
1. Hinweis
In den letzten zehn Jahren sind Web-Apps immer sozialer und interaktiver geworden. Potenzielle Zehntausende Nutzer haben die Möglichkeit, Multimedia-Inhalte, Kommentare und andere Inhalte auf Echtzeit zu nutzen, selbst auf einer mäßig beliebten Website.
Diese Methode bietet Spammern außerdem die Möglichkeit, solche Systeme zu missbrauchen und weniger anzügliche Inhalte mit von ihnen verfassten Artikeln, Videos und Beiträgen zu verknüpfen, um die Sichtbarkeit zu vergrößern.
Ältere Methoden der Spamerkennung, z. B. eine Liste blockierter Wörter, können einfach umgangen und nicht einfach für erweiterte Spam-Bots verwendet werden, die immer komplexer werden. Heutzutage können Sie mit Machine Learning-Modellen lernen, die speziell für die Erkennung von Spam entwickelt wurden.
Bisher wurde das maschinelle Lernen zum Vorfiltern von Kommentaren auf Serverseite ausgeführt. Mit TensorFlow.js können Sie Modelle für maschinelles Lernen jedoch jetzt clientseitig über JavaScript ausführen. Sie können Spam stoppen, noch bevor er das Back-End berührt, was potenziell teure serverseitige Ressourcen sparen kann.
Wie Sie vielleicht wissen, ist maschinelles Lernen heutzutage sehr beliebt und ergreift fast alle Branchen. Wie können Sie jedoch diese Funktionen als Webentwickler nutzen?
In diesem Codelab lernen Sie, wie Sie mithilfe eines Natural Language Processing (der Kunst der menschlichen Sprache mit einem Computer) ein Web-App aus einem leeren Canvas erstellen und damit das eigentliche Problem von Kommentar-Spam lösen. Dieses Problem lässt sich häufig durch Webentwickler beheben, die aktuell an einer der zunehmend wachsenden Zahl beliebter Webanwendungen arbeiten. Dieses Codelab ermöglicht es Ihnen, solche Probleme effizient zu bewältigen.
Voraussetzungen
Dieses Codelab wurde für Webentwickler entwickelt, die noch nicht mit maschinellem Lernen vertraut sind und vortrainierte Modelle mit TensorFlow.js nutzen möchten.
Für dieses Lab wird davon ausgegangen, dass Sie mit HTML5, CSS und JavaScript vertraut sind.
Lerninhalte
Sie werden Folgendes tun:
- Hier erfahren Sie, was TensorFlow.js ist und welche Modelle für die Natural Language Processing vorhanden sind.
- Erstellen Sie eine einfache HTML-/CSS-/JS-Webseite für einen fiktiven Videoblog mit einem Kommentarbereich in Echtzeit.
- Mit TensorFlow.js können Sie ein vortrainiertes Modell für maschinelles Lernen laden. Damit lässt sich vorhersagen, ob ein Satz wahrscheinlich Spam ist oder nicht. Ist das der Fall, warnen Sie den Nutzer vor der Moderation, dass sein Kommentar zurückgehalten wurde.
- Codieren Sie Kommentarsätze so, dass sie vom ML-Modell verwendet werden können, um sie dann zu klassifizieren.
- Interpretieren Sie die Ausgabe des Modells für maschinelles Lernen, um zu entscheiden, ob der Kommentar automatisch gemeldet werden soll. Diese hypothetische UX kann auf jeder Website wiederverwendet werden, an der Sie gerade arbeiten, und an jeden Anwendungsfall angepasst. Das kann z. B. ein herkömmlicher Blog, ein Forum oder eine Form von CMS wie Drupal sein.
Ziemlich übersichtlich. Ist das schwierig? Leider falsch. Lassen Sie uns also beginnen...
Voraussetzungen
- ein Glitch.com-Konto wird bevorzugt und du kannst eine Web-Bereitstellungsumgebung verwenden, die du selbst bearbeiten und selbst verwenden kannst.
2. Was ist TensorFlow.js?

TensorFlow.js ist eine Open-Source-Bibliothek für maschinelles Lernen, die mit JavaScript ausgeführt werden kann. Sie basiert auf der ursprünglichen in Python geschriebenen TensorFlow-Bibliothek und versucht, diese Entwicklungsumgebung und eine Reihe von APIs für die JavaScript-Umgebung neu zu erstellen.
Wo kann die Funktion verwendet werden?
Dank der Portabilität von JavaScript kannst du jetzt mühelos in 1 Sprache schreiben und maschinelles Lernen auf allen folgenden Plattformen ausführen:
- Clientseite im Webbrowser mit Vanilla-JavaScript
- Serverseitige und sogar IoT-Geräte wie Raspberry Pi mit Node.js
- Desktop-Apps mit Electron
- Native mobile Apps mit React Native
TensorFlow.js unterstützt außerdem mehrere Back-Ends in jeder dieser Umgebungen (die tatsächlichen hardwarebasierten Umgebungen, in denen es beispielsweise ausgeführt werden kann, z. B. die CPU oder WebGL). „Back-End“ bedeutet in diesem Zusammenhang nicht eine serverseitige Umgebung. Das Back-End kann beispielsweise clientseitig in WebGL sein, um die Kompatibilität zu gewährleisten und dafür zu sorgen, dass alles schnell läuft. Derzeit unterstützt TensorFlow.js Folgendes:
- WebGL-Ausführung auf der Grafikkarte des Geräts (GPU): Dies ist die schnellste Möglichkeit, größere Modelle (mit mehr als 3 MB) mit GPU-Beschleunigung auszuführen.
- Web Assembly (WASM)-Ausführung auf CPU – zur Verbesserung der CPU-Leistung auf Geräten, z. B. auf älteren Smartphones Diese Option eignet sich besser für kleinere Modelle (mit weniger als 3 MB), die aufgrund des Aufwands für das Hochladen von Inhalten in einen Grafikprozessor mit WASM auf der CPU schneller als mit WebGL ausgeführt werden können.
- CPU-Ausführung: Das Fallback sollte keine der anderen Umgebungen verfügbar sein. Dies ist der langsamste der drei, aber immer für Sie da.
Hinweis:Sie können eines dieser Back-Ends erzwingen, wenn Sie wissen, auf welchem Gerät Sie sie ausführen werden. Alternativ können Sie einfach TensorFlow.js nutzen, um die Entscheidung zu treffen.
Clientseitige Superkräfte
Die Ausführung von TensorFlow.js im Webbrowser auf dem Clientcomputer kann mehrere Vorteile bieten, die sich lohnt.
Datenschutz
Sie können Daten auf dem Client-Computer sowohl trainieren als auch klassifizieren, ohne Daten an einen Webserver eines Drittanbieters zu senden. Es kann vorkommen, dass dies zur Einhaltung lokaler Gesetze wie der DSGVO oder zur Verarbeitung von Daten erforderlich ist, die Nutzer auf ihrem Computer behalten und nicht an Dritte senden möchten.
Geschwindigkeit
Da Sie keine Daten an einen Remote-Server senden müssen, kann die Inferenz, also die Klassifizierung der Daten, schneller sein. Darüber hinaus haben Sie direkten Zugriff auf die Sensoren des Geräts, z. B. Kamera, Mikrofon, GPS, Beschleunigungsmesser und mehr, wenn der Nutzer Ihnen Zugriff gewährt.
Reichweite und Skalierung
Mit nur einem Klick kann jeder auf die von Ihnen gesendeten Links klicken und die Webseite im Browser öffnen. Sie brauchen für die Nutzung des maschinellen Lernsystems keine komplexe serverseitige Linux-Einrichtung mit CUDA-Treibern und vielem mehr.
Kosten
Keine Server bedeutet, dass Sie nur für das Hosten Ihrer HTML-, CSS-, JS- und Modelldateien ein CDN bezahlen müssen. Die Kosten für ein CDN sind viel günstiger als das Arbeiten eines Servers (möglicherweise mit angehängter Grafikkarte), der rund um die Uhr läuft.
Serverseitige Funktionen
Wenn Sie die Node.js-Implementierung von TensorFlow.js nutzen, werden die folgenden Funktionen aktiviert.
Vollständige Unterstützung von CUDA
Auf Serverseite müssen Sie zur Beschleunigung der Grafikkarte die NVIDIA CUDA-Treiber installieren, damit TensorFlow mit der Grafikkarte funktionieren kann. Im Browser funktioniert hierfür WebGL. Sie müssen nichts weiter installieren. Dank des umfassenden CUDA-Supports können Sie die Funktionen der untergeordneten Grafikkarte jedoch auch vollständig nutzen und so schneller trainieren und enden. Die Leistung entspricht der Implementierung von Python TensorFlow, da beide dasselbe C++-Back-End haben.
Modellgröße
Wenn Sie hochmoderne Modelle aus Forschungsergebnissen nutzen möchten, arbeiten Sie möglicherweise mit sehr großen Modellen, die möglicherweise Gigabyte im Umfang haben. Diese Modelle können aufgrund der Beschränkungen der Arbeitsspeichernutzung pro Tab im Browser momentan nicht im Webbrowser ausgeführt werden. Zum Ausführen dieser größeren Modelle können Sie Node.js auf Ihrem eigenen Server mit den Hardwarespezifikationen verwenden, die Sie für ein effizientes Ausführen eines solchen Modells benötigen.
IoT
Node.js wird auf gängigen Einzelplatinen-Computern wie Raspberry Pi unterstützt, was bedeutet, dass Sie auch TensorFlow.js-Modelle auf solchen Geräten ausführen können.
Geschwindigkeit
Node.js ist in JavaScript geschrieben, d. h., es profitieren direkt von der rechtzeitigen Kompilierung. Aus diesem Grund kann es bei der Verwendung von Node.js häufig zu Leistungssteigerungen kommen, da es während der Laufzeit optimiert wird, insbesondere bei Vorabverarbeitung. Ein gutes Beispiel hierfür finden Sie in dieser Fallstudie. Darin wird gezeigt, wie Hugging Face Node.js für das Natural Language Processing-Modell um das 2-Fache erhöht.
Sie kennen nun die Grundlagen von TensorFlow.js und die Vorteile. Sehen wir uns nun einige der Vorteile an.
3. Vortrainierte Modelle
Warum sollte ich ein vortrainiertes Modell verwenden?
Ein beliebtes vortrainiertes Modell bietet zahlreiche Vorteile, wenn es zu Ihrem gewünschten Anwendungsfall passt. Beispiele:
- Sie müssen selbst keine Trainingsdaten erheben. Daten im richtigen Format zu erstellen und mit einem Label zu versehen, damit ein ML-System daraus lernen kann, kann sehr zeitaufwendig und kostspielig sein.
- Die Fähigkeit, eine Idee schnell mit Prototypen und geringeren Kosten zu erstellen.
Es gibt keinen Sinn, das Rad neu zu erfinden, wenn ein vortrainiertes Modell ausreichend genug ist, um das zu tun, was Sie benötigen. - Verwenden Sie hochmoderne Forschung. Vortrainierte Modelle basieren oft auf beliebten Forschungsergebnissen. Sie erhalten also Informationen zu solchen Modellen und können ihre Leistung in der realen Welt beurteilen.
- Nutzerfreundlichkeit und umfassende Dokumentation Aufgrund der Beliebtheit solcher Modelle.
- Transfer Learning Funktionen. Einige vortrainierte Modelle bieten Lerntransferfunktionen. Bei dieser werden übertragene Informationen von einer ML-Aufgabe in ein ähnliches Beispiel übertragen. Ein Modell, das ursprünglich dafür trainiert wurde, Katzen zu erkennen, kann beispielsweise neu trainiert werden, um Hunde zu erkennen, sofern Sie es neue Trainingsdaten bereitgestellt haben. Das geht schneller, da du nicht mit einem leeren Canvas beginnst. Das Modell kann das Gelernte verwenden, um Katzen zu erkennen, um dann das neue wahrzunehmen. Hunde haben auch Augen und Ohren. Wenn sie bereits weiß, wie sie diese Merkmale finden können, ist sie bereits auf halber Strecke. Sie können das Modell viel schneller neu trainieren.
Ein vortrainiertes Spamerkennungsmodell für Kommentare
Sie verwenden die Architektur „Durchschnittliche Worteinbettung“ zur Erkennung von Spamkommentaren. Wenn Sie jedoch ein nicht trainiertes Modell verwenden, ist es besser, als zu erraten, ob es sich bei den Sätzen um Spam handelt.
Damit das Modell nützlich ist, muss es mit benutzerdefinierten Daten trainiert werden, damit es erkennen kann, wie Spam bzw. Nicht-Spam-Kommentare aussehen. Dadurch ist es dann besser, die Dinge in Zukunft richtig einzuordnen.
Zum Glück wurde diese genaue Modellarchitektur bereits für diese Aufgabe zur Klassifizierung von Spamkommentaren trainiert, sodass Sie diese als Ausgangspunkt verwenden können. Unter Umständen werden vortrainierte Modelle mit derselben Modellarchitektur für verschiedene Zwecke verwendet, z. B. um zu ermitteln, in welcher Sprache ein Kommentar geschrieben wurde, oder die Vorhersage, ob Daten zu Website-Kontaktformularen automatisch an ein bestimmtes Unternehmensteam weitergeleitet werden sollen, basierend auf dem geschriebenen Text, z. B. Verkäufe (Produktanfrage) oder Technik (technischer Fehler oder Feedback). Mit genügend Trainingsdaten kann ein Modell wie dieses lernen, einen solchen Text zu klassifizieren, um Ihre Web-App-Superkräfte zu verbessern und die Effizienz Ihrer Organisation zu verbessern.
In einem zukünftigen Code-Lab erfahren Sie, wie Sie mit diesem Modell dieses vortrainierte Spammodell für Kommentare neu trainieren und es anschließend weiter verbessern können. In der Zwischenzeit können Sie das vorhandene Modell zur Spamerkennung von Kommentaren als Ausgangspunkt verwenden, damit die erste Webanwendung als erster Prototyp funktioniert.
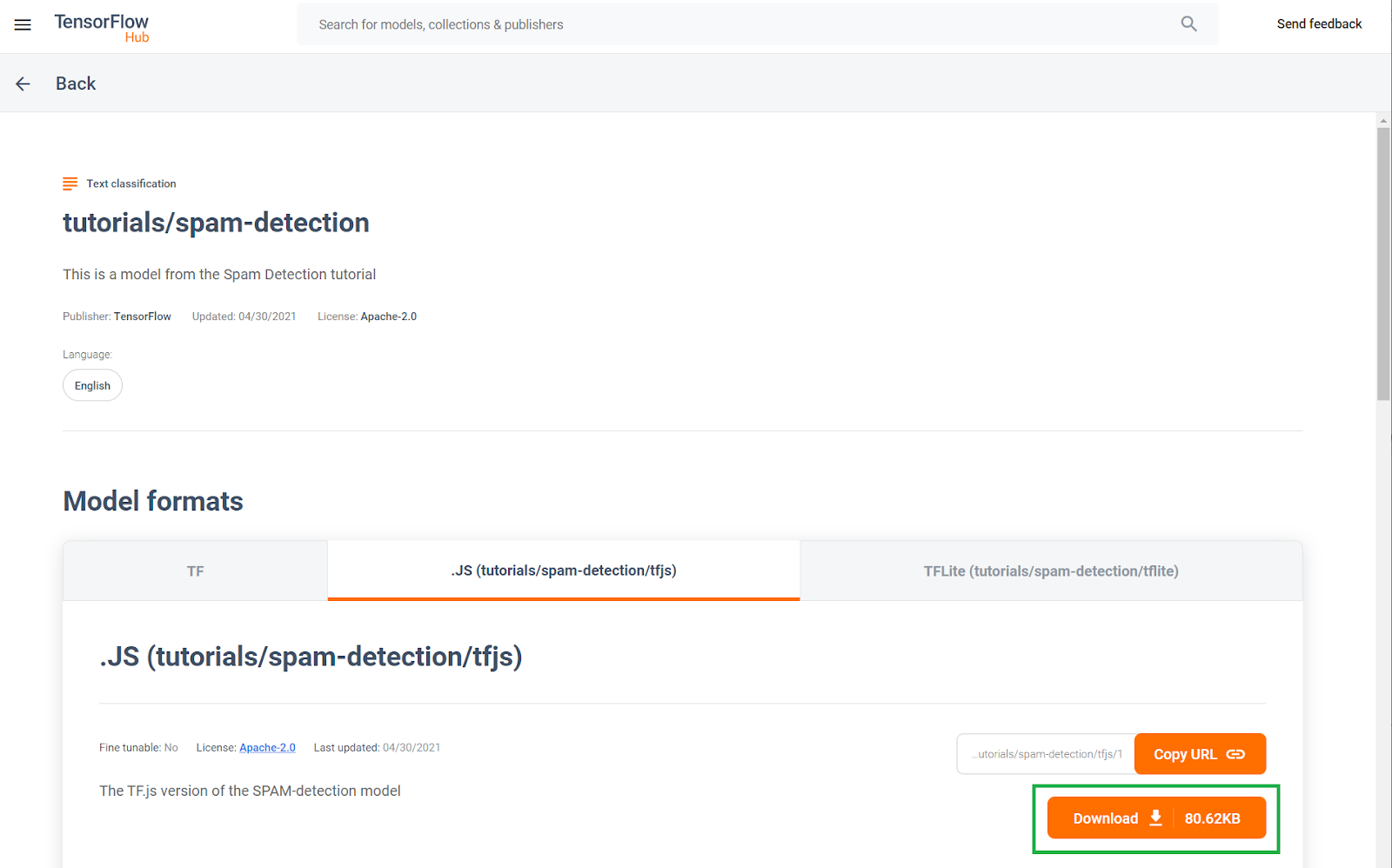
Dieses vortrainierte Spamerkennungsmodell für Kommentare wurde auf einer Website namens TF Hub veröffentlicht. Dies ist ein von Google verwaltetes Modell für maschinelles Lernen, mit dem ML-Entwickler ihre vorgefertigten Modelle für viele gängige Anwendungsfälle (z. B. Text, Bild und Ton) für bestimmte Anwendungsfälle innerhalb dieser Kategorien veröffentlichen können. Laden Sie die Modelldateien jetzt herunter und verwenden Sie sie später in diesem Codelab in der Web-App.
Klicken Sie auf die Downloadschaltfläche für das JS-Modell (siehe unten):
4. Code einrichten
Voraussetzungen
- Ein moderner Webbrowser.
- Grundkenntnisse in HTML, CSS, JavaScript und Chrome-Entwicklertools (Konsolenausgabe ansehen)
Lass Code programmieren.
Wir haben eine Glitch.com-Node.js-Express-Textzeile erstellt, mit der Sie mit nur einem Klick als Basisstatus für dieses Code-Lab klonen können.
Klicke in Glitch einfach auf die Schaltfläche &ret;remixt, um ihn zu verzweigen, und erstelle einen neuen Satz von Dateien, den du bearbeiten kannst.
Dieses einfache Skelett stellt uns die folgenden Dateien im Ordner www zur Verfügung:
- HTML-Seite (index.html)
- Stylesheet (style.css)
- Datei zum Schreiben unseres JavaScript-Codes (script.js)
Wir haben in der HTML-Datei auch einen Import für die TensorFlow.js-Bibliothek hinzugefügt, der so aussieht:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Dieser www-Ordner wird dann über einen einfachen Node Express-Server über package.json und server.js bereitgestellt
5. App-HTML-Boilerplate
Was ist der Ausgangspunkt?
Für alle Prototypen ist ein grundlegendes HTML-Gerüst erforderlich, auf dem die Ergebnisse gerendert werden können. Jetzt einrichten. Folgendes soll hinzugefügt werden:
- Ein Titel für die Seite
- Beschreibung
- Ein Platzhaltervideo für den Videoblogeintrag
- Ein Bereich, in dem Kommentare angezeigt und eingegeben werden können
Öffnen Sie index.html und fügen Sie den vorhandenen Code mit dem folgenden Code ein, um die oben genannten Funktionen einzurichten:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Aufschlüsselung
Lassen Sie uns einen der oben genannten HTML-Codes aufschlüsseln, um einige der von Ihnen hinzugefügten wichtige Elemente hervorzuheben.
- Sie haben ein
<h1>-Tag für den Seitentitel sowie ein<a>-Tag für die Anmeldeschaltfläche hinzugefügt, die alle in der<header>enthalten sind. Anschließend hast du ein<h2>für den Artikeltitel und ein<p>-Tag für die Beschreibung des Videos hinzugefügt. Hier ist nichts Besonderes. - Sie haben ein
iframe-Tag hinzugefügt, über das ein beliebiges YouTube-Video eingebettet wird. Derzeit verwenden Sie den gewaltigen TensorFlow.js-Rap als Platzhalter. Sie können aber ein beliebiges Video einfügen, indem Sie die URL des iFrames ändern. Auf einer Produktionswebsite werden alle diese Werte je nach aufgerufener Seite dynamisch vom Back-End gerendert. - Schließlich haben Sie ein
sectionmit einer ID und der Klasse „comments"“ hinzugefügt, die einen inhaltsrelevantendiventhält, über den Sie neue Kommentare schreiben können, sowie einenbutton, um den neuen Kommentar, der hinzugefügt werden soll, sowie eine ungeordnete Liste von Kommentaren einzureichen. Der Nutzername und die Uhrzeit der Veröffentlichung befinden sich innerhalb einesspan-Tags innerhalb jedes Listenelements und schließlich der Kommentar selbst in einemp-Tag. 2 Beispielkommentare sind derzeit als Platzhalter hartcodiert.
Wenn Sie sich die Vorschau jetzt ansehen, sollte sie in etwa so aussehen:
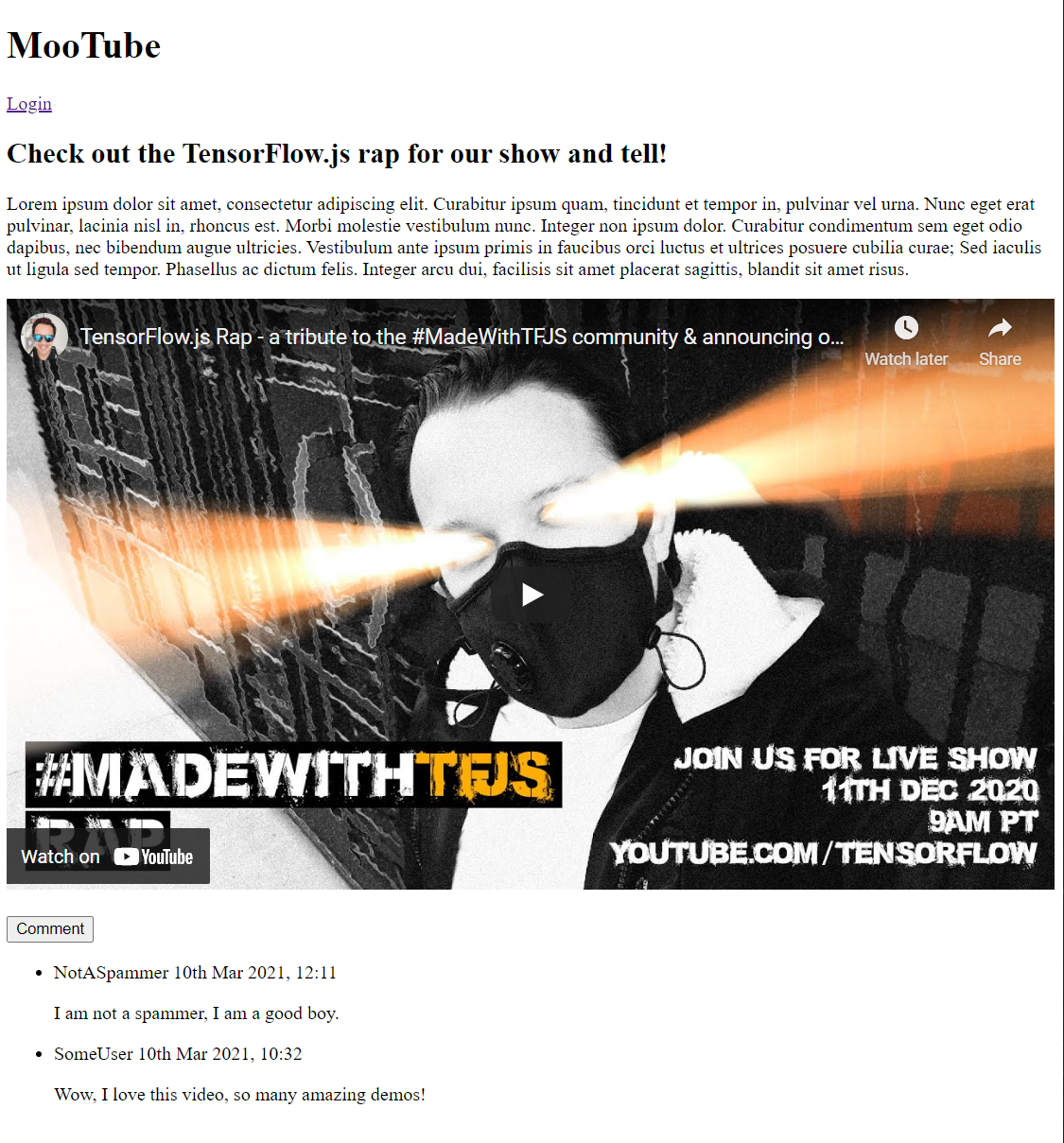
Das ist echt schrecklich. Daher wird es Zeit, etwas Stil hinzuzufügen...
6. Stil hinzufügen
Standardeinstellungen für Elemente
Fügen Sie zuerst die Stile der HTML-Elemente hinzu, die Sie gerade hinzugefügt haben, damit sie richtig gerendert werden.
Verwenden Sie zuerst ein CSS-Zurücksetzen, um einen Kommentarstart in allen Browsern und Betriebssystemen zu haben. style.css-Inhalte folgendermaßen überschreiben:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
Hängen Sie als Nächstes dieses nützliche CSS an, um die Benutzeroberfläche zum Leben zu erwecken.
Fügen Sie unter style.css oben unter dem zuvor hinzugefügten CSS-Code Folgendes ein:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Super! Mehr ist nicht alles. Wenn Sie die Designs mit den beiden Codeelementen oben überschrieben haben, sollte Ihre Livevorschau jetzt so aussehen:
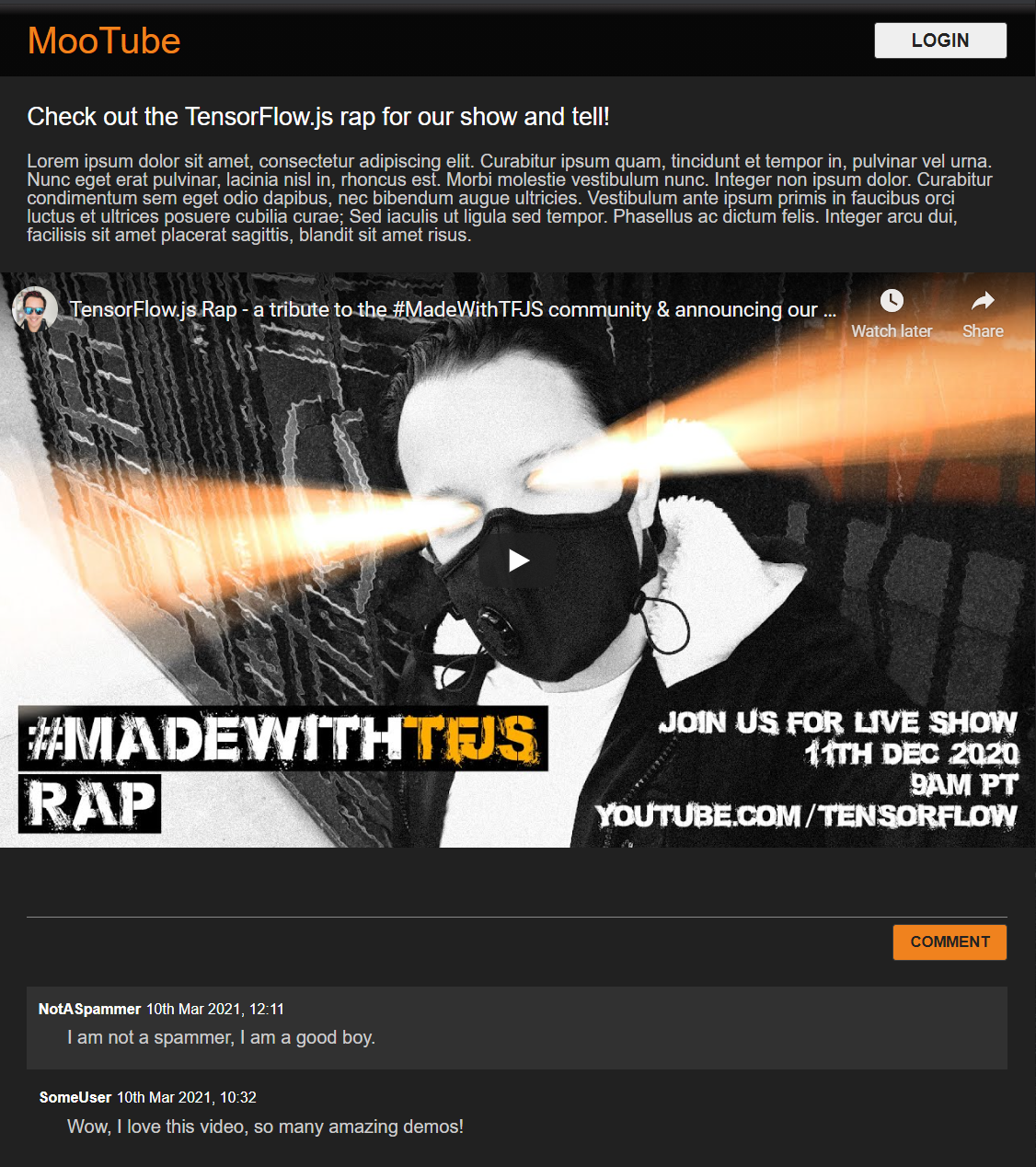
Süßer, standardmäßiger Nachtmodus und charmante CSS-Übergänge für Mouseover-Effekte an wichtigen Elementen. Sieht gut aus. Integrieren Sie jetzt eine Verhaltenslogik mit JavaScript.
7. JavaScript: DOM-Manipulation &Event-Handler
Verweis auf wichtige DOM-Elemente
Stellen Sie zuerst sicher, dass Sie auf die Hauptbereiche der Seite zugreifen können, die Sie später im Code bearbeiten oder aufrufen möchten. Außerdem müssen Sie einige Konstanten der CSS-Klasse für das Formatieren definieren.
Ersetzen Sie zuerst den Inhalt von script.js durch die folgenden Konstanten:
Skript.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Umgang mit Kommentaren
Fügen Sie als Nächstes einen Ereignis-Listener und eine Verarbeitungsfunktion zum Objekt POST_COMMENT_BTN hinzu. Dieser kann dann den geschriebenen Kommentartext abrufen und eine CSS-Klasse festlegen, um anzugeben, dass die Verarbeitung gestartet wurde. Achten Sie darauf, dass Sie nicht bereits auf die Schaltfläche geklickt haben, falls die Verarbeitung bereits läuft.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Super! Wenn Sie die Webseite aktualisieren und versuchen, einen Kommentar zu posten, sehen Sie jetzt die Kommentarschaltfläche und den Text in Graustufen. In der Konsole sollten Sie den Kommentar so sehen:
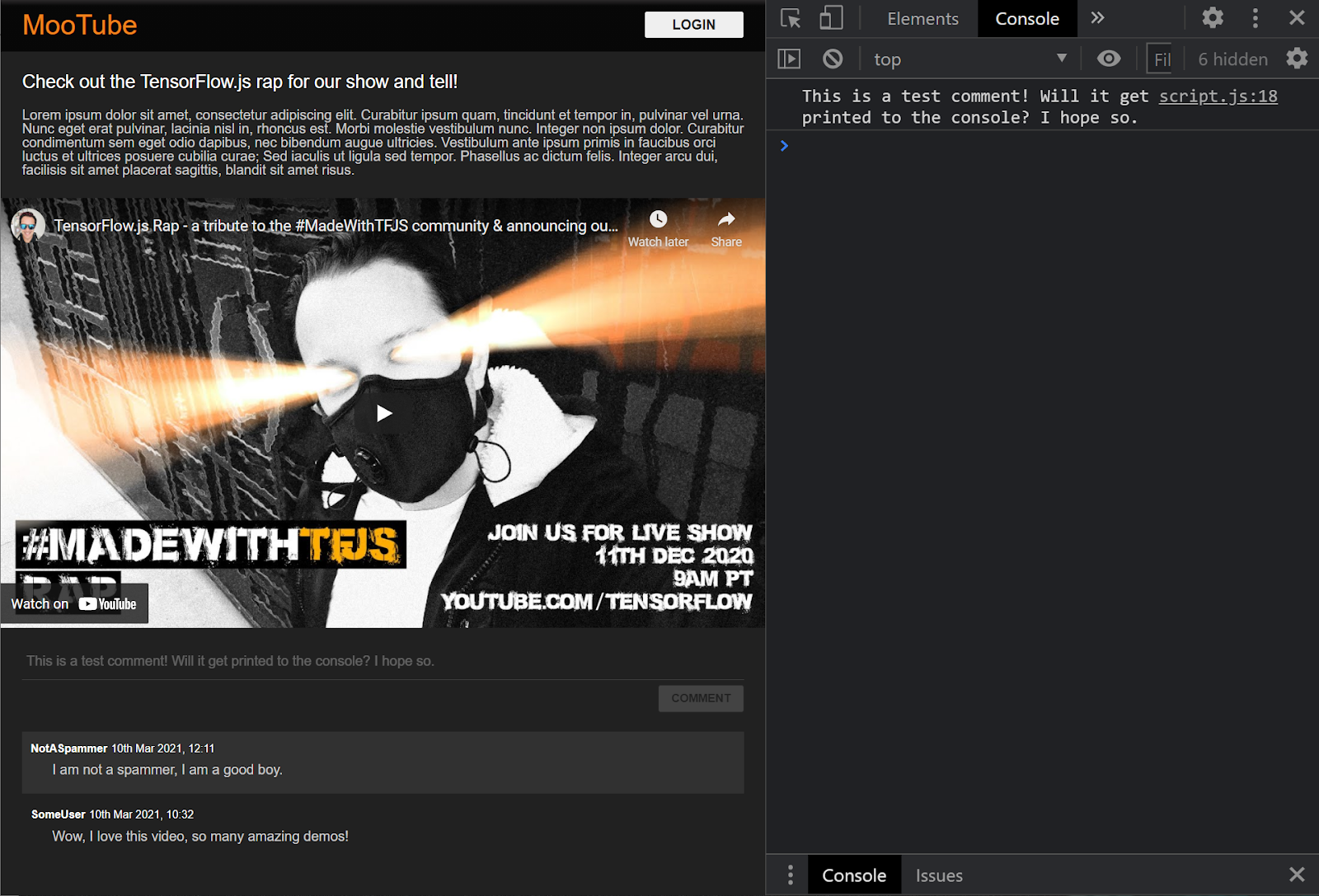
Da Sie jetzt ein grundlegendes HTML-/CSS-/JS-Skelett haben, sollten Sie sich wieder auf das Modell für maschinelles Lernen konzentrieren, damit Sie es in die ansprechende Webseite integrieren können.
8. ML-Modell bereitstellen
Sie sind jetzt fast bereit, das Modell zu laden. Zuvor müssen Sie jedoch die zuvor im Codelab heruntergeladenen Modelldateien auf Ihre Website hochladen, damit sie im Code gehostet und verwendet werden können.
Falls noch nicht geschehen, entpacken Sie die Dateien für das Modell zuerst am Anfang dieses Codelabs. Sie sollten ein Verzeichnis mit den folgenden Dateien sehen:
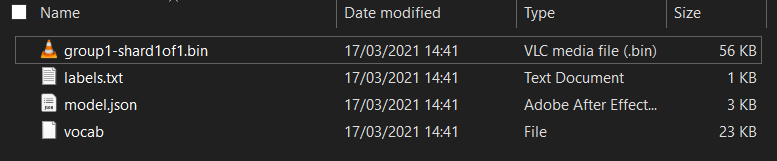
Was haben Sie hier?
model.json– Dies ist eine der Dateien, aus denen das trainierte TensorFlow.js-Modell besteht. Sie werden später in Ihrem TensorFlow.js-Code auf diese Datei verweisen.group1-shard1of1.bin: Dies ist eine Binärdatei mit den trainierten Gewichtungen (im Wesentlichen mehrere Zahlen, die zur Klassifizierungsaufgabe gut gelernt wurden) des TensorFlow.js-Modells. Sie muss irgendwo zum Download auf Ihrem Server gehostet werden.vocab– Diese ungewöhnliche Datei ohne Erweiterung stammt von Model Maker und zeigt uns, wie Wörter in den Sätzen codiert werden. So kann das Modell sie richtig verwenden. Im nächsten Abschnitt erfahren Sie mehr dazu.labels.txt: Dieser enthält nur die resultierenden Klassennamen, die das Modell vorhersagen wird. Wenn Sie diese Datei in Ihrem Texteditor öffnen, sind lediglich die Werte „"true“ und „true“ aufgelistet, mit denen „NOT“ bzw. „Spam“ oder „Spam“ als Vorhersageausgabe angezeigt wird.
TensorFlow.js-Modelldateien hosten
Platziere zuerst die model.json- und die *.bin-Dateien, die auf einem Webserver generiert wurden, damit du über die Webseite darauf zugreifen kannst.
Dateien in Glitch hochladen
- Klicke im linken Bereich deines Glitch-Projekts auf den Ordner assets.
- Klicken Sie auf Asset hochladen und wählen Sie
group1-shard1of1.binaus, um die Datei in diesen Ordner hochzuladen. Nach dem Hochladen sollte sie so aussehen:
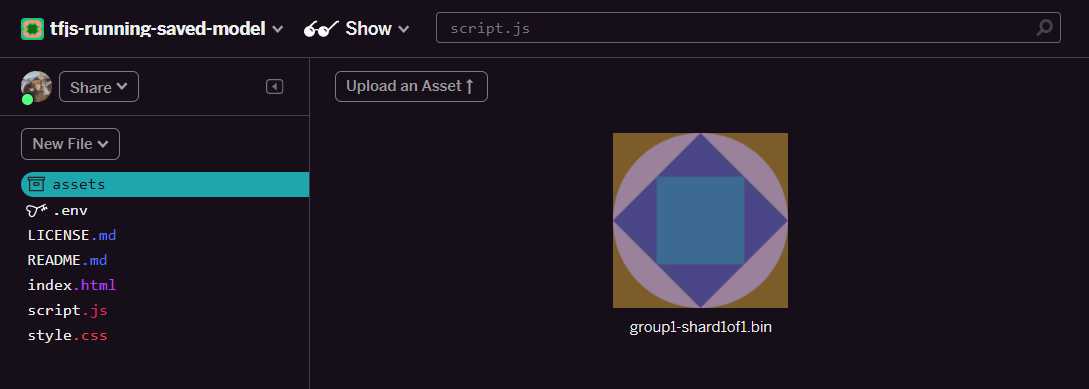
- Super! Wiederholen Sie diesen Schritt für die Datei
model.json. Zwei Dateien sollten im folgenden Ordner in deinem Asset-Ordner enthalten sein:
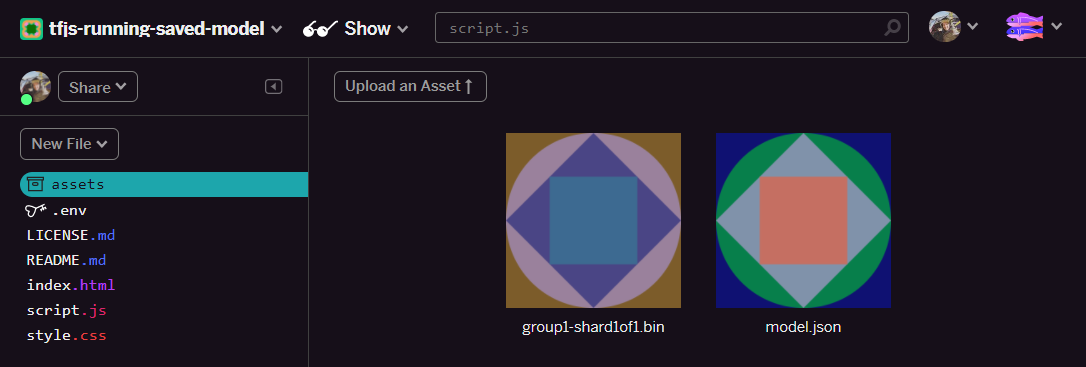
- Klicken Sie auf die
group1-shard1of1.bin-Datei, die Sie gerade hochgeladen haben. Sie können die URL an ihren Speicherort kopieren. Kopieren Sie diesen Pfad jetzt so:
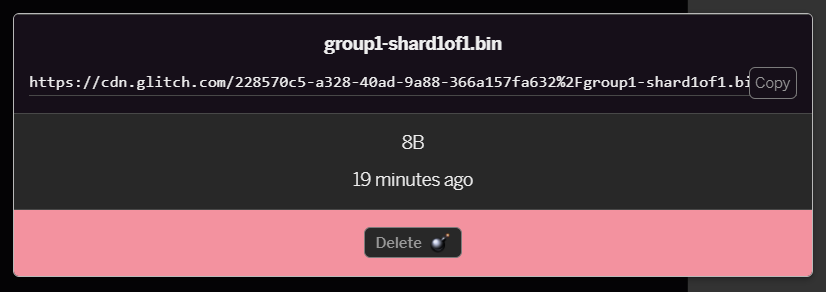
- Klicken Sie jetzt links unten auf Tools > Terminal. Warten Sie, bis das Terminalfenster geladen ist. Geben Sie nach dem Laden den folgenden Code ein und drücken Sie die Eingabetaste, um das Verzeichnis in den Ordner
wwwzu ändern:
Terminal:
cd www
- Lade dann mit
wgetdie beiden Dateien hoch, die du gerade hochgeladen hast. Ersetze die URLs unten durch die URLs, die du für die Dateien im Ordner assets in Glitch erstellt hast. Prüfe den Ordner für Assets für jede benutzerdefinierte URL. Der Abstand zwischen den beiden URLs und die zu verwendenden URLs unterscheiden sich von denen unten, sehen aber ähnlich aus:
Terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super, Sie haben jetzt eine Kopie der Dateien erstellt, die in den Ordner www hochgeladen wurden. Im Moment werden sie jedoch mit neuen Namen heruntergeladen.
- Geben Sie im Terminalfenster
lsein und drücken Sie die Eingabetaste. Die Ansicht sieht ungefähr so aus:

- Mit dem Befehl
mvkönnen Sie die Dateien umbenennen. Geben Sie Folgendes in die Konsole ein und drücken Sie nach jeder Zeile <kbd>Enter</kbd> oder <kbd>return</kbd>.
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Aktualisiere anschließend das Glitch-Projekt, indem du
refreshin das Terminal eingibst und <kbd>Enter</kbd> drückst:
terminal:
refresh
- Nach der Aktualisierung sollten jetzt
model.jsonundgroup1-shard1of1.binim Ordnerwwwder Benutzeroberfläche zu sehen sein:
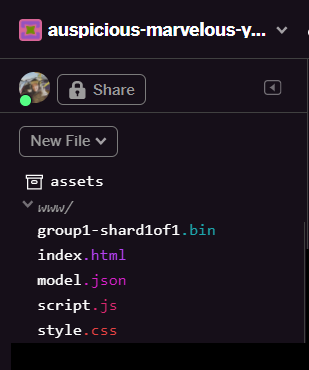
Super! Sie können die hochgeladenen Modelldateien jetzt mit etwas Code im Browser verwenden.
9. Gehostetes TensorFlow.js-Modell laden und verwenden
Jetzt können Sie das hochgeladene TensorFlow.js-Modell mit einigen Daten laden und prüfen, ob es funktioniert.
Im Folgenden sehen Sie die Beispieldaten, die Sie unten sehen, sehr geheimnisvoll – ein Array von Zahlen. Wie sie generiert werden, erfahren Sie im nächsten Abschnitt. Sehen Sie sich das Ganze erst einmal als Zahlenreihe an. In dieser Phase ist es wichtig, einfach zu testen, ob wir keine Fehler zurückgeben.
Füge den folgenden Code am Ende der Datei script.js ein. Achte darauf, den Stringwert MODEL_JSON_URL durch den Pfad der Datei model.json zu ersetzen, die du im vorherigen Schritt in den Ordner mit Glitch-Assets generiert hast. Hinweis: Wenn du die URL suchen möchtest, klicke einfach in Glitch im Ordner assets auf die Datei.
Lesen Sie die Kommentare zum neuen Code unten, um zu verstehen, was in der jeweiligen Zeile passiert:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Wenn das Projekt korrekt eingerichtet ist, sollten Sie in der Konsole Folgendes sehen, wenn Sie das geladene Modell verwenden, um ein Ergebnis aus den an Sie übergebenen Eingaben vorherzusagen:
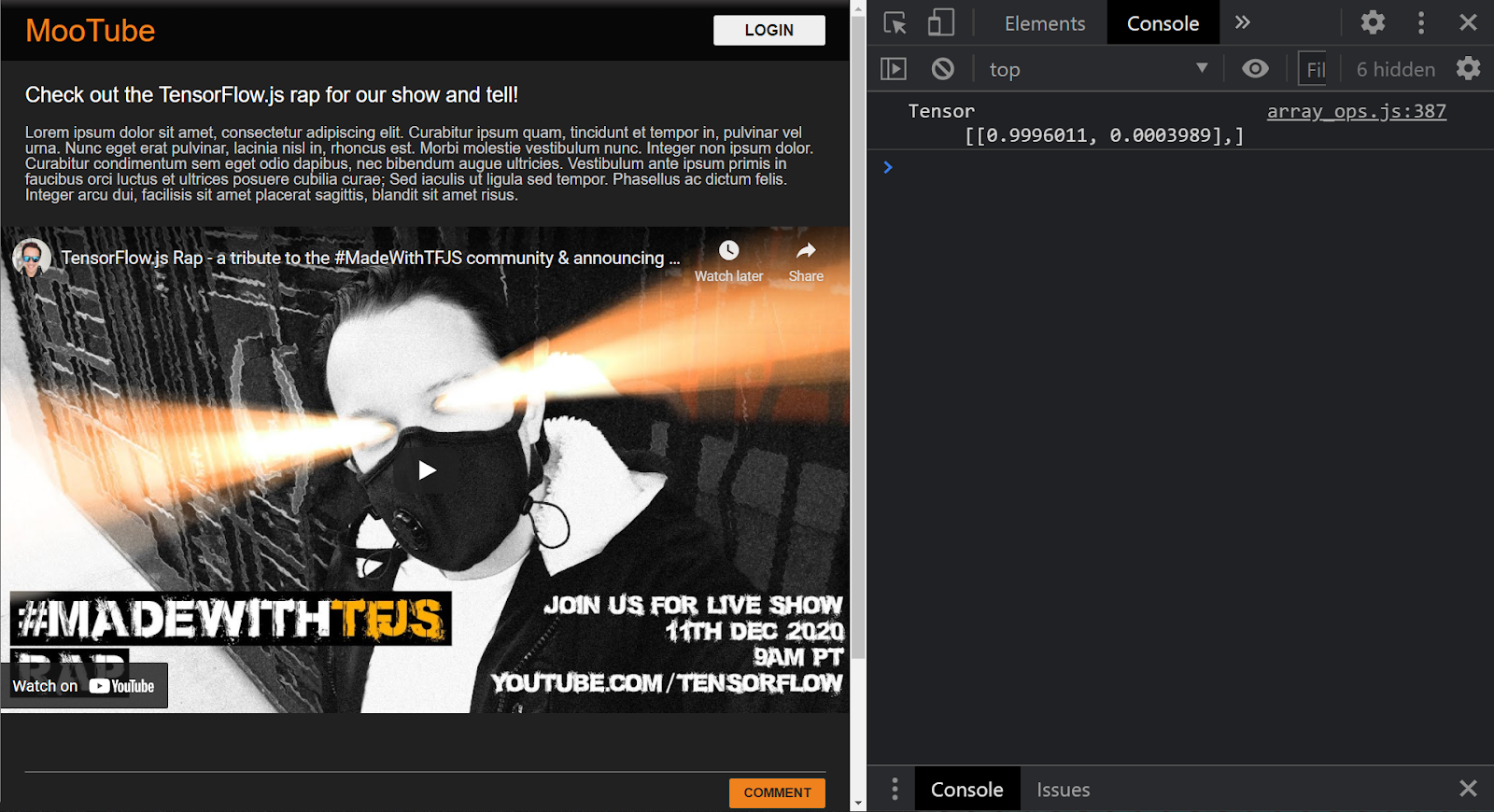
In der Konsole werden zwei Zahlen angezeigt:
- 0,9996011
- 0,0003989
Diese Zahl mag zwar kryptisch erscheinen, aber diese Zahlen entsprechen eigentlich Wahrscheinlichkeiten dafür, was das Modell der Klassifizierung für Ihre Eingabe vermutet. Aber wofür werden sie verwendet?
Wenn Sie die labels.txt-Datei aus den heruntergeladenen Modelldateien auf dem lokalen Computer öffnen, enthält sie auch zwei Felder:
- Falsch
- Wahr
Das Modell sagt in diesem Fall, dass es 99,96011% sicher ist (im Ergebnisobjekt 0,9996011 angezeigt), dass die Eingabe, die [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] gegeben wurde, NICHT Spam (also falsch) war.
Beachten Sie, dass false das erste Label in labels.txt ist und durch die erste Ausgabe im Konsolendruck dargestellt wird. So sehen Sie, auf was sich die Ausgabevorhersage bezieht.
Ok, jetzt wissen Sie also, wie die Ausgabe interpretiert wird. Aber was genau sind die großen Zahlen als Eingabe und wie wandeln Sie die Sätze in dieses Format um, damit das Modell verwendet werden kann? Dafür müssen Sie mehr über Tokenisierung und Tensoren erfahren. Am besten gleich weiterlesen!
10. Tokenisierung &Tensoren
Tokenisierung
Es ist also möglich, dass Modelle für maschinelles Lernen nur wenige Zahlen als Eingabe akzeptieren. Warum? Im Grunde ist es so, dass ein ML-Modell im Grunde eine Reihe von verketteten mathematischen Operationen ist. Wenn Sie also etwas übergeben, das keine Zahl ist, wird es schwierig, sich damit zu beschäftigen. Jetzt stellt sich die Frage: Wie wandelt man die Sätze in Zahlen um, damit sie für das von Ihnen geladene Modell verwendet werden können?
Der genaue Prozess unterscheidet sich von Modell zu Modell, aber für dieses Modell gibt es eine weitere Datei in den Modelldateien, die Sie heruntergeladen haben: vocab,und dies ist der Schlüssel zur Codierung von Daten.
Öffnen Sie vocab in einem lokalen Texteditor auf Ihrem Computer. Der Bildschirm sollte dann ungefähr so aussehen:
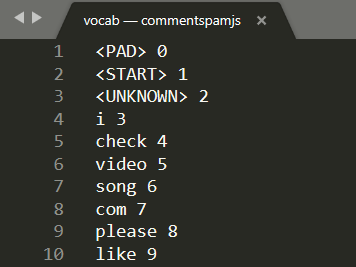
Im Grunde ist das eine Suchtabelle zur Umwandlung aussagekräftiger Wörter in Zahlen, die das Modell gelernt hat. Es gibt auch einige Sonderfälle oben in der Datei <PAD>, <START> und <UNKNOWN>:
<PAD>: Dieser Ausdruck steht für „Abstände“. Es stellt sich heraus, dass Modelle für maschinelles Lernen eine feste Anzahl von Eingaben haben, unabhängig davon, wie lang Ihr Satz ist. Bei dem verwendeten Modell wird davon ausgegangen, dass immer 20 Zahlen für die Eingabe vorhanden sind. Dies wurde vom Ersteller des Modells definiert und kann geändert werden, wenn Sie das Modell neu trainieren. Wenn du z. B. einen Satz wie „Ich mag Video“ hast, füllst du die verbleibenden Bereiche im Array mit 0' aus. Diese stellen das<PAD>-Token dar. Wenn der Satz mehr als 20 Wörter umfasst, müssen Sie ihn aufteilen, damit er dieser Anforderung entspricht. Mehrere Sätze werden dann mehrfach klassifiziert.<START>: Das ist einfach immer das erste Token, das den Anfang des Satzes angibt. Sie sehen in der Beispieleingabe in den vorherigen Schritten, dass das Array der Zahlen mit „&1“ beginnt – dies war das Token<START>.<UNKNOWN>– Wenn Sie das Wort in dieser Suche nicht finden, verwenden Sie einfach das Token<UNKNOWN>(durch &2 dargestellt) als Zahl.
Für alle anderen Wörter ist er entweder in der Suche vorhanden und ihm ist eine spezielle Nummer zugewiesen, sodass Sie diese verwenden würden oder sie nicht existiert. In diesem Fall verwenden Sie stattdessen die Token-Nummer <UNKNOWN>.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Wie Sie sehen, war das ein Satz mit vier Wörtern, da der Rest entweder <START>- oder <PAD>-Tokens ist und es 20 Zahlen im Array gibt. Ok, ich verstehe die Sache etwas besser.
Der Satz, den ich dazu schreibe, war „Mein Hund“. Im Screenshot oben sehen Sie, dass „I“ in die Zahl „3“ konvertiert wurde, die korrekt ist. Bei der Suche nach den anderen Wörtern würden Sie auch die entsprechenden Zahlen finden.
Tensor-
Bevor das ML-Modell Ihre numerische Eingabe akzeptiert, ist noch eine Hürde nötig. Sie müssen das Zahlenarray in einen sogenannten Tensor umwandeln. Ja, Sie haben es erraten: TensorFlow heißt so benannt nach: Tensor ist der Fluss des Tensors durch ein Modell.
Was ist ein Tensor?
Die offizielle Definition von TensorFlow.org lautet:
&COVID-19-Tensoren sind mehrdimensionale Arrays mit einem einheitlichen Typ. Alle Tensoren sind unveränderlich: Sie können niemals den Inhalt eines Tensors aktualisieren, sondern nur einen neuen erstellen."
Mit einfachen Worten ist es nur ein anspruchsvoller mathematischer Name für ein Array mit einer beliebigen Dimension, das einige andere Funktionen in das Tensor-Objekt integriert, die für uns als Entwickler von maschinellem Lernen nützlich sind. Hinweis: Tensor speichert nur Daten eines Typs (z. B. alle Ganzzahlen oder Gleitkommazahlen). Nach dem Erstellen kann der Inhalt eines Tensors nicht mehr geändert werden. Das ist eine permanente Speicherbox für Zahlen.
Mach dir jetzt erst einmal keine Gedanken darüber. Denken Sie zumindest an einen multidimensionalen Speichermechanismus, der für Modelle zum maschinellen Lernen geeignet ist, bis Sie sich mit einem guten Buch wie diesem vertraut machen können. Es wird dringend empfohlen, wenn Sie mehr über Tensoren erfahren möchten und wie Sie diese einsetzen möchten.
Zusammenfassung: Programmier-Tensoren und Tokenisierung
Wie wird die vocab-Datei im Code verwendet? Gute Frage.
Diese Datei ist für Sie als JavaScript-Entwickler ziemlich wenig nützlich. Es wäre viel besser, wenn dies ein JavaScript-Objekt wäre, das Sie einfach importieren und verwenden können. Die Konvertierung der Daten in dieser Datei sieht ganz einfach aus:
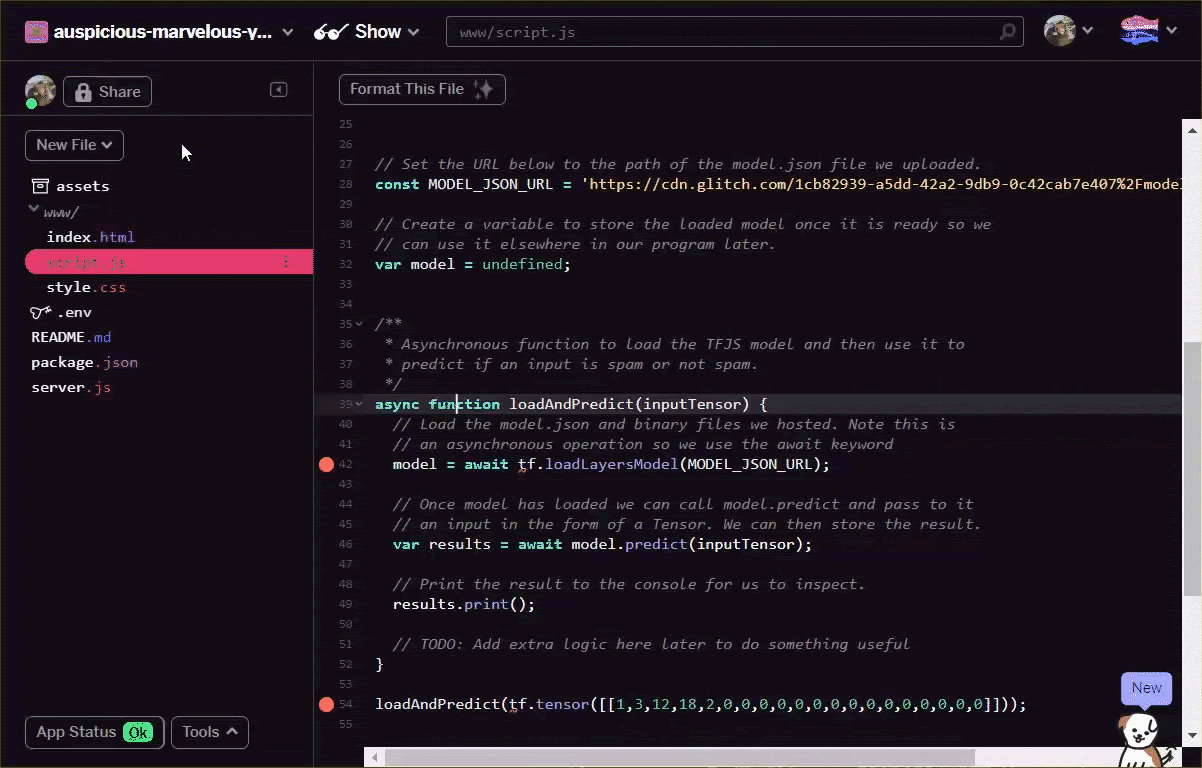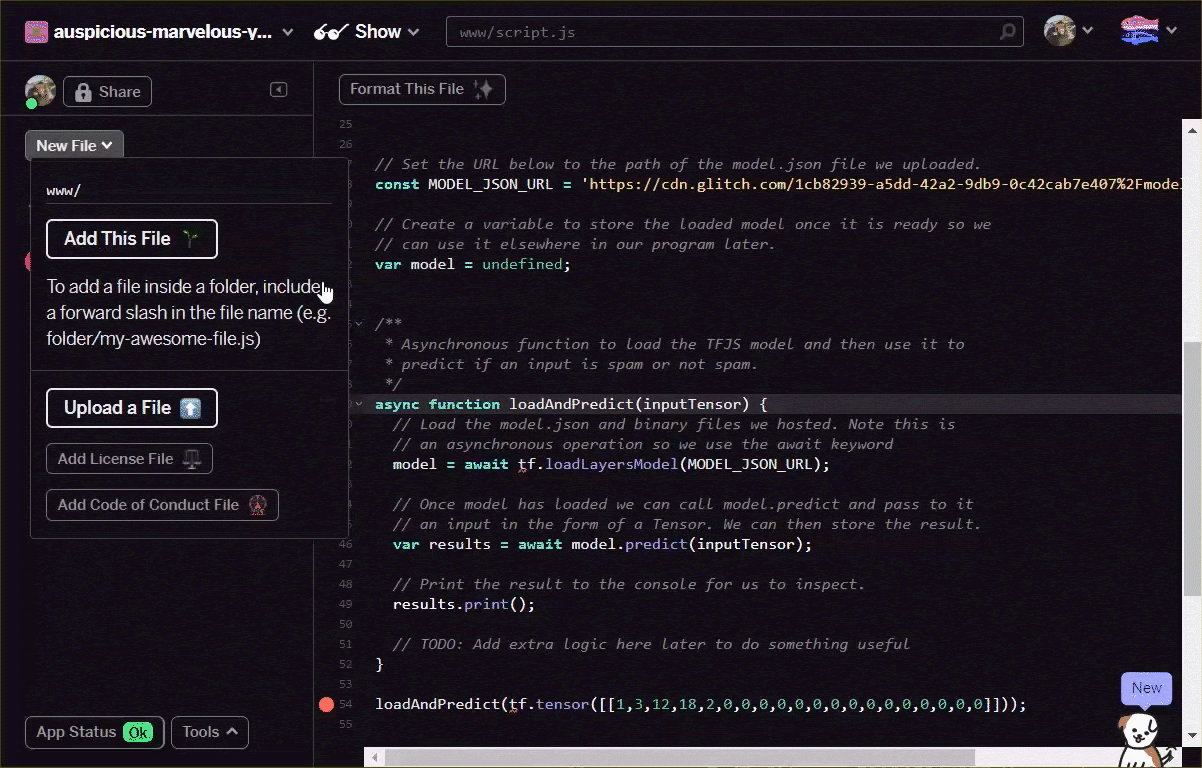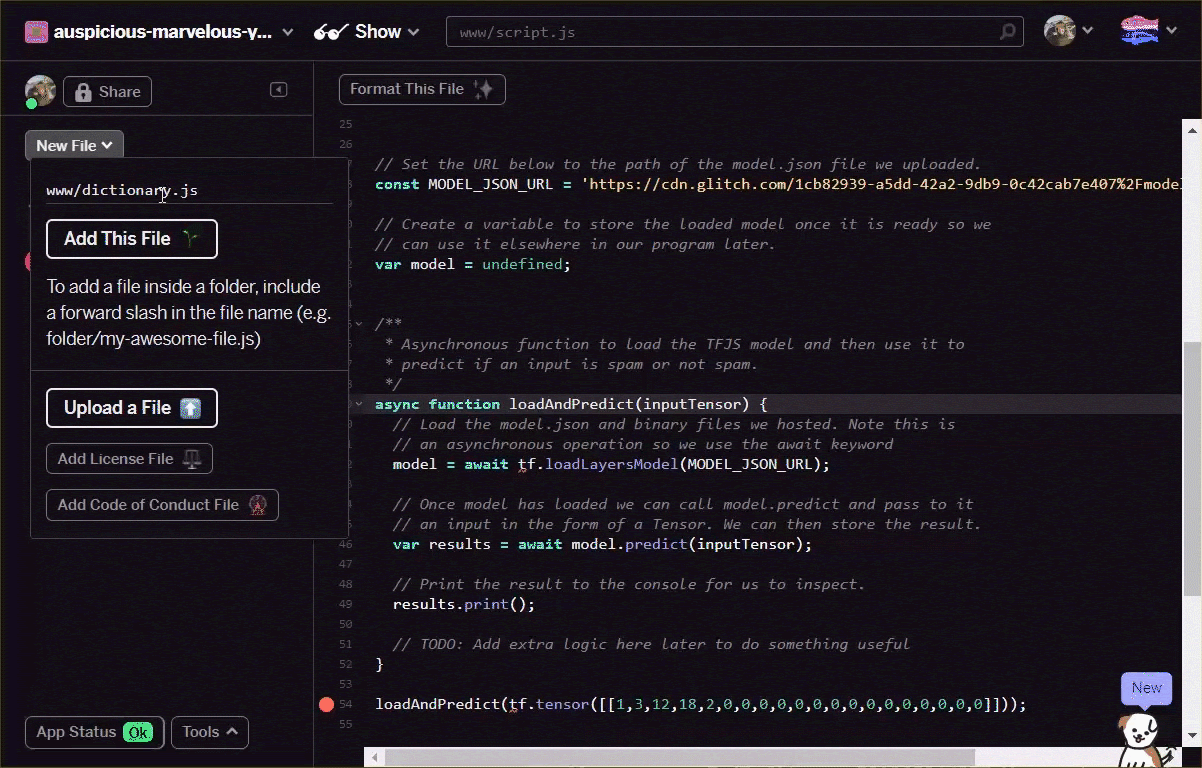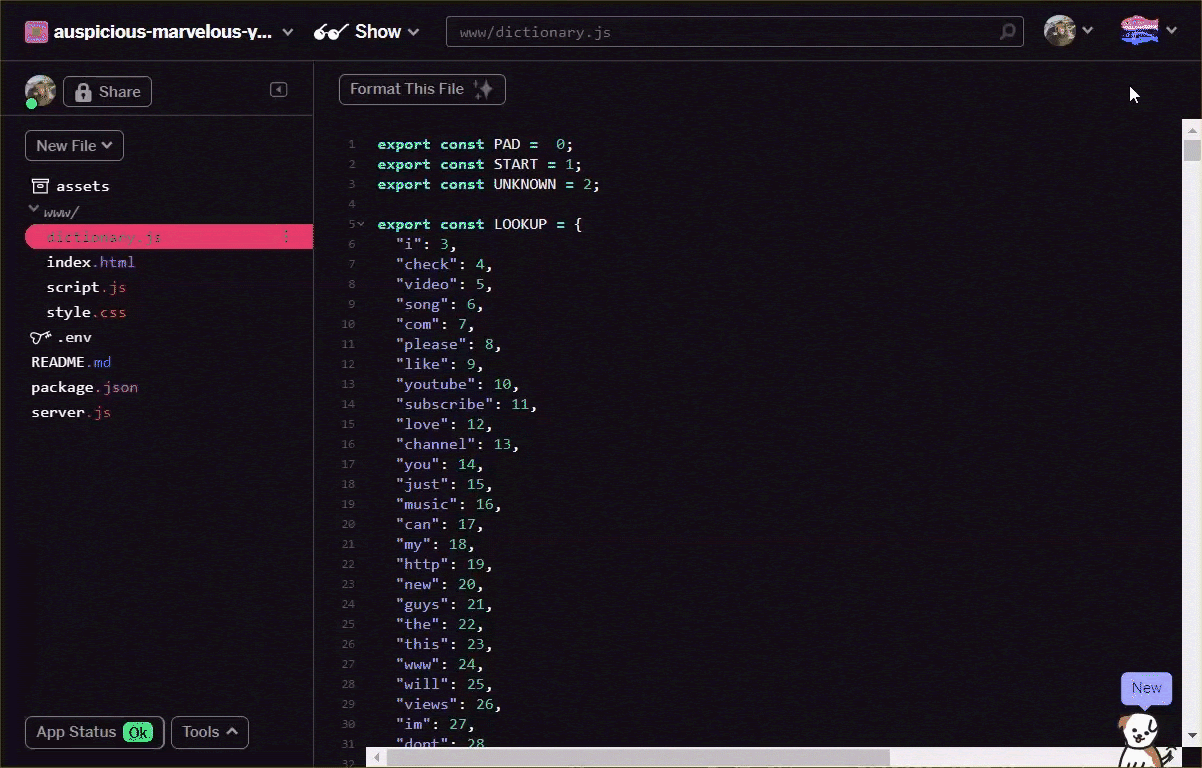
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
Mit deinem bevorzugten Texteditor kannst du die vocab-Datei ganz einfach in ein solches Format umwandeln. Sie können jedoch auch dieses vorgefertigte Tool verwenden.
Wenn du das im Voraus machst und die Datei vocab im richtigen Format speicherst, musst du diese Konvertierung nicht durchführen und jedes Mal, wenn die Seite geladen wird, ist eine Verschwendung von CPU-Ressourcen. Darüber hinaus haben JavaScript-Objekte die folgenden Eigenschaften:
"Ein Objekteigenschaftenname kann ein gültiger JavaScript-String oder ein beliebiger String sein, der in einen String umgewandelt werden kann, einschließlich des leeren Strings. Auf Namen von Properties, die keine gültige JavaScript-ID sind, kann beispielsweise nur mit einer eckigen Klammer auf ein Property zugegriffen werden, zum Beispiel ein Leerzeichen mit einem Leerzeichen oder einem Bindestrich oder eine Ziffer.
Wenn Sie also die eckige Klammer verwenden, können Sie mit dieser einfachen Transformation eine effiziente Suchtabelle erstellen.
In ein hilfreicheres Format konvertieren
Konvertieren Sie die Vokabeldatei entweder oben selbst oder mit diesem Tool manuell in das Format. Speichern Sie die resultierende Ausgabe als dictionary.js im Ordner www.
In Glitch kannst du einfach an dieser Stelle eine neue Datei erstellen und das Resultat deiner Konvertierung einfügen:
Wenn du eine gespeicherte dictionary.js-Datei im oben beschriebenen Format hast, kannst du den folgenden Code ganz oben in script.js voranstellen, um das dictionary.js-Modul zu importieren, das du gerade geschrieben hast. Hier definierst du auch eine zusätzliche Konstante ENCODING_LENGTH, damit du weißt, wie die Abfüllung im Code später möglich sein wird. Außerdem gibst du eine tokenize-Funktion an, mit der du ein Wortarray in einen geeigneten Tensor umwandeln kannst, der als Eingabe für das Modell verwendet werden kann.
In den Kommentaren im Code unten finden Sie weitere Informationen zu den einzelnen Zeilen:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Verwenden Sie jetzt die Funktion handleCommentPost(), indem Sie sie durch die neue Version der Funktion ersetzen.
Im Code für Kommentare zu den von dir hinzugefügten Elementen siehst du:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Aktualisieren Sie dann die loadAndPredict()-Funktion, um einen Stil festzulegen, wenn ein Kommentar als Spam erkannt wird.
Derzeit ändern Sie einfach den Stil. Später können Sie den Kommentar aber in irgendeiner Weise zurückhalten oder nicht mehr senden.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Echtzeitaktualisierungen: Node.js + WebSockets
Sie haben jetzt ein funktionierendes Front-End mit Spamerkennung. Das letzte Teil des Puzzles ist die Verwendung von Node.js mit einigen WebSockets für die Echtzeitkommunikation und die Aktualisierungen in Echtzeit, sofern es sich dabei nicht um Spam handelt.
Socket
Socket.io ist eine der beliebtesten Methoden (zum Zeitpunkt der Erstellung), um WebSockets mit Node.js zu verwenden. Füge jetzt Glitch hinzu, dass die Socket.io-Bibliothek in den Build einbezogen werden soll. Bearbeite dazu package.json im übergeordneten Verzeichnis (im übergeordneten Ordner des www-Ordners), um Socket.io als eine der Abhängigkeiten hinzuzufügen:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Super! Aktualisieren Sie nach der Aktualisierung index.html im Ordner www, um die Socket.io-Bibliothek einzubeziehen.
Fügen Sie die folgende Codezeile einfach über dem HTML-Skript-Tag-Import für script.js am Ende der index.html-Datei ein:
index.html
<script src="/socket.io/socket.io.js"></script>
Die Datei „index.html“ sollte jetzt drei Skript-Tags enthalten:
- ersten Import der TensorFlow.js-Bibliothek
- Der zweite Import von „socket.io“, den Sie gerade hinzugefügt haben,
- und zuletzt importieren Sie den script.js-Code.
Bearbeiten Sie dann server.js, um socket.io innerhalb des Knotens einzurichten und ein einfaches Back-End zu erstellen, um Nachrichten zu empfangen, die an alle verbundenen Clients empfangen wurden.
In den Codekommentaren unten wird die Funktionsweise des Node.js-Codes erläutert:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Super! Sie haben jetzt einen Webserver, der auf socket.io-Ereignisse wartet. Sie haben ein comment-Ereignis, wenn ein neuer Kommentar von einem Client eingeht, und der Server gibt remoteComment-Ereignisse aus, auf die der clientseitige Code wartet, um einen Remotekommentar zu rendern. Der letzte Schritt besteht darin, der clientseitige Socket-Logik hinzuzufügen, um diese Ereignisse auszugeben und zu verarbeiten.
Füge zuerst den folgenden Code am Ende von script.js hinzu, um eine Verbindung zum socket.io-Server herzustellen und Folgendes zu beobachten / behandeln:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Fügen Sie schließlich einen Code in die loadAndPredict-Funktion ein, damit ein socket.io-Ereignis ausgegeben wird, wenn es sich bei dem Kommentar nicht um Spam handelt. Dadurch können Sie die anderen verbundenen Clients mit diesem neuen Kommentar aktualisieren, da der Inhalt dieser Nachricht ihnen über den oben geschriebenen server.js-Code weitergeleitet wird.
Ersetze einfach deine vorhandene loadAndPredict-Funktion durch den folgenden Code, der die else-Anweisung zur letzten Spamprüfung hinzufügt. Wenn es sich bei dem Kommentar nicht um Spam handelt, rufe socket.emit() auf, um alle Kommentardaten zu senden:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
Gut gemacht! Wenn Sie sich an die Regeln halten, sollten Sie jetzt zwei Instanzen Ihrer index.html-Seite öffnen können.
Wenn Sie Kommentare posten, die keine Spamnachrichten sind, sollten Sie sie fast sofort auf dem anderen Client rendern. Falls es sich bei dem Kommentar um Spam handelt, wird er nie gesendet. Stattdessen wird er im Front-End als Spam markiert, sodass er nur so aussieht:
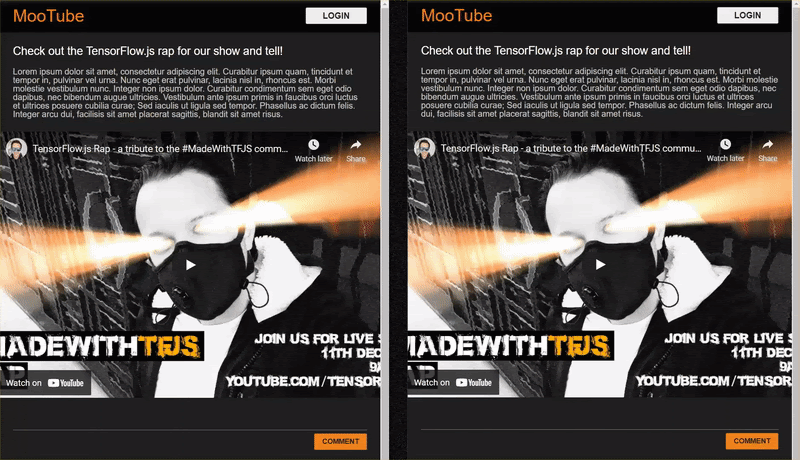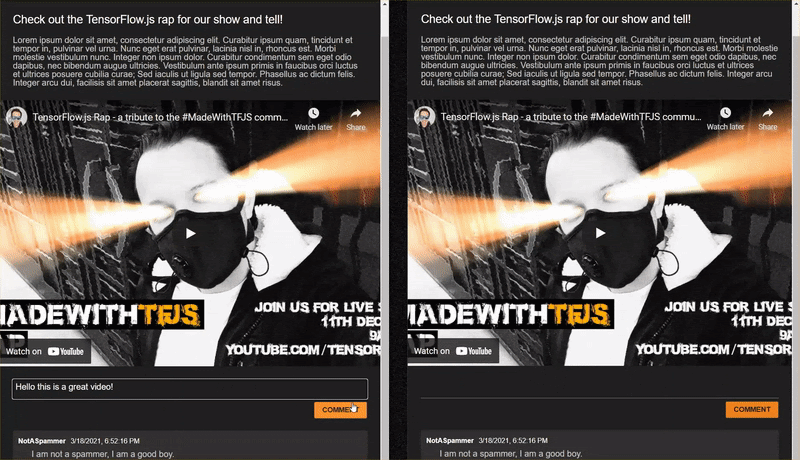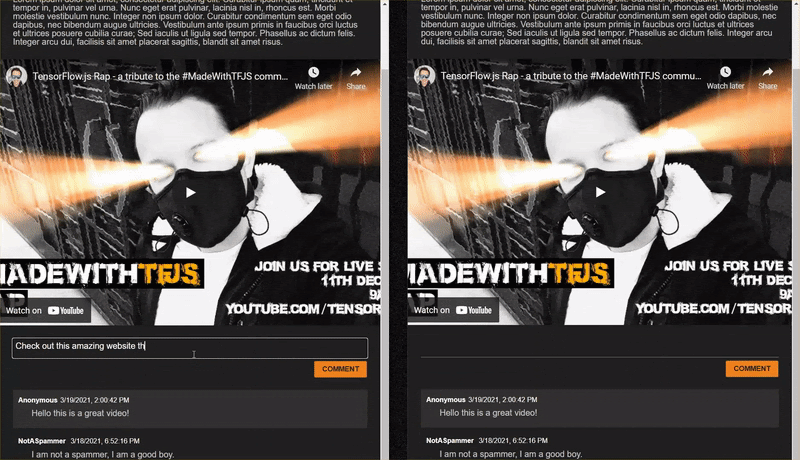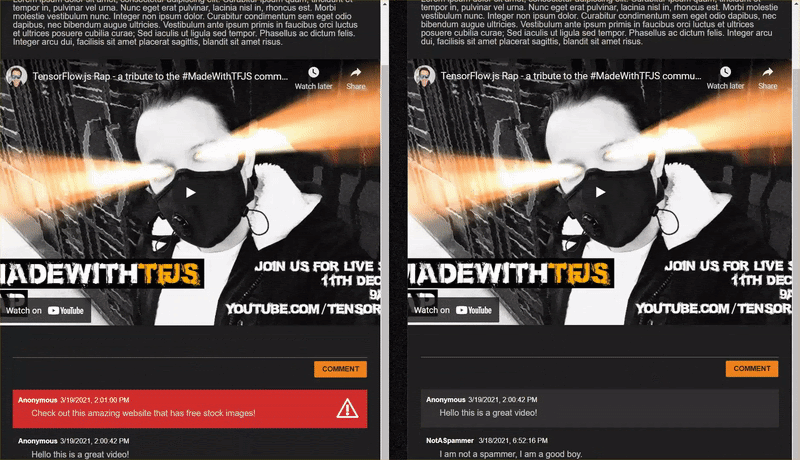
12. Glückwunsch
Glückwunsch! Sie haben die ersten Schritte bei der Verwendung von maschinellem Lernen mit TensorFlow.js im Webbrowser eingesetzt, um eine reale Anwendung zu erhalten – um Spamkommentare zu erkennen.
Probiere sie aus und teste sie bei einer Vielzahl von Kommentaren. Möglicherweise fällt dir dabei noch etwas auf. Beachten Sie auch, dass die Eingabe eines Satzes, der mehr als 20 Wörter umfasst, derzeit fehlschlägt, da das Modell 20 Wörter als Eingabe erwartet.
In diesem Fall müssen Sie lange Sätze in Gruppen mit jeweils 20 Wörtern unter Umständen aufteilen und anschließend die Spamwahrscheinlichkeit für die einzelnen Untergruppen berücksichtigen, um festzustellen, ob sie angezeigt werden sollen. Wir lassen Sie optional weitere optionale Tests durchführen, da Sie viele Möglichkeiten haben, um das Problem zu lösen.
Im nächsten Codelab erfahren Sie, wie Sie dieses Modell mit den benutzerdefinierten Kommentardaten neu trainieren, falls es derzeit nicht erkannt wird. Außerdem haben Sie die Möglichkeit, die Erwartungen der Modelle zu ändern, damit sie Sätze mit einer Länge von mehr als 20 Wörtern verarbeiten und das Modell dann mit TensorFlow.js exportieren und verwenden können.
Falls Sie aus irgendeinem Grund Probleme haben, vergleichen Sie den Code mit dieser abgeschlossenen Version.
Zusammenfassung
In diesem Codelab kannst du Folgendes tun:
- Lerne, was TensorFlow.js ist und welche Modelle für die Natural Language Processing vorhanden sind
- Erstellt eine fiktive Website für Kommentare in Echtzeit zu einer Beispielwebsite.
- Vortrainiertes ML-Modell, das für die Kommentar-Spam-Erkennung über TensorFlow.js auf der Webseite geeignet ist
- Lernen Sie, wie Sie Sätze für das geladene Modell für maschinelles Lernen codieren und diese Codierung in einen Tensor kapseln.
- Die Ausgabe des Modells für maschinelles Lernen wurde so interpretiert, dass entschieden wird, ob der Kommentar zur Überprüfung zurückgehalten werden soll. Ist dies nicht der Fall, wird er an den Server gesendet, um ihn an andere Clients in Echtzeit weiterzuleiten.
Nächste Schritte
Sie haben jetzt eine solide Grundlage für kreative Ideen. Wie könnten Sie Ihre Textbausteine für maschinelles Lernen ausbauen, um damit reale Anwendungsfälle zu testen?
Teilen Sie uns Ihre Meinung mit
Sie können erweitern, was Sie heute für andere kreative Anwendungsfälle gemacht haben, und wir raten Ihnen, auch außerhalb des Internets zu denken und weiterzuhacken.
Denke daran, uns in den sozialen Medien mit dem Hashtag #MadeWithTFJS zu taggen, damit dein Projekt in unserem TensorFlow-Blog oder sogar in nächsten Veranstaltungen präsentiert wird. Wir würden gern wissen, was du machst.
Weitere TensorFlow.js-Codelabs
- In Teil 2 dieser Serie erfährst du, wie du das Kommentar-Spam-Modell neu trainieren kannst, um Grenzfälle zu berücksichtigen, die derzeit nicht als Spam erkannt werden.
- Mit Firebase Hosting ein TensorFlow.js-Modell im großen Maßstab bereitstellen und hosten.
- Mithilfe des vorgefertigten Modell zur Objekterkennung mit TensorFlow.js eine intelligente Webcam erstellen
Websites, die Sie kennenlernen möchten
- Offizielle Website von TensorFlow.js
- Vordefinierte Modelle von TensorFlow.js
- TensorFlow.js-API
- TensorFlow.js-Bilder ansehen – Lassen Sie sich inspirieren und sehen Sie, was andere erstellt haben.