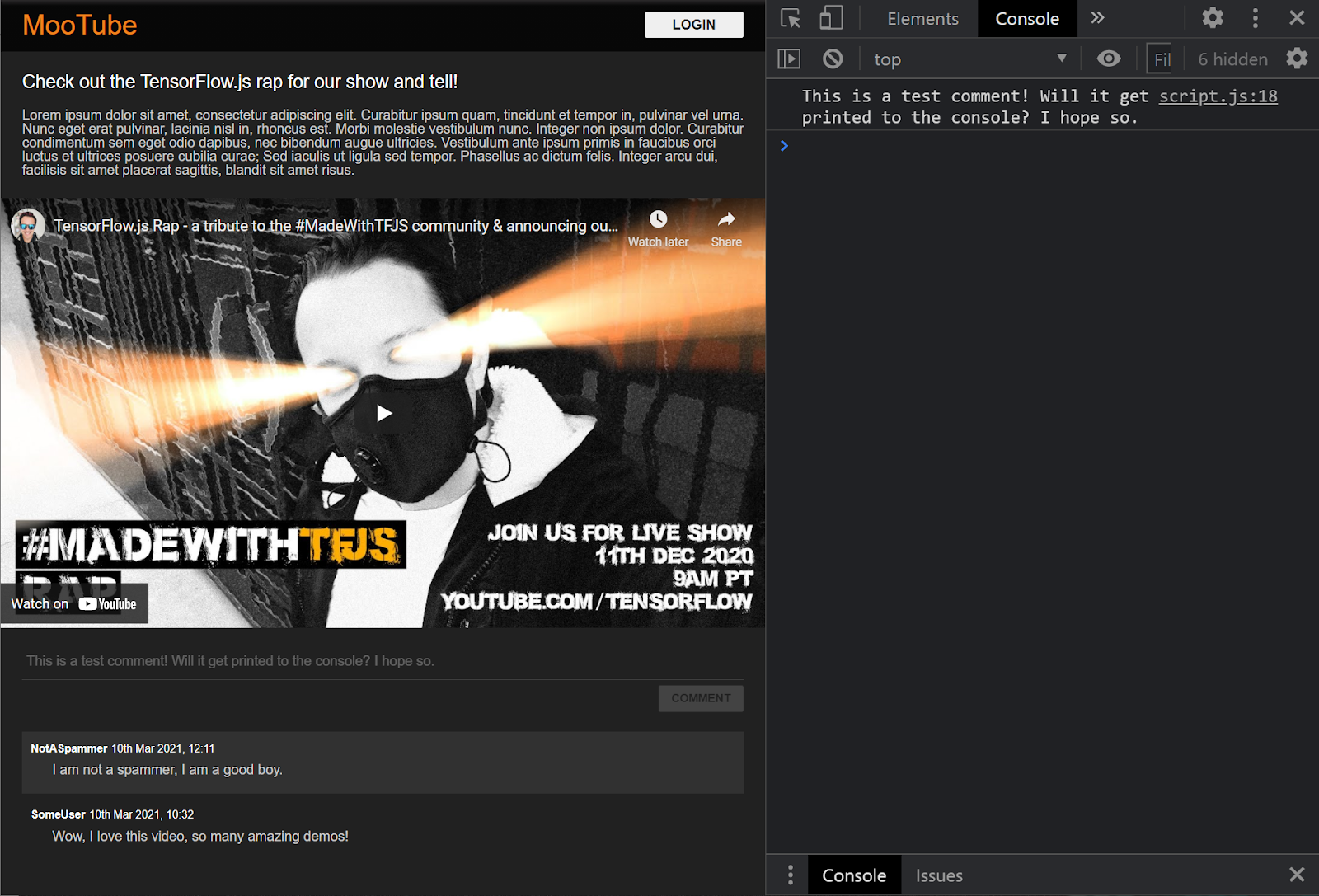
基本的な HTML / CSS / JS スケルトンを作成したら、今度は機械学習モデルに戻って美しいウェブページに組み込めるようにします。
8. 機械学習モデルを提供する
モデルを読み込む準備が整いました。その前に、Codelab で前にダウンロードしたモデルファイルをウェブサイトにアップロードして、コード内でホストして使用できるようにする必要があります。
まず、この Codelab の冒頭でモデルにダウンロードしたファイルを解凍します。以下のファイルを含むディレクトリが表示されます。
機能はありますか?
model.json- これは、トレーニング済みの TensorFlow.js モデルを構成するファイルの 1 つです。後でこのファイルを後ほど TensorFlow.js コードで参照します。group1-shard1of1.bin- TensorFlow.js モデルのトレーニングされた重み(基本的には分類タスクを適切に実行するために学習した大量の数値)を含むバイナリ ファイルです。ダウンロードの際にはサーバー上のどこかでホストする必要があります。vocab- この拡張子のない奇妙なファイルは、Model が理解できるように文中の単語をエンコードする方法を示しています。これについては、次のセクションで詳しく説明します。labels.txt- これは、モデルが予測する結果のクラス名のみを示します。このモデルでは、このファイルをテキスト エディタで開くと、「false」と「true」がリストされ、予測出力として「スパムではない」または「スパム」が示されます。
TensorFlow.js モデルファイルをホストする
まず、ウェブサーバーで生成した model.json ファイルと *.bin ファイルを、ウェブページからアクセスできるように配置します。
Glitch にファイルをアップロードする
- Glitch プロジェクトの左側のパネルで、assets フォルダをクリックします。
- [アセットをアップロード] をクリックし、
group1-shard1of1.binを選択してこのフォルダにアップロードします。アップロードが完了すると、次のように表示されます。
- 次の
model.jsonファイルについても同じ操作を行います。 assets フォルダに次の 2 つのファイルを記述します。
- アップロードした
group1-shard1of1.binファイルをクリックします。URL をその場所にコピーできます。パスを次のようにコピーします。
- 画面左下にある [ツール] > [ターミナル] をクリックします。ターミナル ウィンドウが読み込まれるのを待ちます。読み込まれたら、次のように入力して Enter キーを押して、
wwwフォルダに移動します。
ターミナル:
cd www
- 次に、
wgetを使用して、以下の 2 つのファイルをダウンロードします。そのためには、下の URL を Glitch の assets フォルダにあるファイル用に生成した URL に置き換えます(各ファイルのカスタム URL は assets フォルダを確認してください)。 )。2 つの URL の間のスペースと、必要な URL は以下の URL と異なりますが、見た目は同じです。
ターミナル
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
これで、www フォルダにアップロードされたファイルのコピーが作成されました。しかし、そのファイルには奇妙な名前が付いています。
- ターミナルで「
ls」と入力し、Enter キーを押します。次のような出力が表示されます。

mvコマンドを使用すると、ファイル名を変更できます。コンソールに次のコマンドを入力して、各行の後に <kbd>Enter</kbd> または <kbd>Return</kbd> キーを押します。
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 最後に、ターミナルで「
refresh」と入力して <kbd>Enter</kbd> キーを押し、Glitch プロジェクトを更新します。
terminal:
refresh
- 更新すると、ユーザー インターフェースの
wwwフォルダにmodel.jsonとgroup1-shard1of1.binが表示されます。
次のこれで、アップロードされたモデルファイルを、実際のコードでブラウザで使用する準備が整いました。
9. ホストされている TensorFlow.js モデルを読み込んで使用する
この時点で、アップロードされた TensorFlow.js モデルの読み込みにテストをして、データが正常に機能するかどうかを確認できます。
今のところ、下に示す入力データの例はかなり不明確(数字の配列)に見えますが、これらのデータがどのように生成されるかについては次のセクションで説明します。現時点では、これを数値の配列として表示します。この段階では、モデルがエラーなしで答えを出力することを単にテストすることが重要です。
次のコードを script.js ファイルの末尾に追加し、MODEL_JSON_URL 文字列値を、Glitch アセット フォルダにファイルをアップロードしたときに生成した model.json ファイルのパスに置き換えてください。前のステップに進みます。(Glitch の assets フォルダにあるファイルをクリックすると、その URL が表示されます)。
各行の新しい動作については、以下の新しいコードのコメントをご覧ください。
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
プロジェクトが正しく設定されている場合、読み込まれたモデルを使用して、渡された入力から結果を予測すると、コンソール ウィンドウに次のような出力が表示されます。
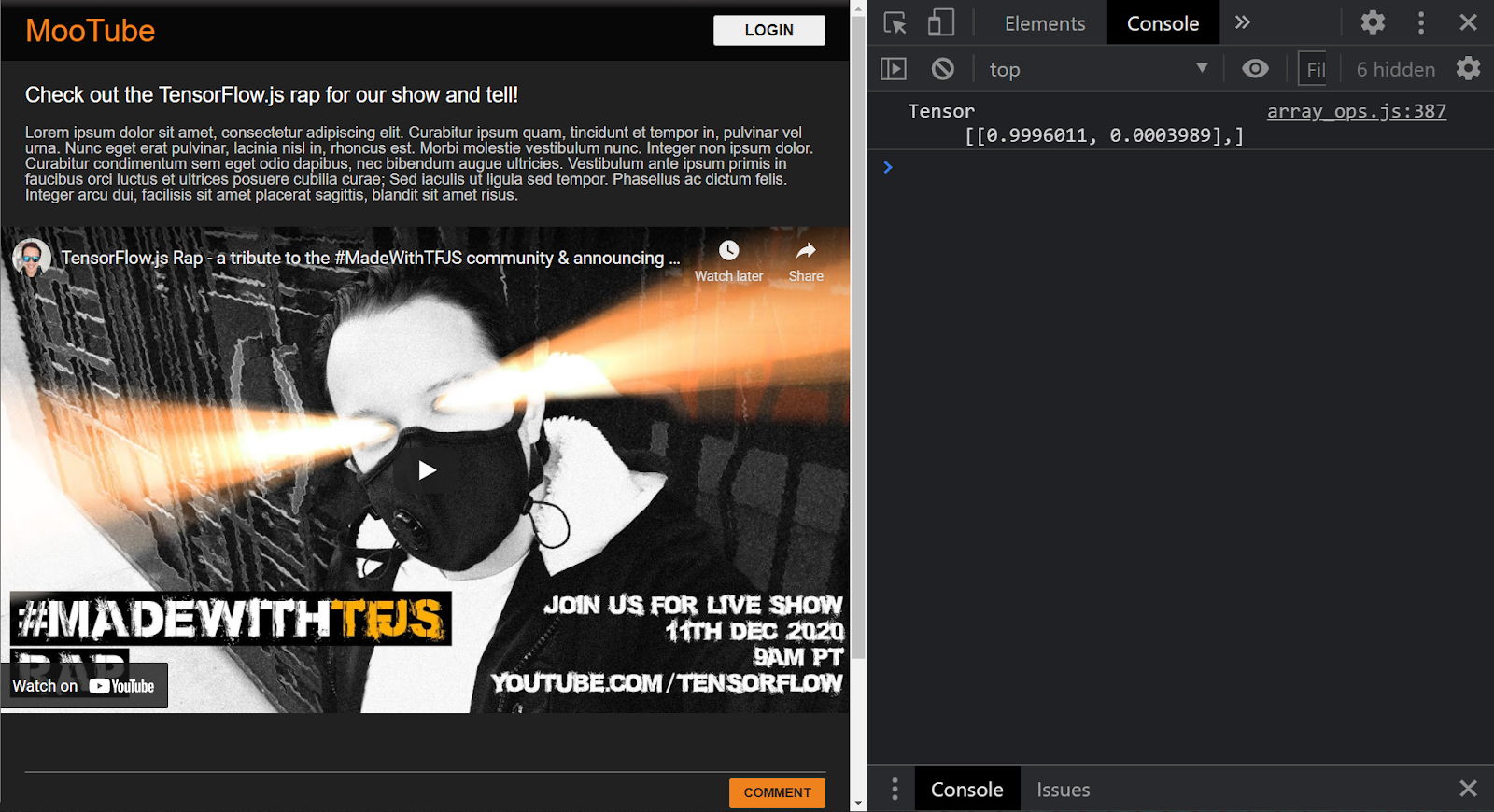
コンソールには、次の 2 つの数字が出力されます。
- 0.9996011
- 0.0003989
この数値はわかりにくいように見えるかもしれませんが、これらの数値は、入力データに対してモデルがモデルで行った分類の確率を表します。それらは何を意味するのでしょうか。
ローカルマシンにあるダウンロードしたモデルファイルから labels.txt ファイルを開くと、次の 2 つのフィールドもあります。
- 誤り
- 正しい
したがって、この場合のモデルは、99.96011%その場合、結果を(0.9996011 として)表示し、[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]でした迷惑メールではない(false など)。
false は labels.txt の最初のラベルであり、出力結果に関連する内容を示すコンソール プリントの最初の出力で表されます。
出力の解釈方法を理解しました。では、出力として大量に提供された数字は何か、また、モデルで使用するために文をこの形式に変換するにはどうすればよいでしょうか。 そのためには、トークン化とテンソルについて学習する必要があります。ぜひご一読ください。
10. トークン化とテンソル
トークン化
その結果、機械学習モデルは入力として大量の数値しか受け取ることができないことがわかりました。なぜなら、基本的に、機械学習モデルは一連のチェーン演算であるため、数値ではないものを渡すと、処理が困難になります。では、読み込んだモデルで使用する文を数字に変換するにはどうすればよいでしょうか。
正確なプロセスはモデルによって異なりますが、ダウンロードしたモデルファイルにはもう 1 つの vocab, というファイルがあり、これがデータのエンコード方法の鍵となります。
マシンのローカル テキスト エディタで vocab を開くと、次のように表示されます。
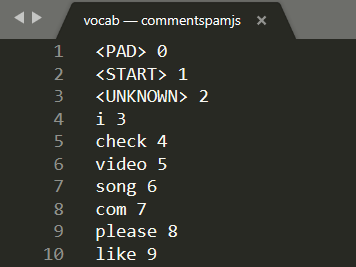
基本的には、モデルが学習した意味のある単語を、理解できる数字に変換する方法に関するルックアップ テーブルです。ファイル <PAD>、<START>、<UNKNOWN> の先頭に特殊なケースがいくつかあります。
<PAD>- 「padding」の略です。機械学習モデルでは、センテンスの長さにかかわらず、決まった数の入力が望ましいことが判明しました。使用されるモデルでは、入力には常に 20 個の数値があると想定されています(数値はモデルの作成者によって定義され、モデルを再トレーニングすることで変更できます)。したがって、「I like video」のようなフレーズがある場合、配列の残りのスペースには<PAD>トークンを表す 0 を入力します。センテンスが 20 語を超える場合は、この要件に適合するように分割し、代わりに多数の小さな文に対して複数の分類を行う必要があります。<START>- 常に文の先頭を示す最初のトークンになります。前の手順の入力例には、「1」で始まる数値の配列が表示されています。これは<START>トークンを表していました。<UNKNOWN>- 推測されたとおり、単語のルックアップにその単語がない場合は、数値として<UNKNOWN>トークン(「2」で表される)を使用します。
その他の単語については、ルックアップに存在し、特別な番号が関連付けられているため、その番号を使用するか、存在しない場合は、代わりに <UNKNOWN> トークン番号を使用します。
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
ここから、4 語の文になっていることがわかります。残りは <START> または <PAD> のトークンであり、配列内に 20 個の数値があります。もう少し理解が深まりましたね。
実際に私が書いたのは、「私の犬が大好き」という文です。上のスクリーンショットでは、「I」が数字の「3」に変換されています。他の単語も調べてみると、それに対応する数字も見つかります。
テンソル
ML モデルが数値入力を受け入れる前に、最後のハードルがあります。数値の配列を Tensor というものに変換する必要があります。そうですね、TensorFlow はそういう名前、つまり基本的にモデルを通じたテンソルのフローにちなんで名付けられました。
Tensor とは
TensorFlow.org の公式定義によると、次のようになります。
「テンソルは、均一な型の多次元配列です。テンソルはすべて不変です。テンソルの内容を更新することはできません。新しいテンソルを作成するだけです。」
簡単な英語では、機械学習オブジェクトとして役立つ、Tensor Object に組み込まれた他の関数が含まれる任意のディメンションの配列を簡潔に数学名で呼んでいます。ただし、Tensor は 1 種類(すべての整数、浮動小数点数など)のデータのみを保存することに注意する必要があります。作成したテンソルのコンテンツは変更できません。そのため、テンソルは数値の永続ストレージ ボックスと考えることができます。
今のところはあまり気にしないでください。少なくとも、機械学習モデルが連携する多次元ストレージのメカニズムと考えてみてください。このような優れた本についてさらに詳しく学ぶには、テンソルについてさらに詳しく学びたい場合に強くおすすめします。使い方をご確認ください。
まとめ: テンソルのコーディングとトークン化
では、その vocab ファイルをコードでどのように使用しますか。 ご質問いただきありがとうございます。
このファイルは単独では、JS 開発者には使えません。これを JavaScript オブジェクトとしてインポートして使用できれば、はるかに効率的です。このファイルのデータを次のような形式に変換するのは非常に簡単であることがわかるでしょう。
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
お好みのテキスト エディタで vocab ファイルを簡単に変換し、検索と置換を行います。ただし、事前に作成されたツールを使用すると、これを簡単に設定できます。
作業を事前に行い、vocab ファイルを正しい形式で保存すれば、ページが読み込まれるたびにこの変換と解析を行う必要がなくなり、CPU リソースの無駄になります。さらに優れた点として、JavaScript オブジェクトには次のプロパティがあります。
「オブジェクト プロパティ名には、有効な JavaScript 文字列や、文字列に変換できるもの(空の文字列を含む)を何でも指定できます。ただし、有効な JavaScript 識別子でないプロパティ名(スペースやハイフンを含むプロパティ名、数字で始まるプロパティ名など)には、角括弧の表記法を使用してのみアクセスできます。」
したがって、角かっこ表記を使用すれば、この単純な変換によってかなり効率的なルックアップ テーブルを作成できます。
より便利な形式に変換する
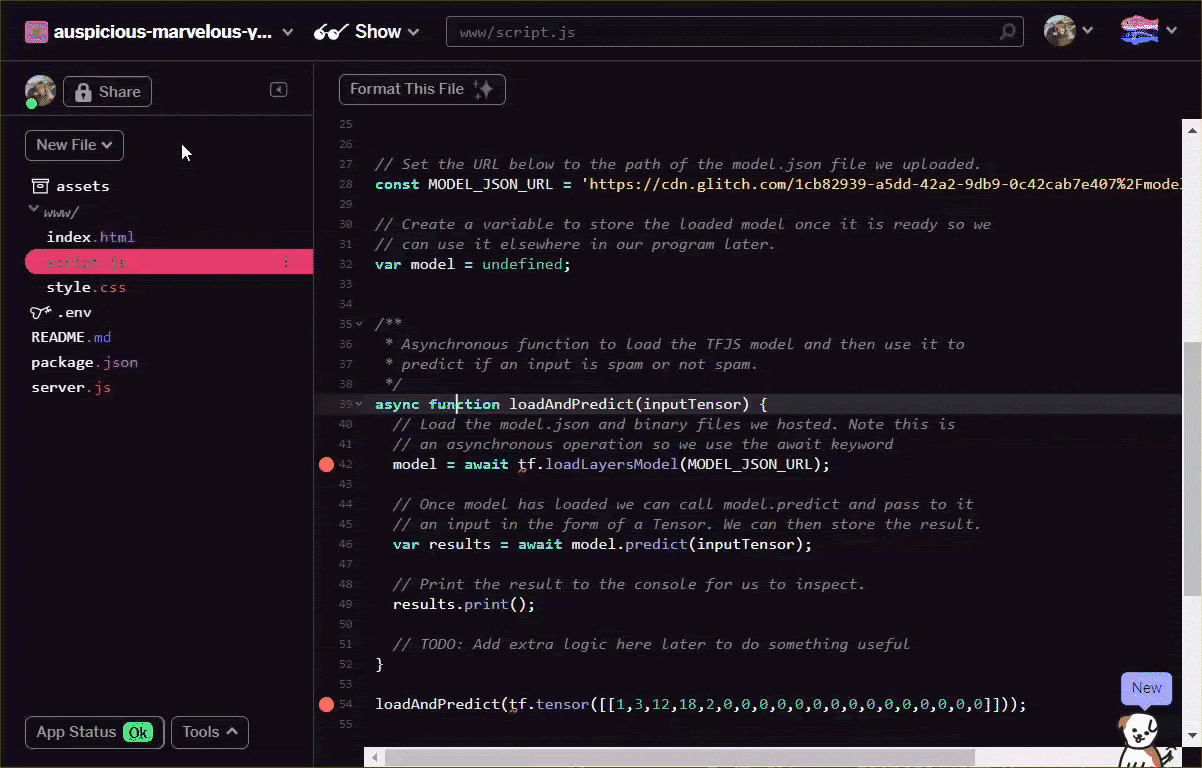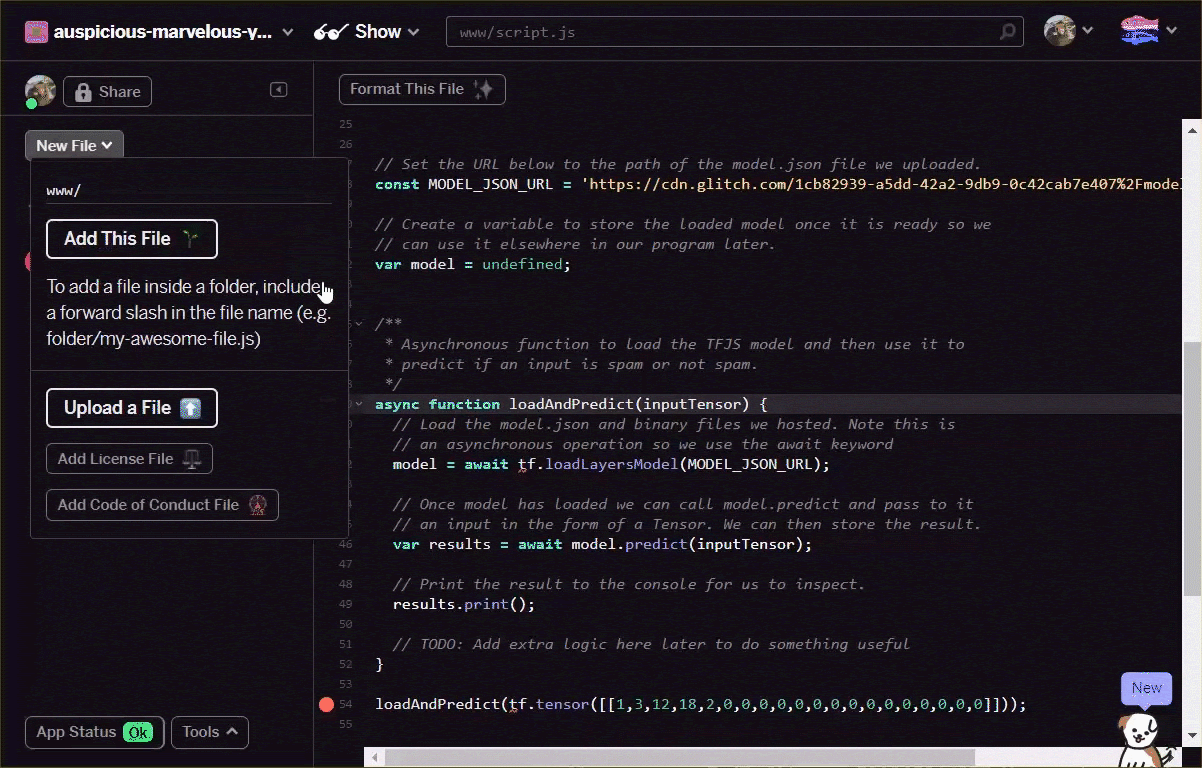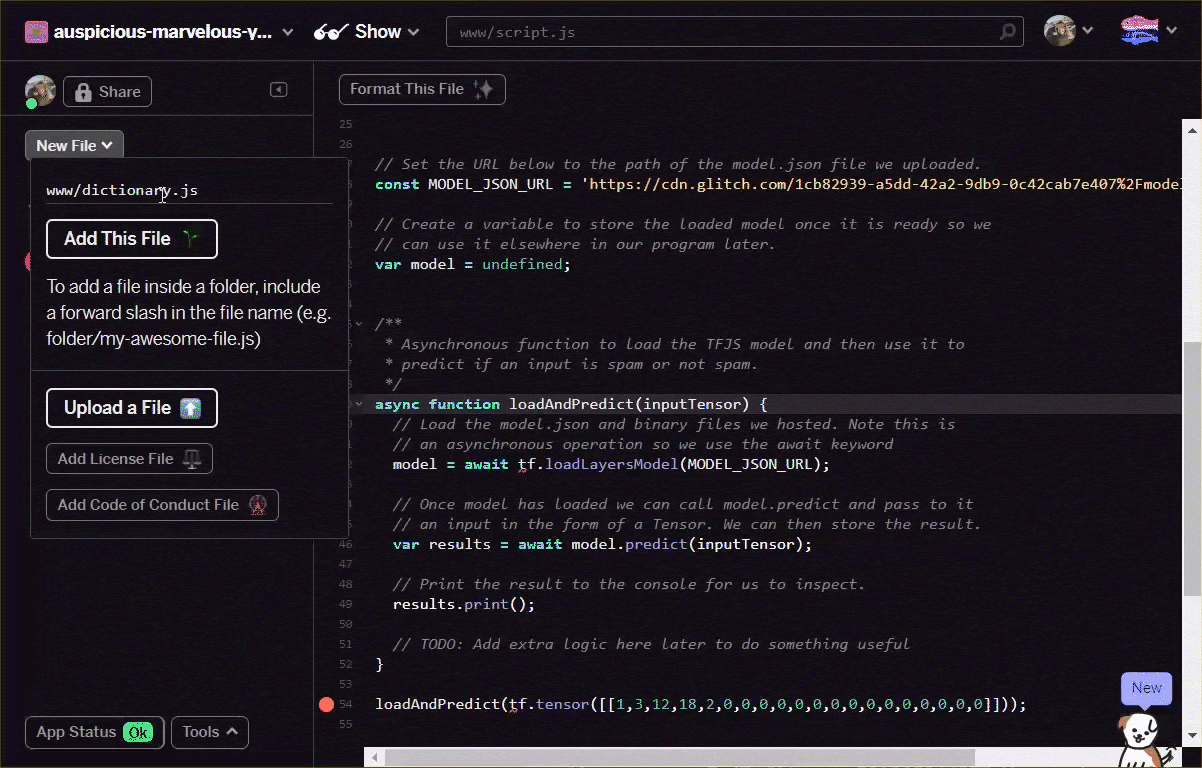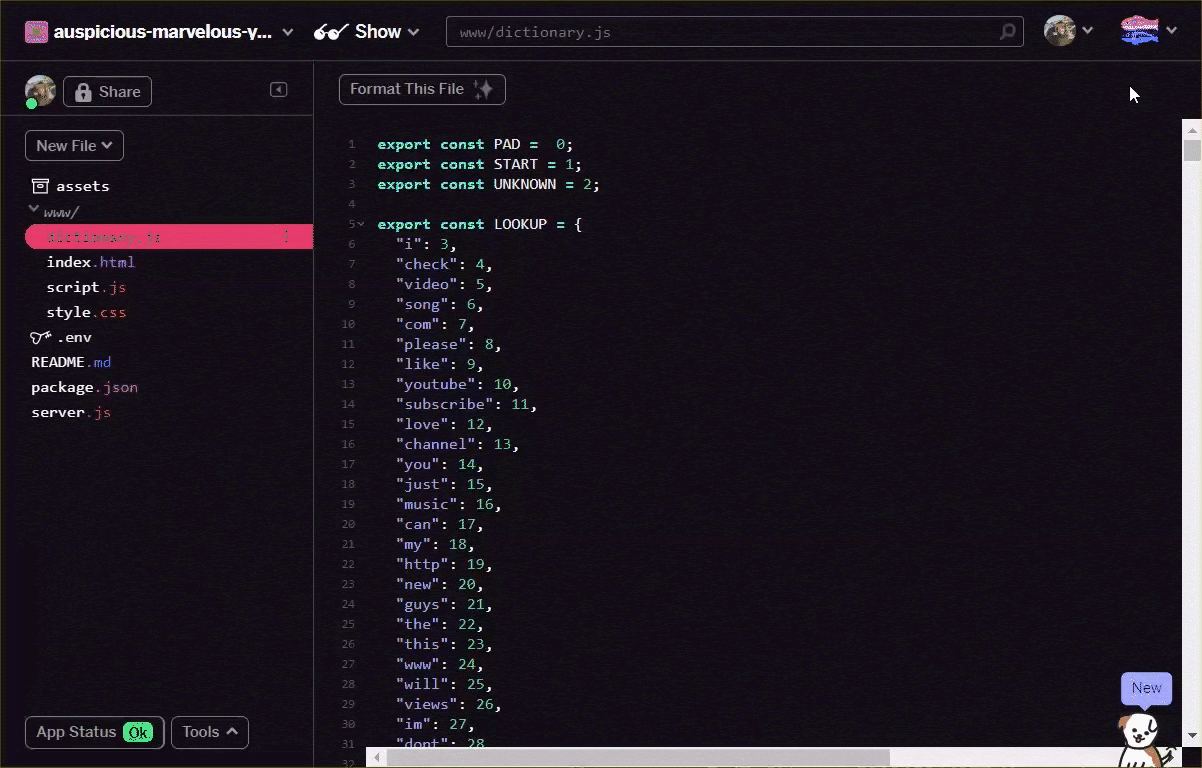
テキスト エディタを使用して手動で、またはこちらのツールを使用して、語彙ファイルを上記の形式に変換します。結果の出力を dictionary.js として www フォルダに保存します。
Glitch では、次に示すように、ここに新しいファイルを作成して変換の結果を貼り付けるだけで保存できます。
前述の形式で保存された dictionary.js ファイルを作成したら、script.js の先頭に次のコードを付加して、先ほど作成した dictionary.js モジュールをインポートできます。ここでは追加の定数 ENCODING_LENGTH を定義して、コードの後半でパディングする量を把握します。また、単語の配列を適切なテンソルに変換するために使用する tokenize 関数も定義します。モデルへの入力。
各行の機能について詳しくは、下記のコメントを参照してください。
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
handleCommentPost() 関数に戻り、この関数の新しいバージョンに置き換えます。
追加した内容に関するコメントのコードを確認します。
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
最後に、コメントがスパムとして検出された場合にスタイルを設定するよう loadAndPredict() 関数を更新します。
ここではスタイルのみを変更しますが、後でコメントをなんらかの管理キューに残すか、送信を停止するかを選択できます。
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. リアルタイム更新: Node.js + WebSocket
これで、フロントエンドでスパム検出を実行できるようになりました。最後のパズルは、Node.js でいくつかの WebSocket を使用してリアルタイムでコミュニケーションし、スパムではない追加されたコメントをリアルタイムで更新する方法です。
Socket.io
Socket.io は、Node.js で WebSocket を使用する最も一般的な方法の 1 つです。ビルドに Socket.io ライブラリを含めるよう Glitch に伝えます。これを行うには、最上位ディレクトリ(www フォルダの親フォルダ内)にある package.json を編集して、依存関係の 1 つとして socket.io を含めます。
JSON
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
次の更新したら、www フォルダ内の index.html を更新して socket.io ライブラリを含めます。
script.js の HTML スクリプトタグ インポートの上の次のコード行を、index.html ファイルの末尾付近に配置します。
index.html
<script src="/socket.io/socket.io.js"></script>
これで、index.html ファイルに次の 3 つのスクリプトタグが追加されます。
- 最初の TensorFlow.js ライブラリのインポート
- 追加した 2 回目の socket.io のインポート
- 最後のスクリプトは script.js コードをインポートするコード、
次に、server.js を編集してノード内で socket.io を設定し、受信したすべてのメッセージを、接続されているすべてのクライアントに中継するシンプルなバックエンドを作成します。
Node.js コードで行われる処理については、以下のコードコメントをご覧ください。
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
次のこれで、socket.io イベントをリッスンするウェブサーバーが作成されました。具体的には、クライアントから新しいコメントを受け取ると comment イベントが発生し、サーバー側では remoteComment イベントが発行されます。このイベントは、クライアントサイドのコードがリッスンし、リモートからのコメントを表示します。したがって、最後に行うのは、これらのイベントを出力して処理するためのクライアント側コードに socket.io のロジックを追加することです。
まず、次のコードを script.js の末尾に追加して socket.io サーバーに接続し、受信した remoteComment イベントをリッスンして処理します。
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
最後に、コメントがスパムでない場合に socket.io イベントを出力するためのコードを loadAndPredict 関数に追加します。このメッセージの内容を新しいクライアント コメント経由で中継できるため、他の接続済みクライアントにもこの新しいコメントで更新することができます。server.js上記で記述したコード
既存の loadAndPredict 関数を次のコードに置き換えて、最終的なスパムチェックに else ステートメントを追加します。コメントがスパムでない場合は、socket.emit() を呼び出してすべてのコメントデータを送信します。
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
これで手順に正しく従えば、index.html ページの 2 つのインスタンスを開くことができます。
スパムでないコメントを投稿すると、他のクライアントではほぼ瞬時に表示されます。コメントがスパムである場合、そのメールは送信されず、フロントエンドでのみ次のようにスパムとしてマークされます。
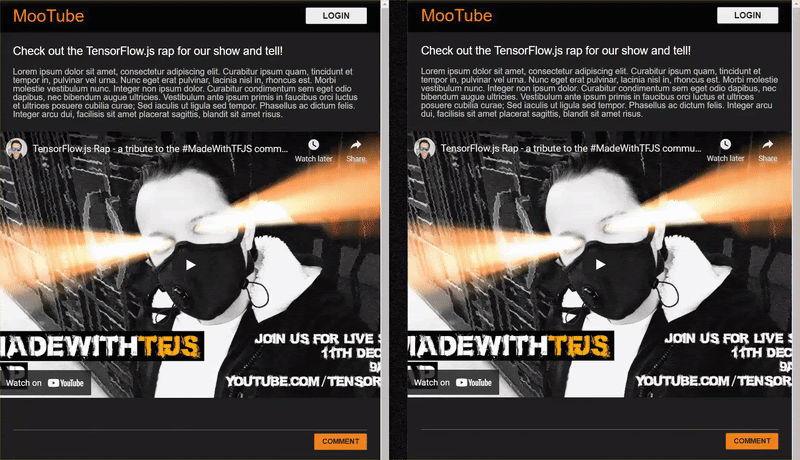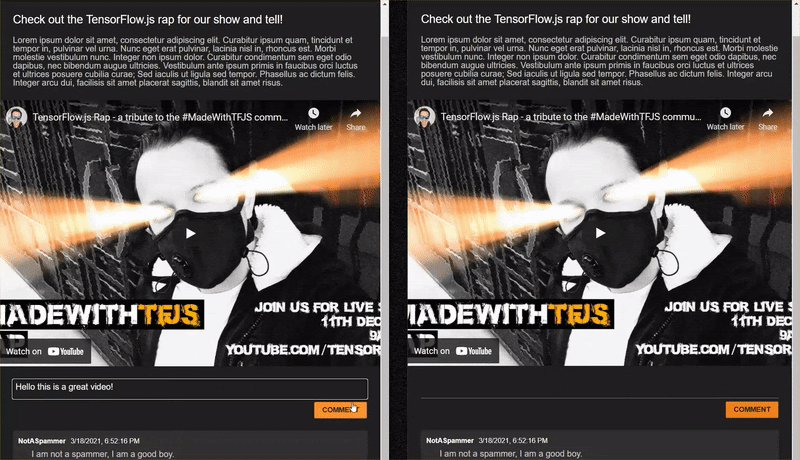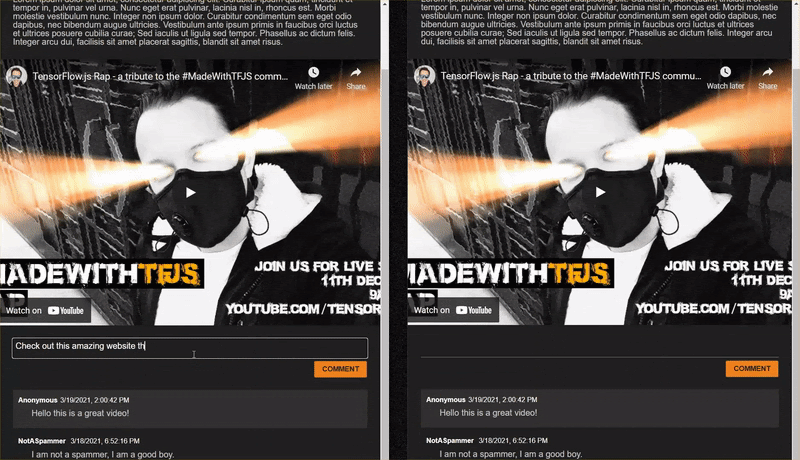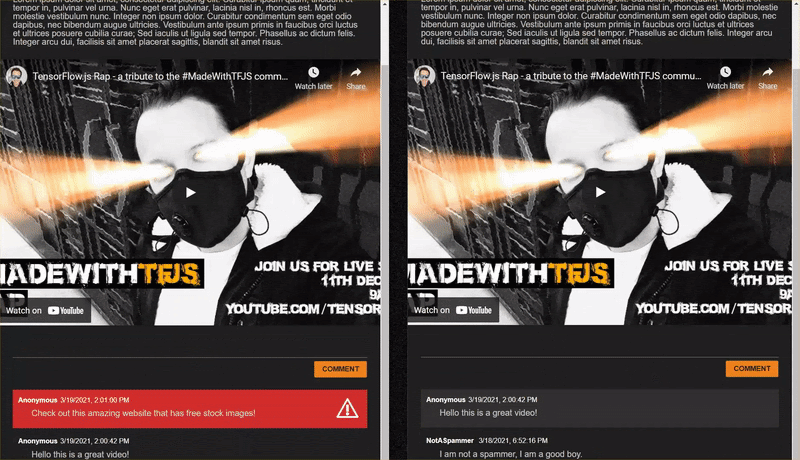
12. 完了
おつかれさまでした。これで、ウェブブラウザで TensorFlow.js を使用して機械学習を導入し、実世界のアプリケーション(コメントスパム)を検出できるようになりました。
さまざまなコメントで試してみましょう。問題が解決されない場合もあります。また、入力する単語が 20 語を超える場合、入力が 20 単語と想定されるため、現在のところ失敗します。
その場合、長い文を 20 語のグループに分割し、各文のスパムの可能性を考慮して判断する必要があります。さまざまなアプローチがあるため、テスト可能な任意タスクとして残しておきます。
次の Codelab では、現在検出されていないエッジケースのカスタム コメントデータを使用してこのモデルを再トレーニングする方法、さらにはそのモデルを TensorFlow.js でエクスポートして使用します。
なんらかの理由で問題が発生した場合は、こちらの完全版とコードを比較して、見落としていないかご確認ください。
内容のまとめ
この Codelab では次のことを学びました。
- TensorFlow.js の概要と、自然言語処理用のモデルについて学習しました
- サンプルのウェブサイトについて、リアルタイムでコメントできる架空のウェブサイトを作成しました。
- ウェブページでの TensorFlow.js によるコメントスパム検出に適した事前トレーニング済み機械学習モデルの読み込み。
- 読み込まれた機械学習モデルで使用する文をエンコードし、そのエンコードを Tensor 内にカプセル化する方法を学びました。
- 機械学習モデルの出力を解釈して、確認のためにコメントを保留するかどうかを決定し、そうでない場合はリアルタイムで他のクライアントに接続するためにサーバーに送信する。
次のステップ
これで、実際に使える基礎的な知識を得ることができました。クリエイティブなアイデアを思いついたときは、この機械学習モデルをボイラープレートに実際に適用して応用できるものがないかと思います。
作成したものを共有する
他のクリエイティブ ユースケースでも、今回作成した機能を簡単に拡張できます。また、既成概念にとらわれずに、引き続きハッキングを行うことをおすすめします。
ソーシャル メディアで #MadeWithTFJS ハッシュタグを使用すると、作成したプロジェクトが TensorFlow ブログや 今後のイベント。作品づくりを楽しみにしています。
理解を深めるための TensorFlow.js のその他の Codelab
- このシリーズのパート 2 を参照し、現在スパムとして検出されていないエッジケースに対応するために、コメントスパム モデルを再トレーニングする方法を確認する。
- Firebase Hosting を使用して TensorFlow.js モデルを大規模にデプロイおよびホストします。
- 事前に作成されたオブジェクト検出モデルを使用したスマート ウェブカメラの作成(TensorFlow.js)
参考になるウェブサイト
- TensorFlow.js の公式ウェブサイト
- TensorFlow.js の事前作成済みモデル
- TensorFlow.js の API
- TensorFlow.js の「Show & Tell」機能 - インスピレーションを得て、他のクリエイターの体験を見てみましょう。